
La forma en que interactuamos con los modelos de lenguaje grandes (LLM) está experimentando una transformación profunda, pasando de un paradigma reactivo y puntual a uno proactivo y evolutivo. Este cambio no se debe a una mejora en el modelo subyacente por sí mismo, sino a un nuevo nivel de sofisticación en cómo le presentamos información y objetivos.
Tradicionalmente, la ingeniería de prompts ha sido la herramienta principal para guiar a estos sistemas, consistiendo en la elaboración cuidadosa de instrucciones para obtener respuestas específicas. Sin embargo, esta aproximación se centra en optimizar una única interacción, como si fuera una pregunta perfectamente formulada.
Los sistemas modernos, especialmente los denominados agentes de IA agnósticos, operan de manera muy diferente. Son entidades autónomas que piensan, planifican, se adaptan y colaboran de forma autónoma para alcanzar metas complejas. Para estas entidades, las instrucciones individuales son insuficientes; lo que necesitan es un entorno informativo completo y coherente.
Aquí es donde emerge la Ingeniería de Contexto (Context Engineering), una disciplina mucho más amplia que va más allá del simple prompt engineering. En lugar de centrarse únicamente en refinar comandos individuales, la ingeniería de contexto se dedica a diseñar, estructurar y optimizar todo el conjunto de información contextual que un sistema de IA consume durante su proceso de inferencia.
Este «espacio de trabajo» informativo es la base sobre la cual el modelo construye sus decisiones y acciones. Incluye elementos cruciales como el sistema de instrucciones (que define la identidad y reglas del agente), las entradas y salidas estructuradas, las herramientas externas disponibles, los datos recuperados de bases de conocimiento, el historial de interacciones previas y el estado global del sistema.
Es fundamental entender que este recurso de contexto es finito. La arquitectura de los LLM, basada en Transformers, tiene un límite práctico en el número de tokens (palabras o partes de palabras) que puede procesar simultáneamente, conocido como el «presupuesto de atención». Esta limitación provoca que el rendimiento degradase gradualmente si el contexto se vuelve demasiado largo, un fenómeno que se conoce coloquialmente como «rotura de contexto» (context rot).
Ante este desafío, la ingeniería de contexto ha desarrollado diversas técnicas para gestionar eficazmente este espacio limitado. Una estrategia clave es la compresión, que implica resumir conversaciones extensas o reiniciar ventanas de contexto para mantenerlo ágil.
Otra técnica avanzada es la memoria persistente, donde la información crucial se almacena fuera del contexto actual (por ejemplo, en un archivo o una base de datos) y se recupera just-in-time cuando sea necesaria, mediante sistemas como el Retrieval-Augmented Generation (RAG). Por ejemplo, un agente podría escribir información importante en un archivo llamado «todo.md» y luego leerlo más tarde, manteniendo así un estado sin saturar la ventana de contexto. Otros mecanismos incluyen el uso de herramientas especializadas para acortar el propio contexto, como un modelo de lenguaje dedicado a la tarea de la abreviatura, o el aislamiento de subtareas para evitar interferencias entre diferentes contextos.
A medida que los agentes se vuelven más complejos y autónomos, la gestión del contexto no es solo una cuestión de eficiencia, sino una infraestructura crítica, análoga a las bases de datos y las APIs en un sistema de software tradicional. Sin una canalización de contexto bien gestionada, incluso los modelos más potentes pueden generar resultados erróneos o «alucinaciones», ya que carecen de un marco informativo estable y relevante para fundamentar sus decisiones.
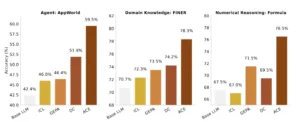
Resultados generales de rendimiento. Nuestro marco de trabajo propuesto, ACE, supera consistentemente las sólidas líneas base en tareas de razonamiento específicas del agente y del dominio.
El marco ACE: Cómo los agentes de IA se automejoran sin reentrenar
El paper «Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models» presenta un avance revolucionario que formaliza y automatiza la mejor práctica más valiosa del mundo de la IA autónoma: la capacidad de aprender de la experiencia y mejorar continuamente. El marco propuesto, conocido como ACE (Ingeniería de Contexto Agente), permite a los modelos de lenguaje grandes (LLM) auto-mejorarse de forma significativa sin necesidad de realizar un costoso reentrenamiento o ajuste de parámetros.
