
En el horizonte de la innovación tecnológica, pocas ideas han capturado la imaginación colectiva con tanta fuerza como la de una inteligencia artificial verdaderamente autónoma. No nos referimos a los asistentes digitales que hoy responden a nuestras órdenes con creciente precisión, ni a los algoritmos que recomiendan nuestra próxima película.
Hablamos de una nueva forma de inteligencia, una entidad digital capaz de aprender por sí misma, de adaptarse a entornos desconocidos y de resolver problemas complejos con una creatividad y una resiliencia que, hasta ahora, parecían ser dominio exclusivo de la cognición humana. El objetivo último, susurrado en los laboratorios de investigación más avanzados del mundo, es crear sistemas que puedan mejorar a través de su propia experiencia, superando eventualmente las capacidades de sus creadores en tareas de gran complejidad en el mundo real.
Este sueño, sin embargo, se ha enfrentado durante años a un obstáculo monumental, una especie de dilema filosófico y técnico que ha frenado el avance hacia la autonomía genuina. La inteligencia artificial, en su estado actual, aprende principalmente de dos maneras, cada una con sus profundas limitaciones.
Por un lado, tenemos el aprendizaje supervisado, un método análogo a un estudiante que memoriza las soluciones exactas de su maestro. Estos sistemas son entrenados con vastos conjuntos de datos de demostraciones de expertos, aprendiendo a imitar el comportamiento humano a la perfección. Son excelentes para replicar lo que se les ha enseñado, pero frágiles e ineficaces cuando se enfrentan a un escenario imprevisto. Su conocimiento es profundo pero estrecho, como un erudito que conoce un solo libro a la perfección pero es incapaz de leer cualquier otro.
En el otro extremo del espectro se encuentra el aprendizaje por refuerzo, un paradigma que evoca la imagen de un explorador incansable que aprende sobre el mundo a través del ensayo y el error. A estos sistemas no se les dice qué hacer, sino que se les da un objetivo y se les recompensa o penaliza en función de sus acciones. A través de innumerables intentos, la máquina puede descubrir estrategias sorprendentemente eficaces. Sin embargo, este proceso es a menudo desesperadamente ineficiente.
En entornos complejos, como navegar por la vasta e impredecible internet o utilizar una nueva aplicación de software, el número de posibles acciones es casi infinito, y un sistema que aprende desde cero podría tardar una eternidad en lograr algo útil, si es que lo logra. La falta de una recompensa clara y verificable en muchas tareas del mundo real complica aún más este enfoque.
Este es el gran desafío que ha mantenido a las inteligencias artificiales más avanzadas en una especie de adolescencia perpetua: son capaces de realizar proezas asombrosas bajo supervisión, pero carecen de la capacidad de crecer y madurar por sí mismas.
Ahora, un trabajo de investigación revolucionario, surgido de los prestigiosos Meta Superintelligence Labs y FAIR at Meta, en colaboración con la Universidad Estatal de Ohio, propone una solución elegante y poderosa.
Un nuevo paradigma que se sitúa a medio camino entre la imitación y la exploración, y que podría ser la clave para desbloquear la siguiente etapa de la evolución de la IA. Lo han llamado «experiencia temprana», un concepto que, en esencia, propone dotar a las máquinas de algo parecido a una infancia.
La idea central es sorprendentemente intuitiva. En lugar de alimentar a los agentes de IA exclusivamente con ejemplos perfectos de expertos o dejarlos explorar el mundo sin ninguna guía, los investigadores proponen un período de aprendizaje basado en la propia interacción del agente con su entorno.
Permiten que el sistema «juegue» en su mundo digital, que intente realizar tareas, que cometa errores y que, en ocasiones, tenga éxito. Esta experiencia, aunque imperfecta y a menudo torpe, es increíblemente rica y diversa. Genera un volumen de datos de aprendizaje que sería imposible de recopilar a través de demostraciones humanas. Es a través de este torrente de experiencias personales que el agente comienza a construir una comprensión fundamental de su mundo, no a través de reglas explícitas, sino de una intuición profunda forjada en la práctica.
