
La inteligencia artificial ha experimentado una transformación radical en los últimos años, pasando de procesar información de un solo tipo a integrar y comprender simultáneamente múltiples flujos de datos. Este salto cualitativo, conocido como inteligencia multimodal, permite a las máquinas analizar no solo el texto, sino también imágenes, audio y video, abriendo un nuevo horizonte de posibilidades.
Los Modelos Multimodales de Lenguaje Grande (MLLM) son los protagonistas de esta revolución, combinando la capacidad de razonamiento semántico de los modelos de lenguaje grandes (LLM) con la percepción sensorial. Sin embargo, a medida que estos sistemas se vuelven más complejos y omnipresentes, surge una pregunta crítica: ¿cómo podemos asegurarnos de que funcionan correctamente? ¿Son capaces de comprender la información visual y auditiva con la misma profundidad y precisión que los humanos?
Este es el núcleo del desafío que enfrenta la comunidad científica. La necesidad de evaluar con rigor la comprensión audiovisual de los MLLM ha dado lugar a proyectos pioneros como OmniVideoBench, un esfuerzo colaborativo que reúne a investigadores de algunas de las instituciones más prestigiosas para construir un estándar de oro en la evaluación de la inteligencia multimodal. Este informe explora en profundidad el contexto tecnológico, la metodología innovadora y la relevancia trascendental de este benchmark, explorando cómo su desarrollo impactará no solo en la investigación, sino en sectores tan diversos como la educación, la salud y la creación de contenido.
El nuevo paradigma de la inteligencia artificial
Para comprender la importancia de benchmarks como OmniVideoBench, es fundamental primero entender el ecosistema tecnológico en el que operan. La era digital nos ha sumergido en un torrente incesante de información heterogénea, donde el significado reside no solo en las palabras, sino en la interacción entre texto, imágenes, sonidos y movimientos. La inteligencia artificial tradicional, centrada en el procesamiento del lenguaje natural (NLP), ha sido históricamente un modelo «unimodal», incapaz de integrar estos diferentes tipos de datos de forma coherente. Un gran modelo de lenguaje (LLM) puede generar texto fluido, pero carece de la capacidad de ver o escuchar.
Los Modelos Multimodales de Lenguaje Grande (MLLM) representan una evolución fundamental que rompe con esta barrera. Estos sistemas están diseñados para procesar y generar datos de diversas modalidades: texto, imagen, audio y video. Su objetivo es simular una comprensión más holística y humana de la realidad. Por ejemplo, mientras que un LLM podría describir una pintura basándose únicamente en su título y una breve sinopsis textual, un MLLM puede analizar directamente la imagen de la Mona Lisa, reconocer sus características visuales, interpretar su técnica y relacionarlas con el contexto histórico, todo ello dentro de una sola arquitectura.
Ejemplos emblemáticos de esta nueva generación de IA incluyen GPT-4o de OpenAI, Gemini de Google y Qwen3-Omni, cada uno con capacidades específicas en la fusión de modos. Esta capacidad tiene implicaciones prácticas masivas, desde asistentes virtuales que pueden responder a consultas sobre lo que ven en una pantalla hasta vehículos autónomos que deben interpretar señales de tráfico y el entorno en tiempo real.
La arquitectura subyacente de un MLLM es notablemente sofisticada. No se trata simplemente de conectar un modelo de lenguaje con un modelo de visión por computadora. En su núcleo, un MLLM integra componentes especializados para cada tipo de dato. Para la visión, utiliza codificadores como redes neuronales convolucionales (CNN) o transformadores de parches (ViT) para convertir matrices de píxeles en vectores numéricos llamados «incrustaciones» (embeddings).
Para el audio, puede emplear modelos como Whisper, y para el texto, modelos como BERT o los propios LLMs como base. El mayor desafío reside en el siguiente paso: la alineación y fusión. Aquí es donde entra en juego el componente clave conocido como «proyector», «conector» o «adaptador». Su función es mapear las incrustaciones de diferentes modalidades a un espacio de representación compartida, permitiendo que el modelo base de lenguaje interactúe con la información visual y auditiva como si fueran palabras más.
Técnicas como el aprendizaje contrastivo, popularizado por el modelo CLIP de OpenAI, entrenan al sistema a asociar pares coincidentes (una imagen y su descripción correcta) y separar pares no coincidentes, forjando así conexiones firmes entre los diferentes dominios de datos.
