
En la incesante búsqueda por dotar a las máquinas de una inteligencia equiparable a la humana, hemos presenciado avances que hace solo unos años parecían relegados a la ciencia ficción. Los modelos de lenguaje a gran escala (LLM) han aprendido a conversar, a escribir poesía, a generar código informático y a responder preguntas con una fluidez asombrosa. Sin embargo, a pesar de su impresionante elocuencia, una cualidad fundamentalmente humana ha permanecido esquiva: la capacidad de pensar antes de hablar. Los humanos no solo reaccionamos a los estímulos; nos detenemos, reflexionamos, estructuramos nuestros pensamientos, anticipamos consecuencias y luego, solo entonces, formulamos una respuesta. Esta deliberación interna, este «pensamiento de sistema 2», como lo denominó el psicólogo Daniel Kahneman, es el sello distintivo de la cognición profunda.
Hasta ahora, la inteligencia artificial conversacional ha operado mayoritariamente en un modo de «sistema 1»: rápido, intuitivo y reactivo. Responde a nuestras preguntas basándose en los patrones estadísticos aprendidos de ingentes cantidades de texto, pero sin un proceso de razonamiento explícito y estructurado. Esta limitación se hace evidente cuando nos enfrentamos a tareas complejas y abiertas, aquellas que no tienen una única respuesta correcta pero que requieren planificación, creatividad y juicio. Pensemos en redactar el esquema de un ensayo, diseñar un plan de comidas para la semana o idear una estrategia de marketing. En estos dominios, una respuesta instantánea rara vez es la mejor.
Un innovador estudio titulado «Language Models that Think, Chat Better» arroja una luz brillante sobre este desafío y propone una solución tan elegante como efectiva. La investigación parte de una observación crítica: los recientes avances en el razonamiento de la IA se han concentrado en dominios «verificables» como las matemáticas y la programación. En estos campos, se ha enseñado a los modelos a generar una larga «cadena de pensamiento» (Chain-of-Thought o CoT), un monólogo interno donde el modelo desglosa el problema paso a paso antes de llegar a la solución final. El éxito de esta estrategia se mide fácilmente: si la respuesta matemática es correcta o el código se ejecuta sin errores, el razonamiento es recompensado. Este paradigma, conocido como aprendizaje por refuerzo con recompensas verificables (RLVR), ha dotado a las máquinas de una capacidad de razonamiento lógico sin precedentes en estos campos cerrados.
El problema, como señalan los autores, es que esta habilidad no se transfiere bien a los dominios abiertos y ambiguos de la vida cotidiana. Un modelo que es un genio resolviendo ecuaciones diferenciales puede ser sorprendentemente torpe a la hora de dar un consejo matizado o estructurar una narrativa coherente. Las reglas del juego cambian drásticamente cuando no hay una respuesta «correcta» que verificar, sino un espectro de respuestas mejores y peores, cuya calidad es inherentemente subjetiva y depende del contexto.
Aquí es donde el estudio introduce su contribución fundamental: el aprendizaje por refuerzo con pensamiento recompensado por modelos (RLMT). La idea central es audaz y simple: extender el paradigma del pensamiento explícito más allá de las matemáticas y llevarlo al corazón de la conversación general. El método RLMT entrena a los modelos de lenguaje para que, ante cualquier pregunta, primero generen una extensa cadena de pensamiento interna, un plan detallado de cómo van a abordar la respuesta. Y aquí reside la innovación clave: en lugar de una regla matemática, la calidad de la respuesta final es juzgada por un modelo de recompensa, otra IA entrenada para reconocer las preferencias humanas. En esencia, se le dice al modelo: «No te precipites. Tómate tu tiempo para pensar, para planificar. Y si, como resultado de ese pensamiento, produces una respuesta que a los humanos les parece mejor, serás recompensado».
