
La inteligencia artificial (IA) ha experimentado una evolución exponencial en las últimas décadas, superando con creces a los humanos en dominios específicos como el ajedrez, el Go o el reconocimiento de patrones complejos. Sin embargo, un umbral persistente y fascinante sigue siendo la replicación del razonamiento abstracto humano, considerado uno de los pilares de la cognición superior. Este tipo de pensamiento nos permite trascender la realidad tangible, reflexionar sobre conceptos intangibles como la justicia o el amor, identificar principios subyacentes en fenómenos aparentemente diversos y construir estrategias complejas para adaptarnos al cambio.
Es la facultad que nos permite resolver problemas con información limitada, pensar hipotéticamente y realizar inferencias basadas en relaciones lógicas más que en datos sensoriales directos. La pregunta central de la investigación contemporánea es si los modelos de IA, especialmente los multimodales capaces de procesar texto, imágenes y otros formatos de datos simultáneamente, pueden emular esta capacidad fundamental.
El razonamiento abstracto se define como un conjunto de operaciones cognitivas que se basan en la reorganización de conceptos no directamente observables para generar nueva información. A diferencia del razonamiento concreto, que opera sobre objetos y eventos presentes físicamente, el abstracto opera sobre ideas, relaciones y principios. Esta habilidad emerge aproximadamente al inicio de la adolescencia, según los estudios del psicólogo Jean Piaget, marcando la transición a su estadio formal de desarrollo cognitivo.
Las funciones ejecutivas, como la planificación, la toma de decisiones y la resolución de problemas, son manifestaciones prácticas de este proceso mental y dependen de áreas cerebrales clave como los lóbulos frontales y la corteza asociativa. El deterioro de estas capacidades puede ser un indicador de enfermedades neurodegenerativas, traumas o el envejecimiento normal.
Para evaluar esta capacidad, los científicos han desarrollado pruebas estandarizadas. Una de las más influyentes es el test de Raven, también conocido como matrices progresivas de Raven, que mide el «Factor G» de inteligencia o razonamiento fluido mediante tareas no verbales basadas en patrones geométricos. Su objetivo es evaluar la capacidad de resolver problemas nuevos sin depender del conocimiento previo, cultura o escolaridad, lo cual lo hace extremadamente útil para comparar diferentes poblaciones y, más recientemente, sistemas de IA.
La investigación actual busca ir más allá de estos tests tradicionales hacia benchmarks más sofisticados que midan la comprensión robusta y la generalización de conceptos. Estudios como CONSTRUCTURE y ConceptARC están diseñados para evaluar no solo si un modelo puede encontrar una solución, sino cómo lo hace, explorando su capacidad para entender jerarquías conceptuales y abstraer reglas fundamentales. Estos nuevos desafíos requieren que los modelos no solo memoricen soluciones, sino que demuestren una verdadera comprensión de los conceptos espaciales y semánticos subyacentes.
En este contexto, la inteligencia artificial multimodal surge como la frontera más prometedora y complicada. Los modelos unimodales, como ChatGPT, procesan una sola fuente de datos (principalmente texto). En contraste, los modelos multimodales integran información heterogénea de textos, imágenes, audio y vídeo para formar una comprensión más completa y contextualizada del mundo. Arquitecturas como los transformadores y mecanismos de atención permiten que estos sistemas conecten dinámicamente información entre modalidades, por ejemplo, vinculando una descripción textual con una región específica de una imagen.
Aplicaciones como análisis médico avanzado, vehículos autónomos y asistentes virtuales cada vez más sofisticados dependen de esta capacidad de integración. Sin embargo, el éxito de la IA multimodal no está garantizado. Los retos son significativos y van desde la dificultad de alinear datos de diferentes fuentes (fusión de datos) hasta la gestión de la alta complejidad computacional y el riesgo de amplificar sesgos existentes en los conjuntos de datos de entrenamiento. Por lo tanto, evaluar si estos sistemas pueden realizar un razonamiento abstracto al estilo humano en un entorno multimodal no es solo un ejercicio académico; es un paso crucial para determinar si podemos construir una IA que sea verdaderamente competente y adaptable, más allá de ser simplemente eficiente.
