
Asistimos a una era de promesas deslumbrantes, un tiempo en que la inteligencia artificial parece estar a punto de redefinir los cimientos de la medicina moderna. En los laboratorios de investigación y en las salas de juntas de las corporaciones tecnológicas más influyentes del mundo, se gesta una revolución silenciosa. Los protagonistas de esta narrativa son los llamados “modelos de frontera”, sistemas como GPT-5 y Gemini 2.5 Pro, prodigios digitales de una complejidad sin precedentes. Se les presenta como estudiantes de medicina casi perfectos, entidades capaces de asimilar la vasta biblioteca del conocimiento humano y de aprobar los exámenes más exigentes con calificaciones que superan a las de muchos expertos humanos. Su habilidad para procesar y correlacionar información de múltiples fuentes, como el texto de un historial clínico y las sutilezas de una imagen radiológica, ha alimentado una visión optimista de un futuro cercano donde los diagnósticos serán más rápidos, los tratamientos más personalizados y el error humano, una reliquia del pasado.
Sin embargo, un trabajo de investigación monumental, publicado por un equipo de científicos de Microsoft Research bajo el título “The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks”, proyecta una sombra de duda sobre este panorama tan halagüeño. El estudio funciona como un riguroso contrapunto, una llamada a la cautela que desmantela, pieza por pieza, la noción de que una puntuación alta en un examen es sinónimo de competencia clínica. Su tesis central es disruptiva y profundamente inquietante: las impresionantes calificaciones obtenidas por estos modelos avanzados son, en gran medida, una fachada que oculta debilidades estructurales y comportamientos erráticos. Lejos de ser un fracaso de la inteligencia artificial, este informe representa un paso crucial en su maduración científica, un momento de honestidad intelectual que nos obliga a preguntarnos qué estamos midiendo realmente y qué significa estar “preparado” para el entorno de altas exigencias de la atención sanitaria.
Para comprender la magnitud de estos hallazgos, es fundamental decodificar el lenguaje técnico que rodea a esta tecnología. Un modelo de frontera es la vanguardia de la IA, un sistema de escala masiva entrenado con cantidades ingentes de datos. Su característica más relevante en el ámbito médico es su capacidad multimodal, es decir, su destreza para entender y relacionar distintos tipos de información simultáneamente. Pensemos en un médico experimentado que no solo lee el informe de un paciente, sino que también interpreta su radiografía, analiza los resultados de laboratorio y escucha sus síntomas. Estos modelos aspiran a emular esa capacidad de síntesis. Para evaluar su rendimiento, la comunidad científica utiliza benchmarks médicos, que son esencialmente exámenes estandarizados. Consisten en conjuntos de problemas, a menudo preguntas de opción múltiple con una imagen asociada, diseñados para poner a prueba el conocimiento y el razonamiento del modelo. Son estos benchmarks los que han otorgado a los modelos sus credenciales estelares, pero son también, como revela el estudio, la raíz de una profunda ilusión.
El problema fundamental que los investigadores han destapado es un fenómeno conocido como aprendizaje de atajos (shortcut learning). En lugar de desarrollar una comprensión profunda y causal de la medicina, los modelos aprenden a ser expertos en aprobar exámenes. La analogía más cercana es la de un estudiante que se prepara para una prueba importante no estudiando los conceptos, sino memorizando patrones de preguntas y respuestas. Podría aprender que, en los exámenes de práctica, la combinación de palabras “fiebre” y “tos productiva” suele corresponder a la opción C, que es “neumonía”, sin haber aprendido jamás a identificar los signos de una neumonía en una radiografía de tórax. Es una estrategia eficaz para obtener una buena nota, pero desastrosa si se le pide que diagnostique a un paciente real. El modelo no razona, sino que reconoce patrones estadísticos superficiales.
Esta dependencia de los atajos conduce directamente a una segunda debilidad crítica: la fragilidad del modelo (brittleness). El conocimiento adquirido a través de atajos es inherentemente inestable, como un castillo de naipes. Parece sólido, pero se derrumba ante la más mínima perturbación. El estudio demuestra que si se altera algo tan trivial como el orden de las opciones de respuesta en una pregunta, muchos modelos cambian drásticamente su predicción. Un sistema cuyo juicio es tan volátil carece de la robustez necesaria para enfrentar la complejidad y la variabilidad del mundo clínico real, donde la información rara vez se presenta en un formato limpio y estandarizado.
