
La creación de entornos tridimensionales que se puedan explorar con naturalidad es una necesidad cada vez más palpable en el mundo tecnológico contemporáneo. Desde los videojuegos hasta la robótica autónoma, pasando por la realidad aumentada y la simulación industrial, la demanda de escenarios que imiten la complejidad del mundo real no deja de crecer. Tradicionalmente, reconstruir una escena 3D de forma fidedigna ha requerido capturar imágenes desde muchos ángulos y medir con precisión la posición de cada cámara. Estos sistemas multi‑vista resultan costosos y limitan su uso a proyectos muy concretos. Aun así, la comunidad científica ha avanzado en técnicas de reconstrucción neural que extraen escenas detalladas a partir de conjuntos de imágenes. Sin embargo, incluso los métodos recientes se apoyan en bases de datos cuidadosamente reunidas y su capacidad de extrapolar a situaciones no vistas sigue siendo escasa.
En paralelo, la inteligencia artificial generativa ha vivido una eclosión. Los modelos de difusión, entrenados con millones de fotos y vídeos, son capaces de imaginar mundos enteros a partir de un ruido inicial, creando imágenes o secuencias que jamás existieron en la realidad. En el ámbito del vídeo, estos modelos se han convertido en una alternativa prometedora a las redes antagónicas generativas (GAN), situándose en el centro del panorama de la generación visual. Su fuerza radica en un proceso de «difusión» que añade ruido de manera progresiva a los datos y luego aprende a revertir ese proceso, de modo que la red pueda convertir un conjunto de ruido en una secuencia coherente y atractiva. La dificultad está en mantener la coherencia temporal: cada fotograma no solo debe ser estético sino también estar alineado con los anteriores para que el movimiento resulte fluido.
Combinar la potencia imaginativa de los modelos generativos con la necesidad de generar entornos tridimensionales ha sido un sueño para investigadores y diseñadores. Lyra es un paso decidido en esa dirección. Presentado por un equipo de NVIDIA y de varias universidades canadienses, este trabajo propone un enfoque generativo para reconstruir escenas 3D a partir de una imagen o un vídeo, sin necesidad de capturar múltiples vistas reales. La idea se resume en entrenar un decodificador de «salpicaduras gaussianas 3D» (3D Gaussian Splatting o 3DGS) para que aprenda de los resultados de un modelo de difusión de vídeo existente. Esta técnica, denominada autoconfiguración o auto‑distilación, transforma la habilidad implícita que tiene el generador de vídeo para entender el espacio tridimensional en una representación explícita que se pueda explorar y renderizar en tiempo real. Al final, Lyra es capaz de recibir una foto o un clip corto y producir una escena tridimensional coherente que se puede recorrer desde distintos ángulos o incluso extender a lo largo del tiempo.
Para quienes no están familiarizados con estos conceptos, este artículo desglosa los elementos técnicos con un lenguaje accesible. Introducimos el contexto de la reconstrucción 3D, repasamos qué son los modelos de difusión de vídeo y qué papel juegan las salpicaduras gaussianas en la representación de escenas. Luego explicamos el entramado de Lyra: cómo se entrenan los modelos, cuál es su arquitectura y qué resultados alcanzan. Por último, reflexionamos sobre las aplicaciones potenciales, las implicancias éticas y los horizontes que se abren en el futuro.
Contexto y estado del arte
El desafío de reconstruir escenas complejas
La reconstrucción de una escena tridimensional a partir de fotografías es un problema clásico de la visión por computadora. La técnica más simple, la fotogrametría, deduce la estructura del entorno extrayendo los puntos de interés y triangulando su posición en el espacio. En los últimos años, las metodologías se han desplazado hacia enfoques de representación neural en los que la escena se modela mediante redes profundas que aprenden a reproducir la iluminación y la geometría. NeRF (Neural Radiance Fields) y sus variantes han demostrado que es posible obtener imágenes fotorrealistas desde cualquier ángulo con unas pocas fotografías de entrada. La principal desventaja de estos sistemas es que necesitan posiciones de cámara precisas y solo reconstruyen aquello que se ve en las imágenes de entrada; extrapolar lo que no aparece es complicado.
