
Cuando la IA aprende a pensar con presupuesto
La inteligencia artificial vive un momento curioso: ya no alcanza con escribir bonito, ahora se le exige razonar. Empresas, instituciones y medios piden respuestas útiles, justificadas y baratas. Ese “y baratas” es el golpe de realidad. Razonar cuesta cómputo, y el cómputo cuesta dinero. En ese contexto aparece Nemotron Nano 2, la segunda generación de modelos abiertos de NVIDIA orientados a combinar tres elementos que rara vez conviven: eficiencia, control fino del razonamiento y transparencia en datos de entrenamiento. La promesa es concreta: un modelo que permite encender o apagar el razonamiento, graduar cuánto “piensa” según la tarea, absorber documentos largos gracias a una ventana de contexto de 128K y, además, exhibir buena parte de su dieta de entrenamiento para que cualquiera audite, replique o discuta.
Qué es Nemotron Nano 2 y por qué cambia la conversación
Nemotron Nano 2 no pretende ser el modelo más grande ni el más espectacular en benchmarks estáticos. Pretende ser el más gobernable en producción. Su propuesta encaja en una pregunta muy práctica que cualquier CTO o editor jefe se hace: cómo despliego un asistente o un agente que resuelva tareas reales, que pueda explicar de dónde sale lo que dice y que no rompa el presupuesto de la nube. Para eso, la apuesta de NVIDIA tiene tres piezas.
La primera es el control del razonamiento. No todo requiere pensar con varios pasos. Muchas tareas rutinarias (clasificar tickets, extraer campos, responder preguntas frecuentes) se resuelven con inferencias directas. En cambio, otras (auditar logs, investigar fraudes, reconciliar versiones de un mismo documento normativo) sí se benefician de deliberación. Nemotron Nano 2 expone una “perilla” para configurar cuántos pasos de pensamiento se autorizan en cada consulta, y hasta permite desactivar el razonamiento cuando no aporta valor.
La segunda es la ventana de contexto de 128K. No es un número para fanfarronear, sino un habilitante concreto: menos troceo agresivo de documentos largos, menos pérdida de coherencia, más capacidad de conservar memoria en flujos extensos. En prácticas de RAG (retrieval augmented generation), pasar de 8K o 32K a 128K cambia el diseño de prompts, la granularidad de indexación y la calidad de los resúmenes.
La tercera es la transparencia de datos. NVIDIA acompaña el modelo con colecciones de preentrenamiento y post-entrenamiento publicadas en repositorios accesibles. Esto no convierte a Nemotron Nano 2 en un experimento académico puro, pero eleva el listón: ya no se pide fe, se ofrecen insumos para verificación externa. Para sectores regulados o redacciones que trabajan con temas sensibles, esta transparencia importa tanto como el rendimiento.
Arquitectura en detalle: por qué combinar Transformer y Mamba no es un capricho
Los Transformers reinaron porque capturan dependencias globales con una eficacia notable. Su debilidad es conocida: el coste cuadrático de la autoatención, que se vuelve prohibitivo en secuencias largas. Mamba, por su parte, es el apellido popular de una familia de modelos de espacio de estados, que procesan secuencias con una complejidad mucho más cercana a lineal y con menos presión de memoria. Su fuerte son los flujos extensos, los datos en streaming y los contextos donde lo que importa es mantener la continuidad sin recalcular relaciones globales a cada paso.
Nemotron Nano 2 mezcla capas Mamba con un número acotado de capas de atención. La intención técnica es clara: mantener la capacidad de enfocar relaciones complejas allí donde son determinantes, sin pagar el peaje de atención en todos los bloques. El resultado esperado es una mejor relación entre tokens por segundo y costo por token, sobre todo cuando el contexto crece. Para quien construye agentes que leen manuales, normas, historiales de chat o largas trazas operativas, esa eficiencia no es un detalle: es la diferencia entre un prototipo simpático y un sistema que puede quedarse en producción.
Un punto menos comentado pero clave es cómo esta arquitectura habilita patrones de orquestación. Si tus agentes alternan entre fases sin razonamiento y microtramos que precisan deliberación, la ruta Mamba reduce el lastre en el tramo “fácil”, y las pocas capas de atención protegen la precisión en el tramo “difícil”. Es una arquitectura consecuente con el propio concepto de presupuesto de pensamiento.
