
Por Benjamín Vidal, Periodista Especializado en Inteligencia Artificial y Ciencia y Datos, para Mundo IA
El punto de partida: de la orquesta caótica al solista que sabe tocarlo todo
Los sistemas multiagente nacieron con una promesa que seduce a cualquier organización: dividir un problema complejo en tareas especializadas, repartirlas entre “personas” sintéticas que dominan un oficio, coordinar su colaboración y recomponer la respuesta final en algo superior a la suma de las partes. En la práctica, esa orquesta suele desafinar. La coordinación cuesta, el intercambio de mensajes crece sin control, la latencia se dispara, los costos se vuelven impredecibles y el mantenimiento se parece más a la logística de un festival que a la tranquilidad de un recital íntimo. A veces, para resolver una consulta razonable, hay que armar una mesa de varios agentes que se pasan notas, consultan herramientas, discuten con buena fe y terminan demorando una decisión que, en teoría, debía agilizarse.
El trabajo Chain-of-Agents ofrece una salida elegante a ese callejón. En lugar de diseñar y operar una troupe de agentes separados, plantea entrenar un solo modelo para que se comporte como muchos. El truco no es místico. Primero se destilan, a partir de corridas exitosas de frameworks multiagente, trayectorias completas que incluyen planificación, llamadas a herramientas, observaciones y etapas de reflexión. Después se pule esa base con aprendizaje por refuerzo orientado a tareas verificables, donde la recompensa es binaria y no hay lugar para el relato. El resultado son Agent Foundation Models, modelos de propósito general que, en tiempo de ejecución, activan internamente diferentes roles y herramientas, conservan un estado unificado y reducen al mínimo la cháchara entre agentes. En vez de coordinar un comité, se entrena a un profesional que, llegado el caso, interpreta a todo el comité.
La diferencia no es menor. Donde un pipeline tradicional reparte el problema en módulos y los hace hablar entre sí, la propuesta seca esa humedad con una dinámica más austera. Al no depender de múltiples instancias con estados dispersos, disminuye el costo de tokens en inferencia, baja la cantidad de llamadas a herramientas y reduce la fragilidad de los flujos. El modelo no deja de “ser varios” cuando le conviene, pero lo hace en silencio, sin boletines internos ni deliberaciones ruidosas. Es como si el solista supiera piano, bandoneón, percusión y contrabajo, y los ejecutara de a uno, en el orden justo, con memoria coherente. Para quien mira desde la platea, el efecto es el mismo que el de una banda afiatada. Para quien paga la luz del escenario, el ahorro es sustantivo.
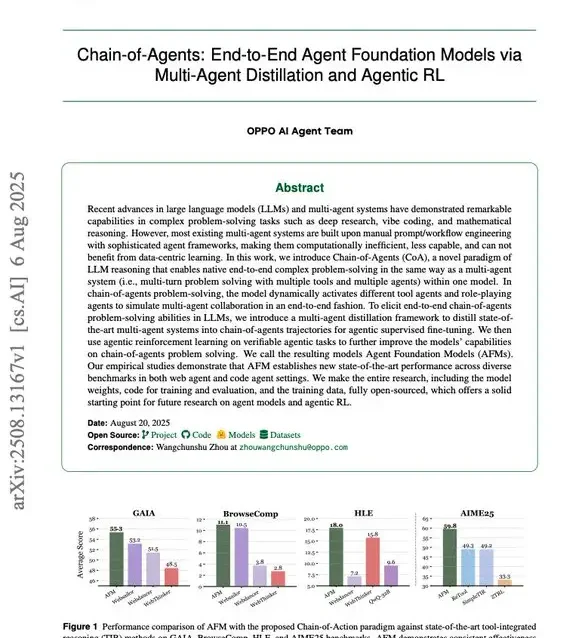
Cadena-de-Agentes
Idea para entrenar un único modelo con las capacidades de un sistema multi-agente. ¡Reducción del 84,6% en el costo de inferencia!
