
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
La mente que aprende a razonar: el ascenso del aprendizaje por refuerzo en los modelos de IA
Los gigantes de la inteligencia artificial están dejando de ser meros generadores de texto para convertirse en pensadores estratégicos. Un nuevo estudio revela cómo el aprendizaje por refuerzo, la técnica que enseñó a las máquinas a dominar juegos complejos, es la clave para desatar su capacidad de razonamiento y transformar nuestro mundo. Esta es la historia de cómo la IA está aprendiendo a pensar, paso a paso, como nosotros.
En los últimos años, el mundo ha sido testigo de una revolución silenciosa, pero monumental, en el campo de la inteligencia artificial. Los modelos de lenguaje de gran tamaño (LLM por sus siglas en inglés), como aquellos que impulsan a los populares chatbots, han redefinido lo que creemos posible para las máquinas. Han demostrado una asombrosa capacidad para generar texto coherente, responder preguntas, traducir idiomas y, en general, interactuar con el lenguaje humano con una fluidez que roza lo indistinguible de la conversación humana. Sin embargo, detrás de esta elocuencia verbal, persistía una pregunta fundamental: ¿están estos modelos realmente «razonando» o simplemente están hilando patrones complejos aprendidos de cantidades ingentes de datos?
La distinción es crucial. Generar texto basado en patrones es una cosa; resolver un problema lógico, planificar una serie de acciones o inferir una conclusión a partir de premisas es otra muy distinta. Aquí es donde entra en juego una de las ramas más fascinantes y poderosas del aprendizaje automático: el aprendizaje por refuerzo (RL). Durante mucho tiempo, el aprendizaje por refuerzo ha sido la técnica detrás de las proezas más impresionantes de la IA en entornos estratégicos, como el dominio del ajedrez, el Go y videojuegos complejos, donde una inteligencia artificial aprende a tomar decisiones secuenciales a través de la experimentación, recibiendo «recompensas» por las acciones correctas y «penalizaciones» por los errores. Ahora, un estudio exhaustivo ha mapeado cómo esta técnica de aprendizaje, basada en la prueba y error guiada por recompensas, se está integrando de manera profunda en los modelos de lenguaje de gran escala para equiparlos con una capacidad de razonamiento mucho más sofisticada.
Este documento, una panorámica detallada sobre la interacción entre el aprendizaje por refuerzo y los grandes modelos de razonamiento (Large Reasoning Models, LRM), nos invita a explorar un futuro donde la inteligencia artificial no solo habla, sino que también piensa de manera estratégica. Para el lector no especializado, los conceptos de «modelo de razonamiento», «aprendizaje por refuerzo» o incluso «cadena de pensamiento» pueden sonar intimidantes. Sin embargo, en su esencia, se trata de enseñar a una máquina a resolver problemas complejos descomponiéndolos en pasos lógicos, a aprender de sus errores y a planificar su camino hacia una solución, tal como lo haría un detective o un científico. Este informe no es solo un compendio técnico; es un mapa de ruta para entender cómo la próxima generación de inteligencias artificiales será capaz de abordar desafíos que van mucho más allá de la mera conversación, transformando industrias desde la ciencia y la medicina hasta la educación y la ingeniería, y planteando preguntas profundas sobre la naturaleza misma de la inteligencia.
Antecedentes y marco: la evolución del pensamiento artificial
Para comprender la trascendencia de la sinergia entre el aprendizaje por refuerzo y los modelos de razonamiento, es fundamental situar ambos conceptos en su contexto evolutivo dentro del campo de la inteligencia artificial. La IA ha recorrido un largo camino desde sus inicios, pasando de sistemas basados en reglas rígidas a arquitecturas flexibles capaces de aprender por sí mismas.
