
El parsing documental es el proceso mediante el cual una computadora analiza una imagen de un documento, como una factura, un formulario o una página escaneada, y no solo extrae el texto, sino que también identifica su estructura: qué es un encabezado, dónde comienza una tabla, cómo se organizan los párrafos o qué símbolos forman una fórmula matemática. A diferencia del simple reconocimiento óptico de caracteres, que solo «lee» letras, el parsing busca comprender la lógica visual del documento, transformando una imagen plana en datos estructurados, útiles y procesables. Durante mucho tiempo, esta tarea fue limitada por la incapacidad de los sistemas para manejar al mismo tiempo la complejidad del diseño y la precisión del contenido. MinerU2.5 representa un salto cualitativo en esta capacidad, combinando visión y lenguaje de una forma que redefine los estándares actuales.
Se trata de un modelo de visión-lenguaje desacoplado de 1.200 millones de parámetros, presentado en septiembre de 2025 por el Shanghai Artificial Intelligence Laboratory, la Universidad de Pekín y la Universidad Jiao Tong de Shanghái, logra algo que hasta hace poco parecía inalcanzable: no solo lee el texto de un documento, sino que comprende su arquitectura visual, sus columnas, sus tablas, sus fórmulas, su flujo lógico, con una precisión que supera a sistemas como Gemini 2.5 Pro, GPT-4o o Qwen2.5-VL-72B en evaluaciones técnicas de referencia.
La innovación de MinerU2.5 reside en su arquitectura sofisticada y en su eficiencia para manejar documentos de alta resolución. A diferencia de los enfoques convencionales que tratan el análisis de diseño y el reconocimiento de contenido de forma monolítica, MinerU2.5 emplea un pipeline de dos etapas desacoplado. En la primera fase, analiza imágenes submuestreadas para obtener una comprensión global de la estructura del documento, identificando elementos como columnas, encabezados, pies de página y áreas de texto. En la segunda fase, utiliza esta hoja de ruta global para enfocarse en recortes específicos de la imagen en su resolución nativa, lo que permite preservar detalles críticos como caracteres finos, fórmulas matemáticas complejas o líneas de tablas sutiles. Esta dualidad le confiere una agudeza sin igual, alcanzando resultados de vanguardia en cinco dominios clave: análisis de diseño, reconocimiento de texto, fórmulas, tablas y predicción del orden de lectura. Su disponibilidad en plataformas como HuggingFace y ModelScope democratiza el acceso a esta tecnología de punta, mientras que las actualizaciones constantes, como la migración de su motor de inferencia a vllm, aseguran su integración fluida en el ecosistema tecnológico existente.
La arquitectura desafía los límites: cómo MinerU2.5 entiende los documentos
El éxito de MinerU2.5 no es producto de un simple aumento en el tamaño de los datos de entrenamiento, sino del resultado de un pensamiento arquitectónico profundo que aborda directamente las limitaciones inherentes a los documentos digitales. Para comprender la genialidad de su diseño, es crucial entender el desafío central que intenta resolver. Los documentos son portadores de información bidimensional rica en jerarquías y relaciones espaciales. Un modelo de inteligencia artificial debe ser capaz de leer no solo las palabras, sino también la forma en que están dispuestas en la página. Esto implica distinguir entre un subtítulo y un pie de figura, reconocer que varias celdas conforman una tabla, o seguir correctamente el flujo de un texto que fluye alrededor de una imagen. Las técnicas tradicionales a menudo luchaban por equilibrar estos dos aspectos: la visión general de la página y el detalle fino del contenido.
MinerU2.5 introduce una solución elegante y poderosa: un modelo de visión-lenguaje desacoplado. La palabra «desacoplado» es clave aquí. Imagina que estás leyendo un periódico complicado. Primero, das un rápido vistazo a la página para ver cómo están organizadas las secciones: titulares grandes, fotos, columnas de texto, anuncios. Una vez que tienes ese mapa mental, te enfocas en cada parte para leer detenidamente el texto. Es exactamente este proceso humano el que imita MinerU2.5, pero a una velocidad computacional inimaginable. Su arquitectura funciona en dos fases bien definidas. En la primera, el modelo procesa una versión de la imagen del documento que ha sido reducida de tamaño («submuestreada»). Al trabajar con una resolución más baja, el modelo puede capturar rápidamente la estructura general, la distribución de los bloques de contenido y la relación espacial entre ellos. Este paso es computacionalmente eficiente y proporciona un contexto crucial.
