
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
El espejismo de la detección: por qué ROUGE engaña en las alucinaciones de los LLMs
La publicación de un estudio en arXiv cuestiona la métrica más usada para evaluar la detección de alucinaciones en grandes modelos de lenguaje. Lo que parecía progreso resulta en parte una ilusión: bajo evaluación humana, los métodos punteros pierden hasta un 45% de rendimiento. El hallazgo obliga a replantear cómo medimos la fiabilidad de sistemas de IA desplegados en ámbitos donde la precisión no es negociable.
Un estándar bajo sospecha
El 13 de agosto de 2025 se difundió en arXiv el paper The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs, firmado por investigadores de la Universidad de Ciencia y Tecnología de Wroclaw, la Universidad de Tecnología de Sídney y la Universidad de Nueva York. La tesis es sencilla y demoledora: la comunidad de IA ha confiado en un criterio de evaluación —ROUGE— que no mide lo que realmente importa.
Los modelos de lenguaje actuales son capaces de responder con una seguridad que en muchos casos es infundada. Llamamos a eso alucinaciones: información incorrecta expresada con fluidez. El problema no es anecdótico. Si un sistema se usa para sugerir diagnósticos médicos, asesorar sobre una política pública o recomendar un tratamiento financiero, una alucinación no es un fallo menor sino un riesgo sistémico.
Por eso, detectar cuándo un modelo inventa datos se ha convertido en una línea de investigación clave. El nuevo estudio demuestra que el campo puede haber sobrestimado sus logros: los detectores parecen mejores de lo que son porque se evalúan con una métrica inadecuada.
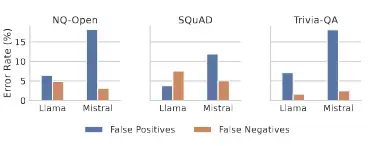
ROUGE produce errores sistemáticos en todos los entornos de evaluación. La distribución de falsos negativos y falsos positivos en diferentes conjuntos de datos y modelos pone de relieve la inconsistencia de la evaluación de ROUGE.
Antecedentes y marco
La historia empieza en 2004, cuando se propuso ROUGE para evaluar resúmenes automáticos. La lógica era pragmática: medir cuánto se parece el texto generado a un conjunto de referencias humanas a través de solapamiento de palabras o frases. Durante años, ROUGE funcionó como un proxy barato para calidad de resúmenes.
Con la irrupción de los LLMs, la métrica se extendió al terreno del question answering. La idea era simple: si la respuesta del modelo comparte pocas palabras con la respuesta correcta, probablemente sea una alucinación. El problema es que la verdad factual no siempre se correlaciona con el parecido léxico. Dos frases pueden compartir muchas palabras y decir cosas distintas, o pueden coincidir en significado usando vocabulario completamente diferente.
Aun así, la práctica se consolidó. Gran parte de la literatura reciente en detección de alucinaciones reporta mejoras en benchmarks sobre la base de ROUGE, sin validar cuánto coinciden esos resultados con juicios humanos.
Cómo funciona la nueva evaluación
El estudio de Janiak y colaboradores tomó tres datasets clásicos de QA: NQ-Open, TriviaQA y SQuAD. Generaron respuestas con dos modelos abiertos —LLaMA-3.1-8B-Instruct y Mistral-7B-Instruct— y aplicaron varios detectores: Perplexity, Length-Normalized Entropy, Semantic Entropy, EigenScore, LogDet y eRank, entre otros.
Después evaluaron su eficacia con dos criterios: ROUGE-L (con el umbral estándar de 0.3) y un enfoque de LLM-as-Judge basado en GPT-4o-mini, validado previamente como más cercano a juicios humanos. Además, realizaron un estudio con anotadores humanos independientes, logrando un acuerdo inter-anotador alto (Cohen’s Kappa = 0.799).
El contraste fue revelador. Mientras que bajo ROUGE varios detectores parecían robustos, al usar evaluaciones humanas sus resultados se desplomaban. Perplexity, por ejemplo, perdió un 45,9% de AUROC en Mistral sobre NQ-Open. EigenScore cayó un 30,4% en el mismo modelo y dataset. Incluso métodos avanzados como eRank se desplomaron más de un 36%.
La conclusión es incómoda: gran parte de los métodos reportados como eficaces lo son solo en apariencia, porque ROUGE está sesgado.
Comparaciones y benchmarks
El análisis no se limitó a ROUGE. Se compararon métricas alternativas como BLEU, BERTScore, UniEval y SummaC. Todas mostraron problemas de alineación con juicios humanos. Ni siquiera BERTScore, que usa embeddings semánticos, logró superar de forma consistente a los enfoques más simples.
Lo más llamativo es que heurísticas triviales, como medir la longitud de la respuesta, rivalizan o incluso superan a detectores complejos. En varios experimentos, respuestas más largas correlacionaban con mayor probabilidad de ser alucinaciones. La simple estadística de longitud se volvió un detector sorprendentemente competitivo.
Esto revela una fragilidad metodológica: muchos sistemas que parecen sofisticados funcionan porque, en la práctica, replican la correlación entre longitud y veracidad. Un recordatorio de que en ciencia de datos, a veces las mejoras se deben a artefactos y no a avances reales.
Voces y fuentes
Los autores del estudio académico son claros en sus conclusiones: el campo necesita un cambio de paradigma en evaluación. “Adoptar marcos de evaluación semánticamente conscientes y robustos es esencial para medir con precisión el rendimiento real de los detectores de alucinaciones”, sostienen.