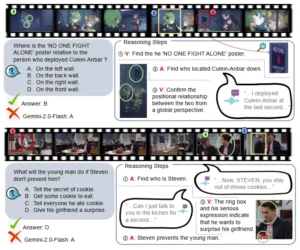
Ejemplo de OmniVideoBench, un test para evaluar si los modelos entienden videos largos con imagen y audio a la vez.
-
Arriba se ven preguntas de opción múltiple sobre escenas de un video y globos que separan las pistas visuales (V) y de audio (A) usadas para razonar. El modelo mostrado falla en ambas preguntas.
-
Abajo, los puntos clave: hoy los modelos rinden mal en este benchmark; ninguno supera 60% y muchos quedan casi al azar. El desempeño empeora en videos largos y varía según el tipo de audio (música, sonido, voz). También cambia según la tarea: fondo, música y relaciones entre personajes resultan especialmente difíciles.
Este paradigma multimodal ya está comenzando a tener un impacto profundo en la sociedad.
En el campo de la salud, modelos como Med-PaLM 2 de Google demuestran una precisión superior al 85% en exámenes médicos simulados, analizando imágenes y textos clínicos para ayudar en el diagnóstico. En la industria creativa, plataformas como Midjourney o Runway utilizan la generación de imágenes a partir de texto para democratizar el arte y el diseño.
Y en la academia, herramientas como Socratic de Google actúan como tutores virtuales 24/7, respondiendo preguntas sobre ciencia y matemáticas. Sin embargo, esta rápida adopción también expone vulnerabilidades críticas. Los modelos pueden cometer errores graves, denominados «alucinaciones», generando información plausible pero falsa, o reflejar sesgos presentes en los datos de entrenamiento.
Además, son extremadamente exigentes desde el punto de vista computacional y requieren enormes cantidades de datos para entrenarse. Por ello, el desarrollo de métodos rigurosos y estandarizados para evaluar su rendimiento, como OmniVideoBench, no es un ejercicio puramente académico, sino una necesidad imperativa para garantizar la fiabilidad, seguridad y equidad de estas tecnologías emergentes.
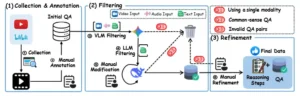
El proceso completo de recopilación, anotación y refinamiento de datos, donde el filtrado y el refinamiento son dos procesos clave para el control de calidad. Las tareas de resumen representan más del 80 %.
Orígenes y limitaciones de los benchmarks existentes
Si bien la tecnología de los MLLM avanza a un ritmo vertiginoso, la capacidad de medir su progreso y comparar diferentes enfoques ha quedado rezagada. Durante mucho tiempo, la comunidad de investigación ha dependido de conjuntos de datos y benchmarks que, aunque valiosos, resultaron ser insuficientes para capturar la verdadera gama de habilidades cognitivas de estos modelos avanzados.
Estos benchmarks tempranos, como MME y LVLM-eHub, fueron fundamentales para establecer un punto de partida, pero pronto se revelaron limitados en varios frentes cruciales. Su principal debilidad radicaba en su naturaleza fragmentada y superficial. Generalmente, consistían en tareas de respuesta a preguntas visuales (VQA) basadas en imágenes o videos cortos, evaluando la capacidad de un modelo para identificar objetos, leer texto o realizar inferencias simples. Si bien útiles para medir habilidades básicas, estos tests no podían evaluar la comprensión narrativa, la continuidad temporal o la capacidad de razonar sobre eventos complejos que ocurren a lo largo de largos períodos.
El salto cualitativo hacia la evaluación de video marcó un hito, pero incluso aquí surgieron nuevas limitaciones. Benchmarks como Video-MME y LVBench intentaron extender la evaluación a secuencias de video más largas, pero a menudo se centraban en segmentos de duración moderada o en tareas muy específicas, como el reconocimiento de acciones. Esto dejaba fuera una gran cantidad de competencias importantes, como la comprensión de la trama de una película completa, la detección de sutiles cambios emocionales a lo largo de una conversación o el seguimiento de múltiples hilos argumentales. La necesidad de un marco más ambicioso se hizo evidente, dando lugar al desarrollo de benchmarks de video más robustos.
