
En los últimos años, hemos sido testigos de una revolución silenciosa que ha permeado casi todos los aspectos de nuestra vida digital. La inteligencia artificial, antes un concepto relegado a la ciencia ficción y a los laboratorios de investigación de vanguardia, se ha convertido en una presencia cotidiana, una voz familiar en nuestros dispositivos y un asistente incansable en nuestras pantallas. El epicentro de esta transformación ha sido el advenimiento de los Modelos Lingüísticos Grandes, o LLM por sus siglas en inglés. Herramientas como ChatGPT han maravillado al mundo con su asombrosa capacidad para comprender y generar texto de una manera sorprendentemente humana.
En su esencia, estos modelos son colosales redes neuronales, arquitecturas de aprendizaje profundo entrenadas con una cantidad de información textual que desafía la imaginación: bibliotecas enteras, la vastedad de internet, artículos académicos y miles de millones de conversaciones. A través de este monumental proceso de aprendizaje, no adquieren una comprensión genuina como la humana, sino que se convierten en maestros incomparables del reconocimiento de patrones. Funcionan como gigantescas máquinas de predicción estadística, calculando con una precisión asombrosa cuál es la siguiente palabra más probable en una secuencia. Esta habilidad les permite realizar una gama diversa de tareas: pueden redactar correos electrónicos, traducir idiomas con fluidez, resumir documentos extensos en segundos y hasta componer poesía.
Sin embargo, esta misma fortaleza es la fuente de su debilidad más profunda y preocupante. Al no poseer un conocimiento real del mundo, los LLM son propensos a lo que los expertos denominan «alucinaciones»: la generación de información que suena perfectamente plausible y está gramaticalmente impecable, pero que es parcial o completamente falsa. Confunden hechos, inventan fuentes y presentan datos incorrectos con la misma seguridad con la que exponen una verdad verificada. Esta limitación, aunque a veces anecdótica, representa una barrera fundamental para su aplicación en tareas de alta responsabilidad.
Es precisamente en este punto de inflexión donde la comunidad científica está dando el siguiente paso evolutivo, un salto paradigmático que nos aleja de la IA como mero generador de contenido para acercarnos a la IA como un actor autónomo. Estamos entrando en la era de la «IA Agéntica». Un agente de IA no es un simple conversador; es un sistema proactivo diseñado para alcanzar objetivos complejos. No se limita a responder una pregunta, sino que emprende una serie de acciones para cumplir una tarea. La diferencia es crucial: un LLM podría escribir un plan de viaje, mientras que un agente de IA podría, además, reservar los vuelos, el hotel y las excursiones, interactuando con sistemas externos para lograrlo.
Dentro de este nuevo paradigma, emerge un campo de aplicación fundamental: la «búsqueda agéntica». Este concepto redefine nuestra interacción con la información. Una búsqueda tradicional en un motor como Google nos ofrece una lista de enlaces, dejándonos la tarea de visitar, evaluar, sintetizar y extraer el conocimiento que necesitamos. La búsqueda agéntica, en cambio, opera como un investigador personal. Comprende la intención profunda de nuestra consulta, la descompone en múltiples subpreguntas, realiza una investigación iterativa a través de diversas fuentes, evalúa la credibilidad de la información y, finalmente, nos presenta una solución integral y sintetizada.
Pero esta prometedora visión nos enfrenta a una pregunta crítica y urgente: si los LLM que actúan como el «cerebro» de estos agentes son propensos a errores y alucinaciones, ¿cómo podemos confiar en que estos nuevos sistemas autónomos actúen de manera fiable, inteligente y segura en el mundo digital? Un error de un LLM es desinformación; un error de un agente de IA puede ser una acción equivocada con consecuencias reales, como la compra de un producto incorrecto, la eliminación de un archivo crucial o la ejecución de una transacción financiera errónea. El riesgo se amplifica exponencialmente.
