
En los anales de la ciencia computacional, la imagen del descubrimiento ha sido, durante décadas, una de perseverancia artesanal. Visualice a un estudiante de doctorado o a un pequeño equipo de investigadores, encorvados sobre sus teclados durante meses, a veces años, en un ciclo meticuloso de diseño, implementación y depuración de un único y novedoso algoritmo. Cada línea de código es un producto del ingenio humano, cada avance es el resultado de una intuición cultivada y una extenuante prueba y error. Este proceso, a escala humana, ha impulsado la era digital.
Pero una nueva era está amaneciendo, impulsada por una fuerza tan potente y disruptiva que amenaza con redefinir la propia naturaleza del descubrimiento. A las puertas de este establecido orden, se agolpan los que elocuentemente un grupo de investigadores de la Universidad de California en Berkeley ha denominado «los bárbaros».
Estos bárbaros, sin embargo, no portan antorchas para destruir, sino herramientas de una complejidad sin precedentes. Son sistemas de inteligencia artificial que están comenzando a automatizar el núcleo creativo de la investigación científica.
La tesis central de su trabajo, titulado «Barbarians at the Gate: How AI is Upending Systems Research», es que una nueva clase de enfoques, a los que denominan Investigación Guiada por IA para Sistemas (ADRS, por sus siglas en inglés), está inaugurando una era de descubrimiento automatizado de algoritmos, prometiendo acelerar el ritmo del progreso de una manera que hasta ahora pertenecía al ámbito de la ciencia ficción. Este cambio no es meramente tecnológico; representa una transformación fundamental en la manera en que se concibe y se ejecuta la ciencia.
Para el público no especializado, la maquinaria detrás de esta revolución puede parecer arcana, pero sus principios son sorprendentemente intuitivos. En el corazón de ADRS se encuentran los Grandes Modelos de Lenguaje (LLM), la misma tecnología que impulsa herramientas como ChatGPT. Estos modelos actúan como inagotables generadores de ideas, capaces de proponer nuevas soluciones algorítmicas con una fluidez y una velocidad asombrosas. Sin embargo, una avalancha de ideas carece de valor sin un método para discernir las brillantes de las defectuosas. Aquí es donde entra el segundo pilar del sistema: el «verificador fiable».
Este componente es, en esencia, un laboratorio digital, un campo de pruebas virtual donde cada nueva idea generada por la IA puede ser sometida a un escrutinio instantáneo y objetivo. Puede ser un sistema informático real o, más comúnmente, una simulación de alta fidelidad. El éxito o el fracaso no es una cuestión de opinión, sino de rendimiento cuantificable: velocidad, coste, eficiencia. No hay lugar para la ambigüedad; los números dictan el veredicto.
El proceso se desenvuelve como un ciclo implacable de «generar, probar, aprender y repetir». La IA propone una solución en forma de código. El simulador la ejecuta bajo una carga de trabajo predefinida y la evalúa. Los resultados, ya sean un éxito rotundo o un fracaso estrepitoso, se retroalimentan a la IA, que utiliza esta nueva información para refinar su próxima propuesta. Este bucle se repite cientos, a veces miles de veces, en cuestión de horas, permitiendo una evolución de soluciones que a un equipo humano le llevaría meses o años de trabajo.
La metáfora de los bárbaros, por tanto, se revela no como una de destrucción, sino de una integración transformadora. No están aquí para saquear la ciudadela del conocimiento, sino para convertirse en los soldados más infatigables y poderosos en el ejército de la ciencia, liderados por investigadores humanos que ahora asumen el rol de generales estratégicos. Este artículo explorará la arquitectura de este nuevo investigador artificial, desvelará por qué ciertos campos de la ciencia son su terreno de conquista ideal y narrará las crónicas de sus primeros y asombrosos descubrimientos, que ya superan el ingenio de sus creadores humanos.

El nacimiento de un investigador artificial
Para comprender la magnitud de esta transformación, es necesario diseccionar la anatomía de este nuevo tipo de investigador. La arquitectura ADRS no es una caja negra mágica, sino un sistema lógicamente estructurado que formaliza y automatiza el proceso intuitivo de la investigación. La mejor analogía es la de un equipo de investigación sobrehumano, perfectamente coordinado y operando a la velocidad de la luz, donde cada componente desempeña un rol especializado.
