
En el campo en constante evolución de la inteligencia artificial, donde el tamaño a menudo se asocia con la potencia, emerge una investigación que desafía esta premisa fundamental. El modelo Apriel-1.5-15B-Thinker no es simplemente otro avance; representa un cambio de paradigma en la construcción de sistemas de lenguaje artificial. Lanzado en agosto de 2025 por ServiceNow, este modelo de 15 mil millones de parámetros ha logrado rendimientos de alto nivel que rivalizan o incluso superan a modelos significativamente más grandes, como los de 32 mil millones de parámetros, pero con una huella computacional drásticamente reducida. Este reporte explora en profundidad las capacidades, la ingeniería y el impacto del Apriel-1.5-15B-Thinker, revelando cómo ha sido posible crear un gigante del razonamiento en un cuerpo compacto y eficiente. Analizaremos su arquitectura, su meticulosa tubería de entrenamiento, su desempeño excepcional en pruebas rigurosas, sus aplicaciones prácticas y las implicaciones que tiene para el futuro de la tecnología empresarial y la accesibilidad de la IA avanzada.
Fundamentos técnicos y arquitectura innovadora
Para comprender la trascendencia del Apriel-1.5-15B-Thinker, es indispensable desglosar los componentes técnicos que lo sustentan, pues su éxito reside en una combinación sofisticada de una base robusta y estrategias de escalado innovadoras. En términos de escala, este modelo pertenece a la categoría de «Modelos de Lenguaje Pequeños» (SLM), una nueva generación de modelos diseñados para ser más ágiles y eficientes que sus predecesores masivos, sin sacrificar capacidad cognitiva crucial. Su núcleo está basado en el modelo Mistral-Nemo-Base-2407, que posee 12 mil millones de parámetros. ServiceNow no partió de cero, sino que construyó sobre esta base estable, una decisión estratégica que aprovecha el conocimiento previamente adquirido y reduce el costo y tiempo de entrenamiento desde el principio. La etapa de «escalado» fue, por tanto, una ampliación incremental diseñada para incrementar la capacidad del modelo sin introducir inestabilidades. Para lograr esto, se exploraron dos métodos principales: el escalado por anchura, que aumentaría el número de unidades dentro de cada capa, y el escalado por profundidad, que añadiría más capas al modelo. Tras la evaluación, la duplicación de las capas intermedias se determinó como la estrategia preferida, ya que demostró ser más estable y efectiva para alcanzar los 15 mil millones de parámetros finales.
El proceso de entrenamiento, o «tubería», es quizás el aspecto más distintivo y revelador del proyecto. A diferencia de muchos modelos que se entrenan una sola vez con un vasto corpus de datos, Apriel-1.5-15B-Thinker pasa por un proceso iterativo y multifacético de cuatro fases cuidadosamente diseñadas. La primera fase, el «Escalado del Modelo», ya descrita, sentó las bases estructurales. La segunda fase, el «Preentrenamiento Continuo» (CPT), es donde el modelo comienza a desarrollar su profundo entendimiento. Se le sometió a un corpus de alrededor de 70 mil millones de tokens, pero no cualquier tipo de texto. Los investigadores hicieron una elección deliberada y estratégica: el 60% de los datos de entrenamiento estaban enfocados en razonamiento, el 25% en pasos de pensamiento (Chain-of-Thought, CoT) y solo el 15% restante en contenido genérico. Esta ponderación tan alta hacia el razonamiento asegura que el modelo desarrolle una comprensión intrínseca de la lógica, la resolución de problemas y la argumentación, habilidades fundamentales para el pensamiento complejo.