Uno de los más destacados es ALLVB (ALL-in-One Long Video Understanding Benchmark), liderado por investigadores chinos. Este conjunto de datos representa un avance significativo, ya que consta de 1.376 películas completas con una duración promedio de casi dos horas cada una, lo que suma más de 252.000 preguntas y respuestas. Utiliza una tubería automatizada que emplea GPT-4o para generar preguntas a partir de los guiones de las películas, cubriendo 91 sub-tareas de comprensión de video.
Sin embargo, incluso ALLVB, por su magnitud y ambición, presenta sus propias limitaciones. Primero, su énfasis exclusivo en películas de ficción significa que carece de diversidad temática, excluyendo categorías como deportes, documentales educativos o videos virales, que podrían presentar desafíos diferentes para los modelos de IA. Segundo, los resultados obtenidos en este benchmark son cautelosamente optimistas; incluso el modelo más potente evaluado, Claude 3.5 Sonnet, alcanzó una precisión media de solo el 75,2%, lo que indica que aún queda un amplio margen de mejora en la comprensión de video a largo plazo.
Otro ejemplo de benchmark de video es Video-Bench, desarrollado por un consorcio internacional de universidades y centros de investigación. Este benchmark se enfoca en la evaluación de la calidad de los *modelos generativos de video*, no de la comprensión. Evalúa videos sintetizados a partir de texto en varias dimensiones, como la calidad de imagen, la coherencia temporal y la alineación con la descripción textual. Utiliza técnicas ingeniosas como «chain-of-query» (hacer preguntas iterativas sobre el video generado) y «few-shot scoring» (comparar el video con otros generados con el mismo prompt) para superar la ambigüedad de la evaluación visual y lograr una alta correlación con las preferencias humanas.
En resumen, la historia de los benchmarks de IA multimodal es una historia de escalada continua. Desde las primeras evaluaciones de VQA hasta los grandes datasets de video, la comunidad ha buscado constantemente nuevos desafíos para empujar los límites de la inteligencia artificial. Cada benchmark anterior ha sido un precursor, revelando las debilidades de los modelos de su tiempo y sentando las bases para los siguientes. OmniVideoBench emerge en este contexto, consciente de los logros y las deficiencias de estos trabajos previos.
Su objetivo no es simplemente crear otro dataset, sino abordar directamente los principales obstáculos que han impedido un avance más rápido: la falta de datos de calidad, la dificultad de la anotación y la necesidad de una evaluación que sea tanto rigurosa como accesible para una amplia gama de modelos. Es el intento de construir el estándar definitivo para una era en la que la comprensión de la realidad audiovisual será tan importante como la comprensión del lenguaje escrito.
OmniVideoBench: construyendo un estándar de oro para la comprensión audiovisual
OmniVideoBench no es simplemente otro conjunto de datos; es un marco integral diseñado para establecer un nuevo estándar de oro en la evaluación de la comprensión audiovisual de los Modelos Multimodales de Lenguaje (MLLM).
A diferencia de los benchmarks anteriores que a menudo eran fragmentados o se centraban en aspectos muy específicos de la inteligencia multimodal, OmniVideoBench adopta un enfoque audaz y ambicioso: medir la capacidad de los modelos para comprender y razonar sobre la información que se encuentra implícita en el flujo dinámico de un video. Este enfoque reconoce que la comprensión genuina va más allá de la simple detección de objetos o la transcripción de diálogo; implica seguir una trama, entender relaciones causales a lo largo del tiempo, captar matices emocionales y extraer información de fuentes visuales y auditivas complementarias.
El corazón del proyecto OmniVideoBench es su vasto y diverso conjunto de datos, meticulosamente curado para desafiar a los modelos en una amplia gama de habilidades. El benchmark está compuesto por 628 videos reales extraídos de YouTube y Bilibili, con una duración que va desde unos pocos segundos hasta 30 minutos. Estos videos abarcan 8 categorías principales (Vlog, Noticias, Dibujos animados, Deportes, Documentales, Televisión, Grabaciones en primera persona, Ego, y Otros) y se subdividen en 68 subcategorías, garantizando una cobertura temática rica y variada. Esta diversidad es crucial, ya que evita que los modelos se especialicen en un solo tipo de contenido y los obliga a desarrollar una comprensión más generalizable.