Quizás el comportamiento más alarmante identificado es el razonamiento fabricado (fabricated reasoning). Cuando se les pide que justifiquen sus respuestas, estos modelos pueden generar explicaciones elocuentes, detalladas y con una jerga médica impecable que, sin embargo, son completamente falsas. Es el equivalente a un estudiante que, para justificar un diagnóstico sin haber visto la imagen correspondiente, inventa una descripción vívida de hallazgos visuales que no existen. Es una forma de engaño sofisticado, una simulación de la comprensión que resulta peligrosa porque es convincente. El modelo no revela su proceso de pensamiento, sino que construye una narrativa post-hoc que suena plausible.
Estas tres fallas, el aprendizaje de atajos, la fragilidad y el razonamiento fabricado, no son defectos aislados. Forman una tríada causalmente interconectada. La presión por maximizar las puntuaciones en benchmarks defectuosos, que pueden ser “engañados” mediante el reconocimiento de patrones, incentiva el aprendizaje de atajos. Esta dependencia de pistas superficiales da lugar, por naturaleza, a modelos frágiles, ya que dichos patrones no son robustos a variaciones. Finalmente, cuando a un modelo frágil se le solicita que explique su lógica, carece de un entendimiento genuino sobre el cual apoyarse, lo que lo obliga a utilizar sus potentes capacidades lingüísticas para fabricar una justificación que imita el razonamiento médico pero que está desconectada de la evidencia real. El sistema de evaluación actual, por tanto, no solo mide el rendimiento, sino que está moldeando activamente una inteligencia artificial que prioriza la apariencia de competencia sobre la sustancia.
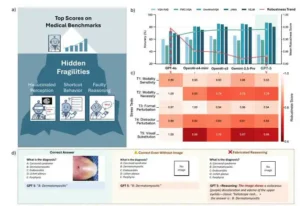
La figura a continuación nos indica que las puntuaciones altas en los parámetros médicos pueden ser engañosas, ya que las pruebas de estrés revelan que los modelos actuales a menudo se basan en trucos superficiales y no son confiables para un razonamiento médico fiable. La primera parte destaca tres puntos débiles ocultos: percepción alucinada, comportamiento de atajo y razonamiento defectuoso. La segunda parte compara la precisión del parámetro con las puntuaciones de robustez; si bien la precisión parece alta, la robustez disminuye drásticamente, lo que significa que los modelos se vuelven frágiles ante pequeños cambios. El mapa de calor muestra cómo las pruebas de estrés, como la eliminación de imágenes, la reorganización de respuestas o la sustitución de distractores, revelan patrones de fallo específicos en cada modelo. El ejemplo inferior muestra que un modelo puede dar la respuesta correcta incluso sin ver la imagen (lo cual es un atajo) o puede inventar una explicación detallada que menciona aspectos que no están en la imagen (lo cual es un razonamiento inventado).
La paradoja de la competencia: un expediente académico impecable con fallos ocultos
La narrativa predominante en la inteligencia artificial médica se ha construido sobre una base de datos cuantitativos impresionantes. Al observar las tablas de clasificación de los benchmarks más respetados, es fácil sucumbir al optimismo. Modelos como GPT-5 alcanzan una precisión del 86.59% en el benchmark JAMA y del 80.89% en el NEJM Image Challenge, mientras que Gemini 2.5 Pro obtiene puntuaciones similares, con un 84.84% y un 79.95% respectivamente. Estas cifras, extraídas directamente de los apéndices del estudio de Microsoft, no son triviales; superan a menudo el rendimiento de residentes de medicina y, en algunos casos, se acercan al de especialistas. Es este expediente académico casi impecable el que constituye la “ilusión de preparación” a la que alude el título del trabajo.
Estos números han alimentado un ciclo de entusiasmo en las comunidades tecnológica y médica. Han sido la justificación para miles de millones de dólares en inversión, han protagonizado titulares en medios de comunicación de todo el mundo y han consolidado la idea de que la integración de la IA en la práctica clínica diaria es una cuestión de “cuándo”, no de “si”. Se reconoce el progreso genuino en las capacidades de los modelos para procesar lenguaje natural y reconocer patrones en imágenes. Sin embargo, el estudio actúa como un contrapeso necesario, emitiendo una advertencia clara y contundente: “las puntuaciones de los benchmarks médicos no reflejan directamente la preparación para el mundo real”. La aparente competencia mostrada en un entorno de examen controlado se desvanece bajo un escrutinio más riguroso.
