
La inteligencia artificial multilingüe enfrenta una paradoja inquietante. Cuando los modelos de lenguaje más avanzados del mundo reciben preguntas en idiomas diferentes al inglés, tienden a traducir mentalmente esas consultas y razonar en la lengua de Shakespeare antes de ofrecer una respuesta. Esta preferencia, aparentemente inocua, revela una asimetría profunda en cómo estas máquinas procesan el pensamiento a través de las barreras lingüísticas. Un reciente estudio liderado por investigadores del Nilekani Centre at AI4Bharat, el Instituto Tecnológico de Madras, Google, Microsoft y la Universidad de Tecnología de Copenhague ha examinado sistemáticamente esta tendencia y descubierto que, si bien razonar en inglés generalmente mejora la precisión de las respuestas, también introduce vulnerabilidades críticas que podrían socavar la confiabilidad de estos sistemas en contextos multilingües.
Los llamados modelos de razonamiento extenso (Large Reasoning Models) representan la vanguardia actual de la inteligencia artificial conversacional. A diferencia de los modelos tradicionales que generan respuestas de manera casi instantánea, estos sistemas exhiben un proceso de pensamiento deliberado que se asemeja notablemente al razonamiento humano paso a paso. Durante varios segundos o incluso minutos, estos modelos exploran soluciones alternativas, verifican cálculos intermedios, retroceden cuando detectan errores y establecen submetas para abordar problemas complejos. Esta capacidad de reflexión prolongada les ha permitido alcanzar niveles de desempeño impresionantes en tareas matemáticas, científicas y de resolución de problemas que antes resultaban prohibitivamente difíciles para la inteligencia artificial.
Sin embargo, cuando se enfrentan a preguntas formuladas en idiomas distintos al inglés, estos modelos muestran una preferencia sistemática por traducir primero la consulta y luego razonar internamente en inglés. Este comportamiento plantea interrogantes fundamentales sobre la interpretabilidad, la preservación de matices culturales y lingüísticos, y la equidad en el acceso a tecnologías de punta. El estudio examinó esta dinámica en dos conjuntos de datos de referencia: MGSM, que contiene problemas matemáticos de nivel universitario en múltiples idiomas, y GPQA Diamond, una colección de preguntas científicas extremadamente desafiantes que requieren conocimiento experto en física, química y biología. Ambos conjuntos fueron evaluados en idiomas que abarcan desde lenguas con abundantes recursos digitales como el francés, alemán, español, ruso, chino y japonés, hasta idiomas con recursos más limitados como el hindi, bengalí, malabar, gujrati, telugu, suajili y tailandés.
Los hallazgos centrales revelan una ventaja consistente del razonamiento en inglés en términos de precisión de respuestas finales. Esta superioridad no se limita meramente a obtener respuestas correctas con mayor frecuencia, sino que se extiende a la calidad del proceso de razonamiento mismo. Los investigadores analizaron la presencia de comportamientos cognitivos sofisticados dentro de las cadenas de pensamiento generadas por estos modelos, incluyendo el establecimiento de submetas, la verificación de resultados intermedios, el retroceso ante estrategias fallidas y el encadenamiento hacia atrás desde la solución deseada. En todos estos indicadores, el razonamiento en inglés mostró una mayor frecuencia de estos comportamientos expertos en comparación con el razonamiento en el idioma original de la pregunta.
No obstante, esta aparente supremacía del inglés oculta una debilidad crítica que los investigadores denominan "perdidos en la traducción". En una proporción sustancial de casos en que el razonamiento en inglés condujo a respuestas incorrectas, el error pudo rastrearse directamente a problemas introducidos durante la traducción implícita de la pregunta. Estos errores de traducción, que incluyen omisiones de información crucial o malinterpretaciones de detalles clave, representan entre el 30% y el 77% de las respuestas incorrectas dependiendo del idioma y el tipo de tarea. Crucialmente, estos errores no habrían ocurrido si el modelo hubiera razonado directamente en el idioma de la pregunta, sin el paso intermedio de traducción.
Esta dicotomía plantea un dilema fundamental para el desarrollo de inteligencia artificial verdaderamente multilingüe. Por un lado, razonar en inglés permite a estos modelos aprovechar mejor su vasto conocimiento de dominio y sus capacidades de razonamiento más refinadas, que han sido optimizadas principalmente con datos en inglés durante el entrenamiento. Por otro lado, esta estrategia anglocéntrica introduce riesgos sistemáticos de errores de traducción que pueden comprometer la fiabilidad de las respuestas en aplicaciones del mundo real donde la precisión es crucial. Los investigadores argumentan que estos resultados subrayan la necesidad urgente de desarrollar capacidades nativas de razonamiento en múltiples idiomas con el mismo rigor y recursos que se han dedicado históricamente al inglés.
El estudio también reveló que la magnitud de la brecha de rendimiento entre razonar en inglés versus el idioma de la pregunta se amplía considerablemente a medida que las tareas se vuelven más complejas. Para los problemas matemáticos de MGSM, la diferencia de precisión entre ambos enfoques era moderada, particularmente para idiomas con abundantes recursos. Sin embargo, para las preguntas científicas de nivel experto en GPQA Diamond, la ventaja del razonamiento en inglés se volvió mucho más pronunciada, especialmente para idiomas con recursos limitados. Este patrón sugiere que el conocimiento especializado y las habilidades de razonamiento avanzado que estos modelos han adquirido están más fuertemente anclados en el inglés que sus capacidades para tareas más simples.
