
El asistente que escribe su propio código mejorado
Google presentó una propuesta innovadora: un agente que no solo ejecuta modelos, sino que diseña, prueba y mejora su propio flujo de trabajo sin supervisión humana directa. La base de este texto se sustenta en dos fuentes fundamentales: el anuncio oficial de Google y el extenso documento técnico “MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement”, donde se describe el funcionamiento de esta herramienta como si infraestructuras completas de inteligencia artificial se coordinaran sólidamente entre sí, como un equipo humano, pero con velocidad y disciplina de máquina.
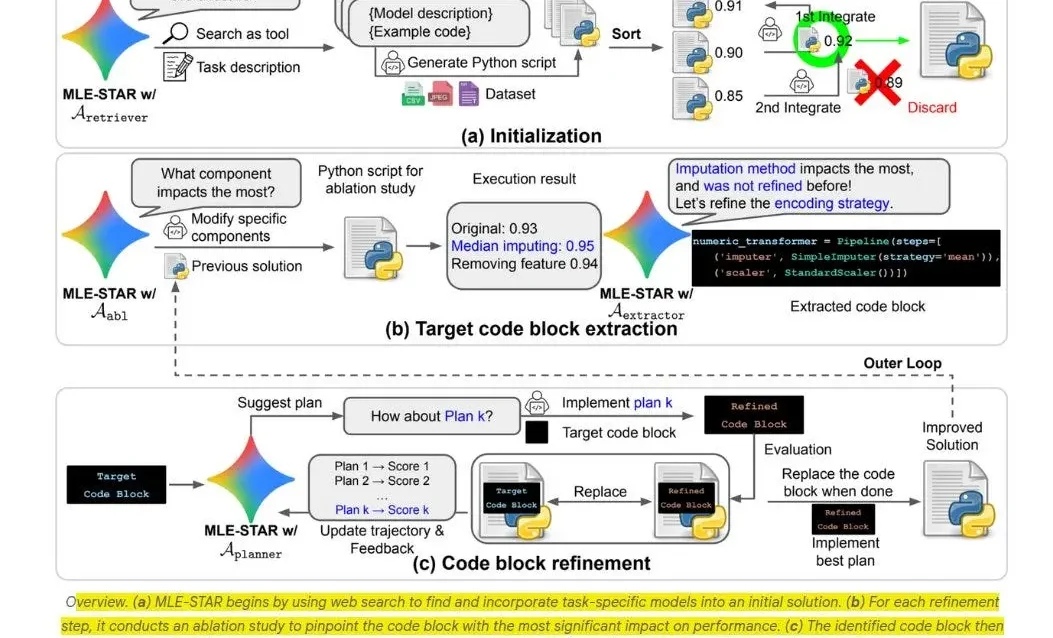
La idea central es sorprendente en su sencillez: cuando recibe un problema y datos, el sistema arma una solución funcional inicial. Esa primera versión ya separa datos de entrenamiento y validación, fija métricas claras y registra entornos para que cualquier mejora posterior se pueda rastrear con rigor. Después, no ejecuta montañas de pruebas sin sentido, sino que hace lo que un ingeniero experto haría intuitivamente: cambia un módulo a la vez (por ejemplo preprocesamiento, selección de características, modelo base) y observa cuál tiene impacto real. Si algo se resiente o no aporta, lo desactiva. Si mejora, lo mantiene e intenta refinarlo. Esa forma quirúrgica de actuar revela la clave de toda innovación fake: menos es más, y el foco bien dirigido produce progreso real.
Con esas piezas brillantes en la mano, el agente no se queda con una sola versión óptima. Propone combinaciones y evalúa si ensamblar varios modelos ofrece más estabilidad o precisión que uno solo. Si el conjunto funciona mejor, lo adopta. Si no, recula. No hay culto al overfitting ni enamoramiento omnipotente. Prefiere robustez. Y mientras hace todo esto, mantiene un registro exhaustivo: cada versión, métrica, cambio aplicado, entorno de ejecución, exacta fecha, hardware usado —todo documentado como si fuera una bitácora profesional que un equipo de MLOps necesitaría para reproducirlo mañana sin fricciones.
