
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
Introducción panorámica
Hay anuncios que son ruido y hay anuncios que cambian el tablero. El del equipo Qwen de Alibaba pertenece a la segunda categoría. En cuestión de meses, el laboratorio pasó de abrir la familia Qwen3, con versiones abiertas y una arquitectura moderna de mezcla de expertos, a presentar su sistema más ambicioso hasta la fecha: un modelo con más de un billón de parámetros en vista previa comercial, Qwen3-Max-Preview. Al mismo tiempo, consolidó una línea “abierta” que hoy tiene a Qwen3-235B-A22B-2507 como referencia: un modelo de 235 mil millones de parámetros totales, con 22 mil millones activados por token, pensado para desplegarse en la práctica, con ventana de contexto extendida y un rendimiento competitivo. La noticia se resume con una idea sencilla para el lector no especialista: Alibaba está empujando los límites por dos vías coordinadas, una de escala extrema accesible por API y otra de código abierto que puede instalarse en infra propia. Esa combinación apunta a cubrir desde prototipos universitarios hasta entornos empresariales críticos.
Antes de adentrarnos, conviene ordenar dos nombres que circulan juntos pero no son lo mismo. Qwen3-Max-Preview es el nuevo sistema “gigante” de la casa, anunciado con más de 1T parámetros y acceso por Qwen Chat y API de Alibaba Cloud, con foco en velocidad, razonamiento práctico, manejo de contextos largos y casos de uso de agentes. Qwen3-235B-A22B-2507, en cambio, es la versión abierta de 235B totales y 22B activos que el equipo ha publicado en Hugging Face bajo licencia Apache 2.0, entrenada y afinada para seguir instrucciones sin generar trazas de pensamiento explícitas, con mejoras en matemáticas, lógica, código, conocimiento general y comprensión de textos. Es natural que aparezcan juntas en titulares y hilos porque la propia Qwen presenta a Max como la “siguiente marcha” que supera a su tope abierto, pero en producto y gobernanza juegan en ligas distintas: una es servicio, la otra es modelo descargable.
Para lectores sin antecedentes en benchmarks y jerga de arquitecturas, tres piezas bastan para seguir la historia. Primero, “parámetros” son los diales internos del sistema; más cantidad no garantiza calidad, pero amplía la capacidad de representar patrones. Segundo, “mezcla de expertos” significa que no toda la red se activa en cada paso: un enrutador decide qué subconjunto especializado procesa cada token, lo que permite aumentar el total sin multiplicar linealmente el cómputo. Tercero, “ventana de contexto” indica cuánta información puede considerar el modelo de una sola vez: pasar de unos pocos miles de tokens a cientos de miles cambia qué problemas son posibles. Con esos tres ladrillos, se entiende por qué el 1T por API impresiona a la industria y por qué un 235B “abierto” bien afinado resulta tan atractivo para equipos que necesitan control local, costos previsibles y libertad de integración.
Qwen en contexto: una familia con dos carriles
Qwen3 no es un modelo suelto, es una línea completa que nace con una promesa clara: pensar más profundo cuando hace falta y actuar más rápido cuando conviene. En el anuncio técnico, la propia Qwen explicó su enfoque de “modos híbridos” de razonamiento: un modo que produce pasos intermedios para problemas complejos y un modo directo sin trazas para consultas simples, con control de presupuesto de cómputo por tarea. Además, la familia es amplia: dos variantes MoE abiertas —Qwen3-235B-A22B y Qwen3-30B-A3B— y seis densas que van de 0.6B a 32B, con soporte multilingüe extendido y herramientas de despliegue que van de vLLM a SGLang, de Ollama a MLX y llama.cpp para uso local. Para quien toma decisiones tecnológicas, esto no es folclore de laboratorio: es un catálogo de opciones concretas, con rutas de implementación y licencias claras.
Ese doble carril —gigantes por API y abiertos descargables— no es capricho. En empresas que manejan datos sensibles o deben cumplir normativas estrictas, el carril abierto permite ajustar y auditar. En startups que necesitan lo último sin invertir en clusters caros, el carril por API acelera la llegada a producción. Qwen, como otros actores de punta, entendió que la pregunta real de 2025 ya no es “¿modelo cerrado u abierto?”, sino “¿qué mezcla de ambos equilibra valor, costo y riesgo para cada proceso?”. El anuncio del 1T llega para ocupar el extremo de máxima capacidad en ese continuo, mientras el 235B-A22B-2507 consolida el extremo abierto de alto desempeño.