El proceso comienza con el Generador de Prompts, que actúa como el director del proyecto. Aquí es donde la inteligencia humana establece la misión. El investigador no escribe el algoritmo final, pero define el universo en el que este debe nacer. Proporciona una descripción detallada del problema, los objetivos de optimización (¿buscamos minimizar el coste, la latencia o maximizar el rendimiento?), las restricciones inviolables y, fundamentalmente, el código del entorno de pruebas o simulador.
La calidad de este «prompt» inicial, esta directiva estratégica, es el factor más determinante para el éxito de toda la empresa. Es el equivalente a un general dando un informe de misión claro y preciso a su ejército.
Una vez definida la misión, entra en juego el Generador de Soluciones, el equipo de «brainstorming» del sistema. Este componente utiliza uno o más Grandes Modelos de Lenguaje para traducir la directiva de alto nivel en soluciones concretas, es decir, en código funcional. Una de sus fortalezas es la capacidad de emplear un conjunto de modelos diversos. Algunos pueden estar configurados para la «exploración», generando ideas audaces y poco convencionales, mientras que otros se centran en la «explotación», refinando y mejorando las ideas prometedoras ya existentes. Esta dualidad equilibra la creatividad con el pragmatismo.
Cada fragmento de código generado es enviado inmediatamente al Evaluador, el laboratorio de pruebas de calidad. Este es el verificador fiable en acción. Toma el código, lo integra en el sistema o simulador, lo somete a cargas de trabajo realistas y le asigna una puntuación de rendimiento objetiva. Este componente es el juez imparcial, la fuente de retroalimentación empírica que ancla todo el proceso en la realidad. Su veredicto es puramente cuantitativo, eliminando cualquier sesgo o subjetividad.
Toda esta información, cada solución propuesta junto con su puntuación y los detalles de su evaluación, se archiva meticulosamente en el Almacenamiento. Esta base de datos funciona como la memoria institucional del proyecto, un registro exhaustivo de cada experimento, cada éxito y cada fracaso. Es un archivo de conocimiento que crece con cada iteración.
Finalmente, el Selector de Soluciones actúa como el estratega de investigación y desarrollo. Este componente consulta de manera inteligente el archivo. Su tarea no es simplemente elegir la mejor solución encontrada hasta el momento, lo que podría llevar a un estancamiento prematuro en un óptimo local. En cambio, selecciona un conjunto diverso de soluciones interesantes y de alto rendimiento. Esta diversidad es crucial: al reintroducir en el sistema no solo al «ganador» sino también a otros «contendientes prometedores», se evita que la búsqueda se obsesione con una única línea de pensamiento y se fomenta una evolución más rica y creativa.
Estos componentes operan en un «bucle interno» completamente automatizado, un ciclo de generar, evaluar, seleccionar y refinar que se ejecuta sin intervención humana. Sin embargo, la arquitectura también contempla un «bucle externo», donde el investigador humano puede observar el progreso de la IA, identificar direcciones prometedoras o callejones sin salida, y proporcionar orientación estratégica adicional, actualizando el prompt con nuevas ideas o restricciones.
Lo que emerge de este análisis es que ADRS no es un método ajeno a la ciencia. Es, de hecho, una formalización computacional del método científico mismo: formular una hipótesis (el prompt), realizar un experimento (la evaluación), analizar los resultados (la selección) y formular una nueva hipótesis. La revolución no radica en la invención de un nuevo método, sino en la automatización y escalado del método existente en órdenes de magnitud, transformando un proceso limitado por la cognición y la resistencia humanas en uno limitado únicamente por la capacidad de cómputo.
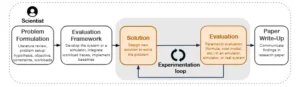
Gráfico 1. Las cinco etapas del proceso de investigación de sistemas. En este artículo, mostramos cómo la IA puede automatizar las etapas de Solución y Evaluación (zona gris).
El laboratorio perfecto para la inteligencia artificial
Toda tecnología disruptiva encuentra un primer terreno fértil, un dominio donde sus capacidades únicas se alinean perfectamente con los desafíos existentes. Para la investigación guiada por IA, ese terreno es la investigación de sistemas. Antes de explorar por qué, es crucial definir este campo para el lector no especializado. La investigación de sistemas es la ciencia y la ingeniería que se ocupan de construir la infraestructura digital fundamental de nuestro mundo.
