
En la acelerada carrera por construir inteligencias artificiales cada vez más capaces, nos hemos topado con un problema fundamental, uno que no reside en la capacidad de las máquinas para crear, sino en nuestra habilidad para juzgarlas. A medida que los modelos de lenguaje a gran escala (LLM) se han vuelto asombrosamente diestros en generar texto, código y conversaciones, la industria se ha enfrentado a un cuello de botella monumental: ¿quién evalúa a los evaluadores? La solución, aparentemente ingeniosa y pragmática, fue encomendar esta tarea a las propias máquinas. Nació así el paradigma del «LLM como juez», un sistema en el que una inteligencia artificial avanzada asume el rol de árbitro, calificando las respuestas de sus pares con una eficiencia y una escala que ningún equipo humano podría igualar.
Esta estrategia ha sido un catalizador para el progreso, permitiendo a los laboratorios de investigación y a las grandes tecnológicas refinar sus creaciones a una velocidad vertiginosa. Los jueces artificiales trabajan sin descanso, comparando miles de respuestas, asignando puntuaciones y determinando qué versión de un modelo es superior. Sin embargo, bajo esta fachada de automatización impecable, ha comenzado a emerger una verdad incómoda y profundamente perturbadora: estos jueces no son imparciales. Peor aún, ni siquiera son consistentes consigo mismos. Sus veredictos, que guían el desarrollo de la próxima generación de IA, están plagados de contradicciones lógicas y fallos irracionales que ponen en tela de juicio la fiabilidad de todo el ecosistema.
Un estudio reciente y revelador, titulado «TrustJudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them», ha arrojado una luz penetrante sobre estas grietas en los cimientos de la evaluación de la IA. La investigación identifica dos tipos de fallos fundamentales que socavan la confianza en estos sistemas. El primero es la inconsistencia entre la puntuación y la comparación. Imagínese a un profesor que califica dos exámenes, otorgando un 8 sobre 10 al primero y un 6 sobre 10 al segundo. Sin embargo, al preguntarle cuál de los dos es mejor, responde sin dudar que el segundo es superior. Esta contradicción flagrante es precisamente lo que ocurre con frecuencia en los jueces de IA. Un modelo puede asignar una puntuación numérica alta a una respuesta, pero al enfrentarla directamente con otra de menor puntuación, declara ganadora a la segunda. Es un fallo que desafía la lógica más básica y revela una profunda inestabilidad en su criterio.
El segundo fallo, aún más sutil pero igualmente dañino, es la inconsistencia en la transitividad de las comparaciones. La transitividad es un pilar del razonamiento lógico que dicta que si A es mejor que B, y B es mejor que C, entonces A debe ser necesariamente mejor que C. Nuestros jueces artificiales, sin embargo, a menudo violan esta regla fundamental. Pueden caer en ciclos de preferencia ilógicos, similares al juego de piedra, papel o tijera, donde afirman que A vence a B, B vence a C, pero C vence a A. También manifiestan contradicciones de equivalencia: pueden juzgar que A es igual a B y que B es igual a C, para luego concluir, de manera inexplicable, que A no es igual a C. Estas cadenas de juicios irracionales no son meras anécdotas; son síntomas de un sistema de evaluación que carece de la coherencia interna necesaria para ser fiable.
El equipo detrás de TrustJudge no se limita a señalar el problema; profundiza en sus causas. Argumentan que estas inconsistencias surgen de dos fuentes principales. Por un lado, la pérdida de información inherente a los sistemas de calificación discretos. Cuando obligamos a un LLM a resumir su compleja evaluación en un simple número del 1 al 5, estamos desechando una enorme cantidad de matices. La verdadera «opinión» del modelo no es un número entero, sino una distribución de probabilidades sobre todas las puntuaciones posibles. Al quedarnos solo con el número más probable, perdemos la noción de su incertidumbre y de la sutileza de su juicio. Por otro lado, los empates ambiguos en las comparaciones directas introducen ruido en el sistema, facilitando la aparición de cadenas de preferencias ilógicas.
