
Por Carlos Mendoza Prado, Periodista Especializado en Ciencia y Salud, para Mundo IA
La IA que acelera la medicina: cómo la poda inteligente de imágenes revoluciona el diagnóstico
En el corazón de la medicina moderna, la capacidad de ver dentro del cuerpo humano sin necesidad de cirugía es una de las hazañas tecnológicas más importantes. Las imágenes obtenidas por resonancia magnética, tomografías computarizadas y otros escáneres avanzados son los ojos de los médicos en el siglo veintiuno, permitiéndoles identificar, diagnosticar y planificar tratamientos para una infinidad de enfermedades. Sin embargo, estas imágenes, a menudo increíblemente detalladas y complejas, presentan un desafío monumental: la interpretación. Encontrar un tumor diminuto, delinear los bordes exactos de un órgano dañado o medir el crecimiento de una lesión son tareas que requieren una precisión y un tiempo extraordinarios, incluso para los radiólogos más experimentados. Aquí es donde la inteligencia artificial ha prometido ser una aliada revolucionaria. Durante años, los algoritmos de IA han sido entrenados para analizar estas imágenes, aprendiendo a reconocer patrones que el ojo humano podría pasar por alto. Pero esta alianza ha enfrentado su propio obstáculo: la eficiencia. Las arquitecturas de inteligencia artificial más potentes, conocidas como Vision Transformers, son bestias computacionales. Para lograr su asombrosa precisión, procesan cada diminuto fragmento de una imagen médica con la misma intensidad, un enfoque de fuerza bruta que consume una enorme cantidad de tiempo y recursos informáticos. Es como leer un diccionario completo, palabra por palabra, cuando solo se necesita encontrar la definición de un único término.
Este problema de eficiencia no es un mero inconveniente técnico; tiene consecuencias en el mundo real. Limita la velocidad con la que se pueden obtener los diagnósticos, aumenta los costos para los hospitales y hace que estas tecnologías de vanguardia sean inaccesibles en entornos con recursos limitados. ¿De qué sirve una herramienta increíblemente precisa si es demasiado lenta o cara para ser utilizada en el día a día de un hospital concurrido? Es en este punto crucial donde un equipo de investigadores ha introducido una solución tan elegante como efectiva, detallada en su trabajo «Poda dinámica de tokens basada en prompts para la segmentación eficiente de imágenes médicas». Su propuesta se aleja del enfoque de fuerza bruta y adopta una estrategia de inteligencia y enfoque. La idea central es simple de concebir pero compleja de ejecutar: en lugar de que la IA analice toda la imagen con la misma atención, ¿por qué no guiarla para que concentre sus esfuerzos solo en las áreas que realmente importan? Su método permite a un clínico, un médico o un técnico, proporcionar una pista simple a la IA, lo que se conoce como «prompt». Este prompt puede ser tan sencillo como dibujar una caja alrededor de una zona sospechosa en la imagen.
Esta simple pista actúa como una señal, un punto de partida que le dice al sistema: «empieza a buscar aquí». A partir de esta guía inicial, la inteligencia artificial cobra vida de una manera completamente nueva. La tecnología subyacente, el Vision Transformer, funciona dividiendo la imagen médica en miles de pequeños cuadros o «tokens», como si convirtiera una fotografía en un mosaico. Tradicionalmente, la IA procesaría cada uno de estos tokens con el mismo rigor. El nuevo método, sin embargo, utiliza la pista del médico para realizar una evaluación instantánea. De forma inteligente, califica la relevancia de cada token. Aquellos que están dentro o cerca del área señalada se consideran de alta importancia, mientras que los que están lejos, en regiones de la imagen claramente irrelevantes para la tarea en cuestión, como el fondo del escáner o tejido sano distante, reciben una puntuación baja. Y aquí es donde ocurre la magia, en un proceso que los investigadores llaman «poda dinámica». La IA «poda» o ignora selectivamente los tokens de baja relevancia. No pierde tiempo ni poder de cómputo analizándolos. En su lugar, dedica todos sus recursos a los fragmentos de la imagen que tienen más probabilidades de contener la información crucial. Es un cambio de paradigma: de un análisis exhaustivo a un análisis focalizado e inteligente.