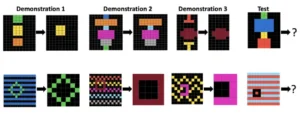
Cada fila muestra una tarea del benchmark ConceptARC. Cada tarea mostrada consta de tres demostraciones de una transformación y una cuadrícula de prueba. En este estudio, el solucionador debe generar una regla que describa las transformaciones y aplicarla a la cuadrícula de prueba.
El Benchmark ConceptARC: Evaluando la Capacidad de Abstracción de los Modelos de IA
El benchmark ConceptARC representa un intento deliberado de medir la genuina capacidad de abstracción de los modelos de inteligencia artificial, alejándose de las métricas de precisión pura que a menudo ocultan las debilidades conceptuales. Desarrollado por Melanie Mitchell y sus colegas, este conjunto de datos está diseñado para evaluar la comprensión robusta y la generalización en el dominio del Abstraction and Reasoning Corpus (ARC), creado originalmente por François Chollet en 2019.
Mientras que el ARC original consiste en 1.000 tareas de completación de patrones visuales que requieren inducir reglas abstractas a partir de ejemplos muy limitados, ConceptARC organiza estos problemas en «grupos de conceptos» que se centran en conceptos espaciales y semánticos específicos. Estos conceptos incluyen ideas básicas como «dentro vs. fuera», «arriba vs. abajo», «extender al límite» y «igual vs. diferente», organizados en 16 grupos distintos dentro de las 480 tareas analizadas en el estudio del paper.
Una de las características más innovadoras de ConceptARC es su diseño dual, que presenta cada tarea en dos modalidades: visual y textual. En la modalidad visual, los usuarios reciben cuadrículas de entrada y salida representadas como imágenes, donde los colores codifican diferentes valores. En la modalidad textual, la misma información se representa como matrices de enteros (del 0 al 9) codificando los mismos colores, lo que permite que los modelos de lenguaje grandes (LLM) puedan procesar la información.
Este diseño dual es fundamental para el propósito del estudio, ya que permite una comparación directa de cómo los modelos de IA responden a la misma estructura conceptual pero presentada en formatos radicalmente diferentes. Esto revela si su capacidad de razonamiento es realmente abstracta y portátil, o si está anclada a las propiedades superficiales de una modalidad específica.
Los resultados de evaluar modelos de IA en ConceptARC han sido reveladores y consistentes en múltiples estudios. En un trabajo anterior, se evaluó a GPT-4 (la versión de texto) y a su versión multimodal GPT-4V, encontrando que ninguna de las dos alcanzaba los niveles de abstracción robusta del ser humano. Otro estudio, que utilizó un conjunto de datos a gran escala llamado H-ARC (con más de 1700 participantes humanos), estimó que los humanos alcanzan una precisión promedio del 70.5% en el conjunto de entrenamiento y 65.7% en el de evaluación.
Para poner esto en perspectiva, la precisión humana reportada en el propio paper de ConceptARC fue del 73%. En contraste, el mejor modelo de IA en ese estudio, basado en GPT-4, obtuvo solo un 42% de precisión en el conjunto de evaluación del ARC. Estos datos sugieren una brecha considerable entre la capacidad de los humanos para generalizar reglas abstractas a partir de pocos ejemplos y la de los actuales modelos de IA. Los humanos, incluso con errores, tienden a usar un razonamiento flexible y a autocorregirse, mientras que los modelos de IA carecen de esta adaptabilidad.
Otro marco de evaluación, CONSTRUCTURE, se enfoca en el razonamiento jerárquico de conceptos visuales. Evalúa la capacidad de los modelos para comprender conceptos atómicos, razonar de forma ascendente (abstracción) y descendente (concretización), y relacionar conceptos hermanos. Los resultados fueron igualmente modestos: el mejor modelo, GPT-4o, alcanzó un puntaje promedio de 0.621, con rendimientos particularmente bajos en tareas que requerían razonar sobre ancestros comunes de los conceptos.