Presupuesto de pensamiento: la perilla que cambia la economía
La idea de “pensar con presupuesto” merece un capítulo aparte. Veníamos de modelos donde cada consulta incurría en el mismo tipo de razonamiento, porque el usuario no podía controlar esa dimensión con granularidad. Nemotron Nano 2 expone ese control al integrador. El beneficio no se queda en una lámina de PowerPoint: impacta en la economía del sistema.
Imaginemos un contact center con tres colas. La cola oro atiende clientes de alta prioridad y casos con señales contradictorias; allí tiene sentido activar el razonamiento y permitir varios pasos. La cola plata concentra consultas intermedias, con razonamiento moderado. La cola bronce procesa FAQs y trámites simples, con razonamiento mínimo o apagado. Esta segmentación no es una ocurrencia de consultoría: estabiliza los costos mes a mes, evita el sobregasto por defecto y permite medir con claridad cuándo conviene “comprar” pasos extra de pensamiento.
Del lado editorial, la lógica es parecida. Una investigación compleja o una verificación sensible se benefician de razonamiento alto, con recuperación de documentos, citas y contrafácticos. Un boletín de agenda (temas, horarios, sumarios) no amerita la misma inversión. A igualdad de hardware, esa elasticidad cognitiva separa a los modelos que suenan bien en demo de los que sobreviven al cierre de edición.
Ventana de 128K: menos troceo, más continuidad
La ventana de 128K no se come por sí sola los problemas del contexto largo, pero destraba soluciones pragmáticas. En RAG jurídico o financiero, por ejemplo, reducir el troceo de contratos y normativas disminuye la tasa de respuestas que “pierden el hilo”. En analítica operacional, retener un historial amplio de logs y anotaciones en el propio prompt permite diagnósticos y resúmenes que no rompen el contexto cada pocas páginas. Y en flujos de colaboración largos (equipo humano más agente) el modelo puede medir mejor la coherencia entre decisiones y políticas, sin depender tanto de saltos entre resúmenes parciales.
La clave, en cualquier caso, es la ingeniería del pipeline. Una ventana grande es un instrumento, no una garantía. Si la recuperación es ruidosa, si la indexación no distingue relevancia o si el prompt mezcla objetivos, la ventana se convierte en un cajón de sastre que traga tokens. Cuando se diseña con criterio, sin embargo, 128K reduce ese “coste cognitivo” que toda redacción o equipo técnico conoce: el de repetir, cortar y pegar, recomponer.
Datos y transparencia: qué liberó NVIDIA y cómo usarlo
El acompañamiento en datasets es una de las apuestas más interesantes de esta familia. Por un lado, aparece un conjunto de preentrenamiento a escala de billones de tokens que combina web premium, matemáticas, código y bloques multilingües de preguntas y respuestas curados. Por otro, datasets específicos para post-entrenamiento y SFT (fine-tuning supervisado) que cubren STEM, razonamiento, dominios académicos e idiomas. En paralelo, hay tarjetas de modelo y de datos con descripciones de procedencia, deduplicación y licencias.
Para quien construye plataformas con exigencias de cumplimiento, esto abre dos oportunidades. La primera es auditar contenidos: saber qué tipo de textos leyó el modelo y, por tanto, qué sesgos podrían haber ingresado. La segunda es replicar parte del camino: entrenar variantes internas con subsets parecidos, medir regresiones y publicar resultados. Para periodistas y divulgadores, todo esto habilita una crónica más responsable. No alcanza con decir “la IA aprendió”, también hay que poder contar “de qué aprendió”.
Rendimiento y costo: números, matices y gráficos
Las comunicaciones alrededor de Nemotron Nano 2 ponen el foco en dos cifras que son fáciles de recordar: generación de tokens hasta seis veces mayor que su predecesor y reducción del sesenta por ciento en el costo del razonamiento. Como todo “hasta”, hay que leerlo con lupa: los resultados varían según hardware, longitud de secuencia, estrategia de batching y nivel de razonamiento. Dicho eso, si las ganancias se sostienen en cargas reales, se cambia la conversación sobre unit economics en agentes.
Para que la idea quede visualmente clara, trabajamos dos gráficos ilustrativos a partir de esas promesas oficiales. El primero compara la generación relativa de tokens; el segundo, el costo relativo de razonamiento a igualdad de baseline. Son imágenes de referencia para comunicar el concepto a equipos no técnicos y para iniciar una discusión interna de costos.