Qwen3-235B-A22B-2507, pieza clave del carril abierto
Empecemos por el caballo de batalla abierto. Qwen3-235B-A22B-2507 usa una arquitectura de mezcla de expertos con 128 expertos y 8 activos por token. Traducido: el modelo “elige” subredes especializadas para cada parte del texto, por lo que mantiene 235B parámetros totales, pero activa un subconjunto equivalente a unos 22B en cada paso. El diseño incluye 94 capas, atención GQA con 64 cabezas de consulta y 4 para claves y valores, y una ventana nativa de 262 mil tokens que puede extenderse hasta alrededor de un millón cuando las condiciones de inferencia lo permiten. A diferencia de las variantes con razonamiento explícito, la edición 2507 está fijada en modo “no-thinking” y evita emitir cadenas de pensamiento, una decisión alineada con quienes buscan salidas más rápidas y consistentes en producción. Todo bajo licencia Apache 2.0, que habilita usos comerciales sin las restricciones de licencias más rígidas.
El rendimiento declarado en su ficha muestra un perfil equilibrado. En conocimiento general, alcanza 83.0 en MMLU-Pro y 93.1 en MMLU-Redux, y sube al 77.5 en GPQA múltiple. En razonamiento matemático y lógico figura con 70.3 en AIME25, 55.4 en HMMT25 y 95.0 en ZebraLogic; en código, 51.8 en LiveCodeBench v6 y 87.9 en MultiPL-E. No hace falta saber qué significa cada sigla para captar la idea: está en la zona alta de la tabla donde compiten sistemas de primer nivel. Como siempre, conviene leer estas cifras como brújula y no como sentencia. Lo relevante para un equipo es si, en su dominio concreto, estas capacidades se traducen en entregas más confiables y menos fricción en la integración.
Más allá de los números, lo distintivo es que Qwen y su ecosistema cuidaron la ruta a producción. Baseten y SGLang publicaron guías y benchmarks “día cero” que muestran cómo servir la variante 235B en FP8 sobre cuatro GPUs H100 con latencias razonables, combinando paralelismo de tensores para la atención y paralelismo de expertos para las capas MoE. La recomendación pragmática: usar FP8 por costo y rendimiento casi equivalente a BF16, y ajustar el tamaño de lote según el perfil de concurrencia de cada servicio. Este tipo de recetas ahorra semanas de ensayo y error a equipos que, en otros tiempos, debían inventar su propia ingeniería de servicio desde cero.
Para quienes se preguntan “qué compro con MoE”, la respuesta corta es amplitud sin pagar todo el cómputo en cada paso. La larga merece una sección aparte.
MoE sin dolor de cabeza: cómo funciona la mezcla de expertos
Imaginemos una red densa clásica como un gran conservatorio donde todos los músicos tocan siempre, aunque la partitura requiera solo un cuarteto. MoE cambia la regla: existe una orquesta enorme de “expertos” y, para cada fragmento del texto, un director de orquesta, el enrutador, decide qué músicos deben tocar. Así se gana versatilidad y se reduce el costo por inferencia. Los detalles prácticos importan: el enrutamiento debe ser estable para no producir resultados erráticos, la carga por GPU se reparte con cuidado para no ahogar la comunicación entre dispositivos y el entrenamiento debe evitar que algunos expertos queden infrautilizados. El resultado, cuando se implementa bien, es un motor que parece “más grande” de lo que cuesta ejecutar, capaz de mantener especializaciones internas sin saturarlo todo en cada token. Las notas técnicas públicas sobre Qwen3 explican estos principios en términos accesibles y muestran configuraciones típicas de 128 expertos con 8 activos por token, justo la receta del 235B-A22B.
El reverso de MoE es que todavía exige memoria para almacenar a toda la orquesta, incluso si solo suena un subconjunto en cada paso. Por eso los despliegues suelen combinar trucos de precisión numérica, sharding y cacheo de contexto para mantener latencias bajas. La buena noticia es que esa ingeniería dejó de ser artesanal. Hoy existen frameworks y guías de referencia que descomprimen el costo cognitivo de servir estos modelos a escala.