Los investigadores atribuyeron los errores a inconsistencias en el razonamiento y a dificultades con jerarquías finas de conceptos. Juntas, estas evaluaciones sugieren que, aunque los modelos de IA modernos pueden sobresalir en tareas de reconocimiento de patrones y aprendizaje de memoria, aún les falta profundidad conceptual. No logran capturar la esencia de un problema abstracto de la misma manera que lo haría un humano, lo que indica que estamos lejos de haber construido una IA con una comprensión genuina del mundo.
| Benchmark | Principales Hallazgos | Precisión Humana Reportada | Precisión Mejor Modelo de IA Reportada |
|---|---|---|---|
| Abstraction and Reasoning Corpus (ARC) | Los humanos superan significativamente a los modelos de IA en abstracción y generalización. El razonamiento humano es flexible y usa autocorrección. | ~70.5% – 76.2% | ~42% (basado en GPT-4) |
| ConceptARC | Demostró una brecha significativa entre humanos y máquinas, especialmente en la modalidad visual. La precisión de los humanos fue del 73%. | 73% | o3-preview alcanzó un 77.1% en texto, pero solo un 5.6% en visual sin herramientas |
| CONSTRUCTURE | Reveló limitaciones profundas en el razonamiento estructural jerárquico de los MLLMs. El rendimiento disminuye con la granularidad del concepto. | Información no disponible en las fuentes proporcionadas. | GPT-4o-0513 alcanzó un puntaje de 0.621 |
Un Experimento Multimodal: Resultados y Análisis Comparativo de Siete Grandes Modelos
El corazón del estudio «Do AI Models Perform Human-like Abstract Reasoning Across Modalities?» es una exhaustiva evaluación experimental que compara el rendimiento de siete modelos de IA prominentes en el benchmark ConceptARC, utilizando tanto la modalidad textual como la visual. Los modelos seleccionados representan una gama de arquitecturas y filosofías de desarrollo, incluyendo tanto modelos de código cerrado de gigantes tecnológicos como modelos de código abierto que impulsan la colaboración en la comunidad de IA. Los modelos evaluados son: `o3-preview` y `o4-mini` de OpenAI, `Gemini 2.5 Pro` de Google, `Claude Sonnet 4` de Anthropic, y tres modelos que los autores clasifican como «no razonadores»: `GPT-4o`, `Llama 4 Scout` de Meta y `Qwen 2.5 VL 72B` de Alibaba.
La metodología del estudio es rigurosa, midiendo el desempeño en dos frentes principales: la precisión de la salida y la calidad de las reglas generadas. La precisión se mide con la métrica `pass@1`, que indica si la solución generada por el modelo coincide exactamente con la solución correcta. Sin embargo, el análisis más profundo reside en el segundo frente: la evaluación cualitativa de las reglas en lenguaje natural que los modelos generan para explicar su propia solución.
Este enfoque es crucial porque permite a los investigadores mirar más allá del resultado final y examinar el proceso de razonamiento interno del modelo, buscando si la solución se basa en una comprensión genuina del concepto abstracto o en atajos superficiales. Las reglas se clasifican manualmente en tres categorías: Incorrectas, Correctas pero No Intencionadas (atajos superficiales) y Correctas e Intencionadas (reflejan la abstracción real del problema).
Los resultados obtenidos son sorprendentes y revelan una brecha profunda entre el rendimiento superficial y la capacidad de razonamiento real, especialmente cuando se cruzan las modalidades. En la modalidad textual, donde los modelos de lenguaje grandes tienen una clara ventaja, el modelo `o3-preview` de OpenAI demostró un rendimiento excepcional. Con un nivel de esfuerzo de razonamiento medio, alcanzó una precisión de `pass@1` del 77.1%, superando la precisión humana promedio reportada en el mismo benchmark, que fue del 73%.
Esto sugiere que en un formato puramente simbólico, los modelos actuales pueden ser muy eficaces para encontrar soluciones a problemas de razonamiento abstracto. Sin embargo, el análisis de sus reglas de razonamiento destaca una debilidad crítica: un 28% de sus respuestas correctas se basaban en reglas que eran o incorrectas o correctas pero no intencionadas (patrones superficiales). En comparación, solo el 8% de las respuestas correctas de los humanos se basaban en tales atajos.
La situación cambia drásticamente cuando se evalúa a los mismos modelos en la modalidad visual. Aquí, la precisión de todos los modelos cae de forma drástica. El `o3-preview`, que lideraba en texto, solo alcanzó un 5.6% de precisión sin el uso de herramientas externas. Este número es alarmantemente bajo y sugiere que la capacidad de razonamiento abstracto del modelo está estrechamente ligada a su modalidad de entrada preferida. Sorprendentemente, el análisis de las reglas en este modo visual revela un patrón diferente.