A partir de estos videos, el equipo de NJU-LINK construyó 1.000 pares de preguntas y respuestas de alta calidad, cada uno cuidadosamente anotado con cadenas de razonamiento paso a paso. Estas cadenas no solo indican la respuesta correcta, sino que desglosan explícitamente cómo se llegó a ella, especificando en cada paso si la evidencia proviene de la modalidad visual (V) o auditiva (A).
Por ejemplo, una pregunta podría requerir primero identificar un objeto en la escena (V), luego escuchar un diálogo clave (A) y finalmente inferir una relación espacial entre ambos (V+A). Este diseño es revolucionario porque permite a los investigadores no solo evaluar «si» un modelo acierta, sino «cómo» razona, revelando sus fortalezas y debilidades cognitivas de una manera sin precedentes.
Las preguntas en OmniVideoBench están organizadas en 13 tipos de tareas cuidadosamente diseñadas, que van desde la percepción fina y el conteo hasta el razonamiento causal, la inferencia hipotética y la comprensión de la música de fondo. Esta taxonomía exhaustiva asegura que el benchmark capture los desafíos esenciales de la comprensión de video, especialmente aquellos que requieren una integración lógica y coherente de las modalidades de audio y video.
La creación de este conjunto de datos fue un proceso riguroso y multifásico, que combinó la anotación manual con filtros automatizados para garantizar la máxima calidad y evitar que las preguntas pudieran resolverse con una sola modalidad o mediante pistas textuales ocultas.
| Característica | ALLVB (Benchmark de Video Completo) | Video-Bench (Generación de Video) | OmniVideoBench (Propuesto) |
|---|---|---|---|
| Objetivo Principal | Comprensión de video largo (películas) | Calidad y alineación de video generado a partir de texto | Comprensión y razonamiento audiovisual general |
| Dominio de Datos | Películas de ficción | Videos sintetizados de texto a video | Diverso (Vlogs, Noticias, Deportes, Documentales, etc.) |
| Tamaño del Dataset | ~252,000 Q&A en 1,376 películas | 419 prompts, ~70-90 por dimensión | 1,000 Q&A en 628 videos |
| Metodología de Anotación | Generación automática con GPT-4o, validación manual | Evaluación por modelos MLLM (GPT-4o) y humanos | Anotación manual con cadenas de razonamiento, filtros MLLM/LLM |
| Principales Limitaciones | Contenido limitado a películas, alta dificultad para modelos | Foco en la generación, no la comprensión | Ninguna reportada; diseñado para superar las limitaciones anteriores |
Innovaciones metodológicas en el benchmark
El éxito de un benchmark como OmniVideoBench depende menos de la cantidad de datos que de la inteligencia y sofisticación de su metodología de evaluación. El equipo detrás de este proyecto ha implementado un proceso de construcción de datos riguroso y de varias etapas, diseñado para garantizar la máxima calidad y dificultad. El proceso comienza con la anotación manual, donde expertos humanos formulan preguntas de opción múltiple basadas en los videos. Este enfoque es fundamental porque evita el techo de evaluación inherente a los métodos automatizados, que están limitados por las capacidades del propio modelo anotador.
Tras obtener un conjunto inicial de aproximadamente 2.500 pares de preguntas y respuestas, el equipo aplica una serie de filtros de alta precisión. En primer lugar, utilizan un modelo multimodal avanzado (Gemini 2.0 Flash) para eliminar cualquier pregunta que pueda resolverse utilizando únicamente una modalidad (solo visión o solo audio). Luego, emplean un modelo de lenguaje grande con fuertes capacidades de razonamiento (DeepSeek-V3.1) para filtrar preguntas que puedan responderse con conocimiento general o que contengan pistas textuales no intencionadas en las opciones. Finalmente, un equipo de anotadores realiza una revisión manual exhaustiva para garantizar que cada respuesta sea correcta, única y que las opciones de distracción sean relevantes y equilibradas en términos de distancia semántica.
La innovación más destacada de OmniVideoBench es la inclusión de cadenas de razonamiento paso a paso para cada pregunta. Cada paso en esta cadena es atómico y especifica tres elementos: la modalidad (V o A), la evidencia (la información específica extraída del video) y la inferencia (el razonamiento derivado). Este diseño no solo fortalece la fiabilidad de la evaluación, sino que proporciona una señal única para analizar cómo los modelos razonan, en lugar de centrarse únicamente en la respuesta final. Esta transparencia en el proceso de razonamiento es crucial para el desarrollo de modelos más robustos y explicables.