Es en este contexto de inmenso potencial y elevado riesgo donde se inscribe un trabajo de investigación fundamental titulado Beneficial Reasoning Behaviors in Agentic Search and Effective Post-Training to Obtain Them. Este estudio no solo reconoce el problema, sino que propone una solución elegante y poderosa. Los investigadores postulan que para construir agentes fiables, no basta con darles más datos; es necesario enseñarles a razonar.
El estudio académico identifica un conjunto de cuatro comportamientos de razonamiento cruciales que imitan las mejores prácticas del pensamiento crítico humano y presenta una novedosa técnica de entrenamiento, denominada «Behavior Priming», diseñada específicamente para inculcar estas habilidades en los agentes de IA. Este artículo periodístico se adentrará en las profundidades de esta investigación, desentrañando cómo la ciencia está enseñando a las máquinas no solo a hablar, sino a pensar.

El nacimiento de los agentes autónomos: cuando la IA aprende a «hacer» en lugar de solo «decir»
Para comprender la magnitud del avance que propone esta investigación, primero debemos establecer una distinción clara entre el chatbot con el que hemos llegado a familiarizarnos y el agente autónomo que representa el futuro. Un chatbot es un interlocutor, un experto en el diálogo. Un agente de IA, por otro lado, es un ejecutor, un análogo digital de un asistente personal o un empleado diligente. Su propósito no es conversar, sino actuar.
La operación de un agente de IA se puede describir a través de un ciclo continuo de cuatro fases fundamentales. Primero, la Percepción: el agente recopila datos de su entorno, que puede ser una página web, una base de datos, una serie de correos electrónicos o las instrucciones de un usuario. Segundo, el Razonamiento: utilizando un modelo lingüístico grande como su motor cognitivo, el agente analiza la información percibida para comprender el contexto, identificar los objetivos y formular un plan. Tercero, la Planificación: descompone el objetivo principal en una secuencia de pasos o tareas más pequeñas y manejables. Finalmente, la Acción: el agente ejecuta estos pasos interactuando con herramientas externas. Estas herramientas pueden ser APIs (Interfaces de Programación de Aplicaciones) que le permiten comunicarse con otros programas, un navegador web para buscar información o un sistema de archivos para gestionar documentos.
Este ciclo de percibir, razonar, planificar y actuar se repite hasta que la tarea se completa. Lo que hace que este proceso sea tan revolucionario es el registro detallado que genera: la «trayectoria del agente». Este concepto es absolutamente central para el avance de la IA. Una trayectoria es el rastro digital completo del proceso de pensamiento y acción del agente. Es un registro paso a paso que documenta cada observación que hizo, cada «pensamiento» interno o línea de razonamiento que formuló, cada herramienta que decidió usar y cada acción que llevó a cabo.
La importancia de la trayectoria no puede subestimarse. Transforma al agente de una enigmática «caja negra», cuyo funcionamiento interno es un misterio, a una «caja de cristal» transparente. Al analizar estas trayectorias, los desarrolladores e investigadores pueden comprender con precisión por qué un agente tuvo éxito o por qué fracasó. Pueden ver el momento exacto en que tomó un desvío equivocado, malinterpretó una instrucción o eligió la herramienta incorrecta. El foco se desplaza del resultado final (si la respuesta fue correcta o no) al proceso que condujo a ese resultado (cómo llegó a esa respuesta).
Esta perspectiva revela una comprensión más profunda: la trayectoria no es simplemente un archivo de registro para depurar errores. Es una nueva y riquísima forma de datos. Mientras que los LLM se entrenan con texto masivo y no estructurado, aprendiendo correlaciones estadísticas en el lenguaje, una trayectoria es un conjunto de datos altamente estructurado. Captura una secuencia lógica de estados, pensamientos, acciones y observaciones. Este formato no solo muestra lenguaje, sino que codifica un proceso de resolución de problemas dirigido a un objetivo. Encapsula relaciones causales: «Debido a que observé X, razoné Y, y por lo tanto, realicé la acción Z».