Este enfoque unifica lo mejor de dos mundos. Mantiene la estructura de razonamiento explícito del RLVR, pero la libera de las ataduras de los dominios verificables, permitiendo su aplicación a la infinita variedad de tareas conversacionales. Es un intento de enseñar a las máquinas no solo a hablar, sino a deliberar. Como demuestra la investigación a través de una exhaustiva batería de experimentos con modelos como Llama-3.1 y Qwen-2.5, los resultados de este entrenamiento son extraordinarios. Los modelos entrenados con RLMT no solo mejoran marginalmente; superan de forma consistente y significativa a sus homólogos entrenados con los métodos convencionales. Se vuelven mejores conversadores, mejores escritores creativos, mejores solucionadores de problemas abiertos.
Quizás el hallazgo más sorprendente del estudio es la eficacia de esta técnica incluso cuando se aplica directamente a modelos base, sin el complejo y costoso proceso de ajuste supervisado que normalmente se requiere. Con una fracción de los datos, un modelo base entrenado para pensar puede superar a su versión «Instruct», que ha sido meticulosamente afinada con millones de ejemplos. Este descubrimiento no solo presenta una nueva y poderosa técnica de entrenamiento, sino que nos obliga a repensar toda la arquitectura del «post-entrenamiento» de los modelos de lenguaje. Nos sugiere que enseñar a una máquina a pensar podría ser un atajo mucho más eficiente hacia la inteligencia general que simplemente mostrarle millones de ejemplos de cómo actuar. Este artículo se sumergirá en las profundidades de esta idea revolucionaria, explorando cómo funciona el RLMT, por qué es tan efectivo y qué significa para el futuro de las máquinas que, finalmente, están aprendiendo a pensar antes de hablar.

Dos caminos hacia la inteligencia: RLHF y RLVR
Para apreciar la novedad del enfoque RLMT, es esencial comprender los dos paradigmas dominantes que han guiado el refinamiento de los modelos de lenguaje hasta la fecha. Estos dos caminos, aunque diferentes en su metodología, comparten un objetivo común: alinear el comportamiento de la IA con los objetivos y preferencias humanas.
El primer camino, y el más conocido en el ámbito de los chatbots conversacionales, es el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). Este proceso, que fue fundamental para el éxito de modelos como ChatGPT, es una especie de adiestramiento digital basado en la opinión humana. El proceso comienza con la recopilación de un vasto conjunto de datos de preferencias. A los humanos se les presentan dos respuestas diferentes de un modelo a la misma pregunta y se les pide que elijan cuál es mejor. Esta colección de juicios («prefiero A sobre B») se utiliza para entrenar un «modelo de recompensa». Este segundo modelo aprende a predecir qué tipo de respuesta es probable que un humano prefiera, asignando una puntuación numérica a cualquier respuesta dada.
Una vez que se tiene este árbitro artificial, comienza el aprendizaje por refuerzo. El modelo de lenguaje principal genera respuestas a una variedad de preguntas. Cada respuesta es evaluada por el modelo de recompensa, que le otorga una puntuación. Si la puntuación es alta, los parámetros internos del modelo de lenguaje se ajustan para hacer más probable ese tipo de respuesta en el futuro. Si la puntuación es baja, se ajustan para hacerlo menos probable. A través de millones de estos ciclos de generación y recompensa, el modelo aprende gradualmente a producir respuestas que se alinean con los gustos y preferencias codificados en el modelo de recompensa. El RLHF es, en esencia, un método para enseñar buenos modales y utilidad general, pero no se enfoca explícitamente en el proceso de razonamiento subyacente. La respuesta simplemente «aparece», y es la calidad de este producto final lo que se juzga.
El segundo camino, que ha ganado una enorme tracción en los últimos tiempos, es el aprendizaje por refuerzo con recompensas verificables (RLVR). Este enfoque se centra en dominios donde la corrección no es una cuestión de opinión, sino un hecho objetivo. Las matemáticas, la lógica y la programación son los ejemplos perfectos. En estos campos, una respuesta es correcta o incorrecta, sin ambigüedad.