Los modelos de lenguaje de gran tamaño (LLM) representan la cúspide de una línea de investigación que se centra en el procesamiento y la generación del lenguaje natural. Estos prodigios computacionales son redes neuronales masivas, con miles de millones de parámetros, entrenadas en volúmenes de texto y código sin precedentes. Su éxito radica en su habilidad para predecir la siguiente palabra en una secuencia, una tarea aparentemente simple que, cuando se escala, les permite aprender patrones gramaticales, semánticos e incluso pragmáticos del lenguaje humano. Esto les permite generar ensayos coherentes, traducir idiomas con fluidez o resumir documentos extensos. Sin embargo, su capacidad principal ha sido la generación de texto coherente, a menudo impresionantemente similar al humano, pero no necesariamente la resolución de problemas lógicos o matemáticos que requieren múltiples pasos de inferencia.
Aquí es donde entra en juego el concepto de modelos de razonamiento (LRM). Un modelo de razonamiento va más allá de la mera predicción de texto. Está diseñado para realizar inferencias, resolver problemas complejos paso a paso y emular el tipo de pensamiento estructurado que los humanos utilizamos en tareas lógicas o científicas. Esto implica la capacidad de descomponer un problema grande en subproblemas más pequeños, aplicar conocimientos relevantes en cada paso y evaluar la validez de los pasos intermedios. Los LRM son el puente entre la fluidez del lenguaje y la rigurosidad del pensamiento lógico.
Por otro lado, el aprendizaje por refuerzo (RL) es una metodología fundamentalmente diferente. En lugar de aprender de un conjunto de datos estáticos y etiquetados (como lo hacen los LLM en su preentrenamiento), un agente de RL aprende interactuando con un entorno. Es como un niño que aprende a jugar un videojuego: prueba diferentes acciones, recibe una «recompensa» (puntos, avanzar de nivel) o una «penalización» (perder una vida, ser derrotado), y ajusta su estrategia para maximizar las recompensas futuras. La meta de un agente de RL es aprender una «política» óptima, es decir, un conjunto de reglas que le dictan qué acción tomar en cada situación para alcanzar su objetivo. Esta capacidad de aprender de la experiencia y de la retroalimentación ha permitido a la IA dominar juegos complejos con reglas claras y objetivos definidos, como el ajedrez o el Go, e incluso entornos más ambiguos como los videojuegos.
La intersección de estos dos campos es lo que está definiendo la próxima frontera de la inteligencia artificial. El LLM proporciona la capacidad lingüística y el vasto conocimiento del mundo. El LRM refina esa capacidad para tareas de razonamiento. Y el RL dota a estos modelos de la habilidad de aprender a mejorar sus propios procesos de razonamiento a través de la práctica y la retroalimentación, de la misma manera que un estudiante mejora sus habilidades de resolución de problemas al practicar y aprender de sus errores. Esta amalgama promete crear inteligencias artificiales que no solo son elocuentes, sino también pensadores estratégicos y solucionadores de problemas extraordinariamente capaces.
Cómo funciona: enseñando a la IA a pensar con recompensas
La idea de infundir el poder del aprendizaje por refuerzo en los modelos de lenguaje para mejorar su capacidad de razonamiento puede parecer compleja, pero se basa en una serie de técnicas ingeniosas que adaptan los principios del RL a la naturaleza del procesamiento del lenguaje. El objetivo es guiar al modelo para que genere no solo respuestas superficialmente correctas, sino también procesos de pensamiento lógicos y verificables.
El corazón de este enfoque reside en el concepto de retroalimentación o recompensa. En los sistemas tradicionales de LLM, el modelo es recompensado implícitamente por generar texto que parece «natural» o «correcto» basándose en los datos de entrenamiento. Con el RL, introducimos una señal de recompensa explícita que evalúa la calidad del razonamiento o la corrección de la solución final de un problema.
Existen diversas maneras de proporcionar esta retroalimentación:
- Recompensas basadas en el resultado final: Esta es la forma más directa. Se presenta un problema al modelo (por ejemplo, un problema de matemáticas, un rompecabezas lógico o una tarea de codificación). El modelo genera su «razonamiento» (una secuencia de pasos) y una respuesta final. Si la respuesta final es correcta, el modelo recibe una recompensa positiva. Si es incorrecta, una recompensa negativa. El sistema de RL utiliza esta señal para ajustar los parámetros del modelo, de modo que en el futuro sea más probable que genere razonamientos que lleven a la respuesta correcta. Esto es similar a un jugador de ajedrez que solo sabe si ha ganado o perdido al final de la partida.