Una colección de trayectorias exitosas se convierte, en efecto, en una biblioteca de estrategias de razonamiento eficaces. Este nuevo tipo de datos es inmensamente más valioso para el entrenamiento avanzado que simplemente exponer al modelo a más texto genérico de la web. Permite un tipo de enseñanza mucho más específico y potente, centrado en inculcar metodologías de pensamiento en lugar de meros patrones lingüísticos. Es sobre esta base, el análisis y el aprovechamiento de la trayectoria, que se construye toda la filosofía de la investigación para crear agentes más inteligentes y fiables.

Los cuatro pilares del razonamiento robusto: enseñando a la IA a pensar como un detective
El núcleo de la propuesta de los investigadores reside en la identificación y formalización de cuatro comportamientos de razonamiento beneficiosos. Estos no son simplemente trucos o parches, sino principios cognitivos fundamentales que, cuando se integran en el comportamiento de un agente, lo transforman de un autómata frágil a un solucionador de problemas robusto. En conjunto, forman un flujo de trabajo que refleja el escepticismo saludable y la metodología rigurosa de un pensador crítico humano.
Verificación de la información: la lucha contra la alucinación
El primer pilar aborda directamente el talón de Aquiles de los modelos lingüísticos: su tendencia a generar información falsa. La Verificación de la Información es la capacidad del agente para no aceptar ciegamente el primer dato que encuentra. En su lugar, se le enseña a buscar activamente corroboración. Al enfrentarse a una afirmación o un dato crucial para su tarea, un agente dotado de este comportamiento buscará la misma información en múltiples fuentes independientes y diversas. Solo después de confirmar que varias fuentes fiables coinciden, considerará el dato como verificado y procederá a utilizarlo en su razonamiento.
Este comportamiento es la primera y más importante línea de defensa contra la desinformación. La analogía perfecta es la de un periodista diligente o un verificador de hechos profesional. Ningún reportero serio publicaría una noticia basándose en una única fuente anónima. Siempre buscará una segunda y tercera confirmación. Al inculcar este principio en la IA, se reduce drásticamente la probabilidad de que el agente base sus acciones en una «alucinación» del modelo subyacente, aumentando su fiabilidad de manera significativa.
Evaluación de la autoridad: ¿quién lo dice y por qué debería importarme?
El segundo pilar va un paso más allá de la simple verificación cuantitativa. La Evaluación de la Autoridad introduce un juicio cualitativo sobre las fuentes de información. No todas las fuentes son iguales, y un agente inteligente debe ser capaz de discernir esta diferencia. Este comportamiento enseña al agente a sopesar la credibilidad de las fuentes que consulta. Aprende a dar más valor a un artículo científico revisado por pares que a un comentario en un foro de internet, a priorizar la documentación oficial de un producto sobre la entrada de un blog personal, o a confiar más en los datos de una agencia gubernamental que en una opinión en redes sociales.
Este proceso es análogo al de un investigador académico que construye su argumento. Un académico evalúa meticulosamente la procedencia de sus fuentes, buscando estudios de instituciones reconocidas, autores con experiencia en el campo y publicaciones de prestigio. De manera similar, el agente aprende a identificar indicadores de autoridad y fiabilidad. Este comportamiento es esencial para navegar el ruidoso y a menudo poco fiable paisaje informativo de la web, permitiendo al agente filtrar el ruido y centrarse en las señales de alta calidad.
Búsqueda adaptativa: el arte de cambiar de rumbo cuando el camino se agota
El tercer pilar combate la rigidez y la fragilidad. Los problemas complejos rara vez tienen una solución lineal. A menudo, el camino inicial resulta ser un callejón sin salida. La Búsqueda Adaptativa es la habilidad del agente para reconocer cuándo una estrategia de búsqueda o una línea de investigación no está dando frutos y, en consecuencia, cambiar de táctica de forma dinámica. Si una consulta de búsqueda inicial produce resultados irrelevantes o escasos, el agente no se queda atascado repitiéndola. En su lugar, reformula la pregunta, prueba con sinónimos, aborda el problema desde un ángulo diferente o busca un tipo de información completamente nuevo.