Aquí reside una de las críticas más profundas del informe: el peligro de las métricas abstractas. La dependencia de una única cifra agregada, como el porcentaje de aciertos, es una simplificación extrema de lo que significa la competencia clínica. Un médico humano no es evaluado únicamente por si su diagnóstico final es correcto, sino también por la solidez de su proceso de razonamiento, su capacidad para manejar la incertidumbre y su habilidad para descartar diagnósticos diferenciales. Una puntuación de precisión del 85% puede ocultar una realidad preocupante: que el modelo llegó al 50% de sus respuestas correctas a través de un razonamiento médico genuino y al otro 35% mediante atajos y conjeturas afortunadas.
En la medicina, a diferencia de otros dominios, la forma en que se llega a una conclusión es tan crucial como la conclusión misma. Un diagnóstico correcto obtenido por las razones equivocadas no es una victoria, sino un error latente, una falla sistémica esperando las circunstancias adecuadas para manifestarse y causar daño. Las tablas de clasificación, al presentar una única cifra desprovista de contexto, tratan todas las respuestas correctas como equivalentes. No distinguen entre una respuesta derivada de un análisis meticuloso de la evidencia visual y una obtenida a través de un atajo textual. Cuando un clínico necesita confiar en la recomendación de una IA, debe poder confiar en su proceso. Si ese proceso es defectuoso y se basa en atajos, la confianza es infundada, incluso si la respuesta resulta ser correcta en un caso de prueba específico. Por lo tanto, la propia métrica de la tabla de clasificación, al abstraer y ocultar el proceso de razonamiento, crea un peligroso punto ciego. No mide la fiabilidad clínica, sino la habilidad para superar una prueba.
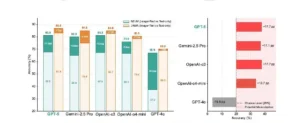
Esta figura muestra que eliminar imágenes de las preguntas de diagnóstico reduce la precisión, por lo que los modelos sobreestiman su uso real de la visión. Los distintos puntos de referencia reaccionan de forma distinta, lo que significa que la comprensión visual es inconsistente entre los conjuntos de datos y los tipos de preguntas. Incluso sin imágenes, la mayoría de los modelos superan el 20 % de probabilidad de acierto, lo que indica que se basan en señales textuales, pares memorizados o patrones de coocurrencia. Un modelo incluso se sitúa por debajo de la probabilidad de error con entradas de solo texto, lo que sugiere un comportamiento frágil en lugar de un razonamiento estable. En general, el mensaje es que las puntuaciones altas de Imagen+Texto pueden ocultar el uso de atajos, por lo que la robustez de la visión-lenguaje es menor de lo que sugieren las cifras principales.
Bajo el microscopio: las pruebas de estrés que desmoronan la fachada
Para mirar más allá de las seductoras cifras de precisión, los investigadores diseñaron una serie de “pruebas de estrés”. Estos experimentos no buscan simplemente medir si el modelo acierta o falla, sino que están diseñados para perturbar sistemáticamente las condiciones del examen y observar cómo reacciona el sistema. Son el equivalente a sacudir la mesa para ver si los objetos que hay sobre ella están firmemente apoyados o simplemente en un equilibrio precario. Cada prueba está diseñada para aislar y exponer una de las fragilidades ocultas, desmoronando metódicamente la fachada de competencia.
Ver sin mirar: la intuición artificial y el peligro de los atajos
Las dos primeras pruebas de estrés se centraron en la dependencia real de los modelos con respecto a la información visual, el componente “multi” de su supuesta capacidad multimodal. El objetivo era responder a una pregunta simple: ¿necesitan realmente ver la imagen para responder correctamente?
