
En el corazón palpitante de la era digital, residen titanes de una escala sin precedentes. Modelos de inteligencia artificial como GPT-4 son catedrales de silicio, construcciones lógicas tan vastas que desafían la intuición humana. Su poder emana de una arquitectura de miles de millones de «parámetros», un término técnico que podemos visualizar como el número de conexiones en un cerebro sintético o la cantidad de perillas de ajuste en una máquina de complejidad casi infinita. Cada parámetro, un número de alta precisión, contribuye a la asombrosa capacidad de estos sistemas para escribir poesía, generar código o conversar con una fluidez inquietantemente humana. Este gigantismo es el resultado de una filosofía de desarrollo que ha dominado la última década: la creencia de que para alcanzar una inteligencia superior, el tamaño es el único camino. Los grandes laboratorios, verdaderos imperios de la IA, se han lanzado a una carrera armamentista por la escala, creando modelos cada vez más colosales. GPT-4, por ejemplo, es en algunas métricas más de 15,000 veces mayor que su antecesor de primera generación, GPT-1, lanzado apenas cinco años antes. Esta búsqueda de la escala, sin embargo, tiene un precio oculto, una factura que el planeta y la sociedad están empezando a pagar.
El primer coste es financiero, y es astronómico. Entrenar un modelo de vanguardia no es una empresa para los débiles de corazón ni para los de billetera modesta. Se estima que el coste de entrenamiento de GPT-4 superó los 100 millones de dólares, una cifra que palidece frente a las inversiones multimillonarias que gigantes como Google destinan a su infraestructura de IA. Esta barrera económica crea un oligopolio de facto, donde solo un puñado de corporaciones y naciones ricas pueden permitirse el lujo de innovar en la frontera del conocimiento, concentrando un poder tecnológico sin parangón en la historia.
El segundo coste es ambiental, y es insostenible. Estas inteligencias no viven en un éter abstracto; residen en centros de datos físicos, enormes complejos industriales que consumen cantidades ingentes de energía y agua. La Agencia Internacional de la Energía (AIE) estima que la demanda de electricidad de los centros de datos podría duplicarse para 2030, llegando a consumir tanta energía como todo Japón. Y por cada kilovatio-hora de energía, se necesitan litros de agua potable para refrigerar los servidores que arden con el esfuerzo computacional. Se produce así una profunda paradoja: se nos promete que la IA resolverá el cambio climático, mientras que su propio desarrollo acelera la crisis energética y hídrica, alimentando una huella de carbono cada vez mayor.
Finalmente, existe un coste de hardware que define la geopolítica de la era digital. La revolución de la IA se apoya sobre los hombros de procesadores altamente especializados, como las GPU de NVIDIA, cuyo acceso es limitado y costoso. Esta dependencia del hardware crea un cuello de botella que consolida aún más el poder en los centros tecnológicos tradicionales, dejando al resto del mundo en una posición de dependencia, obligados a importar tecnología en lugar de crearla.
En este contexto de crecimiento desmedido y costes prohibitivos, un trabajo de investigación surgido de Brasil propone una solución tan radical como elegante, un verdadero gambito tecnológico. El artículo, titulado «1 BIT IS ALL WE NEED: Binary Normalized Neural Networks» (Un bit es todo lo que necesitamos: redes neuronales binarias normalizadas), desafía el dogma de la escala desde sus cimientos. Sus autores, Eduardo L. L. Cabral del Instituto Mauá de Tecnologia y el Instituto de Pesquisas Energéticas e Nucleares, Paulo Pirozelli, también de Mauá, y Larissa Driemeier de la Universidad de São Paulo, proponen algo que suena a ciencia ficción: una red neuronal que puede alcanzar un rendimiento comparable al de los titanes de 32 bits utilizando parámetros que son, literalmente, un solo bit de información. Cada «perilla» de su máquina solo puede estar en una de dos posiciones: encendida (1) o apagada (0). La implicación es monumental: una reducción de hasta 32 veces en los requisitos de memoria, abriendo la puerta a que modelos de gran potencia puedan ejecutarse en hardware simple y barato, como un teléfono móvil o un ordenador personal sin tarjetas gráficas especializadas. Este no es solo un avance en eficiencia; es una propuesta para romper el ciclo vicioso de la escala, una rebelión silenciosa contra los imperios de la IA, nacida no en los opulentos campus de Silicon Valley, sino en los laboratorios de São Paulo.