La segunda fase es donde se revela la verdadera fuerza del modelo. Utilizando la estructura obtenida en la primera etapa como guía, MinerU2.5 se centra en regiones específicas del documento, pero ahora con una perspectiva de alta fidelidad. Recorta estas áreas del documento original y las procesa a su resolución nativa, es decir, a la misma calidad que se ve con el ojo humano. Este enfoque híbrido es el corazón de su innovación. Mientras la vista de conjunto le da el «qué» y el «dónde», el análisis local le proporciona el «cómo» y el «cuándo». Por ejemplo, al detectar una tabla, la segunda fase entra en acción para analizar cada celda en su resolución completa, asegurando que el texto, los números y las líneas de la tabla sean reconocidos con la máxima claridad posible. De manera similar, cuando se enfrenta a una fórmula matemática densa o un bloque de texto con una tipografía delgada, la capacidad de operar a resolución nativa es fundamental para evitar errores de interpretación.
Esta estrategia contrasta drásticamente con los modelos monolíticos que intentan hacer ambas cosas a la vez. Tratar de analizar toda la página a alta resolución sería extremadamente costoso en términos de recursos computacionales, limitando la longitud de los documentos que pueden procesar o la cantidad de documentos que pueden analizar simultáneamente. Por otro lado, confiar únicamente en una vista de bajo nivel ignora la estructura global, llevando a errores como fusionar accidentalmente dos bloques de texto separados o malinterpretar la función de un elemento. La arquitectura de MinerU2.5 elimina este compromiso. Ofrece la eficiencia conceptual de un análisis de alto nivel junto con la precisión meticulosa de un reconocimiento de bajo nivel. Esta combinación es lo que le permite superar a modelos mucho más grandes y potentes como Gemini 2.5 Pro y GPT-4o en tareas que requieren una comprensión tanto estructural como de contenido. Es una demostración magistral de que a veces la división de tareas y la especialización estratégica conducen a un rendimiento superior que cualquier intento de hacerlo todo a la vez.
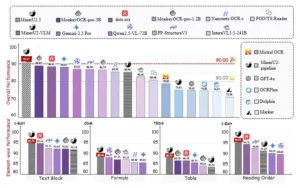
Aspectos destacados del rendimiento de MinerU2.5 en OmniDocBench. MinerU2.5 supera consistentemente tanto a los VLM de propósito general (p. ej., Gemini-2.5 Pro, Qwen2.5-VL-72B, GPT-4o) como a los modelos específicos de dominio (p. ej., MonkeyOCR, dots.ocr, PP-StructureV3), estableciendo nuevos récords de rendimiento en reconocimiento de texto, fórmulas, tablas y predicción del orden de lectura.
Rendimiento de vanguardia: benchmarking y comparativa con modelos competidores
La afirmación de que MinerU2.5 domina el parsing de documentos no es una declaración vacía; está respaldada por una sólida evidencia empírica obtenida a través de pruebas rigurosas en múltiples benchmark. Estos conjuntos de datos de prueba son el equivalente digital de los campos de competición atlética, diseñados para evaluar el rendimiento específico de los modelos en tareas desafiantes. El trabajo presenta los resultados de MinerU2.5 en algunos de los benchmarks más exigentes del sector, demostrando consistentemente un rendimiento líder sobre una larga lista de modelos competidores, tanto generales como especializados.
El principal punto de referencia utilizado es OmniDocBench, un conjunto de datos diverso que incluye nueve tipos diferentes de documentos, desde formularios y artículos académicos hasta documentos legales y manuscritos. En este entorno variado, MinerU2.5 ha demostrado superar a modelos de primer nivel del mercado. En la categoría de análisis de diseño, reconoce con mayor precisión la estructura general del documento. En el reconocimiento de texto, obtiene una mayor proporción de caracteres correctamente leídos. En el reconocimiento de fórmulas, excela en la interpretación de expresiones matemáticas complejas. En la extracción de tablas, muestra una superioridad notable en la identificación y estructuración de datos tabulares. Finalmente, en la predicción del orden de lectura, demuestra una comprensión superior de la secuencia lógica en la que un lector debería consumir la información en una página multifacética.
Como se puede observar, MinerU2.5 establece un nuevo umbral de calidad en prácticamente todas las facetas del parsing documental. Incluso frente a modelos especializados como dots.ocr y MonkeyOCR, que se centran exclusivamente en ciertos tipos de documentos, MinerU2.5 logra un rendimiento superior, lo que sugiere una mayor versatilidad y robustez general.
