
Los grandes modelos de lenguaje han transformado radicalmente la forma en que interactuamos con las máquinas. Capaces de redactar ensayos, responder preguntas complejas e incluso simular conversaciones humanas, estos sistemas han demostrado una fluidez lingüística sorprendente. Sin embargo, detrás de esa apariencia de inteligencia se esconde una limitación fundamental: su capacidad de razonamiento lógico sigue siendo frágil. A diferencia de un matemático que deduce un teorema paso a paso o un médico que evalúa síntomas para llegar a un diagnóstico, los modelos tradicionales no razonan; más bien, predicen secuencias de palabras basadas en patrones estadísticos aprendidos de ingentes volúmenes de texto. Este enfoque, aunque efectivo para tareas de generación, conduce frecuentemente a respuestas que suenan plausibles pero son incorrectas o contradictorias, un fenómeno conocido como “alucinación”.
En los últimos años, la comunidad científica ha centrado sus esfuerzos en superar esta barrera, buscando dotar a los modelos de una forma de pensamiento estructurado. La estrategia más prometedora consiste en guiar al modelo para que genere no solo una respuesta final, sino también una “cadena de pensamiento”: una secuencia de pasos intermedios que justifiquen su conclusión. Esta técnica ha mejorado notablemente el desempeño en tareas como la resolución de problemas matemáticos o la escritura de código. No obstante, entrenar a un modelo para que produzca estas cadenas de pensamiento de manera fiable y coherente sigue siendo un reto. Los métodos actuales, basados en ajuste fino supervisado o en aprendizaje por refuerzo, presentan limitaciones significativas. El primero depende de ejemplos de razonamiento de alta calidad, costosos de producir, mientras que el segundo puede ser inestable y tiende a favorecer soluciones simples en detrimento de las más complejas.
Es en este contexto que surge un nuevo enfoque: el razonamiento variacional. Este marco teórico, profundamente arraigado en la estadística bayesiana, propone una visión revolucionaria del proceso de razonamiento. En lugar de tratar la cadena de pensamiento como una simple secuencia de texto, la concibe como una variable latente, una entidad oculta cuya distribución de probabilidad puede ser optimizada para maximizar la verosimilitud de obtener una respuesta correcta. Esta perspectiva probabilística no solo ofrece un objetivo de entrenamiento más estable y principiado, sino que también proporciona una lente unificadora para entender por qué algunos métodos de entrenamiento funcionan y otros no. Al hacerlo, abre la puerta a una nueva generación de modelos de lenguaje que no solo hablan con elocuencia, sino que también piensan con rigor.
Una perspectiva bayesiana en los modelos de lenguaje
Para comprender la esencia del razonamiento variacional, es necesario retroceder hasta los cimientos de la inferencia estadística. En el corazón de este enfoque yace el teorema de Bayes, una fórmula que permite actualizar nuestras creencias a la luz de nueva evidencia. Imaginemos que un médico tiene una hipótesis inicial sobre una enfermedad (la probabilidad a priori). Al recibir los resultados de un análisis de sangre (la evidencia), utiliza el teorema de Bayes para calcular la probabilidad a posteriori: la probabilidad de que el paciente tenga la enfermedad dada la nueva información. Este proceso iterativo de revisión de creencias es la base del razonamiento bajo incertidumbre.
Aplicar este principio directamente a los modelos de lenguaje es, sin embargo, computacionalmente inviable. El cálculo de la probabilidad a posteriori exacta implicaría sumar sobre todas las posibles cadenas de pensamiento que podrían conducir a una respuesta correcta, un espacio de posibilidades infinitamente grande. Aquí es donde entra en juego la inferencia variacional, una técnica que aproxima la distribución posterior verdadera con una distribución más simple y manejable. El objetivo es encontrar la distribución de esta familia simple que esté más “cerca” de la posterior real, según una medida de distancia probabilística conocida como divergencia Kullback-Leibler.
Este mismo principio se ha utilizado con gran éxito en el campo del aprendizaje profundo, particularmente en los autocodificadores variacionales (VAEs). Un VAE aprende a comprimir datos complejos, como imágenes, en un espacio latente de menor dimensión y luego a reconstruirlos a partir de ese espacio. La clave está en que el codificador no produce un solo punto en el espacio latente, sino una distribución de probabilidad (normalmente una gaussiana). Esto obliga al modelo a aprender una representación estructurada y continua del espacio latente, lo que permite generar nuevas muestras al muestrear de él. La función de pérdida del VAE combina dos objetivos: minimizar el error de reconstrucción y asegurar que la distribución latente se parezca a una distribución de referencia simple, generalmente una gaussiana estándar.