Eso convierte a la herramienta, más que en un asistente, en un colaborador con memoria y criterio. Imaginá que cada vez que se introduce una nueva base de datos o un nuevo objetivo, en lugar de arrancar de cero, el sistema ya tiene protocolo, ha aprendido cómo reducir errores, qué partes del pipeline suelen quebrarse y cómo solucionar sin arrastre. Eso implica desplazar al ingeniero del rol de “ajustador manual” al de “defensor de identidad técnica”: quien dicta las reglas del juego, define metas estratégicas, audita límites roles, y recibe propuestas catalogadas claramente. No se queda en “hace lo que te parece”: monitorea, valida, decide.
Un punto crítico que el documento técnico no omite es la ética. Un sistema de auto-mejora así puede derivar hacia objetivos técnicos que escapan al propósito inicial. Para evitar eso, Google propone marcos de restricción: métricas compuestas que ponderan precisión con equidad, penalizaciones claras por errores graves y revisiones humanas obligatorias si un cambio supera cierta magnitud. No es un obstáculo burocrático, sino un elemento central para estabilizar el sistema, especialmente en sectores donde la interpretación errónea de una señal puede derivar en consecuencias reales, como salud o finanzas.
Otro riesgo potencial es la degradación del ingeniero humano. Delegar todo en un sistema que “aprende solo” puede atrofia habilidades críticas. El equipo propone al mismo tiempo un entorno educativo donde el sistema genera reporte sobre cada mejora: qué cambió, por qué y con qué impacto. Esa transparencia obliga a que haya alguien que disienta si algo carece de sentido estratégico o ético. El agente no reemplaza al ingeniero: lo desafía, lo estimula y lo complementa, pero nunca lo anula.
La cuestión de los recursos computacionales también está bien considerada. La arquitectura implementa políticas de parada: si no hay mejora sustancial tras X iteraciones, se detiene, preservando recursos. También prioriza módulos con mayor potencial de impacto, evitando gastar ciclos en ajustes no prometedores. Esto reduce no solo tiempo y gasto, sino el consumo energético, alineándose con la creciente preocupación por la huella ecotécnica de los modelos de gran escala.
Al comparar con otros agentes que prometen automatización total, lo que diferencia a esta propuesta es su combinación de autonomía e integridad. No se trata de acelerar el proceso hacia la línea final a toda costa, sino de ser riguroso, claro, repetible y alineado con buenas prácticas públicas. No desaparece el ingeniero de la ecuación, simplemente cambia el lugar desde donde marca la cancha.
Esto no es una promesa vacía. Ya existen ejemplos donde el sistema, recibiendo una base de datos real, propuso una mejora significativa del modelo principal sin requerir ajustes manuales. Incluyó optimización de batch sizes, cambios en el preprocesamiento, mejor regularización y ensamblaje, todo en menos tiempo que lo que tardaría un ingeniero tradicional en reproducir. En esos casos, se alcanzaron mejoras medibles de rendimiento de entre un 5 y un 10 %, que si bien parecen pequeños, aceleraron el despliegue y permitieron nuevas iteraciones en semanas en lugar de meses.
En resumen, lo que Google ha mostrado no es una revolución estridente, sino un paso hacia un futuro donde las tareas más repetitivas de ingeniería de modelos pueden ser delegadas a un sistema entrenado para trabajar con rigor, claridad y disciplina. No es inteligencia artificial reemplazando ingenieros, sino extendiendo sus capacidades a ritmos imposibles para un ser humano. Y todo eso, con la trazabilidad y control necesarios para que la novedad no se convierta en una caja oscura a la que temer.
Lo que significa ceder el tablero, pero no la partida
La lectura pausada del documento técnico y del comunicado de Google revela que este agente no fue diseñado para asombrar con un despliegue de potencia bruta, sino para imitar el razonamiento progresivo de un profesional. No toma el conjunto de datos, lo arroja a un modelo preentrenado y canta victoria. Antes de que corra la primera línea de código, evalúa el problema y define un plan. Eso incluye elegir cómo dividir datos para evitar fuga de información, qué métricas realmente representan éxito y qué límites serán innegociables. Así, cada mejora posterior nace en terreno sólido, no sobre arena.
