
Las conversaciones sobre inteligencia artificial suelen girar en torno a modelos gigantescos que aprenden de todo Internet y se despliegan en potentes centros de datos. Sin embargo, la realidad es que, para muchas aplicaciones, la energía y la privacidad son restricciones que no se pueden ignorar. Pensemos en un teléfono móvil que quiere responder a preguntas sobre documentos que nunca fueron vistos por el fabricante del dispositivo. ¿Cómo lograr que esa inteligencia artificial sea útil sin enviar todos los datos personales a un servidor central? Ese interrogante es el punto de partida de una investigación reciente que combina tres conceptos: aprendizaje federado, adaptadores ad hoc y soft embeddings. Aunque a primera vista estas expresiones puedan sonar técnicas, esconden una historia accesible sobre cómo hacer más eficiente y seguro el aprendizaje automático.
El aprendizaje federado permite que muchos dispositivos colaboren en la mejora de un modelo sin compartir entre sí sus datos crudos. Cada teléfono entrena localmente y envía pequeñas actualizaciones a un servidor que combina los ajustes. De ese modo, los datos privados se quedan donde deben, pero el modelo aprende de la experiencia colectiva. Esto plantea un desafío: las grandes redes neuronales que dominan la conversación sobre inteligencia artificial general son demasiado pesadas para ser entrenadas en teléfonos o sensores sencillos. La solución parece obvia: ¿por qué no usar modelos más pequeños? La respuesta es que, al ser pequeños, estos modelos no capturan todo lo que necesitamos y su capacidad para adaptarse a nuevos dominios es limitada. Aquí entra el segundo ingrediente de la historia: los adaptadores.
Un adaptador es un pequeño módulo entrenable que se inserta en un modelo congelado. En lugar de ajustar millones de parámetros, se coloca un bloque ligero que redirecciona las entradas y altera el comportamiento. Es como poner una pieza intermedia en una cadena de montaje para cambiar el producto final. Los adaptadores son populares en la llamada adaptación eficiente de parámetros, porque permiten ajustar redes sin reescribir su memoria completa. Pero ¿dónde insertar esa pieza para aprovecharla al máximo en un modelo que actúa como recuperador de información? Esa pregunta guía la idea de los soft embeddings. Cuando un modelo procesa texto, lo primero que hace es convertir palabras en vectores numéricos; esas representaciones iniciales se denominan embeddings. Los investigadores propusieron añadir un adaptador justo antes de esa conversión. De este modo, el modelo puede aprender representaciones más ricas del nuevo dominio sin tener que tocar sus capas internas. A esas representaciones enriquecidas las llaman soft embeddings.
La propuesta se completa con un enfoque novedoso para recuperar información: en lugar de calcular una similitud matemática fija entre la pregunta y los documentos, se adjunta una cabeza de clasificación que aprende a decidir qué documentos son relevantes. Ese módulo se entrena dentro del mismo esquema federado, con privacidad diferencial para preservar los datos de los usuarios. Al final, el sistema está compuesto por un pequeño modelo lingüístico congelado, un adaptador entrenable que genera soft embeddings y una cabeza de clasificación que actúa como recuperador; todo afinado de manera federada en los dispositivos.
En esta introducción hemos mencionado varios términos (adaptador, recuperación de información, aprendizaje federado, privacidad diferencial) sin entrar en detalles. El objetivo de las siguientes secciones es desglosar cada concepto con claridad, mostrar cómo se combinan y analizar las implicaciones de la investigación tanto para especialistas como para lectores interesados en entender hacia dónde se dirigen las aplicaciones de la inteligencia artificial.
De qué trata el trabajo y qué problema pretende resolver
El estudio del que hablamos analiza un problema muy concreto: cómo entrenar un recuperador de información en un entorno donde los datos están dispersos en muchos dispositivos y la capacidad de cómputo es limitada. Los recuperadores suelen funcionar con una métrica de similitud entre la pregunta y los documentos, como el producto interno entre sus representaciones. Aunque ese mecanismo es simple y rápido, su calidad depende de que los embeddings capten bien el contenido. Con un modelo pequeño, esos embeddings son menos expresivos y la función de similitud fija no siempre es adecuada para todas las tareas. La investigación plantea que se puede mejorar tanto la representación como la comparación, siempre respetando la privacidad y las limitaciones de hardware.
