
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
Prophet Arena: El Nuevo Benchmark que Pone a Prueba la Inteligencia Predictiva de la IA en Eventos Reales
En un mundo donde la inteligencia artificial (IA) ya supera a los humanos en tareas como el reconocimiento de imágenes o el juego de ajedrez, surge una pregunta crucial: ¿puede la IA predecir el futuro mejor que nosotros? Prophet Arena, un innovador benchmark lanzado recientemente, busca responder a esto evaluando la «inteligencia predictiva» de modelos de IA mediante pronósticos en eventos reales y en tiempo real, desde elecciones políticas hasta resultados deportivos. A diferencia de benchmarks tradicionales como GLUE o MMLU, que usan datos históricos con respuestas conocidas, Prophet Arena se basa en eventos no resueltos, extraídos de mercados de predicción como Kalshi, para evitar sesgos y medir la capacidad real de razonar bajo incertidumbre.
Desarrollado por un equipo de investigadores en IA, el proyecto se presenta como el «próximo frontier» de la evaluación tecnológica, enfatizando el forecasting como una habilidad esencial para la IA general (AGI). «El forecasting no es solo predecir; es conectar información existente para anticipar lo impredecible», explica el blog de lanzamiento de Prophet Arena, destacando su potencial para aplicaciones en finanzas, política y ciencia. Con un leaderboard en vivo y métricas que combinan precisión estadística con rentabilidad simulada, este benchmark podría revolucionar cómo medimos el progreso de la IA, especialmente en un 2025 donde modelos como Grok-4, DeepSeek R1 y Llama 4 Scout compiten por dominar tareas complejas.
¿Cómo Funciona Prophet Arena? Un Pipeline para Predecir el Mundo Real
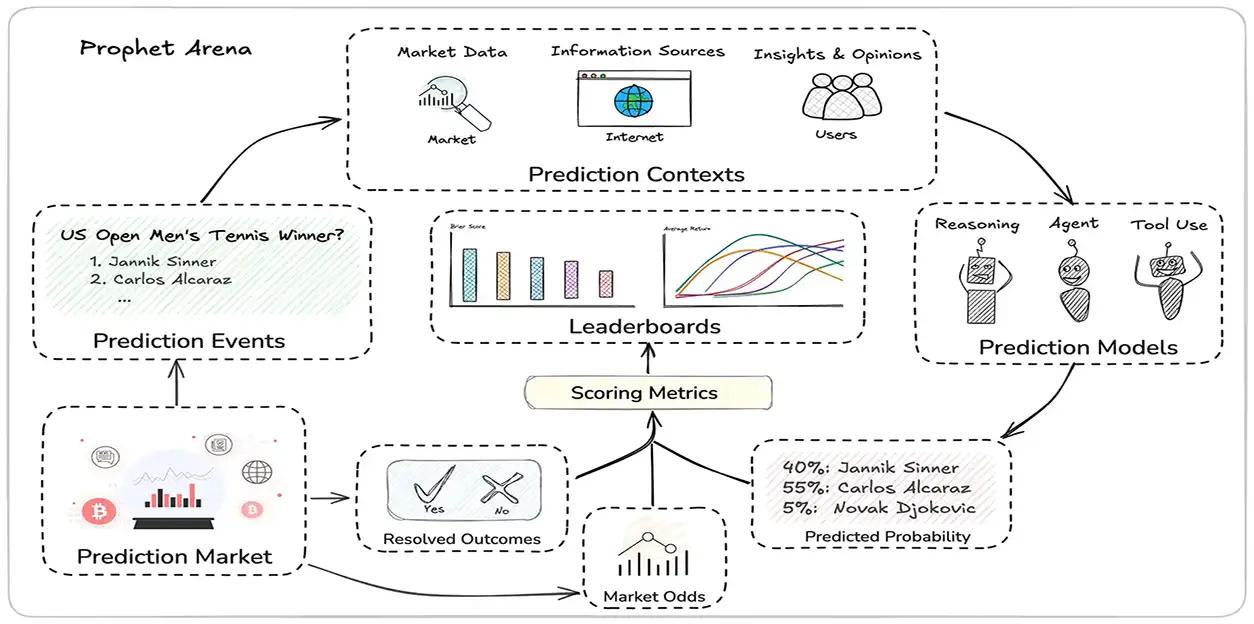
El diseño de Prophet Arena es elegante y práctico, estructurado en un pipeline de tres etapas que simula un proceso de forecasting humano-IA colaborativo. Primero, se recopila información relevante: noticias, datos de mercados de predicción y contexto histórico sobre eventos no resueltos. Estos se curan manualmente para diversidad —cubriendo política, economía, ciencia, deportes y entretenimiento— y se priorizan por popularidad y recurrencia, asegurando un flujo constante de desafíos.