La dieta digital: el arte de la cuantización extrema
Para comprender la magnitud de la propuesta brasileña, primero debemos adentrarnos en un concepto fundamental en la optimización de la inteligencia artificial: la cuantización. Imagine una fotografía digital de alta resolución. Para capturar cada matiz sutil de luz, sombra y color, utiliza una paleta de millones de tonalidades distintas. Cada píxel se describe con una precisión exquisita, análoga a los números de «punto flotante de 32 bits» (FP32) que usan los modelos de IA convencionales. Estos números son como las infinitas gradaciones de un pintor, capaces de representar valores con una enorme cantidad de decimales.
La cuantización es el arte de poner a dieta a esta representación. Es como si le dijéramos al fotógrafo que, en lugar de millones de colores, debe recrear la misma imagen con una paleta limitada, digamos, de solo 256 colores. Esta es la esencia de la cuantización a «enteros de 8 bits» (INT8). La imagen resultante será mucho más ligera, ocupará menos espacio y se podrá cargar más rápido. Aunque se pierde algo de la finura original, el sujeto principal de la fotografía sigue siendo perfectamente reconocible. En el mundo de la IA, esta «dieta» reduce el tamaño del modelo hasta cuatro veces y, a menudo, acelera los cálculos, ya que los procesadores son más eficientes manejando números enteros y simples que decimales complejos.
El trabajo de Cabral, Pirozelli y Driemeier lleva esta lógica a su conclusión más radical y absoluta. No proponen una dieta de 256 colores, sino una reducción a la paleta más minimalista posible: blanco y negro. Proponen un universo donde cada parámetro, cada peso que define el comportamiento de la red neuronal, solo puede tener dos valores: 0 o 1. Esto es la binarización, una forma extrema de cuantización que promete una compresión de hasta 32 veces en comparación con los modelos estándar de 32 bits. Es pasar de una sinfonía con infinitos matices dinámicos a una pieza musical donde cada instrumento solo puede estar en silencio o sonar a su máximo volumen.
Esta propuesta nos enfrenta a una aparente paradoja informativa. ¿Cómo es posible que un sistema despojado de casi toda su complejidad numérica pueda seguir funcionando de manera inteligente? Si los modelos convencionales necesitan 32 bits de información para cada uno de sus miles de millones de parámetros para funcionar, ¿cómo puede una versión con un solo bit lograr resultados «casi idénticos»?. Esta pregunta nos obliga a reconsiderar lo que realmente constituye la «información» dentro de una red neuronal. El éxito de las redes binarias sugiere una idea profunda: quizás la precisión decimal de los parámetros no es donde reside la verdadera inteligencia. Tal vez, esos valores exactos son simplemente un subproducto de un proceso de entrenamiento que busca un óptimo en un espacio de posibilidades infinito. Lo que realmente podría importar son las relaciones, la estructura y el signo de esas conexiones, no su valor numérico exacto. La investigación brasileña, por tanto, no es solo un truco de compresión; es una investigación fundamental sobre la naturaleza de la información y el conocimiento en las mentes artificiales, sugiriendo que 31 de cada 32 bits de información en un modelo estándar podrían ser, en esencia, redundantes.