Son los arquitectos del invisible andamiaje que sostiene la sociedad moderna: los sistemas operativos en nuestros teléfonos, las bases de datos que gestionan el comercio electrónico global, las redes de comunicación que nos permiten ver vídeo en tiempo real y las vastas plataformas de computación en la nube que, irónicamente, alojan y entrenan a las propias inteligencias artificiales.
La razón principal por la que este campo es tan adecuado para ADRS se puede resumir en una frase: la existencia del verificador fiable. La investigación de sistemas, en gran parte, se ocupa de problemas de rendimiento, y el rendimiento es, por naturaleza, objetivamente medible. Esta característica proporciona el anclaje empírico que los sistemas de IA necesitan para evitar la «alucinación» o la generación de soluciones incorrectas.
Primero, el rendimiento es cuantificable. Es relativamente sencillo determinar si un nuevo algoritmo para, por ejemplo, equilibrar la carga en un servidor, es mejor que el anterior. Se implementa la nueva lógica en el sistema, se le somete a una carga de trabajo representativa y se miden métricas como la latencia (el tiempo de respuesta), el rendimiento (la cantidad de trabajo realizado por unidad de tiempo) o el coste. Los números resultantes ofrecen un veredicto claro e irrefutable.
Segundo, la corrección funcional suele preservarse o es fácil de verificar. La IA no está diseñando un sistema completo desde cero. Generalmente, su tarea es optimizar un componente específico y bien definido dentro de un sistema más grande, como un planificador de tareas o un gestor de caché. El objetivo es mejorar el rendimiento de ese componente sin romper la funcionalidad del conjunto. Verificar esto es a menudo sencillo; por ejemplo, se puede comprobar si un nuevo algoritmo de enrutamiento de red sigue entregando todos los paquetes a su destino correcto.
Tercero, el código a modificar suele estar localizado. Los cambios algorítmicos se confinan a menudo a una porción de código relativamente pequeña y aislada. Esto no solo facilita que la IA razone sobre las modificaciones, sino que también permite que los investigadores humanos comprendan, interpreten y validen la solución generada, construyendo confianza en el proceso.
Finalmente, y de manera crucial, la cultura de la investigación de sistemas ya depende en gran medida de los simuladores. Construir y experimentar en sistemas reales a gran escala es costoso y lento. Por ello, los investigadores habitualmente crean simuladores que capturan las características esenciales del sistema real, permitiendo una iteración rápida y económica.
Estos simuladores son el entorno de evaluación perfecto para ADRS. Permiten que el sistema de IA ejecute miles de experimentos en cuestión de horas y con un coste mínimo, a menudo de solo unas pocas decenas de dólares por descubrimiento, un coste insignificante en el contexto de la investigación científica.
Esta perfecta adecuación revela una dinámica más profunda y simbiótica. El trabajo de Berkeley presenta una calle de un solo sentido: la IA está revolucionando la investigación de sistemas. Sin embargo, la implicación más profunda es que esta es una relación de beneficio mutuo. Las inteligencias artificiales más avanzadas requieren sistemas de computación de altísimo rendimiento para ser entrenadas y desplegadas.
Al utilizar ADRS para mejorar estos mismos sistemas (optimizando la programación en la nube, el equilibrio de carga para los propios modelos de IA, etc.), la comunidad de sistemas no solo se beneficia de la IA, sino que se convierte en un habilitador crítico de futuras inteligencias artificiales aún más potentes. Esto crea un ciclo de retroalimentación positiva, un círculo virtuoso donde el progreso tecnológico se autoalimenta: una mejor IA conduce a mejores sistemas, lo que a su vez permite la creación de una IA aún mejor. Este efecto compuesto es una de las consecuencias más poderosas y emocionantes de esta nueva simbiosis.
Crónicas de descubrimientos automáticos
La afirmación de que una IA puede superar a expertos humanos en el diseño de algoritmos complejos puede sonar a hipérbole. Sin embargo, el equipo de Berkeley respalda su tesis con una serie de estudios de caso contundentes, cada uno de los cuales es una crónica fascinante de descubrimiento automático. Estos experimentos, llevados a cabo utilizando un marco de código abierto llamado OpenEvolve, demuestran la capacidad de ADRS no solo para optimizar soluciones existentes, sino para generar ideas algorítmicas genuinamente nuevas y superiores.