Qué aporta Qwen3-Max-Preview de 1T en el carril de servicio
Volvamos al nuevo protagonista. Qwen3-Max-Preview no llega como PDF académico, llega como servicio disponible hoy en Qwen Chat y API de Alibaba Cloud. Es un sistema de más de 1T parámetros que, según datos compartidos por el propio equipo y recogidos por la prensa tecnológica, supera a Qwen3-235B-A22B-2507 en pruebas internas y compite con la primera línea del mercado en tareas de conversación, instrucciones complejas, razonamiento práctico, código y agentes. La ventana de contexto ronda los 262K tokens con salidas de hasta 32K, y el proveedor acompaña el lanzamiento con cacheo de contexto y precios por tramos, lo que sugiere que el objetivo no es solo marcar un récord de parámetros, sino ofrecer un servicio con latencias y costos racionales. No es open source y, por ahora, se accede por API o socios de distribución. Para muchos casos de uso, esa vía resulta suficiente y hasta preferible.
VentureBeat, entre otros, subrayó algo interesante: pese a que la versión de vista previa no está “marketinée” como un modelo de razonamiento formal, parte de la comunidad notó que ante desafíos difíciles el sistema organiza respuestas paso a paso y mantiene una estructura ordenada. No es prueba de laboratorio y conviene tomarlo como indicio, no como veredicto, pero revela una tendencia: los gigantes actuales combinan capacidad de escala con una disciplina práctica para tareas compuestas, justo lo que piden agentes que encadenan herramientas, formatos estructurados y consultas largas.
Más allá del asombro por el número, lo relevante para un equipo técnico es el diseño de producto alrededor del 1T. La estructura de precios por tramos, el cacheo de prefijos y la compatibilidad con API estilo OpenAI no son detalles cosméticos. Indican una estrategia de adopción que intenta minimizar fricciones: acelerar migraciones, amortiguar el costo de contextos enormes y mantener predecibles las integraciones vía SDKs conocidos. Si su organización vive de automatizaciones y orquestación, esos elementos pueden valer más en el presupuesto anual que el último punto porcentual en un benchmark.
Entrenamiento a escala y datos: por qué Qwen3 entiende tanto y en tantos idiomas
Detrás del rendimiento de Qwen3 hay entrenamiento masivo. Análisis técnicos públicos describen un corpus de más de 36 billones de tokens, que duplicó el volumen de Qwen2.5, con 119 idiomas y dialectos, y una pipeline en fases: base de 4K de contexto, refuerzo en dominios intensivos como STEM y código, y una etapa de optimización para contextos largos. Aparece, además, el uso de datos sintéticos generados por variantes especializadas en matemáticas y programación, un patrón ya extendido en la industria para reforzar habilidades específicas. El objetivo no es solo subir la escala, sino balancear la dieta del modelo para que no pierda pie cuando el texto se vuelve técnico.
El multilingüismo no es un adorno, es un vector de adopción. Qwen3 declara soporte para más de un centenar de lenguas y variedades, lo que habilita despliegues reales en mercados donde el inglés no es la lengua franca. En la práctica, esto significa que flujos de atención al cliente, soporte técnico o sistemas de búsqueda interna pueden operar sin la fricción constante de traducir todo al inglés para recién después procesar.
Rendimiento en pruebas públicas: brújula, no dogma
El 235B-A22B-2507 muestra un perfil robusto en múltiples familias de pruebas. La ficha oficial en Hugging Face detalla mejoras sustanciales en seguimiento de instrucciones, razonamiento lógico, matemáticas, ciencia, código y uso de herramientas, así como avances en cobertura de conocimiento de cola larga y en tareas subjetivas, donde la alineación con preferencias del usuario es crítica. También recoge resultados en AIME25, HMMT25 y LiveCodeBench, además de comparativas con modelos cerrados de referencia como GPT-4o y variantes de DeepSeek. Se ve un patrón: el 235B abierto disputa la conversación con sistemas comerciales que no se pueden autoalojar, y lo hace con suficiente soltura como para ser opción real en despliegues serios. La lección práctica es no absolutizar un leaderboard, sino ponerlo a trabajar sobre su caso de uso. Si su pipeline es extracción estructurada de PDF, el mejor puntaje en matemática recreativa puede ser irrelevante frente a la consistencia de formato.