Cómo se entrena a un “equipo” dentro de una sola cabeza
La receta se despliega en dos actos. El primero, de ajuste supervisado, adapta datos estilo ReAct a un formato Chain-of-Agents que conserva cadenas de razonamiento largas y cortas, enfatiza coherencia entre pasos, eficiencia en el uso de herramientas y una cuota explícita de reflexión. No todo vale: hay un filtrado progresivo, que limpia trayectorias flojas, prioriza casos exigentes y rescata aquellas secuencias donde el plan, la ejecución y la verificación formaron un hilo sin nudos. Ese “arranque en frío” le da al modelo repertorio táctico. Aprende a planificar, a decidir cuándo invocar una herramienta, a leer lo que vuelve, a incorporar la evidencia y a corregir el rumbo si llega una señal contradictoria.
El segundo acto, de refuerzo, evita la gimnasia abstracta. Se eligen tareas donde las herramientas importan de verdad. En web, el veredicto lo dicta un juez automático basado en LLM que sanciona correcto o incorrecto. En programación y matemática, hay exact match o ejecución de tests. No se premian intuiciones bonitas ni frases redondas, se premia acertar. Ese mecanismo endurece el músculo agentivo, robustece la coordinación de herramientas y templ(a) la cadena de pensamiento para que soporte presión. Lo más valioso no es que el modelo “sepa más”, sino que desarrolle hábitos operativos: decidir con criterio cuándo mirar afuera, cómo controlar la calidad de lo que trae una API, qué hacer si la herramienta devuelve ruido, cuándo es momento de replanificar y cuándo conviene insistir.
El punto sutil está en el estado. Un multiagente típico reparte estados parciales. Cada subagente guarda su memoria y, si el orquestador no sincroniza con precisión, emergen contradicciones. El enfoque de Chain-of-Agents prefiere un solo estado coherente. Los “roles” conviven dentro de la misma memoria de trabajo, de modo que la percepción, el razonamiento y la acción se encadenan sin pérdidas por fricción. Cuando se activa el rol planificador y luego el rol de ejecución, ambos pisan la misma pista. No hay que traducir de un dialecto a otro ni reconciliar subversiones de la verdad. Esa continuidad reduce las posibilidades de aprietos conocidos: loops de coordinación, decisiones inconsistentes, herramientas invocadas tarde o mal, resultados que nadie revalida.
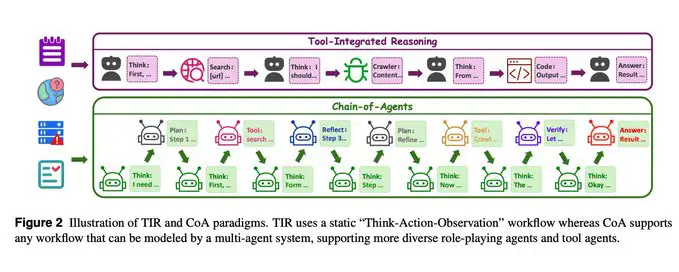
Cambio de paradigma: generalizar sin inflar la factura
La comparación con estrategias como ReAct y Tool-Integrated Reasoning es inevitable. Esas familias demostraron que razonar en público, alternar pensamiento y acción, y apoyarse en herramientas externas mejora el desempeño. Lo que faltaba era un modo de escalar esa idea sin inflar costos ni complejidades de ingeniería. Chain-of-Agents toma ese hilo y lo estira: en vez de sumar agentes para cada rol, activa roles dentro del mismo modelo. El estado unificado evita repetir contexto, sintetiza lo que importa y recorta llamadas innecesarias. La intuición es simple. Si en un sistema con múltiples voces cada intervención exige repetir el guion, pagar ese peaje en tokens una y otra vez quita aire. Si en cambio la voz que piensa, la que busca y la que verifica comparten memoria, los peajes se pagan una sola vez.
Los números acompañan la intuición. Al reducir el ida y vuelta entre instancias, la propuesta recorta la cuenta de inferencia y la cantidad de herramientas invocadas. En el balance reportado, el costo de tokens cae de manera muy marcada y el rendimiento se mantiene competitivo, incluso sube cuando se habilita escalado en tiempo de prueba con estrategias simples como best-of-n o pass@n. No hay magia, hay menos sobrecarga estructural. Para quien opera agentes en producción, esa diferencia se traduce en dos cosas que valen oro: previsibilidad y margen. Previsibilidad, porque ya no hay que adivinar cuántas rondas de conversación entre agentes requerirá un caso problemático. Margen, porque cada consulta quema menos presupuesto.