El «dinamismo» de este enfoque es clave. La poda no es una decisión fija, sino que se adapta en tiempo real a cada imagen y a cada pista proporcionada. El sistema decide sobre la marcha cuántos tokens podar y en qué etapas del análisis hacerlo, asegurando un equilibrio perfecto entre eficiencia y precisión. Los resultados de esta técnica son asombrosos. Los investigadores han demostrado que su método puede reducir la cantidad de tokens que necesitan ser procesados entre un 35% y un 55%. Esta drástica reducción en la carga de trabajo computacional se traduce directamente en un análisis de imágenes significativamente más rápido y en un menor consumo de energía. Lo más impresionante es que esta ganancia de velocidad no se produce a costa de la precisión. De hecho, al obligar a la IA a concentrarse en la información más pertinente, en algunos casos la precisión del análisis incluso mejora. Esta innovación tiene el potencial de transformar la radiología y el diagnóstico médico. Abre la puerta a diagnósticos casi en tiempo real, donde un médico podría obtener un análisis detallado de una imagen en cuestión de minutos en lugar de horas. Reduce los costos asociados con el hardware de alto rendimiento y el consumo de energía, haciendo que la IA médica avanzada sea una herramienta viable para una gama mucho más amplia de hospitales y clínicas en todo el mundo. En esencia, este trabajo no solo presenta un algoritmo más inteligente, sino que traza un camino hacia un futuro en el que la asistencia de la inteligencia artificial en la medicina sea más rápida, más precisa y, fundamentalmente, más accesible para todos.
El desafío de ver dentro del cuerpo humano
Desde que Wilhelm Röntgen descubrió los rayos X a finales del siglo XIX, la humanidad ha estado obsesionada con la idea de observar el interior del cuerpo humano sin la necesidad del bisturí. Lo que comenzó como imágenes fantasmales en blanco y negro de los huesos ha evolucionado hasta convertirse en un campo increíblemente sofisticado conocido como imagenología médica. Hoy en día, los médicos tienen a su disposición un arsenal de tecnologías que ofrecen ventanas con una claridad sin precedentes a los intrincados funcionamientos de nuestra biología. Las tomografías computarizadas, o TC, utilizan múltiples radiografías para crear imágenes transversales detalladas, casi como si el cuerpo fuera cortado en finas lonjas virtuales, permitiendo ver órganos, huesos y tejidos blandos con gran detalle. Las imágenes por resonancia magnética, o IRM, van un paso más allá, utilizando potentes campos magnéticos y ondas de radio para generar imágenes de una calidad asombrosa, especialmente de los tejidos blandos como el cerebro, los músculos y los ligamentos. Otras modalidades, como la tomografía por emisión de positrones o PET, pueden incluso mostrar la actividad metabólica de las células, revelando cómo funcionan los órganos y tejidos, y no solo cómo se ven.
Estas tecnologías generan una cantidad de datos visuales abrumadora. Un solo escaneo de IRM puede consistir en cientos de imágenes de alta resolución, cada una de las cuales contiene millones de píxeles. En algún lugar dentro de este vasto mar de datos se encuentra la información que el médico necesita para salvar una vida: la silueta de un tumor en sus primeras etapas, la ubicación exacta de un coágulo de sangre en el cerebro, la extensión del daño en el tejido cardíaco después de un infarto. Pero encontrar esta aguja en el pajar digital es solo el primer paso. Para que la información sea clínicamente útil, a menudo se requiere un proceso llamado segmentación de imágenes. La segmentación es el acto de delinear digitalmente los contornos de una estructura específica dentro de una imagen. Es, en esencia, un ejercicio de coloreado digital de alta precisión. Un radiólogo podría necesitar trazar el borde exacto de un riñón para evaluar su tamaño, delinear un tumor cerebral para planificar una cirugía o una radioterapia, o aislar una región específica del pulmón afectada por una neumonía para cuantificar la gravedad de la infección.