La tercera fase, el «Ajuste Fino Supervisado» (SFT), es una etapa de refinamiento especializado. Aquí, el modelo no aprende de forma autónoma, sino que sigue instrucciones detalladas. Se utilizó un conjunto de datos de hasta un millón de muestras para entrenar un modelo equilibrado, y un subconjunto específico de 200,000 demostraciones de alta calidad para entrenar un modelo enfocado en matemáticas avanzadas. Este último fue entrenado durante ocho épocas, generando entre tres y cuatro soluciones diferentes para cada prompt, lo que obliga al modelo a explorar múltiples caminos de solución y robustece su capacidad de razonamiento matemático. La cuarta y última fase es el «Aprendizaje por Refuerzo con Optimización Guiada de Preferencias» (GRPO). Este método es crucial para alinear el comportamiento del modelo con las expectativas humanas. Utiliza recompensas basadas en reglas para guiar al modelo hacia respuestas correctas en formato, matemáticas, código y uso de herramientas. Durante esta etapa, se generan ocho soluciones candidatas para cada uno de los 100,000 prompts seleccionados, y a partir de un subconjunto de 18,000 prompts que ya tienen al menos una solución correcta, se seleccionan ejemplos para entrenar al modelo en la distinción entre una respuesta buena y una excelente. Finalmente, para obtener el modelo final, se fusionan los puntos de control (checkpoints) de SFT y GRPO utilizando una herramienta llamada mergekit, combinando la precisión de la enseñanza directa con la madurez del refuerzo guiado. Esta tubería meticulosa es la clave de su rendimiento superior.
Rendimiento y capacidad de razonamiento demostrado
El verdadero valor de Apriel-1.5-15B-Thinker se manifiesta en su impresionante desempeño en una batería diversa y exigente de benchmarks académicos y empresariales. Estas evaluaciones no son meras métricas; son crucibles que miden la capacidad real del modelo para resolver problemas complejos, razonar lógicamente y generar código funcional. El objetivo era competir con los modelos de 32 mil millones de parámetros más destacados del mercado, y los resultados demuestran que Apriel ha logrado con creces este objetivo, a menudo superándolos con una eficiencia notable. En tareas de razonamiento matemático, Apriel destaca en benchmarks como MATH-500, AIME’24 y AIME’25, donde obtuvo calificaciones de 91.6%, 73.33% y 60% respectivamente. Otro indicador de su dominio en el razonamiento técnico es GPQA-Diamond, donde alcanzó un 57.4%. En el ámbito del desarrollo de software, el benchmark MBPP (Micro-Benchmark for Professional Programming) registró un 85.8% de pasos completados, y también quedó en segundo lugar en MixEval y MBPP, demostrando una sólida capacidad de codificación.
Pero el alcance de Apriel no se limita a los dominios académicos. Ha sido diseñado específicamente para las complejidades del mundo empresarial. En el benchmark Enterprise RAG (Retrieval-Augmented Generation), que evalúa la capacidad del modelo para utilizar información externa extraída de documentos corporativos, Apriel logró un 69.2%. Esto es crucial para su aplicación como agente de soporte o analista de negocio. Además, en IFEval, una prueba de razonamiento empresarial, el modelo obtuvo una calificación del 84.6%, colocándose en segundo lugar junto con MBPP y MixEval. Su rendimiento general en exámenes de conocimiento amplio, como MMLU-Pro, fue del 73.42%, y mostró un rendimiento competitivo en otros benchmarks importantes como MUSR, Minerva Math y WinoGrande. Una característica distintiva y deliberada del modelo es su implementación explícita de razonamiento paso a paso. Su plantilla de chat obliga al modelo a generar una secuencia de pasos de razonamiento antes de producir una respuesta final, encerrada entre las etiquetas [BEGIN FINAL RESPONSE] y [END FINAL RESPONSE]. Esta función no solo mejora la transparencia del proceso de pensamiento del modelo, sino que también es una estrategia pedagógica que facilita la verificación y la corrección por parte de los usuarios.
La siguiente tabla resume el rendimiento comparativo de Apriel-1.5-15B-Thinker frente a modelos de 32B y otras referencias relevantes.
| Benchmark | Métrica | Apriel-1.5-15B-Thinker | Modelos de 32B de Referencia |
|---|---|---|---|
| MATH-500 | Porcentaje Correcto | 91.6% | Superior |
| AIME’24 | Porcentaje Correcto | 73.33% | Competitivo |
| AIME’25 | Porcentaje Correcto | 60% | Competitivo |
| GPQA-Diamond | Porcentaje Correcto | 57.4% | Competitivo |
| MMLU-Pro | Porcentaje Correcto | 73.42% | Igual / Superior |
| MBPP (pass@1) | Porcentaje Correcto | 85.8% | Segundo Lugar |
| Enterprise RAG | Porcentaje Correcto | 69.2% | Destacado |
| IFEval | Porcentaje Correcto | 84.6% | Segundo Lugar |
Este rendimiento sobresaliente es especialmente notable dada su eficiencia. En comparación con modelos como QWQ-32b y LG-ExaOne-32b, Apriel consume un 40% menos de tokens durante el razonamiento y, crucialmente, requiere aproximadamente la mitad de la memoria computacional. Esta eficiencia es el resultado directo de su diseño optimizado y su tubería de entrenamiento, que prioriza la calidad conceptual sobre la cantidad pura de datos. Al enfocarse en la formación de un sólido fundamento de razonamiento desde el principio, el modelo puede llegar a conclusiones más rápidamente y con menos recursos computacionales, lo que representa una ventaja estratégica considerable en la industria de la IA.