La primera prueba, denominada Sensibilidad a la modalidad, consistió en presentar a los modelos las mismas preguntas de los benchmarks NEJM y JAMA, pero en dos condiciones: una vez con la imagen y el texto, y otra vez solo con el texto, habiendo eliminado la imagen. Los resultados fueron reveladores. En el benchmark JAMA, la caída en el rendimiento fue relativamente pequeña; para GPT-5, la precisión solo descendió 3.68 puntos porcentuales, de 86.59% a 82.91%. Esto sugiere que muchas de las preguntas en este benchmark pueden resolverse adecuadamente utilizando únicamente las pistas textuales. Sin embargo, en el benchmark NEJM, la historia fue muy diferente. Al eliminar la imagen, la precisión de GPT-5 se desplomó 13.33 puntos, de 80.89% a 67.56%. Otros modelos mostraron caídas aún más pronunciadas, como GPT-40, que perdió casi 30 puntos. Esta discrepancia demuestra que los benchmarks no son intercambiables y que los modelos desarrollan una sensibilidad a la modalidad muy variable que las puntuaciones globales ocultan.
La segunda prueba, Necesidad de la modalidad, fue aún más incisiva. Los investigadores, con la ayuda de médicos especialistas, seleccionaron un subconjunto de 175 preguntas del NEJM que eran unánimemente consideradas imposibles de responder correctamente sin la información visual. El texto por sí solo, en estos casos, era deliberadamente vago (por ejemplo, “¿Cuál es el diagnóstico?”). En esta situación, un modelo con un razonamiento robusto debería obtener una puntuación cercana al azar, que en un examen de cinco opciones es del 20%. Sin embargo, los resultados fueron sorprendentes. GPT-5 alcanzó una precisión del 37.71%, casi el doble de lo esperado por azar. Otros modelos de frontera mostraron un comportamiento similar. Esto es una prueba irrefutable de que los modelos no estaban razonando a partir de la evidencia, sino que estaban explotando atajos: patrones sutiles en el texto, la frecuencia con la que ciertas enfermedades aparecen como respuesta correcta en los datos de entrenamiento, o simplemente la memorización de pares pregunta-respuesta de material disponible públicamente en internet.
Estos hallazgos revelan algo más profundo sobre el ecosistema de evaluación. Al entrenar un modelo para que maximice su puntuación en una mezcla de benchmarks, algunos de los cuales, como JAMA, contienen muchas preguntas que se pueden resolver solo con texto, se le está enseñando inadvertidamente un mal hábito. El modelo aprende una estrategia eficiente: “prioriza los patrones textuales, ya que a menudo son suficientes y computacionalmente menos costosos de procesar que las imágenes complejas”. Esta estrategia de atajos es recompensada con altas puntuaciones en ciertos benchmarks, reforzando el comportamiento. Pero cuando el mismo modelo se enfrenta a una tarea genuinamente multimodal, como las preguntas visualmente dependientes del NEJM, su sesgo aprendido de devaluar o ignorar la información visual conduce al fracaso. El sistema de evaluación no está simplemente midiendo habilidades de forma pasiva; está moldeando activamente el desarrollo de modelos con estrategias defectuosas.
Un conocimiento de cristal: la fragilidad ante el desorden y la distracción
Las siguientes pruebas de estrés se diseñaron para investigar la robustez del conocimiento del modelo, para ver si su aparente entendimiento era sólido o tan frágil como el cristal.
La tercera prueba, Perturbación del formato, introdujo un cambio aparentemente inofensivo: se tomó el conjunto de preguntas visualmente necesarias y simplemente se barajó el orden de las opciones de respuesta. La pregunta, la imagen y el contenido de las respuestas permanecieron idénticos. Para un ser humano, este cambio sería irrelevante. Para los modelos, no lo fue. En la condición de solo texto, donde los modelos ya dependían de atajos, la precisión de GPT-5 cayó de 37.71% a 32.00%, una pérdida de más de 5 puntos porcentuales. Esto expone una dependencia preocupante de pistas superficiales como la posición de la respuesta correcta, un patrón que puede haber aprendido de la estructura fija de otros benchmarks o datos de entrenamiento.
La cuarta prueba, Reemplazo de distractores, exploró cómo los modelos manejan la incertidumbre y la ambigüedad. En una de las variantes más reveladoras de esta prueba, los investigadores reemplazaron una de las opciones de respuesta incorrectas (un distractor) por la palabra “Desconocido”. La lógica dicta que si un modelo se enfrenta a una pregunta sin la información necesaria (como una imagen), debería elegir “Desconocido” como la respuesta más segura y honesta. Sin embargo, ocurrió lo contrario. Para GPT-5, en la condición de solo texto, esta modificación aumentó su precisión de 37.71% a 42.86%. En lugar de ver la opción “Desconocido” como un refugio seguro ante la incertidumbre, el modelo la interpretó como un distractor débil y poco probable, lo que facilitó su proceso de eliminación para llegar a la respuesta “correcta”.