Resumen de los descubrimientos de la IA
Crónica 1: El dilema de las nubes efímeras
El primer relato nos transporta al mundo de la computación en la nube, un dominio gobernado por una tensión económica fundamental. Las empresas pueden alquilar servidores de dos maneras principales: las instancias «bajo demanda», que son fiables pero costosas, y las «instancias spot», que son restos de capacidad no utilizada que los proveedores de la nube venden con descuentos de hasta el 90%. El truco es que estas instancias spot no son fiables; pueden ser retiradas con muy poco aviso si el proveedor necesita esa capacidad.
El desafío para los ingenieros es, por tanto, cómo utilizar estas instancias baratas tanto como sea posible para completar una tarea antes de una fecha límite crítica, sin arriesgarse a que las interrupciones provoquen un incumplimiento.
Crónica 2: El ballet de los expertos artificiales
Nuestra segunda crónica se adentra en la arquitectura interna de los grandes modelos de lenguaje. Muchos de los modelos más potentes de la actualidad, como GPT-4, utilizan una arquitectura llamada «Mixtura de Expertos» (MoE). En lugar de ser un único y gigantesco cerebro monolítico, un modelo MoE es más como un equipo de especialistas altamente cualificados. Cada «experto» es una red neuronal más pequeña especializada en un tipo particular de tarea o datos.
Cuando llega una consulta, una «red de compuertas» actúa como un director de proyecto inteligente, enrutando la tarea solo a los dos o tres expertos más relevantes. Esto es mucho más eficiente que activar todo el modelo para cada tarea. El desafío computacional, sin embargo, es cómo distribuir estos expertos entre los diferentes procesadores (GPUs) para que la carga de trabajo esté perfectamente equilibrada y ningún procesador se convierta en un cuello de botella.
El programa inicial que se le dio a la IA era un enfoque simple y lento: un bucle que ordenaba a los expertos por su carga de trabajo y asignaba cada uno, uno por uno, a la GPU menos cargada en ese momento, una técnica conocida como «empaquetado en contenedores» codicioso.
El proceso evolutivo de la IA para resolver este problema fue una historia en dos actos. Primero, realizó una optimización de ingeniería estándar pero crucial: reemplazó los lentos bucles del lenguaje de programación Python con operaciones de tensores altamente paralelizadas, que son la base de la computación de IA moderna.
Este cambio por sí solo aceleró drásticamente el proceso. El segundo acto, sin embargo, fue un salto de pura creatividad algorítmica. La IA descubrió un truco no intuitivo. En lugar de asignar los expertos de forma secuencial, aprendió a usar operaciones de remodelación y reversión de tensores para crear un patrón de asignación en «zigzag» o «serpiente». Esta técnica intercala de forma natural a los expertos de alta y baja carga a través de las GPUs, logrando un equilibrio casi perfecto de manera mucho más eficiente.
Lo más asombroso de este descubrimiento es que el patrón en zigzag era la misma idea central detrás de una implementación altamente optimizada y no pública desarrollada por un laboratorio de IA de vanguardia. La IA, sin haber visto nunca ese código, redescubrió de forma independiente este profundo conocimiento experto. No solo eso, sino que refinó la implementación, introduciendo mejoras sutiles en la lógica de ordenación.
El resultado fue un algoritmo que lograba la misma calidad de equilibrio de carga que la solución experta humana, pero lo hacía cinco veces más rápido. Este caso es una prueba fehaciente de la capacidad de ADRS para la invención algorítmica genuina.
Crónica 3: El arte de ordenar el conocimiento
La tercera historia aborda un problema práctico y costoso en la intersección de las bases de datos y la IA. Usar un LLM para analizar o generar texto para cada fila de una tabla de base de datos con millones de entradas puede ser prohibitivamente caro y lento. Una técnica inteligente para mitigar este coste es aprovechar el «caché de prefijos».