Esto representa una disrupción fundamental en la industria, donde históricamente la mejora de un modelo ha requerido acceso a sus pesos internos y vastos recursos computacionales. ACE postula que la verdadera inteligencia y capacidad de adaptación de un agente no reside tanto en sus conexiones neuronales preestablecidas como en la calidad dinámica de su «libro de apuntes» o playbook: su contexto. Al permitir que este libro de apuntes evolucione y se refine a lo largo del tiempo, ACE logra una mejora de rendimiento notable, demostrando que el conocimiento y las estrategias efectivas pueden ser encapsulados y perfeccionados dentro de la propia información contextual del modelo.
El núcleo del marco ACE es un proceso modular y cíclico de tres fases: Generación, Reflexión y Curaduría. Este ciclo se repite iterativamente para acumular, evaluar y pulir las estrategias que el agente utiliza para resolver tareas. En la fase de Generación, el agente utiliza el contexto existente (su playbook) para ejecutar una tarea específica, produciendo una acción y una observación. En la fase de Reflexión, el sistema analiza esta ejecución, extrae lecciones aprendidas y evalúa el resultado. Finalmente, en la fase de Curaduría, el sistema decide qué información de esta nueva experiencia (la acción, la observación y la reflexión) debe ser preservada y añadida al contexto para futuras referencias.
Este proceso de crecimiento y refinamiento («grow-and-refine») es crucial para evitar el colapso del contexto, asegurando que solo la información más valiosa y relevante se conserve, mientras que el ruido se elimina. El sistema utiliza actualizaciones incrementales, similares a los «deltas» en control de versiones, para incorporar nuevas lecciones de forma estructurada e incremental, lo que ayuda a preservar el conocimiento detallado y a evitar la pérdida de información valiosa a lo largo del tiempo.
Una de las innovaciones más importantes de ACE es su capacidad para funcionar de forma completamente automática y sin supervisión etiquetada. En lugar de depender de humanos que revisen y califiquen cada ejecución, ACE aprovecha las señales de retroalimentación naturales que surgen directamente de la propia ejecución del agente. Si el agente completa una tarea con éxito, esa secuencia de acciones y el contexto asociado se consideran exitosos y se archivan.
Si falla, el sistema puede analizar el punto de error para aprender desde ello, una idea que algunos han bautizado empíricamente como ‘descenso estocástico del graduado’ (Stochastic Graduate Descent). Esta dependencia de la retroalimentación natural de ejecución no solo reduce drásticamente los costos y la complejidad del entrenamiento, sino que también permite una escala inmensamente superior, ya que el agente puede aprender constantemente de miles o millones de interacciones sin intervención humana continua.
El marco fue desarrollado por un equipo multidisciplinar de investigadores de Stanford University, SambaNova Systems, Inc. y UC Berkeley en el estudio académico «Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models», lo que subraya su importancia y aplicabilidad industrial. La premisa central de ACE es que la inteligencia no reside en los pesos, sino en el contexto que evoluciona.
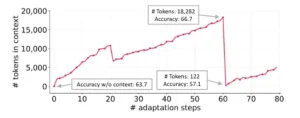
Colapso del contexto. La reescritura monolítica del contexto por parte de un LLM puede reducirlo a resúmenes más cortos y menos informativos, lo que provoca caídas drásticas del rendimiento.
Un sistema de Auto-Aprendizaje Modular
Para comprender la potencia de Agentic Context Engineering (ACE), es necesario desglosar su arquitectura modular y su flujo de trabajo. El sistema está diseñado para ser robusto y escalable, capaz de operar con modelos de contexto largo y aprender de manera autónoma. Su corazón es un proceso iterativo y cíclico que combina generación, reflexión y curaduría, pero lo hace de una manera que ataca directamente dos de las debilidades más persistentes de los sistemas de IA autónomos: el sesgo de brevedad y el colapso del contexto.