- Recompensas basadas en la verificación de pasos intermedios: Esta técnica es más sofisticada. En lugar de esperar el resultado final, el sistema evalúa la validez de cada paso en el proceso de razonamiento del modelo. Esto puede hacerse de varias maneras:
- Verificación externa: Un programa o una base de datos externa pueden verificar si un paso de cálculo es correcto, si una inferencia lógica es válida o si una pieza de código intermedia compila o ejecuta correctamente.
- Autoconsistencia: El modelo puede ser instruido para generar múltiples caminos de razonamiento y, si la mayoría de ellos convergen en la misma respuesta o en los mismos pasos intermedios, se asigna una recompensa positiva a esos caminos.
- Evaluación por otro LLM: Un LLM más pequeño o específicamente entrenado puede actuar como un «juez» o «crítico», evaluando la lógica y la coherencia de cada paso del razonamiento generado por el modelo principal. Este «juez» proporciona la señal de recompensa al modelo que está aprendiendo.
Una vez que se define el sistema de recompensas, se utilizan algoritmos de aprendizaje por refuerzo, como el Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF) o variaciones del Proximal Policy Optimization (PPO). Estos algoritmos ajustan los «pesos» internos del LLM para que las secuencias de texto (es decir, los pasos de razonamiento) que llevaron a recompensas positivas sean más probables en el futuro, y las que llevaron a penalizaciones, menos probables.
Este proceso de aprendizaje por refuerzo es iterativo. El modelo explora diferentes formas de razonar, recibe retroalimentación, aprende y refina su estrategia continuamente. La clave no es solo aprender la respuesta correcta, sino aprender el proceso correcto para llegar a esa respuesta, lo que le permite generalizar su capacidad de razonamiento a problemas nuevos y no vistos. Es así como la IA deja de ser solo un loro superdotado para convertirse en un aprendiz autodidacta en el arte del pensamiento lógico.
Comparaciones y puntos de referencia: midiendo la mente de la máquina
En el vertiginoso mundo de la inteligencia artificial, la evaluación del rendimiento de los sistemas es tan crucial como su desarrollo. Para entender verdaderamente las capacidades de los modelos de razonamiento potenciados por el aprendizaje por refuerzo, los investigadores se basan en un conjunto de benchmarks o puntos de referencia específicos. Estos son conjuntos de datos estandarizados y problemas predefinidos que permiten comparar de forma objetiva el progreso de diferentes arquitecturas y técnicas.
Tradicionalmente, la evaluación de los LLM se centraba en métricas de lenguaje, como la fluidez, la coherencia o la adecuación de la respuesta en tareas como la traducción o la generación de texto creativo. Sin embargo, para los modelos de razonamiento (LRM), estas métricas son insuficientes. Aquí, lo que importa es la precisión en la resolución de problemas, la corrección lógica de los pasos intermedios y la capacidad de inferencia en problemas que requieren múltiples pasos de deducción.
Algunos de los benchmarks más relevantes para evaluar los LRM potenciados por RL incluyen:
- Problemas matemáticos y de lógica: Conjuntos de datos como GSM8K (problemas de matemáticas a nivel de escuela primaria) o MATH (problemas de matemáticas de nivel más avanzado, incluyendo álgebra, cálculo y geometría) son utilizados para evaluar la capacidad de la IA para realizar cálculos precisos y razonar a través de problemas numéricos de varios pasos.
- Razonamiento simbólico y deductivo: Benchmarks que presentan problemas de lógica formal, silogismos o inferencias basadas en un conjunto de reglas. Estos evalúan si el modelo puede aplicar principios lógicos abstractos para llegar a conclusiones válidas.
- Planificación y toma de decisiones: En entornos simulados o juegos simples, se mide la capacidad del modelo para planificar una secuencia de acciones para alcanzar un objetivo, teniendo en cuenta las recompensas y penalizaciones.
- Generación de código funcional: Dada una descripción en lenguaje natural, se evalúa si el modelo puede generar código funcional y eficiente, y si es capaz de depurar sus propios errores.