La tesis central combina dos ideas: adaptar localmente la representación de los documentos mediante soft embeddings y reemplazar el cálculo de similitud por una cabeza clasificadora que decide cuáles son los documentos relevantes. Así, cada dispositivo no solo calcula su propio contexto sino que también participa en enseñar al modelo cuáles documentos son los adecuados para diferentes preguntas. Para lograrlo, se recurre al aprendizaje federado, una estrategia que permite actualizar el modelo sin extraer datos sensibles de los dispositivos. Las actualizaciones se transmiten al servidor de manera diferida y se agregan para mejorar la versión global.
¿Por qué es importante este planteamiento? Por dos razones clave. La primera es la eficiencia: insertar un adaptador ligero antes de la primera capa de un modelo de lenguaje congela la mayor parte de la red y reduce los parámetros entrenables. Esto hace viable la adaptación en dispositivos con poca memoria. La segunda es la privacidad: entrenar la cabeza de clasificación y el adaptador en cada cliente, combinando los cambios de forma federada, evita exponer directamente los datos personales. Además, se aplica ruido y clipping a las actualizaciones para garantizar privacidad diferencial a nivel local. De esta forma, se preserva la utilidad del modelo sin sacrificar la seguridad de los datos.
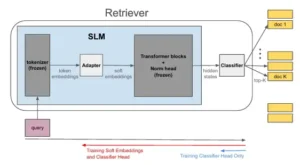
Resumen de nuestro enfoque CaR, donde hacemos dos mejoras ortogonales a la arquitectura del retriever. En contraste con los algoritmos de entrenamiento RAG existentes, donde el LLM completo del retriever es ajustado finamente, en nuestro trabajo en cambio lo congelamos y añadimos una pequeña red Adapter para PEFT. Segundo, en lugar de depender de la búsqueda de producto interno máximo para la recuperación, adjuntamos una cabeza de Clasificador al retriever para obtener documentos similares a una consulta. Nótese que esta arquitectura nos permite entrenar el retriever de dos maneras: una donde solo entrenamos la cabeza del clasificador, y la otra donde ajustamos finamente tanto la red adapter de incrustación suave como la cabeza del clasificador.
Conceptos básicos y marco conceptual
Para comprender plenamente la propuesta, es útil detenerse en algunos conceptos. La inteligencia artificial general es la idea de un sistema que puede realizar cualquier tarea cognitiva al nivel de un humano o superior. Por contraste, una inteligencia artificial estrecha se entrena para resolver tareas específicas, como traducir idiomas o clasificar imágenes. Este trabajo se centra en un modelo pequeño destinado a recuperar documentos: una aplicación estrecha, pero que utiliza estrategias inspiradas en sistemas generales.
La multimodalidad suele referirse a modelos que procesan texto, imágenes, audio o video de manera conjunta. En este estudio, la multimodalidad es limitada, ya que se trata de textos. Aun así, la noción de combinar distintas fuentes de información (embeddings, adaptadores, clasificadores) se mantiene. El razonamiento aquí aparece en el sentido de decidir qué documentos son pertinentes. En lugar de dejar esa decisión a un cálculo fijo, el modelo aprende a razonar con ejemplos para clasificar correctamente.
La alineación es la adecuación entre los objetivos del sistema y los valores o requisitos impuestos por los usuarios. En aprendizaje federado, la alineación se refiere a que las actualizaciones sean compatibles con la privacidad y las necesidades locales. Los priors, o probabilidades previas, son expectativas que un modelo tiene sobre los datos antes de ver ejemplos concretos. En contextos de recuperación, los priors pueden influir en la forma en que el modelo estima la relevancia de un documento. Los adaptadores permiten ajustar esos priors a dominios nuevos sin reentrenar la red completa.