El RLVR introduce un paso crucial que falta en el RLHF: la cadena de pensamiento (CoT). Antes de dar la respuesta final, se le pide al modelo que «muestre su trabajo», que externalice su proceso de razonamiento en una serie de pasos lógicos. Por ejemplo, para resolver un problema matemático, primero escribiría los pasos para desglosar el problema, luego las ecuaciones que va a utilizar, los cálculos intermedios y, finalmente, la solución. La recompensa en este paradigma no proviene de un modelo de opinión subjetiva, sino de un verificador automático. Este verificador puede ser tan simple como comparar la respuesta final del modelo con la solución correcta, o tan complejo como ejecutar un conjunto de pruebas unitarias sobre el código que ha generado. Si la respuesta es correcta, todo el proceso de pensamiento que condujo a ella es recompensado, reforzando esas vías neuronales para futuros problemas.
El RLVR ha demostrado ser increíblemente poderoso para mejorar las capacidades de razonamiento de los modelos en estos dominios estructurados. Ha sido la fuerza impulsora detrás de modelos como DeepSeek-R1, que han alcanzado niveles de rendimiento en matemáticas y codificación que antes se consideraban inalcanzables. Sin embargo, su dependencia de un verificador objetivo es tanto su mayor fortaleza como su mayor limitación. El mundo real, en su mayor parte, no es verificable. No hay una «solución correcta» para escribir un poema, consolar a un amigo o negociar un acuerdo comercial. Y es aquí donde el RLVR tradicional se detiene, incapaz de aplicar su poderoso mecanismo de pensamiento a la vasta mayoría de las interacciones humanas.
La síntesis: cómo funciona el RLMT
El aprendizaje por refuerzo con pensamiento recompensado por modelos (RLMT) emerge como una brillante síntesis de estos dos paradigmas. Su objetivo es tomar el poder del razonamiento explícito del RLVR y aplicarlo a la amplitud de los dominios conversacionales del RLHF. Lo logra combinando los elementos centrales de ambos en un nuevo y unificado marco de entrenamiento.
El proceso de RLMT se desarrolla de la siguiente manera: al igual que en el RLVR, se le pide al modelo de lenguaje que, ante una pregunta, no genere inmediatamente una respuesta. En su lugar, debe producir primero una cadena de pensamiento. Pero a diferencia del RLVR, donde las preguntas se limitan a las matemáticas o al código, en el RLMT las preguntas son diversas y abiertas. Pueden ser cualquier cosa que un usuario le preguntaría a un chatbot: «Ayúdame a planificar unas vacaciones en Italia», «Explica la teoría de la relatividad como si tuviera cinco años» o «¿Cuáles son los pros y los contras de la energía nuclear?».
Para estas preguntas abiertas, el modelo genera un plan interno. Por ejemplo, para la pregunta sobre las vacaciones, el pensamiento podría ser: «1. Identificar las preferencias del usuario: presupuesto, duración, intereses. 2. Sugerir un itinerario geográfico: norte, centro, sur. 3. Detallar actividades para cada región: arte, comida, naturaleza. 4. Estructurar la respuesta: introducción, itinerario día por día, consejos prácticos». Este monólogo interno es la fase de «pensamiento».
Una vez que el pensamiento está completo, el modelo genera la respuesta final basándose en ese plan. Y aquí es donde el RLMT se aleja del RLVR y se acerca al RLHF. Como no hay una respuesta «correcta» para verificar, la calidad de la respuesta final es evaluada por un modelo de recompensa entrenado en preferencias humanas, exactamente el mismo tipo de árbitro utilizado en el RLHF.