De la teoría al rack: cómo servir Qwen3 sin sufrir
Servir un MoE grande dejó de ser arte oscuro. Baseten y SGLang publicaron trayectos de despliegue que combinan paralelismo de tensores para la atención, paralelismo de expertos para las capas MoE y configuraciones recomendadas por precisión. En FP8, un nodo con cuatro H100 alcanza latencias razonables con lotes medios, y en BF16 se escala a ocho GPUs con un coste superior. La clave es tratar el tamaño de lote como dial económico: lotes pequeños bajan latencia pero suben costo por token; lotes grandes optimizan throughput cuando la latencia no es crítica. Esta granularidad permite que la misma infraestructura sirva tanto para endpoints conversacionales como para trabajos batch.
La otra mitad de la ecuación es el contexto. Cuando se trabaja con ventanas de cientos de miles de tokens, cachear prefijos y reusar fragmentos repetidos se vuelve vital. El ecosistema alrededor de Qwen3 ya incorpora estas técnicas, y el propio servicio de Qwen3-Max-Preview expone cacheo de contexto y precios por tramo de entrada para desalentar prompts gigantes innecesarios. Es una manera elegante de alinear incentivos: pague menos si diseña prompts eficientes, pague más si necesita ingerir corpus completos en un solo paso.
Aplicaciones claras para quien no vive de benchmarks
En qué se traduce todo esto para un lector que quiere resolver problemas concretos. Primero, en edición de documentos y contratos, un 235B abierto con 256K de contexto puede comparar versiones, consolidar cambios y explicar diferencias sin cortar texto en pedazos. Segundo, en soporte técnico con bases de conocimiento grandes, el sistema puede leer y cruzar manuales, artículos y tickets largos sin perder el hilo, y hacerlo en el idioma del usuario. Tercero, en analítica de logs y seguridad, la ventana extendida permite resumir sesiones extensas y detectar patrones que antes quedaban ocultos por falta de memoria contextual. Cuarto, en código, el modelo soporta pruebas de integración con múltiples archivos en un solo prompt, útil para refactorizaciones amplias o migraciones de frameworks.
Y si hay que elegir entre el 1T por API y el 235B abierto, la decisión se vuelve menos ideológica y más de proyecto. Si su producto necesita lo último en conversación abierta, razonamiento y agentes, con picos de tráfico y sin restricciones duras de soberanía de datos, Qwen3-Max-Preview brilla. Si su prioridad es control local, costos previsibles y capacidad de auditar, Qwen3-235B-A22B-2507 ofrece una ruta madura.
Dos decisiones operativas que ayudan a no perderse
- Si la información es sensible o regulada, empiece por el 235B abierto en infraestructura propia, establezca métricas de calidad y recién luego compare contra el 1T por API con datos anonimizados.
- Si el cuello de botella es velocidad de entrega y no hay restricciones fuertes, prototipe con el 1T por API y diseñe desde el primer día prompts y cadenas de herramientas que puedan migrarse a un modelo abierto sin reescribir todo.
Lo que cambia con contextos ultra largos
Durante años nos acostumbramos a fragmentar. Partir una licitación en secciones, dividir un expediente en documentos, trocear una base de código en módulos. No era un gusto estético, era una obligación técnica. Con ventanas de cientos de miles de tokens, la estrategia cambia. Ahora es posible pedirle a un sistema que lea varias versiones de un proyecto, entienda dependencias entre archivos y produzca un plan de refactorización coherente sin pérdida de estado entre cortes. O que, ante un litigio, conecte alegatos, pruebas y doctrina en un mismo pasaje sin necesidad de coser resúmenes parciales. Conviene no romantizar: una ventana enorme no reemplaza criterio humano ni control de calidad, pero amplía el espacio de maniobra y reduce errores por fragmentación. Qwen3, tanto en su ruta abierta como en la comercial, está optimizado para ese mundo de entradas extensas.
Gobernanza, sesgos y el problema práctico de la alineación
El 235B-A22B-2507 declara mejor alineación en tareas subjetivas y abiertas. Traducido: produce salidas más útiles cuando el pedido no tiene única respuesta correcta. Es un excelente objetivo, pero introduce desafíos de evaluación. ¿Qué significa “mejor” cuando varias salidas son plausibles? La ficha del modelo adopta pruebas como WritingBench o Arena-Hard para estimar preferencia, y reporta avances. A nivel operativo, esto se complementa con control de temperatura, penalizaciones de presencia y otras palancas de muestreo que el propio equipo recomienda. En producción, la receta madura combina alineación genérica con una capa de verificación específica al dominio: evaluadores automáticos para formato, chequeras de reglas, tests de seguridad, y cuando corresponde, revisión humana de alto impacto. Nadie quiere que el entusiasmo por un 1T eufórico se traduzca en texto elegante que falla en lo esencial: cumplir una política, adherir a un formato, respetar una regulación.