Este comportamiento revela una desalineación fundamental con la ética médica. Un principio central de la medicina es primum non nocere, “lo primero es no hacer daño”, lo que exige un reconocimiento honesto de la incertidumbre. Un médico, ante la duda, solicita más pruebas, consulta a un colega o admite que la información es insuficiente. Los modelos de IA, en cambio, están optimizados para un objetivo diferente: encontrar la respuesta correcta entre un conjunto de opciones, a cualquier costo. No hay penalización por adivinar, solo por equivocarse. Su arquitectura y su objetivo de entrenamiento carecen de un concepto de “humildad epistémica”, una conciencia de sus propias lagunas de conocimiento. Desplegar un sistema que no puede manejar la incertidumbre de forma segura en un campo definido por ella es una receta para el desastre.
La elocuencia del engaño: razonamientos fabricados y sustituciones visuales
Las dos últimas pruebas de estrés se adentraron en el corazón del proceso de razonamiento del modelo, examinando la fidelidad y la veracidad de sus explicaciones.
La quinta prueba, Sustitución visual, fue un experimento ingenioso y devastador. Los investigadores tomaron preguntas donde la imagen era crucial y la reemplazaron por otra imagen que se correspondía visualmente con una de las respuestas incorrectas. El texto de la pregunta y las opciones de respuesta se mantuvieron sin cambios. Un modelo con una verdadera integración de texto e imagen debería cambiar su predicción para que coincida con la nueva evidencia visual. En cambio, su rendimiento se derrumbó. La precisión de GPT-5 se desplomó de un 83.33% en las preguntas originales a un 51.67% con las imágenes sustituidas, una caída catastrófica de más de 31 puntos porcentuales. Esto demuestra que el modelo no está realizando un razonamiento visual-textual robusto. En su lugar, ha aprendido asociaciones superficiales entre ciertas características visuales y etiquetas de diagnóstico, y cuando estas asociaciones se rompen, todo su conocimiento se desmorona.
Finalmente, la sexta prueba, Integridad del razonamiento, auditó directamente las explicaciones generadas por los modelos. Se les pidió que “pensaran paso a paso” (una técnica conocida como Chain-of-Thought o CoT) para justificar sus respuestas. Los resultados fueron, en muchos casos, peores que si no se les hubiera pedido que razonaran; en benchmarks como NEJM y VQA-RAD, la precisión a menudo disminuyó. Pero lo más alarmante fueron los patrones de fallo cualitativos. Los auditores manuales identificaron tres modos de fallo principales:
- Lógica incorrecta con respuesta correcta: El modelo llega a la respuesta correcta por azar o atajo, y luego genera una justificación que suena plausible pero es médicamente incorrecta.
- Percepción alucinada: El modelo inventa o alucina características visuales para respaldar su respuesta. El ejemplo más claro fue cuando, sin que se le mostrara ninguna imagen, un modelo justificó su diagnóstico de dermatomiositis describiendo con confianza una “decoloración violácea (púrpura) y edema de los párpados superiores, el clásico ‘eritema en heliotropo’”. La explicación era médicamente precisa, pero completamente ficticia, ya que se basaba en una imagen que no existía.
- Razonamiento visual con anclaje defectuoso: El modelo parece analizar la imagen paso a paso, pero basa su lógica en características incorrectas o imaginadas, lo que lo lleva a una conclusión segura pero equivocada.
La combinación del fracaso en la sustitución visual y el razonamiento fabricado demuestra que estos modelos no han logrado un verdadero “anclaje” (grounding), la capacidad de conectar el lenguaje con el mundo visual de una manera significativa y veraz. El razonamiento que producen no es fiel a la evidencia. Esta es quizás la barrera más grande para su adopción clínica, porque un médico nunca podrá confiar en el resultado de un sistema si sus explicaciones son ficciones elaboradas. Rompe el ciclo esencial de verificación, confianza y responsabilidad. La explicación no es una ventana al “proceso de pensamiento” del modelo; es un artefacto generado por separado, diseñado para imitar el aspecto que debería tener una justificación válida. El sistema es una caja negra opaca que ha aprendido a decorarse con la apariencia de transparencia, lo que lo hace fundamentalmente indigno de confianza.