Esta forma de proceder rompe con una tendencia dominante en entornos de experimentación, donde la abundancia de cómputo permite saltar de idea en idea sin verificar fundamentos. Aquí, en cambio, la optimización se realiza por objetivos concretos. El agente examina su solución inicial como un boceto que necesita ajustes precisos, no como una obra terminada ni como una pieza que deba rehacerse por completo. Eso le permite concentrar energía y tiempo en cambios que tienen mayor probabilidad de impacto.
Cuando la búsqueda avanza, el sistema no se limita a probar variantes internas. Puede integrar modelos complementarios, incluso si provienen de arquitecturas distintas, siempre que la combinación aporte beneficios netos. Este ensamblaje no es un simple voto mayoritario: evalúa correlación de errores, diversidad de predicciones y equilibrio entre sesgo y varianza. En términos prácticos, busca que los modelos no se equivoquen todos en lo mismo al mismo tiempo, lo que incrementa la resiliencia del resultado final.
Ese enfoque modular tiene una consecuencia directa: la trazabilidad de cada cambio. Cada módulo mejorado lleva consigo un historial que detalla la razón de la modificación, las métricas previas, las posteriores, y el contexto en el que se aplicó. No es un diario íntimo, sino un registro auditable. En empresas o centros de investigación donde los modelos deben pasar revisiones externas, esta bitácora se convierte en un salvavidas.
En la dimensión ética, el paper dedica secciones completas a los riesgos de un sistema que mejora por sí mismo. El más evidente es la deriva de objetivos: si la única métrica que se optimiza es la precisión, el agente podría sacrificar equidad o interpretabilidad. Para prevenirlo, se plantea un esquema de optimización múltiple donde distintas métricas (algunas técnicas, otras normativas) pesan en la decisión final. La selección de esas métricas no la hace el agente, sino el equipo humano. Esto coloca un dique de contención para evitar que la lógica algorítmica ignore contextos sociales o legales.
Otro riesgo, más sutil, es la desincronización entre el ritmo del agente y el de la organización. Un sistema que produce mejoras continuas puede imponer presión sobre equipos que no tienen la capacidad de validar o desplegar esos cambios a la misma velocidad. Google propone una capa de gobernanza que no interrumpe la capacidad de búsqueda del agente, pero sí regula el momento en que las mejoras pasan a producción. Esto asegura que el avance técnico no se transforme en una cascada incontrolable de versiones.
La cuestión de la eficiencia también es clave. El paper detalla que, al priorizar intervenciones con mayor potencial de mejora, se reduce el número de iteraciones necesarias para alcanzar un nivel alto de rendimiento. Esa reducción no es cosmética: en pruebas internas, el agente alcanzó resultados similares a los obtenidos por ingenieros humanos en un 40 % menos de tiempo y con un 30 % menos de uso de recursos de cómputo. En entornos donde cada hora de GPU tiene un coste elevado, esa diferencia se traduce en ahorros considerables.
Más allá de los números, hay un aspecto cultural que no se puede pasar por alto. La aparición de un colaborador automatizado capaz de proponer y ejecutar mejoras puede alterar dinámicas de poder en los equipos de trabajo. Si la figura del “experto en ajustes finos” pierde centralidad, ¿qué lugar ocupa ese profesional? El documento sugiere un reposicionamiento: pasar de ejecutar modificaciones a diseñar marcos, supervisar resultados y establecer estrategias de largo plazo. Un rol menos artesanal pero más influyente.
Es aquí donde se abre un terreno fértil para la formación cruzada. El agente, al documentar cada paso con lenguaje comprensible, puede servir como mentor implícito para ingenieros en etapa de aprendizaje. Observar cómo decide qué probar, por qué descarta ciertas opciones y cómo interpreta los resultados es un ejercicio formativo. Esa transparencia también es un antídoto contra la opacidad que a menudo acompaña a las herramientas de IA avanzada.