Las implicaciones de estos hallazgos trascienden la mera curiosidad académica. En un mundo donde la inteligencia artificial se integra cada vez más en sistemas críticos de educación, atención médica, servicios legales y toma de decisiones, la equidad lingüística no es opcional sino esencial. Si estos sistemas presentan tasas de error sistemáticamente más altas para hablantes de idiomas distintos al inglés, especialmente cuando esos errores son predecibles y evitables, entonces estamos construyendo infraestructuras tecnológicas que perpetúan desigualdades existentes. La investigación sugiere que los modelos que razonan principalmente en inglés mediante traducción de entradas no inglesas no son suficientes para un razonamiento multilingüe robusto. Lograr capacidades confiables de razonamiento en idiomas nativos requerirá esfuerzos específicos en construcción de conjuntos de datos, objetivos de entrenamiento y metodologías de evaluación que preserven patrones de razonamiento específicos de cada lengua.
Los modelos de razonamiento extenso y su arquitectura de pensamiento
La emergencia de los modelos de razonamiento extenso durante el último año ha marcado un punto de inflexión en la evolución de la inteligencia artificial conversacional. Estos sistemas, desarrollados por organizaciones como OpenAI con su modelo o1, DeepSeek con su familia R1, y Alibaba con Qwen QwQ, representan una desviación fundamental respecto a la arquitectura de respuesta de los modelos de lenguaje tradicionales. Mientras que un modelo convencional procesa una consulta y genera una respuesta de forma casi inmediata, los modelos de razonamiento extenso introducen una fase intermedia deliberada de procesamiento cognitivo que simula el pensamiento paso a paso característico de expertos humanos enfrentando problemas complejos.
Esta fase de razonamiento se manifiesta como una secuencia textual intermedia, típicamente encerrada entre etiquetas especiales en el código del modelo, donde el sistema literalmente piensa en voz alta. Durante esta etapa, el modelo puede explorar múltiples enfoques para resolver un problema, verificar sus cálculos intermedios, reconocer cuando una estrategia no funcionará y cambiar de rumbo, o establecer objetivos parciales que debe cumplir antes de alcanzar la solución final. Solo después de completar esta elaborada cadena de razonamiento interno, el modelo genera una respuesta final concisa que presenta la solución derivada del proceso anterior.
Este enfoque de dos fases ha demostrado ser particularmente efectivo para tareas que requieren múltiples pasos de razonamiento lógico, como problemas matemáticos complejos, análisis científicos detallados o resolución de acertijos que demandan pensamiento sistemático. En evaluaciones de referencia, estos modelos superan consistentemente a sus predecesores en pruebas que miden capacidades de razonamiento, aunque a costa de tiempos de respuesta significativamente mayores y consumo computacional más elevado. La capacidad de observar el proceso de razonamiento intermedio también ofrece ventajas en términos de interpretabilidad, permitiendo a usuarios y desarrolladores entender cómo el modelo llegó a una conclusión particular.
Sin embargo, esta nueva arquitectura también introduce complejidades adicionales cuando se trata de aplicaciones multilingües. El proceso de razonamiento interno, que constituye la innovación distintiva de estos sistemas, resulta ser predominantemente anglocéntrico incluso cuando las preguntas se formulan en otros idiomas. Los investigadores han observado que, sin intervenciones específicas para forzar el razonamiento en el idioma de la consulta, estos modelos tienden naturalmente a traducir preguntas no inglesas y realizar todo su procesamiento cognitivo en inglés antes de traducir la respuesta final de vuelta al idioma original.
El dilema multilingüe y la hegemonía del inglés
La preferencia de los modelos de razonamiento extenso por el inglés no es accidental ni arbitraria. Refleja una realidad estructural del entrenamiento de estos sistemas que ha favorecido abrumadoramente el contenido en lengua inglesa. Los vastos conjuntos de datos utilizados para entrenar modelos de lenguaje de gran escala contienen proporciones desproporcionadamente altas de texto en inglés, que domina internet, las publicaciones científicas, la documentación técnica y otros corpus digitales. Esta asimetría en los datos de entrenamiento se traduce en representaciones internas más ricas y capacidades de razonamiento más refinadas cuando el modelo opera en inglés.
Investigaciones previas han demostrado que los modelos multilingües, aunque superficialmente capaces de procesar múltiples idiomas, tienden a realizar su procesamiento interno en un espacio semántico latente sesgado hacia el inglés. Algunos investigadores han descrito este fenómeno como un sesgo hacia el inglés en las representaciones semánticas compartidas, donde conceptos de diferentes idiomas convergen hacia representaciones que privilegian estructuras lingüísticas anglosajonas. Este sesgo no se limita al procesamiento lingüístico sino que se extiende a través de modalidades, afectando cómo estos modelos integran información visual, auditiva y textual.
Los modelos de razonamiento extenso amplifican esta tendencia al hacer explícito y visible el proceso de pensamiento interno. Cuando se les presentan preguntas en idiomas distintos al inglés, estos sistemas enfrentan un dilema implícito: razonar en el idioma de la pregunta, lo que mejoraría la interpretabilidad y preservaría matices lingüísticos y culturales, o traducir al inglés y aprovechar sus capacidades de razonamiento más desarrolladas en ese idioma. La evidencia sugiere que, sin orientación explícita, los modelos optan sistemáticamente por la segunda estrategia.
Esta elección tiene consecuencias significativas para la equidad y accesibilidad de estas tecnologías. Para hablantes de inglés, la experiencia de usuario es óptima: el modelo razona en su idioma nativo, preservando todos los matices y contextos culturales relevantes, y aprovecha plenamente sus capacidades cognitivas más avanzadas. Para hablantes de otros idiomas, especialmente aquellos con recursos digitales limitados, la experiencia se degrada de múltiples maneras. La traducción implícita puede introducir errores o perder información contextual importante. El razonamiento en un idioma diferente al de la pregunta reduce la transparencia del proceso cognitivo del modelo. Y las capacidades aparentemente inferiores en idiomas no ingleses pueden reforzar percepciones de inferioridad tecnológica de lenguas minoritarias.