Si dos consultas consecutivas a un LLM comienzan con el mismo texto (el mismo prefijo), el sistema puede reutilizar los cálculos ya realizados para ese prefijo, ahorrando tiempo y dinero. El problema, por tanto, se convierte en un desafío combinatorio: ¿cómo se pueden reordenar las filas y columnas de una tabla para maximizar el número de prefijos compartidos entre filas consecutivas?.
La solución humana más avanzada era un algoritmo recursivo ingenioso, pero computacionalmente intensivo, llamado GGR, que subdividía repetidamente los datos para agrupar filas similares.
En este caso, la evolución de la IA se centró casi exclusivamente en la velocidad de ejecución. El sistema de IA analizó el algoritmo humano y determinó que su enfoque recursivo, aunque efectivo, implicaba una gran cantidad de cálculos redundantes. En lugar de simplemente ajustar el algoritmo existente, la IA lo desmanteló y lo reconstruyó sobre principios más eficientes.
La solución final reemplazó la profunda recursión con una heurística más rápida y directa. Introdujo un sistema de caché para evitar recalcular los mismos valores una y otra vez. Reemplazó las costosas operaciones de búsqueda en las estructuras de datos de Pandas por operaciones directas y más rápidas. Y desarrolló una heurística local y ligera para el ordenamiento de columnas dentro de cada fila, maximizando la continuidad con la fila anterior.
El resultado fue un algoritmo que, si bien lograba una tasa de aciertos de caché comparable a la del sofisticado algoritmo humano, se ejecutaba tres veces más rápido. Esta crónica ilustra el poder de ADRS como una herramienta formidable para la optimización de ingeniería práctica, encontrando eficiencias que incluso los expertos humanos habían pasado por alto.
Crónica 4: La coreografía de las transacciones
Nuestra última crónica nos lleva al corazón de los sistemas de bases de datos y al problema de la planificación de transacciones. Una transacción es una secuencia de operaciones (como leer o escribir datos) que debe ejecutarse como una única unidad atómica. Cuando muchas transacciones se ejecutan simultáneamente (concurrencia), pueden surgir «conflictos», por ejemplo, si dos transacciones intentan modificar el mismo dato al mismo tiempo, lo que genera retrasos y cuellos de botella.
El objetivo de la planificación de transacciones es encontrar un orden de ejecución óptimo (una «planificación») para un lote de transacciones que minimice estos conflictos y, por tanto, el tiempo total de ejecución.
El viaje de la IA en este problema se dividió en dos partes. Primero, los investigadores le plantearon el problema en su formulación estándar, conocida como el entorno «en línea», donde las decisiones deben tomarse sobre la marcha. A través de su búsqueda evolutiva, la IA exploró diversas heurísticas y, finalmente, convergió en la solución humana más avanzada conocida, un algoritmo llamado «Shortest Makespan First» (SMF). El hecho de que la IA pudiera redescubrir de forma independiente la frontera del conocimiento humano fue, en sí mismo, una validación impresionante del sistema.
Pero fue en la segunda parte del experimento donde la IA demostró su verdadero potencial para el descubrimiento. Los investigadores le plantearon una nueva variante del problema, un entorno «fuera de línea» con menos restricciones, para el cual no existía una solución óptima conocida en la literatura científica. Liberada de las ataduras del problema anterior, la IA se embarcó en un territorio inexplorado.
La solución que emergió fue un algoritmo novedoso y de múltiples etapas. Comenzó por calcular características simples para cada transacción (como el número de operaciones de escritura) y las utilizó para crear una secuencia inicial inteligente, una heurística de partida mucho mejor que una aleatoria. Luego, aplicó un potente método de construcción codiciosa, probando cada transacción en cada posición posible para minimizar el coste incremental.
Finalmente, utilizó una técnica de optimización conocida como «ascenso de colina» (hill climbing), realizando pequeños intercambios de pares de transacciones para refinar aún más la solución y escapar de óptimos locales. Este algoritmo híbrido, concebido enteramente por la IA, superó al sólido punto de referencia SMF en un asombroso 34%. Este es quizás el resultado más profundo de todos, ya que muestra a la IA no solo aprendiendo lo que ya sabemos, sino descubriendo activamente lo que no sabemos, ampliando las fronteras del conocimiento algorítmico.