Para subsanar estas deficiencias críticas, el estudio propone un nuevo marco de evaluación llamado TrustJudge. Este sistema no es un nuevo modelo, sino una metodología probabilística diseñada para restaurar la lógica y la consistencia en el proceso de juicio. Introduce dos innovaciones clave. La primera es una puntuación sensible a la distribución, que en lugar de tomar un número discreto, calcula un valor esperado continuo a partir de las probabilidades de calificación del juez. Esto preserva la riqueza de la evaluación original y genera puntuaciones mucho más precisas y matizadas. La segunda es una agregación consciente de la verosimilitud, un método para resolver las violaciones de transitividad y los empates ambiguos utilizando la confianza inherente del modelo en cada posible veredicto. En esencia, TrustJudge obliga al juez a ser más transparente sobre su nivel de certeza y utiliza esa información para construir un juicio final más robusto y lógicamente coherente. Este artículo explorará en profundidad la naturaleza de estas inconsistencias, desentrañará el ingenioso mecanismo de TrustJudge y reflexionará sobre las profundas implicaciones que tiene para el futuro de una inteligencia artificial en la que podamos, verdaderamente, confiar.
El ascenso del árbitro artificial
Para comprender la magnitud del problema que TrustJudge busca resolver, primero debemos entender por qué la figura del «LLM como juez» se ha vuelto tan indispensable. El desarrollo de la inteligencia artificial moderna es un proceso de refinamiento constante. Los ingenieros crean un modelo base y luego lo entrenan repetidamente con vastos conjuntos de datos para mejorar su rendimiento. Cada nueva versión, cada ajuste en sus parámetros, debe ser evaluado para determinar si representa un paso adelante o un paso atrás. En las primeras etapas de la IA, esta evaluación era una tarea relativamente manejable para los humanos. Un equipo de expertos podía revisar un conjunto de respuestas y emitir un juicio de calidad.
Sin embargo, la escala y la velocidad del desarrollo actual han hecho que la evaluación humana sea un lujo insostenible. Un solo modelo puede generar miles de respuestas a miles de preguntas en cuestión de horas. Evaluar todo este volumen de producción de forma manual no solo sería astronómicamente caro, sino también desesperadamente lento, creando un cuello de botella que ahogaría la innovación. La industria necesitaba una alternativa escalable, y la encontró en sus propias creaciones. La idea era simple: si un modelo como GPT-4 es lo suficientemente avanzado como para generar respuestas de alta calidad, también debería ser capaz de reconocerla en las respuestas de otros.
Así se consolidaron dos protocolos de evaluación principales. El primero es la evaluación de puntuación única. En este método, el LLM juez recibe una pregunta y una única respuesta generada por el modelo a prueba. Su tarea es asignar una calificación numérica, generalmente en una escala discreta como del 1 al 10, basándose en criterios como la utilidad, la coherencia, la veracidad y la creatividad. Es el equivalente a un examen tradicional, donde cada respuesta recibe una nota final que supuestamente refleja su mérito absoluto.
El segundo protocolo es la comparación por pares. Aquí, al juez se le presentan dos respuestas diferentes (A y B) a la misma pregunta. En lugar de asignar una puntuación absoluta a cada una, debe decidir cuál es mejor, o si son de una calidad equivalente. Para mitigar sesgos, como la tendencia de algunos modelos a preferir la primera respuesta que leen, el proceso se repite intercambiando el orden de las respuestas. Este método se considera a menudo más fiable que la puntuación única porque a los humanos, y presumiblemente a las IA, les resulta más fácil hacer juicios relativos que absolutos. Es más sencillo decir que una manzana es más sabrosa que una naranja que asignar a la manzana una puntuación de «sabor» de 8.7 sobre 10.