Para profundizar aún más en sus capacidades, el desarrollo del modelo incluyó un motor de datos integral y sofisticado. Este motor fue responsable de generar un corpus de entrenamiento masivo y diverso mediante un proceso de minería iterativa basado en la consistencia de las inferencias. En esencia, el propio modelo ayudaba a etiquetar nuevos datos, seleccionando aquellos en los que estaba más seguro, lo que permitió crear un conjunto de entrenamiento de alta calidad. Además, el motor aplicó transformaciones sistemáticas a las imágenes de los documentos durante el entrenamiento, incluyendo cambios en la posición espacial, el color de fondo, el color del texto y degradaciones simuladas para hacer que el modelo fuera resilientes a condiciones del mundo real, como documentos amarillentos o de baja calidad fotográfica. Este enfoque proactivo en el entrenamiento es tan crucial como la propia arquitectura, ya que le permite al modelo generalizar mejor a documentos que nunca ha visto antes.
Es importante señalar que, aunque el documento técnico menciona la superación de modelos líderes como Gemini 2.5 Pro, GPT-4o y otros, no proporciona datos cuantitativos detallados para todas las métricas y competidores. Sin embargo, la afirmación repetida de que supera a los modelos líderes en el OmniDocBench es una declaración contundente que posiciona a MinerU2.5 como un referente tecnológico en el campo. Su rendimiento en benchmarks específicos como PubTabNet y FinTabNet para la extracción de tablas financieras, y en olmOCR-bench y Ocean-OCR Benchmark para documentos multilingües, refuerza aún más su perfil de versatilidad y precisión. En resumen, MinerU2.5 no es simplemente un mejor modelo; es un modelo que redefine qué es posible en el parsing de documentos modernos.
Aplicaciones transformadoras: impacto en la gestión documental pública y empresarial
El valor de un avance tecnológico como MinerU2.5 no se mide únicamente por sus puntuaciones en un benchmark, sino por su capacidad para resolver problemas del mundo real. Sus capacidades de parsing de documentos de alta precisión tienen el potencial de transformar radicalmente la gestión documental en sectores críticos como el público y el privado, donde la eficiencia, la seguridad y la accesibilidad son imperativos estratégicos. En un momento en que las administraciones públicas y las empresas buscan activamente optimizar sus operaciones a través de la digitalización, MinerU2.5 emerge como una herramienta poderosa para automatizar y mejorar procesos fundamentales.
En el ámbito de las administraciones públicas, la digitalización es un objetivo central. En España, por ejemplo, el Plan de Digitalización de las Administraciones Públicas 2021-2025 busca mejorar la atención ciudadana, implementar operaciones inteligentes y proteger los datos, con miles de proyectos en marcha en comunidades autónomas y entidades locales. Dentro de este marco, MinerU2.5 podría tener un impacto profundo. Podría acelerar significativamente la tramitación de expedientes judiciales, un área en la que el Ministerio de Justicia ya impulsa juicios telemáticos. Imagina un sistema que pueda tomar un montón de documentos PDF de un caso, extraer automáticamente los datos relevantes (nombres, fechas, referencias legales), estructurar la información y preparar un resumen inicial para el juez o el abogado. Esto no solo ahorraría horas de trabajo manual, sino que reduciría la probabilidad de errores humanos y agilizaría los procesos judiciales.
Otra aplicación clave en el sector público es la gestión de servicios para los ciudadanos. Con iniciativas como Mi Carpeta Ciudadana en España, que ya cuenta con más de 2.1 millones de usuarios, la capacidad de procesar documentos de forma automática y segura es vital. Un sistema como MinerU2.5 podría utilizarse para validar instantáneamente declaraciones fiscales, certificados médicos o solicitudes de ayudas sociales. Podría extraer datos de un formulario en papel, verificar su coherencia interna y cargarlos directamente en los sistemas backend, permitiendo que los ciudadanos accedan a servicios como la Historia Clínica Digital o notificaciones electrónicas con mayor rapidez y fiabilidad. Además, en un entorno donde la seguridad cibernética es primordial, con más de 2.000 incidentes evitados en 2023 gracias a los Centros de Operaciones de Ciberseguridad (COCs), la capacidad de MinerU2.5 para funcionar de forma autónoma y precisa reduce la superficie de ataque asociada al manejo manual de datos sensibles.