Metodología del estudio y diseño experimental
Para investigar sistemáticamente la dicotomía entre razonar en inglés versus el idioma de la pregunta, los investigadores diseñaron un protocolo experimental riguroso que combina evaluaciones cuantitativas de precisión con análisis cualitativos de procesos cognitivos. El estudio se centró en dos conjuntos de datos de referencia que representan diferentes niveles de dificultad y tipos de razonamiento: MGSM para matemáticas de nivel universitario y GPQA Diamond para preguntas científicas de nivel experto.
MGSM contiene 250 problemas matemáticos en múltiples idiomas que requieren razonamiento aritmético de varios pasos. Los investigadores extendieron este conjunto de datos para incluir hindi, malabar y danés mediante traducción automatizada de alta calidad verificada manualmente. GPQA Diamond presenta 198 preguntas científicas extremadamente desafiantes en física, química y biología que originalmente fueron diseñadas para ser resistentes a búsquedas en internet y requerir conocimiento de posgrado. Este conjunto fue traducido a danés y cinco lenguas índicas para el estudio.
Los experimentos utilizaron varios modelos de razonamiento de código abierto, incluyendo Qwen QwQ 32B, diferentes variantes de Qwen3, y versiones destiladas de DeepSeek R1. Para forzar a los modelos a razonar en el idioma de la pregunta en lugar de en inglés, los investigadores emplearon dos técnicas complementarias. La primera consistió en instrucciones explícitas en el prompt del sistema especificando el idioma deseado de razonamiento. La segunda técnica implicó la inserción de tokens prefijo al inicio de la secuencia de razonamiento que contenían una frase traducida sugiriendo el inicio del pensamiento paso a paso en el idioma objetivo. Por ejemplo, si se deseaba forzar el razonamiento en francés, el prefijo podría ser "D'accord, laissez-moi essayer de résoudre ce problème étape par étape".
Dado que los modelos de razonamiento generalmente utilizan decodificación basada en muestreo en lugar de decodificación codiciosa, cada experimento se ejecutó cuatro veces con parámetros fijos de temperatura (0.6), probabilidad acumulativa (0.95) y parámetro k de muestreo por núcleo (20). Los investigadores reportaron tanto la media como la desviación estándar de las cuatro ejecuciones, encontrando que la variabilidad era generalmente baja con desviaciones estándar por debajo de 0.05 en la mayoría de los casos. La inferencia se realizó a través de la API de DeepInfra, un proveedor de acceso a modelos de código abierto, con un costo total aproximado de 295 dólares para todo el proyecto.
Resultados principales: la ventaja del inglés y sus límites
Los resultados del estudio revelaron patrones claros y consistentes en el rendimiento comparativo del razonamiento en inglés frente al razonamiento en el idioma de la pregunta. Para MGSM, la precisión de respuestas finales fue máxima para el inglés, se mantuvo robusta para idiomas con recursos abundantes como francés, alemán, español, ruso, chino y japonés, y disminuyó progresivamente para idiomas con recursos más limitados como hindi, bengalí, malabar, gujrati, telugu, suajili y tailandés.
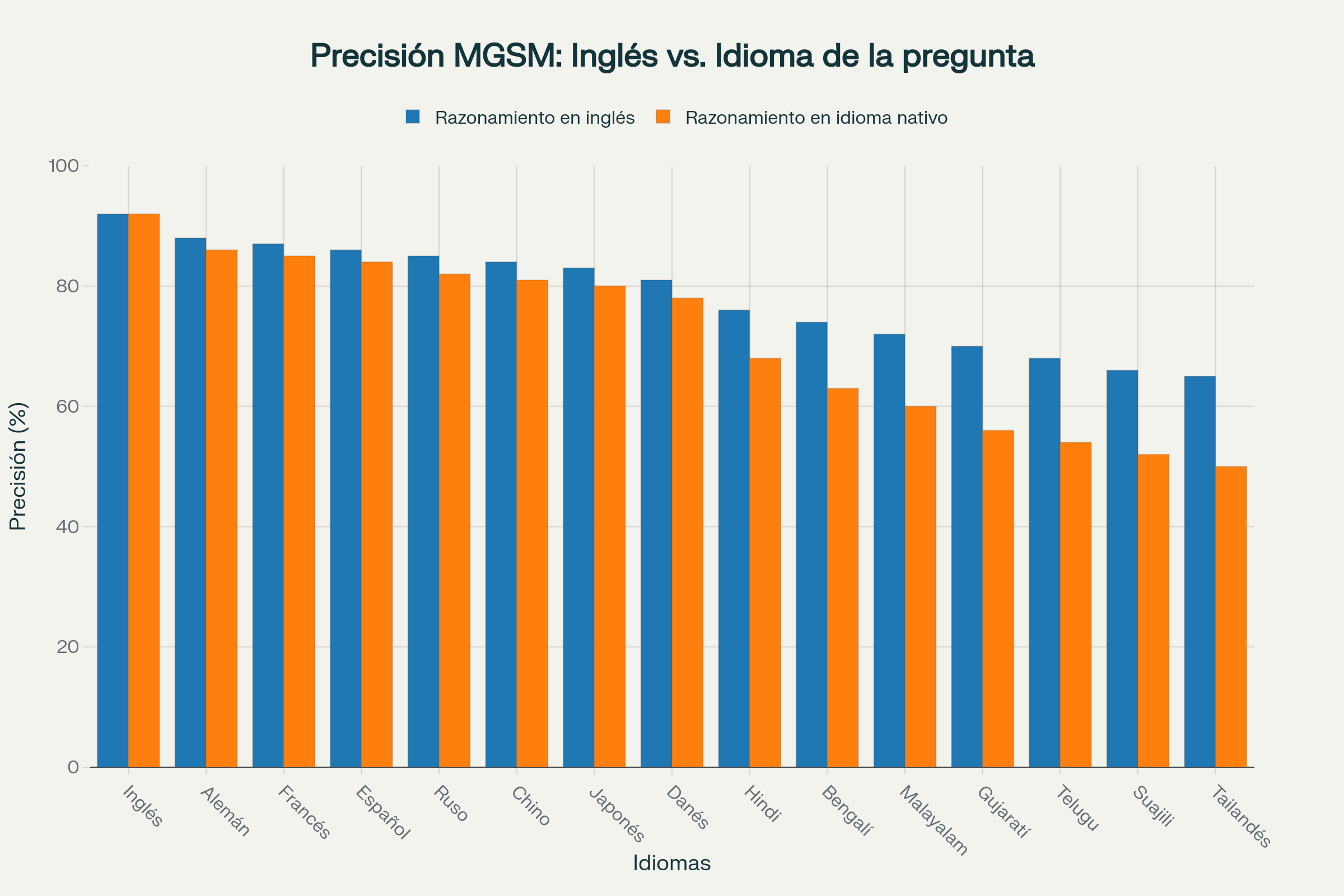
La comparación directa entre razonar en inglés versus el idioma nativo de la pregunta mostró que, a medida que se avanza de idiomas con recursos abundantes hacia aquellos con recursos escasos, la brecha de precisión entre ambos enfoques se amplifica significativamente. Esta tendencia indica que el razonamiento en inglés generalmente produce mayor precisión en respuestas finales, con la ventaja volviéndose más pronunciada para idiomas menos representados en los datos de entrenamiento de los modelos. Para idiomas de bajos recursos, la diferencia puede alcanzar más de treinta puntos porcentuales en términos de precisión.