Economía del despliegue: dónde está el costo realmente
Un presupuesto técnico no se agota en “precio por millón de tokens”. Hay costos de ingeniería, de seguridad, de mantenimiento y de riesgo. En el carril abierto, la inversión recae en infraestructura y MLOps: cómo servir, cómo monitorear, cómo actualizar sin romper. A cambio, se gana control, previsibilidad y libertad contractual. En el carril de servicio, el precio por tramos y el cacheo de contexto ayudan a mantener cuentas bajo control, pero la organización queda atada a ventanas de disponibilidad, políticas de uso y evolución de producto del proveedor. La novedad de Qwen3-Max-Preview es que asume explícitamente este juego y publica estructuras de precio acordes a tamaños de prompt, con cacheo para abaratar prefijos repetidos. Ese tipo de transparencia operativa vale tanto como un decimal más en un leaderboard.
Competencia y paisaje estratégico
Qwen no aparece en vacío. El anuncio del 1T se inscribe en una carrera donde conviven estrategias de compactación, motores de razonamiento “pensantes”, y despliegues mixtos. En ese paisaje, la apuesta de Alibaba combina escala extrema por servicio con un carril abierto muy competitivo. El 235B abierto se midió bien frente a modelos comerciales fuertes y, según análisis de terceros, rivaliza con sistemas de razonamiento de mayor coste, incluso con requerimientos de hardware más bajos, como las configuraciones de 4 H100. El 1T, por su parte, llega para pelear conversaciones difíciles, agentes, código y contextos extensos con agresividad. Son dos piezas de un mismo rompecabezas: cobertura amplia de casos con caminos de adopción claros.
Guía rápida de adopción para equipos no obsesionados con el SOTA
Si usted dirige una redacción, una oficina legal, un área de atención al cliente o un equipo de ingeniería que necesita resultados ya, piense en capas. Empiece por procesos que toleren supervisión y que ganen con ventanas largas: conciliación de documentos, consolidación de versiones, sumarios de expedientes, lectura cruzada de normas. Llévelos a Qwen3-235B-A22B-2507 en open source y mida calidad, velocidad y costo. En paralelo, pilotee con Qwen3-Max-Preview funciones que dependan de razonamiento compuesto, agentes y formatos estructurados, midiendo impacto y latencia. Si el producto despega y hay presupuesto, consolide en el carril más conveniente según riesgos y contratos. No es una carrera de pureza ideológica. Es ingeniería aplicada a resultados.
Una aclaración necesaria sobre nombres y cifras
Dado que el ciclo de anuncios fue vertiginoso, es normal encontrar titulares que mezclan la noticia del 1T con el 235B. Vale la síntesis precisa: Qwen3-Max-Preview es el modelo de más de 1T de parámetros, disponible por API en vista previa y posicionado por Qwen como su sistema más grande hasta ahora. Qwen3-235B-A22B-2507 es la edición abierta de 235B totales y 22B activos por token, con mejoras de julio de 2025, no “el 1T”. Si ve ambos nombres en el mismo hilo, casi seguro están comparando el salto de rendimiento del nuevo servicio frente al mejor modelo abierto de la casa. Conviene retener esta distinción para leer bien qué se promete y qué se puede instalar hoy en su infraestructura.
Epílogo técnico: por qué esto importa más allá de un número
Los parámetros importan por lo que permiten, no por lo que lucen. Un 1T útil no es el que recita manuales, sino el que entrega decisiones paso a paso, se lleva bien con herramientas externas, respeta formatos y aguanta sesiones largas sin perder la trama. Un 235B abierto valioso no es el que gana un gráfico, sino el que puede auditarse, adaptarse y escalar dentro de límites presupuestarios razonables. El aporte de Qwen esta temporada es haber empujado ambos frentes a la vez, con una familia que no se agota en el póster del anuncio y que documenta rutas concretas de despliegue. Para quienes trabajamos en tecnología aplicada, es una buena noticia. Reduce la distancia entre lo que la industria promete y lo que las organizaciones pueden hacer mañana a las 9 de la mañana.