Los modelos feed‑forward surgen como alternativa para acelerar la reconstrucción sin tener que optimizar cada escena. En lugar de refinar una representación mediante un proceso iterativo, estos modelos aprenden a predecir la estructura 3D directamente a partir de una o varias imágenes. Aunque permiten inferir resultados con rapidez, su rendimiento tiende a depender del dominio en el que se entrenan: si aprenden a partir de imágenes de interiores, su capacidad para generalizar a paisajes es limitada. Además, las redes suelen requerir un conjunto de vistas fijas para funcionar bien, lo que vuelve a caer en la dependencia de datos multi‑vista difíciles de conseguir.
Modelos de difusión de vídeo y control de cámara
En el mundo de la inteligencia artificial generativa, los modelos de difusión se han revelado como herramientas versátiles para crear imágenes y vídeos. Su idea básica es comenzar con un ruido caótico y enseñar a la red a eliminar ese ruido paso a paso, generando un resultado coherente. A diferencia de los generadores clásicos, la difusión permite un control más preciso sobre las condiciones de salida, como el texto o la cámara, y facilita la integración de distintas modalidades. Los algoritmos han tenido tal impacto que se consideran el sustituto natural de las GAN en muchos casos.
Los modelos de difusión de vídeo amplían el concepto a secuencias temporales. Para que un vídeo resulte realista, los diferentes fotogramas deben mantener la continuidad. Para lograrlo, los investigadores introducen capas de atención temporal que permiten compartir información entre los fotogramas y garantizan que los movimientos y los cambios de iluminación tengan sentido a lo largo del tiempo. Algunas arquitecturas incorporan atajos causales que solo permiten que un fotograma se influencie por los anteriores, reduciendo así el consumo de memoria y mejorando la eficiencia. También se ha generalizado el uso de autoencoders variacionales que codifican el vídeo en un espacio latente compacto para que la generación sea más rápida y escalable.
Para obtener control de cámara, los investigadores han desarrollado adaptaciones que representan las poses como embebidos de Plücker y ajustan la red para condicionar la generación de cada fotograma en la posición y orientación de la cámara. Trabajos como GEN3C, MotionCtrl y otros han demostrado que es posible generar vídeos con trayectorias de cámara arbitrarias e incluso realizar operaciones como realizar un recorrido circular alrededor de un objeto. No obstante, estas técnicas producen solamente secuencias bidimensionales; carecen de una representación tridimensional explícita que pueda utilizarse en simuladores físicos o motores gráficos.
Salpicaduras gaussianas 3D (3D Gaussian Splatting)
Para superar las limitaciones de las representaciones volumétricas densas o de los campos radiantes, algunos investigadores han adoptado la técnica de las salpicaduras gaussianas en 3D. Este enfoque consiste en representar la escena mediante millones de elipsoides translúcidos («splats»), cada uno con su posición, tamaño, color y transparencia. Cuando se observan en conjunto, estos splats se combinan y recrean con fidelidad el objeto o el entorno original. Según un artículo del equipo de Chaos, cada splat se genera a partir de un punto de un nublado inicial de fotogrametría, y sus parámetros se ajustan mediante un proceso de optimización que compara las imágenes renderizadas con las fotografías reales. Esta representación tiene varias ventajas: captura detalles de iluminación complejos, requiere menos memoria que mallas densas y permite renderizar escenas con millones de elementos en tiempo real. Sin embargo, también presenta desafíos, como la dificultad para representar detalles finos y la gestión de la memoria cuando la escena es muy grande.