La interpretabilidad alude a nuestra capacidad de entender por qué el sistema produce una salida. Aunque el estudio no se centra en interpretabilidad, el uso de adaptadores ligeros sugiere que se podrían aislar y examinar sus efectos. La robustez se refiere a la capacidad del sistema de mantener su comportamiento cuando cambian las condiciones de entrada o surgen ruidos inesperados. Ajustar solo un adaptador y una cabeza de clasificación puede ofrecer robustez frente a diferencias entre los datos de entrenamiento y los de despliegue.
El escalamiento se refiere a cómo crece el rendimiento o la complejidad de un sistema al aumentar su tamaño o su conjunto de datos. Los autores proponen técnicas para escalar el sistema sin comprometer la eficiencia, mediante mezcla de expertos y distribución de la carga computacional entre dispositivos y servidores. La gobernanza y la regulación se relacionan con las normas que guían el uso de la inteligencia artificial. Aquí, la gobernanza aparece en el diseño del protocolo federado y en la incorporación de privacidad diferencial para cumplir requisitos de protección de datos.
Respecto a la privacidad, el estudio adopta la privacidad diferencial, una garantía formal que asegura que los resultados de un proceso no permiten deducir si un dato particular formaba parte del conjunto de entrenamiento. La privacidad diferencial local implica que cada cliente aplica el ruido a sus datos antes de enviarlos, de modo que ninguna combinación futura pueda revelar información individual. Finalmente, el concepto de mezcla de expertos (MoE) se refiere a una estructura de modelo que distribuye tareas entre varios submodelos especializados. Se utiliza en la investigación para gestionar la creciente cantidad de clases cuando se clasifican grandes números de documentos.
Metodología: cómo se diseña el sistema
La metodología se desglosa en tres partes: la construcción de los soft embeddings, la definición del Classifier-as-Retriever y el protocolo de aprendizaje federado con privacidad diferencial.
Soft embeddings mediante adaptadores insertados
El proceso comienza con un modelo de lenguaje pequeño, un small language model (SLM), que ya ha sido preentrenado en grandes corpus. Este SLM permanece congelado, es decir, sus pesos no se modifican durante el entrenamiento federado. Entre la capa de entrada y la primera capa del transformador se inserta un pequeño adaptador entrenable. Este adaptador es una matriz cuadrada que transforma las representaciones iniciales de las palabras. Las nuevas representaciones se denominan soft embeddings porque resultan de una mezcla suave entre las embeddings originales y la adaptación aprendida.
El adaptador produce un vector intermedio para cada token, que luego se inyecta en el transformador. Como el SLM no se ajusta, los cálculos internos son eficientes y se mantienen estables, lo que facilita el despliegue en dispositivos con poca memoria. Esta estrategia difiere de otros métodos de afinado parcial, como la inserción de LoRA (low-rank adapters) en cada bloque, ya que aquí solo se modifica la fase de entrada. La consecuencia es que se necesitan muchos menos parámetros para adaptar el modelo a un nuevo dominio, lo que disminuye la comunicación en el aprendizaje federado.
El recuperador como clasificador
Una vez que se obtienen los soft embeddings, el siguiente paso es definir cómo medir la similitud entre una pregunta y los documentos. El enfoque clásico consiste en calcular un producto interno entre los vectores de la pregunta y de cada documento. Ese método, conocido como MIPS (máxima búsqueda de producto interno), es rápido pero no captura matices semánticos complejos. El trabajo propone reemplazar la función fija por un Classifier-as-Retriever (CaR). La idea es sencilla: si se quiere saber qué documentos son relevantes, ¿por qué no entrenar un clasificador que reciba un par (pregunta, documento) y devuelva la probabilidad de que el documento sea la respuesta correcta?
Para lograrlo, se añade una cabeza de clasificación encima del SLM congelado. La cabeza toma la salida del transformador que procesó la pregunta y los documentos (mediante sus soft embeddings) y genera puntajes para cada documento. En lugar de usar un único vector como representación del documento, se utilizan sumarios de sus palabras que pasan por la misma arquitectura.