El patrón observado para MGSM se intensificó dramáticamente cuando los investigadores examinaron GPQA Diamond, que requiere conocimiento experto de dominio. El contraste de rendimiento entre inglés y lenguas no inglesas durante el razonamiento en el idioma de la pregunta fue sustancialmente mayor que para MGSM. De manera similar, la brecha entre razonar en inglés versus el idioma de la consulta para preguntas multilingües fue mucho más amplia en GPQA que en MGSM.
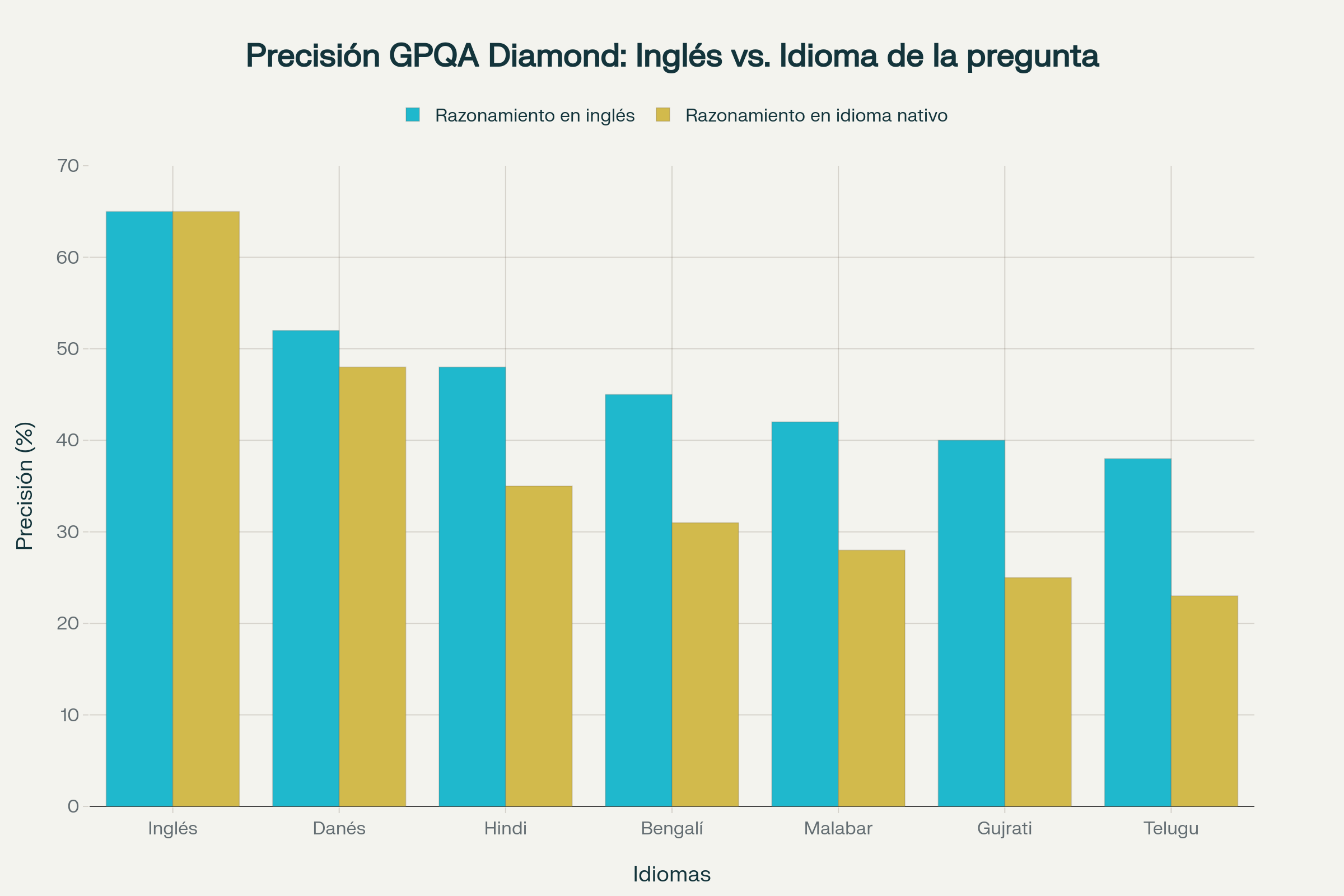
Una excepción notable fue el danés, que exhibió una brecha de precisión relativamente pequeña entre razonar en su propio idioma y razonar en inglés. El danés también mostró rendimiento comparativamente sólido en GPQA Diamond en relación con otras lenguas no inglesas. Los investigadores atribuyen este resultado al estatus relativamente alto del danés en términos de recursos digitales disponibles entre los idiomas analizados, sugiriendo que la cantidad y calidad de datos de entrenamiento en un idioma particular correlaciona directamente con las capacidades de razonamiento del modelo en ese idioma.