Aunque la precisión es baja, se encuentra que los modelos generan un número sustancial de reglas que son, de hecho, correctas e intencionadas. De hecho, se informa que el `o3-preview` generó reglas correctas e intencionadas en un 27% de los casos en los que su salida fue incorrecta. Esto lleva a una conclusión poderosa: la métrica de precisión de salida por sí sola es engañosa. Puede sobreestimar el razonamiento abstracto en la modalidad textual (donde los modelos pueden obtener aciertos gracias a atajos) y, al mismo tiempo, subestimarlo en la modalidad visual (donde la incapacidad de aplicar correctamente una regla abstracta correcta se pierde bajo una baja precisión).
| Modelo | Modalidad | Esfuerzo de Razonamiento | Precisión pass@1 | Reglas Correctas e Intencionadas (%) | Reglas Superficiales/Incorrectas (%) |
|---|---|---|---|---|---|
| o3-preview | Texto | Medio | 77.1% | 57% (total) | 28% |
| o3-preview | Visual | Medio | 5.6% | 27% (en salidas incorrectas) | Información no disponible en las fuentes |
| o3-preview | Visual + Python | Medio | 29.2% | Información no disponible en las fuentes | Información no disponible en las fuentes |
| Humanos | Ambas | N/A | 73% | 90% | 8% |
*Nota: Los datos de reglas se basan en la comparación entre o3 y humanos. Los datos del resto de modelos no están disponibles en las fuentes proporcionadas.*
Allá de la Precisión: La Importancia del Análisis Semántico de las Reglas
La conclusión más significativa y transformadora del estudio radica en su crítica implícita a la métrica de precisión como única medida de éxito en la inteligencia artificial. Al introducir el análisis detallado de las reglas en lenguaje natural generadas por los modelos, el estudio demuestra que la respuesta a la pregunta «¿Los modelos de IA realizan un razonamiento abstracto con rasgos humanos?» no puede reducirse a un simple porcentaje de acierto.
Este enfoque dual, que combina la métrica de precisión (`pass@1`) con un análisis semántico cualitativo de las reglas, ofrece una ventana mucho más profunda y fiel a la naturaleza del razonamiento del modelo. El hallazgo principal es que existe una desconexión notable entre la capacidad de un modelo para generar una salida numérica o gráfica correcta y su capacidad para articular una justificación conceptual que coincida con la intención del creador del problema.
En la modalidad textual, donde el `o3-preview` alcanzó una alta precisión del 77.1%, el análisis de reglas expuso una tendencia preocupante hacia el uso de atajos superficiales. Un atajo superficial es una regla que funciona para resolver un problema específico, pero que se basa en características irrelevantes o accidentales del ejemplo de entrada, en lugar de capturar el principio abstracto subyacente. Por ejemplo, un modelo podría aprender que en todas las tareas de entrenamiento donde la respuesta es «rojo», la entrada contiene un patrón de píxeles específico en la esquina superior izquierda. Si aplica esta regla para resolver una nueva tarea, podría obtener una respuesta correcta por casualidad, pero su «razonamiento» sería erróneo.
El estudio encontró que cerca del 28% de las respuestas correctas del `o3-preview` se basaban en estas reglas «correct-unintended» (cuya traducción sería: correcto, pero no por las razones adecuadas). Esto implica que la alta precisión en texto no es necesariamente un indicador de una comprensión genuina, sino potencialmente el resultado de un modelado exitoso de patrones secundarios en los datos de entrenamiento. En contraste, los humanos utilizaron reglas correctas e intencionadas en un 90% de sus respuestas correctas, mostrando una conexión mucho más sólida entre su proceso de pensamiento y la solución.
Este análisis semántico es aún más revelador en la modalidad visual. Aquí, la precisión de casi todos los modelos es mínima. El `o3-preview` pasó de un 77.1% en texto a un 5.6% en visual, un descenso vertiginoso.