Este proceso se ve potenciado por dos mecanismos cognitivos de gran sofisticación. El primero es la construcción de un modelo implícito del mundo. Al interactuar repetidamente con un sistema, el agente comienza a internalizar sus reglas y dinámicas.
Aprende que ciertas acciones conducen a ciertos resultados, desarrollando una comprensión de causa y efecto que es fundamental para la planificación y la resolución de problemas. El segundo mecanismo es la autorreflexión. El sistema no solo actúa, sino que también tiene la capacidad de analizar sus propias acciones pasadas, identificar dónde se equivocó, reconocer estrategias exitosas y aprender de su propia historia. Es un proceso análogo al de un diario personal, a través del cual el agente refina continuamente su comportamiento.
Este artículo se sumergirá en las profundidades de esta investigación pionera. Exploraremos el dilema del aprendizaje que ha definido el campo de la IA durante décadas, desentrañaremos el funcionamiento de la experiencia temprana y sus mecanismos subyacentes, y analizaremos los asombrosos resultados que demuestran un salto cualitativo en la autonomía de los agentes inteligentes.
Finalmente, reflexionaremos sobre las profundas implicaciones de este trabajo, que no solo representa un avance tecnológico, sino un cambio fundamental en nuestra forma de concebir la creación de inteligencia, acercándonos un paso más al amanecer de las máquinas verdaderamente autónomas.
El dilema del aprendizaje: entre la imitación y la exploración
Para comprender la magnitud del avance que supone la experiencia temprana, es crucial profundizar en las dos filosofías de aprendizaje que han dominado el desarrollo de la inteligencia artificial hasta la fecha. Cada una de ellas encarna un enfoque distinto sobre cómo una entidad, ya sea biológica o artificial, puede adquirir conocimiento y habilidades. Y cada una, a su manera, ha resultado ser insuficiente para alcanzar el objetivo de una autonomía general y robusta.
El primer pilar es el aprendizaje supervisado, y más específicamente, el ajuste fino supervisado. Este método ha sido el motor detrás de muchos de los éxitos más visibles de la IA en los últimos años, desde los grandes modelos de lenguaje que pueden escribir poesía hasta los sistemas de reconocimiento de imágenes que superan la precisión humana.
La metodología es conceptualmente sencilla: se recopila un vasto corpus de datos de alta calidad, curado y etiquetado por expertos humanos, y se utiliza para entrenar un modelo de IA. En el contexto de los agentes autónomos, esto se traduce en «clonación de comportamiento». Los investigadores registran a expertos humanos realizando tareas complejas, como reservar un vuelo en una página web o gestionar un proyecto utilizando varias herramientas de software. Cada clic, cada pulsación de tecla, cada decisión se convierte en un dato de entrenamiento.
El agente de IA estudia estas miles de demostraciones y aprende a imitar las acciones del experto en cada paso.
Podemos imaginarlo como un aprendiz de chef al que se le entrega un libro con las recetas de un maestro cocinero. El aprendiz estudia cada receta meticulosamente, memorizando las cantidades exactas de cada ingrediente, los tiempos de cocción precisos y la técnica de emplatado. Si se le pide que prepare un plato del libro y se le proporcionan todos los ingredientes y utensilios necesarios, es muy probable que produzca una réplica perfecta.
El resultado es impecable. Sin embargo, este método de aprendizaje tiene una fragilidad inherente. ¿Qué ocurre si un ingrediente no está disponible? ¿O si el horno funciona de manera ligeramente diferente al de la receta? El aprendiz, que solo sabe imitar, se queda paralizado. No posee una comprensión fundamental de la cocina, no entiende por qué ciertos ingredientes combinan bien o cómo el calor transforma los alimentos. No puede improvisar, no puede adaptarse.