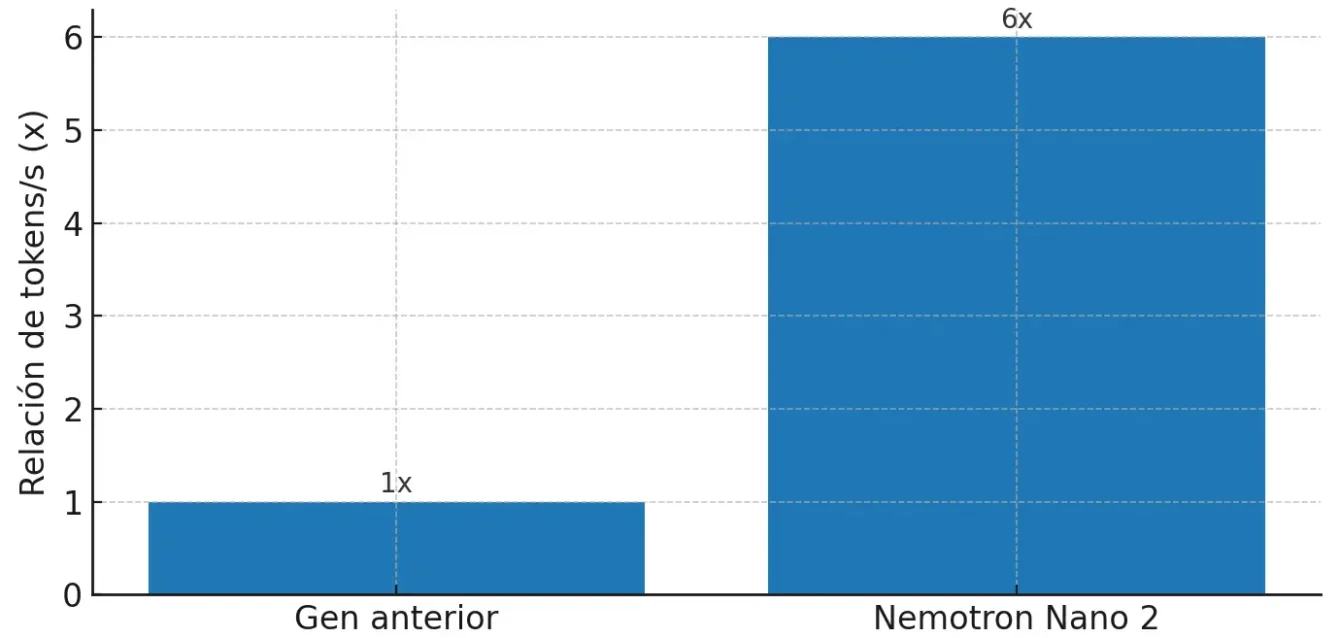
Gráfico 1. Generación de tokens relativa (Nemotron Nano 2 frente a la generación anterior)
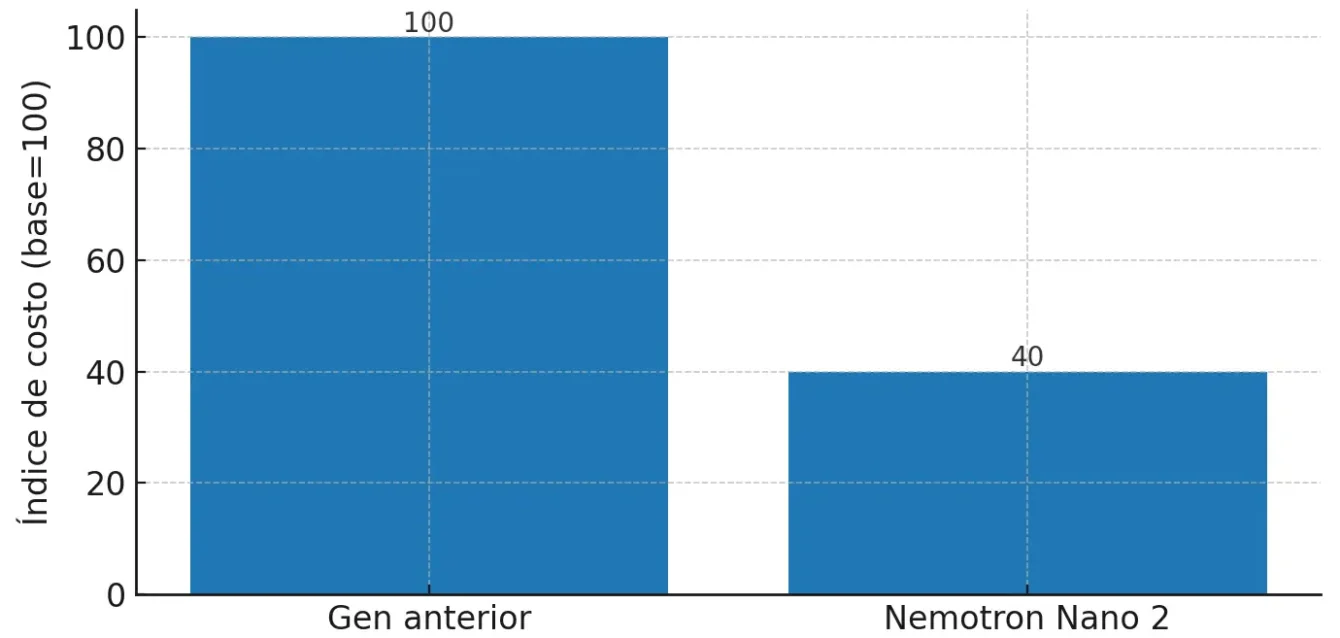
Gráfico 2. Costo relativo del razonamiento (índice base = 100)
Estos gráficos funcionan como brújula para decidir qué medir en un piloto: latencia por tipo de tarea, tokens por segundo reales en tu infraestructura, costo por interacción y sensibilidad del sistema a incrementos del presupuesto de pensamiento.
Dónde puede brillar: escenarios concretos
Edge e industria. En retail, manufactura y mantenimiento predictivo confluyen tres restricciones: latencia, conectividad y presupuesto. Un modelo compacto con perilla de razonamiento y contexto largo encaja con naturalidad: procesa flujos continuos, “piensa caro” cuando el caso lo exige y mantiene historial suficiente para que el análisis no se rompa al primer salto.
RAG con documentos extensos. Manuales técnicos, políticas internas, compliance, contratos, pliegos. Menos troceo y más continuidad producen respuestas menos fragmentadas. Para equipos legales, el valor está en resúmenes con citas recuperadas y en la capacidad de seguir hilos largos sin desarmar el contexto.
Operaciones de plataforma. SRE, seguridad, dataops. Triages masivos sin razonamiento; escalado con razonamiento cuando aparecen correlaciones extrañas o ambigüedades. Las ganancias de eficiencia se notan cuando se concentran los pasos “caros” en el cinco o diez por ciento de eventos que lo ameritan.
Formación y auditoría. Datasets públicos, tarjetas de modelo y documentación facilitan entrenamientos parciales reproducibles, suites de regresión y reportes de cumplimiento. En redacciones, eso se traduce en un plus de credibilidad: se evita la acusación de “caja negra”.