Además, el benchmark está diseñado para evaluar la complementariedad de las modalidades. Muchos videos en el conjunto de datos están seleccionados específicamente porque la información en audio y video es complementaria, no redundante. Por ejemplo, un video puede mostrar a una persona caminando (V), pero el audio revela que está hablando por teléfono (A), y la combinación de ambas pistas permite inferir su estado emocional o intención. Esta exigencia de integración lógica y coherente es lo que hace que OmniVideoBench sea un desafío tan significativo para los modelos actuales.
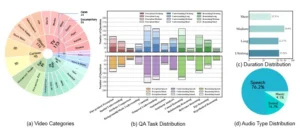
a) OmniVideoBench abarca 8 categorías principales y 68 subcategorías. (b) OmniVideoBench comprende 13 tipos de tareas. La sección superior muestra la distribución de la duración del vídeo en las diferentes tareas, categorizadas en cuatro grupos: «Corto» (menos de 1 minuto), «Medio» (de 1 a 5 minutos), «Largo» (de 5 a 10 minutos) y «Ultralargo» (más de 10 minutos). La sección inferior ilustra la distribución de tres tipos de audio (es decir, voz, sonido y música). (c) Distribución de la duración del vídeo en cuatro intervalos de tiempo. (d) Distribución de tres tipos de audio.
Riesgos, beneficios y el impacto en la educación
La creación de un estándar de oro como OmniVideoBench no es solo un avance técnico, sino una contribución significativa a la gobernanza y el desarrollo responsable de la inteligencia artificial. Al proporcionar una plataforma de evaluación rigurosa y transparente, el benchmark empodera a la comunidad de investigación para identificar, diagnosticar y corregir las fallas de los modelos de IA. Esto tiene profundas implicaciones para la seguridad y la equidad.
Por ejemplo, si un modelo demuestra una tendencia a ignorar ciertos tipos de información visual o a confundir intenciones en situaciones sociales complejas, los desarrolladores pueden utilizar los resultados de OmniVideoBench para dirigir mejor sus esfuerzos de fine-tuning. Esto es vital para prevenir problemas como las alucinaciones, donde el modelo genera información falsa pero convincente, o los sesgos, donde el modelo reproduce estereotipos discriminatorios presentes en sus datos de entrenamiento.
En el ámbito industrial, el impacto de un benchmark de alta calidad es inmediato. Empresas que desean integrar MLLM en sus productos, desde asistentes de voz hasta sistemas de vigilancia, necesitan una forma objetiva de comparar diferentes soluciones. OmniVideoBench ofrecería un terreno de juego común para evaluar el rendimiento de modelos de código abierto como Qwen3-Omni frente a gigantes comerciales como Gemini-2.5-Pro.
Esto fomenta la competencia sana y puede acelerar la innovación al incentivar a todos los participantes a elevar su juego. Además, al definir claramente qué significa «comprensión audiovisual», el benchmark ayuda a establecer expectativas realistas para los usuarios finales, evitando las altas expectativas creadas por marketing exagerado y promoviendo un uso más prudente y efectivo de la tecnología.
Quizás el sector con el potencial más transformador para beneficiarse de los avances impulsados por benchmarks como OmniVideoBench es la educación. La integración de la IA en el aprendizaje ya está demostrando ser revolucionaria. Herramientas como Microsoft Copilot en el distrito escolar de Wichita ayudan a los maestros a preparar planes de lección y corregir trabajos. Plataformas como DreamBox Learning adaptan las lecciones de matemáticas en tiempo real al ritmo del estudiante.
Tutorías inteligentes como Jill Watson en Georgia Tech responden miles de consultas estudiantiles por semestre con una precisión del 97%. Sin embargo, el potencial actual de estas herramientas está limitado por la capacidad de los MLLM para comprender el contenido de forma integral. Imagine un tutor virtual que no solo pueda responder a preguntas sobre un texto, sino que también pueda analizar un diagrama de un átomo, interpretar un gráfico de cambio poblacional y explicar el concepto de fracturas óseas mirando una radiografía médica.