La segmentación precisa es absolutamente fundamental para la medicina moderna. En la planificación del tratamiento del cáncer, por ejemplo, la radioterapia requiere que los haces de radiación se dirijan con una precisión milimétrica al tumor, evitando al mismo tiempo el tejido sano circundante. Un error en la segmentación del tumor podría significar que las células cancerosas no reciban una dosis letal de radiación, o peor aún, que el tejido sano sea dañado innecesariamente. En la cirugía, los modelos tridimensionales creados a partir de imágenes segmentadas permiten a los cirujanos planificar y ensayar procedimientos complejos antes de entrar en el quirófano, reduciendo los riesgos y mejorando los resultados. El seguimiento de la progresión de una enfermedad también depende en gran medida de la segmentación. Al comparar la segmentación de una lesión a lo largo del tiempo, los médicos pueden determinar objetivamente si un tratamiento está funcionando, si un tumor está creciendo o encogiéndose, o si una enfermedad neurodegenerativa como el alzhéimer está causando la atrofia de ciertas regiones del cerebro.
A pesar de su importancia crítica, el proceso de segmentación manual es un cuello de botella notorio en el flujo de trabajo clínico. Es una tarea increíblemente laboriosa, repetitiva y que requiere mucho tiempo. Un radiólogo puede pasar horas trazando meticulosamente los contornos de las estructuras en cientos de cortes de imágenes de un solo paciente. Este trabajo no solo es tedioso, sino que también es inherentemente subjetivo. Dos expertos diferentes, al observar la misma imagen, pueden producir segmentaciones ligeramente diferentes, una variabilidad que puede afectar las decisiones clínicas. Además, la fatiga puede influir en la calidad del trabajo. El tiempo dedicado a la segmentación manual es tiempo que un especialista no puede dedicar a otras tareas críticas, como la interpretación de diagnósticos más complejos o la consulta con los pacientes. Esta combinación de ser un proceso lento, costoso y propenso a la variabilidad ha hecho de la segmentación de imágenes médicas un candidato ideal para la automatización a través de la inteligencia artificial. La promesa es clara: desarrollar sistemas que puedan realizar esta tarea de forma más rápida, consistente y, potencialmente, más precisa que los humanos, liberando a los profesionales médicos para que se centren en lo que mejor saben hacer: cuidar a los pacientes.
La Inteligencia Artificial al rescate de la medicina
La idea de que las máquinas puedan pensar o aprender, el concepto central de la inteligencia artificial, ha pasado de ser un elemento de la ciencia ficción a una fuerza transformadora en innumerables industrias, y la medicina no es una excepción. El subcampo de la IA que ha demostrado ser más prometedor para el análisis de imágenes es el aprendizaje profundo o «deep learning», un enfoque inspirado en la estructura y función del cerebro humano. Los modelos de aprendizaje profundo utilizan redes neuronales artificiales con muchas capas, de ahí el término «profundo», para aprender a reconocer patrones complejos a partir de vastas cantidades de datos. En el contexto de la medicina, esto significa que los investigadores pueden «alimentar» a un algoritmo con miles o incluso millones de imágenes médicas previamente etiquetadas por expertos. Por ejemplo, para entrenar una IA para que segmente tumores cerebrales, los desarrolladores le proporcionarían una enorme base de datos de escáneres cerebrales en los que los radiólogos ya han delineado los tumores.
A través de un proceso de entrenamiento iterativo, la red neuronal ajusta sus conexiones internas para aprender a asociar ciertos patrones de píxeles, texturas y formas con la etiqueta «tumor». Con el tiempo, el modelo se vuelve increíblemente hábil para identificar estas características, hasta el punto de que puede analizar una imagen completamente nueva que nunca antes ha visto y producir una segmentación precisa por sí mismo. Los primeros éxitos en este campo se lograron con un tipo de red neuronal llamada Red Neuronal Convolucional (CNN, por sus siglas en inglés). Las CNN fueron diseñadas específicamente para procesar datos de cuadrícula, como las imágenes, y demostraron ser excepcionalmente buenas en tareas como la clasificación de imágenes (por ejemplo, determinar si una radiografía de tórax muestra signos de neumonía) y la segmentación. Sin embargo, en los últimos años, ha surgido una nueva arquitectura de IA, que ha demostrado ser aún más poderosa para ciertas tareas de visión por computadora: los Vision Transformers (ViT).
