
Vivimos inmersos en un océano de datos que fluye sin cesar, una marea digital que sube con cada segundo que pasa. Cada transacción con tarjeta de crédito, cada actualización del estado del tiempo, cada latido de nuestro corazón registrado por un reloj inteligente, cada fluctuación en el precio de una materia prima en los mercados globales, cada vatio de electricidad consumido en una ciudad durante una sofocante ola de calor, cada partícula de dióxido de carbono medida en la prístina atmósfera de la Antártida.
Todas estas secuencias de información, y un sinfín más que tejen la compleja tela de nuestra realidad, comparten una característica fundamental y definitoria: están intrínsecamente ordenadas en el tiempo. Son el pulso rítmico, a veces predecible, a veces caótico, del mundo. En la jerga de los especialistas, se conocen como series temporales. Desentrañar los secretos que esconden en su interior, comprender sus patrones ocultos y, sobre todo, predecir su próximo movimiento, se ha convertido en uno de los desafíos más cruciales y complejos de nuestra era. De nuestra capacidad para pronosticar con acierto el futuro de estas secuencias dependen decisiones que afectan a la economía global, la salud pública, la estabilidad de nuestras infraestructuras críticas y, en última instancia, el futuro de nuestro planeta.
Durante décadas, la formidable tarea de analizar estas secuencias ha recaído sobre los hombros de una élite de expertos humanos: estadísticos, economistas, actuarios y, más recientemente, científicos de datos. Armados con un profundo conocimiento del dominio específico en el que trabajan y un vasto arsenal de herramientas matemáticas y computacionales, estos especialistas dedican una cantidad ingente de tiempo y esfuerzo a una labor que se asemeja más a la de un artesano que a la de un operario de maquinaria.
Su trabajo no consiste, como podría suponerse ingenuamente, en alimentar con datos un algoritmo y esperar a que este produzca un resultado mágico. La realidad es mucho más laboriosa. La mayor parte de su jornada, a menudo una cifra que supera el ochenta por ciento de su tiempo efectivo, se consume en las etapas preliminares, un meticuloso y a menudo tedioso proceso de preparación. Este incluye una minuciosa inspección de los datos para diagnosticar su calidad, la limpieza de valores anómalos o ausentes que podrían contaminar el análisis, la transformación matemática de las cifras para estabilizar sus propiedades estadísticas y la validación de los supuestos subyacentes a cualquier modelo. Solo después de este laborioso y concienzudo proceso de preparación, el analista puede comenzar a experimentar con distintos modelos predictivos, ajustando sus innumerables parámetros, comparando rigurosamente sus resultados y, finalmente, en un acto de síntesis final, combinando varias predicciones para obtener un pronóstico más robusto, fiable y resistente a los caprichos del azar. Es un proceso iterativo, costoso en tiempo y recursos, y profundamente dependiente de la intuición, el juicio y la experiencia acumulada por el ser humano.
La inteligencia artificial, en sus múltiples encarnaciones, ha intentado durante años automatizar fragmentos de este intrincado flujo de trabajo. Hemos sido testigos del desarrollo de modelos estadísticos cada vez más sofisticados y, más recientemente, del auge espectacular de las redes neuronales profundas, sistemas capaces de aprender patrones de una complejidad asombrosa a partir de enormes volúmenes de datos. Sin embargo, estas herramientas, a pesar de su innegable potencia, a menudo se comportan como especialistas con una visión de túnel. Un modelo que funciona excepcionalmente bien para predecir las ventas en el sector minorista puede fracasar estrepitosamente al intentar prever la demanda de energía de una red eléctrica.
Suelen ser sistemas frágiles, que requieren una configuración experta para rendir al máximo y que generalizan con suma dificultad a nuevos dominios o a series de datos que no se parecen a aquellas con las que fueron entrenados. La necesidad de un enfoque verdaderamente general, una metodología agnóstica al dominio y que minimice la intervención humana, se ha vuelto no solo apremiante, sino existencial para poder gestionar el auténtico diluvio de datos temporales que nuestra civilización genera a cada instante.