Estos dos sistemas se convirtieron en el andamiaje sobre el que se construye gran parte de la evaluación moderna de la IA. Plataformas como MT-Bench y Chatbot Arena popularizaron su uso, demostrando que los juicios de los mejores LLM tenían una alta correlación con las preferencias humanas. No solo servían para evaluar, sino también para entrenar. Mediante técnicas como el aprendizaje por refuerzo con retroalimentación humana (RLHF), las preferencias de estos jueces artificiales se utilizan para recompensar o penalizar al modelo en entrenamiento, guiándolo gradualmente hacia la generación de respuestas de mayor calidad. El juez no es solo un árbitro; es un maestro. Y es precisamente por este doble rol crucial que su fiabilidad no es negociable. Si el maestro es inconsistente, el alumno aprenderá lecciones confusas y erróneas.

Grietas en la fundación: la anatomía de la inconsistencia
A pesar de su adopción generalizada, una observación más atenta de los veredictos emitidos por estos jueces artificiales revela un patrón de comportamiento errático que desafía los principios fundamentales de la lógica y la racionalidad. El estudio TrustJudge sistematiza estos fallos en dos categorías principales que, juntas, pintan un cuadro preocupante sobre la fiabilidad de nuestros métodos de evaluación.
La primera y más evidente es la paradoja de la puntuación. Este fenómeno describe la contradicción directa entre los dos protocolos de evaluación. En un mundo lógicamente coherente, si un sistema de puntuación única determina que la respuesta A (calificada con un 4/5) es superior a la respuesta B (calificada con un 3/5), entonces una comparación directa por pares debería confirmar esta preferencia. Sin embargo, los LLM jueces fallan en esta prueba de consistencia con una frecuencia alarmante. Es común que, tras haber calificado A por encima de B, el mismo juez, al ser presentado con ambas respuestas simultáneamente, declare que B es la mejor opción o que ambas son equivalentes.
Esta discrepancia no es un error trivial. Socava la validez de ambos métodos de evaluación. Si las puntuaciones absolutas no se corresponden con las preferencias relativas, ¿qué miden realmente esas puntuaciones? ¿Y si las comparaciones directas contradicen las calificaciones numéricas, podemos confiar en que el modelo está aplicando un criterio estable? La causa raíz de esta paradoja, según el análisis de TrustJudge, es la pérdida de información. Una escala de 1 a 5 es un instrumento de medición extraordinariamente tosco. La evaluación interna de un LLM es un proceso complejo que resulta en una delicada distribución de probabilidades. El modelo puede estar, por ejemplo, un 55% seguro de que una respuesta merece un 4, un 40% seguro de que merece un 3, y un 5% seguro de que merece un 5. El sistema tradicional simplemente toma la opción más probable (el 4) y descarta el resto de la información. Al hacerlo, se pierde toda la riqueza del juicio del modelo, incluida su incertidumbre. Dos respuestas muy diferentes, una que es un «4» sólido y otra que es un «4» dudoso, terminan con la misma etiqueta, ocultando las sutilezas que luego afloran en una comparación directa.
La segunda inconsistencia, más profunda y matemática, es el círculo de la irracionalidad en las comparaciones por pares. Este problema se manifiesta de dos maneras:
- Violación de la transitividad circular: Como se mencionó, esto ocurre cuando el juez entra en un bucle de preferencias ilógico: prefiere A sobre B, B sobre C, pero luego C sobre A. Esto convierte cualquier intento de crear un ranking o una clasificación ordenada a partir de sus juicios en una tarea imposible. No hay un «mejor» absoluto, solo una cadena de preferencias que se muerde la cola.
- Violación de la transitividad de equivalencia: Esta es una forma más sutil de irracionalidad. El juez podría determinar que la respuesta A y la B son de igual calidad (un empate), y que la B y la C también son equivalentes. La lógica transitiva dictaría que A y C también deben serlo. Sin embargo, el juez artificial a menudo rompe esta cadena, declarando que A es, de hecho, superior o inferior a C.