El objetivo de optimización del RLMT es, por lo tanto, maximizar la recompensa esperada de la respuesta final, pero condicionada a la generación previa de una cadena de pensamiento. La fórmula es simple pero poderosa: se recompensa el pensamiento que conduce a buenas respuestas. A través de este proceso, el modelo no solo aprende qué respuestas son buenas, sino también qué procesos de planificación y razonamiento son los que más probablemente conducen a esas buenas respuestas. Aprende a pensar de una manera que sea útil y alineada con las preferencias humanas.
Un aspecto crucial de la implementación del RLMT es el algoritmo de aprendizaje por refuerzo utilizado. El estudio explora varias opciones, incluyendo DPO (Optimización Directa de Preferencias), PPO (Optimización de Políticas Próximas) y GRPO (Optimización de Políticas Relativas a Grupos). Si bien todos funcionan, el estudio encuentra que GRPO, un algoritmo que ha demostrado ser particularmente eficaz en el RLVR, también ofrece los mejores resultados en el marco del RLMT.
Además, el estudio investiga dos formas de enseñar al modelo a adoptar este formato de pensamiento. La primera es un inicio en caliente con SFT (ajuste supervisado). Antes del aprendizaje por refuerzo, el modelo se entrena con un pequeño conjunto de ejemplos de alta calidad que ya incluyen la estructura <pensamiento>...</pensamiento> <respuesta>...</respuesta>. Estos ejemplos se generan utilizando un modelo «profesor» más grande, como Gemini 2.5 Flash de Google. Esto le da al modelo una plantilla inicial de cómo se espera que piense.
La segunda, y quizás más revolucionaria, es el entrenamiento «cero». En este caso, el RLMT se aplica directamente a un modelo base, uno que solo ha pasado por la fase de pre-entrenamiento y no ha recibido ningún ajuste de instrucciones. Simplemente se le indica en el prompt inicial que debe pensar antes de responder. Sorprendentemente, el modelo es capaz de aprender a generar un razonamiento coherente y útil desde cero, guiado únicamente por la señal de recompensa. Este hallazgo sugiere que la capacidad de pensar y planificar podría ser una habilidad latente en los modelos base, esperando ser despertada por el incentivo correcto.

Los frutos del pensamiento: resultados experimentales
La prueba definitiva de cualquier nueva metodología de entrenamiento reside en su capacidad para producir modelos demostrablemente mejores. Los autores de «Language Models that Think, Chat Better» sometieron a sus modelos entrenados con RLMT a una rigurosa evaluación en una amplia gama de benchmarks, comparándolos sistemáticamente con modelos entrenados mediante métodos estándar de RLHF. Los resultados no son solo positivos; son transformadores, especialmente en las áreas que más se benefician del razonamiento y la planificación.
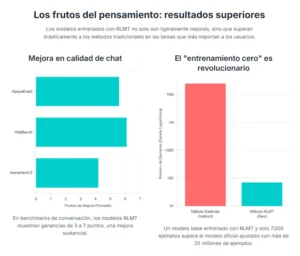
El dominio donde el RLMT brilla con más intensidad es en el chat de propósito general. En benchmarks ampliamente reconocidos como AlpacaEval2 y WildBench, que miden la calidad conversacional en una variedad de temas del mundo real, los modelos RLMT superaron a sus contrapartes RLHF por márgenes sustanciales, logrando mejoras de entre 3 y 7 puntos porcentuales. Esto es una diferencia significativa en un campo donde las ganancias suelen ser incrementales. La capacidad de planificar la respuesta, de estructurar los argumentos y de considerar diferentes ángulos antes de escribir, se traduce directamente en conversaciones más coherentes, útiles y satisfactorias para el usuario. El mejor modelo de 8 mil millones de parámetros entrenado con RLMT no solo superó a modelos mucho más grandes como Llama-3.1-70B, sino que incluso llegó a rivalizar y en algunos casos superar a gigantes como GPT-4o y Claude-3.7-Sonnet en estas tareas de conversación.