La creación de estándares de evaluación como OmniVideoBench es, por tanto, una parte inseparable de este viaje, asegurando que la tecnología se desarrolle de una manera que no solo sea más inteligente, sino también más segura, equitativa y beneficiosa para todos. Un modelo capaz de superar las pruebas de OmniVideoBench podría revolucionar la educación al crear experiencias de aprendizaje verdaderamente personalizadas y multimodales, donde el contenido se adapta no solo al nivel del estudiante, sino a su estilo de aprendizaje preferido, ya sea visual, auditivo o kinestésico.
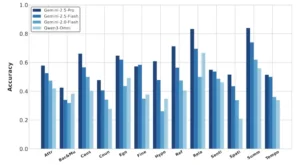
Comparación del rendimiento de algunos modelos Omni de código abierto y cerrado en 13 tareas en OmniVideoBench. Aquí, «Attr«: Comparación de atributos, «Bac&Mu«: Comprensión de música de fondo y música, «Caus«: Razonamiento de causa y efecto, «Coun«: Conteo, «Ego«: Razonamiento egoico, «Fine«: Percepción detallada, «Hypo«: Razonamiento hipotético, «Ref«: Razonamiento referencial, «Rela«: Razonamiento relacional, «Senti«: Análisis de sentimientos, «Spati«: Razonamiento espacial, «Summ«: Resumen, «Tempo«: Comprensión de secuenciación temporal
El camino hacia una inteligencia audible y visible
En conclusión, el desarrollo de benchmarks como OmniVideoBench marca un hito crucial en la evolución de la inteligencia artificial. Representa un reconocimiento maduro de que el futuro de la IA no reside en silos de especialización, sino en la síntesis de conocimientos de múltiples dominios. Al centrarse en la comprensión audiovisual, OmniVideoBench apunta a un pilar fundamental de la experiencia humana y, por extensión, a una de las fronteras más importantes para la inteligencia artificial. Este proyecto no es meramente un ejercicio de medición; es una iniciativa filosófica que busca definir y cuantificar la capacidad de una máquina para «ver» y «escuchar» el mundo.
Los resultados de la evaluación de múltiples MLLM en OmniVideoBench son reveladores. Ningún modelo ha logrado una puntuación de aprobado, con el mejor, Gemini-2.0-Pro, alcanzando apenas un 58,90% de precisión. Los modelos de código abierto se desempeñan cerca del azar, lo que subraya la inmensa dificultad del razonamiento audiovisual genuino. Además, los modelos luchan particularmente con videos que contienen música, donde la información es más abstracta y emocional, y con videos largos, donde mantener el contexto a lo largo del tiempo es un desafío. Estas brechas no son meras curiosidades técnicas; son mapas que señalan el camino a seguir para la investigación futura.
Las implicaciones de este avance son profundas y trascienden el ámbito académico. En el plano social, una IA que comprende el video con la profundidad de un ser humano podría transformar radicalmente campos como la educación, la salud y la accesibilidad. Podría dar lugar a tutores virtuales capaces de explicar conceptos complejos a través de analogías visuales y auditivas, democratizando el conocimiento. En medicina, permitiría el análisis automatizado de registros de ultrasonidos o resonancias magnéticas para detectar patrones sutiles que escaparían a la mirada humana. En el día a día, mejorarían drásticamente las herramientas de accesibilidad, como las transcripciones en tiempo real para personas con discapacidad auditiva o los asistentes visuales para personas con discapacidad visual.
Sin embargo, este camino hacia una inteligencia audible y visible también viene acompañado de desafíos éticos y de seguridad. La capacidad de una IA para interpretar el comportamiento humano a partir de videos eleva las alarmas sobre la vigilancia masiva y la pérdida de privacidad. La responsabilidad de los desarrolladores se intensifica, y la necesidad de marcos regulatorios se vuelve cada vez más imperativa.
Por lo tanto, el valor de OmniVideoBench no se mide únicamente por su capacidad para clasificar modelos. Su verdadero impacto radica en su función como un catalizador para la innovación responsable. Al exponer las lagunas en la comprensión de los MLLM actuales, el benchmark dirige los esfuerzos de investigación hacia donde más se necesita. Sirve como un recordatorio constante de que, aunque hemos construido sistemas capaces de conversar sobre casi cualquier tema textual, todavía estamos en una fase inicial cuando se trata de comprender el mundo en todas sus dimensiones.