Sin embargo, el análisis de sus reglas generadas durante esta modalidad muestra que, aunque fracasan en la aplicación práctica, a menudo comprenden la regla abstracta en teoría. Se encontró que hasta el 27% de las veces que el `o3-preview` fallaba en la visualización, su regla escrita era correcta e intencionada. Esto sugiere que el problema no siempre es una falta total de comprensión abstracta, sino una incapacidad para mapear esa comprensión abstracta a la representación visual específica de la tarea.
Este hallazgo es crucial porque invierte la interpretación habitual de los resultados. En lugar de ver un fallo absoluto en la modalidad visual, el análisis de reglas revela una capacidad de abstracción parcial que sería completamente invisible si solo se evaluara por la precisión de la salida. Esto lleva a la conclusión de que la métrica de precisión de salida subestima el verdadero potencial de razonamiento abstracto de los modelos en esta modalidad.
Esta distinción tiene profundas implicaciones para la evaluación futura de la IA. Sugiere que cualquier benchmark que aspire a medir la inteligencia artificial de verdad debe incorporar obligatoriamente un componente de explicabilidad. Simplemente preguntar «¿Cuál es la respuesta?» es insuficiente. Es necesario seguir preguntando «¿Por qué crees que esa es la respuesta?» y analizar la coherencia y la profundidad de esa justificación.
El marco propuesto por los autores, evaluar simultáneamente la precisión y la calidad semántica de las reglas, es un paso fundamental en esta dirección. Al hacerlo, el estudio no solo critica la métrica de precisión, sino que también proporciona una hoja de ruta para una investigación más matizada y efectiva. Nos ayuda a entender no solo *si* los modelos pueden resolver problemas, sino *cómo* lo hacen, permitiéndonos identificar sus puntos fuertes y débiles con mayor claridad y dirigir el desarrollo futuro de la IA hacia una comprensión más robusta y menos dependiente de atajos superficiales.

Ejemplos de reglas que parecen correctas, pero no lo son del todo. En la parte superior: el modelo o3, usando un esfuerzo y herramientas promedio, resuelve una tarea sobre “horizontal vs. vertical”. Pero en lugar de entender que debe relacionar la forma con su orientación, se fija solo en si hay un píxel azul (el número 8). Esta regla funciona por casualidad en ese caso, pero fallaría si cambiamos los colores o la posición. En el centro: o3 intenta resolver una tarea de “forma completa”. En vez de captar que debe copiar la forma principal (el prototipo gris), se queda atrapado en detalles de los ejemplos de entrenamiento. Crea una regla muy específica, basada en colores y patrones que solo funcionan para esos casos, no para otros similares. Abajo: Claude Sonnet 4 enfrenta una tarea 3D de “superior vs. inferior”. No entiende qué significa “más abajo” en una pila tridimensional. En su lugar, usa un truco: busca la figura con más píxeles juntos (densidad). Esto puede dar buenos resultados en algunos casos, pero no es lo que realmente se pide, y en otras situaciones, como cuando hay figuras superpuestas, esta estrategia falla completamente.
Herramientas Externas y Esfuerzo de Razonamiento: Factores Clave en el Rendimiento
El estudio explora activamente dos variables adicionales que podrían influir en el rendimiento de los modelos de IA: el uso de herramientas externas y el nivel de esfuerzo de razonamiento asignado. Estos factores son cruciales para entender no solo el estado actual de la tecnología, sino también el potencial para mejorar el razonamiento abstracto de los modelos y la naturaleza de las tareas que pueden manejar. La primera variable, las herramientas externas, se aborda principalmente a través de la integración de un entorno de programación Python. La segunda, el esfuerzo de razonamiento, se manipula ajustando el presupuesto de tokens (número máximo de palabras que el modelo puede generar) para llegar a una solución.
La inclusión de un entorno de Python como herramienta externa tuvo un impacto transformador en el desempeño de los modelos, especialmente en la modalidad visual. En la modalidad visual sin herramientas, el `o3-preview` tenía una baja precisión del 5.6%. Sin embargo, cuando se le permitió utilizar Python, su precisión aumentó drásticamente a un 29.2% con un nivel de esfuerzo medio. Este aumento de cinco veces es un testimonio contundente de que los modelos de IA actuales, aunque sean capaces de razonar abstractamente, a menudo se ven superados por la complejidad de aplicar sus conclusiones directamente a una representación visual.