El razonamiento variacional traslada esta lógica al dominio del lenguaje. Aquí, la “entrada” es una pregunta, la “salida” es una respuesta correcta, y el “espacio latente” está compuesto por todas las posibles cadenas de pensamiento que podrían conectar ambas. El modelo de razonamiento actúa como el decodificador, generando una respuesta a partir de una cadena de pensamiento. La distribución variacional, por su parte, actúa como un codificador inverso: dado una pregunta y una pista en forma de una respuesta correcta, genera cadenas de pensamiento que probablemente conduzcan a esa respuesta. Al optimizar conjuntamente estos dos componentes, el sistema aprende a navegar de manera eficiente por el vasto espacio del razonamiento, priorizando las trayectorias que son más propensas a llevar a la verdad.
El marco de razonamiento variacional
El marco de razonamiento variacional formaliza la intuición anterior en un objetivo de entrenamiento concreto y matemáticamente sólido. Su punto de partida es la cota inferior de evidencia (ELBO), una herramienta fundamental en la inferencia variacional que proporciona un límite inferior a la log-verosimilitud de los datos observados. En este contexto, los “datos observados” son las respuestas correctas a las preguntas planteadas. Maximizar la ELBO equivale a empujar la distribución variacional (nuestra aproximación al razonamiento) lo más cerca posible de la distribución posterior verdadera, que repondera todas las posibles cadenas de pensamiento en función de su capacidad para producir una respuesta correcta.
Una de las innovaciones clave del marco es su extensión a múltiples trayectorias de pensamiento. En lugar de considerar una sola cadena de razonamiento por pregunta, el modelo genera varias y las combina de manera ponderada. Esta estrategia, inspirada en los autocodificadores de importancia ponderada (IWAE), produce una cota inferior más ajustada a la log-verosimilitud real, lo que conduce a un entrenamiento más eficaz. Las cadenas de pensamiento que tienen una mayor probabilidad de generar una respuesta correcta reciben un peso mayor en la actualización de los parámetros del modelo.
Sin embargo, el mayor avance conceptual del trabajo es la introducción de una formulación basada en la divergencia KL hacia adelante. La inferencia variacional clásica minimiza la divergencia KL hacia atrás, lo que puede llevar a que la distribución aproximada colapse en un solo modo, ignorando otras regiones importantes del espacio latente. La KL hacia adelante, en cambio, es más robusta y fomenta una exploración más diversa y completa del espacio de razonamiento. Esta estabilidad es crucial para el entrenamiento de la distribución variacional, que de otro modo podría aprender atajos no deseados, como simplemente copiar fragmentos de la respuesta correcta en la cadena de pensamiento.
Quizás la contribución más reveladora del marco es su capacidad para reinterpretar métodos de entrenamiento existentes. El trabajo demuestra que técnicas populares como el ajuste fino con muestreo por rechazo y el aprendizaje por refuerzo con recompensa binaria pueden verse como instancias particulares de la minimización de la divergencia KL hacia adelante. Esta unificación teórica explica un fenómeno observado empíricamente: estos métodos tienden a desarrollar un sesgo implícito hacia las preguntas más fáciles. La razón es que la optimización está naturalmente ponderada por la precisión del modelo en cada pregunta. Las preguntas fáciles, para las que el modelo ya tiene una alta probabilidad de acertar, reciben un peso mucho mayor en la actualización de los parámetros, mientras que las preguntas difíciles, donde la probabilidad de éxito es baja, son efectivamente ignoradas. Al hacer explícito este mecanismo, el razonamiento variacional no solo ofrece una solución superior, sino que también proporciona una comprensión profunda de las limitaciones inherentes a los enfoques anteriores.
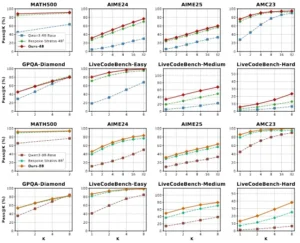
Comparación de las líneas base de Pass@K frente a nuestro método basado en Qwen3-4B/8B-Base
Aplicaciones prácticas y casos de uso reales del razonamiento avanzado en IA
El impacto del razonamiento avanzado en la inteligencia artificial ya se deja sentir en una amplia gama de sectores. Estos sistemas, capaces de simular procesos de pensamiento lógico y estructurado, están transformando la forma en que las empresas y las instituciones abordan problemas complejos. A diferencia de los modelos de generación pura, que a menudo producen resultados que deben ser verificados manualmente, los sistemas de razonamiento ofrecen un mayor grado de autonomía y fiabilidad, lo que los hace ideales para aplicaciones de alto riesgo y alto valor.