En este contexto de necesidad y expectación, un reciente trabajo de investigación procedente de un consorcio de prestigiosas universidades norteamericanas y asiáticas introduce un cambio de paradigma radical, una nueva forma de concebir el problema. El estudio presenta TimeSeriesScientist, o TSci, el primer sistema de inteligencia artificial que aborda el análisis de series temporales no como un problema aislado de modelado, sino como un proceso científico completo, automatizado de principio a fin. TSci no es un simple algoritmo; es un marco de trabajo integral compuesto por agentes de inteligencia artificial, cada uno especializado en una de las fases del trabajo que hasta ahora realizaba un analista humano. Impulsado por los grandes modelos de lenguaje (LLM), la misma tecnología que subyace a herramientas de conversación como ChatGPT, TSci es capaz de razonar sobre los datos, diagnosticar sus problemas, planificar una estrategia de análisis, ejecutarla utilizando las herramientas adecuadas y, finalmente, sintetizar los resultados en una conclusión coherente.
Este innovador sistema se estructura como un equipo de expertos virtuales que colaboran entre sí. Un primer agente, bautizado como el Curador, actúa como un meticuloso archivero y restaurador de datos. Examina la serie temporal, identifica sus peculiaridades estadísticas y, utilizando un conjunto de herramientas externas, decide y aplica los procedimientos de limpieza y preprocesamiento más adecuados para ese caso concreto. Una vez que los datos están impolutos, entra en escena el Planificador.
Este agente es el estratega del equipo. Aprovechando un análisis multifacético de los datos ya limpios, formula una hipótesis sobre qué tipos de modelos predictivos tienen más probabilidades de éxito y diseña un plan de ataque detallado. A continuación, el Pronosticador, que en realidad es un conjunto diverso de modelos estadísticos y de aprendizaje profundo, ejecuta el plan, generando múltiples pronósticos desde diferentes perspectivas algorítmicas. Finalmente, el Integrador, el sabio del grupo, evalúa todos los pronósticos individuales, sopesa sus fortalezas y debilidades, y decide la mejor manera de combinarlos para producir una única predicción final, coherente y de alta confianza. Este enfoque colaborativo y modular es lo que permite a TSci emular el flujo de trabajo completo de un científico de datos humano, pero a una velocidad y escala inalcanzables para cualquier persona o equipo. Es, en esencia, la primera encarnación de un analista de datos autónomo de propósito general.
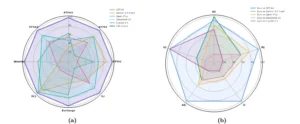
Comparación del rendimiento de TSci con cinco competidores. TSci supera a los otros sistemas de IA en ocho pruebas de predicción de distintos dominios (Figura 1a). Además, el informe completo que genera TSci es de mayor calidad que el de sus competidores en cinco categorías de evaluación (Figura 1b).
La naturaleza omnipresente del tiempo en los datos
Para apreciar la magnitud del logro que representa TimeSeriesScientist, es fundamental comprender primero la naturaleza y los desafíos inherentes a los datos de series temporales. A diferencia de una simple colección de datos, como una lista de clientes con sus respectivas edades y ciudades, una serie temporal posee una dimensión adicional que lo cambia todo: el orden secuencial. El valor de una medición en un punto determinado del tiempo depende, en mayor o menor medida, de los valores que la precedieron. Esta dependencia temporal, esta memoria del pasado, es la que permite la predicción, pero también es la fuente de su enorme complejidad.
Pensemos en la serie temporal del electrocardiograma de un paciente. Los picos y valles que dibuja la aguja no son aleatorios; siguen un patrón rítmico que refleja la salud del corazón. Un cardiólogo experto puede leer esta serie y detectar arritmias, isquemias o prever posibles eventos cardíacos futuros. Su pericia reside en su capacidad para reconocer patrones sutiles en esa secuencia ordenada. Consideremos ahora los datos de tráfico de una gran ciudad, medidos cada cinco minutos en una arteria principal. Existe un patrón diario evidente, con picos en las horas de entrada y salida del trabajo. También hay un patrón semanal, con menos tráfico durante los fines de semana. Y puede haber un patrón estacional, con más tráfico en períodos vacacionales o menos durante las lluvias intensas. Superpuesta a todos estos patrones regulares y cíclicos, hay una tendencia a largo plazo, quizás el tráfico aumenta un pequeño porcentaje año tras año debido al crecimiento de la población. Y finalmente, como una capa de imprevisibilidad, existe un componente de ruido aleatorio: un accidente, una manifestación, un semáforo averiado o la simple variabilidad del comportamiento humano introducen fluctuaciones que son, por naturaleza, difíciles de predecir.