En la segunda etapa, los modelos de IA reciben prompts con esta información y deben generar predicciones probabilísticas, acompañadas de un razonamiento detallado. Por ejemplo, una pregunta podría ser: «¿Ganará el equipo de Toronto FC contra San Diego FC?», donde la IA asigna porcentajes (e.g., 30% para victoria de Toronto) basados en análisis de datos recientes. Esto fomenta no solo la precisión, sino también la explicación lógica, permitiendo a humanos intervenir con feedback o fuentes adicionales.
Finalmente, una vez resuelto el evento, se evalúa el rendimiento. Aquí radica la innovación: métricas absolutas como el Brier Score (que mide calibración y precisión, con puntuación de 1 como perfecta) se combinan con relativas como Average Return, que simula apuestas en mercados virtuales. Un modelo con alto Brier Score no siempre genera alto retorno; depende de su «actitud al riesgo». Por instancia, predicciones conservadoras pueden ser precisas pero poco rentables, mientras que apuestas agresivas en underdogs (como un 40% de probabilidad en un evento con odds de mercado del 11%) pueden maximizar ganancias si aciertan.
El benchmark aborda problemas crónicos en evaluaciones de IA, como la contaminación de datos (overfitting): al usar eventos futuros, impide que modelos «aprendan» respuestas preexistentes. Además, su enfoque probabilístico mide no solo aciertos, sino calibración —evitando modelos que sobrestimen o subestimen riesgos— y utiliza Item Response Theory y modelos Bradley-Terry para rankings profundos.
Hallazgos Iniciales: Modelos de IA Muestran Fortalezas y Sesgos en Predicciones
Datos recolectados hasta el 11 de agosto de 2025 revelan insights fascinantes. En una muestra de miles de predicciones, modelos como o3-mini destacan en Average Return (e.g., ganando $9 por $1 apostado en un partido de fútbol), mientras que GPT-4o y GPT-4.1 brillan en razonamientos matizados, ajustando probabilidades por factores como empates o noticias de último minuto. DeepSeek R1 y Llama 4 Scout dominan en bins de Brier Score medio (0.4-0.5), a menudo con predicciones «all-zeros» en escenarios inciertos, mostrando una «postura de riesgo» conservadora pero efectiva en upsets deportivos.
Correlaciones entre modelos varían: Grok-4 y GPT-5 se alinean estrechamente (distancia L2 <0.3), pero DeepSeek R1 diverge (>0.7), sugiriendo enfoques únicos en procesamiento de incertidumbre. En eventos políticos, como regulaciones de IA antes de 2026, Qwen 3 asigna 75% de probabilidad vs. 35% de Llama 4 Maverick, reflejando diferencias en peso a mercados vs. noticias. Globalmente, modelos superan baselines de mercado en 72-80% de eventos, pero pierden más a menudo —ganancias dependen de «edge» en magnitudes.
Estos resultados preliminares, no consejo de inversión, indican que la IA ya rivaliza con humanos en forecasting, pero con sesgos: algunos son demasiado optimistas, otros evitan riesgos. Como nota el blog, «El forecasting resuelve contaminación de benchmarks al usar eventos irresueltos».
Implicaciones para el Futuro de la IA: Colaboración Humano-Máquina y Más Allá
Prophet Arena va más allá de la evaluación: facilita colaboración, con interfaces interactivas donde humanos preguntan «cómo es probable que suceda esto» y reciben explicaciones. Planes futuros incluyen soporte para agentes IA autónomos, herramientas para sugerir fuentes y métricas avanzadas para AGI. Comparado con benchmarks como MIRAI o RealityBench, se destaca por su énfasis en pronósticos estadísticos y eventos reales, posicionándolo como herramienta para investigación en AI alignment y policy-making.
Expertos como Nick Bostrom (autor de Superintelligence) ven en estos benchmarks un paso hacia IA «útil pero segura», midiendo no solo inteligencia, sino foresight. En un año donde la IA genera titulares —de Grok-4 a regulaciones chinas—, Prophet Arena invita a desarrolladores a probar modelos en su leaderboard vivo, explorando si la IA puede «predecir el futuro, no solo procesar el pasado».
¿Podrá la IA superar a los humanos en predecir elecciones 2026 o mercados volátiles? Prophet Arena está aquí para descubrirlo.