El dilema del entrenamiento: cómo enseñar a pensar a una red binaria
La idea de una red neuronal binaria es seductora por su eficiencia, pero se enfrenta a un obstáculo monumental en su creación: el entrenamiento. El método estándar para entrenar redes neuronales, conocido como retropropagación del error (o backpropagation), es un proceso de ajuste fino y delicado. Imaginemos a un director de orquesta intentando afinar a miles de millones de músicos. El director no grita; susurra correcciones minúsculas a cada uno. «Tú, un 0.001% más fuerte»; «tú, un 0.0005% más lento». Estos susurros son los «gradientes», las señales matemáticas que guían a cada parámetro a ajustarse para mejorar el rendimiento general.
Aquí radica el problema. Si los músicos solo pueden estar en silencio (0) o tocar a todo volumen (1), los susurros del director se pierden en el viento. No hay forma de aplicar una corrección de «0.001%». Como señalan los propios autores, las actualizaciones de los gradientes son tan pequeñas que «se perderían por completo si los parámetros se binarizaran permanentemente durante el entrenamiento». La función de binarización es un acantilado digital, no una suave pendiente que el algoritmo pueda descender.
Para resolver este dilema, la comunidad de IA desarrolló una ingeniosa técnica llamada Entrenamiento Consciente de la Cuantización (Quantization-Aware Training o QAT). El QAT es, en esencia, un sofisticado acto de simulación. Durante el entrenamiento, el modelo lleva una doble vida. Para el mundo exterior, durante la «pasada hacia adelante» (cuando realiza una tarea y se evalúa su rendimiento), finge ser una red cuantizada. Sus parámetros se redondean a los valores de baja precisión que usará en el futuro. Sin embargo, para su aprendizaje interno, durante la «pasada hacia atrás» (cuando calcula los errores y ajusta sus pesos), utiliza una copia «maestra» de sus parámetros en alta precisión de 32 bits. Este truco, a menudo implementado con una técnica llamada Estimador Directo (Straight-Through Estimator o STE), permite que los gradientes (los susurros) fluyan a través de la barrera no diferenciable de la cuantización y actualicen la copia de alta precisión, que a su vez informará la próxima versión cuantizada.
La solución propuesta en el artículo brasileño es una aplicación brillante y extrema de esta misma filosofía. Implementan lo que describen como un sistema de «representación dual». Cada parámetro en la red existe simultáneamente en dos formas durante el entrenamiento: un valor de punto flotante de 32 bits, denominado , que se utiliza para recibir las minúsculas actualizaciones de los gradientes, y su contraparte binarizada, , que solo puede ser 0 o 1 y se utiliza para realizar los cálculos de la red. Es como tener un aprendiz (el parámetro binario) que realiza el trabajo pesado, y un maestro (el parámetro de 32 bits) que observa, aprende de los errores y le da nuevas instrucciones al aprendiz para la siguiente tarea. Una vez que el entrenamiento ha concluido y el maestro ha impartido toda su sabiduría, este es descartado. Solo queda el aprendiz, ahora un experto, ligero, rápido y eficiente, listo para operar en el mundo real con solo su conocimiento de 1 bit.
Sin embargo, había un último obstáculo para garantizar la estabilidad. Una red compuesta únicamente por ceros y unos tiene una capacidad expresiva muy limitada; sus operaciones matemáticas se reducen a simples sumas de las entradas. Esto puede provocar que las señales que viajan a través de la red se desvanezcan hasta desaparecer o exploten hasta volverse inmanejables. La clave del éxito del equipo brasileño fue la introducción de la «Capa Binaria Normalizada» (Binary Normalized Layer). Después de que la capa realiza sus operaciones binarias, una función de normalización recalcula y reescala la salida, devolviéndole un rango dinámico y asegurando que la información fluya de manera estable a través de la red. Esta normalización actúa como un estabilizador crucial, compensando la simplicidad extrema de los parámetros y permitiendo que el entrenamiento converja de manera efectiva. No es una invención de un paradigma de entrenamiento completamente nuevo, sino la adaptación inteligente y audaz de un concepto probado (QAT) a su caso más extremo, demostrando un profundo dominio de los principios que gobiernan el aprendizaje profundo.