Hay otra derivada interesante. Generalizar a herramientas que el modelo no vio requiere disciplina en el formato. Si el sistema espera inputs y outputs precisos, cualquier desviación se convierte en tropiezo. En esa arena, un solo cerebro obsesivo funciona mejor que una mesa con varios criterios. El entrenamiento incentiva a respetar “formas” estrictas y a detectar rápido cuándo una herramienta no respondió con el molde correcto. Ese celo formalista suele traducirse en menos errores tontos en la integración con APIs, bases y navegadores.

Cambio de paradigma: CoA generaliza ReAct/TIR al activar dinámicamente múltiples roles y herramientas dentro de un mismo modelo, preservando un único estado coherente mientras reduce el intercambio innecesario entre agentes.
Resultados que importan: web, código, matemática y multi-paso
Un enfoque ambicioso debe rendir cuentas en pruebas acordes. El paper evalúa con una batería amplia. En tareas que exigen navegación, extracción y síntesis de la web, los modelos muestran avances concretos frente a enfoques previos. En suites de preguntas que requieren saltos múltiples, la consistencia del estado unificado ayuda a sostener la cadena lógico-evidencial sin que se desarme a mitad de camino. En entornos de programación y matemática, donde la verificación es tajante, el ajuste por refuerzo sobre test cases empuja mejoras claras. No es casualidad. El eco entre plan, herramienta, observación y reflexión, entrenado como rutina, genera menos fallas de integración y más respuestas que pasan los chequeos externos.
Esa misma disciplina se potencia con escalado en tiempo de prueba. Si se permite que el modelo explore varias trayectorias y se quede con la mejor de tres, el techo sube. Es un recordatorio útil: no todo lo que mejora una arquitectura requiere reentrenar. A veces basta con jugar en inferencia, dar una segunda oportunidad y elegir la más consistente. En un modelo que internalizó el hábito de planificar, mirar, verificar y corregir, esa segunda oportunidad no duplica caprichos, duplica orden.
Un detalle a no perder de vista es el backbone. Los resultados reportados con familias de 32B muestran que la idea no necesita escalar hasta dimensiones exóticas para dar frutos. Es una buena noticia para equipos que no tienen granjas inagotables. La eficiencia de tokens y la parsimonia en llamadas a herramientas, sumadas a la posibilidad de escalar con best-of sin multiplicar instancias, dibujan una curva de costo-beneficio razonable. En otras palabras, no hace falta hipotecar la infraestructura para probar este enfoque en serio.
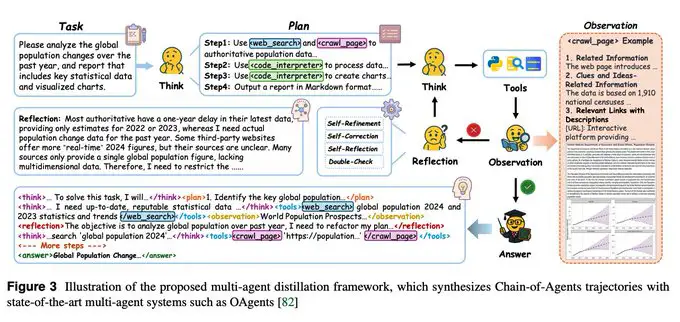
-
La destilación multi-agente convierte ejecuciones exitosas de OAgents en trazas con formato CoA que incluyen planificación, llamadas a herramientas, observaciones y reflexión, filtradas según dificultad y calidad.
-
El aprendizaje por refuerzo agentivo se dirige a consultas difíciles donde las herramientas son relevantes, utilizando recompensas binarias simples mediante un LLM-como-Juez para tareas web, y recompensas ejecutables o de coincidencia exacta para código/matemática.
Del laboratorio al trabajo: qué cambia para productos y procesos
Llevar agentes a producción siempre fue más antropología que ingeniería. No alcanza con que el prototipo brille. Hay que insertarlo en flujos, hablar con sistemas que ya estaban, respetar políticas de datos, seguir normas, tolerar casos raros y, sobre todo, no romper nada. El talón de Aquiles de muchas arquitecturas multiagente fue precisamente ese: alinear tantas piezas en una cadena larga, con estados parciales y responsabilidades cruzadas, exponía demasiadas costuras. El paso a un modelo único que interpreta varios roles reduce esa superficie de riesgo. No elimina el desafío de integrar, pero baja el número de uniones que pueden fallar.