Este es el problema de los agentes entrenados exclusivamente mediante la clonación de comportamiento. Generalizan mal. El mundo real es caótico e impredecible; las páginas web cambian su diseño, las aplicaciones se actualizan y surgen problemas inesperados. Un agente entrenado para seguir una ruta fija fracasará en cuanto encuentre una desviación.
Además, la creación de estos conjuntos de datos de expertos es un proceso arduo, lento y extremadamente costoso. Escalar este enfoque para cubrir la inmensa diversidad de tareas y entornos que un agente verdaderamente útil debería manejar es, sencillamente, inviable. La dependencia de datos de expertos condena a estos sistemas a un conocimiento que siempre será limitado y, a menudo, obsoleto.
Frente a la rigidez de la imitación, el aprendizaje por refuerzo ofrece una visión radicalmente diferente: el aprendizaje a través de la experiencia directa. Este paradigma se inspira en la psicología conductista y es la forma en que los seres vivos aprenden a navegar por su entorno. Un agente de aprendizaje por refuerzo se lanza a un entorno sin un conocimiento previo explícito de cómo realizar una tarea. Su único objetivo es maximizar una «señal de recompensa». Realiza acciones, observa los resultados y, si una acción lo acerca a su objetivo, recibe una recompensa positiva; si lo aleja, una penalización.
Pensemos ahora en un cocinero que aprende desde cero, sin recetas. Entra en una cocina llena de ingredientes y empieza a experimentar. Mezcla harina y agua, y obtiene una pasta insípida. Lo considera un resultado negativo. Luego, prueba a añadir sal y levadura, y a meter la mezcla en el horno. El resultado es un pan delicioso, una gran recompensa.
A través de miles de estos experimentos, algunos desastrosos y otros exitosos, el cocinero podría llegar a descubrir los principios fundamentales de la panadería e incluso inventar sus propias recetas. Este es el poder del aprendizaje por refuerzo: la capacidad de descubrir soluciones novedosas y óptimas que quizás ningún experto humano había considerado.
Sin embargo, su aplicación práctica en el dominio de los agentes de lenguaje complejos es extraordinariamente difícil. El primer problema es la «escasez de la recompensa». En una tarea de varios pasos, como organizar un viaje completo, la recompensa final (el viaje reservado con éxito) solo llega después de una larga secuencia de acciones. La mayoría de las acciones intermedias no tienen una recompensa inmediata, lo que hace muy difícil para el agente saber si está en el camino correcto. Es como intentar encontrar un tesoro en una isla gigantesca con una brújula que solo apunta al norte cuando estás a un metro del cofre.
El segundo problema es la «ineficiencia de la muestra». El espacio de posibles acciones en entornos digitales es astronómico. Un agente que explora al azar tardaría un tiempo impracticable en tropezar con una secuencia de acciones útil. Esta exploración ineficiente no solo consume una cantidad masiva de recursos computacionales, sino que también puede ser arriesgada en entornos reales. La disyuntiva entre explorar nuevas acciones para encontrar mejores estrategias y explotar las estrategias ya conocidas que garantizan una cierta recompensa es uno de los desafíos centrales del campo.
Así, la inteligencia artificial se encontraba atrapada. La imitación produce agentes competentes pero frágiles, incapaces de generalizar. La exploración pura puede llevar a una inteligencia superior, pero a un coste computacional y temporal prohibitivo en la mayoría de los escenarios prácticos. Se necesitaba un nuevo camino, una síntesis que combinara la eficiencia de aprender de ejemplos con la robustez de la experiencia directa.
Un método que permitiera a los agentes aprender como lo hacen los humanos: no solo copiando a los maestros o explorando a ciegas, sino a través de un período de práctica, de juego, de cometer errores y aprender de ellos en un entorno de bajo riesgo. Se necesitaba una infancia artificial.
La experiencia temprana: una infancia para las máquinas
La propuesta central del equipo de Meta es tan elegante como rompedora. En lugar de ver los datos imperfectos como ruido que debe ser filtrado, los reconocen como la fuente de aprendizaje más rica y escalable disponible. El paradigma de la experiencia temprana se basa en la idea de que la propia interacción de un agente novato con su entorno, con todos sus errores, callejones sin salida y éxitos fortuitos, constituye el material de entrenamiento ideal para forjar una inteligencia verdaderamente adaptable.