Los Vision Transformers se originaron en el campo del procesamiento del lenguaje natural, donde revolucionaron la forma en que las máquinas entienden y generan el lenguaje humano. La idea innovadora detrás de los Transformers fue un mecanismo llamado «atención». En lugar de procesar una oración palabra por palabra en un orden fijo, el mecanismo de atención permite al modelo sopesar la importancia de todas las palabras en la oración simultáneamente, permitiéndole captar el contexto y las relaciones a larga distancia entre las palabras de una manera mucho más sofisticada. Los investigadores de la visión por computadora se dieron cuenta de que este mismo principio podría aplicarse a las imágenes. La pregunta era cómo. La solución fue brillante en su simplicidad: dividir la imagen en una cuadrícula de pequeños parches o «tokens». Cada uno de estos parches se trata entonces como si fuera una «palabra». El Vision Transformer procesa estos parches, utilizando el mecanismo de atención para evaluar las relaciones entre cada parche y todos los demás parches de la imagen.
Este enfoque global tiene una ventaja fundamental sobre las CNN. Mientras que las CNN tienden a centrarse en características locales (bordes, texturas en una pequeña región), los ViT pueden capturar el contexto general de la imagen desde el principio. Pueden entender cómo una parte distante de un órgano se relaciona con otra, lo que es crucial para tareas de segmentación complejas donde la forma y la estructura generales son tan importantes como los detalles locales. Gracias a esta capacidad de ver el «bosque» además de los «árboles», los Vision Transformers rápidamente comenzaron a establecer nuevos récados de precisión en una amplia gama de tareas de análisis de imágenes médicas. Demostraron ser superiores en la segmentación de órganos complejos, la identificación de lesiones sutiles y la clasificación de diferentes tipos de tejidos. Parecía que la solución definitiva para la segmentación automatizada de imágenes médicas había llegado. Sin embargo, este extraordinario poder tenía un costo oculto, un talón de Aquiles que pronto se haría evidente: una voracidad computacional sin precedentes.
Vision Transformers: una nueva forma de ver
Para comprender verdaderamente la revolución que suponen los Vision Transformers, y el problema que el nuevo método de poda busca resolver, es útil profundizar en cómo «ven» realmente estas arquitecturas. Imaginemos una imagen médica de alta resolución, por ejemplo, un corte transversal de un cerebro obtenido por resonancia magnética. Para un humano, esta es una imagen coherente. Para una computadora, es simplemente una vasta cuadrícula de píxeles, cada uno con un valor de intensidad. Las redes neuronales convolucionales (CNN) abordan esta cuadrícula aplicando una serie de «filtros» o «kernels». Cada filtro es una pequeña ventana que se desliza por toda la imagen, buscando patrones específicos como bordes, esquinas o texturas. Las capas más profundas de la CNN combinan estos patrones simples para reconocer características más complejas, como la forma de un ojo o, en nuestro caso, la textura de un tipo particular de tejido cerebral. Este enfoque es jerárquico y local. La información se procesa de abajo hacia arriba, desde los detalles pequeños hasta las estructuras grandes.
Los Vision Transformers (ViT) rompen radicalmente con esta tradición. Su primer paso es deconstruir la imagen. En lugar de procesar píxeles individuales, dividen la imagen en una cuadrícula regular de parches. Por ejemplo, una imagen de 224×224 píxeles podría dividirse en una cuadrícula de 14×14 parches, donde cada parche es un cuadrado de 16×16 píxeles. Cada uno de estos 196 parches se convierte en un «token». Es fundamental entender que en este punto, la noción espacial bidimensional de la imagen se transforma. Cada parche se «aplana» en una larga secuencia de números, y el conjunto de todos los parches se convierte en una secuencia de tokens, muy parecida a una secuencia de palabras en una oración. Aquí es donde entra en juego el mecanismo de «auto-atención», el corazón del Transformer. Por cada token en la secuencia, el mecanismo de auto-atención calcula una «puntuación de atención» con respecto a todos los demás tokens de la secuencia, incluido él mismo. Esta puntuación representa la relevancia o la conexión contextual entre los dos tokens. Si un token que representa una parte de un tumor tiene una alta puntuación de atención con otro token que también forma parte del tumor, incluso si están en lados opuestos de la lesión, el modelo aprende que están contextualmente relacionados.