Competidores y comparativas: la discusión no es solo de precisión
Nemotron Nano 2 entra a un tablero donde conviven Qwen, Mistral, Llama y otros actores que lanzan iteraciones a ritmo frenético. NVIDIA sugiere paridad o ventaja frente a modelos de tamaños similares en benchmarks de razonamiento, con la diferencia de throughput marcada por su arquitectura y por la perilla de pensamiento. La cuestión es qué métrica importa para cada organización. Si tu objetivo es reducir coste por conversación con calidad estable, el throughput por GPU pesa tanto como la precisión en una batería sintética. Si te preocupa el control y la trazabilidad, el plus está en la transparencia de datos.
En ese sentido, no es descabellado pensar la comparación con un vector de tres componentes: precisión, tokens por segundo y gobernanza (datos, despliegue, seguridad). La combinación óptima cambia por sector. Un banco valorará de manera distinta a un medio de comunicación o a un operador de logística.
Riesgos y límites: más pasos no garantizan más verdad
Conviene decirlo sin rodeos. Más razonamiento no elimina alucinaciones si la recuperación de evidencias falla, si el prompt es ambiguo o si la orquestación no contiene verificaciones duras. Un modelo puede deliberar con gran confianza y estar equivocado. Además, existe el riesgo de “rigidez”, esa tendencia a pegarse a soluciones prototípicas cuando la consigna cambia por un giro contextual. Aumentar el presupuesto de pensamiento ayuda si se diseñan mecanismos explícitos para: extraer hechos, listar suposiciones, señalar contradicciones y citar evidencias recuperadas, no si solo se pide “pensar más”.