El acceso a un lenguaje de programación les permite externalizar parte del trabajo de implementación, automatizando los pasos de la regla abstracta que han deducido. Pueden escribir scripts para iterar sobre la cuadrícula de entrada, aplicar transformaciones condicionales y construir la cuadrícula de salida paso a paso, mitigando así la dificultad de la tarea de generación directa.
Este hallazgo sugiere que la barrera principal para el razonamiento visual no es la comprensión abstracta en sí, sino la capacidad de ejecutar esa comprensión en un espacio de salida complejo y estructurado. Además, el uso de herramientas externas benefició significativamente el rendimiento en entradas visuales en general, lo que demuestra el valor de una arquitectura híbrida que combine la inteligencia del modelo con la potencia de herramientas especializadas.
La segunda variable, el esfuerzo de razonamiento, se manifiesta a través de la cantidad de tokens que el modelo puede gastar en una tarea. El estudio utiliza diferentes niveles de esfuerzo, desde «bajo» hasta «alto». Los resultados muestran que el aumento del presupuesto de tokens beneficia más a la modalidad textual que a la visual.
En la modalidad textual, el aumento del esfuerzo de razonamiento mejora la precisión del `o3-preview` de un 77.1% a un 75.6% con herramientas, lo que indica que incluso con más tiempo para «pensar», la ventaja sigue estando en el formato simbólico. Esto contrasta con la modalidad visual, donde el aumento del esfuerzo de razonamiento, combinado con el uso de herramientas, parece tener un impacto más profundo, posiblemente porque permite al modelo explorar más secuencias de pensamiento o scripts de Python antes de tomar una decisión final.
Además del uso de herramientas externas, el estudio también menciona la técnica de cadena de pensamientos (Chain-of-Thought, CoT), que es otra forma de aumentar el esfuerzo de razonamiento. CoT descompone una tarea compleja en una serie de pasos lógicos intermedios, simulando un razonamiento humano más deliberado. Si bien el paper no detalla el uso de CoT como una variable de prueba, sí lo menciona en el contexto de métodos de mejora.
Un estudio similar sobre CONSTRUCTURE encontró que la adición de CoT de pocos ejemplos elevó el puntaje promedio de GPT-4o de 0.498 a 0.699, demostrando el potencial de esta técnica para mejorar el razonamiento. El uso de CoT, junto con el presupuesto de tokens, representa una forma de forzar al modelo a un razonamiento más explícito y menos impulsivo. El hallazgo de que el mayor esfuerzo de razonamiento favorece más la entrada textual sugiere que el modelo ya está optimizado para trabajar en ese dominio simbólico y que la externalización (mediante herramientas) o el razonamiento explícito (CoT) son formas de compensar sus debilidades inherentes en otras modalidades.
Finalmente, el costo computacional de este alto esfuerzo es una consideración práctica importante. El estudio estima que la ejecución de una tarea en modo de bajo esfuerzo costó aproximadamente 200 dólares, mientras que el modo de alto esfuerzo ascendió a 20.000 dólares por tarea. Este costo exorbitante refleja la naturaleza intensiva en recursos de los modelos de lenguaje grandes y subraya la brecha económica entre el potencial de investigación y la viabilidad práctica. A pesar de las mejoras en el rendimiento, la escalabilidad de estas técnicas sigue siendo un obstáculo significativo para su aplicación generalizada.
Implicaciones Científicas, Sociales y Tecnológicas del Descubrimiento
El hallazgo de que los modelos de IA actuales no realizan un razonamiento abstracto semejante a lo humano, sino que a menudo dependen de atajos superficiales, tiene profundas y amplias implicaciones que trascienden el campo de la investigación académica. Este descubrimiento no es meramente técnico; afecta a nuestra comprensión de la cognición, a la dirección del desarrollo de la tecnología y a las expectativas sociales sobre el papel de la inteligencia artificial en la vida cotidiana.
La conclusión de que la IA moderna, a pesar de su éxito en tareas de reconocimiento de patrones, carece de una comprensión robusta de conceptos abstractos, es un recordatorio crucial de que estamos lejos de haber alcanzado la inteligencia artificial general (AGI).