Este proceso se repite en múltiples capas y a través de múltiples «cabezas de atención», cada una de las cuales puede aprender a buscar diferentes tipos de relaciones. El resultado final es que, al final del proceso, cada token ha sido enriquecido con información contextual de toda la imagen. El modelo no solo sabe qué hay en ese pequeño parche, sino cómo ese parche se relaciona con el panorama general. Esta capacidad de modelar relaciones a larga distancia es lo que hace que los ViT sean tan poderosos. En una imagen médica, las pistas diagnósticas a menudo dependen del contexto global. La forma completa de un órgano, las sutiles asimetrías entre los dos hemisferios del cerebro o la distribución de las lesiones en todo el pulmón son piezas de información que los ViT pueden capturar de forma natural. Sin embargo, esta capacidad tiene un costo computacional que crece de forma cuadrática con el número de tokens. Si se duplica el número de tokens (por ejemplo, utilizando parches más pequeños para obtener más detalles), la cantidad de cálculos necesarios para la auto-atención se cuadruplica. Esto se debe a que cada token debe «atender» a todos los demás tokens. Para una secuencia de N tokens, hay N x N interacciones que calcular. Este es el cuello de botella computacional que ha limitado la aplicación de los ViT, especialmente con las imágenes médicas, que suelen ser de muy alta resolución y, por tanto, generan un número enorme de tokens. El poder de los ViT es innegable, pero su costo los hacía parecer un motor de un coche de carreras de Fórmula 1: increíblemente potente, pero demasiado ineficiente y caro para el uso diario.
La solución: poda dinámica de tokens guiada por prompts
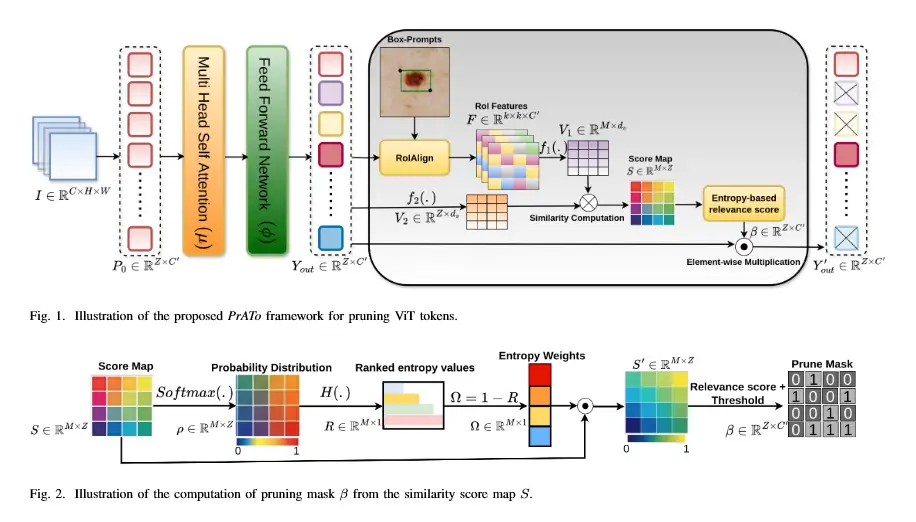
El problema estaba claramente definido: los Vision Transformers eran demasiado exhaustivos para su propio bien. Trataban cada fragmento de la imagen como si fuera potencialmente el más importante, un enfoque democrático que, en la práctica, resultaba ser una enorme pérdida de recursos. La gran mayoría de los tokens en una imagen médica típica corresponden a fondo, aire o tejido sano que no es relevante para la tarea de segmentación específica. La solución propuesta por el equipo de investigación es un golpe de genialidad pragmática, que introduce la colaboración entre el humano y la máquina en el corazón mismo del proceso computacional. Bautizaron a su método como «Poda de Tokens Adaptativa Impulsada por Prompts» (PrATo, por sus siglas en inglés), y su funcionamiento se puede desglosar en varios pasos lógicos.