Estos fallos de transitividad son particularmente problemáticos porque la comparación por pares se considera el «estándar de oro» para la evaluación, precisamente por su supuesta robustez. Descubrir que este estándar está construido sobre una lógica inestable es alarmante. El análisis de TrustJudge sugiere que una de las principales culpables de estas violaciones es la gestión de los empates ambiguos. Cuando dos respuestas son de una calidad muy similar, el modelo puede tener dificultades para decidirse. En lugar de forzar una elección, a menudo opta por un empate. Sin embargo, esta declaración de «empate» puede no ser estable. Pequeños cambios en el contexto o en el orden de presentación pueden hacer que el modelo se incline ligeramente hacia un lado u otro en una comparación posterior, rompiendo así la cadena de equivalencias y dando lugar a contradicciones. El sistema es frágil precisamente donde el juicio es más difícil.
Un nuevo veredicto: la solución TrustJudge
Ante este panorama de inconsistencia, el marco TrustJudge no propone reemplazar al juez artificial, sino equiparlo con mejores herramientas para que su juicio sea más coherente y transparente. La solución no es un nuevo modelo, sino un cambio metodológico que se apoya en los principios de la probabilidad para extraer una señal más fiable de los LLM existentes. Se articula en torno a dos componentes principales, cada uno diseñado para atajar una de las inconsistencias fundamentales.
El primer componente es la puntuación sensible a la distribución, concebida para resolver la paradoja entre puntuaciones y comparaciones. En lugar de pedir al juez una única calificación en una escala de 1 a 5, TrustJudge le pide que evalúe la respuesta en una escala mucho más granular, como de 1 a 100. Más importante aún, no se queda con un único número. Aprovecha el hecho de que, para cada posible token que un LLM puede generar, este calcula una probabilidad. TrustJudge extrae las probabilidades que el modelo asigna a cada uno de los 100 posibles números de la escala. Esto revela la «opinión» completa del juez: una distribución de probabilidad que muestra no solo la puntuación más probable, sino también las alternativas que consideró y con qué grado de confianza.
Con esta distribución en mano, TrustJudge calcula la puntuación esperada. Este es un concepto estadístico que pondera cada posible puntuación por su probabilidad y luego suma los resultados. Por ejemplo, si el modelo cree que hay un 70% de probabilidad de que una respuesta merezca un 85 y un 30% de que merezca un 86, la puntuación esperada no sería 85, sino (0.70 * 85) + (0.30 * 86) = 85.3. El resultado es una puntuación continua y de alta precisión que captura los matices del juicio del modelo. Esta puntuación preserva la información que antes se perdía y reduce drásticamente las contradicciones, ya que dos respuestas con una calidad ligeramente diferente recibirán puntuaciones finales también ligeramente diferentes, en lugar de ser agrupadas bajo el mismo número entero.
El segundo componente es la agregación consciente de la verosimilitud, un conjunto de técnicas para resolver las inconsistencias de transitividad en las comparaciones por pares. El objetivo es proporcionar al juez una forma más robusta de resolver los casos difíciles, especialmente los empates. TrustJudge propone dos enfoques:
- Método basado en la perplejidad (PPL): La perplejidad es una medida de cuán «sorprendente» es una secuencia de texto para un modelo de lenguaje. Una perplejidad baja significa que el texto es coherente y predecible según el conocimiento del modelo. TrustJudge aprovecha esto. Cuando se comparan las respuestas A y B, el juez no solo emite un veredicto, sino que también genera una justificación. Este método calcula la perplejidad de esa justificación. Si el modelo está indeciso entre A y B, TrustJudge puede desempatar a favor de la opción cuya justificación generó con mayor «fluidez» y confianza (menor perplejidad). Es una forma de preguntarle al juez: «Más allá de tu veredicto, ¿qué decisión te resultó más fácil y natural de argumentar?».