Desde una perspectiva científica, este estudio contribuye a una línea de investigación emergente que busca definir y medir la «genuinidad» del razonamiento en la IA. Mientras que benchmarks como el ARC han sido útiles para establecer un punto de referencia en el rendimiento de la IA, el enfoque en el análisis de reglas en lenguaje natural representa un avance metodológico fundamental. Permite a los científicos cognitivos y los investigadores de la IA colaborar de manera más efectiva, utilizando conocimientos sobre cómo los humanos piensan para diseñar mejores pruebas y, a su vez, utilizando los modelos de IA como un laboratorio para probar hipótesis sobre la cognición humana.
El hallazgo de que los modelos son más propensos a atajos superficiales que los humanos no solo revela una debilidad en la IA, sino que también puede ofrecer pistas sobre cómo funcionan las atajos cognitivos en la mente humana. Esta retroalimentación bidireccional es esencial para avanzar en ambas disciplinas. Además, los hallazgos destacan la necesidad de una mayor diversidad y calidad en los conjuntos de datos de entrenamiento para evitar que los modelos aprendan a explotar sesgos y patrones superficiales en lugar de aprender conceptos verdaderos.
En el ámbito tecnológico, las implicaciones son inmediatas y prácticas. Muchas aplicaciones de IA pretenden realizar tareas que requieren un cierto grado de razonamiento y juicio, desde la moderación de contenido hasta la asesoría financiera o médica. Si estos sistemas no están basados en un razonamiento abstracto robusto, sino en la detección de atajos, su fiabilidad y seguridad pueden ser problemáticas.
Podrían funcionar bien en condiciones controladas, pero fallar de manera impredecible cuando se enfrentan a situaciones ligeramente diferentes a las de su entrenamiento, una debilidad conocida como «generalización adversaria». La dependencia de herramientas externas como Python para mejorar el rendimiento en tareas visuales, aunque prometedora, también introduce una capa de complejidad y posible punto de fallo en los sistemas. Por lo tanto, el desarrollo futuro debe centrarse en mejorar la capacidad intrínseca de los modelos para razonar y generalizar, en lugar de depender exclusivamente de la externalización de tareas complejas.
Desde una perspectiva social, este estudio tiene implicaciones significativas para la ética de la IA y las expectativas públicas. Hay una tendencia a suponer que la IA es más inteligente y comprensiva de lo que realmente es, lo que puede llevar a una sobreconfianza en sus decisiones. Este documento aclara que, aunque la IA puede parecer brillante, su «inteligencia» es a menudo frágil y susceptible a errores sutiles. Reconocer estas limitaciones es fundamental para su implementación ética.
Las decisiones críticas que afectan a la vida de las personas deben ser supervisadas por humanos, y los sistemas de IA deben ser diseñados para operar como asistentes, no como autoridades omniscientes. La investigación futura debe priorizar la colaboración entre expertos de la IA, científicos cognitivos, filósofos y sociólogos para asegurar que el progreso tecnológico esté alineado con los valores humanos y nuestras necesidades reales. En última instancia, este estudio no solo nos dice dónde estamos en la carrera hacia la AGI, sino que también nos brinda una guía invaluable sobre cómo debemos caminar hacia allá, con los ojos abiertos a las limitaciones inherentes de nuestra propia creación.
Referencias
Beger, C., Yi, R., Fu, S., Moskvichev, A., Tsai, S. W., Rajamanickam, S., & Mitchell, M. (2025). Do AI Models Perform Human-like Abstract Reasoning Across Modalities? arXiv preprint arXiv:2510.02125.
Chollet, F. (2019). On the measure of intelligence. arXiv preprint arXiv:1911.01547.
Moskvichev, A., Odouard, V. V., & Mitchell, M. (2023). The ConceptARC benchmark: Evaluating understanding and generalization in the ARC domain. Transactions on Machine Learning Research.
LeGris, S., Vong, W. K., Lake, B. M., & Gureckis, T. M. (2024). H-ARC: A robust estimate of human performance on the Abstraction and Reasoning Corpus benchmark. arXiv preprint arXiv:2409.01374.
Chollet, F., Knoop, M., Kamradt, G., Landers, B., & Pinkard, H. (2025). ARC-AGI-2: A new challenge for frontier AI reasoning systems. arXiv preprint arXiv:2505.11831.