En el sector empresarial, las implicaciones son igualmente revolucionarias. Las empresas gestionan continuamente una avalancha de documentos: facturas, contratos, informes de investigación, manuales técnicos y correspondencia. El parsing de documentos automatizado por MinerU2.5 podría revolucionar la gestión de estos activos de información. Por ejemplo, en el sector financiero, podría analizar extractos bancarios o estados financieros complejos para extraer flujos de caja, ingresos y gastos, alimentando así sistemas de planificación financiera en tiempo real. En el sector legal, podría revisar docenas de contratos para identificar cláusulas específicas o inconsistencias, un proceso que hoy consume innumerables horas de trabajo de abogados.
El modelo también tiene un papel crucial en la preservación y accesibilidad de la historia. Muchos archivos históricos, libros antiguos o manuscritos son demasiado frágiles para ser escaneados a alta resolución estándar sin riesgo de daño. La capacidad de MinerU2.5 para operar en resolución nativa significa que puede procesar imágenes de alta calidad de estos documentos valiosos, reconociendo texto antiguo, símbolos o diagramas con una precisión que antes era inalcanzable. Esto abriría nuevas vías para la investigación histórica y la digitalización de bibliotecas y archivos nacionales, haciendo que la información perdida durante décadas o siglos sea accesible para el público en general. La capacidad de analizar documentos bilingües, como se evaluó en el Ocean-OCR Benchmark, amplía aún más este potencial, facilitando el estudio de materiales históricos multilingües. En última instancia, MinerU2.5 no es solo una herramienta técnica; es un catalizador de eficiencia, seguridad y conocimiento en la sociedad digital.
Más allá de la eficiencia: implicaciones sociales y científicas del nuevo paradigma
Más allá de los beneficios tangibles de la eficiencia y la productividad en la gestión documental, el desarrollo de MinerU2.5 simboliza un cambio de paradigma más profundo con implicaciones científicas y sociales de gran calado. Representa un paso decisivo hacia una inteligencia artificial que puede interactuar con la información humana de una manera más contextual, estructurada y, en cierto modo, «inteligente». Este avance no es meramente incremental; marca un punto de inflexión en la capacidad de las máquinas para comprender el mundo tal como los humanos lo construyen y representan.
Desde una perspectiva científica, MinerU2.5 demuestra el poder de la especialización y la modularidad en el aprendizaje profundo. La arquitectura desacoplada no es solo un truco ingenioso para mejorar el rendimiento; es una validación experimental de una idea teórica fundamental: que la comprensión de la estructura es un precursor necesario para la comprensión del contenido. Este principio podría inspirar nuevas líneas de investigación en otros dominios multimodales, como el análisis de video (donde primero se detecta el movimiento y luego se identifican los objetos) o el diseño asistido por computadora (CAD). Si el análisis de la «forma» o la «estructura» de un objeto es un paso previo para comprender su «contenido» o «función», entonces MinerU2.5 sirve como un brillante caso de estudio para esta filosofía de diseño de IA. Además, la metodología de creación de datos, utilizando el propio modelo para afinar el corpus de entrenamiento, abre caminos hacia sistemas de aprendizaje autónomo y auto-mejorantes, reduciendo la dependencia de los enormes conjuntos de datos etiquetados manualmente y que a menudo son costosos y sesgados.
Las implicaciones sociales son igualmente profundas. En un mundo inundado de información, la capacidad de navegar y extraer conocimiento de documentos de forma rápida y fiable es una habilidad democrática. Tecnologías como MinerU2.5 pueden actuar como un graniglerador de información, nivelando el campo de juego para individuos y pequeñas organizaciones que no pueden permitirse equipos de expertos para analizar documentos complejos. Esto tiene un impacto directo en la transparencia y la rendición de cuentas. Por ejemplo, periodistas de investigación podrían utilizar herramientas basadas en MinerU2.5 para analizar miles de documentos filtrados, identificando patrones y conexiones que de otro modo permanecerían ocultos. Abogados defensores de derechos humanos podrían procesar grandes volúmenes de testimonios o documentos oficiales para encontrar correlaciones significativas. En última instancia, al facilitar el acceso al conocimiento contenido en los documentos, MinerU2.5 puede contribuir a una sociedad más informada y justa.