Estos hallazgos subrayan que aprovechar el inglés es particularmente crucial para acceder al conocimiento especializado de dominio y las capacidades de razonamiento avanzadas de estos modelos en preguntas de nivel experto. La complejidad de la tarea actúa como un multiplicador de las asimetrías lingüísticas subyacentes en las capacidades del modelo.
Comportamientos cognitivos en las cadenas de razonamiento
Evaluar el razonamiento multilingüe únicamente mediante la precisión de respuestas finales omite aspectos fundamentales de cómo estos modelos generan sus respuestas. Los modelos de razonamiento extenso introducen complejidad adicional a través de sus cadenas de pensamiento intermedio, que constituyen el núcleo de su innovación arquitectónica. Para capturar esta dimensión, los investigadores analizaron las cadenas de razonamiento en busca de atributos cognitivos específicos que reflejan cómo expertos humanos abordan problemas difíciles.
Cuatro comportamientos cognitivos fueron examinados sistemáticamente. El establecimiento de submetas implica descomponer una tarea compleja en pasos más pequeños y manejables, como cuando alguien dice "primero necesito aislar la variable x". La verificación consiste en realizar comprobaciones sistemáticas para detectar y corregir errores en resultados intermedios. El retroceso ocurre cuando el modelo reconoce que su enfoque actual no conducirá a la respuesta correcta y abandona explícitamente esa estrategia para explorar alternativas. El encadenamiento hacia atrás involucra razonar desde el resultado deseado hacia atrás hacia las condiciones iniciales necesarias para obtenerlo.
Los investigadores utilizaron GPT-4o mini como evaluador automatizado para identificar y contar la frecuencia de estos comportamientos en las cadenas de razonamiento, empleando prompts de evaluación adaptados de estudios previos. Los análisis revelaron que estos comportamientos cognitivos aparecen con mayor frecuencia cuando el modelo razona en inglés que cuando razona en el idioma de la pregunta, y esta mayor presencia de cognición sofisticada coincide con mayor precisión en respuestas finales.
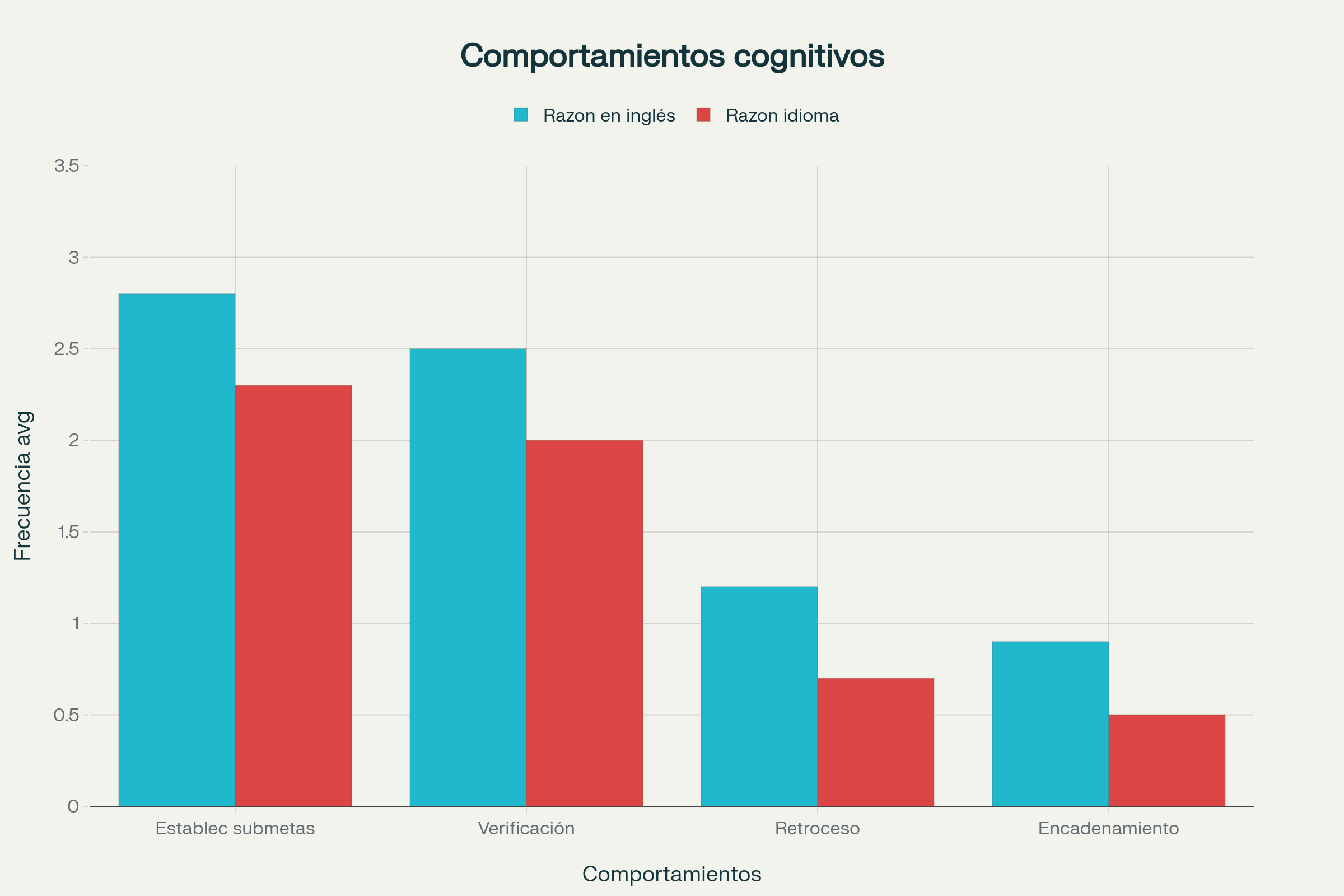
Entre los atributos analizados, el establecimiento de submetas y la verificación aparecieron con mayor prominencia en las cadenas de razonamiento en el idioma de la pregunta, mientras que el retroceso y el encadenamiento hacia atrás fueron comparativamente menos frecuentes. Esta distribución desigual sugiere que diferentes aspectos del razonamiento experto se ven afectados de manera diferencial por el idioma en que se realiza el procesamiento cognitivo.