Durante el entrenamiento, el modelo aprende a ajustar los pesos del adaptador y de la cabeza para maximizar la probabilidad de asignar la puntuación más alta a los documentos correctos. Al final del proceso, la cabeza de clasificación es capaz de reemplazar la similitud fija: una nueva pregunta se empareja con cada documento, se calcula el puntaje y se devuelven los k documentos con las probabilidades más altas.
Aprendizaje federado y privacidad diferencial
La tercera pieza del método es el aprendizaje federado. Se parte de un conjunto de clientes (por ejemplo, usuarios de teléfonos) numerados del uno al m. Cada cliente tiene un conjunto local de documentos y preguntas. En cada ronda de entrenamiento, el cliente calcula actualizaciones para el adaptador y la cabeza de clasificación basándose en sus datos. Luego envía solo las diferencias entre sus pesos y los pesos globales a un servidor que ejecuta la agregación de los cambios, generalmente mediante el algoritmo FedAvg. Tras combinar las actualizaciones, el servidor actualiza el modelo global y lo distribuye de nuevo a los clientes. Al repetir el ciclo, se obtiene un modelo que mejora con las aportaciones de todos sin acceder directamente a los documentos de cada cliente.
Para preservar la privacidad, no basta con no compartir datos crudos. Incluso las actualizaciones podrían revelar información sensible si se analizan de manera cuidadosa. Por eso, se recurre a la privacidad diferencial local. Antes de enviar la actualización, cada cliente aplica un recorte a los vectores (clipping) para limitar su magnitud y añade ruido gaussiano con una varianza calibrada. Este procedimiento garantiza que un observador externo no pueda determinar si un dato específico estaba en el conjunto de entrenamiento. La cantidad de ruido se elige de manera que mantenga un equilibrio entre privacidad y precisión. Los autores mencionan un enfoque adaptativo para ajustar el nivel de ruido según la dinámica del entrenamiento, aunque los detalles completos se encuentran en el apéndice del trabajo.

Resultados del entrenamiento federado en AG News utilizando el modelo Llama‑3.2‑3B
Cómo se defiende la propuesta y qué muestra la teoría
Para justificar sus decisiones, los autores aportan argumentos y análisis teóricos. Un punto clave es mostrar que la inserción del adaptador como soft embedding no degrada la capacidad del modelo y que puede aprender representaciones específicas de cada dominio sin sacrificar la estabilidad del SLM. Argumentan que el adaptador puede verse como una transformación lineal que ajusta la base del espacio de embeddings, proporcionando más flexibilidad a las representaciones iniciales. Además, destacan que, al ser un módulo pequeño, la comunicación en federated learning se mantiene manejable.
El artículo también proporciona una versión simplificada de la función de pérdida que se optimiza de manera federada. Considera que, para cada cliente, el objetivo local es maximizar la probabilidad de que el clasificadora asigne alta puntuación a los documentos correctos y baja a los incorrectos. La pérdida global es la suma de todas las pérdidas locales ponderadas por el número de ejemplos en cada cliente. El texto explica que, bajo ciertas condiciones de convexidad y regularidad de la función de pérdida, es posible demostrar la convergencia del algoritmo FedAvg a un punto próximo al mínimo global. Aunque el modelo es no convexo debido a la naturaleza de las redes neuronales, se ofrece un análisis que acota la diferencia entre la solución federada y la centralizada.
Otro argumento teórico se refiere a la mezcla de expertos para escalar el número de clases. Cuando la colección de documentos crece, la cabeza de clasificación debe manejar muchos pares pregunta‑documento, y el espacio de salida se vuelve ineficiente. Los autores proponen dividir la colección en clústeres y asignar un experto a cada clúster. Un gating decide qué experto se activa para cada par. Esto reduce la complejidad y, según las simulaciones, no penaliza la precisión.