El modelo a seguir aquí es el de un detective experimentado. Cuando una pista no lleva a ninguna parte, el detective no insiste en ella indefinidamente. Reexamina la evidencia, reconsidera las hipótesis y abre una nueva línea de investigación. Esta flexibilidad cognitiva es una marca distintiva de la inteligencia resolutiva. Para un agente de IA, esta capacidad es crucial para evitar caer en bucles inútiles y para resolver problemas que requieren creatividad y persistencia, garantizando que pueda encontrar una solución incluso cuando el camino no es obvio.
Recuperación de errores: aprender del tropiezo para no volver a caer
El cuarto y último pilar es la resiliencia. Cometer errores es inevitable, incluso para los sistemas más avanzados. La Recuperación de Errores es la capacidad del agente para identificar cuándo ha cometido un fallo, comprender la naturaleza de ese error y, lo más importante, retroceder a un estado válido anterior para intentar un enfoque diferente. Esto podría ocurrir si el agente intenta usar una herramienta de software con parámetros incorrectos, sigue un enlace roto o basa una decisión en una premisa que luego se demuestra falsa.
Este comportamiento es similar al de un sistema de navegación GPS. Cuando nos equivocamos de salida en una autopista, el GPS no se rinde ni sigue dándonos instrucciones para una ruta que ya es imposible. Reconoce instantáneamente el error, recalcula una nueva ruta desde nuestra posición actual y nos guía de vuelta al camino correcto. Para un agente de IA, esta capacidad de autocorregirse sobre la marcha es fundamental. Le permite completar tareas complejas y de varios pasos sin ser descarrilado permanentemente por un único fallo, convirtiéndolo en un sistema mucho más robusto y fiable.
Estos cuatro comportamientos no son meras adiciones aisladas. Funcionan en conjunto como un flujo de trabajo cognitivo integrado y jerárquico. Ante un problema, el agente primero recopila y filtra datos usando la Verificación de Información y la Evaluación de Autoridad. Si esta fase de recopilación de datos de alta calidad falla, la Búsqueda Adaptativa se activa para cambiar la estrategia general. Y en cualquier punto de este proceso, si una acción específica falla, la Recuperación de Errores actúa como un mecanismo de tolerancia a fallos de bajo nivel para corregir el curso. Enseñar a una IA este flujo de trabajo completo es enseñarle una metodología para navegar la incertidumbre, un paso mucho más profundo que simplemente enseñarle habilidades aisladas.
Behavior Priming: un nuevo paradigma para esculpir el comportamiento de la IA
Habiendo definido el «qué» (los cuatro comportamientos de razonamiento deseables), la investigación aborda el «cómo»: ¿cuál es el método más eficaz para inculcar estas sofisticadas habilidades en un agente de IA? Para apreciar la novedad de la solución propuesta, el «Behavior Priming», es útil entender primero los dos enfoques de entrenamiento predominantes en la actualidad: el Ajuste Fino Supervisado (SFT) y el Aprendizaje por Refuerzo (RL).
El primer método, el Ajuste Fino Supervisado o SFT, puede entenderse como «aprender por imitación». En este proceso, se toma un modelo de lenguaje preentrenado y se le expone a un conjunto de datos más pequeño y de muy alta calidad. Este conjunto de datos consiste en ejemplos perfectos, a menudo curados por humanos, del comportamiento que se desea que el modelo emule. En el contexto de los agentes, esto significaría mostrarle miles de «trayectorias ideales» donde un agente experto resuelve un problema de manera impecable. La analogía es la de un chef aprendiz al que se le enseña pidiéndole que replique, paso a paso y con total precisión, una receta de un chef maestro. La gran fortaleza del SFT es su capacidad para enseñar al modelo a producir resultados de alta calidad y con un formato específico. Su debilidad es que puede llevar a una falta de flexibilidad; el modelo se vuelve muy bueno imitando los ejemplos que ha visto, pero puede tener dificultades cuando se enfrenta a una situación completamente nueva que no estaba en su conjunto de datos de entrenamiento.