Cualquier analista, ya sea humano o artificial, que se enfrente a una serie temporal debe ser capaz de descomponerla en estos componentes fundamentales: tendencia, estacionalidad y ruido. La tendencia representa la dirección a largo plazo de la serie. La estacionalidad se refiere a los patrones que se repiten en intervalos fijos de tiempo. El ruido, o residuo, es lo que queda después de haber extraído los dos primeros. Pero los desafíos no terminan ahí, ni mucho menos. Los datos del mundo real son inherentemente sucios, imperfectos. Las series temporales a menudo llegan con valores faltantes, producto de un fallo en un sensor, un error en la transmisión o un simple descuido en la recolección. Pueden contener valores atípicos o anómalos, como una caída repentina a cero en las ventas de un producto porque se agotó el stock, un dato que no refleja la demanda real sino una limitación logística. La frecuencia de las mediciones puede variar, o puede que necesitemos combinar datos medidos en intervalos distintos, como datos de ventas diarias con datos de gasto en publicidad mensual, un problema conocido como alineación temporal.
El trabajo de un científico de datos consiste en navegar este laberinto de complejidades. Debe seleccionar las técnicas estadísticas adecuadas para imputar los valores faltantes, decidir si un valor atípico debe ser eliminado, ajustado o simplemente ignorado, y determinar cómo alinear series con diferentes frecuencias sin introducir sesgos. Cada una de estas decisiones es crucial y puede tener un impacto dramático en la calidad del pronóstico final. Un error en la fase de preprocesamiento puede invalidar por completo el trabajo posterior, sin importar cuán avanzado o sofisticado sea el modelo predictivo que se utilice. Esta es la razón principal por la que la automatización completa ha sido tan esquiva durante tanto tiempo. No se trata solo de aplicar fórmulas matemáticas, sino de tomar decisiones informadas y contextualizadas basadas en un entendimiento profundo de la estructura y la naturaleza de los datos.
| Característica del Análisis | Enfoque Tradicional (Humano) | Enfoque de TimeSeriesScientist (Agente IA) |
| Diagnóstico de Datos | Manual, visual, basado en la experiencia. Lento y propenso a la subjetividad. | Automático, guiado por LLM, usa herramientas estadísticas. Rápido, sistemático y justificable. |
| Preprocesamiento | Selección manual de técnicas (imputación, transformación). Proceso de prueba y error. | El agente Curador selecciona y aplica la mejor técnica basándose en el diagnóstico. |
| Selección de Modelos | Basada en el conocimiento del analista y la experimentación. Puede ser un proceso largo. | El agente Planificador crea una hipótesis y un plan acotado de modelos prometedores. Eficiente. |
| Pronóstico | Se prueban varios modelos de forma secuencial o en paralelo, con ajuste manual de parámetros. | El agente Pronosticador ejecuta el plan, probando un conjunto diverso de modelos optimizados. |
| Integración de Resultados | Se combinan pronósticos manualmente (ej. promedios). La ponderación es a menudo heurística. | El agente Integrador evalúa y combina los pronósticos con una estrategia razonada (ej. ponderación). |
| Generalización | La experiencia de un analista está a menudo ligada a un dominio específico (ej. finanzas). | Diseñado para ser agnóstico al dominio, aprendiendo las características de cada nueva serie. |
Un cambio de paradigma: de herramientas aisladas a agentes autónomos
La historia de la predicción de series temporales es una crónica de la creación de herramientas cada vez más potentes y especializadas. Comenzó con métodos estadísticos clásicos como los modelos ARIMA (Modelos Autoregresivos Integrados de Media Móvil), que son excepcionalmente buenos para capturar relaciones lineales simples en los datos. Luego llegaron modelos más complejos como el suavizado exponencial, capaces de manejar explícitamente la tendencia y la estacionalidad. Con la revolución del aprendizaje profundo, que transformó tantos otros campos de la inteligencia artificial, surgieron las redes neuronales recurrentes (RNN) y las más sofisticadas redes de memoria a corto y largo plazo (LSTM), diseñadas específicamente para procesar secuencias y recordar información a lo largo del tiempo. Más recientemente, arquitecturas como los Transformers, que han demostrado un éxito espectacular en el procesamiento del lenguaje natural, se han adaptado con gran acierto para el análisis de series temporales, mostrando una capacidad sin precedentes para capturar dependencias a muy largo plazo.