Finalmente, el trabajo incluye una discusión sobre distribución de la carga. En algunos escenarios, los dispositivos pueden no tener recursos para procesar la totalidad de un modelo, incluso con adaptadores. Se sugiere entonces desplegar las capas más pesadas en servidores cercanos, mientras los clientes ejecutan la primera etapa. Esta colaboración híbrida mantiene la eficiencia y permite escalar la capacidad de los modelos.
Hallazgos experimentales
El estudio complementa la teoría con experiencias numéricas. Se comparó el nuevo método con recuperadores basados en productos internos y con adaptaciones estándar de modelos de lenguaje. Las pruebas se realizaron en tareas de recuperación de documentos donde cada pregunta debía enlazarse con las respuestas correctas entre miles de candidatos. Se evaluaron métricas habituales como la precisión en los primeros k resultados y el costo computacional.
Los resultados muestran que insertar un adaptador para soft embeddings y entrenar una cabeza de clasificación mejora la precisión respecto a utilizar un producto interno fijo. Además, al congelar el SLM se redujo el uso de memoria, lo que permite ejecutar el modelo en dispositivos con limitaciones. En el contexto de aprendizaje federado, el método preservó el rendimiento a medida que aumentaba el número de clientes. Se observó un fenómeno llamado speedup, donde la aceleración del entrenamiento federado crece al añadir más participantes, hasta cierto límite. El equilibrio entre privacidad y precisión también fue favorable: el ruido agregado para garantizar la privacidad diferencial no destruyó la capacidad de recuperación.
Las simulaciones incluyeron pruebas con y sin mezcla de expertos. En colecciones pequeñas, la cabeza de clasificación simple es suficiente. Cuando el número de documentos crece, la mezcla de expertos mejora la eficiencia sin sacrificar exactitud. Los autores exploraron distintos tamaños de adaptadores y niveles de ruido para la privacidad diferencial, mostrando que existe un rango de hiperparámetros que mantiene la estabilidad del entrenamiento.
En cuanto a la comparación con otros métodos de adaptación, como LoRA o ajuste completo de modelos, el artículo destaca que la inserción de adaptadores ad hoc en la fase de embeddings requiere menos parámetros y menos comunicación, lo que lo hace más adecuado para entornos federados. El ajuste completo de todos los bloques, aunque puede alcanzar mayor precisión en un servidor centralizado, resulta inviable en dispositivos con recursos limitados y puede generar problemas de privacidad y transferencia de datos. La propuesta ofrece un compromiso atractivo entre eficacia y eficiencia.
Análisis crítico y preguntas abiertas
La investigación planteada es ambiciosa y presenta soluciones para varios problemas simultáneos: la necesidad de actualizar recuperadores en dominios nuevos, las limitaciones de memoria y cómputo de los dispositivos y la protección de la privacidad de los datos. Al proponer soft embeddings y una cabeza de clasificación, abre la puerta a métodos de recuperación más adaptativos. Sin embargo, conviene reflexionar sobre algunos desafíos no resueltos y preguntas que emergen de este trabajo.
Un aspecto que podría mejorar es la transparencia respecto a la interpretabilidad. Aunque el uso de adaptadores parece aumentar la flexibilidad sin tocar el núcleo del modelo, sería útil investigar cómo influyen en las decisiones y si pueden ofrecer pistas sobre qué características del texto son más relevantes en cada dominio. Esto podría fomentar la confianza de usuarios y reguladores.
Otro punto abierto es la gestión de recursos en escenarios reales. Si bien el estudio propone distribuir las capas, los detalles de esa arquitectura híbrida no se exploran en profundidad. Sería interesante ver pruebas de latencia, fiabilidad y consumo energético en condiciones de red variables. Asimismo, la mezcla de expertos plantea un problema práctico: cómo decidir el número de clústeres y cómo actualizarlos cuando la colección de documentos crece o cambia con el tiempo.