Estas limitaciones son críticas: el «sesgo de brevedad» ocurre cuando los modelos tienden a preferir respuestas cortas y genéricas, sacrificando profundidad y precisión, mientras que el «colapso del contexto» se refiere a la degradación del rendimiento a medida que la cantidad de información en la ventana de contexto aumenta, llevando a confusiones y olvidos. ACE aborda ambos problemas mediante una combinación de actualizaciones incrementales y mecanismos de selección de información inteligente.
El flujo de trabajo de ACE se puede visualizar como un motor de mejora continua. Comienza con un Contexto Inicial, que puede ser tan sencillo como un Prompt del Sistema básico o un conjunto de conocimientos de dominio. A partir de ahí, el ciclo de 3 fases se inicia:
- Generación: El agente utiliza el contexto actual para ejecutar una tarea. Este proceso produce una salida y una observación sobre el resultado.
- Reflexión: Un componente separado, a menudo otro modelo de lenguaje, analiza la ejecución completa (tarea, acción, observación). Su función es evaluar el resultado y extraer conclusiones valiosas. Esto puede implicar verificar la corrección, identificar patrones de éxito o fracaso, y formular estrategias mejoradas para tareas futuras.
- Curaduría: Basándose en la reflexión, un mecanismo de toma de decisiones decide qué información del evento de ejecución debe ser conservada. Solo la información seleccionada se añade al contexto, creando una versión mejorada del «playbook» del agente. Esta etapa es vital para evitar la saturación del contexto con datos irrelevantes o redundantes.
Esta arquitectura modular permite una gran flexibilidad. Por ejemplo, el mecanismo de reflexión puede ser tan simple como un verificador de hechos o tan complejo como un sub-agente especializado en la optimización de estrategias. La curaduría también puede implementar múltiples políticas de filtrado, como priorizar la información de las ejecuciones exitosas, guardar los errores para el análisis futuro o eliminar las estrategias que han demostrado ser consistentemente ineficaces.
Además, el marco se inspira en conceptos previos como la «memoria adaptable» de Dynamic Cheatsheet, pero lo expande para ser más sistemático y estructurado. La idea de tratar el contexto como una memoria que se puede consultar, modificar y mejorar es central. Esta perspectiva transforma el contexto de un mero conjunto de datos en un activo dinámico y evolutivo.
La capacidad de ACE para funcionar sin supervisión etiquetada es un corolario directo de esta arquitectura. Al confiar en la retroalimentación natural de la ejecución, el sistema puede escalar de manera exponencial, aprendiendo de cada interacción en tiempo real y acumulando conocimiento de forma autónoma, sin la necesidad de costosas campañas de anotación manual.
| Componente | Descripción | |
|---|---|---|
| Proceso Modular | Ciclo iterativo de Generación, Reflexión y Curaduría para la auto-mejora. | |
| Actualizaciones Incrementales | Incorporación de nueva información en formato de «delta» para un crecimiento estructurado y evitar el colapso de contexto. | |
| Reflexión Automatizada | Uso de un componente de IA para analizar las ejecuciones y extraer lecciones aprendidas, eliminando la necesidad de supervisión manual. | |
| Gestión del Sesgo | Mecanismos para mitigar el sesgo de brevedad y el colapso del contexto, mejorando la calidad y profundidad de las respuestas. | |
| Base de Conocimiento | Se basa en ideas de memoria adaptable, como la introducida por Dynamic Cheatsheet, pero de forma más amplia y estructurada. |
Este diseño no solo es teórico; es funcional. El marco fue probado con modelos de código abierto, como DeepSeek-V3.1, demostrando que la auto-mejora a través de la ingeniería de contexto es accesible para una gama más amplia de organizaciones, no solo para aquellos con acceso a los modelos más grandes y caros del mercado.
Medición del rendimiento de la Auto-Mejora
La validez de cualquier marco de mejora de IA debe ser probada rigurosamente a través de métricas cuantitativas y comparativas. El paper que presenta Agentic Context Engineering (ACE) no solo presenta una idea conceptual, sino que también la valida con un conjunto robusto de pruebas en dominios de alto nivel de dificultad.