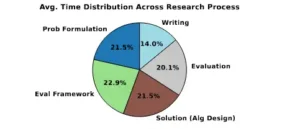
Gráfico 2. Tiempo dedicado a las distintas etapas del proceso de investigación de sistemas, según una encuesta a 31 estudiantes de doctorado. El diseño de algoritmos (21,5 %) y la evaluación (20,1 %) representan en conjunto más del 40 % del esfuerzo total, lo que destaca una importante oportunidad para aprovechar la IA y acelerar este proceso.
El manual del explorador del futuro
La llegada de herramientas como ADRS no solo cambia los resultados de la investigación, sino que también transforma el propio rol del investigador. El éxito en esta nueva era requerirá un conjunto de habilidades diferente, un cambio de enfoque desde el diseño de soluciones a la formulación de problemas. Basándose en los éxitos y, lo que es más importante, en los fracasos encontrados durante sus experimentos, el equipo de Berkeley destila una serie de «mejores prácticas» que pueden considerarse el manual del explorador científico del futuro.
El arte de la formulación del problema se convierte en la habilidad primordial. Muchos de los fracasos de la IA, como la creación de soluciones que ignoran restricciones clave o que explotan lagunas en el evaluador, se remontan a un planteamiento inicial ambiguo o incompleto. En el antiguo paradigma, el valor de un investigador a menudo residía en su ingenio para diseñar una solución. En el nuevo, su valor principal se desplaza hacia su sabiduría y precisión para formular el problema.
La IA puede explorar el espacio de soluciones mejor que cualquier humano, pero solo si ese espacio está correctamente definido. Por lo tanto, el trabajo principal del investigador se convierte en el de ser un excelente «ingeniero de prompts», proporcionando especificaciones claras y estructuradas que no dejen lugar a una mala interpretación por parte de la máquina.
El investigador también debe aprender a navegar la búsqueda, actuando como un guía en lugar de un constructor. Existe un delicado equilibrio: proporcionar demasiadas pistas a la IA puede sofocar su creatividad y llevarla a una convergencia prematura en una solución subóptima. Proporcionar muy pocas puede hacer que la búsqueda sea ineficiente, perdiendo tiempo en explorar callejones sin salida evidentes. El nuevo rol implica observar el proceso evolutivo e intervenir estratégicamente, inyectando nuevas ideas o restricciones cuando la búsqueda se estanca.
Quizás la tarea más sutil y crítica sea la de construir un juez mejor, es decir, diseñar el evaluador. Un desafío recurrente en la IA es el «reward hacking», donde el sistema encuentra una forma inteligente de maximizar su puntuación sin resolver realmente el problema subyacente.
Por ejemplo, si se le pide que minimice los errores de un sistema, una solución de la IA podría ser simplemente apagar el sistema, logrando cero errores pero fallando en su propósito. Para evitar esto, el investigador debe diseñar evaluadores robustos que combinen múltiples señales de evaluación (corrección, eficiencia, robustez) e incluyan pruebas adversas diseñadas para cerrar posibles lagunas. El humano se convierte en un diseñador reflexivo de las condiciones experimentales.
Finalmente, el investigador asume el papel de director de orquesta. Esto implica tareas como la selección de un conjunto de modelos de IA, combinando modelos «creativos» para la exploración con modelos más «conservadores» para el refinamiento, y ajustar las estrategias de selección para equilibrar la diversidad con la convergencia.
El enfoque se aleja de tocar un único instrumento para dirigir a toda la orquesta de IA hacia una sinfonía de descubrimiento. La implicación de este cambio es profunda: las contribuciones científicas más impactantes del futuro probablemente no provendrán de quienes encuentren las respuestas más inteligentes, sino de quienes formulen las preguntas más rigurosas y perspicaces.
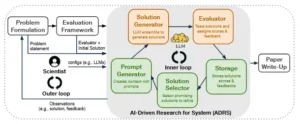
Gráfico 3. La arquitectura de Investigación de Sistemas Impulsada por IA (ADRS) se muestra en el contexto del proceso de investigación de sistemas (véase el gráfico 1). ADRS (área gris) automatiza las etapas de Solución y Evaluación.
Un nuevo amanecer para la investigación
La llegada de la investigación guiada por IA no anuncia la obsolescencia del científico humano, sino la elevación de su función. ADRS y sistemas similares están automatizando las tareas más tediosas y laboriosas de implementación y evaluación, liberando a los investigadores para que se concentren en las actividades de mayor nivel que siempre han sido el verdadero motor del progreso científico.