Eficiencia computacional y ventajas estratégicas
Más allá de su impresionante capacidad de razonamiento, el factor diferenciador más crítico de Apriel-1.5-15B-Thinker es su extraordinaria eficiencia computacional. En la actualidad, el coste de la infraestructura de cómputo es una barrera significativa para la adopción de la inteligencia artificial avanzada, una preocupación compartida por el 68% de las empresas según un informe de 2025. Apriel aborda directamente este problema, ofreciendo un rendimiento de gama alta a un costo operativo drásticamente menor. El modelo requiere aproximadamente la mitad de la memoria computacional que sus contrapartes de 32 mil millones de parámetros, como QWQ-32b y EXAONE-Deep-32b. Esta reducción en la demanda de memoria RAM es fundamental, ya que el hardware dedicado a la IA, como las GPUs, es el componente más costoso de la infraestructura. Al necesitar menos de estos recursos, las organizaciones pueden alojar modelos más grandes o ejecutar más instancias simultáneas de modelos similares sin una inversión proporcionalmente mayor.
Además de la eficiencia en memoria, Apriel también es significativamente más económico en términos de consumo de tokens durante las tareas de inferencia, especialmente aquellas que requieren un profundo razonamiento. Se ha estimado que consume un 40% menos de tokens que modelos como QWQ-32b en estas cargas de trabajo. Los tokens son las unidades de procesamiento que consumen los modelos de lenguaje; cada palabra o fragmento de palabra que un usuario introduce y cada palabra que el modelo genera cuenta como un token. Cuanto menos tokens se necesiten para completar una tarea compleja, menor será el tiempo de procesamiento y, por ende, el coste asociado. Esta eficiencia se deriva directamente de su diseño de razonamiento profundo. En lugar de recurrir a largos ciclos de ensayo y error, Apriel ha sido entrenado para seguir caminos de pensamiento más directos y lógicos, llegando a soluciones correctas en menos pasos. Esta ventaja estratégica no es trivial; transforma la IA de un lujo para las grandes corporaciones tecnológicas en una herramienta viable para empresas de todos los tamaños, incluidas pequeñas y medianas empresas (PYMES) que históricamente han sido excluidas por los altos costos operativos.
Esta eficiencia tiene profundas implicaciones para la escalabilidad y la democratización de la IA. Las organizaciones pueden integrar modelos de razonamiento como Apriel en sus flujos de trabajo diarios sin enfrentar la complejidad y el desgaste financieros que antes eran inevitables. El 82% de las empresas planea integrar modelos de razonamiento en los próximos dos años, pero el 60% reconoce que enfrenta dificultades de costo y complejidad. Apriel ofrece una solución tangible a este dilema. Al requerir menos recursos, el modelo es más fácil de implementar, mantener y escalar. Puede ser desplegado en entornos locales, en la nube híbrida o en servidores más económicos, lo que proporciona a las empresas una mayor flexibilidad y control sobre sus activos de IA. Además, la licencia MIT bajo la cual se distribuye el modelo en Hugging Face elimina las barreras legales y de licencia que a menudo frenan la adopción, permitiendo una rápida integración y personalización por parte de la comunidad de desarrolladores. En resumen, la eficiencia de Apriel no es solo una característica técnica, sino un catalizador de cambio que acelera la transición de la IA desde una tecnología de nicho a una herramienta empresarial centralizada y accesible.