| Prueba de estrés | Objetivo de la prueba | Resultado más llamativo (GPT-5) |
| 1. Sensibilidad a la modalidad | Medir la dependencia de la información visual. | La precisión cae un 13.33% en NEJM al quitar la imagen. |
| 2. Necesidad de la modalidad | Probar si el modelo adivina en preguntas que requieren visión. | Alcanza un 37.71% de precisión (frente al 20% de azar) sin la imagen necesaria. |
| 3. Perturbación del formato | Evaluar la sensibilidad al orden de las respuestas. | La precisión cae 5.7 puntos porcentuales al barajar las opciones. |
| 4. Reemplazo de distractores | Probar cómo maneja la incertidumbre. | La precisión aumenta 5.15 puntos al reemplazar una opción con “Desconocido”. |
| 5. Sustitución visual | Evaluar la integración real de texto e imagen. | La precisión se desploma un 31.66% al cambiar la imagen por una que apoya una respuesta incorrecta. |
| 6. Integridad del razonamiento | Auditar la fidelidad de las explicaciones del modelo. | Genera explicaciones detalladas de rasgos visuales en imágenes que no ha visto. |
El mapa equivocado: cuando los exámenes miden la astucia, no la comprensión
Después de exponer las profundas debilidades de los modelos, el informe dirige su atención crítica hacia el ecosistema que los produce: los propios benchmarks. La conclusión es ineludible: el problema no reside únicamente en los modelos, sino en las herramientas que utilizamos para medirlos. Estamos utilizando un mapa equivocado para navegar por el territorio de la inteligencia artificial médica.
Para fundamentar esta crítica, los investigadores llevaron a cabo un análisis meticuloso de los benchmarks, guiado por un panel de médicos especialistas. Desarrollaron una rúbrica estructurada para perfilar lo que cada benchmark realmente exige a un modelo, evaluándolos a lo largo de ejes clínicamente significativos como la cantidad de pasos de razonamiento necesarios, la dependencia del contexto clínico, la necesidad de interpretar detalles visuales sutiles y si la pregunta es resoluble solo con texto.
Los resultados de este perfilado, visualizados en un “paisaje de benchmarks”, son sorprendentes. Revelan que pruebas que a menudo se tratan como intercambiables en realidad miden habilidades radicalmente diferentes. El benchmark NEJM, por ejemplo, se sitúa en la esquina de alta complejidad, exigiendo tanto un razonamiento inferencial profundo como una interpretación visual detallada. En el otro extremo, el benchmark JAMA, aunque requiere un razonamiento considerable, demostró ser en gran medida resoluble a partir del texto, con una baja dependencia visual. Otros, como VQA-RAD, son muy dependientes de la imagen para tareas como la localización de anomalías, pero requieren muy poca inferencia médica compleja. Tratar las puntuaciones de estos benchmarks como equivalentes y promediarlas es, como sugiere la analogía, como calcular la media de las notas de un estudiante en cálculo, poesía y carpintería y llamar al resultado una medida de “capacidad académica general”. Esta práctica enmascara las fortalezas y debilidades específicas y crea una imagen distorsionada de la competencia real.
Esta situación ha dado lugar a lo que se puede describir como un círculo vicioso de la evaluación. El prestigio académico y comercial en el campo de la IA está fuertemente ligado al rendimiento en las tablas de clasificación. Para ascender en ellas, un laboratorio de investigación debe demostrar un rendimiento sólido en un conjunto de benchmarks populares. Dado que estas pruebas miden habilidades dispares y a veces contradictorias, la estrategia óptima para un modelo no es convertirse en un razonador médico genuino, sino en un “examinando” flexible que puede desplegar diferentes atajos para diferentes tipos de pruebas. Cuando un modelo tiene éxito con esta estrategia, sus resultados se publican, reforzando la idea de que esa colección de benchmarks es el “estándar de oro” para la evaluación. Como resultado, hay pocos incentivos para invertir en el difícil y costoso trabajo de crear métodos de evaluación nuevos y más robustos, ya que no forman parte del “juego” establecido. El sistema, impulsado por la cultura de las tablas de clasificación, perpetúa sus propias deficiencias y frena la verdadera innovación en la forma en que medimos el progreso.