La mejora no se limitó al chat. En la escritura creativa, una tarea inherentemente abierta que exige estructura y coherencia, los modelos RLMT también mostraron ganancias significativas, con mejoras de 1 a 3 puntos en el benchmark Creative WritingV3. La fase de pensamiento permite al modelo esbozar la trama, desarrollar los personajes o planificar la estructura de un poema antes de empezar a escribir, lo que resulta en piezas más pulidas y elaboradas.
Un hallazgo particularmente revelador provino de la comparación con otros modelos de «pensamiento» entrenados exclusivamente en dominios verificables como las matemáticas. Cuando estos especialistas en matemáticas fueron puestos a prueba en benchmarks de chat general, su rendimiento fue notablemente bajo, a menudo peor que los modelos estándar ajustados por instrucciones. Esto confirma la hipótesis inicial del estudio: el razonamiento aprendido en dominios cerrados no se generaliza bien. En contraste, los modelos RLMT, entrenados para pensar en dominios abiertos, no solo destacaron en el chat, sino que también mantuvieron o incluso mejoraron ligeramente su rendimiento en tareas de conocimiento general y seguimiento de instrucciones, demostrando una generalización mucho más amplia.
Quizás el resultado más impactante es el éxito del entrenamiento «cero». Un modelo base de Llama-3.1-8B, entrenado directamente con RLMT utilizando solo 7,000 ejemplos de prompts, logró superar al modelo oficial Llama-3.1-8B-Instruct. Es crucial entender la magnitud de este logro. El modelo oficial «Instruct» es el resultado de un complejo proceso de post-entrenamiento de varias etapas que utiliza más de 25 millones de ejemplos. El hecho de que un entrenamiento enfocado en el pensamiento, con una fracción minúscula de los datos, pueda producir un modelo superior sugiere que «enseñar a pensar» es una estrategia de alineación mucho más eficiente en términos de datos que simplemente «enseñar a imitar».
El estudio también profundizó en el «cómo» de estas mejoras. Un análisis cualitativo de las cadenas de pensamiento reveló una fascinante evolución en el estilo de razonamiento del modelo después del entrenamiento con RLMT. Mientras que el modelo inicial (solo con SFT) tendía a generar planes lineales, similares a una lista de verificación, el modelo final entrenado con RLMT exhibía estrategias de planificación mucho más sofisticadas. Enumeraba restricciones, agrupaba ideas en temas comunes, exploraba casos límite e incluso revisaba y refinaba partes anteriores de su plan de forma iterativa. En esencia, el modelo no solo aprendió a hacer un plan, sino que aprendió a hacer un buen plan, adoptando estrategias que reflejan las de los buenos escritores y pensadores humanos. Además, se observó que a medida que avanzaba el entrenamiento, la longitud y la complejidad tanto de la fase de pensamiento como de la respuesta final aumentaban, en un claro signo de que el modelo ganaba confianza en sus propias capacidades deliberativas.
Repensando el futuro: un nuevo paradigma para la IA
Los descubrimientos presentados en «Language Models that Think, Chat Better» no son meramente una mejora incremental en las técnicas de entrenamiento de la inteligencia artificial. Representan un cambio conceptual que podría tener profundas implicaciones para la trayectoria futura del campo, tanto desde una perspectiva científica y tecnológica como social.
Desde el punto de vista científico, este trabajo desafía la concepción tradicional del post-entrenamiento de los modelos de lenguaje. El paradigma dominante ha sido una progresión lineal: pre-entrenamiento masivo, seguido de un ajuste supervisado a gran escala y, finalmente, un refinamiento a través de RLHF. El éxito del entrenamiento «cero» con RLMT sugiere que esta compleja y costosa tubería podría no ser la única, ni siquiera la más eficiente, para lograr la alineación. Plantea la posibilidad de que la capacidad de razonamiento y planificación sea una habilidad más fundamental y generalizable que el simple seguimiento de instrucciones. Enseñar a un modelo el proceso de cómo llegar a una buena respuesta podría ser más poderoso que simplemente mostrarle millones de ejemplos de buenas respuestas. Esto abre nuevas y emocionantes vías de investigación sobre la naturaleza de la inteligencia y el aprendizaje en estos sistemas artificiales.