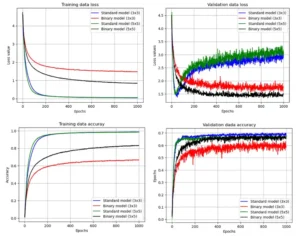
Resultados del entrenamiento del problema de clasificación de imágenes con los modelos convolucionales.
Un bit contra 1.58: la nueva frontera de la eficiencia
En el vertiginoso mundo de la investigación en IA, las ideas rara vez surgen en el vacío. Casi en paralelo al trabajo brasileño, un equipo de Microsoft Research presentó su propia propuesta radical para la eficiencia de los modelos de lenguaje: BitNet b1.58. Este desarrollo establece un fascinante punto de comparación, un duelo tecnológico entre un proyecto liderado por una universidad del Sur Global y una iniciativa impulsada por uno de los gigantes tecnológicos más poderosos del planeta.
A primera vista, las propuestas parecen notablemente similares. Ambas buscan reducir drásticamente la precisión de los parámetros para lograr una eficiencia sin precedentes. Sin embargo, la diferencia clave reside en un detalle aparentemente minúsculo pero conceptualmente profundo: el número de estados que puede adoptar cada parámetro. Mientras que el modelo brasileño es puramente binario, con parámetros que solo pueden ser 0 o 1, BitNet b1.58 es, en esencia, ternario. Sus parámetros pueden adoptar tres valores: -1, 0 o 1.
El curioso número «1.58» en su nombre proviene de la teoría de la información. Para representar tres estados distintos se necesita una cantidad de información equivalente a , que es aproximadamente 1.58 bits. La inclusión del valor «-1» permite a la red modelar directamente relaciones inhibitorias (una neurona que suprime la activación de otra), algo que en el modelo binario debe aprenderse de forma implícita a través de la estructura de la red. Pero la adición más significativa en el modelo de Microsoft es el uso explícito del «0» como un estado intermedio. Esto le confiere a BitNet una capacidad inherente para lo que se conoce como «filtrado de características» (feature filtering). Al asignar un peso de 0 a una conexión, la red puede «apagarla» eficazmente, ignorando las entradas irrelevantes y creando una «escasez» (sparsity) en sus cálculos, lo que se traduce en una mayor eficiencia computacional.
Aquí es donde el análisis se vuelve más sutil. El modelo brasileño, al ser puramente binario {0, 1}, también utiliza el cero. Aunque no se enmarca de la misma manera, su estado «0» cumple una función análoga de filtrado: si un peso es 0, esa conexión no contribuye a la salida, efectivamente podando la red en tiempo de ejecución. La verdadera diferencia filosófica radica en la ausencia del «-1». BitNet opta por sacrificar un mínimo de eficiencia de memoria (1.58 bits frente a 1 bit) para ganar una mayor expresividad en sus parámetros, manteniendo la capacidad de representar conexiones excitatorias (+1), inhibitorias (-1) y nulas (0). El enfoque brasileño, en cambio, realiza una apuesta más audaz por el minimalismo puro. Sugiere que incluso las conexiones inhibitorias explícitas podrían ser redundantes, y que una red puede aprender a modelar estas complejas interacciones únicamente a través de la disposición estructural de sus conexiones activas (1) e inactivas (0).
Esta distinción no es meramente académica; tiene implicaciones directas para el futuro. Aunque ambos enfoques eliminan las costosas operaciones de multiplicación de punto flotante, reemplazándolas por sumas y restas mucho más simples, el sistema puramente binario del modelo brasileño es fundamentalmente más simple de implementar en la lógica de hardware digital. Los circuitos electrónicos operan de forma nativa con lógica binaria (encendido/apagado, alto/bajo, 1/0). Un sistema ternario, aunque eficiente, requiere una lógica ligeramente más compleja para representar sus tres estados. Esto sugiere que, a largo plazo, el enfoque brasileño podría tener una ventaja natural para el co-diseño de hardware especializado, abriendo la puerta a la creación de chips de IA aún más simples, baratos y energéticamente eficientes. Es una visión de futuro en la que la inteligencia artificial no solo se ejecuta en hardware simple, sino que el propio hardware se simplifica gracias a ella.