Sin embargo, todos estos modelos, desde el más simple hasta el más complejo, son en esencia herramientas pasivas. Son como martillos neumáticos, sierras de precisión y destornilladores sónicos de una caja de herramientas de alta tecnología. Para construir algo de valor, se necesita un artesano que sepa qué herramienta usar, en qué orden y con qué técnica específica. El artesano examina la madera (los datos), concibe un plan en su mente (la estrategia de análisis) y luego selecciona y aplica las herramientas con destreza.
El problema fundamental en el análisis de datos es que el número de «maderas» diferentes es prácticamente infinito, y cada una requiere un tratamiento distinto. Los modelos existentes son como artesanos hiperespecializados: un experto en el uso del martillo que intenta usarlo para cortar, lijar y barnizar. Su rendimiento es excepcional en la tarea para la que fue diseñado, pero muy pobre fuera de ella.
TimeSeriesScientist propone una visión completamente diferente, un auténtico salto conceptual. En lugar de intentar crear una herramienta aún mejor, sus creadores se han enfocado en construir al artesano. El concepto de «agente» de inteligencia artificial es clave para entender esta distinción. Un agente no es solo un programa que ejecuta una tarea predefinida. Es un sistema que percibe su entorno (en este caso, las propiedades de la serie temporal), razona sobre él, establece objetivos (como mejorar la calidad de los datos o encontrar el mejor modelo), crea un plan para alcanzar dichos objetivos y ejecuta ese plan, a menudo coordinando el uso de múltiples herramientas externas. Es un sistema proactivo, autónomo y con capacidad de razonamiento.
El motor que impulsa esta capacidad de razonamiento y planificación en TSci es un gran modelo de lenguaje. Los LLM, al haber sido entrenados con la inmensidad de textos y códigos disponibles en internet, han desarrollado capacidades emergentes que van mucho más allá de la simple generación de lenguaje. Han aprendido a descomponer un problema complejo en pasos más simples, pueden inferir intenciones a partir de una descripción de alto nivel y pueden interactuar con otras herramientas de software a través de interfaces de programación (API).
El equipo detrás de TSci ha aprovechado de manera brillante estas capacidades para orquestar el complejo ballet del análisis de datos. Han enseñado al LLM a actuar como el director de proyecto de un equipo de analistas de datos, guiando a agentes especializados en cada etapa del proceso. Este es el verdadero salto cualitativo: la inteligencia artificial no solo ejecuta tareas, sino que gestiona el flujo de trabajo completo, tomando decisiones estratégicas en cada punto de inflexión.
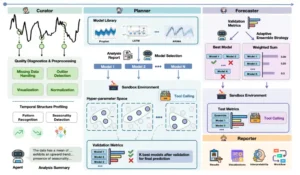
Visión general del sistema TSci. Este diagrama muestra el flujo de trabajo de cuatro agentes que colaboran como un científico de datos. El Curador limpia y analiza los datos. El Planificador selecciona los mejores modelos. El Pronosticador combina sus resultados para la predicción final. El Reportero genera un informe completo.
La anatomía de un científico de datos artificial: el equipo de TSci
El poder y la robustez de TimeSeriesScientist residen en su arquitectura modular, una inteligente división del trabajo que imita la especialización que se encuentra en un equipo humano de alto rendimiento. Cada uno de sus cuatro agentes tiene una misión clara, un conjunto de habilidades únicas y un protocolo de comunicación para colaborar con los demás.
El primer agente, el Curador, es el guardián de la calidad de los datos. Su lema podría ser «basura entra, basura sale». Sabe que ningún análisis, por sofisticado que sea, puede ser fiable si se basa en datos defectuosos o mal preparados. Cuando recibe una serie temporal cruda, el Curador inicia un diálogo interno con el gran modelo de lenguaje. El LLM, actuando como un consultor senior, genera un perfil descriptivo de la serie. A continuación, el Curador utiliza un conjunto de herramientas de análisis estadístico para calcular métricas concretas: el porcentaje de valores nulos, la presencia de valores atípicos mediante pruebas estadísticas, el grado de estacionalidad, o si la serie es estacionaria (una propiedad técnica fundamental que indica si las propiedades estadísticas de la serie, como la media y la varianza, cambian con el tiempo). Con este diagnóstico completo sobre la mesa, el LLM, actuando como un supervisor experto, instruye al Curador sobre qué acciones tomar. Por ejemplo, podría decidir que la mejor estrategia para los valores faltantes en esta serie particular es la «imputación por media móvil» en lugar de simplemente rellenarlos con el valor anterior. O podría optar por una transformación logarítmica para estabilizar la varianza de una serie que muestra un crecimiento exponencial. El Curador ejecuta estas operaciones, entregando un conjunto de datos limpio, normalizado y preparado para el análisis predictivo.