El segundo método, el Aprendizaje por Refuerzo o RL, funciona de manera muy diferente. Se puede describir como «aprender por prueba y error». En lugar de mostrarle ejemplos perfectos, se deja que el agente explore un entorno digital por su cuenta. El agente toma acciones, y por cada acción, recibe una señal del entorno: una «recompensa» si la acción lo acerca a su objetivo, o una «penalización» si lo aleja. A lo largo de millones de intentos, el agente aprende a asociar ciertas secuencias de acciones con la máxima recompensa acumulada. La analogía clásica es la de entrenar a un perro: se le da una golosina (recompensa positiva) cuando realiza el truco correctamente y un «no» firme (penalización) cuando no lo hace. La principal ventaja del RL es su poder para descubrir estrategias novedosas y eficaces que los humanos podrían no haber considerado. Su principal inconveniente es que puede ser muy ineficiente, requiriendo una enorme cantidad de intentos para aprender. Además, al estar centrado únicamente en el resultado final (la recompensa), al agente no le importa cómo llega a la solución, lo que a veces puede llevarlo a aprender «atajos» o comportamientos extraños que logran el objetivo pero no reflejan un razonamiento sólido.
Aquí es donde la investigación introduce el «Behavior Priming» como una tercera vía, un enfoque más matizado y sofisticado. Como su nombre indica, esta técnica no se centra en recompensar una trayectoria perfecta (como el SFT) ni únicamente el resultado final (como el RL). En su lugar, su objetivo es identificar y recompensar la presencia de los cuatro comportamientos de razonamiento beneficiosos dentro de la trayectoria del agente. El modelo es «preparado» (primed) para actuar como un buen razonador.
La analogía del chef nos ayuda a entender la diferencia. El SFT le enseña al chef una receta específica. El RL lo recompensa por un plato sabroso, sin importar cómo lo preparó. El Behavior Priming, en cambio, le enseña las técnicas culinarias fundamentales: cómo saltear correctamente, el arte del estofado, las habilidades con el cuchillo, el balance de sabores. Con estas técnicas fundamentales, el chef no solo puede replicar una receta, sino que puede crear cualquier plato, incluso uno que nunca haya visto antes. De manera similar, el Behavior Priming no enseña al agente a resolver un problema específico, sino que le inculca los principios abstractos del buen razonamiento que puede aplicar a una infinidad de problemas.
Este enfoque representa la implementación técnica de la tesis filosófica central del artículo: para crear agentes autónomos fiables y seguros, la calidad del proceso de razonamiento es más importante que la corrección de un único resultado. Un buen proceso conducirá de manera fiable a buenos resultados en una amplia variedad de situaciones, mientras que un proceso deficiente podría llegar a la respuesta correcta de vez en cuando por pura suerte.
El Behavior Priming es la herramienta diseñada para esculpir ese proceso de razonamiento virtuoso. Es probable que funcione como un híbrido inteligente, utilizando datos etiquetados por humanos (como en SFT) para identificar ejemplos de los cuatro comportamientos en diversas trayectorias, y luego utilizando una señal de recompensa (como en RL) para reforzar al agente cada vez que exhibe uno de estos comportamientos, independientemente del contexto específico de la tarea. Este método enseña al modelo a generalizar los principios del pensamiento, no solo a imitar ejemplos o a perseguir una puntuación, lo que conduce a un rendimiento mucho más robusto en tareas complejas y desconocidas.
Midiendo la inteligencia real: más allá de la puntuación final
Una vez desarrollado un nuevo método de entrenamiento, es imperativo medir su eficacia. Sin embargo, en el campo de la inteligencia artificial, la evaluación no es una tarea trivial. Los benchmarks, o pruebas estandarizadas, son la herramienta principal para comparar el rendimiento de diferentes modelos, pero tienen sus propias limitaciones.
El problema con muchos benchmarks de IA es el riesgo de «sobreajuste» o «enseñar para la prueba». Un modelo puede ser entrenado intensivamente en un conjunto de datos muy similar al del benchmark, lo que le permite obtener una puntuación muy alta sin poseer una capacidad de razonamiento generalizable. Es como un estudiante que memoriza las respuestas de exámenes de años anteriores: puede que apruebe con nota, pero carece de una comprensión profunda de la materia y probablemente fracasaría ante una pregunta formulada de manera ligeramente diferente. Para evaluar verdaderamente la eficacia del Behavior Priming y los comportamientos de razonamiento, los investigadores necesitaban pruebas que no pudieran resolverse con simple memorización, pruebas que exigieran un razonamiento genuino y de varios pasos.