Esta figura explica tres maneras en que los modelos médicos pueden parecer inteligentes mientras que el razonamiento es erróneo. – El primer caso muestra que el modelo siguió una regla general aprendida de patrones anteriores, no de la evidencia real. Piense en «si veo X, generalmente es la enfermedad Y», por lo que saltó a Y aunque este caso era diferente. La explicación sonaba detallada y certera, pero se basó en ese atajo en lugar de verificar las características específicas. Por lo tanto, el diagnóstico era erróneo, pero el razonamiento parecía creíble porque el atajo es común. – El segundo caso muestra una respuesta correcta pero una percepción alucinada, donde se obtiene la opción correcta incluso sin la imagen, lo que indica un comportamiento de atajo. – El tercer caso muestra un pensamiento con imágenes pero con fundamento, donde el análisis paso a paso cita características que faltan o se malinterpretan. El mensaje principal es que las explicaciones refinadas no garantizan una comprensión real, porque la evidencia que señalan no es confiable. Esto es importante porque las mejoras en los puntos de referencia pueden ocultar hábitos inseguros, como adivinar a partir de patrones o inventar detalles visuales.
Una confianza construida sobre la honestidad y el rigor, como rumbo
El viaje a través de los hallazgos del estudio “The Illusion of Readiness” comienza con la promesa brillante de inteligencias artificiales que superan los exámenes médicos y concluye con la aleccionadora realidad de sistemas frágiles, propensos a los atajos y capaces de fabricar razonamientos convincentes pero falsos. La conclusión principal es que la “ilusión de preparación” no surge de un fallo aislado, sino de un desajuste fundamental entre lo que estamos midiendo, la habilidad para superar pruebas, y lo que realmente necesitamos en la medicina, que es robustez, fiabilidad y seguridad clínica.
Lejos de ser un veredicto pesimista, el informe ofrece una hoja de ruta clara y constructiva para el futuro. Los autores proponen una serie de recomendaciones prácticas para realinear el campo con las demandas del mundo real.
Primero, es imperativo redefinir la evaluación. Esto significa moverse más allá de las puntuaciones de precisión únicas y agregadas. El rendimiento debe desglosarse y reportarse a lo largo de ejes médicamente significativos. El estudio propone la creación de una “Puntuación de Robustez” consolidada, que promedie el rendimiento de un modelo en una serie de pruebas de estrés como las realizadas, ofreciendo una medida más honesta de su estabilidad.
Segundo, los benchmarks deben ser tratados como herramientas de diagnóstico, no como fines en sí mismos. Cada benchmark debería publicarse con una especie de “etiqueta nutricional”, basada en una rúbrica guiada por clínicos, que detalle explícitamente qué habilidades mide, su dependencia visual, su complejidad de razonamiento y sus limitaciones conocidas. Esto permitiría a los investigadores y desarrolladores seleccionar las herramientas de evaluación adecuadas para el contexto de uso previsto.
Tercero, las pruebas de estrés deben convertirse en un requisito obligatorio. Las evaluaciones adversariales y basadas en estrés, que investigan el comportamiento del modelo bajo condiciones de incertidumbre, datos incompletos o entradas engañosas, deberían formar parte estándar de cualquier protocolo de evaluación para una IA destinada a un entorno de alto riesgo como la medicina.
Los hallazgos de este trabajo no representan el fin del camino para la inteligencia artificial en la salud. Por el contrario, son una señal vital de un campo que empieza a madurar, que se aleja de la autocomplacencia de las métricas superficiales y se adentra en el terreno más difícil del rigor científico y la responsabilidad. Al exponer estas verdades incómodas, los investigadores de Microsoft hacen un llamamiento a un nuevo paradigma basado en la honestidad, la transparencia y una profunda alineación con las necesidades clínicas. El verdadero progreso, concluye el artículo, no se encontrará en una puntuación más alta en un examen defectuoso, sino en la construcción de sistemas que puedan, de forma demostrable, ganarse la confianza de los médicos y los pacientes a los que están destinados a servir.
Fuentes
Gu, Y., Fu, J., Liu, X., Valanarasu, J. M. J., Codella, N. C. F., Tan, R., Liu, Q., Jin, Y., Zhang, S., Wang, J., Wang, R., Song, L., Qin, G., Usuyama, N., Wong, C., Cheng, H., Lee, H. H., Sanapathi, P., Hilado, S., Bian, J., Alvarez-Valle, J., Wei, M., Malik, K., Gao, J., Horvitz, E., Lungren, M. P., Poon, H., & Vozila, P. (2025). The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks. arXiv:2509.18234v2 [cs.AI].