Con los datos ya depurados y en condiciones óptimas, el Planificador toma el relevo. Su función es la de un estratega consumado. No se precipita a aplicar ciegamente el primer modelo que se le ocurre. En su lugar, realiza un profundo análisis diagnóstico, que incluye la visualización de los datos (aunque sea de forma interna y abstracta para la máquina) y el cálculo de características adicionales como la autocorrelación o la entropía. El objetivo es entender la «personalidad» de la serie temporal. ¿Es suave y predecible o errática y ruidosa? ¿Tiene ciclos estacionales claros y repetitivos o patrones más complejos y cambiantes? Basándose en este perfil detallado, el Planificador, de nuevo guiado por el razonamiento del LLM, elabora una lista corta de candidatos a modelos. Formula una hipótesis explícita: «Dado que esta serie muestra una fuerte estacionalidad semanal y una tendencia lineal clara, los modelos de suavizado exponencial y ARIMA deberían funcionar bien, mientras que un modelo basado en redes neuronales simples, que es mejor para datos sin tendencia, probablemente tendrá un rendimiento inferior». Este paso de planificación es fundamental, ya que reduce drásticamente el espacio de búsqueda y enfoca los valiosos recursos computacionales en las estrategias más prometedoras, evitando perder tiempo en callejones sin salida.
El tercer componente es el Pronosticador. Es importante destacar que no es un único agente, sino una colección heterogénea de modelos de predicción. Es un verdadero arsenal que va desde los confiables caballos de batalla estadísticos como ARIMA y ETS (Error, Trend, Seasonality), hasta sofisticadas redes neuronales profundas como N-BEATS y PatchTST. Actúa como un equipo de especialistas a los que el Planificador encarga el trabajo. Cada modelo del Pronosticador recibe los datos limpios y genera una predicción siguiendo sus propios principios matemáticos y algorítmicos. El resultado es un conjunto de pronósticos, cada uno ofreciendo una visión del futuro desde una perspectiva diferente. Esta diversidad es una de las mayores fortalezas del sistema, ya que distintos modelos son buenos para capturar diferentes tipos de patrones en los datos.
Finalmente, entra en juego el Integrador. Su tarea es, quizás, la más delicada y la que más se asemeja al juicio experto: sintetizar la sabiduría colectiva del Pronosticador. El Integrador recibe todos los pronósticos individuales, junto con información detallada sobre el rendimiento de cada modelo en el pasado reciente de la propia serie. El LLM examina toda esta evidencia y razona sobre la mejor forma de combinarla. A veces, la decisión puede ser simple: un modelo ha superado claramente a todos los demás en precisión, por lo que su pronóstico se elige como el final. En otros casos, el camino es más sutil y requiere más juicio. El Integrador puede decidir que la mejor estrategia es un «promedio ponderado», dando más peso a los modelos que han demostrado ser más precisos o más estables. O podría optar por una «media recortada», una estrategia robusta que ignora los pronósticos más extremos (tanto los demasiado optimistas como los demasiado pesimistas) para quedarse con el consenso del centro. El Integrador incluso puede asignar pesos personalizados basándose en un análisis cualitativo de los resultados, como por ejemplo, dando más peso a un modelo más simple si su precisión es casi tan buena como la de un modelo mucho más complejo. Su decisión final, siempre justificada y razonada, produce el pronóstico definitivo del sistema, junto con una evaluación de la confianza en esa predicción.
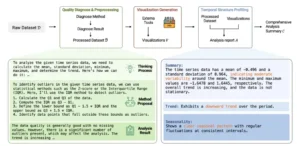
Flujo de trabajo del Curador. El agente recibe datos brutos, los diagnostica y procesa, genera visualizaciones para el análisis y finalmente produce un resumen con los hallazgos clave sobre la tendencia y estacionalidad de los datos.