Fundamentos técnicos
Principios de los modelos de difusión
La difusión es un proceso probabilístico que puede entenderse como la conversión gradual de datos estructurados en ruido y viceversa. En la etapa de entrenamiento, se añade ruido aleatorio al input —una imagen o un vídeo— durante muchos pasos hasta convertirla en ruido puro. A continuación, el modelo aprende a revertir ese proceso al predecir el ruido que debe sustraerse en cada paso. Una vez que se aprende esta inversión, la red puede empezar con ruido y generar datos sintéticos. En el caso de las imágenes, la arquitectura más utilizada es una U‑Net con bloques de transformer que permiten compartir información a lo largo de toda la imagen y condicionar la generación en función de textos u otras entradas. Para el vídeo, los bloques se modifican añadiendo atención temporal y mecanismos causales que garantizan que los fotogramas sean coherentes en el tiempo.
Para reducir la carga computacional, muchos modelos trabajan en un espacio latente. Mediante un autoencoder variacional (VAE), las imágenes se transforman en un conjunto de variables comprimidas que preservan la información esencial. La difusión se lleva a cabo en este espacio reducido y, una vez completado el proceso de denoising, un decodificador reconstruye la imagen o el vídeo final. Este enfoque, llamado difusión latente, hace posible generar contenidos de alta resolución con hardware convencional.
Representación con salpicaduras gaussianas
Las salpicaduras gaussianas constituyen una alternativa eficiente para almacenar y renderizar escenas tridimensionales. Cada splat es un elipsoide definido por catorce parámetros: posición, escala, rotación, opacidad y color. Durante la reconstrucción, los splats se proyectan sobre una pantalla y se mezclan para producir un fotograma que se asemeje a la escena original. Este proceso, conocido como rasterización diferenciable, permite calcular gradientes y ajustar los parámetros de los splats para minimizar la diferencia entre las imágenes renderizadas y las de referencia. El resultado es una representación que ofrece un equilibrio entre realismo, eficiencia y velocidad, adecuada para aplicaciones en tiempo real.
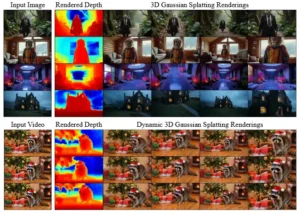
Generación de escenas 3D y 4D con avance. A partir de una sola imagen (arriba), Lyra infiere una representación 3D de dispersión gaussiana (3DGS) con avance, mediante la autodestilación de un modelo de difusión de video sin necesidad de datos multivista reales. Con una entrada de video (abajo), Lyra infiere un 3DGS dinámico que ofrece control interactivo tanto en tiempo (filas) como en punto de vista (columnas).
El enfoque Lyra
Auto‑distilación: enseñar a un modelo a ser maestro
El corazón de Lyra reside en un mecanismo de auto‑distilación que convierte el conocimiento implícito de un modelo de difusión de vídeo en una forma explícita y navegable. Para ello, los autores adoptan un esquema de maestro–aprendiz: el maestro es un modelo de difusión de vídeo con control de cámara (en este caso, el modelo GEN3C) y el aprendiz es un decodificador de salpicaduras gaussianas 3D diseñado para generar una escena tridimensional a partir del espacio latente del maestro. Durante el entrenamiento, el modelo de difusión genera secuencias de vídeo a partir de imágenes y trayectorias de cámara sintéticas. El decodificador 3DGS se alimenta del mismo espacio latente pero produce un conjunto de splats que, al renderizarse desde las mismas cámaras, deberían coincidir con los fotogramas del maestro. La pérdida de entrenamiento se calcula comparando las imágenes producidas por ambos y ajustando los parámetros del decodificador para minimizar esta diferencia.
El truco consiste en no utilizar ningún dato real de múltiples vistas. En lugar de capturar escenas con cámaras físicas, los investigadores generan sus propios ejemplos con el modelo de difusión maestro. Para cada imagen se seleccionan seis trayectorias de cámara que exploran la escena desde ángulos distintos, generando 726 vistas sintéticas de alta resolución. El decodificador 3DGS aprende a fusionar toda esta información en una escena coherente, rellenando las zonas ocultas o poco vistas. Gracias a que se opera en el espacio latente, el modelo puede manejar una gran cantidad de vistas sin saturar la memoria.