Desde São Paulo para el mundo: el ingenio que desafía a los imperios
Detrás de cada avance científico hay rostros humanos, y en el caso de esta silenciosa revolución, los protagonistas no se encuentran en los habituales centros de poder tecnológico, sino en el vibrante ecosistema académico de Brasil. El equipo está formado por Eduardo L. L. Cabral, un investigador con doble afiliación en el prestigioso Instituto Mauá de Tecnologia y en el Instituto de Pesquisas Energéticas e Nucleares, aportando una perspectiva multidisciplinar; Paulo Pirozelli, también del Instituto Mauá; y Larissa Driemeier, profesora del Departamento de Ingeniería Mecatrónica y de Sistemas Mecánicos de la mundialmente reconocida Universidad de São Paulo. Sus perfiles revelan una profunda experiencia en campos como la robótica, los sistemas de control, la visión computacional y la mecánica de estructuras, áreas donde la eficiencia y la optimización son cruciales.
Su trabajo no surge en un vacío, sino en el contexto específico del panorama de la investigación en América Latina. Aunque la región cuenta con un ecosistema de IA en rápido crecimiento y lleno de talento, los investigadores se enfrentan a desafíos estructurales significativos en comparación con sus colegas de Norteamérica, Europa o Asia Oriental. El acceso a la infraestructura computacional de vanguardia, necesaria para entrenar los modelos a gran escala que dominan la industria, es uno de los mayores obstáculos. La importación de GPUs de alto rendimiento, como las de NVIDIA, implica costes prohibitivos y barreras logísticas complejas, mientras que el alquiler de tiempo de computación en la nube de los «hiperescaladores» como Amazon, Google o Microsoft supone una sangría económica constante que pocas instituciones pueden sostener. Competir en la carrera de la escala es, para la mayoría, una batalla perdida de antemano.
Es precisamente en este crisol de limitaciones donde la necesidad se convierte en la madre de la invención. El desarrollo de una red neuronal binaria normalizada no es solo una curiosidad académica; es una respuesta brillante y pragmática a un entorno de recursos limitados. Cuando no se puede ganar la carrera de la fuerza bruta, se compite con ingenio. Esta investigación ofrece un poderoso contra-relato a la narrativa dominante de Silicon Valley, que postula que el progreso en IA requiere recursos casi ilimitados. Demuestra que las restricciones, lejos de ser un impedimento, pueden actuar como un catalizador para la innovación, forzando a los investigadores a buscar soluciones más creativas, elegantes y, en última instancia, sostenibles. Desafía la idea de que el único camino hacia adelante es arrojar más dinero, más energía y más datos al problema.
Las implicaciones de este cambio de perspectiva son profundamente geopolíticas. Al demostrar que la investigación de vanguardia en IA es posible sin la necesidad de centros de datos de miles de millones de dólares, el trabajo brasileño ofrece una hoja de ruta tecnológica para otras naciones e instituciones del Sur Global. Podría inspirar una nueva ola de desarrollo de IA descentralizada y eficiente en recursos en todo el mundo, desde la India hasta Nigeria, pasando por Malasia y Argentina. Esto podría alterar fundamentalmente el actual panorama de la IA, hoy dominado por un puñado de corporaciones y países. El artículo no es solo una publicación científica; es un manifiesto técnico que demuestra que la democratización de la inteligencia artificial no es una utopía, sino una posibilidad tangible. Representa la posibilidad de un futuro en el que la innovación no dependa del acceso a un capital masivo, sino de la brillantez de las ideas, sin importar de dónde provengan.