- Método de probabilidad bidireccional: Esta técnica ataca directamente el sesgo de posición y la inestabilidad. Realiza la comparación en ambos sentidos (A vs. B y B vs. A). Luego, en lugar de simplemente registrar los veredictos, agrega las probabilidades que el modelo asignó a cada posible resultado («A gana», «B gana», «Empate») en ambas rondas. El resultado final se basa en la suma de estas confianzas. Este proceso de promediado cancela el ruido y los sesgos, produciendo una decisión final mucho más estable y menos propensa a formar parte de una cadena de juicios irracional.
En conjunto, estos dos componentes transforman al LLM juez de un árbitro que emite veredictos frágiles y opacos a uno que proporciona un juicio probabilístico, matizado y, lo que es más importante, lógicamente consistente.
La evidencia: TrustJudge a prueba
Una propuesta metodológica, por elegante que sea, debe demostrar su valía en el campo de batalla de los datos. El equipo de investigación detrás de TrustJudge sometió su marco a una serie de experimentos rigurosos para cuantificar su eficacia en la reducción de inconsistencias y su impacto en la precisión de la evaluación. Utilizaron un conjunto de datos diverso, que combinaba preguntas de benchmarks establecidos como MT-Bench y ArenaHard, y recopilaron respuestas de una amplia gama de modelos de lenguaje, desde arquitecturas de código abierto como Llama-3 hasta sistemas propietarios como GPT-4.
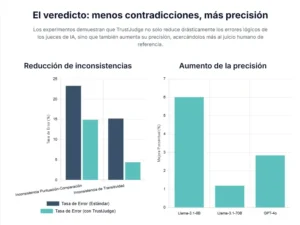
Los resultados fueron inequívocos y contundentes. Al aplicar la puntuación sensible a la distribución, TrustJudge logró reducir la inconsistencia entre puntuación y comparación hasta en un 8.43% en términos absolutos. Esto significa que un número significativo de los casos en los que los jueces estándar se contradecían a sí mismos fueron resueltos, alineando las calificaciones numéricas con las preferencias directas. El sistema demostró ser consistentemente superior tanto al método de puntuación directa como a otras técnicas probabilísticas que no normalizan adecuadamente las distribuciones de probabilidad.
Los logros en la corrección de la inconsistencia de transitividad fueron aún más espectaculares. Usando la agregación consciente de la verosimilitud, TrustJudge redujo la tasa de violaciones de transitividad en un asombroso 10.82% absoluto en las pruebas más complejas. Los ciclos ilógicos y las contradicciones de equivalencia, que plagaban a los sistemas de evaluación estándar, se vieron drásticamente disminuidos. Los estudios de ablación, en los que los componentes de TrustJudge se activaban y desactivaban selectivamente, confirmaron que tanto la mejora de la granularidad de la escala (usar 100 puntos en lugar de 5) como las estrategias de agregación probabilística contribuían de manera significativa a esta mejora.
Un aspecto crucial de estos resultados es que la reducción de la inconsistencia no se produjo a expensas de la precisión. De hecho, TrustJudge no solo mantuvo, sino que a menudo mejoró la exactitud de las evaluaciones en comparación con las anotaciones humanas de referencia. Las tasas de coincidencia exacta en las comparaciones por pares aumentaron entre un 1.19% y un 6.85%, dependiendo del modelo. Esto demuestra que un juicio más consistente es también un juicio más preciso. Al obligar al modelo a ser más riguroso lógicamente, TrustJudge también lo empuja a ser un mejor evaluador en general.