El primer paso es el «prompt» o la pista. El sistema está diseñado para aceptar una guía inicial de un usuario humano. Esta guía es intencionadamente simple, para no añadir una carga de trabajo significativa al clínico. Puede ser un punto hecho con un clic en el centro de la región de interés, o una caja delimitadora dibujada de forma aproximada alrededor de la misma. Este prompt no necesita ser preciso. Su único propósito es proporcionar una localización espacial aproximada, un «aquí está» general. Este simple acto de señalar transforma por completo el problema desde el punto de vista de la IA. En lugar de enfrentarse a la imagen a ciegas, ahora tiene un punto de partida, un ancla contextual.
Una vez que se proporciona el prompt, entra en juego el primer componente clave del sistema: un mecanismo para calificar los tokens. El sistema utiliza la información espacial del prompt para realizar una primera evaluación de todos los tokens de la imagen. Los tokens que caen dentro o cerca de la caja delimitadora del prompt reciben una puntuación alta de relevancia. Los que están lejos reciben una puntuación baja. Es importante destacar que los investigadores desarrollaron un método de puntuación muy eficiente, basado en la entropía, que no requiere parámetros adicionales de aprendizaje. Esto significa que no añade una sobrecarga computacional significativa al proceso, un detalle crucial para mantener la eficiencia general del sistema. Esta puntuación inicial crea un mapa de calor de relevancia sobre la imagen, destacando las zonas «calientes» que probablemente requieran un análisis más profundo y las zonas «frías» que probablemente puedan ser ignoradas.
Aquí es donde se produce el paso más innovador: la «poda dinámica». Basándose en las puntuaciones de relevancia, el sistema toma la decisión de «podar» un cierto porcentaje de los tokens con la puntuación más baja. Podar, en este contexto, significa que estos tokens son eliminados del proceso de cálculo de la atención en las capas posteriores del Vision Transformer. Es como si un editor tachara los párrafos irrelevantes de un texto antes de que el lector principal los vea, permitiendo que el lector se concentre solo en el contenido esencial. La belleza de este sistema es que la poda es «dinámica». No es una decisión única y estática. El sistema cuenta con un «programador de poda dinámico» que decide cuántos tokens podar y en qué etapa del modelo hacerlo. Puede decidir podar una gran cantidad de tokens de fondo obvios en las primeras capas del modelo, y luego volverse más conservador en las capas más profundas, donde se analizan características más abstractas y complejas. Esta flexibilidad asegura que no se descarte información importante prematuramente. El sistema logra un equilibrio constante entre la velocidad y la precisión.
Este enfoque guiado por prompts imita de forma elegante el flujo de trabajo de un radiólogo humano. Cuando un radiólogo mira una imagen, no examina cada píxel con la misma atención. Su mirada se dirige rápidamente a las áreas anatómicas relevantes o a las regiones que parecen anómalas, basándose en su vasta experiencia. El prompt del usuario sirve como un sustituto de esta intuición inicial, y la poda dinámica emula el proceso cognitivo de centrar la atención en lo que importa. El resultado es un Vision Transformer que trabaja de forma más inteligente, no más dura. En lugar de gastar ciclos de computación en analizar el ruido de fondo o el tejido sano que no está en cuestión, concentra todo su formidable poder de análisis contextual en la región de interés y sus alrededores inmediatos. Es una simbiosis perfecta: la intuición del humano guía la precisión de la máquina, y la eficiencia de la máquina amplifica la pericia del humano.
Resultados que hablan por sí mismos
Una nueva idea en la investigación científica, por muy elegante que sea, debe demostrar su valía a través de una experimentación rigurosa. El equipo detrás de la poda dinámica de tokens sometió su método a una serie de pruebas exhaustivas, comparándolo con los modelos de Vision Transformer existentes en varios conjuntos de datos de imágenes médicas disponibles públicamente. Estos conjuntos de datos representaban una variedad de desafíos de segmentación del mundo real, desde la delineación de órganos abdominales en tomografías computarizadas hasta la identificación de lesiones en diferentes modalidades de imagen. Los resultados obtenidos no solo validaron su enfoque, sino que superaron las expectativas.