Los resultados demuestran no solo la viabilidad, sino también la superioridad de ACE frente a los métodos de referencia, estableciendo un nuevo estándar para la auto-mejora en agentes de IA. Las evaluaciones se llevaron a cabo en dos campos principales: tareas de agentes generales (evaluadas en el leaderboard de AppWorld) y tareas financieras especializadas (evaluadas en conjuntos de datos FiNER y Formula).
En el ámbito de los agentes de IA, ACE fue sometido a prueba en el conjunto de pruebas AppWorld, que es reconocido como un marcador de prestaciones para la capacidad de los agentes de completar tareas complejas en entornos simulados de computadora. Los resultados fueron extraordinarios. ACE igualó al agente líder en la puntuación media general, un sistema poderoso basado en GPT-4.1 de IBM. Pero la verdadera demostración de su valor se manifestó en el conjunto de pruebas más difícil (test-challenge), donde ACE superó al líder, logrando un rendimiento significativamente mejor.
Esto sugiere que ACE no solo es competitivo, sino que posee una mayor robustez y capacidad de adaptación en situaciones de alta complejidad y ambigüedad. Lo más destacable de este logro es que ACE alcanzó estos resultados utilizando un modelo de código abierto más pequeño y menos costoso, DeepSeek-V3.1, lo que demuestra que la ingeniería de contexto puede compensar la falta de tamaño en el modelo subyacente.
En el dominio financiero, ACE también mostró mejoras sustanciales. En el análisis de documentos financieros (FiNER), la precisión del modelo mejoró en un +8.6%. De manera similar, en la extracción de fórmulas matemáticas de documentos científicos y financieros (Formula), el rendimiento mejoró en un +8.6%. Juntas, estas mejoras de +10.6% en tareas de agentes y +8.6% en finanzas representan una mejora promedio considerable que demuestra la versatilidad del marco ACE para dominios diversos. La siguiente tabla resume los resultados clave obtenidos en las evaluaciones del paper.
| Dominio de Prueba | Métrica Principal | Resultado de ACE | Comparación con Líder | Modelo Subyacente | |
|---|---|---|---|---|---|
| Agentes (AppWorld) | Precisión Media General (TGC) | 59.4% | Iguale al líder basado en GPT-4.1 (60.3%) | DeepSeek-V3.1 (Open Source) | |
| Agentes (AppWorld) | Precisión en Conjunto Difícil (Challenge Test) | 57.3% | Superó al líder basado en GPT-4.1 | DeepSeek-V3.1 (Open Source) | |
| Finanzas (FiNER) | Exactitud | 78.3% | Mejora del +8.6% vs baseline | DeepSeek-V3.1 (Open Source) | |
| Finanzas (Formula) | Exactitud | 85.5% | Mejora del +8.6% vs baseline | DeepSeek-V3.1 (Open Source) |
Además de las mejoras en el rendimiento, ACE demostró beneficios tangibles en eficiencia. Al reducir la latencia de adaptación hasta en un 86.9% y los costos de ejecución hasta en un 83.6%, el marco no solo hace que los agentes sean más inteligentes, sino también más rápidos y económicos. Tal combinación de superioridad en rendimiento, especialmente en pruebas difíciles, y un aumento de la eficiencia operativa, posiciona a ACE como una tecnología fundamental para el futuro de la IA autónoma. Demuestra que la auto-mejora no es un sueño lejano, sino una realidad tangible que puede ser implementada hoy para crear sistemas de IA más competentes, resilientes y rentables.

Ejemplo de contexto generado por ACE en el AppWorld Benchmark (mostrado parcialmente). Los contextos generados por ACE contienen información detallada y específica del dominio, junto con herramientas y código fácilmente utilizables, lo que sirve como guía completa para las solicitudes de LLM.
Redefiniendo la gestión de IA
La aparición de Agentic Context Engineering (ACE) no es simplemente una mejora incremental; es una transformación conceptual que redefine cómo se construyen, gestionan y comprenden los sistemas de IA autónomos. Sus implicaciones técnicas y operativas son profundas y de largo alcance, desplazando paradigmas establecidos y sentando las bases para una nueva era de desarrollo de agentes de IA. Uno de los cambios más significativos es el desplazamiento del foco desde el ajuste fino (fine-tuning) hacia la ingeniería de flujos de trabajo y el contexto.