- Razonamiento multi-paso en preguntas abiertas: Aunque más difíciles de evaluar automáticamente, estos benchmarks presentan preguntas complejas que requieren que el modelo descomponga el problema, consulte múltiples fuentes de conocimiento (internas o externas) y sintetice una respuesta bien razonada.
Los resultados iniciales de los modelos de razonamiento potenciados por RL en estos benchmarks son consistentemente superiores a los de los LLM que no utilizan esta técnica. Por ejemplo, en algunos problemas matemáticos complejos, se ha observado que los LRM con RL pueden duplicar o triplicar la precisión de los modelos base. La razón de esta mejora radica en la capacidad del RL para refinar el proceso de pensamiento, no solo el resultado. Al ser recompensados por caminos de razonamiento correctos, los modelos aprenden heurísticas (atajos mentales válidos) y estrategias de resolución de problemas que los LLM sin RL no desarrollan tan eficientemente.
Además, el uso de técnicas como la «cadena de pensamiento» (Chain-of-Thought, CoT), donde el modelo verbaliza sus pasos de razonamiento, ha demostrado ser crucial. Cuando se combina con RL, el modelo no solo aprende a generar buenos pasos, sino que también aprende a evaluar la calidad de sus propios pasos, lo que lo hace más autónomo y robusto. La meta a largo plazo no es solo que la IA acierte la respuesta, sino que también nos muestre y justifique su proceso de pensamiento, haciéndola más transparente y confiable para los usuarios.
Voces y fuentes: el consenso de la vanguardia
La explosiva integración del aprendizaje por refuerzo en los modelos de lenguaje de gran tamaño no es un fenómeno aislado, sino el resultado de un consenso creciente y de esfuerzos convergentes por parte de los principales centros de investigación en inteligencia artificial a nivel mundial. Este informe no solo recopila datos, sino que sintetiza el pensamiento de las mentes más brillantes que están dando forma a esta nueva frontera.
Los nombres asociados con este avance son los mismos que han estado a la vanguardia de la revolución de la IA en la última década. Investigadores de instituciones como Google DeepMind, OpenAI, Meta AI y varias de las universidades más prestigiosas del mundo (como Stanford, MIT y Carnegie Mellon) son los principales arquitectos de esta convergencia. Sus publicaciones y los estudios que se analizan en esta revisión son los pilares sobre los que se construye la comprensión actual del aprendizaje por refuerzo aplicado al razonamiento.
La comunidad ha identificado varios motivos clave para esta integración estratégica:
- Superar las limitaciones del preentrenamiento: Si bien los LLM son excepcionales para la generación de texto, su preentrenamiento masivo a menudo los deja «sin aliento» en tareas de razonamiento complejas. Aprenden a predecir la siguiente palabra, pero no necesariamente la siguiente acción lógica en una secuencia de pasos para resolver un problema. El RL proporciona un mecanismo para afinar esta capacidad de acción.
- Mejorar la alineación con la intención humana: Los modelos de lenguaje a menudo producen resultados que son técnicamente correctos, pero que no se alinean perfectamente con lo que un usuario realmente quería o esperaba. Técnicas como el Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF) son fundamentales aquí. En RLHF, las preferencias de los humanos (qué respuestas son más útiles, seguras o correctas) se utilizan como señales de recompensa para entrenar al modelo. Esto permite que la IA no solo aprenda a razonar, sino a razonar de una manera que los humanos encuentran deseable.
- Fomentar el aprendizaje continuo y la exploración: A diferencia de los modelos entrenados una sola vez y luego desplegados, los agentes de RL tienen un potencial inherente para el aprendizaje continuo. En entornos donde las reglas o los datos cambian, un agente de RL puede adaptarse y mejorar su estrategia con el tiempo, siempre buscando maximizar una recompensa. Esto es crucial para la longevidad y la relevancia de los sistemas de IA en el mundo real.