Tres antídotos prácticos para producción. Primero, grounding: exigir que el modelo devuelva pasajes o fuentes, no solo conclusiones. Segundo, guardrails: políticas que bloqueen respuestas finales cuando faltan hechos mínimos o cuando la jurisdicción cambia. Tercero, evaluación continua en producción: liberar de a poco, medir con paneles de costo y calidad, y retroalimentar el sistema.
Cómo medimos la sensibilidad del sistema: ISG y TAG
Para dejar de discutir a ciegas, proponemos dos métricas simples. El ISG (Índice de Sensibilidad al Giro) mide qué tan bien mantiene la precisión cuando un detalle invalida el patrón típico del caso. Si un modelo luce excelente en el caso base pero se desmorona con un giro pequeño, no es robusto para la vida real. La TAG (Tasa de Adaptación al Giro) mide el porcentaje de respuestas que ajustan explícitamente su recomendación después de detectar y explicar el giro en el propio razonamiento. Son métricas agnósticas del proveedor, comparables entre versiones y modelos y aplicables a dominios críticos como salud o finanzas.
Implementarlas es más sencillo de lo que parece. Se construyen pares de casos: uno base, tres variantes con giros diferentes (contradicción explícita, resolución previa, cambio de actor relevante o restricción normativa). Se obliga al modelo a enumerar hechos, listar suposiciones, marcar el giro, aplicar un marco y ofrecer opciones con pros y contras. Luego se registra si vio el giro, si cambió la conclusión y si lo dejó claro en su traza de razonamiento.
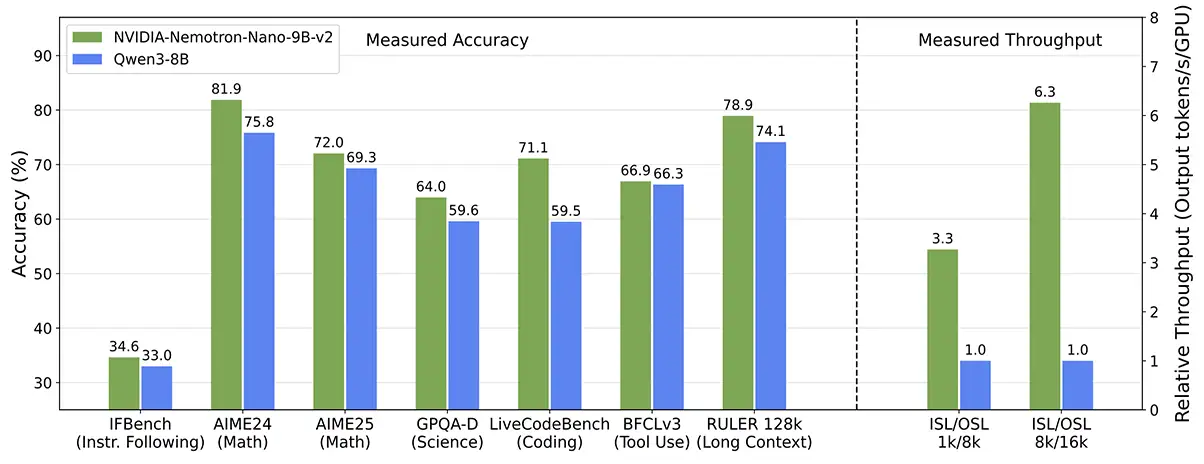
Gráfico 3. Como se muestra en el informe técnico, el modelo de razonamiento NVIDIA-Nemotron-Nano-v2-9B logra precisiones comparables o mejores en puntos de referencia de razonamiento complejo que el modelo abierto líder de tamaño comparable Qwen3-8B con un rendimiento hasta 6 veces mayor. En la figura, se abrevia la longitud de la secuencia de entrada a ISL y la longitud de la secuencia de salida a OSL. El rendimiento se midió en una sola GPU NVIDIA A10G con precisión bfloat16.
Cómo lo integramos sin dolor: hoja de ruta operativa
Piloto con datos propios. Elegir tres flujos reales (uno simple, uno intermedio, uno complejo) con objetivos y métricas claras. Medir con y sin razonamiento, y con tres niveles de presupuesto.