Estos hallazgos proporcionan evidencia de que la ventaja del razonamiento en inglés no se limita a obtener respuestas correctas con mayor frecuencia, sino que se extiende a la riqueza y sofisticación del proceso de razonamiento subyacente. Las cadenas de pensamiento en inglés exhiben patrones más complejos de cognición experta, lo que sugiere que las representaciones internas y procesos algorítmicos que sustentan el razonamiento avanzado están más desarrollados cuando operan en inglés. El modelo parece contar con un repertorio más amplio de estrategias cognitivas cuando se comunica en esta lengua.
Perdidos en la traducción: el talón de Aquiles del razonamiento anglófono
A pesar de la aparente superioridad general del razonamiento en inglés, los investigadores identificaron un modo de fallo crítico que socava esta estrategia anglocéntrica. En un análisis detallado de casos donde el razonamiento en el idioma de la pregunta superó al razonamiento en inglés, emergió un patrón consistente: los errores del razonamiento en inglés con frecuencia podían rastrearse directamente a problemas introducidos durante la traducción implícita de la pregunta.
El fenómeno denominado "perdidos en la traducción" (Lost in Translation) se refiere a situaciones donde información crucial contenida en la pregunta original se omite o malinterpreta durante el paso de traducción que precede al razonamiento en inglés. Un ejemplo ilustrativo del estudio involucra un problema matemático en hindi sobre correspondencia epistolar. La pregunta original especificaba que el protagonista enviaba dos cartas a cada uno de sus corresponsales. Sin embargo, al razonar en inglés, el modelo tradujo incorrectamente este detalle como "enviaba dos cartas en total", omitiendo el crucial "a cada uno". Este error de traducción propagó un cálculo incorrecto a través de toda la cadena de razonamiento, conduciendo a una respuesta final errónea de dos horas cuando la respuesta correcta era tres horas. En contraste, cuando el modelo razonó directamente en hindi sin ningún paso de traducción, interpretó correctamente la pregunta y arribó a la respuesta correcta.
Pregunta original en hindi: "Mike tenía 5 correspondientes. Ya no es corresponsal con 2 de ellos. Ellos envían 2 cartas a cada una de las semanas que tienen 5 páginas cada una. Él hace lo mismo en reciprocidad. Puede escribir una página en 6 minutos. ¿Cuántas horas a la semana dedica a escribir?"
Razonamiento en inglés (incorrecto): "Envía dos cartas en total. Para 3 personas, 3 × 2 = 6 cartas. Pero cálculo incorrecto: 6 × 5 = 30 páginas. 30 × 6 = 180 minutos. 180 ÷ 60 = 3 horas." [Respuesta final incorrecta: 3 horas cuando debería ser más]
Razonamiento en hindi (correcto): "Envía dos cartas a cada persona. Para 3 personas: 3 × 2 = 6 cartas por semana. Cada carta tiene 5 páginas: 6 × 5 = 30 páginas. 30 páginas × 6 minutos = 180 minutos = 3 horas." [Respuesta final correcta]
Para cuantificar la prevalencia de este fenómeno, los investigadores midieron la fracción de respuestas incorrectas del razonamiento en inglés causadas por errores de traducción que no habrían ocurrido si el razonamiento se hubiera realizado directamente en el idioma de la pregunta. Utilizando GPT-4o mini como evaluador automatizado con verificación manual de un subconjunto de casos, calcularon lo que denominaron la fracción LiT (Lost in Translation).
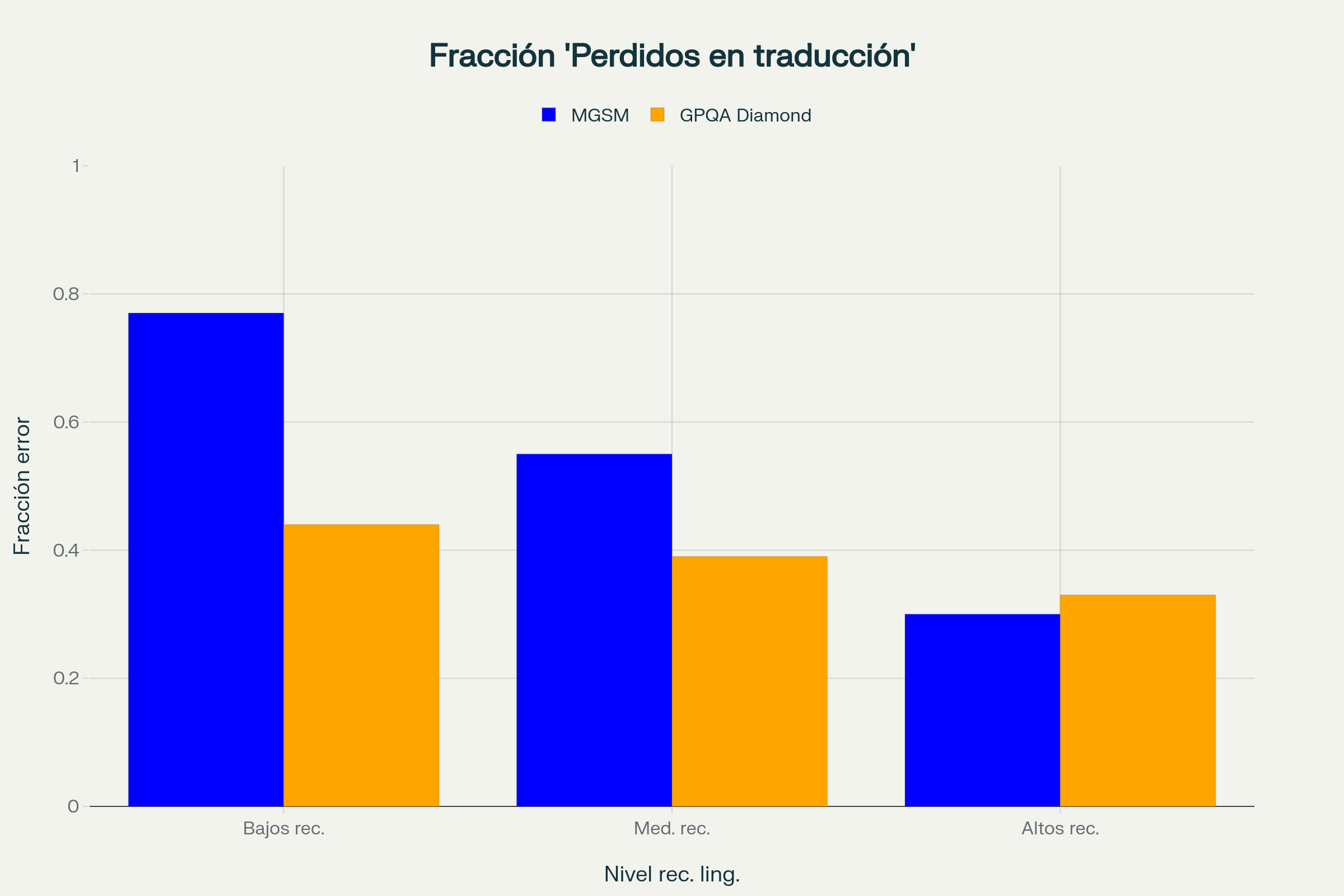