En un equipo de producto, ese cambio se percibe así. Antes, para sumar una capacidad nueva, había que definir un agente, describir su contrato, crear su ciclo de vida, asegurarse de que los demás lo respetaran y que el orquestador supiera darle la palabra y escuchar su regreso. Ahora, la nueva capacidad se enseña como un rol interno con sus señales de activación. La conversación ya no es “cómo se lleva este agente con los demás”, sino “cuándo conviene que el modelo despierte esta habilidad y cómo valida lo que trae”. La frontera entre diseño de prompts, herramientas y política de control se vuelve más limpia.
Para áreas como atención al cliente, soporte técnico, cobranzas, compliance o backoffice, que suelen tener procesos con reglas claras y mucha variación en superficie, la disciplina de plan-actuar-verificar cae bien. Un caso típico: triage de tickets con sugerencia de resolución y borrador de respuesta. El modelo puede planificar qué datos internos mirar, invocar un buscador corporativo, leer artículos de conocimiento relevantes, redactar una propuesta y pasarla por un verificador final que controle tono, campos obligatorios y referencias. Todo en la misma cabeza, con el mismo estado. Si el verificador detecta una falta, se reintenta. No hay que coordinar dos o tres agentes que discuten quién tiene razón, basta con ajustar el paso que falló.
En marketing de performance, donde abundan herramientas externas y formatos estrictos, la obsesión por cumplir con schemas minimiza rechazos en APIs y acelera ciclos de experimentación. En operaciones financieras, la ventaja aparece al integrar conectores que piden números con precisión decimal y tolerancia cero a ambigüedades. En ingeniería, la ruta de generar código, ejecutar tests, leer resultados y corregir, todo bajo una misma memoria, se siente natural. Donde antes había un ping-pong entre agentes que generaban y otros que verificaban, ahora hay un hábito unificado de escribir, probar y refinar.
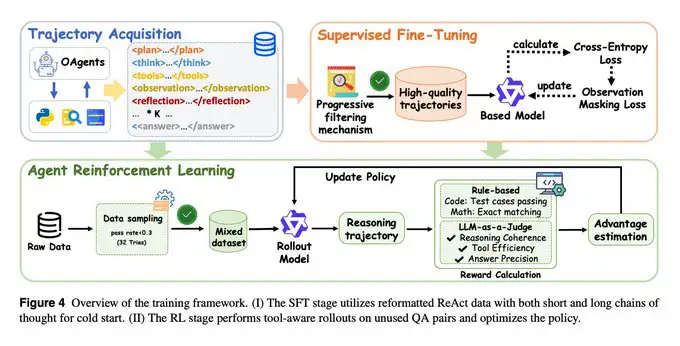
Marco de entrenamiento
Etapa 1 (SFT) – utiliza datos reformateados al estilo ReAct (tanto cadenas de razonamiento cortas como largas) para darle al modelo un sólido “arranque en frío”. Un filtrado progresivo asegura que solo se usen trayectorias de alta calidad, enfatizando coherencia, eficiencia en el uso de herramientas y razonamiento reflexivo.
Etapa 2 (RL) – se construye sobre la base de SFT. El modelo realiza rollouts con conciencia de herramientas en pares de preguntas y respuestas no utilizados. Las recompensas se calculan a partir de la corrección de la tarea (mediante LLM-como-Juez, coincidencia exacta o casos de prueba), y las actualizaciones de la política mejoran la coordinación con herramientas y la solidez del razonamiento.
Limitaciones reales y cómo encararlas sin autoengañarse
No todo es rosa. Un modelo que hace de muchos también concentra responsabilidad. Si falla un rol interno, falla la obra. El entrenamiento tiene que ser cuidadoso para que los distintos papeles no se pisen ni se confundan. La detección de cuándo invocar una herramienta sigue siendo un arte con espinas. Un exceso de confianza lleva a consultas innecesarias que devoran presupuesto. Una timidez excesiva evita mirar afuera cuando hace falta, y la respuesta pierde sustancia. El equilibrio se aprende, pero nunca se fija para siempre. Por eso conviene monitorear de cerca métricas operativas: frecuencia de llamadas, tasa de éxito por herramienta, formatos mal formados, reintentos, loops de replanificación.