RAG con fuentes internas. Indexación curada, recuperación con citas y prompts que separen objetivos. Eliminar ruido paga más que pedir milagros al modelo.
Orquestación de agentes. Separar fases: recuperar, razonar, proponer, verificar. Cuanto más monolítico sea el prompt, más difícil será auditar.
Gobernanza y seguridad. Políticas de uso, límites de dominio, rutas de escalamiento a humano y trazas de decisiones. Para despliegues on-prem o en edge, microservicios y controles de seguridad consistentes.
Costeo vivo. Panel de tokens por segundo, latencia y costo por interacción, segmentado por nivel de razonamiento. Ajustar la perilla según prioridad de colas y horas pico.
Capacitación. Equipos que entienden qué hace el razonador y qué no hace cometen menos errores y diseñan flujos más realistas.
Perspectiva estratégica: dónde encaja en el juego de NVIDIA
Nemotron Nano 2 no nace aislado. Encaja en una estrategia que abarca desde el hardware hasta microservicios de despliegue. La familia Nemotron, los NIM para orquestación y seguridad, y los esfuerzos en multimodalidad pintan un ecosistema donde el razonamiento no vive solo en la nube, sino también en el borde. Para organizaciones que no pueden sacar sus datos de su perímetro, o que necesitan latencias por debajo del segundo, este enfoque es más que un detalle: es la puerta de entrada.
Hacia afuera, la competencia no es solo con otros modelos abiertos. Es con las plataformas cerradas que ofrecen lo último en capacidad pero piden confianza a ciegas. A medida que más instituciones pidan explicaciones, trazabilidad y control de costos, el péndulo podría moverse hacia soluciones como Nano 2. No porque sean perfectas, sino porque alinean tres cosas que el mundo real valora: saber qué hay dentro, pagar solo lo que aporta y poder demostrar cómo se decidió.
El modelo que cobra por pensar, cuando hace falta
Nemotron Nano 2 no intenta impresionar por tamaño. Intenta convencer por gobernabilidad. La perilla del razonamiento permite gastar donde importa y ahorrar donde no. La ventana de 128K recorta fricción en documentos largos y flujos persistentes. La publicación de datasets y tarjetas suma credibilidad y facilita auditorías. Todo eso no elimina riesgos ni garantiza verdades. Significa, sí, que hay instrumentos concretos para diseñar agentes que razonan con criterio y presupuestos que no tiemblan a fin de mes.
El paso siguiente es simple de enunciar y exigente de ejecutar: pasar del anuncio al piloto. Elegir tres flujos, medir con y sin razonamiento, instrumentar recuperación con citas, establecer guardrails y monitorear costo en tiempo real. Si las ganancias se sostienen en tu entorno, el titular no será “la IA piensa mejor”, sino “la IA piensa lo suficiente, al costo correcto”. Que, al final del día, es la clase de titular que cierra presupuesto y, a veces, también historias.
Referencias
[1] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Modelo alcanza precisión comparable o superior a Qwen3‑8B con un rendimiento hasta 6× mayorresearch.nvidia.com.
[2] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: La familia incluye tres modelos capaces de manejar 128 K tokensresearch.nvidia.com.
[3] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: El dataset de preentrenamiento comprende 6,6 billones de tokens organizados en cuatro categoríasresearch.nvidia.com.
[4] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Descripción detallada del dataset Nemotron‑Pretraining‑SFT‑v1 y de la muestra representativaresearch.nvidia.com.
[5] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Uso del navegador Lynx y LLM phi‑4 para crear Nemotron‑CC‑Math, y mejoras obtenidas en benchmarksresearch.nvidia.comresearch.nvidia.com.
[6] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Traducción de datos de QA a 15 idiomas y mejora de 10 puntos en Global‑MMLUresearch.nvidia.comresearch.nvidia.com.
[7] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Publicación del dataset de código con 175 000 M tokens y metadatos para reproducir 747 000 M tokensresearch.nvidia.com.
[8] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: El modelo base de 12 000 M de parámetros se preentrenó con 20 T tokens en precisión FP8research.nvidia.com.
[9] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: El posentrenamiento combinó SFT, GRPO, DPO y RLHF con trazas de razonamiento truncadasresearch.nvidia.com.