Arquitectura del decodificador 3DGS
La arquitectura del decodificador se inspira en los modelos de transformers y en los novedosos bloques Mamba‑2, que combinan atención y filtros de convolución para procesar de manera eficiente secuencias largas. El decodificador recibe como entradas los latentes de vídeo generados por el maestro y los embebidos de Plücker que codifican la dirección y el origen de cada rayo de cámara. Antes de procesarlos, se dividen en parches para reducir su tamaño, y luego se apilan y atraviesan un conjunto de bloques de reconstrucción. Tras dos repeticiones de dieciséis capas con 512 dimensiones ocultas, un módulo de convolución transpuesta produce catorce canales que representan las propiedades de cada salpicadura.
Un elemento clave de esta arquitectura es la fusión multi‑vista. En lugar de generar una nube de splats por cada trayectoria de cámara y fusionarlas después, el decodificador aprende a combinar toda la información simultáneamente. El resultado es una escena compacta, con redundancias mínimas y con mayor consistencia geométrica. Para mejorar la calidad y evitar que los splats de baja importancia saturen la representación, el modelo utiliza un pruning basado en la opacidad: se eliminan el 80 % de las salpicaduras con menor opacidad, lo que reduce el tiempo de renderizado y mejora la visibilidad de los elementos importantes.
Función de pérdida y supervisión
El entrenamiento del decodificador se guía mediante varias componentes de pérdida. La más básica es la pérdida de reconstrucción, que combina un error cuadrático medio (MSE) con una medida perceptual (LPIPS) para asegurar que las imágenes renderizadas no solo sean parecidas en términos de intensidad de píxel sino también perceptualmente similares. Además, se utiliza un término de profundidad que compara los mapas de profundidad estimados con los generados por una herramienta externa para evitar geometrías planas. Finalmente, se penaliza la opacidad excesiva para fomentar una representación más limpia y eficiente. Estos términos se ponderan con factores fijados empíricamente, y el resultado es una pérdida total que guía al modelo hacia representaciones tridimensionales realistas y compactas.
Extensión a escenas dinámicas
Lyra no se limita a entornos estáticos. Los autores extienden su enfoque para manejar escenas dinámicas, lo que equivale a generar un conjunto de salpicaduras 4D (3D + tiempo) que varían en función del fotograma. Para ello, se introducen embebidos temporales que codifican el tiempo de origen y destino en la secuencia. Durante el entrenamiento, se seleccionan momentos aleatorios y se supervisa la representación solo en ese instante. El modelo también emplea una estrategia de aumento de datos que invierte la secuencia temporal para evitar que las primeras vistas carezcan de cobertura y se generen splats con opacidad baja. De este modo, la red aprende a interpolar de manera fluida entre distintos momentos y a producir escenas dinámicas coherentes.

Generación de imágenes a 3DGS. Visualizamos cinco vistas de escenas 3DGS generadas.
Resultados experimentales
Para evaluar la eficacia de Lyra, los autores crearon su propio conjunto de entrenamiento (el Lyra dataset) a partir de millones de combinaciones de textos y escenas generadas con el modelo maestro. En total, recopilaron 59 031 imágenes para la configuración estática y 7 378 vídeos para la dinámica. A cada entrada se le asociaron seis trayectorias de cámara, lo que produjo más de 354 000 secuencias para la parte estática y 44 268 para la dinámica.
En la evaluación de imágenes a 3D, Lyra se probó en los conjuntos estándar RealEstate10K, DL3DV y Tanks‑and‑Temples. Los resultados se valoraron con métricas como PSNR (Signal‑to‑Noise Ratio), SSIM (Structural Similarity Index) y LPIPS (una medida perceptual de distancias entre imágenes). Los métodos previos, como ZeroNVS, ViewCrafter, Wonderland y Bolt3D, servían de referencia. Los números mostraron que Lyra superó a los competidores en la mayoría de las métricas: en RealEstate10K obtuvo un PSNR de 21,79 dB, un SSIM de 0,752 y un LPIPS de 0,219, ligeramente superiores a Bolt3D. En DL3DV y Tanks‑and‑Temples, los valores también fueron competitivos, consolidando su posición como referencia en la generación de escenas desde una sola imagen.