El proceso comienza con un modelo de lenguaje base, una IA que tiene una comprensión general del lenguaje pero que no ha sido entrenada específicamente para actuar en un entorno concreto. A este modelo se le dota de una capacidad de acción rudimentaria y se le «suelta» en un entorno digital, como una colección de páginas web o aplicaciones de software. Se le dan tareas para que intente completarlas. Es importante destacar que, en esta fase, el agente no es un experto. Su política de acción es imperfecta.
A menudo tomará decisiones subóptimas, hará clic en enlaces incorrectos, se perderá en menús complejos o no utilizará las herramientas de la manera más eficiente. En esencia, se le permite «balbucear» digitalmente.
Esta fase de interacción genera un volumen de datos colosal. Cada intento, ya sea un éxito o un fracaso, se registra como una «trayectoria»: una secuencia completa de observaciones, acciones y resultados.
A diferencia de los datos de expertos, que por definición solo muestran trayectorias exitosas y eficientes, este nuevo conjunto de datos, al que llamaremos el «diario de experiencias», es increíblemente diverso. Contiene ejemplos de lo que funciona, pero, lo que es más importante, contiene innumerables ejemplos de lo que no funciona. Muestra al agente perdiéndose y luego encontrando el camino de vuelta, intentando una acción que falla y luego probando otra que tiene éxito.
Aquí es donde reside la primera genialidad del enfoque. Un fracaso no es simplemente un resultado negativo; es una lección invaluable. Para un sistema de aprendizaje, entender por qué un camino determinado conduce a un error es tan importante como saber cuál es el camino correcto.
Pensemos en un niño aprendiendo a construir una torre con bloques. Intenta poner un bloque grande sobre uno pequeño y la torre se derrumba. Esta experiencia le enseña una lección fundamental sobre la gravedad y la estabilidad. Si solo viera ejemplos de torres perfectamente construidas, nunca internalizaría estos principios físicos subyacentes. De la misma manera, un agente de IA que solo ve demostraciones de expertos nunca aprende a recuperarse de un error, una habilidad que es absolutamente crítica para la autonomía en el mundo real.
Una vez que se ha generado este masivo diario de experiencias, el siguiente paso es refinarlo. No todas las experiencias son igualmente instructivas. El sistema utiliza varios métodos para filtrar y ponderar estas trayectorias. Por ejemplo, las trayectorias que finalmente llevaron al éxito de la tarea, incluso si lo hicieron de una manera ineficiente, son etiquetadas como positivas.
El agente puede aprender de la secuencia completa, incluyendo los pasos en falso iniciales que finalmente fueron corregidos. Se utilizan técnicas sofisticadas para identificar las decisiones cruciales dentro de una trayectoria y para inferir los objetivos intermedios que el agente podría haber estado persiguiendo.
Con este conjunto de datos masivo y refinado, que consiste en las propias experiencias del agente, se procede a entrenar el modelo. Se utiliza una técnica similar al ajuste fino supervisado, pero con una diferencia fundamental: el «supervisor» no es un experto humano, sino la propia experiencia pasada y reflexionada del agente. El sistema aprende a replicar sus propios comportamientos exitosos y, crucialmente, a evitar las secuencias de acciones que lo llevaron al fracaso.
Debido a que el conjunto de datos de experiencia temprana es órdenes de magnitud más grande y más diverso que cualquier conjunto de datos de expertos, el agente resultante es mucho más robusto.
Este proceso de generar experiencia y luego aprender de ella se puede repetir en un ciclo virtuoso. Un agente entrenado con la primera ronda de experiencia temprana será más competente que el modelo base inicial. Este agente mejorado puede entonces ser desplegado de nuevo para generar un segundo diario de experiencias, que será de mayor calidad y cubrirá escenarios aún más complejos. Al iterar este proceso, el agente se va puliendo a sí mismo, mejorando progresivamente su rendimiento en un ciclo de autoaprendizaje que tiene el potencial de escalar a niveles de competencia sobrehumanos.