Además, los experimentos demostraron la generalización del marco. TrustJudge funcionó eficazmente en una amplia variedad de arquitecturas de modelos (Llama, GPT, Qwen, Gemma) y tamaños (desde 3 mil millones hasta 70 mil millones de parámetros). Esto confirma que los beneficios de TrustJudge no dependen de las peculiaridades de un modelo específico, sino que abordan un problema fundamental en la metodología de evaluación misma. Curiosamente, los resultados también revelaron que los modelos entrenados intensivamente en tareas de razonamiento, como las matemáticas, a veces mostraban mayores tasas de inconsistencia en tareas de juicio, lo que sugiere un posible «olvido catastrófico» de habilidades más generales. Incluso en estos casos difíciles, TrustJudge logró mejorar significativamente su rendimiento como jueces.
Más allá del veredicto: el futuro de la IA confiable
La investigación sobre TrustJudge trasciende el ámbito técnico de los benchmarks para tocar el núcleo de una de las preguntas más importantes de nuestro tiempo: ¿cómo podemos construir una inteligencia artificial en la que podamos confiar? Los hallazgos de este estudio tienen profundas implicaciones a nivel científico, tecnológico y social.
Desde una perspectiva científica, TrustJudge ofrece una lupa más precisa para medir el progreso real en el campo de la IA. Si nuestras herramientas de medición son defectuosas e inconsistentes, corremos el riesgo de engañarnos a nosotros mismos, declarando avances donde no los hay y optimizando nuestros modelos para satisfacer los caprichos de un árbitro irracional. Al introducir un marco de evaluación más riguroso y lógicamente coherente, la comunidad de investigación puede tener una mayor confianza en que las mejoras que observa son genuinas y significativas. Permite una comparación más justa y fiable entre diferentes modelos, lo que es esencial para una ciencia sólida.
A nivel tecnológico, el impacto es aún más directo e inmediato. Los jueces de IA no solo evalúan, sino que activamente dan forma a los modelos del mañana. Son la fuente de la señal de recompensa en muchos de los paradigmas de entrenamiento más avanzados. Si esa señal es ruidosa y contradictoria, el modelo que se entrena con ella desarrollará capacidades defectuosas o, en el peor de los casos, aprenderá a «piratear» al juez, encontrando formas de obtener una buena puntuación sin generar realmente una respuesta de alta calidad. TrustJudge, al limpiar y estabilizar esta señal de recompensa, permite un entrenamiento más eficaz y seguro. Abre la puerta a la creación de modelos que no solo son más inteligentes en el papel, sino también más robustos y fiables en la práctica.
Finalmente, la relevancia social de construir jueces de IA confiables es inmensa. A medida que delegamos cada vez más decisiones a los sistemas de inteligencia artificial, desde la moderación de contenido en redes sociales hasta el diagnóstico médico preliminar, la capacidad de estos sistemas para realizar juicios consistentes y racionales se vuelve primordial. El trabajo de TrustJudge es un paso fundamental en esa dirección. Nos recuerda que la confianza no es un subproducto accidental de la capacidad, sino una propiedad que debe ser diseñada, medida y verificada con el máximo rigor. No podemos permitirnos construir una sociedad que dependa de los veredictos de máquinas que operan bajo una lógica defectuosa.
En conclusión, el paradigma del «LLM como juez» es una herramienta demasiado poderosa como para abandonarla, pero demasiado defectuosa como para confiar ciegamente en ella. TrustJudge no nos pide que elijamos entre la escala de la automatización y el rigor de la lógica. En cambio, nos muestra un camino para tener ambas cosas. Al abrazar la naturaleza probabilística de la inteligencia artificial y al insistir en la coherencia como un principio no negociable, este marco nos acerca un paso más a un futuro en el que los veredictos de nuestras máquinas sean no solo rápidos y eficientes, sino también justos, racionales y, en última instancia, dignos de nuestra confianza.
Referencias
Wang, Y. et al. (2025) Trustjudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them. arXiv preprint arXiv:2509.21117
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Li, T., Chiang, W.-L., Frick, E., Dunlap, L., Wu, T., Zhu, B., Gonzalez, J. E., & Stoica, I. (2024). From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939.