La otra cara del realismo tiene que ver con el contexto corporativo. Aunque se reduzca la complejidad de coordinación, la integración con sistemas legados, permisos, auditoría y cumplimiento normativo no desaparece. Hay que seguir resolviendo autenticación, trazabilidad y límites de uso. En sectores regulados, la verificación independiente no es un capricho, es una obligación. La buena noticia es que un modelo que aprendió a validar su propio output conversa mejor con controles externos. Si ya está acostumbrado a chequear formatos y pasar tests, aceptar un validador corporativo adicional no es un trauma.
También es sano reconocer que un único estado coherente no siempre es la mejor opción. Hay escenarios donde sí conviene separar. Por motivos de seguridad, por independencia de fallas, por escalamiento diferenciado, por competencia de proveedores. La virtud de la propuesta no está en prohibir el multiagente tradicional, sino en ampliar el repertorio. En muchos flujos de trabajo, simplificar a un solista capaz rinde más que sostener una orquesta pequeña. En otros, la orquesta tiene sentido y el solista puede ocupar uno de los atriles.
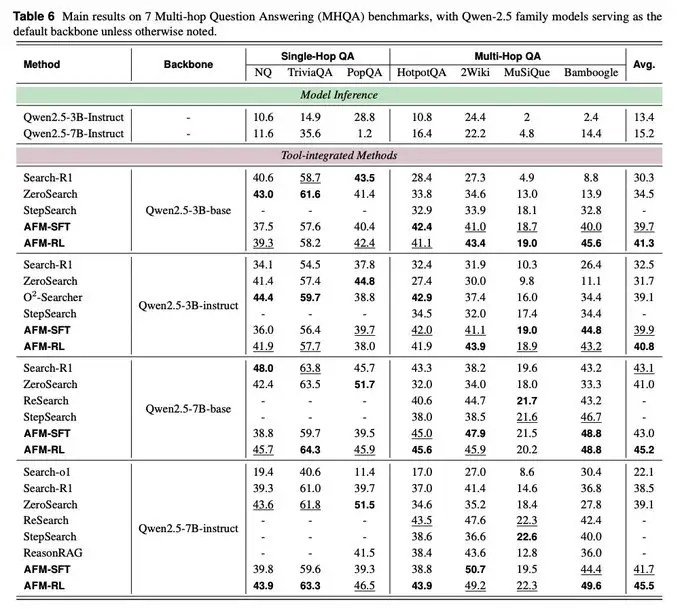
Resultados principales
Con los backbones Qwen-2.5-32B, los Agent Foundation Models (AFM) establecen un nuevo pass@1 en GAIA con 55.3, en BrowseComp con 11.1, en HLE con 18.0, y lideran en WebWalker con 63.0; además, también superan en suites de preguntas y respuestas multi-hop en todos los tamaños.
Analogías para aterrizar la idea sin perder precisión
Una metáfora útil es la de una cocina intensa. En la versión multiagente clásica, la receta viaja entre partidas. El pastelero pide al confitero, que reclama al hornero, que consulta a la jefa de sala, que devuelve la orden con una nota, y todos repiten ingredientes en cada mensaje. En la versión Chain-of-Agents, el cocinero es uno. Sabe medir, batir, hornear y emplatar. No hace todo a la vez, va activando su rol según la etapa. No multiplica conversaciones, conserva una lista única de ingredientes y una memoria viva de lo que ya está en el horno. El comensal recibe un postre igual o mejor. El dueño del restaurante recibe una cuenta de gas más baja.
Otra imagen sirve para el escalado en tiempo de prueba. Es el mismo cocinero que prepara tres variantes rápidas, las prueba, elige la más lograda y sirve esa. No contrató dos ayudantes extra. No duplicó la vajilla. Aprovechó que, como ya entrenó el hábito de verificar, puede fallar barato y decidir mejor sin convertir cada intento en un banquete. En entornos donde hay poco margen para equivocarse de cara al cliente pero sí margen para explorar tras bambalinas, ese best-of-tres aporta calidad sin multiplicar costo fijo.