Tecnológicamente, las implicaciones son inmensas. La eficiencia del RLMT podría reducir drásticamente los recursos computacionales y de datos necesarios para alinear los modelos de lenguaje, democratizando el acceso a la IA de alto rendimiento. Las empresas y los desarrolladores podrían ser capaces de crear chatbots y asistentes altamente capaces sin necesidad de invertir en la curación de gigantescos conjuntos de datos de ajuste. Además, la naturaleza explícita del proceso de pensamiento ofrece una ventaja crucial en términos de interpretabilidad y seguridad. Al externalizar su plan, el modelo nos da una ventana a su «mente». Podemos ver por qué está a punto de dar una respuesta determinada. Esto permite la supervisión, la depuración y la intervención de una manera que es imposible con los modelos de «caja negra» que simplemente producen una salida. Podríamos, por ejemplo, entrenar a los modelos para que se detengan y pidan ayuda si su plan de pensamiento contiene elementos peligrosos o poco éticos.
La relevancia social de tener una IA que piensa antes de hablar es quizás la más importante de todas. A medida que integramos estos sistemas en roles cada vez más críticos en la sociedad, desde la atención al cliente y la educación hasta el asesoramiento legal y médico, la calidad de su deliberación se vuelve primordial. Queremos una IA que no solo nos dé la respuesta más probable estadísticamente, sino la más considerada, matizada y reflexiva. Un médico de IA que piensa explícitamente en los síntomas, las posibles diagnosis diferenciales y los pros y los contras de cada tratamiento antes de hacer una recomendación es inherentemente más confiable que uno que simplemente emite un diagnóstico instantáneo.

En conclusión, este estudio nos ofrece un vistazo a una nueva clase de modelos de lenguaje: aquellos que no solo son conversadores elocuentes, sino también pensadores deliberados. El RLMT proporciona una receta práctica y sorprendentemente eficaz para cultivar esta habilidad, uniendo el rigor del razonamiento verificable con la flexibilidad de la conversación abierta. Los resultados sugieren que al enseñar a las máquinas a emular uno de los aspectos más profundos de la cognición humana, la reflexión antes de la acción, no solo las hacemos más inteligentes en los benchmarks, sino que las hacemos fundamentalmente mejores, más seguras y más útiles para la humanidad. El futuro de la IA conversacional podría no depender de cuántos datos más podamos darle, sino de cuán bien podamos enseñarle el antiguo arte de pensar antes de hablar.
Referencias
Bhaskar, Adithya et al. (2025) Language Models that Think, Chat Better. Arxiv 2509.20357
Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V., Liu, A., Dziri, N., Lyu, X., Gu, Y., Malik, S., Graf, V., Hwang, J. D., Yang, J., Le Bras, R., Tafjord, O., Wilhelm, C., Soldaini, L., Smith, N. A., Wang, Y., Dasigi, P., & Hajishirzi, H. (2025). Tülu 3: Pushing frontiers in open language model post-training. En Second Conference on Language Modeling.
Lin, B. Y., Deng, Y., Chandu, K. R., Ravichander, A., Pyatkin, V., Dziri, N., Le Bras, R., & Choi, Y. (2025b). WildBench: Benchmarking LLMs with challenging tasks from real users in the wild. En ICLR.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., ichter, b., Xia, F., Chi, E. H., Le, Q. V., & Zhou, D. (2022). Chain of thought prompting elicits reasoning in large language models. En Advances in Neural Information Processing Systems.
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., & Irving, G. (2020). Fine-tuning language models from human preferences.