En el ámbito de la atención al cliente, los asistentes virtuales equipados con capacidades de razonamiento pueden manejar consultas complejas que requieren comprender el contexto de una conversación completa. Por ejemplo, un cliente que reporta un problema con un producto y luego pregunta sobre las opciones de reembolso puede recibir una respuesta coherente que vincule ambos temas, explicando no solo las políticas de reembolso, sino también cómo se aplican a su caso específico. En el sector financiero, estos modelos se utilizan para el análisis de riesgo y la detección de fraudes. Pueden examinar transacciones en tiempo real, identificar patrones sospechosos y, lo que es más importante, justificar sus alertas mediante reglas lógicas, reduciendo drásticamente la tasa de falsos positivos que sobrecargan a los analistas humanos.
La medicina es otro campo donde el razonamiento de la IA tiene un potencial transformador. Los sistemas pueden integrar datos de historiales clínicos, resultados de pruebas de laboratorio y la literatura médica más reciente para ayudar a los médicos en el diagnóstico de enfermedades raras o complejas. En lugar de ofrecer un diagnóstico en una caja negra, el modelo puede presentar una lista de posibles diagnósticos diferenciales, junto con la evidencia que respalda cada uno, permitiendo al profesional sanitario tomar una decisión informada. De manera similar, en la investigación farmacológica, los modelos de razonamiento pueden acelerar el descubrimiento de nuevos fármacos al predecir las interacciones entre moléculas y simular los efectos de posibles compuestos en vías biológicas específicas.
En el mundo de la robótica y la automatización industrial, el razonamiento es esencial para la planificación y la toma de decisiones en entornos dinámicos. Un robot en una fábrica no solo debe ejecutar una secuencia de movimientos preprogramada, sino también adaptarse a cambios en su entorno, como la presencia de un obstáculo inesperado. Un sistema de razonamiento le permite planificar una nueva ruta en tiempo real, evaluando múltiples opciones y seleccionando la más segura y eficiente. Finalmente, en el desarrollo de software, los modelos de razonamiento están alcanzando niveles de competencia que rivalizan con los programadores humanos en competiciones de codificación, capaces no solo de escribir código funcional, sino también de depurarlo y optimizarlo.
Los resultados empíricos del marco de razonamiento variacional, validados en las familias de modelos Qwen 2.5 y Qwen 3, demuestran ganancias consistentes y significativas en una amplia variedad de tareas de razonamiento. La siguiente tabla resume el desempeño de varios modelos entrenados a partir de Qwen3-4B-Base y Qwen3-8B-Base, comparando el nuevo enfoque con baselines sólidos como Bespoke-Stratos y General-Reasoner. Los resultados son contundentes: en benchmarks tan exigentes como MATH500, AIME24&25, OlympiadBench y GPQA-Diamond, las variantes del razonamiento variacional superan sistemáticamente a todos los competidores, a menudo por márgenes considerables. Esto no solo confirma la eficacia del método, sino que también sugiere que las mejoras en el razonamiento son robustas y generalizables, incluso a dominios fuera de la distribución de entrenamiento.
| Método | MATH500 (Avg@2) | AIME24 (Avg@32) | AIME25 (Avg@32) | OlympiadBench (Avg@2) | GPQA-D (Avg@8) | MMLU-Pro (Avg@1) |
|---|---|---|---|---|---|---|
| Qwen3-4B-Base | 45.30 | 4.79 | 5.73 | 23.37 | 29.10 | 36.89 |
| General-Reasoner-4B | 71.70 | 19.06 | 16.77 | 45.18 | 40.97 | 61.36 |
| Bespoke-Stratos-4B | 84.70 | 27.29 | 24.17 | 50.45 | 44.95 | 63.03 |
| Ours-PB-Acc-4B | 88.30 | 31.67 | 27.29 | 55.71 | 45.33 | 65.53 |
| Qwen3-8B-Base | 65.20 | 11.46 | 10.10 | 34.72 | 35.42 | 45.62 |
| Bespoke-Stratos-8B | 89.70 | 39.58 | 28.85 | 55.64 | 53.03 | 68.74 |
| Ours-PB-Acc-8B | 91.80 | 45.63 | 31.98 | 58.98 | 53.66 | 70.76 |
Impacto social y ético: navegando los desafíos de la nueva era de la IA razonadora
La emergencia de sistemas de IA con capacidades de razonamiento avanzado plantea una serie de cuestiones sociales y éticas de gran calado. El más inmediato es el impacto en el mercado laboral. A medida que estos modelos se vuelven más competentes en tareas cognitivas complejas, desde la redacción de contratos legales hasta la realización de auditorías financieras, es inevitable que reconfiguren el panorama profesional. Muchos trabajos que antes se consideraban a salvo de la automatización podrían verse transformados o incluso desaparecer, lo que exigirá una reevaluación masiva de las habilidades y la educación en la era digital.