Una tercera analogía habla de viajes. Un sistema multiagente entrega varios mapas, cada uno con notas, y un coordinador que intenta consolidar rutas con resaltador. Chain-of-Agents maneja un mapa único donde las notas se suman en el margen y las marcas se actualizan sobre el mismo papel. Se evitan duplicados, no hace falta reconciliar nomenclaturas y se reduce la oportunidad de terminar en una rotonda de la que nadie sabe salir.
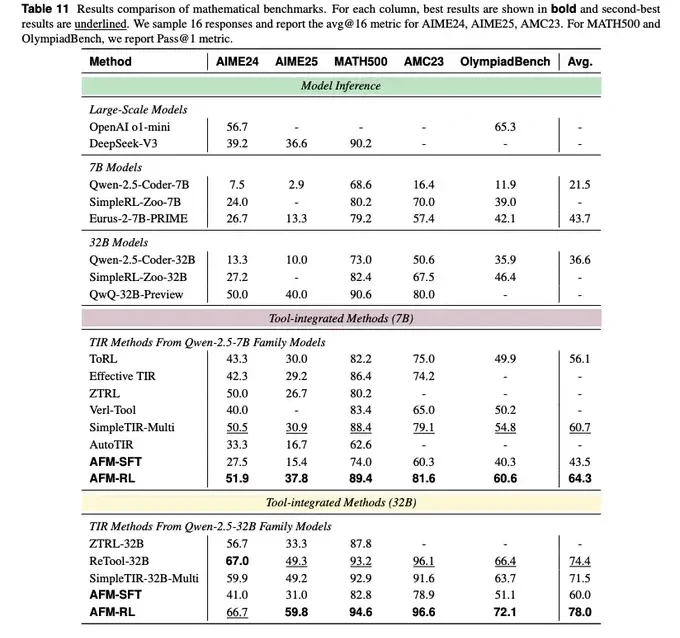
Código + matemática
AFM-RL-32B alcanza 59.8 en AIME25, 94.6 en MATH500, 72.1 en OlympiadBench y 47.9 en LiveCodeBench v5, superando a métodos TIR previos como ReTool y Reveal.
Qué significa esto para equipos en Argentina y la región
Para quien desarrolla productos desde Buenos Aires, Córdoba, Montevideo o Santiago, sin presupuestos siderales ni GPUs a discreción, la tesis es atractiva. Si una arquitectura de un solo modelo, entrenada con disciplina, puede ofrecer resultados de punta con una factura de cómputo contenida, entonces la barrera de entrada baja. No hay que montar un parque de agentes con mantenimiento permanente. Se puede dedicar el tiempo a seleccionar bien los casos en los que la herramienta hace diferencia, a diseñar ciclos de verificación austeros y a instrumentar monitoreo que alerte antes de que algo se descontrole.
En términos de adopción empresarial, hay un mensaje claro para quienes lideran áreas con presión de eficiencia. Es preferible encarar dos o tres flujos de alto impacto con un modelo que planifica, actúa, observa y reflexiona de manera ordenada, que dispersarse en un catálogo de bots que nadie logra alinear. Empezar por procesos con verificación automática ayuda a generar confianza interna, medir mejoras y ajustar parámetros con datos. Luego sí, escalar hacia casos menos obvios, quizá con validadores humanos al principio, hasta que la tasa de aciertos habilite más autonomía.
Para universidades y laboratorios, hay un campo fértil de investigación aplicada. Evaluar hasta dónde llega la generalización a herramientas no vistas, estudiar estrategias de curriculum para roles internos, explorar recompensas que midan no solo exactitud sino economía de recursos, investigar cómo detectar tempranamente loops improductivos, diseñar memorias que preserven contexto útil sin inflarlo todo. La intersección entre ciencia de datos y diseño de procesos vuelve a ser un territorio compartido, de esos donde un estudiante curioso puede aportar una idea que baje costo mañana.