La historia de la IA multimodal es una carrera contra la complejidad, y benchmarks como OmniVideoBench son nuestros cronómetros y nuestras pistas de atletismo. Ayudan a medir el progreso, a establecer récords y a inspirar a los próximos campeones a alcanzar nuevas cotas de comprensión.
En última instancia, el éxito de este esfuerzo no se determinará por el número de puntuaciones perfectas, sino por la calidad de las preguntas que inspire y las soluciones que ayude a encontrar, guiando a la humanidad hacia una nueva era de inteligencia, más profunda y más conectada que nunca.
Referencias
NJU-LINK Team. OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs. arXiv:2510.10689 [cs.AI], 12 Oct 2025.
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., & Chen, E. (2024). A survey on multimodal large language models. National Science Review, 11(12), nwae403.
Song, S., Li, X., Li, S., Zhao, S., Yu, J., Ma, J., … & Wang, M. (2025). How to bridge the gap between modalities: Survey on multimodal large language model. IEEE Transactions on Knowledge and Data Engineering, 37(9), 5311–5329.
Cheng, J., Ge, Y., Wang, T., Ge, Y., Liao, J., & Shan, Y. (2025). Video-holmes: Can mllm think like holmes for complex video reasoning? ArXiv, abs/2505.21374.
Xu, W., Wang, J., Wang, W., Chen, Z., Zhou, W., Yang, A., … & Zhu, X. (2025a). Visulogic: A benchmark for evaluating visual reasoning in multi-modal large language models. arXiv preprint arXiv:2504.15279.
Chen, Q., Qin, L., Zhang, J., Chen, Z., Xu, X., & Che, W. (2024a). M 3 cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. arXiv preprint arXiv:2405.16473.
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., … & Chen, W. (2024a). MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9556–9567).
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., & Shan, Y. (2024a). Seed-bench: Benchmarking multimodal large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13299–13308).
Hong, J., Yan, S., Cai, J., Jiang, X., Hu, Y., & Xie, W. (2025). Worldsense: Evaluating real-world omnimodal understanding for multimodal llms. ArXiv, abs/2502.04326.
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., … & Deng, C. (2024a). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
Li, G., Wei, Y., Tian, Y., Xu, C., Wen, J., & Hu, D. (2022). Learning to answer questions in dynamic audio-visual scenarios. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19086–19096.
Gong, K., Feng, K., Li, B., Wang, Y., Cheng, M., Yang, S., … & Yue, X. (2024). AV-Odyssey Bench: Can your multimodal llms really understand audio-visual information? ArXiv, abs/2412.02611.
Li, Y., Zhang, G., Ma, Y., Yuan, R., Zhu, K., Guo, H., … & Lin, C. (2024b). Omnibench: Towards the future of universal omni-language models. ArXiv, abs/2409.15272.
Zhou, Z., Wang, R., & Wu, Z. (2025). Daily-Omni: Towards audio-visual reasoning with temporal alignment across modalities. ArXiv, abs/2505.17862.
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., … & Lin, J. (2025b). Qwen3-omni technical report. arXiv preprint arXiv:2509.17765.
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., … & Dang, K. (2025c). Qwen2.5-omni technical report. arXiv preprint arXiv:2503.20215.
Li, Y., Liu, J., Zhang, T., Chen, S., Li, T., Li, Z., … & Chen, W. (2025). Baichuan-omni-1.5 technical report. ArXiv, abs/2501.15368.
Zhao, J., Yang, Q., Peng, Y., Bai, D., Yao, S., Sun, B., … & Bo, L. (2025). Humanomni: A large vision-speech language model for human-centric video understanding. ArXiv, abs/2501.15111.
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., … & Sun, M. (2024). Minicpm-v: A gpt-4v level mllm on your phone. ArXiv, abs/2408.01800.
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., … & Zhao, D. (2024). Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476.
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., … & Zhang, D. (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261.
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., … & Tang, J. (2025). Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923.
Liu, A. H., Ehrenberg, A., Lo, A., Denoix, C., Barreau, C., Lample, G., … & Muddireddy, P. R. (2025a). Voxtral. arXiv preprint arXiv:2507.13264.