[10] NVIDIA ADLR. NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1: Compresión para ejecutar contextos de 128 K tokens en una GPU A10Gresearch.nvidia.com.
[11] NVIDIA. ¿Qué es NVIDIA Nemotron? Página corporativa: la versión Nano 2 admite presupuesto de pensamiento configurablenvidia.com.
[12] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: Descripción del sistema de interruptores /think y /no_think para activar o desactivar el razonamientoventurebeat.com.
[13] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: Control de presupuesto de pensamiento para equilibrar precisión y latenciaventurebeat.com.
[14] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Resultados de benchmarks en AIME25, MATH500, GPQA, LCB, BFCL v3, IFEval, HLE y RULER 128Khuggingface.co.
[15] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: Uso de datos mixtos —web, código, matemáticas, ciencia, legal y finanzas— con generación sintéticaventurebeat.com.
[16] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: Condiciones de la NVIDIA Open Model License —guardas, redistribución, cumplimiento y terminación por litigioventurebeat.com.
[17] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: Los modelos Nano 9B v2 están diseñados para que los desarrolladores gestionen coste y latencia mediante el control de razonamientoventurebeat.com.
[18] VentureBeat. Nvidia releases a new small, open model Nemotron‑Nano‑9B‑v2 with toggle on/off reasoning: La arquitectura híbrida y la compresión permiten mantener precisión reduciendo coste y latenciaventurebeat.com.
[19] TechRepublic. ‘The Pace is Incredible’: NVIDIA devotes more resources to robotics and physical AI: Durante SIGGRAPH se anunció que Nemotron Nano 2 genera hasta 6× más tokens que su predecesor y reduce el coste de razonamiento en un 60 %techrepublic.com.
[20] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: El refinamiento de Llama Nemotron incrementa hasta un 20 % la precisión y multiplica por cinco la velocidad de inferencianvidianews.nvidia.com.
[21] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: Declaración de Jensen Huang sobre la adopción masiva del razonamiento y el objetivo de dotar a las empresas de herramientas para construir una fuerza laboral de IA aceleradanvidianews.nvidia.com.
[22] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: La descripción de las versiones Nano, Super y Ultra y sus objetivos de precisión y rendimientonvidianews.nvidia.com.
[23] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: El posentrenamiento se llevó a cabo en NVIDIA DGX Cloud con datos sintéticos generados por Nemotron y otros modelos, además de datos curadosnvidianews.nvidia.com.
[24] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: Herramientas y técnicas de post‑training se abrirán para que las empresas construyan modelos de razonamiento personalizadosnvidianews.nvidia.com.
[25] NVIDIA Newsroom. NVIDIA Launches Family of Open Reasoning AI Models for Developers and Enterprises: Testimonios de socios que integran modelos Nemotron en sus plataformas para mejorar la eficiencia y la interacciónnvidianews.nvidia.com.
[26] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Descripción general del modelo, su entrenamiento desde cero y soporte para idiomas (inglés, alemán, español, francés, italiano y japonés)huggingface.co.
[27] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: La arquitectura híbrida consiste principalmente en capas Mamba‑2 y MLP, con solo cuatro capas de atenciónhuggingface.co.
[28] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Idiomas soportados —inglés, alemán, español, francés, italiano y japonés— y que el modelo está listo para uso comercialhuggingface.co.
[29] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Tabla de benchmarks detallada y mejora en cada prueba frente a Qwen3‑8Bhuggingface.co.
[30] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Soporte para presupuesto de pensamiento configurable en tiempo de ejecuciónhuggingface.co.
[31] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: La arquitectura se denomina Mamba2‑Transformer Hybridhuggingface.co.
[32] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Propiedades de entrada y salida, contexto de hasta 128 K tokens y soporte multilingüehuggingface.co.
[33] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Cálculo total de entrenamiento (1,53 × 10²⁴ FLOPs) y consumo energético (747,6 MWh)huggingface.co.
[34] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Detalles sobre las propiedades de entrada/salida y límites de contextohuggingface.co.
[35] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Optimización para hardware NVIDIA A10G, H100-80GB y A100, y uso de bfloat16huggingface.co.
[36] Hugging Face. NVIDIA‑Nemotron‑Nano‑9B‑v2 model card: Instrucciones para usar el modelo con /think y /no_think y recomendaciones de parámetros de generaciónhuggingface.co.