El interés de Google por presentar esta arquitectura no se limita a un gesto de liderazgo técnico. El contexto competitivo es evidente: otras empresas exploran agentes similares, pero no todos están dispuestos a revelar el detalle de sus procesos. Al publicar el paper, Google coloca la discusión en terreno abierto y se asegura un lugar central en el debate sobre el futuro de la ingeniería de modelos. Esto también le permite influir en los estándares que podrían adoptarse en la industria para evaluar y auditar este tipo de sistemas.
No es menor que el equipo haya optado por un enfoque basado en iteración y refinamiento dirigido, en lugar de la búsqueda exhaustiva y aleatoria. Esta elección, además de ser más eficiente, refuerza la idea de que el valor no está en probar todas las combinaciones posibles, sino en identificar las más prometedoras y explorarlas con profundidad. El agente, por tanto, no es un trabajador incansable que prueba sin pensar, sino un estratega que mide cada movimiento antes de ejecutarlo.
El cierre provisional de esta segunda entrega no es una conclusión, sino un puente hacia lo que sigue: las implicaciones más amplias de introducir un sistema así en sectores críticos, la posible evolución hacia capacidades más generales y el impacto que tendría un ecosistema de agentes auto-mejorables trabajando en paralelo. Todo, siempre, con el telón de fondo de que lo que hoy se muestra como un avance controlado podría convertirse, si se pierde el hilo ético y regulatorio, en una fuerza difícil de detener.
El horizonte que se dibuja
Proyectar este tipo de tecnología a un horizonte de cinco o diez años no es un ejercicio de adivinación ingenua, sino un intento de leer las señales que ya están presentes. Hoy, el ingeniero algorítmico de Google es una novedad, pero en un lustro podría convertirse en la norma de trabajo en empresas que dependan de aprendizaje automático. Lo que ahora se percibe como una ventaja competitiva singular podría, en pocos ciclos de adopción, transformarse en un requisito mínimo para mantenerse en el juego.
En ese escenario, el mercado se dividiría entre quienes poseen agentes de optimización de última generación y quienes dependen de soluciones más estáticas. La brecha no solo se mediría en velocidad de desarrollo, sino también en resiliencia frente a eventos disruptivos. Un sistema capaz de detectar cambios en el entorno, adaptarse y refinarse sin intervención constante podría amortiguar crisis que dejarían fuera de combate a sus competidores menos flexibles.
Sin embargo, este despliegue masivo tendría una consecuencia inevitable: la concentración del poder computacional y de la capacidad de mejora continua en un puñado de actores. No sería extraño que en 2030 existiera un ecosistema dominado por tres o cuatro corporaciones que controlen la arquitectura y el ciclo de vida de estos agentes. Esa concentración podría derivar en monopolios de facto, no tanto por la venta directa de la tecnología, sino por el acceso privilegiado a datos y a infraestructuras de entrenamiento capaces de sostener procesos de auto-optimización a gran escala.
Aquí surge la cuestión de la soberanía algorítmica. Países con fuerte capacidad de I+D podrían desarrollar variantes nacionales o regionales de estos ingenieros automáticos, adaptados a marcos regulatorios y prioridades locales. Otros, con menor capacidad de inversión, quedarían en la posición de meros usuarios de sistemas diseñados en contextos culturales, económicos y políticos muy distintos. Esta asimetría no es nueva, pero en el campo de la inteligencia artificial auto-mejorable, sus efectos pueden ser más profundos y menos reversibles.
En términos de regulación, el desafío será equilibrar innovación y control. Dejar que estos agentes evolucionen sin supervisión podría derivar en conductas opacas o incluso en formas de optimización que entren en conflicto con normas de seguridad o principios éticos básicos. En el otro extremo, imponer reglas demasiado rígidas podría sofocar el potencial de la tecnología antes de que alcance su madurez. Lo más probable es que se adopten marcos flexibles pero vinculantes, similares a las regulaciones en la aviación o la biotecnología, donde la innovación está sujeta a auditorías, certificaciones y protocolos de transparencia obligatoria.