El juicio final: TSci frente a los mejores del mundo
Una nueva tecnología, por muy elegante que sea su diseño teórico, debe demostrar su valía en el campo de batalla de la evidencia empírica. Para TimeSeriesScientist, este campo de batalla son los benchmarks de series temporales, colecciones estandarizadas que contienen miles de conjuntos de datos del mundo real, extraídos de dominios tan diversos como la economía, la industria, la demografía, el clima y el turismo. Estos benchmarks son el estándar de oro aceptado por la comunidad científica para evaluar y comparar de forma justa y reproducible el rendimiento de los modelos de predicción.
Los investigadores sometieron a TSci a una batería de pruebas exhaustivas y rigurosas, enfrentándolo no solo a modelos individuales de última generación, sino también a las mejores soluciones de «autoML» (aprendizaje automático automatizado) disponibles en la industria, plataformas que también intentan automatizar la selección del mejor modelo. Los resultados, detallados en el artículo científico, son notables y consistentes. En un amplio espectro de tareas y conjuntos de datos, TimeSeriesScientist superó de manera sistemática a todos sus competidores.
Por ejemplo, en tareas de predicción con un horizonte corto, donde el objetivo es prever los próximos pasos inmediatos de una serie, TSci demostró una precisión superior a la de los modelos más avanzados diseñados específicamente para esa tarea. Pero su verdadero poder se reveló en su generalidad y su robustez. Mientras que otros modelos mostraban un rendimiento muy desigual, destacando en ciertos tipos de datos (por ejemplo, series largas y estables) pero fallando estrepitosamente en otros (series cortas y ruidosas), TSci mantuvo un nivel de excelencia en todos los ámbitos. Era igualmente hábil pronosticando las series temporales cortas y con mucho ruido, que son la pesadilla de muchos algoritmos, como lo era con series largas y con patrones bien definidos y predecibles.
Un aspecto particularmente revelador de la evaluación fue el análisis de ablación. En este tipo de análisis, los científicos desactivan sistemáticamente partes del sistema para ver cómo afecta al rendimiento general. Es como quitarle una pieza a un motor para entender para qué sirve. Cuando desactivaron el agente Curador, el rendimiento del sistema se desplomó, lo que demuestra la importancia crítica del preprocesamiento inteligente y adaptativo de los datos. Cuando eliminaron al Planificador, el sistema se volvió mucho menos eficiente, gastando una cantidad excesiva de recursos en probar modelos inadecuados que un experto humano habría descartado de inmediato. Y cuando anularon al Integrador, la robustez y la fiabilidad de los pronósticos disminuyeron considerablemente, mostrando el inmenso valor de combinar múltiples perspectivas en lugar de apostar por un único ganador. Cada agente demostró ser no solo útil, sino una pieza indispensable de un todo sinérgico. El éxito de TSci no provenía de un único componente revolucionario, sino de la perfecta orquestación de todas las etapas del proceso científico.
| Componente de TSci | Propósito Fundamental | Impacto de su Eliminación (Análisis de Ablación) |
| Curador | Limpieza y preparación de datos (manejo de nulos, anomalías, etc.). | Caída drástica en la precisión general. Demuestra que la calidad de los datos es la base de todo pronóstico fiable. |
| Planificador | Reducción del espacio de búsqueda de modelos mediante un plan estratégico. | Aumento significativo del coste computacional y del tiempo de ejecución. El sistema se vuelve ineficiente. |
| Pronosticador | Generación de un conjunto diverso de predicciones desde múltiples enfoques algorítmicos. | El sistema pierde la diversidad de perspectivas, volviéndose un modelo único y menos adaptable. |
| Integrador | Síntesis inteligente de los múltiples pronósticos en una única predicción robusta. | Menor robustez y fiabilidad. El pronóstico final se vuelve más vulnerable a los errores de un solo modelo. |
El futuro pronosticado: el impacto de un analista autónomo
La llegada de TimeSeriesScientist no es simplemente un avance incremental en el campo del aprendizaje automático; no es un coche un poco más rápido o un ordenador un poco más potente. Es el heraldo de una nueva era en el análisis de datos, una en la que la inteligencia artificial puede asumir roles cognitivos de alto nivel, roles que implican razonamiento, planificación y estrategia, que hasta ahora eran dominio exclusivo de los expertos humanos. Las implicaciones de esta transición son profundas, de gran alcance y se extenderán por toda la sociedad.