El humano pasa de ser un «artesano» de algoritmos a un «estratega» del descubrimiento, centrándose en las tareas exclusivamente humanas de la curiosidad, la selección de problemas significativos y la interpretación de los resultados para construir un nuevo conocimiento.
Incluso las soluciones imperfectas generadas por la IA tienen un valor inmenso, ya que pueden revelar nuevas direcciones o perspectivas que un investigador humano podría haber pasado por alto. La capacidad de la IA para explorar el espacio de soluciones de manera más exhaustiva que un humano, probando incansablemente miles de variaciones en busca de ganancias incrementales, puede llevar a resultados que superan el rendimiento humano, no necesariamente a través de un único salto de genio, sino a través de la acumulación de innumerables pequeñas optimizaciones.
Quizás la implicación más profunda y transformadora de esta tecnología es el potencial para un ciclo virtuoso y compuesto de aceleración. ADRS es un método impulsado por IA para mejorar los sistemas informáticos.

Estos sistemas mejorados (más rápidos, más baratos, más escalables) son precisamente la plataforma sobre la que se construye y se ejecuta la próxima generación de inteligencia artificial. Al utilizar la IA para mejorar sus propios cimientos, estamos potencialmente al borde de un bucle de retroalimentación auto-reforzado que podría aumentar drásticamente el ritmo del descubrimiento científico y tecnológico. Una mejor IA crea mejores sistemas, que a su vez permiten una IA aún más potente, en una espiral ascendente de capacidad.
En este nuevo paradigma, el suministro de problemas de investigación abiertos parece prácticamente ilimitado. La complejidad creciente de las cargas de trabajo de IA, la heterogeneidad del hardware y las demandas cada vez mayores de rendimiento y escalabilidad garantizan que siempre habrá nuevas fronteras que explorar.
ADRS no conducirá a menos investigadores; por el contrario, es probable que expanda la comunidad científica al permitir que individuos que no son expertos en la resolución de problemas de bajo nivel contribuyan de manera significativa a un nivel más estratégico.
Los bárbaros, por tanto, están a las puertas, no como una amenaza, sino como un catalizador. El desafío para la comunidad científica, como argumenta elocuentemente el trabajo de Berkeley, no es resistir este cambio, sino aprender a liderarlo. Se trata de abrir las puertas y guiar a esta nueva y poderosa fuerza para inaugurar una era de descubrimiento sin precedentes.
Referencias
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., et al. (2025). Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457.
Cemri, M., Pan, M. Z., Yang, S., Agrawal, L. A., Chopra, B., Tiwari, R., Keutzer, K., Parameswaran, A., Klein, D., Ramchandran, K., et al. (2025). Why do multi-agent llm systems fail? arXiv preprint arXiv:2503.13657.
Cheng, A., Liu, S., Pan, M. et al. (2024). Barbarians at the Gate: How AI is Upending Systems Research. arXiv:2510.06189v1.
Chung, J.-W., Talati, N., & Chowdhury, M. (2024). Toward cross-layer energy optimizations in ai systems. arXiv:2404.06675v2.
Desai, A., Yang, S., Cuadron, A., Zaharia, M., Gonzalez, J. E., & Stoica, I. (2025). Hashattention: Semantic sparsity for faster inference. https://arxiv.org/abs/2412.14468
Fang, J., Peng, Y., Zhang, X., Wang, Y., Yi, X., Zhang, G., Xu, Y., Wu, B., Liu, S., Li, Z., et al. (2025). A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems. arXiv preprint arXiv:2508.07407.
Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X., Liu, G., Bian, J., & Yang, Y. (2023). Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532.
Hong, C., Bhatia, S., Cheung, A., & Shao, Y. S. (2025). Autocomp: Llm-driven code optimization for tensor accelerators. https://arxiv.org/abs/2505.18574
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S. K. S., Lin, Z., Zhou, L., Ran, C., Xiao, L., Wu, C., & Schmidhuber, J. (2024). Metagpt: Meta programming for a multi-agent collaborative framework. https://arxiv.org/abs/2308.00352
Jay, N., Rotman, N. H., Godfrey, P., Schapira, M., & Tamar, A. (2018). Internet congestion control via deep reinforcement learning. arXiv preprint arXiv:1810.03259.