Aplicaciones empresariales y potencial transformador
El Apriel-1.5-15B-Thinker no fue concebido como un mero experimento académico; está diseñado para ser un motor de transformación digital en el mundo empresarial. Su arquitectura y capacidades están orientadas explícitamente a resolver problemas tangibles dentro de los flujos de trabajo comerciales actuales. Uno de sus usos más prometedores es como agente de servicio al cliente impulsado por IA. Gracias a su capacidad de razonamiento y su integración con Enterprise RAG, Apriel puede leer y comprender documentación técnica, políticas corporativas o historiales de clientes, y luego generar respuestas precisas y contextualizadas en tiempo real. Esto podría automatizar gran parte del primer nivel de soporte, liberando a los agentes humanos para que se centren en casos más complejos y emocionales, mejorando así la eficiencia y la satisfacción del cliente. La plataforma UBOS, por ejemplo, ya permite la integración de Apriel con plataformas populares como OpenAI ChatGPT y Telegram, lo que facilita su incorporación en los ecosistemas existentes de comunicación empresarial.
Otra área de gran impacto es el análisis predictivo en la cadena de suministro. Apriel puede procesar vastas cantidades de datos operativos, como patrones de demanda, datos meteorológicos, noticias geopolíticas y precios de materias primas, para identificar tendencias y prever posibles interrupciones. Su capacidad de razonamiento lógico le permite evaluar múltiples escenarios y sugerir estrategias de mitigación proactivas. Por ejemplo, podría alertar a una empresa de un posible retraso en la entrega de un proveedor clave y recomendar alternativas basadas en un análisis en tiempo real de la red logística. Esto transforma la cadena de suministro de una operación reactiva a una inteligente y anticipatoria.
En el ámbito del marketing, Apriel puede funcionar como un agente de marketing impulsado por IA. Podría analizar los datos del cliente para segmentar audiencias con gran precisión, generar campañas publicitarias personalizadas y adaptar dinámicamente el mensaje en función de la interacción del usuario. Su capacidad para generar código también es una ventaja poderosa aquí; podría escribir scripts para automatizar campañas de correo electrónico o crear micrositios de destino personalizados para diferentes segmentos de mercado. La atención positiva que ha recibido de expertos y la comunidad de IA se debe precisamente a este potencial transformador en operaciones empresariales.
La integración de Apriel en los flujos de trabajo de ServiceNow está diseñada para ser fluida y sin fisuras. La compañía proporciona documentación detallada para ayudar a las organizaciones a incorporar el modelo en sus sistemas existentes. Esto significa que las empresas pueden aprovechar las capacidades de razonamiento avanzado de Apriel sin tener que reinventar por completo sus procesos o sistemas. Desde la gestión de incidentes hasta la automatización de tareas administrativas, Apriel tiene el potencial de mejorar la productividad, reducir errores humanos y permitir que los empleados se enfoquen en trabajos de mayor valor estratégico. Sin embargo, es importante señalar que, aunque sea muy potente, el modelo no está diseñado para aplicaciones críticas sin supervisión humana. Su naturaleza de «pensamiento» lo hace ideal para tareas de asistencia y recomendación, pero la toma de decisiones final en situaciones de alto riesgo aún debe residir en manos humanas. El futuro que Apriel anuncia es uno en el que la IA no reemplaza al empleado, sino que lo empodera, actuando como un socio de alto rendimiento que acelera el pensamiento y la acción empresarial.
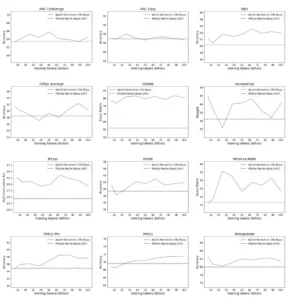
La figura muestra la progresión del rendimiento de Apriel-Nemotron-15B-Base y el rendimiento estático de referencia de Mistral-Nemo-Base-2407 (representado por una línea punteada) en doce pruebas de referencia posteriores. El eje x indica los tokens acumulados de preentrenamiento (en miles de millones, de 10 000 000 a 100 000 000 000), y el eje y muestra la métrica de rendimiento relevante (p. ej., precisión, coincidencia exacta). Las pruebas de referencia incluyen ARC Challenge, ARC Easy, BBH, GPQA Average, GSM8K, HumanEval, IfEval, MUSR, Minerva Math, MMLU Pro, MMLU y WinoGrande, lo que proporciona una visión completa de las capacidades del modelo en razonamiento, generación de código, resolución de problemas matemáticos y comprensión general del lenguaje.