Históricamente, la búsqueda de la máxima precisión en un modelo de IA ha implicado ajustar sus miles de millones de parámetros mediante reentrenamientos costosos y complejos. ACE propone una alternativa radical: en lugar de cambiar el cerebro del modelo, se cambia su libreta de apuntes. Esta filosofía democratiza la mejora de la IA, ya que la ingeniería de contexto es un problema de software y gestión de datos, no de supercomputación exclusiva. Cualquier organización puede mejorar sus agentes de IA al optimizar la calidad y la estructura de la información que consumen.
Operativamente, esto significa que las mejores prácticas para los equipos de IA están cambiando. En lugar de centrarse únicamente en la optimización del modelo, los equipos deben comenzar a pensar en su canalización de contexto como una infraestructura crítica. Esto implica invertir en herramientas y metodologías para la gestión de la memoria, el seguimiento del estado, la recuperación e inyección de contexto y la consistencia entre múltiples agentes.
Herramientas como LLUMO Eval360, que permiten trazar el contexto paso a paso y verificar la solidez de las respuestas, se volverán tan importantes como las suites de validación de modelos. La ingeniería de flujos de trabajo se convierte en un arte en sí mismo, donde los ingenieros de IA actúan como orquestadores de agentes, diseñando arquitecturas multiagente y flujos de trabajo que dividen tareas complejas en pasos con contexto optimizado. Patrones de diseño como la reflexión interna (donde un agente evalúa y refina su propio trabajo, como GitHub Copilot), el uso de herramientas externas estandarizadas y la planificación jerárquica (descomponiendo problemas grandes en pequeños) son ahora pilares fundamentales de la construcción de sistemas de IA agnósticos.
La arquitectura de ACE también introduce nuevos paradigmas operativos. El concepto de usar el sistema de archivos como una memoria externa persistente, como hace el proyecto Manus, es una idea poderosa que mejora la atención del modelo y evita la saturación del contexto.
Mantener un prefijo estable en el prompt para maximizar la tasa de aciertos de la caché de claves/valores (KV-cache) es otra técnica operativa avanzada que puede reducir drásticamente los costos de inferencia, convirtiéndose en una práctica estándar en sistemas de producción. Además, la decisión de ACE de funcionar sin supervisión etiquetada tiene implicaciones operativas masivas. Permite la creación de agentes que aprenden de forma continua en producción, acumulando conocimiento de manera autónoma y escalable. Esto reduce la carga sobre los equipos de validación y permite una mejora constante sin pausas en el servicio. Sin embargo, también introduce nuevos desafíos.
La gestión de riesgos como el envenenamiento del contexto (inyección de información falsa), la filtración de prompts y los sesgos contextuales requiere un enfoque proactivo. Las estrategias de mitigación, como el aislamiento de sesiones, el control de acceso basado en roles (RBAC) y la validación de entradas, pasarán a ser parte integral de la implementación de sistemas basados en ACE. En resumen, ACE no solo ofrece una nueva herramienta, sino que propone un nuevo modo de pensar sobre la inteligencia artificial, trasladando el centro de gravedad de la modelización a la ingeniería del comportamiento.
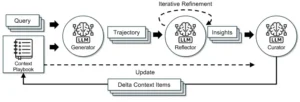
El marco ACE. Inspirado en Dynamic Cheatsheet, ACE adopta una arquitectura agencial con tres componentes especializados: un generador, un reflector y un curador.
La frontera de la auto-conciencia artificial
A medida que los modelos de lenguaje se vuelven más autónomos y capaces de auto-mejorarse, surgen preguntas sociales y éticas profundas que van más allá de la pura eficiencia técnica. La capacidad de un agente de IA para recordar, evaluar y adaptar su comportamiento según sus experiencias previas, como describe el ciclo Actuar → Evaluar → Recordar → Adaptar, plantea fascinantes paralelos con la autorreflexión y el aprendizaje humano.
Vimal Dwarampudi argumenta que esta memoria no es meramente un almacenamiento de datos, sino la base de una posible auto-conciencia y autorreflexión en las máquinas. Si un agente puede aprender de sus errores, corregir sus propias acciones y adaptar sus estrategias para futuras situaciones, ¿no estamos viendo los primeros brotes de una forma elemental de inteligencia? Esta línea de pensamiento eleva la discusión desde la optimización de un producto de software a la exploración de las fronteras de la cognición artificial.