La cooperación internacional también jugará un papel decisivo. Un agente auto-mejorable no se detiene en las fronteras físicas: sus optimizaciones pueden influir en mercados y sectores a escala global. Si un modelo ajustado en un país con regulaciones laxas se integra en la cadena de suministro digital de otro con reglas más estrictas, el riesgo de conflicto es alto. Por eso, es plausible imaginar foros multilaterales dedicados exclusivamente a la gobernanza de IA auto-evolutiva, donde se definan estándares de interoperabilidad, seguridad y trazabilidad de cambios.
Desde el punto de vista técnico, la evolución futura de estos agentes podría orientarse hacia una integración más profunda con sistemas de razonamiento multimodal. Esto significaría que el ingeniero automático no solo optimice modelos de texto o de datos tabulares, sino también arquitecturas que combinen visión, audio, lenguaje y señales sensoriales en un mismo flujo. Un agente así podría, por ejemplo, ajustar simultáneamente un modelo que procesa imágenes médicas, otro que interpreta descripciones clínicas en lenguaje natural y un tercero que analiza patrones de voz para detectar síntomas.
Otro avance probable será la aparición de ecosistemas distribuidos de agentes que colaboren entre sí sin necesidad de un controlador central. Imaginemos un consorcio de empresas de energía que, sin compartir datos brutos, permita que sus ingenieros automáticos intercambien aprendizajes estructurados sobre optimización de redes eléctricas. Este tipo de cooperación, basada en principios de federated learning y privacidad diferencial, podría acelerar el progreso sin sacrificar la confidencialidad.
En paralelo, veremos el surgimiento de agentes “especialistas” que se concentren en nichos muy concretos: optimización de modelos de predicción climática, ajuste de redes neuronales para simulaciones físicas o calibración de sistemas de recomendación. La coexistencia de estos especialistas con agentes “generalistas” creará un ecosistema más rico, pero también más complejo de gobernar.
El componente humano seguirá siendo crucial, aunque en un rol distinto al actual. El ingeniero de datos o científico de machine learning ya no pasará la mayor parte del tiempo afinando hiperparámetros o reentrenando modelos, sino evaluando las propuestas de optimización de un colaborador no humano, validando su impacto en escenarios reales y asegurando que las decisiones estén alineadas con los objetivos estratégicos de la organización. En otras palabras, el foco pasará de la microgestión técnica a la supervisión estratégica.
El reto cultural no debe subestimarse. Para que un equipo adopte plenamente a un ingeniero automático, necesita confianza en su criterio y en la transparencia de sus decisiones. Eso implica que el agente no solo debe ser eficaz, sino también explicable. Aquí entran en juego técnicas de interpretabilidad que permitan trazar, paso a paso, la lógica detrás de cada optimización. Google lo menciona en su propuesta: sin una capa sólida de interpretabilidad, la adopción será superficial y limitada.
En el largo plazo, si la tecnología madura como se espera, podríamos ver un cambio en la propia noción de “modelo entrenado”. En lugar de pensar en un modelo como un artefacto estático que se despliega y se mantiene hasta que pierde relevancia, el concepto pasaría a ser el de un organismo vivo, en constante ajuste, siempre en relación con un entorno cambiante. Este cambio conceptual impactaría en la manera en que las empresas calculan el retorno de inversión, presupuestan proyectos y planifican a largo plazo.
La pregunta final es si este horizonte será inclusivo o excluyente. Un mundo donde la capacidad de mejora continua esté al alcance de todos los actores, desde startups hasta grandes corporaciones, podría ser más dinámico y resiliente. Pero si se convierte en un privilegio de pocos, el riesgo es cristalizar desigualdades y acelerar la concentración de poder tecnológico. El resultado dependerá tanto de las decisiones técnicas como de las políticas y acuerdos que se establezcan en esta década crítica.
En definitiva, lo que hoy Google presenta como un paso innovador en ingeniería de modelos podría ser, dentro de unos años, el equivalente a la revolución industrial en la era del aprendizaje automático. Una transformación que no solo alterará cómo trabajamos con la inteligencia artificial, sino también quiénes pueden moldear su evolución y con qué propósito. La ventana para decidir cómo será ese futuro está abierta ahora, y se cerrará más rápido de lo que muchos imaginan.