Paralelamente, el problema del sesgo algorítmico adquiere una nueva dimensión. Si un modelo de razonamiento se entrena con datos históricos que reflejan prejuicios sociales, no solo los replicará, sino que los codificará en una lógica aparentemente impecable. Un sistema utilizado para evaluar solicitudes de crédito podría, por ejemplo, construir una cadena de razonamiento que, partiendo de datos aparentemente neutrales como el código postal o la ocupación, llegue a conclusiones discriminatorias contra ciertos grupos demográficos. La apariencia de racionalidad del modelo hace que estos sesgos sean aún más peligrosos, ya que son más difíciles de detectar y cuestionar.
La interpretabilidad sigue siendo un desafío fundamental. Aunque los modelos de razonamiento generan cadenas de pensamiento, no siempre es claro si estas reflejan genuinamente su proceso de toma de decisiones o son meras justificaciones post hoc diseñadas para parecer lógicas. Esta falta de transparencia es especialmente problemática en aplicaciones críticas, como la justicia o la atención sanitaria, donde las decisiones automatizadas pueden tener consecuencias vitales. La normativa emergente, como el Reglamento sobre Inteligencia Artificial de la Unión Europea, exige que los sistemas de alto riesgo sean explicables, lo que impulsa la investigación hacia enfoques que ofrezcan un mayor control y comprensión del proceso de inferencia.
Finalmente, la sostenibilidad y la equidad en el acceso a esta tecnología son preocupaciones crecientes. El entrenamiento de estos modelos requiere una cantidad ingente de recursos computacionales, lo que concentra su desarrollo en un puñado de grandes corporaciones y naciones con los medios para afrontar estos costos. Esta concentración de poder tecnológico podría exacerbar las desigualdades globales, creando una nueva brecha digital entre quienes tienen acceso a las herramientas de IA más avanzadas y quienes no. Abordar estos desafíos requerirá un esfuerzo concertado que vaya más allá de la ingeniería, involucrando a legisladores, filósofos de la ética y a la sociedad civil en su conjunto.
La revolución silenciosa en el corazón del razonamiento AI
En su esencia, el razonamiento variacional representa un salto cualitativo en la búsqueda de una inteligencia artificial verdaderamente capaz. Al enmarcar el razonamiento como un problema de inferencia probabilística, este enfoque supera las limitaciones de los métodos anteriores y establece un camino más sólido y principiado hacia la construcción de sistemas que piensen, no solo que hablen. La unificación teórica que ofrece no es un mero ejercicio académico; es una brújula que guía el diseño de algoritmos de entrenamiento más eficaces y robustos.
El impacto de este avance se extiende desde lo puramente técnico hasta lo profundamente social. Tecnológicamente, sienta las bases para la creación de agentes de IA autónomos y versátiles, capaces de abordar problemas abiertos en ciencia, ingeniería y más allá. Científicamente, proporciona un lenguaje común para entender y mejorar los mecanismos de razonamiento en los modelos de lenguaje, moviendo el campo de la experimentación empírica hacia una ciencia más predictiva y rigurosa.
Sin embargo, con este gran poder viene una gran responsabilidad. La capacidad de los modelos para razonar de manera convincente y autónoma amplifica tanto sus beneficios potenciales como sus riesgos. Es imperativo que el desarrollo de esta tecnología vaya de la mano de un debate ético y social profundo, que asegure que sus frutos se distribuyan de manera justa y que sus fallos no se conviertan en injusticias sistémicas. La revolución del razonamiento en la IA ya ha comenzado; nuestro desafío colectivo es guiarla hacia un futuro que beneficie a toda la humanidad.
Referencias
Burda, Y., Grosse, R., & Salakhutdinov, R. (2015). Importance weighted autoencoders. arXiv preprint arXiv:1509.00519.
Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q. V., Levine, S., & Ma, Y. (2025). SFT memorizes, RL generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161.
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., … & Zhang, D. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., … & Bi, X. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948.
Hochlehnert, A., Bhatnagar, H., Udandarao, V., Albanie, S., Prabhu, A., & Bethge, M. (2025). A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility. arXiv preprint arXiv:2504.07086.
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., … & Sutskever, I. (2024). OpenAI o1 system card. arXiv preprint arXiv:2412.16720.
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., … & Wu, Y. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., … & Scialom, T. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Zhou, X., Liu, Z., Wang, H., Du, C., Lin, M., Li, C., Wang, L., & Pang, T. (2025). Variational Reasoning for Language Models. arXiv preprint arXiv:2509.22637.