La privacidad es un pilar del enfoque, pero añade un parámetro que debe calibrarse: demasiada perturbación puede degradar la utilidad del modelo, muy poca puede dejar expuestos los datos. El artículo menciona un método adaptativo para ajustar el ruido, pero no profundiza en su implementación. Una investigación futura podría explorar cómo automatizar ese equilibrio de manera dinámica según las características de los datos y del entrenamiento.
Finalmente, quedan pendientes exploraciones sobre la generalización a otros dominios más allá del texto puro. ¿Qué ocurre cuando se combinan imágenes y texto, o audio y transcripciones? ¿Sería posible insertar adaptadores multimodales que ajusten las representaciones de diversos tipos de datos? Estas preguntas son relevantes porque el aprendizaje federado se utiliza en aplicaciones como salud, domótica y vehículos autónomos, donde los datos provienen de múltiples fuentes.
Síntesis final
En un campo dominado por modelos colosales y centros de datos que consumen energía en cantidades astronómicas, el trabajo que hemos explorado plantea un camino alternativo. Su propuesta combina la flexibilidad de los adaptadores, la eficiencia del aprendizaje federado y la protección de la privacidad mediante ruido calibrado. El resultado es un mecanismo para entrenar un recuperador de información que se adapta a nuevos dominios sin transferir datos sensibles ni requerir cómputo excesivo. La pieza clave es la inserción de un pequeño módulo que ajusta las representaciones de entrada, generando soft embeddings que captan mejor el contexto local. Al sustituir la función fija de similitud por una cabeza de clasificación entrenada, el sistema logra una recuperación más precisa y controlada.
La relevancia social de este enfoque es evidente. Nos encontramos en una época en la que la información personal viaja en miles de dispositivos y la confianza en la inteligencia artificial depende de su capacidad para proteger esos datos. El aprendizaje federado con adaptadores ad hoc ofrece un modelo de colaboración distribuida que respeta la privacidad y permite a las comunidades entrenar sistemas útiles sin ceder el control de sus datos. A nivel tecnológico, abre horizontes sobre cómo escalar sistemas a grandes colecciones sin saturar la memoria de los clientes. Y desde la perspectiva científica, propone líneas de investigación sobre convergencia, interpretabilidad y mezcla de expertos que podrían redefinir la arquitectura de recuperadores futuros.
El libro de ruta que deja el trabajo es claro: para avanzar hacia inteligencias artificiales realmente útiles, necesitamos equilibrar ambición y prudencia. Es necesario innovar en modelos que consuman menos recursos y que aprendan de manera más segura. Es imprescindible diseñar protocolos que permitan aprovechar la sabiduría de muchos sin vulnerar a nadie. Y es esencial introducir adaptabilidad en los engranajes de la IA, para que no dependan de una lógica rígida sino que se ajusten a las necesidades de los usuarios. El método de soft embeddings en aprendizaje federado se presenta así como una pieza más en la construcción de ese futuro: una pieza que propone unir eficiencia, privacidad y adaptabilidad en una sola estructura.
Referencias
-
Gu, Y., Fu, J., Liu, X., Valanarasu, J. M. J., Codella, N., Tan, R., Liu, Q., Jin, Y., Zhang, S., Wang, J., Wang, R., Song, L., Qin, G., Usuyama, N., Wong, C., Hao, C., Lee, H., Sanapathi, P., Hilado, S., Jiang, B., Álvarez-Valle, J., Wei, M., Gao, J., Horvitz, E., Lungren, M., Poon, H., & Vozila, P. (2025). Federated Learning with Ad-hoc Adapter Insertions: The Case of Soft-Embeddings for Training Classifier-as-Retriever. Microsoft Research, Health & Life Sciences.
-
Kairouz, P., McMahan, H. B., et al. (2019). Advances and Open Problems in Federated Learning. Foundations and Trends in Machine Learning, 14(1–2), 1–210.
-
Ramage, D., et al. (2023). Privacy at Scale: Local Differential Privacy in Practice. Google AI blog.
-
Bommasani, R., et al. (2021). On the Opportunities and Risks of Foundation Models. Stanford University report.