Los papers citados en el estudio abarcan desde los fundamentos teóricos de cómo se puede aplicar el RL a secuencias de texto, hasta aplicaciones específicas en dominios como la resolución de problemas matemáticos, la generación de código y la planificación. Un tema recurrente es la búsqueda de eficiencia en el proceso de RL, ya que entrenar grandes modelos con esta técnica puede ser computacionalmente intensivo. Las innovaciones en este campo buscan formas de aprender de menos interacciones o de utilizar simulaciones más realistas para acelerar el proceso. La colaboración entre equipos, el intercambio de ideas y la publicación de nuevos benchmarks son vitales para el rápido avance de esta subdisciplina de la IA, que promete desbloquear niveles sin precedentes de inteligencia artificial razonadora.
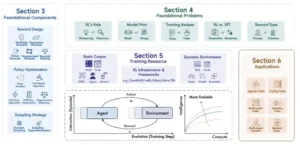
Descripción general del estudio. Se observan los componentes fundamentales del RL para los LRM, junto con problemas abiertos, recursos de entrenamiento y aplicaciones. Un aspecto central de este estudio es el enfoque en las interacciones a gran escala entre agentes de lenguaje y entornos a lo largo de una evolución a largo plazo.
Impactos por sector: la IA que piensa transforma el mundo
La emergencia de modelos de inteligencia artificial capaces de razonar de manera estratégica a través del aprendizaje por refuerzo no es una mera curiosidad académica; sus implicaciones resuenan profundamente en una multitud de sectores, prometiendo transformar desde la forma en que los científicos descubren hasta cómo las empresas toman decisiones. Estamos al borde de una era donde la IA no solo automatiza tareas, sino que también ayuda a resolver problemas complejos y a generar nuevas ideas.
En el ámbito científico y de investigación, el impacto podría ser revolucionario. Imaginemos un agente de IA que, dada una hipótesis en biología o física, no solo la comprende, sino que también puede diseñar experimentos, simular resultados, analizar datos complejos y proponer nuevas vías de investigación. Los LRM con RL pueden asistir en el diseño de nuevos materiales, la optimización de reacciones químicas o el descubrimiento de fármacos, explorando un espacio de soluciones que sería inabarcable para los investigadores humanos. Ya se están viendo avances en la generación de código científico robusto y en la optimización de diseños experimentales, acelerando drásticamente el ritmo del descubrimiento.
En la medicina y la salud, los agentes de razonamiento pueden asistir en el diagnóstico, sugiriendo planes de tratamiento personalizados basados en una comprensión profunda del historial del paciente y la literatura médica más reciente. Podrían ayudar a los investigadores a desarrollar nuevos enfoques terapéuticos o a optimizar la gestión de recursos hospitalarios complejos, considerando múltiples variables y resultados a largo plazo. La capacidad de razonar sobre la causalidad y la incertidumbre es fundamental en este sector.
Para la educación, la promesa es la de tutores de IA profundamente personalizados. Un agente de razonamiento podría identificar las lagunas en el conocimiento de un estudiante, proponer problemas adaptados a su nivel, guiarlo a través de los pasos de resolución de problemas y corregirlo con retroalimentación específica, todo ello imitando la paciencia y el conocimiento de un educador humano. Esto podría democratizar el acceso a una enseñanza de alta calidad y hacer que el aprendizaje sea más atractivo y eficaz.
En el sector financiero, los LRM potenciados por RL podrían revolucionar el comercio algorítmico, la gestión de carteras y la detección de fraudes. Un agente podría analizar vastas cantidades de datos de mercado, identificar patrones sutiles, tomar decisiones de inversión en tiempo real y adaptarse a las condiciones cambiantes del mercado con una sofisticación estratégica. Su capacidad para aprender de la experiencia es especialmente valiosa en entornos volátiles.
Finalmente, en el campo de la ingeniería y el desarrollo de software, estos modelos pueden automatizar tareas complejas como la generación de código, la depuración, la verificación de sistemas y la optimización de arquitecturas. Un ingeniero podría describir un problema en lenguaje natural, y el agente podría generar no solo el código, sino también las pruebas y un plan de despliegue, mejorando significativamente la productividad y la calidad del software. La capacidad de un LRM para razonar sobre los requisitos y las limitaciones de un sistema puede llevar a soluciones de diseño innovadoras y eficientes. Estos ejemplos son solo la punta del iceberg, señalando una era donde la IA se convierte en un socio intelectual activo en la resolución de los problemas más apremiantes del mundo.