Para MGSM, la fracción LiT disminuyó de 0.77 en idiomas de bajos recursos a 0.30 en idiomas de altos recursos, demostrando que los errores de traducción son más comunes en contextos de recursos limitados. Este hallazgo es particularmente significativo: significa que entre las respuestas incorrectas generadas al razonar en inglés, entre el 30% y el 77% de ellas son directamente atribuibles a errores de traducción. Para GPQA, las fracciones LiT oscilaron entre 0.44 y 0.33, mostrando que incluso en tareas de alto nivel de dificultad, entre un tercio y casi la mitad de los errores tienen origen en problemas de traducción. Estas cifras indican que una porción sustancial de respuestas incorrectas puede atribuirse directamente a errores introducidos durante la traducción, exponiendo una debilidad sistémica en la estrategia de razonamiento en inglés.
Este hallazgo es particularmente significativo porque revela una vulnerabilidad que persiste incluso cuando el razonamiento en inglés generalmente supera al razonamiento en el idioma nativo. Si bien los experimentos anteriores mostraron que razonar en inglés permite aprovechar mejor el conocimiento de dominio y las capacidades de razonamiento del modelo, este experimento revela que, en tareas multilingües, el razonamiento en inglés corre el riesgo de perderse en la traducción.
Implicaciones para el futuro de la inteligencia artificial multilingüe
Los hallazgos de este estudio plantean interrogantes fundamentales sobre la suficiencia de modelos de razonamiento que operan principalmente en inglés mediante traducción de entradas en otros idiomas. Los resultados sugieren inequívocamente que tales sistemas no son adecuados para razonamiento multilingüe verdaderamente robusto. Lograr capacidades confiables de razonamiento en idiomas nativos requerirá esfuerzos dirigidos en múltiples frentes: construcción de conjuntos de datos multilingües de alta calidad, objetivos de entrenamiento que incentiven explícitamente el desarrollo de capacidades de razonamiento en múltiples lenguas, y metodologías de evaluación que preserven y midan patrones de razonamiento específicos de cada idioma.
La brecha de rendimiento entre idiomas con recursos abundantes y aquellos con recursos escasos subraya la urgencia de invertir en infraestructura lingüística digital para lenguas subrepresentadas. Mientras el inglés, y en menor medida otros idiomas europeos y asiáticos mayoritarios, continúen dominando los corpus de entrenamiento, las asimetrías observadas en este estudio persistirán y probablemente se amplificarán a medida que los modelos se vuelvan más sofisticados.
El fenómeno de perderse en la traducción resalta un riesgo operacional concreto que debe considerarse en aplicaciones del mundo real. En dominios donde la precisión es crítica, como atención médica, servicios legales, educación o ingeniería, errores causados por traducciones automáticas defectuosas pueden tener consecuencias graves. Un diagnosis médico incorrecto por un malentendido lingüístico, un consejo legal erróneo por omisión de detalles importantes, o un cálculo ingenieril equivocado podrían tener repercusiones peligrosas. Los desarrolladores y usuarios de estos sistemas deben ser conscientes de que la aparente capacidad multilingüe de estos modelos enmascara vulnerabilidades sistemáticas que no son inmediatamente evidentes en evaluaciones superficiales.
- Para gobiernos y responsables políticos: La inversión en infraestructura de datos y recursos de IA en idiomas locales se convierte en una cuestión de soberanía digital y equidad nacional. Permitir que poblaciones enteras sean servidas por modelos de IA menos confiables constituye una forma de exclusión tecnológica que perpetúa brechas de acceso.
- Para desarrolladores de aplicaciones: Asumir que un modelo multilingüe funciona igualmente bien en todos los idiomas es una suposición peligrosa. Las auditorías de equidad lingüística deben convertirse en práctica estándar antes de desplegar sistemas de IA en aplicaciones críticas en contextos multilingües.