El principal objetivo del proyecto era mejorar la eficiencia, y en este frente, el éxito fue rotundo. El método demostró ser capaz de reducir la cantidad total de tokens procesados en el modelo entre un 35% y un 55% en promedio. Esta es una cifra asombrosa en el mundo de la optimización de modelos. Para ponerlo en perspectiva, una reducción del 50% en los tokens puede llevar a una disminución aún mayor en el tiempo de cálculo total, debido a la naturaleza cuadrática del mecanismo de atención de los Transformers. Esto se traduce directamente en diagnósticos más rápidos. Un análisis que antes podía tardar varios minutos en un hardware potente ahora podría completarse en una fracción de ese tiempo, acercando la segmentación por IA al ámbito del tiempo real. Además de la velocidad, la reducción de la carga computacional también significa un menor consumo de energía, un factor cada vez más importante, y la capacidad de ejecutar estos modelos avanzados en hardware menos costoso y más accesible.
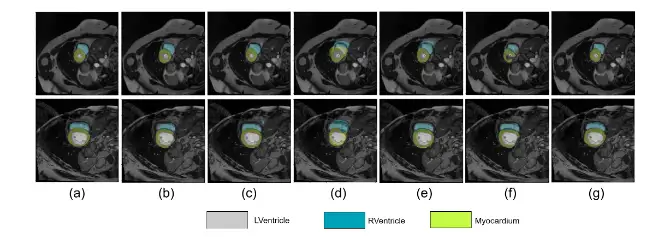
Sin embargo, la pregunta más crítica era si esta drástica ganancia de eficiencia se lograría a expensas de la precisión. A menudo, en el aprendizaje automático, existe un compromiso entre la velocidad y la exactitud. Sorprendentemente, este no fue el caso aquí. Al comparar las segmentaciones producidas por su método de poda con las de los modelos ViT estándar, los investigadores encontraron que la precisión se mantenía o, en algunos casos, incluso mejoraba. Para medir la precisión, utilizaron métricas estándar en el campo, como el coeficiente de Dice, que mide la superposición entre la segmentación predicha por la IA y la segmentación de referencia realizada por un experto humano. Los resultados mostraron que al forzar al modelo a ignorar la información de fondo irrelevante y a centrarse exclusivamente en la región de interés, se reducía el riesgo de que el modelo se confundiera con patrones de ruido o artefactos en otras partes de la imagen. La poda actuó como una forma de regularización, guiando al modelo para que aprendiera las características más robustas y pertinentes.
La generalización del método fue otro punto fuerte. Los investigadores demostraron que su marco de poda podía integrarse fácilmente en varias arquitecturas de Vision Transformer de última generación existentes. Esto significa que no es una solución aislada, sino una técnica complementaria que puede utilizarse para mejorar una amplia gama of de modelos ya establecidos. Probaron su enfoque en diferentes conjuntos de datos con diferentes características, demostrando que la técnica es robusta y no se limita a un solo tipo de imagen o tarea de segmentación. Esta versatilidad es clave para su adopción en el mundo real, ya que los hospitales y los centros de investigación trabajan con una gran diversidad de equipos de imagen y necesidades clínicas. Los resultados, en su conjunto, pintan un cuadro muy claro: la poda dinámica de tokens guiada por prompts no es solo una mejora incremental. Es un avance significativo que aborda directamente el principal cuello de botella de una de las tecnologías de IA más potentes de nuestro tiempo, logrando lo que a menudo parece imposible: hacer algo a la vez significativamente más rápido y ligeramente mejor.
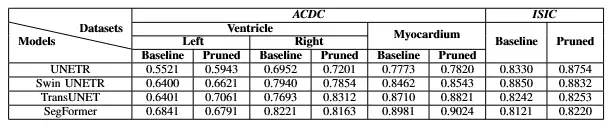
Análisis cuantitativo de la implementación de PrATo en varios modelos de línea de base de segmentación de imágenes médicas en el ACDC y conjuntos de datos de la CIIU. el valor de DSC se notifica para cada línea de base y su versión eliminada correspondiente.
El futuro de la imagen médica: más rápido, más preciso, más accesible
La introducción de técnicas como la poda dinámica de tokens no es simplemente una mejora técnica para los informáticos, sino que presagia un cambio fundamental en la forma en que se practicará la medicina diagnóstica en el futuro. Las implicaciones de tener una inteligencia artificial que puede analizar imágenes médicas de manera más rápida, económica y, a veces, más precisa, son profundas y de gran alcance, y afectarán tanto a los médicos como a los pacientes.