La belleza de este paradigma es que resuelve simultáneamente las deficiencias de los dos enfoques anteriores. Supera la fragilidad y el coste del aprendizaje por imitación al generar sus propios datos de entrenamiento, que son abundantes, baratos y diversos. Al mismo tiempo, elude la ineficiencia del aprendizaje por refuerzo puro al estructurar el proceso de aprendizaje de una manera más guiada.
En lugar de una exploración completamente aleatoria, el agente aprende de trayectorias completas y coherentes, lo que le permite asimilar patrones de comportamiento complejos de manera mucho más eficiente. Es un término medio que aprovecha lo mejor de ambos mundos, proporcionando un camino práctico y escalable hacia la autonomía.

Construyendo un modelo del mundo y la conciencia de sí
La eficacia del paradigma de la experiencia temprana no reside únicamente en la generación masiva de datos, sino en dos procesos cognitivos computacionales que emergen de esta interacción intensiva con el entorno. Estos mecanismos, el modelo implícito del mundo y la autorreflexión, son los que permiten al agente trascender la simple imitación de sus propias acciones exitosas y desarrollar una comprensión más profunda y generalizable, una especie de sentido común digital.
El primer concepto, el modelo implícito del mundo, se refiere a la capacidad del agente para desarrollar una comprensión intuitiva de las reglas y la dinámica del entorno con el que interactúa. En los enfoques tradicionales, a un agente se le podría dar un «modelo explícito» del mundo, un conjunto de reglas codificadas que describen cómo funciona todo.
Sin embargo, estos modelos son frágiles y difíciles de crear para entornos complejos como internet. La experiencia temprana fomenta algo mucho más poderoso. Al realizar millones de acciones y observar sus resultados, el agente comienza a internalizar patrones y relaciones de causa y efecto.
No aprende la regla abstracta «hacer clic en un botón con una etiqueta de ‘siguiente’ generalmente lleva a la siguiente página de un formulario». En cambio, después de haber hecho clic en miles de botones de «siguiente» en innumerables contextos diferentes y haber observado el resultado, la red neuronal del agente ajusta sus pesos para que la acción de hacer clic en ese tipo de botón se asocie fuertemente con la consecuencia deseada. Este conocimiento no está codificado en una línea de lógica, sino distribuido a través de la arquitectura del modelo. Es implícito.
Esta comprensión implícita es mucho más robusta que un conjunto de reglas rígidas. Permite al agente generalizar a situaciones nuevas. Si se encuentra con un botón de «continuar» que nunca ha visto antes, pero que comparte características visuales y contextuales con los botones de «siguiente» que ha experimentado, su modelo implícito del mundo le permitirá predecir con alta probabilidad que realizar esa acción lo hará avanzar.
Está aprendiendo los «conceptos» del mundo digital, no solo los ejemplos específicos. Este es el salto de la memorización a la comprensión. A través de la experiencia temprana, el agente aprende la «física» de las interfaces de usuario, la «gramática» de las interacciones web, la «lógica» de las herramientas de software.
El segundo mecanismo, y quizás el más fascinante, es la autorreflexión. Este proceso dota al agente de una capacidad metacognitiva: la habilidad de pensar sobre su propio pensamiento, o en este caso, sobre sus propias acciones. Una vez que una trayectoria ha sido completada, el sistema no la archiva simplemente como un dato más. Puede volver a analizarla, evaluarla y extraer lecciones de ella.
El proceso de autorreflexión puede adoptar varias formas. Una de las más poderosas es el análisis de errores. El modelo puede examinar una trayectoria fallida e intentar identificar el punto exacto en el que se tomó la decisión equivocada. Al comparar esta trayectoria con otras similares que sí tuvieron éxito, puede aislar la acción crítica que marcó la diferencia.