Síntesis reflexiva
El lanzamiento del 1T de Qwen, junto con la consolidación de Qwen3-235B-A22B-2507 en el carril abierto, no es solo una carrera de tamaño. Es una estrategia coherente para cubrir necesidades reales: razonamiento práctico, contextos extensos, multilingüismo, costos controlables y caminos de adopción claros. En un ecosistema saturado de siglas, la conversación importante se desplaza hacia preguntas sencillas: ¿resuelve mi proceso?, ¿puedo integrarlo sin reescribir el mundo?, ¿cuánto cuesta operar el mes tres y el mes nueve?, ¿qué pasa con mis datos? La oferta dual de Qwen permite responder con matices. Si la prioridad es potencia instantánea sin levantar hierro, el 1T por API es una herramienta poderosa. Si el centro es control local y previsibilidad, el 235B abierto es una base sólida y sorprendentemente capaz. Vivimos un momento en el que el tamaño vuelve a importar, sí, pero solo cuando llega de la mano de ingeniería de producto y rutas de despliegue que no rompen los presupuestos ni los nervios. En esa combinación, la jugada de Alibaba se siente menos como un golpe de efecto y más como la arquitectura de una nueva normalidad.
Precios:
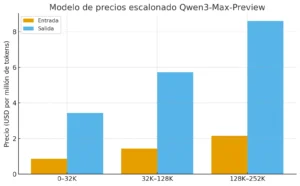
Alibaba Cloud ha lanzado un modelo de precios escalonado para Qwen3-Max-Preview, en el que los costos varían según la cantidad de tokens de entrada utilizados:
-
0–32K tokens: USD 0,861 por cada millón de tokens de entrada y USD 3,441 por cada millón de tokens de salida.
-
32K–128K tokens: USD 1,434 por cada millón de tokens de entrada y USD 5,735 por cada millón de tokens de salida.
-
128K–252K tokens: USD 2,151 por cada millón de tokens de entrada y USD 8,602 por cada millón de tokens de salida.
La idea es que los prompts más pequeños resultan más baratos, mientras que los trabajos más grandes escalan en costo.
Fuentes
Alibaba Cloud Qwen Team. (2025, 29 de abril). Qwen3: Think Deeper, Act Faster [Entrada de blog]. Qwen. https://qwenlm.github.io/blog/qwen3/
Qwen. (s. f.). Qwen3-235B-A22B-Instruct-2507 [Model card]. Hugging Face. https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
Tuluk, U. E. (2025, 22 de julio). Qwen3-235B-A22B-Instruct-2507: Alibaba’s Updated 235B-Parameter Instruction-Tuned LLM. RITS, NYU Shanghai. https://rits.shanghai.nyu.edu/ai/qwen3-235b-a22b-instruct-2507-alibabas-updated-235b-parameter-instruction-tuned-llm/
Franzen, C. (2025, 5 de septiembre). Qwen3-Max arrives in preview with 1 trillion parameters, blazing fast response speed, and API availability. VentureBeat. https://venturebeat.com/ai/qwen3-max-arrives-in-preview-with-1-trillion-parameters-blazing-fast
Paul, R. (2025, 5 de septiembre). Alibaba’s Qwen team just launched its BIGGEST model yet (1T+ parameter). Rohan’s Bytes. https://www.rohan-paul.com/p/alibabas-qwen-team-just-launched
Zhang, Y., Feil, M., & Kiely, P. (2025, 19 de mayo). Day zero benchmarks for Qwen 3 with SGLang on Baseten. Baseten. https://www.baseten.co/blog/day-zero-benchmarks-for-qwen-3-with-sglang-on-baseten/
Sivamani, V. (2025, 28 de agosto). Mixture of Experts explained. Understanding MOEs in Qwen3–30B-A3B. Medium. https://medium.com/@varunsivamani/mixture-of-experts-explained-b36591f936a9
CometAPI. (2025, 29 de mayo). Decoding Qwen3’s Training: A Deep Dive. https://www.cometapi.com/decoding-qwen3s-training-a-deep-dive/
QwenLM. (s. f.). Qwen3 [Repositorio]. GitHub. https://github.com/QwenLM/Qwen3