La consecuencia más inmediata y tangible es la aceleración del flujo de trabajo clínico. En un entorno hospitalario donde cada minuto cuenta, reducir el tiempo necesario para segmentar y analizar una imagen puede tener un impacto directo en la atención al paciente. Imaginemos un caso de accidente cerebrovascular agudo, donde es crucial determinar rápidamente el área del cerebro afectada para administrar el tratamiento adecuado. Una herramienta de IA que puede proporcionar una segmentación precisa del coágulo o la hemorragia en segundos en lugar de minutos u horas podría ser la diferencia entre una recuperación completa y una discapacidad permanente. Del mismo modo, en un departamento de radiología concurrido, la automatización rápida de tareas rutinarias de segmentación libera a los radiólogos de la carga de trabajo tediosa, permitiéndoles centrarse en los casos más complejos y en la interpretación final, lo que en última instancia conduce a diagnósticos de mayor calidad para más pacientes en menos tiempo.
Más allá de la velocidad, la eficiencia computacional de estos nuevos modelos tiene el poder de democratizar el acceso a la atención médica de alta tecnología. Los modelos de inteligencia artificial de vanguardia a menudo requieren una infraestructura informática costosa, con potentes unidades de procesamiento gráfico (GPU) que están fuera del alcance de muchos hospitales pequeños, clínicas rurales o sistemas de salud en países en desarrollo. Al reducir drásticamente los requisitos computacionales, la poda de tokens permite que estos algoritmos avanzados se ejecuten en hardware más modesto y asequible. Esto podría significar que un pequeño hospital comunitario podría tener acceso a la misma calidad de análisis de imágenes por IA que un gran centro médico académico. Esta democratización es un paso crucial para reducir las disparidades en la atención médica y garantizar que los beneficios de la revolución de la IA lleguen a todas las poblaciones.
Además, la naturaleza interactiva del enfoque basado en prompts fomenta un nuevo paradigma de colaboración entre el médico y la IA. En lugar de que la IA sea una «caja negra» que produce un resultado sin explicación, este sistema invita al médico a participar en el proceso. El clínico utiliza su experiencia para guiar a la IA, y la IA utiliza su poder computacional para refinar y cuantificar las observaciones del clínico. Este modelo de «humano en el circuito» no solo mejora la confianza del médico en las herramientas de IA, sino que también crea un sistema robusto que combina lo mejor de ambos mundos: la intuición y el conocimiento contextual del experto humano con la velocidad, la precisión y la resistencia a la fatiga de la máquina.
Mirando hacia el futuro, esta línea de investigación abre nuevas y emocionantes vías. Se podría explorar el uso de prompts más sofisticados, como indicaciones de texto o incluso comandos de voz, para guiar a la IA. Los modelos futuros podrían aprender a solicitar la intervención humana cuando su confianza es baja, creando un diálogo aún más fluido entre el médico y la máquina. La eficiencia ganada también podría permitir el desarrollo de modelos aún más grandes y complejos, capaces de analizar no solo imágenes, sino de integrar información de múltiples fuentes, como el historial clínico electrónico del paciente, los datos genómicos y los informes de laboratorio, para llegar a un diagnóstico verdaderamente holístico y personalizado. En última instancia, el trabajo sobre la poda dinámica de tokens es un brillante ejemplo de cómo la investigación en inteligencia artificial puede abordar problemas del mundo real con soluciones elegantes y de gran impacto. No se trata de reemplazar a los médicos, sino de empoderarlos con herramientas que son más inteligentes, más rápidas y más eficientes. Es un paso importante hacia un futuro en el que la tecnología no solo amplía los límites de lo que es posible en la medicina, sino que también hace que esa posibilidad sea una realidad accesible para todos.
Fuentes
- Dutta, P., Maity, A., & Mitra, S. (2024). Prompt-based Dynamic Token Pruning for Efficient Segmentation of Medical Images. arXiv preprint arXiv:2506.16369.