Para las escenas dinámicas, aunque los conjuntos de prueba eran más limitados, Lyra demostró que es capaz de generar entornos 4D coherentes y que mantiene la continuidad temporal. El estudio incluyó visualizaciones cualitativas que mostraban paseos virtuales alrededor de esculturas, interiores de viviendas y paisajes generados a partir de un vídeo de entrada. El modelo reproducía detalles temporales como el movimiento de las olas o la variación de la luz a lo largo del día, algo difícil de conseguir con técnicas previas.
Ablaciones y análisis de diseño
Un aspecto que refuerza la solidez del trabajo es el análisis ablatorio. Los investigadores deshabilitaron componentes clave y midieron cómo afectaban al resultado. Cuando se eliminaba la auto‑distilación y se entrenaba solo con datos reales, el rendimiento se desplomaba: la PSNR caía a 19,08 y la SSIM a 0,659. Esto evidenciaba que el conjunto sintético generado por el modelo maestro era más diverso y coherente que los conjuntos de datos multi‑vista tradicionales. Al suprimir la pérdida de profundidad, la geometría se volvía más plana y las imágenes menos precisas. La eliminación del pruning de opacidad incrementaba el tiempo de renderizado en un 67 % y empeoraba ligeramente la calidad visual. La ausencia de la pérdida perceptual (LPIPS) provocaba artefactos y reducía notablemente el LPIPS global.
Otro elemento crítico era la fusión multi‑vista. Si se generaba una nube de splats por trayectoria y luego se fusionaba, la calidad decrecía considerablemente. La arquitectura conjunta con bloques Mamba‑2 también aceleraba la inferencia; sustituirlos por transformadores puros aumentaba el tiempo de cómputo de 3,2 segundos a 20,9 segundos por escena. Finalmente, al intentar operar en espacio de píxeles en lugar de espacio latente, el modelo consumía tanta memoria que el entrenamiento se volvía inviable.
Aplicaciones y repercusiones
El potencial de Lyra va más allá de un mero avance académico. La posibilidad de generar entornos tridimensionales a partir de una sola fotografía abre oportunidades en la realidad virtual, el cine y el videojuego, donde los artistas podrían materializar escenas imaginarias sin el coste de modelarlas manualmente. En la robótica y la conducción autónoma, la capacidad de sintetizar mundos plausibles permite entrenar agentes en simuladores realistas sin depender de costosas capturas del mundo real. La propia NVIDIA ha destacado que las técnicas de generación y simulación que presentará en congresos como SIGGRAPH ayudan a diseñar objetos, personajes y entornos complejos; estas herramientas de generación pueden alimentar simuladores para entrenar robots o vehículos autónomos.
El enfoque de Lyra resulta particularmente atractivo para la investigación en IA encarnada, en la que un agente debe percibir, navegar e interactuar con su entorno. La posibilidad de disponer de escenas consistentes y geográficamente correctas en tiempo real proporciona un banco de pruebas infinito para algoritmos de planificación y aprendizaje por refuerzo. La representación con salpicaduras gaussianas, al garantizar la consistencia geométrica, permite simular colisiones, trayectorias y respuestas físicas de manera realista.
Además, esta tecnología tiene implicaciones sociales. Al democratizar la generación de mundos 3D, se podrían facilitar proyectos artísticos o educativos en los que cualquier usuario, con una simple imagen, cree entornos inmersivos. Sin embargo, también se abren riesgos: la generación de mundos plausibles a partir de datos mínimos podría utilizarse para generar contenidos engañosos o manipulados. El propio artículo reconoce que la tecnología puede ser mal utilizada para crear escenas sintéticas engañosas y aboga por mecanismos de trazabilidad de procedencia y documentación rigurosa.
Contribuciones de Lyra
Para resumir los logros y la originalidad de Lyra, los autores destacan tres aportaciones fundamentales:
-
Autoconfiguración sin datos multi‑vista reales. Lyra entrena un decodificador 3DGS usando un modelo de difusión de vídeo controlado por cámara como maestro, eliminando la necesidad de datos capturados de escenas reales y diversificando así los entornos de entrenamiento.