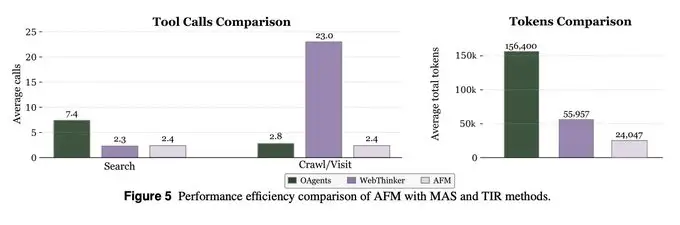
Eficiencia y solidez
En comparación con los sistemas multi-agente tradicionales, AFM reduce sustancialmente los tokens de inferencia y las llamadas a herramientas.
El paper informa una reducción del 84,6% en el costo de tokens mientras mantiene competitividad. Además, generaliza mejor a herramientas no vistas cuando se requiere un formato estricto.
Mirada a mediano plazo: agentes menos teatrales, más profesionales
Si algo deja claro esta línea es que la evolución interesante no pasa por sumar efectos especiales, sino por domar la coreografía. Menos grandilocuencia y más oficio. Un agente capaz, en este sentido, se parece a una buena herramienta de trabajo. No tiene que impresionar cada vez, tiene que rendir todos los días. El entrenamiento que combina destilación multiagente con refuerzo en tareas verificables apunta a eso: inculcar hábitos de oficio. Ver primero, decidir con criterio, ejecutar con prolijidad, chequear que está bien y recién ahí cerrar.
La industria aprendió a los golpes que la adopción exitosa de IA no es una cuestión de comprar cajitas, sino de acomodar prácticas, medir, iterar y dejar que las capacidades se inserten en lo cotidiano. Chain-of-Agents contribuye un eslabón técnico que facilita esa transición. Tal vez no sea el único camino, pero es uno que enchufa bien con las restricciones reales que enfrentan equipos chicos, medianos y grandes. Menos cables sueltos, menos fricción, menos sobresaltos de factura, más foco en lo que la herramienta entrega.
Queda mucho por explorar. La interacción con memorias de largo plazo, la convivencia con servicios críticos, la convivencia con agentes externos cuando tiene sentido federar, los límites de la auto-verificación y la relación entre costo y calidad cuando los problemas son abiertos. Pero hay una ganancia inmediata: si una sola mente bien entrenada puede simular un equipo cuando conviene, los proyectos dejan de depender de hilos invisibles que siempre se cortan en el peor momento. El oficio vuelve a estar en el centro. Y cuando hay oficio, lo demás se ordena.
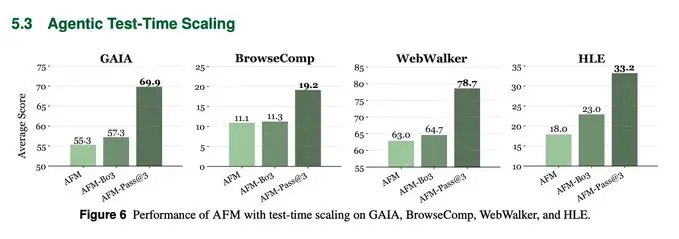
Escalado en tiempo de prueba
Best-of-3 y pass@3 impulsan notablemente a AFM, por ejemplo, GAIA 69.9 y HLE 33.2, cerrando la brecha con stacks de agentes propietarios más grandes.
En conjunto, Chain-of-Agents permite entrenar modelos fundacionales de un solo agente que simulan de manera nativa la colaboración multi-agente, combinando destilación multi-agente con aprendizaje por refuerzo agentivo para alcanzar resultados de vanguardia.
Cierre: una arquitectura para pensar menos en el andamiaje y más en el valor
La gran virtud de esta propuesta no es técnica por sí misma. Es estratégica. Permite recuperar el foco en el problema que importa y dedicarle menos tiempo a sostener la escenografía. Si un modelo único puede internalizar la colaboración y sostener una cadena de acción verificada con menos gasto, cada peso invertido viaja más lejos. En un contexto de presupuestos más vigilados, eso puede marcar la diferencia entre un piloto simpático y un sistema que se queda.
A veces la innovación no aparece cuando inventamos instrumentos nuevos, sino cuando aprendemos a tocar mejor los que ya tenemos. Chain-of-Agents suena a eso. No suma más instrumentos, enseña al músico a cambiar de rol sin desafinar. Para quienes construyen productos y procesos que tienen que funcionar sin épica, esa música suena bien.