A continuación, el agente puede generar una reflexión en lenguaje natural, algo así como: «En el paso 5, hice clic en ‘cancelar’ en lugar de ‘aceptar’, lo que terminó la sesión prematuramente. La próxima vez, en un diálogo de confirmación similar, debería buscar y seleccionar la opción afirmativa para continuar con el proceso». Esta reflexión se convierte en una valiosa pieza de información que puede ser utilizada en el futuro entrenamiento, enseñando al modelo a evitar errores específicos.
La autorreflexión también funciona para los éxitos. Un agente puede completar una tarea, pero de una manera muy ineficiente. Al reflexionar sobre su trayectoria, puede identificar bucles, acciones redundantes o caminos más cortos que podría haber tomado. Podría generar una crítica como: «Completé la tarea, pero tuve que volver a la página de inicio tres veces.
Podría haber guardado la URL directa de la sección de perfil en el paso 2 para navegar allí directamente en los pasos posteriores, ahorrando tiempo y acciones». Este tipo de optimización a través de la reflexión es lo que permite que el rendimiento del agente mejore no solo en términos de éxito o fracaso, sino también en términos de eficiencia y elegancia.
Estos dos mecanismos trabajan en simbiosis. El modelo implícito del mundo proporciona al agente la intuición básica para actuar en el entorno, mientras que la autorreflexión le proporciona un mecanismo de alto nivel para analizar y refinar estratégicamente su comportamiento. Es la combinación de la práctica masiva y el análisis deliberado lo que impulsa el rápido y robusto aprendizaje. La experiencia temprana no es solo un método para generar datos; es un marco para cultivar una forma de inteligencia que aprende, comprende y se corrige a sí misma, sentando las bases para una autonomía mucho más sofisticada y fiable.
Los resultados hablan: un salto cuántico en la autonomía
Toda teoría, por elegante que sea, debe finalmente enfrentarse a la prueba de la realidad empírica. El valor del paradigma de la experiencia temprana se mide, en última instancia, por su capacidad para producir agentes que superen a los creados con métodos anteriores. Y los resultados presentados en el estudio son, sin ambages, espectaculares. El equipo de investigación sometió a sus agentes a una batería de pruebas de referencia diseñadas para evaluar la capacidad de la IA para realizar tareas complejas en entornos digitales realistas.
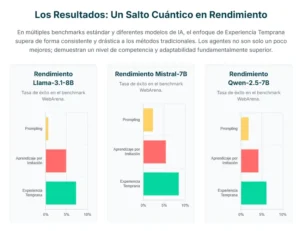
Una de las pruebas clave fue WebArena, un exigente campo de batalla que requiere que los agentes naveguen por sitios web reales y funcionales para realizar tareas como comprar productos, gestionar reservas o encontrar información específica. Estos entornos son dinámicos y están diseñados para reflejar la complejidad y la imprevisibilidad de la web real, lo que los convierte en un examen formidable para la capacidad de generalización de un agente. Otra prueba fue ToolBench, que evalúa la habilidad de un agente para utilizar una amplia gama de herramientas de software y API, una habilidad crucial para cualquier asistente digital avanzado.
Los investigadores compararon el rendimiento de varios de los modelos de lenguaje más avanzados, como Mistral-7B, Qwen-2.5-7B y Llama-3.1-8B, entrenados con diferentes metodologías. Los resultados se presentaron como tasas de éxito en la finalización de las tareas. La primera línea de base fue el «prompting», que consiste en dar al modelo base instrucciones detalladas en lenguaje natural sobre cómo realizar la tarea, sin ningún entrenamiento adicional. La segunda fue la «clonación de comportamiento», el método tradicional de aprendizaje por imitación a partir de demostraciones de expertos. La tercera, por supuesto, fue la «experiencia temprana», incluyendo sus variantes que incorporan el modelo del mundo implícito y la autorreflexión.
Los datos mostraron una tendencia abrumadora y consistente en todas las pruebas y todos los modelos. Los agentes entrenados con experiencia temprana superaron de manera significativa a sus homólogos.