Limitaciones, implicaciones éticas y consideraciones futuras
A pesar de sus logros notables, el Apriel-1.5-15B-Thinker, como cualquier sistema de inteligencia artificial avanzado, no está exento de limitaciones y desafíos éticos. Es fundamental entender estos aspectos para una implementación responsable y realista. Entre las limitaciones técnicas, se encuentra la posibilidad de inexactitud factual. Aunque el modelo es formidable en el razonamiento estructurado, puede generar afirmaciones que parecen plausibles pero que no se corresponden con la realidad. Esto es inherente a la manera en que los modelos de lenguaje generan texto, basándose en patrones estadísticos en lugar de una comprensión semántica genuina. Otra limitación significativa es la presencia de sesgos sociales. Dado que el modelo fue entrenado con un vasto corpus de internet, heredó los prejuicios y desigualdades presentes en esos datos, lo que podría llevar a respuestas que reflejen o incluso perpetúen estereotipos insensibles. Además, su rendimiento tiende a disminuir en idiomas que no están bien representados en el corpus de entrenamiento, lo que plantea cuestiones de inclusión lingüística y acceso equitativo a la tecnología.
Las implicaciones éticas van más allá de las limitaciones técnicas. La capacidad de Apriel para razonar y generar texto convincente levanta preguntas sobre el uso indebido, como la creación de contenido engañoso o malintencionado a gran escala. Su diseño para tareas agenticas, como la recuperación de información y la llamada a funciones, lo convierte en una herramienta poderosa en las manos de quienes buscan realizar ataques de ingeniería social o manipulación. Por ello, la recomendación de que no se utilice para aplicaciones críticas sin supervisión humana es más que un simple consejo técnico; es una declaración ética fundamental. La responsabilidad recae en los desarrolladores y las organizaciones que lo implementen para establecer marcos de gobernanza claros, mecanismos de auditoría y controles de seguridad para mitigar estos riesgos.
Mirando hacia el futuro, el éxito de Apriel-1.5-15B-Thinker abre nuevas vías de investigación y desarrollo. La demostración de que un modelo más pequeño puede igualar o superar a uno más grande en ciertas tareas sugiere que el futuro de la IA podría no ser una carrera desenfrenada hacia el tamaño, sino una optimización inteligente del diseño y el entrenamiento. La idea de «razonamiento profundo» como principal motor de rendimiento, en lugar de «escala masiva», podría inspirar a otros laboratorios a rediseñar sus propias tuberías de entrenamiento para priorizar la calidad conceptual. Esto podría conducir a una nueva generación de modelos aún más eficientes y especializados para dominios específicos, desde la medicina hasta la ingeniería legal.
Además, el enfoque de ServiceNow en la creación de un modelo empresarialmente útil y eficiente podría inspirar a otras compañías tecnológicas a seguir un camino similar. En lugar de centrarse únicamente en récords mundiales de rendimiento en benchmarks, el foco podría desplazarse hacia la creación de soluciones prácticas que resuelvan problemas reales y sean económicamente viables para una amplia gama de clientes. La disponibilidad del modelo bajo una licencia permissive como la MIT fomentará la colaboración y la innovación abierta, permitiendo a la comunidad global construir sobre esta base y explorar nuevas aplicaciones. En última instancia, el futuro que Apriel anuncia es uno en el que la inteligencia artificial se integra de manera más profunda y eficiente en la vida cotidiana de las empresas y los individuos, pero también uno en el que la responsabilidad, la ética y la comprensión de sus límites serán tan cruciales como su propio poder de cálculo.
La revolución de la eficiencia en IA
En conclusión, el Apriel-1.5-15B-Thinker representa un hito significativo en la trayectoria de la inteligencia artificial, no por su tamaño, sino por su inteligencia y eficiencia. Ha desafiado la creencia arraigada de que la capacidad de razonamiento de alto nivel debe ir acompañada de un coste computacional prohibitivo. A través de una arquitectura meticulosamente diseñada, una tubería de entrenamiento innovadora y un enfoque estratégico en el razonamiento profundo, este modelo ha demostrado que es posible lograr un rendimiento de clase mundial con una fracción de los recursos necesarios para sus predecesores más grandes. Su capacidad para igualar o superar a los modelos de 32 mil millones de parámetros en una amplia gama de benchmarks académicos y empresariales, mientras reduce drásticamente la demanda de memoria y tokens, marca el inicio de una nueva era en el diseño de IA.