En pos de una inteligencia artificial más democrática y sostenible
El verdadero alcance de la investigación llevada a cabo por Cabral, Pirozelli y Driemeier trasciende la elegancia de su solución técnica. El valor del parámetro de 1 bit no reside únicamente en su minimalismo, sino en el cambio de paradigma que representa. Este avance se erige sobre tres pilares que podrían redefinir el futuro de la inteligencia artificial, haciéndola más democrática, accesible y sostenible.
El primer pilar es la democratización. Al reducir drásticamente los requisitos de hardware y, por consiguiente, los costes financieros y energéticos, las redes neuronales binarias tienen el potencial de romper el dominio casi absoluto que ejercen los gigantes tecnológicos. Universidades, startups, laboratorios de investigación en países en desarrollo e incluso investigadores individuales podrían, por primera vez, desarrollar, entrenar y desplegar modelos de IA potentes sin necesidad de una infraestructura multimillonaria. Esto podría desencadenar una explosión de innovación similar a la que el software de código abierto provocó en el desarrollo de software, diversificando el campo y asegurando que el futuro de la IA sea construido por muchos, y no por unos pocos.
El segundo pilar es la accesibilidad. La eficiencia extrema de estos modelos abre la puerta a una nueva era de «IA en el borde» (edge AI). Aplicaciones sofisticadas que hoy requieren una conexión constante a la nube para procesar datos en potentes servidores remotos podrían ejecutarse directamente en dispositivos de bajo coste y bajo consumo. Pensemos en diagnósticos médicos asistidos por IA en un teléfono móvil en una zona rural sin conexión a internet, en sistemas de visión por ordenador para la agricultura de precisión integrados en sensores baratos alimentados por energía solar, o en asistentes de lenguaje avanzados que funcionen en un simple microcontrolador. La inteligencia artificial dejaría de ser un servicio centralizado para convertirse en una capacidad distribuida, presente y útil en los rincones más remotos del planeta.
El tercer y último pilar es la sostenibilidad. Como se detalló al principio, el paradigma actual de la IA es ecológicamente insostenible. El enfoque binario ofrece una ruta de escape, un camino hacia una IA «verde» que consume una fracción de la energía y los recursos. Aborda directamente la contradicción de una tecnología que promete resolver los grandes problemas de la humanidad mientras agrava uno de los más urgentes: la crisis climática. Es una visión de progreso tecnológico que no exige un peaje insostenible a nuestro planeta.
Mientras los titanes de la industria continúan su frenética carrera por construir catedrales digitales cada vez más grandes, complejas y costosas, este trabajo surgido de Brasil nos recuerda que otro camino es posible. Es una senda más silenciosa, más eficiente y, fundamentalmente, más inclusiva. Nos sugiere que el futuro de la inteligencia artificial podría no depender de la fuerza bruta y la escala desmedida, sino de la elegancia, el ingenio y la optimización. Quizás, la revolución más profunda y transformadora no vendrá del estruendo de los superordenadores, sino del susurro de la unidad de información más pequeña y fundamental que existe: un solo bit.
Referencias
Cabral, E. L. L., Pirozelli, P., & Driemeier, L. (2025). 1 bit is all we need: binary normalized neural networks. arXiv preprint arXiv:2509.07025.
Hao, K. (2025). Empire of AI: Dreams and Nightmares in Sam Altman’s OpenAI. Penguin Press.
International Energy Agency. (2025). Energy and AI. IEA.
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., & Kalenichenko, D. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Krishnamoorthi, R. (2018). Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342.
Hubara, I., Courbariaux, M., Soudry, D., El-Yaniv, R., & Bengio, Y. (2017). Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. Journal of Machine Learning Research, 18, 1-30.
Wang, S., Li, H., Song, Y., Wang, Z., Zhao, R., Zhang, Z., & Ma, S. (2024). The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits. arXiv preprint arXiv:2402.17764.