Para ello, utilizaron un conjunto de benchmarks de alta dificultad, diseñados específicamente para poner a prueba los límites de la IA agéntica en escenarios realistas y complejos. Entre ellos se encuentran GAIA, WebWalker y HLE. Aunque los detalles técnicos son complejos, podemos entender su propósito por su naturaleza:
- GAIA (General AI Assistant) es un benchmark que presenta preguntas complejas que requieren que el agente navegue por la web, utilice diversas herramientas (como calculadoras o intérpretes de código) y sintetice información de múltiples fuentes para llegar a una respuesta final. Está diseñado para imitar las tareas de un asistente de investigación humano.
- WebWalker se centra específicamente en la capacidad del agente para navegar e interactuar con sitios web complejos y dinámicos. Las tareas pueden implicar rellenar formularios, seguir una serie de enlaces para encontrar una información específica o extraer datos de páginas con estructuras complicadas.
- HLE (Human-Level Evaluation), como su nombre indica, probablemente comprende un conjunto de tareas que se consideran desafiantes incluso para los humanos, requiriendo una planificación cuidadosa, inferencia lógica y una robusta recuperación de errores.
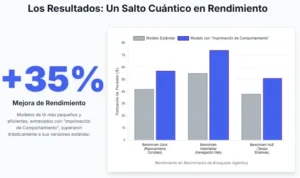
Los resultados cuantitativos reportados en el estudio son significativos. Los modelos entrenados con la técnica de Behavior Priming mostraron una mejora sustancial en su tasa de éxito en estos desafiantes benchmarks en comparación con los modelos entrenados con métodos estándar. Sin embargo, la verdadera importancia de estos resultados no reside en el número exacto del porcentaje de mejora. La clave es la interpretación de por qué se produjo esa mejora.
El éxito en estas pruebas no se debe a que el modelo sea simplemente «más inteligente» en un sentido abstracto o a que haya memorizado más hechos. El rendimiento superior es una consecuencia directa de la internalización de los cuatro comportamientos de razonamiento. El modelo tiene éxito porque, cuando se encuentra con información contradictoria, la verifica (Verificación de Información). Cuando se enfrenta a múltiples fuentes, prioriza las más fiables (Evaluación de Autoridad). Cuando una estrategia de búsqueda falla, prueba una nueva (Búsqueda Adaptativa). Y cuando una de sus acciones da un error, retrocede y lo intenta de nuevo (Recuperación de Errores). El modelo no es simplemente mejor para encontrar la respuesta correcta; es un solucionador de problemas más metódico, resiliente y sistemático.
Esta perspectiva redefine el papel de los benchmarks. Dejan de ser un simple tablero de clasificación para convertirse en herramientas de diagnóstico para habilidades cognitivas. Al analizar la trayectoria de un agente en una tarea fallida, los investigadores pueden identificar la causa raíz del fracaso con una precisión sin precedentes.
¿El agente falló porque aceptó una premisa falsa sin contrastarla? Eso es un fallo en la Verificación de Información. ¿Se quedó atascado en un bucle de búsqueda ineficaz? Un fallo en la Búsqueda Adaptativa. ¿Utilizó una herramienta incorrectamente y no fue capaz de retroceder? Un fallo en la Recuperación de Errores. Este nivel de análisis permite a los científicos pasar de una conclusión genérica como «el modelo falló» a un diagnóstico específico como «el modelo falló porque carece de la habilidad X».
Esta capacidad diagnóstica hace que el proceso de mejora de la IA sea mucho más científico, sistemático y dirigido, convirtiendo los benchmarks en una herramienta para el progreso científico en lugar de una simple competición.