Sin embargo, este nuevo poder viene acompañado de riesgos significativos que deben ser cuidadosamente gestionados. La misma capacidad para aprender y adaptar puede ser explotada. Uno de los mayores peligros es el envenenamiento del contexto (context poisoning), donde la información falsa o maliciosa se introduce intencionadamente en el «libro de apuntes» del agente para corromper su razonamiento y manipular su comportamiento. Esto podría tener consecuencias graves en aplicaciones críticas, como la gestión de infraestructuras o la toma de decisiones financieras.
La filtración de prompts (prompt leakage), donde el agente revela detalles sensibles de su entrenamiento o configuración interna, también es una preocupación de seguridad importante. Además, existe el riesgo de que los agentes desarrollen sesgos contextuales profundos y difíciles de detectar, aprendiendo y perpetuando patrones discriminatorios de la información con la que interactúan. La opacidad inherente de los modelos de lenguaje (‘caja negra’) se agrava cuando el comportamiento del agente se origina en un contexto complejo y en evolución que ni los desarrolladores ni los usuarios pueden seguir fácilmente.
Para abordar estos desafíos, es imperativo desarrollar marcos robustos de gobernanza y salvaguardas. Esto incluye la implementación de controles de acceso basados en roles (RBAC) para proteger el contexto del agente, validación exhaustiva de todas las entradas para prevenir ataques de inyección y sistemas de auditoría transparentes que puedan rastrear el origen de las decisiones del agente. La responsabilidad también es un tema delicado. Si un agente autónomo, mejorado por ACE, toma una decisión perjudicial, ¿quién es responsable: el desarrollador que creó el marco, la organización que lo desplegó, o el propio agente? Esta es una pregunta legal y ética compleja que la sociedad aún no ha respondido adecuadamente.
En conclusión, el marco ACE representa un hito tecnológico de primer orden. Nos acerca a sistemas de IA más inteligentes y autónomos que nunca. Pero también nos sitúa en una encrucijada moral. La responsabilidad recae sobre nosotros, como creadores y usuarios de esta tecnología, garantizar que la auto-mejora de la IA sea guiada por principios de seguridad, transparencia y responsabilidad. La capacidad de crear memorias que aprenden es una bendición y una maldición; su destino final dependerá de nuestra sabiduría para construir un futuro en el que la tecnología sirva a la humanidad de una manera segura y ética.
Referencias
Zhang, Q., Hu, C., Upasani, S., Ma, B., Hong, F., Kamanuru, V., Rainton, J., Wu, C., Ji, M., Li, H., Thakker, U., Zou, J., & Olukotun, K. (2025). Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models. arXiv preprint arXiv:2510.04618.
Suzgun, M., Yuksekgonul, M., Bianchi, F., Jurafsky, D., & Zou, J. (2025). Dynamic Cheatsheet: Test-time learning with adaptive memory. arXiv preprint arXiv:2504.07952.
Trivedi, H., Khot, T., Hartmann, M., Manku, R., Dong, V., Li, E., Gupta, S., Sabharwal, A., & Balasubramanian, N. (2024). AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. arXiv preprint arXiv:2407.18901.
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., et al. (2025). GEPA: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457.
Dwarampudi, V. (2025). The Memory That Learns: Toward Self-Reflective AI. Personal communication.
Xu, W., Mei, K., Gao, H., Tan, J., Liang, Z., & Zhang, Y. (2025). A-MEM: Agentic memory for LLM agents. arXiv preprint arXiv:2502.12110.
Khot, T., Trivedi, H., Finlayson, M., Fu, Y., Richardson, K., Clark, P., & Sabharwal, A. (2022). Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406.
Wang, Z. Z., Mao, J., Fried, D., & Neubig, G. (2024). Agent workflow memory. arXiv preprint arXiv:2409.07429.
Jiang, M., Ruan, Y., Lastras, L., Kapanipathi, P., & Hashimoto, T. (2025). Putting it all into context: Simplifying agents with LCLMs. arXiv preprint arXiv:2505.08120.