Controversias y vacíos: los desafíos en el camino hacia la IA razonadora
A pesar del innegable progreso y el inmenso potencial de los modelos de razonamiento potenciados por el aprendizaje por refuerzo, la investigación en este campo no está exenta de desafíos significativos y controversias que requieren una atención cuidadosa. La ambición de crear inteligencias artificiales que «piensen» como los humanos plantea preguntas técnicas, éticas y filosóficas que deben ser abordadas para asegurar un desarrollo responsable y beneficioso.
Una de las principales controversias técnicas radica en la interpretabilidad y transparencia del razonamiento de la IA. Si bien los modelos pueden generar cadenas de pensamiento, a menudo es difícil entender por qué el modelo tomó ciertas decisiones o cómo llegó a una conclusión específica. Esta falta de transparencia puede ser problemática en aplicaciones críticas como la medicina o las finanzas, donde la explicabilidad es esencial. Los esfuerzos de investigación actuales buscan desarrollar mecanismos para que los modelos no solo razonen, sino que también justifiquen su razonamiento de una manera comprensible para los humanos.
Otro desafío clave es el coste computacional. Entrenar grandes modelos de lenguaje ya es extremadamente caro en términos de recursos informáticos y energéticos. Añadir una capa de aprendizaje por refuerzo, que a menudo requiere miles o millones de interacciones con un entorno, multiplica exponencialmente estos costes. Esto plantea preguntas sobre la sostenibilidad ambiental de estas tecnologías y si su desarrollo solo será accesible para las organizaciones con los mayores recursos. Se necesitan innovaciones en algoritmos de RL más eficientes y en hardware especializado para democratizar el acceso a esta capacidad.
Existen también vacíos en la investigación que necesitan ser llenados. La mayoría de los trabajos actuales se centran en problemas con reglas claras y objetivos bien definidos (como juegos o problemas matemáticos). Sin embargo, el razonamiento humano en el mundo real a menudo implica:
- Manejar la ambigüedad y la incertidumbre: Los problemas del mundo real rara vez son «limpios».
- Razonamiento de sentido común: Integrar conocimientos implícitos sobre cómo funciona el mundo.
- Razonamiento moral y ético: Considerar las implicaciones de las decisiones más allá de la mera optimización.
- Aprendizaje continuo y adaptable: La capacidad de un agente para adaptarse a entornos completamente nuevos o cambiantes sin un reentrenamiento masivo.
La investigación sobre cómo los LRM pueden abordar estas formas más «blandas» y menos estructuradas de razonamiento está aún en sus primeras etapas.
Desde una perspectiva ética y social, la capacidad de una IA para razonar de manera autónoma plantea preocupaciones sobre el control y la alineación. ¿Cómo nos aseguramos de que los objetivos para los que optimiza un agente de RL estén perfectamente alineados con los valores humanos? Si un agente se vuelve extremadamente competente en la resolución de problemas, pero con objetivos ligeramente desalineados, las consecuencias podrían ser significativas. La regulación y las políticas públicas tendrán que evolucionar rápidamente para abordar estas cuestiones, equilibrando la innovación con la protección y la garantía de un uso responsable. Abordar estas controversias y llenar estos vacíos no es solo un imperativo técnico, sino una responsabilidad social que definirá el impacto final de la IA razonadora en el futuro de la humanidad.
Escenarios a corto, mediano y largo plazo
La trayectoria actual de los modelos de razonamiento potenciados por el aprendizaje por refuerzo nos permite vislumbrar una serie de escenarios futuros, cada uno con sus propias implicaciones. Comprender estos posibles futuros, junto con las consideraciones éticas y regulatorias inherentes, es esencial para guiar el desarrollo de esta tecnología de manera responsable.
En el corto plazo se afianzará una receta de tres etapas.
- Primero, distilar y ajustar para que el modelo “piense” en pequeño, sin caer en monólogos eternos.
- Segundo, entrenar con recompensas verificables en matemáticas, programación y dominios con simuladores.