Otros investigadores ya venían advirtiendo sobre las limitaciones de ROUGE. Honovich et al. (2022), Dziri et al. (2022) y Zhong et al. (2022) habían señalado su incapacidad para capturar consistencia factual en diálogos o resúmenes largos. El nuevo estudio lleva esa crítica al terreno de la detección de alucinaciones y la convierte en evidencia cuantitativa sistemática.
En paralelo, trabajos recientes como los de Thakur et al. (2025) muestran que los métodos LLM-as-Judge pueden alinear mejor con juicios humanos, aunque no están exentos de sesgos propios.
Impactos por sector
En educación, la detección automática de errores de un tutor IA depende de métricas confiables. Si se usan métricas engañosas, el riesgo es formar estudiantes con conceptos equivocados validados por un sistema que parece confiable.
En salud, un asistente que no reconoce cuándo inventa información médica puede ser peligroso. Si el detector de alucinaciones se sobreestima por culpa de ROUGE, la validación clínica queda en entredicho.
En economía, la automatización de informes y análisis con LLMs depende de que podamos auditar la veracidad de la información. Un falso sentido de seguridad puede llevar a decisiones de inversión mal fundamentadas.
En política y seguridad, donde los LLMs se proponen para filtrar desinformación, un detector mal evaluado puede fallar en el punto crítico: distinguir entre datos inventados y reales.
Controversias y vacíos
El trabajo expone varios puntos ciegos. Primero, la excesiva dependencia de métricas de referencia. ROUGE y BLEU fueron diseñados para tareas distintas y su adopción acrítica revela más comodidad que solidez científica.
Segundo, la falta de validación sistemática con juicios humanos. Solo cuando se midió directamente con evaluadores se constató la magnitud del problema.
Tercero, el riesgo de optimizar para la métrica en lugar de para la tarea. Si los detectores se calibran para maximizar ROUGE, lo que aprenden en realidad es a cumplir con los sesgos de esa métrica, no a detectar alucinaciones genuinas.
Escenarios futuros
En el corto plazo, veremos una reevaluación de papers previos que reportaron grandes avances en detección de alucinaciones. No es improbable que parte de esos resultados se revisen a la baja.
En el mediano plazo, la adopción de métodos LLM-as-Judge como estándar de evaluación se consolidará. El problema será su costo computacional y el riesgo de circularidad: usar un modelo para evaluar a otro puede introducir dependencias no deseadas.
En el largo plazo, el campo necesitará marcos híbridos: métricas automáticas más económicas entrenadas y calibradas sobre grandes corpus de juicios humanos, complementadas con auditorías periódicas. La meta será construir un ecosistema de métricas tan confiable como los propios sistemas que buscan medir.
Ética y regulación
La dimensión ética es clara: usar métricas engañosas para declarar confiables a sistemas desplegados en entornos sensibles es irresponsable. La regulación debería exigir auditorías basadas en juicios humanos antes de aprobar el uso de LLMs en medicina, justicia o educación.
También se abren preguntas de transparencia. Los usuarios tienen derecho a saber con qué criterios se valida un asistente y qué limitaciones tiene. Si un banco usa un modelo para asesorar clientes, ¿qué métrica garantiza que las respuestas no sean invenciones? Si es ROUGE, la garantía es endeble.
Cierre interpretativo
El nuevo estudio funciona como advertencia: el progreso en detección de alucinaciones puede haber sido, en parte, un espejismo estadístico. Lo que parecía sofisticado se reduce a un sesgo por longitud y una métrica mal alineada con lo humano.
La lección es simple: sin validación con juicios humanos, las métricas automáticas no son fiables. Lo que está en juego no es un debate académico, sino la credibilidad de la inteligencia artificial en sectores donde el margen de error es cero.
Glosario
-
Hallucination: Respuesta generada por un modelo de lenguaje que suena plausible pero es falsa.
-
ROUGE: Métrica basada en solapamiento léxico usada para evaluar resúmenes y respuestas de QA.
-
LLM-as-Judge: Método que usa un modelo de lenguaje avanzado como evaluador semántico de respuestas.
-
AUROC: Área bajo la curva ROC, mide capacidad de un detector para distinguir entre casos positivos y negativos.
-
Few-shot vs Zero-shot: Modos de evaluación con ejemplos (few-shot) o sin ejemplos (zero-shot) como contexto.
-
Semantic Entropy: Método de detección de alucinaciones que mide incertidumbre a nivel de secuencia generada.
Métricas y benchmarks
-
Perplexity en Mistral/NQ-Open: −45,9% de caída al pasar de ROUGE a LLM-as-Judge (2025).
-
EigenScore en Mistral/NQ-Open: −30,4%.
-
eRank en Mistral/NQ-Open: −36,4%.
-
Cohen’s Kappa en validación humana: 0,799.
-
Datasets usados: NQ-Open (3.610 pares QA), TriviaQA (3.842), SQuAD (4.150).
Fuentes
Janiak, D. et al. (2025). The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs. arXiv:2508.08285v2. Disponible en: https://arxiv.org/abs/2508.08285v2
Honovich, O. et al. (2022). Evaluating Factual Consistency in Natural Language Generation with QA-based Metrics. ACL.
Dziri, N. et al. (2022). Faithfulness in Natural Language Generation: A Systematic Survey of Analysis, Evaluation, and Optimization Methods. TACL.
Zhong, M. et al. (2022). Towards Faithful Summarization with Entailment-based Evaluation Metrics. ACL.
Thakur, N. et al. (2025). Aligning LLM-as-Judge with Human Evaluation for QA.