En el ámbito empresarial, TSci tiene el potencial de democratizar el acceso a la analítica predictiva avanzada. Hasta ahora, solo las grandes corporaciones con equipos de científicos de datos bien financiados podían permitirse desarrollar pronósticos sofisticados de demanda de productos, ventas futuras o niveles de inventario. Con un sistema como TSci, una pequeña o mediana empresa podría, en teoría, obtener pronósticos de alta calidad de forma automática y a un coste marginal, permitiéndole optimizar sus operaciones, reducir drásticamente los costes de inventario y el desperdicio, y competir en igualdad de condiciones con los gigantes de su sector. Desde una panadería local que quiere predecir con precisión la demanda de pan para minimizar el producto no vendido al final del día, hasta una startup tecnológica que busca prever el crecimiento de usuarios para planificar la escalabilidad de su infraestructura, las aplicaciones son casi ilimitadas.
En el campo de la ciencia y la investigación, el impacto podría ser aún más transformador si cabe. Los científicos de disciplinas tan variadas como la climatología, la sismología, la epidemiología o la neurociencia dedican una parte considerable de su valioso tiempo al análisis de datos temporales. Un agente autónomo como TSci podría liberar a estos investigadores de la carga del análisis de datos rutinario, una tarea necesaria pero que a menudo les aparta de su objetivo principal. Esto les permitiría centrarse en la interpretación de los resultados, en la formulación de nuevas hipótesis y en el diseño de nuevos experimentos. Podría acelerar de forma exponencial el ritmo de los descubrimientos, ayudando a encontrar patrones sutiles en los datos climáticos que alerten sobre puntos de inflexión irreversibles, a predecir la propagación de una nueva epidemia con mayor antelación, o a identificar biomarcadores predictivos en las señales cerebrales de pacientes con enfermedades neurodegenerativas como el Alzheimer o el Parkinson.
Por supuesto, esta nueva y poderosa tecnología también plantea interrogantes y desafíos que debemos abordar con seriedad. La idea de una inteligencia artificial que toma decisiones autónomas sobre cómo tratar y modelar los datos requiere un altísimo grado de confianza y transparencia. ¿Cómo podemos estar seguros de que las decisiones que toma el agente son las correctas y no están basadas en sesgos espurios de los datos? El marco de TSci, al hacer que el gran modelo de lenguaje justifique explícitamente cada una de sus decisiones estratégicas (por qué eligió una estrategia de imputación, por qué seleccionó ciertos modelos, por qué los combinó de una manera específica), ofrece una vía prometedora hacia la interpretabilidad. Podemos auditar su cadena de razonamiento de una manera que a menudo es imposible con las impenetrables «cajas negras» de muchas redes neuronales profundas.
Estamos, quizás, en el umbral de una era en la que el rol del científico de datos humano evolucionará de ser un «hacedor» a ser un «supervisor» o un «director de orquesta». Nuestro papel se desplazará de la ejecución manual y detallada de análisis a la supervisión de equipos de agentes de inteligencia artificial, estableciendo los objetivos estratégicos, validando sus resultados más críticos y utilizando nuestra intuición y conocimiento del dominio para guiar su trabajo en las fronteras más complejas e inexploradas del conocimiento.
TimeSeriesScientist es mucho más que un simple sistema de pronóstico. Es una prueba de concepto contundente de que la inteligencia artificial puede emular y automatizar un proceso intelectual complejo, de principio a fin. Nos muestra un futuro en el que la colaboración simbiótica entre humanos y máquinas inteligentes nos permitirá navegar por el vasto y a menudo turbulento océano de datos con una claridad y una previsión que hoy apenas podemos empezar a imaginar. El pulso del mundo se está acelerando, los datos fluyen cada vez más rápido, pero por primera vez, tenemos una herramienta que podría ser capaz no solo de seguirle el ritmo, sino incluso de adelantarse a él.
Fuentes
Zhao, H., Zhang, X., Wei, J., Xu, Y., He, Y., Sun, S., & You, C. (2025). TimeSeriesScientist: A General-Purpose AI Agent for Time Series Analysis. arXiv preprint arXiv:2510.01538.
Box, G. E. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time Series Analysis: Forecasting and Control. John Wiley & Sons.