En busca de una inteligencia artificial más fiable, transparente y colaborativa
El viaje que hemos emprendido a través de esta investigación nos lleva desde el asombro inicial por los modelos lingüísticos hasta la promesa de los agentes autónomos, reconociendo al mismo tiempo los serios desafíos que esta transición implica. El trabajo sobre los comportamientos de razonamiento beneficiosos y el Behavior Priming no ofrece una solución mágica, sino algo mucho más valioso: una hoja de ruta concreta y fundamentada para construir la próxima generación de sistemas de inteligencia artificial. La contribución fundamental de este estudio es un cambio de enfoque: de la obsesión por el resultado final a la valoración primordial del proceso de razonamiento. Nos enseña que para que una IA sea verdaderamente inteligente, no solo debe saber la respuesta, sino que debe saber cómo llegar a ella de una manera robusta y fiable.
Las implicaciones de este avance se extienden en múltiples direcciones. En el plano tecnológico, esta investigación impulsa a la industria más allá de la carrera por construir modelos cada vez más grandes. Demuestra que la sofisticación en las metodologías de entrenamiento puede ser tan importante, o incluso más, que la simple fuerza bruta computacional. El futuro del desarrollo de la IA no residirá únicamente en añadir más parámetros o más datos, sino en diseñar técnicas de aprendizaje más inteligentes que inculquen principios de razonamiento. Esto conducirá a asistentes virtuales más capaces, herramientas de investigación científica más potentes y sistemas de automatización industrial más eficientes y seguros.
En el ámbito social, el impacto es quizás aún más profundo. Uno de los mayores obstáculos para la adopción generalizada de la IA en campos de alta responsabilidad como la medicina, las finanzas o el derecho es la falta de confianza y transparencia.
¿Cómo podemos confiar una decisión crítica a un sistema cuyo proceso de pensamiento es una caja negra? Al hacer que el razonamiento del agente sea visible a través de sus trayectorias y, lo que es más importante, al garantizar que ese proceso sea intrínsecamente robusto y siga principios lógicos, comenzamos a construir las bases de una IA fiable. Un sistema que puede explicar sus pasos, justificar sus decisiones y corregir sus propios errores es un sistema con el que podemos empezar a colaborar de forma segura.
Finalmente, en el terreno científico, este trabajo representa un paso significativo en la gran búsqueda de la inteligencia artificial general (AGI). Al codificar e inculcar en las máquinas elementos que consideramos fundamentales para el «buen juicio» humano, no solo estamos construyendo mejores herramientas. Estamos creando modelos computacionales de la cognición. Cada comportamiento de razonamiento formalizado es una hipótesis sobre cómo funciona la inteligencia resolutiva, una hipótesis que ahora puede ser probada, refinada y expandida dentro de un entorno digital. Este enfoque nos permite no solo imitar las manifestaciones externas de la inteligencia, sino empezar a diseñar sus mecanismos internos.
La era de la inteligencia artificial agéntica está apenas comenzando. Los desafíos que tenemos por delante son inmensos, y las cuestiones éticas y de seguridad deben abordarse con la máxima seriedad. Sin embargo, trabajos como este iluminan el camino a seguir. Nos muestran que el futuro de la IA no tiene por qué ser una carrera ciega hacia una mayor potencia, sino que puede ser una búsqueda deliberada y reflexiva de una mayor sabiduría. Una búsqueda para construir no solo máquinas que calculan, sino máquinas que razonan, colaboran y, en última instancia, nos ayudan a comprender mejor el universo y nuestro propio lugar en él.
Referencias
Jin, J. et al. (2025) Beneficial Reasoning Behaviors in Agentic Search and Effective Post-Training to Obtain Them. Arxiv 2510.04721.
Milvus. (s.f.). What are the key challenges in AI reasoning?
McKinsey & Company. (2024). Seizing the agentic AI advantage.
Nine Peaks. (s.f.). What is Agentic Search?
Stanford University IT. (s.f.). AI Demystified: Large Language Models (LLMs).
Ye, X., et al. (2024). AnaloBench: Benchmarking the Identification of Abstract and Long-context Analogies. arXiv.