Las implicaciones éticas también son profundas. Si los sistemas de inteligencia artificial de vanguardia funcionan sistemáticamente mejor para hablantes de inglés que para hablantes de otros idiomas, estamos construyendo una infraestructura tecnológica que codifica y perpetúa desigualdades lingüísticas existentes. En un mundo cada vez más dependiente de estas tecnologías para funciones críticas, tales asimetrías no son meramente inconvenientes técnicos sino cuestiones de justicia distributiva y acceso equitativo a recursos tecnológicos. Además, este sesgo anglófono puede tener efectos psicológicos y culturales a largo plazo, reforzando nociones de superioridad lingüística del inglés y marginalizando otras formas de conocimiento que se expresan en lenguas minorizadas.
Hacia una verdadera democracia lingüística en la inteligencia artificial
El estudio del inglés como lingua franca del razonamiento artificial ilumina una tensión fundamental en el desarrollo de inteligencia artificial global. Por un lado, la convergencia hacia un idioma común de procesamiento interno podría verse como una eficiencia práctica que permite a los modelos aprovechar sus capacidades más desarrolladas. Por otro lado, esta convergencia representa una forma de colonialismo lingüístico tecnológico que marginaliza sistemáticamente a hablantes de idiomas no hegemónicos. El fenómeno no es nuevo: a lo largo de la historia, las potencias dominantes han impuesto sus lenguas como vehículos de comunicación global. La diferencia ahora es que no se trata solo de una imposición cultural sino de una que está codificada en los algoritmos y matemáticas de los sistemas que cada vez más median nuestras vidas.
La metáfora de la espada de doble filo captura precisamente esta ambigüedad. El inglés como lengua de razonamiento ofrece ventajas medibles en términos de precisión y sofisticación cognitiva, pero simultáneamente introduce riesgos sistemáticos de error y reduce la transparencia e interpretabilidad para usuarios no anglófonos. Los hablantes de inglés obtienen un sistema de razonamiento más poderoso y confiable. Los hablantes de otros idiomas obtienen un sistema que finge ser multilingüe pero que, en realidad, traduce sus pensamientos a otra lengua para procesarlos realmente. Resolver esta tensión no será simple ni rápido. Requerirá inversiones sustanciales en recursos lingüísticos digitales, innovaciones en arquitecturas de modelos que puedan desarrollar capacidades equivalentes en múltiples idiomas simultáneamente, y un compromiso sostenido con la equidad lingüística como principio de diseño fundamental en lugar de una ocurrencia tardía.
Los investigadores han proporcionado un diagnóstico empírico riguroso del problema y han establecido líneas de base que el trabajo futuro puede utilizar para medir el progreso hacia el razonamiento en idiomas nativos. Su contribución no se limita a documentar las limitaciones actuales, sino también a demostrar que existen casos concretos donde el razonamiento en el idioma de la pregunta puede superar al razonamiento en inglés, ofreciendo así una prueba de concepto de que enfoques alternativos son viables. Esto es especialmente importante porque sugiere que no es una limitación intrínseca de las lenguas no inglesas sino una consecuencia de decisiones de diseño y prioridades de entrenamiento que podrían ser revocadas.
La pregunta que queda abierta no es si debemos desarrollar capacidades de razonamiento nativas multilingües, sino cómo y cuán rápido podemos hacerlo. En un mundo donde miles de millones de personas hablan idiomas distintos al inglés como lengua materna, construir inteligencia artificial que funcione de manera óptima solo en inglés no es aceptable ni sostenible. El futuro de la inteligencia artificial verdaderamente global depende de nuestra capacidad colectiva para transcender las hegemonías lingüísticas del pasado y construir sistemas que respeten y celebren la diversidad lingüística de la humanidad. Los investigadores han arrojado luz sobre la grieta en los cimientos; ahora corresponde a la comunidad científica, los desarrolladores, los diseñadores de políticas y la sociedad en general comenzar el arduo trabajo de reconstrucción en una dirección más equitativa.
Referencias
Saji, A., Dabre, R., Kunchukuttan, A., & Puduppully, R. (2025). The Reasoning Lingua Franca: A Double-Edged Sword for Multilingual AI. arXiv:2510.20647v1.
Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., Vosoughi, S., Chung, H. W., Tay, Y., Ruder, S., Zhou, D., et al. (2022). Language models are multilingual chain-of-thought reasoners. arXiv preprint arXiv:2210.03057.
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2024). GPQA: A graduate-level google-proof Q&A benchmark. First Conference on Language Modeling.
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948.
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. (2024). OpenAI o1 system card. arXiv preprint arXiv:2412.16720.
Gandhi, K., Chakravarthy, A., Singh, A., Lile, N., & Goodman, N. D. (2025). Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars. arXiv preprint arXiv:2503.01307.
Yong, Z. X., Adilazuarda, M. F., Mansurov, J., Zhang, R., Muennighoff, N., Eickhoff, C., Winata, G. I., Kreutzer, J., Bach, S. H., & Aji, A. F. (2025). Crosslingual reasoning through test-time scaling. arXiv preprint arXiv:2505.05408.
Wendler, C., Veselovsky, V., Monea, G., & West, R. (2024). Do llamas work in English? On the latent language of multilingual transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 15366-15394.
Wu, Z., Yu, X. V., Yogatama, D., Lu, J., & Kim, Y. (2025). The semantic hub hypothesis: Language models share semantic representations across languages and modalities. The Thirteenth International Conference on Learning Representations, ICLR 2025.
Aggarwal, T., Tanmay, K., Agrawal, A., Ayush, K., Palangi, H., & Liang, P. P. (2025). Language models' factuality depends on the language of inquiry. arXiv preprint arXiv:2502.17955.
Zhao, Y., Zhang, W., Chen, G., Kawaguchi, K., & Bing, L. (2024). How do large language models handle multilingualism? In Advances in Neural Information Processing Systems 38 Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada.

")