Este avance también tiene consecuencias directas en la confianza pública. Existe una correlación estadística fuerte y positiva entre la satisfacción del ciudadano con los servicios públicos y la confianza en el gobierno. La implementación de tecnologías como MinerU2.5 para agilizar y mejorar la calidad de esos servicios públicos es una inversión estratégica en esa confianza. Cuando un ciudadano puede recibir una respuesta a su consulta administrativa en minutos en lugar de días, o completar un trámite en línea sin errores, su percepción del gobierno cambia de una entidad burocrática y distante a una organización eficiente y centrada en el usuario. Países como Alemania, que han simplificado cientos de transacciones gubernamentales para el usuario final, o Dubai, que aspira a unificar todas sus interacciones con el gobierno en una sola aplicación móvil, comprenden que la experiencia del ciudadano es el nuevo estándar de excelencia. MinerU2.5 es una de las herramientas tecnológicas clave para alcanzar ese estándar. Al reducir la frustración y aumentar la eficacia de la interacción con las instituciones, ayuda a fortalecer el contrato social en un mundo digital.
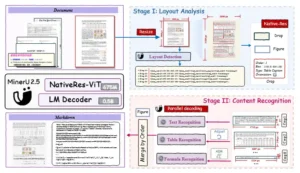
El marco de trabajo de MinerU2.5. En la etapa I, MinerU2.5 realiza un análisis de diseño global y rápido en una página con resolución reducida. En la etapa II, MinerU2.5 aprovecha los resultados del diseño para recortar regiones clave del documento original de alta resolución, realizando un reconocimiento de contenido detallado (por ejemplo, texto, tablas y fórmulas) dentro de estas regiones locales de resolución nativa.
El futuro del parsing documental y el legado de MinerU2.5
En conclusión, MinerU2.5 no es simplemente otro modelo de inteligencia artificial lanzado al mercado; es un faro que ilumina el futuro del parsing de documentos. Su llegada marca el fin de un paradigma en el que la comprensión de documentos se basaba en aproximaciones burdas y sacrificios inevitables entre precisión y escala. Mediante su innovadora arquitectura desacoplada, MinerU2.5 ha demostrado que es posible alcanzar un alto rendimiento en múltiples facetas del análisis documental —la estructura, el texto, las fórmulas y las tablas— sin tener que elegir entre ellas. Ha elevado el estándar de la industria, mostrando que la eficiencia computacional y la precisión de alto nivel pueden coexistir y reforzarse mutuamente.
El legado de MinerU2.5 se materializará en la transformación de la gestión documental pública y empresarial. En el sector público, impulsará la agenda de digitalización, acelerando la tramitación de expedientes, mejorando la seguridad de los datos y aumentando la satisfacción ciudadana, lo cual a su vez fortalece la confianza en las instituciones. En el sector privado, automatizará procesos laboriosos, liberando capital humano para tareas creativas y estratégicas. Y en el ámbito científico y cultural, actuará como un puente hacia el conocimiento perdido, haciendo que los archivos históricos y los documentos de investigación más valiosos sean descifrados y accesibles para la próxima generación.
A nivel más profundo, MinerU2.5 nos enseña una lección crucial sobre el futuro de la inteligencia artificial: la especialización y la modularidad son aliadas de la inteligencia general. Su éxito no proviene de ser un modelo más grande, sino de ser más inteligente en su diseño. Ha demostrado que descomponer un problema complejo en pasos más manejables y especializados puede llevar a soluciones más robustas y eficaces. Esta filosofía será probablemente una de las principales leyes de la ingeniería de IA en los próximos años.
Por tanto, el impacto de MinerU2.5 trascenderá su utilidad inmediata. Será recordado como un hito que no solo ofreció una herramienta poderosa, sino que también redefinió el camino de la investigación futura. Nos ha mostrado que la próxima frontera no está en la escalabilidad pura, sino en la inteligencia estructural. El futuro del parsing documental, y de la IA en general, parece estar escrito en un código que combina la visión sistémica con la precisión metódica, y MinerU2.5 es uno de sus primeros y más elocuentes poemas.
Referencias
- Shanghai Artificial Intelligence Laboratory, Peking University, Shanghai Jiao Tong University. MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing. arXiv:2509.22186 [cs.CV]. 2025.
- Shanghai Artificial Intelligence Laboratory. MinerU2.5 Technical Report and Model Card. 2025.
- Ministerio de Asuntos Económicos y Transformación Digital. Plan de Digitalización de las Administraciones Públicas 2021-2025. Gobierno de España. 2023.
- Organisation for Economic Co-operation and Development. Trust in Government and Public Service Satisfaction. OECD Digital Government Studies. 2024.