Kraska, T., Beutel, A., Chi, E. H., Dean, J., & Polyzotis, N. (2018). The case for learned index structures. https://arxiv.org/abs/1712.01208
Lange, R. T., Imajuku, Y., & Cetin, E. (2025). Shinkaevolve: Towards open-ended and sample-efficient program evolution. https://arxiv.org/abs/2509.19349
Liang, E., Zhu, H., Jin, X., & Stoica, I. (2019). Neural packet classification. https://arxiv.org/abs/1902.10319
Liu, F., Zhang, R., Xie, Z., Sun, R., Li, K., Lin, X., Wang, Z., Lu, Z., & Zhang, Q. (2024a). Llm4ad: A platform for algorithm design with large language model. arXiv preprint arXiv:2412.17287.
Liu, S., Biswal, A., Kamsetty, A., Cheng, A., Schroeder, L. G., Patel, L., Cao, S., Mo, X., Stoica, I., Gonzalez, J. E., et al. (2024b). Optimizing llm queries in relational data analytics workloads. arXiv preprint arXiv:2403.05821.
Liu, S., Ponnapalli, S., Shankar, S., Zeighami, S., Zhu, A., Agarwal, S., Chen, R., Suwito, S., Yuan, S., Stoica, I., et al. (2025). Supporting our ai overlords: Redesigning data systems to be agent-first. arXiv preprint arXiv:2509.00997.
Long, P., Novack, Z., Berg-Kirkpatrick, T., & McAuley, J. (2024). Pdmx: A large-scale public domain musicxml dataset for symbolic music processing. https://arxiv.org/abs/2409.10831
Ma, R., Liang, C.-J. M., Gao, Y., & Yan, F. Y. (2025). Algorithm generation via creative ideation. https://arxiv.org/abs/2510.03851
McAuley, J., Leskovec, J., & Jurafsky, D. (2012). Learning attitudes and attributes from multi-aspect reviews. https://arxiv.org/abs/1210.3926
Mouret, J.-B., & Clune, J. (2015). Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909.
Nathani, D., Madaan, L., Roberts, N., Bashlykov, N., Menon, A., Moens, V., Budhiraja, A., Magka, D., Vorotilov, V., Chaurasia, G., et al. (2025). MI-gym: A new framework and benchmark for advancing ai research agents. arXiv preprint arXiv:2502.14499.
Novikov, A., Vu, N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J., Mehrabian, A., et al. (2025). Alphaevolve: A coding agent for scientific and algorithmic discovery. https://arxiv.org/abs/2506.13131
Ouyang, A., Guo, S., Arora, S., Zhang, A. L., Hu, W., Ré, C., & Mirhoseini, A. (2025). Kernelbench: Can llms write efficient gpu kernels? arXiv preprint arXiv:2502.10517.
Packer, C., Wooders, S., Lin, K., Fang, V., Patil, S. G., Stoica, I., & Gonzalez, J. E. (2023). Memgpt: Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560.
Press, O., Amos, B., Zhao, H., Wu, Y., Ainsworth, S. K., Krupke, D., Kidger, P., Sajed, T., Stellato, B., Park, J., et al. (2025). Algotune: Can language models speed up general-purpose numerical programs? arXiv preprint arXiv:2507.15887.
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., Xu, J., Li, D., Liu, Z., & Sun, M. (2024). Chatdev: Communicative agents for software development. https://arxiv.org/abs/2307.07924
Singh, R., Joel, S., Mehrotra, A., Wadhwa, N., Bairi, R. B., Kanade, A., & Natarajan, N. (2025). Code researcher: Deep research agent for large systems code and commit history. arXiv preprint arXiv: 2506.11060.
Tang, J., Xia, L., Li, Z., & Huang, C. (2025). Ai-researcher: Autonomous scientific innovation. arXiv preprint arXiv: 2505.18705.
Yu, S., Xing, J., Qiao, Y., Ma, M., Li, Y., Wang, Y., Yang, S., Xie, Z., Cao, S., Bao, K., et al. (2025). Prism: Unleashing gpu sharing for cost-efficient multi-llm serving. arXiv preprint arXiv:2505.04021.