- Tercero, alinear estilo y seguridad con retoques livianos. Los resultados inmediatos serán modelos medianos que, en esas áreas, rinden por encima de lo que su tamaño haría suponer, gracias a una política entrenada para usar bien el tiempo y una verificación barata.
En el mediano plazo veremos expansión a entornos mixtos. Se mezclarán tareas con verificación dura con tramos que exigen juicio. Ahí los jueces generativos deberán madurar. Aprenderán a justificar con criterios claros, a calibrarse contra señales objetivas y a resistir intentos de manipulación. También crecerán los catálogos de entornos: lógicas más ricas, juegos que obligan a planificar, gimnasios de ciencia con modelos físicos simplificados y suites que generan problemas de manera programática para cubrir huecos del entrenamiento.
En el largo plazo hay líneas de investigación que prometen cambiar el tablero.
- Una es el refuerzo continuo, no como etapa posterior al preentrenamiento, sino como modo de vida del modelo, donde la política sigue aprendiendo en operación con controles estrictos de seguridad.
- Otra es la memoria, no solo como contexto, sino como mecanismo que conecta episodios lejanos de manera estructurada.
- Una tercera es integrar modelos de mundo que permitan simular consecuencias y planificar más allá del siguiente paso.
- Una cuarta, explorar preentrenamientos con decisiones, donde el modelo aprende a elegir qué leer, qué ignorar y cómo combinar fragmentos informativos. El hilo común es bajar el costo de verificar y ampliar la gama de tareas donde la verificación es aceptable socialmente.
La reflexión proactiva sobre estos dilemas es tan importante como el desarrollo tecnológico en sí. La creación de una IA que piensa de manera estratégica es una de las empresas más ambiciosas de la humanidad, y su éxito final dependerá no solo de lo inteligentes que seamos para construirla, sino de lo sabios que seamos para guiarla.
Ética y regulación
El refuerzo tiene una virtud rara en tecnología: obliga a blanquear qué se premia. Ese acto de transparencia sirve para la gobernanza. Si un sistema decide en educación, justicia o salud, debe ser posible reconstruir qué señal lo llevó a elegir A y no B. La privacidad entra de lleno porque los pipelines de refuerzo guardan trazas, entradas y salidas que pueden contener información sensible. Minimización, anonimización y retención limitada son requisitos, no extras.
La seguridad es un capítulo aparte. Un juez generativo mal entrenado puede consolidar estereotipos o fallar en contextos minoritarios. Un verificador incompleto puede dar por correctas salidas peligrosas. Por eso, además de los clásicos filtros de seguridad, se necesitan pruebas de robustez para los propios jueces y verificadores. Y porque el aprendizaje es interactivo, las responsabilidades cambian. Ya no alcanza con auditar datasets y pesos, también hay que auditar herramientas, orquestación y reglas de muestreo.
Finalmente, la equidad. Si entrenamos políticas con objetivos mal definidos, corremos el riesgo de optimizar métricas fáciles y olvidar objetivos sociales más complejos. En espacios donde la evaluación tiene componentes cualitativos, la transparencia sobre las rúbricas y la participación de personas afectadas por las decisiones no es solo un gesto, es un antídoto contra el diseño de metas equivocadas.
La chispa del pensamiento en la máquina
Hemos recorrido un camino fascinante, desde los humildes orígenes de los modelos de lenguaje hasta la sofisticada amalgama de razonamiento y aprendizaje por refuerzo. El estudio que nos ha guiado a través de esta panorámica no es solo un compendio de técnicas, sino una ventana hacia el futuro de la inteligencia artificial, un futuro en el que las máquinas están aprendiendo a pensar, a planificar y a resolver problemas de una manera que se asemeja cada vez más a la cognición humana. La chispa del pensamiento, esa capacidad de ir más allá de la mera imitación para generar inferencias y estrategias novedosas, está siendo encendida en los circuitos de silicio.