La relevancia de este trabajo trasciende el ámbito técnico. Al democratizar el acceso a la IA de alto rendimiento, Apriel tiene el potencial de transformar radicalmente la economía digital. Al eliminar la barrera del coste, abre la puerta para que las pequeñas y medianas empresas participen en la revolución de la automatización y la inteligencia artificial, impulsando la innovación y la competencia en mercados enteros. Sus aplicaciones prácticas, desde la asistencia al cliente hasta el análisis predictivo y el marketing, prometen aumentar drásticamente la productividad y la eficiencia empresarial.
Sin embargo, el camino hacia una futura dominada por la IA no está exento de desafíos. Las limitaciones de exactitud factual, los sesgos inherentes y los riesgos éticos asociados a su poder de razonamiento y generación de texto deben ser gestionados con la máxima diligencia. La implementación de tales sistemas debe ir siempre acompañada de marcos de gobernanza robustos y una supervisión humana continua, especialmente en aplicaciones de alto impacto. El Apriel-1.5-15B-Thinker, por lo tanto, no es solo una herramienta tecnológica; es un catalizador que nos obliga a reflexionar sobre cómo queremos que la sociedad se relacione con la inteligencia artificial. Nos presenta un futuro brillante y eficiente, pero también nos recuerda que con un poder tan grande viene una responsabilidad aún mayor.
Referencias
- Roziere, B., et al. (2023). Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Li, R., et al. (2023). StarCoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Wei, J., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824–24837.
- OpenAI. (2025). Our experimental reasoning model scored a perfect 42/42 on the 2025 International Mathematical Olympiad. X (formerly Twitter) post. https://x.com/OpenAI/status/1946594928945148246
- DeepMind Research Team. (2025). Gemini Deep Think achieves gold-medal score at the International Mathematical Olympiad. DeepMind blog. https://deepmind.google/discover/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad
- Abdin, M., et al. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219 [cs.CL].
- Chowdhery, A., et al. (2023). PaLM: scaling language modeling with pathways. Journal of Machine Learning Research, 24(1).
- Dumitru, R.-G., et al. (2024). Layer-wise quantization: A pragmatic and effective method for quantizing llms beyond integer bit-levels. arXiv preprint arXiv:2406.17415.
- OpenAI. (2024). OpenAI o1 System Card. https://cdn.openai.com/o1-system-card.pdf
- Qwen Team. (2025). QwQ-32B: Embracing the Power of Reinforcement Learning. https://qwenlm.github.io/blog/qwq-32b/
- LGAI Research. (2025). EXAONE Deep: Reasoning Enhanced Language Models. arXiv preprint arXiv:2503.12524.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361 [cs.LG].
- Berti, L., Giorgi, F., & Kasneci, G. (2025). Emergent Abilities in Large Language Models: A Survey. arXiv:2503.05788 [cs.LG].
- Kim, D., et al. (2024). SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling. arXiv:2312.15166 [cs.CL].
- Falcon-LLM Team. (2024). The Falcon 3 Family of Open Models. https://huggingface.co/blog/falcon3
- Toshniwal, S., et al. (2024). OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data. arXiv:2410.01560 [cs.CL].
- Gao, L., et al. (2024). The Language Model Evaluation Harness (v0.4.3). Zenodo. https://doi.org/10.5281/zenodo.12608602
- Nvidia, et al. (2024). Nemotron-4 340B Technical Report. arXiv:2406.11704 [cs.CL].
- Maheshwary, R., et al. (2025). M2Lingual: Enhancing Multilingual, Multi-Turn Instruction Alignment in Large Language Models. Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 9676–9713.
- Moshkov, I., et al. (2025). AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset. arXiv:2504.16891 [cs.AI].
- Shao, Z., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL].
- Goddard, C., et al. (2024). Arcee’s MergeKit: A Toolkit for Merging Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 477–485.
- Austin, J., et al. (2021). Program Synthesis with Large Language Models. arXiv preprint arXiv:2108.07732.
- Machine Learning Foundations. (2023). Evalchemy: A General Evaluation Framework for AI Models. https://github.com/mlfoundations/evalchemy
- Ni, J., et al. (2024). MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures. arXiv:2406.06565 [cs.CL].
- Zhou, J., et al. (2023). Instruction-Following Evaluation for Large Language Models. arXiv:2311.07911 [cs.CL].
- Sirdeshmukh, V., et al. (2025). MultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs. arXiv:2501.17399 [cs.CL].
- Wang, Y., et al. (2024). MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv:2406.01574 [cs.CL].
«`