-
Extensión a escenas dinámicas. El método se adapta fácilmente para generar escenas 4D (3D más tiempo) a partir de un vídeo monocular, permitiendo que las salpicaduras gaussianas varíen a lo largo de la secuencia.
-
Generalización y rendimiento superior. El modelo demostró un rendimiento de vanguardia en la generación de escenas tridimensionales a partir de una sola imagen y en la generación de escenas dinámicas a partir de un vídeo, superando a métodos anteriores en diversas métricas y escenarios de prueba.
Estas contribuciones se basan en una fusión inteligente de conceptos previamente separados: la generación de vídeo y la reconstrucción 3D. El resultado no solo es técnicamente elegante, sino que abre un abanico de posibilidades para construir «motores de mundos» que puedan alimentar simuladores, videojuegos o espacios artísticos de una forma sencilla y accesible.
Consideraciones éticas y futuras direcciones
Como ocurre con cualquier avance en inteligencia artificial generativa, la ética ocupa un lugar central. Lyra permite generar mundos creíbles a partir de información limitada, lo que puede prestarse a usos engañosos o maliciosos. El equipo de investigación reconoce estos riesgos y propone medidas como el seguimiento de procedencia, la transparencia en los datos y buenas prácticas de evaluación. También advierte sobre el potencial de que la gente confunda escenas generadas con realidades, y anima a que se desarrollen herramientas para detectar contenido sintético.
En el plano técnico, los autores señalan que el rendimiento de Lyra está condicionado por la capacidad del modelo de difusión maestro. La generación de escenas aún puede presentar inconsistencias o limitaciones de escala si el maestro no es suficientemente robusto. Un camino natural es mejorar los modelos de difusión de vídeo con arquitecturas más ricas o técnicas autorregresivas que permitan crear mundos más extensos. También es interesante investigar métodos para integrar datos reales con la auto‑distilación, explorar representaciones alternativas y aplicar Lyra a ámbitos como la medicina o la arqueología, donde la reconstrucción de espacios tiene impacto directo.
Conclusiones
Lyra representa un punto de inflexión en la confluencia entre la generación de vídeo y la reconstrucción de escenas tridimensionales. Mediante una estrategia de auto‑distilación ingeniosa, el método destila el entendimiento espacial de un modelo de difusión en una representación explícita de salpicaduras gaussianas. Gracias a ello, es capaz de crear entornos 3D y 4D coherentes a partir de una sola imagen o un vídeo, sin necesidad de conjuntos de datos multi‑vista capturados en el mundo real. Sus resultados superan a los métodos contemporáneos y muestran que es posible generalizar a una gran variedad de escenas, desde interiores domésticos hasta paisajes imaginarios.
Más allá de las cifras, Lyra ofrece una visión estimulante del futuro. Su tecnología podría alimentar simuladores para robots, generar mundos virtuales para videojuegos o construir espacios educativos accesibles desde cualquier dispositivo. Sin embargo, también plantea retos éticos y técnicos que exigen atención. Los próximos años serán decisivos para ver cómo evoluciona esta línea de investigación y cómo se integran sus logros en la sociedad. Lo que es seguro es que, al igual que ocurrió con los modelos generativos de imágenes, la capacidad de generar mundos tridimensionales a partir de simples indicios transformará nuestra relación con la realidad virtual, la simulación y la creatividad.
Referencias
Bahmani, S., Shen, T., Ren, J., Huang, J., Jiang, Y., Turki, H., Tagliasacchi, A., Lindell, D., Gojcic, Z., Fidler, S., Ling, H., Gao, J., & Ren, X. (2025). Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self‑Distillation. arXiv:2509.19296.
Zhekov, G. (2025). 3D Gaussian Splatting: A new frontier in rendering. Chaos. Recuperado de https://blog.chaos.com/3d-gaussian-splatting-new-frontier-in-rendering