La integración del aprendizaje por refuerzo ha dotado a los modelos de lenguaje de una habilidad transformadora: la capacidad de aprender de la experiencia, de ajustar su proceso de razonamiento basándose en la retroalimentación y de maximizar la consecución de objetivos complejos. Esto significa que las futuras inteligencias artificiales no solo serán capaces de articular ideas con fluidez, sino también de construir argumentos lógicos sólidos, de diseñar experimentos coherentes y de trazar planes estratégicos en un vasto abanico de dominios. Desde la aceleración del descubrimiento científico hasta la optimización de complejas operaciones industriales, pasando por la creación de herramientas educativas personalizadas, el impacto será omnipresente.
Sin embargo, este viaje no está exento de obstáculos ni de profundas interrogantes. Los desafíos relacionados con la interpretabilidad del razonamiento de la IA, los altos costes computacionales y la necesidad de una alineación inquebrantable entre los objetivos de la máquina y los valores humanos son escollos que debemos sortear con prudencia. La tarea no es solo construir inteligencias más capaces, sino construir inteligencias más sabias, más éticas y más transparentes.
En última instancia, el verdadero valor de esta convergencia no reside en la capacidad de la IA para superar a los humanos en una tarea específica, sino en su potencial para amplificar la inteligencia humana misma. Estos modelos de razonamiento se convertirán en nuestros «co-pilotos» intelectuales, herramientas que nos liberarán de las tareas rutinarias de cálculo y lógica para permitirnos centrarnos en la creatividad, la intuición, la formulación de grandes preguntas y la interpretación de los significados más profundos de nuestros descubrimientos. La IA no está aprendiendo a reemplazarnos como pensadores, sino a empoderarnos, a catalizar nuestra capacidad colectiva para innovar y para comprender el universo en el que vivimos. La mente que aprende a razonar nos está invitando a una era de posibilidades sin precedentes.
Glosario de Términos Clave
- Modelo de Lenguaje de Gran Tamaño (LLM): Modelos de IA con miles de millones de parámetros, entrenados en vastas cantidades de texto, capaces de generar y comprender lenguaje natural.
- Aprendizaje por Refuerzo (RL): Metodología de aprendizaje automático donde un agente aprende a tomar decisiones interactuando con un entorno y recibiendo recompensas o penalizaciones.
- Modelo de Razonamiento (LRM): Un LLM especializado o adaptado para realizar tareas que requieren inferencia lógica, planificación y resolución de problemas multi-paso.
- Ingeniería de Prompts: El arte y la ciencia de diseñar las instrucciones iniciales para un LLM para guiar su comportamiento y calidad de respuesta.
- Chain-of-Thought (CoT) / Cadena de Pensamiento: Una técnica que instruye a un LLM para que verbalice sus pasos de razonamiento intermedios, lo que mejora su capacidad de resolver problemas complejos.
- Alineación de la IA: El proceso de asegurar que los objetivos y el comportamiento de un sistema de IA estén en armonía con los valores humanos y los resultados deseados.
- Benchmarks: Conjuntos de datos y problemas estandarizados utilizados para evaluar y comparar el rendimiento de diferentes modelos de IA en tareas específicas.
Métricas y Benchmarks Relevantes
La evaluación del razonamiento en la IA es crucial y se apoya en métricas específicas y conjuntos de datos rigurosos. No basta con generar una respuesta; la precisión del razonamiento es clave.
- Precisión de la respuesta final: Mide el porcentaje de veces que el modelo llega a la solución correcta de un problema.
- Exactitud del camino de razonamiento: Evalúa si los pasos intermedios generados por el modelo son lógicamente correctos y coherentes, incluso si la respuesta final es incorrecta.
- Capacidad de generalización: Determina si un modelo entrenado en un tipo de problema puede aplicar sus habilidades de razonamiento a problemas similares pero no vistos.
- GSM8K: Un conjunto de 8.5K problemas de matemáticas de escuela primaria, utilizado para evaluar la capacidad de los LLM para resolver problemas numéricos de varios pasos.
- MATH: Un benchmark más desafiante con 12.5K problemas de matemáticas de instituto y olimpiada, cubriendo álgebra, cálculo, geometría y teoría de números.
- HumanEval: Un conjunto de problemas de programación que mide la capacidad de la IA para generar código funcional a partir de descripciones en lenguaje natural.
Fuentes
A Survey of Reinforcement Learning for Large Reasoning Models. (2025). arXiv:2509.08827.