En tareas donde los agentes basados en la imitación apenas lograban tasas de éxito de un solo dígito, los agentes de experiencia temprana a menudo alcanzaban puntuaciones varias veces superiores. La mejora no fue marginal; representó un salto cualitativo en la competencia. Esto demuestra que la riqueza y diversidad de la experiencia autogenerada proporciona una base de aprendizaje muy superior a la de los datos de expertos, por muy alta que sea su calidad.
Quizás el hallazgo más impactante es la eficiencia del método. El estudio demuestra que modelos de lenguaje relativamente pequeños, con 7 u 8 mil millones de parámetros, cuando se entrenan con experiencia temprana, pueden alcanzar o incluso superar el rendimiento de modelos mucho más grandes y computacionalmente costosos. Esto tiene implicaciones profundas para el futuro de la inteligencia artificial. Significa que no es necesario construir modelos cada vez más gigantescos para lograr un rendimiento superior.
Un mejor método de entrenamiento, uno que fomente una comprensión más profunda en lugar de la memorización superficial, puede ser mucho más eficaz. La experiencia temprana democratiza el acceso a la IA de alto rendimiento, haciéndola más accesible y sostenible desde el punto de vista computacional y energético.
El hecho de que la mejora se observara de manera consistente en diferentes arquitecturas de modelos (Mistral, Qwen, Llama) también es de vital importancia. Demuestra que la experiencia temprana no es un truco que solo funciona para un modelo específico, sino un principio de aprendizaje fundamental y generalizable. Es un avance a nivel de paradigma, no solo a nivel de implementación.
En esencia, los resultados validan la hipótesis central de la investigación: la experiencia imperfecta pero masiva es un maestro mucho más eficaz que la instrucción perfecta pero limitada. Los números no mienten. Los agentes que han pasado por una «infancia» de exploración, error y reflexión no solo son más competentes, sino fundamentalmente más inteligentes. Han desarrollado la resiliencia y la capacidad de adaptación necesarias para operar en el desordenado e impredecible mundo digital, marcando un hito en la larga búsqueda de la autonomía artificial.

Reflexiones finales: el amanecer de los agentes autónomos
El trabajo sobre el aprendizaje de agentes a través de la experiencia temprana es mucho más que un simple avance incremental en el campo de la inteligencia artificial. Representa un cambio de perspectiva, una nueva forma de pensar sobre cómo podemos construir y cultivar la inteligencia en las máquinas. Nos aleja de la metáfora de la IA como una herramienta que se programa y nos acerca a la de la IA como una entidad que se educa. Las implicaciones de este cambio son profundas y se extienden a los ámbitos científico, tecnológico y social.
Desde una perspectiva científica, este estudio ofrece una solución elegante al prolongado debate entre los paradigmas de imitación y exploración. Al crear un puente práctico y escalable entre el aprendizaje supervisado y el aprendizaje por refuerzo, abre una nueva y prometedora vía de investigación. Desplaza el foco de la ingeniería de datos, la costosa curación de conjuntos de datos de expertos, hacia la ingeniería de entornos de aprendizaje.
El desafío ya no es solo cómo enseñar a la máquina, sino cómo crear los «patios de recreo» digitales y los currículos de experiencia que permitan a las máquinas aprender por sí mismas de la manera más eficiente y segura posible. Este enfoque se asemeja mucho más a los principios de la psicología del desarrollo y la pedagogía que a la informática tradicional, lo que sugiere una futura y fructífera convergencia de disciplinas.
Tecnológicamente, las consecuencias son inmensas y se materializarán en un futuro próximo. Estamos en la cúspide de una nueva generación de asistentes de IA y herramientas de automatización. Olvidemos los asistentes actuales, que en su mayoría se limitan a ejecutar comandos específicos. Imaginemos un agente autónomo entrenado mediante experiencia temprana.
Sería un colaborador digital capaz de aprender a utilizar cualquier nueva pieza de software simplemente interactuando con ella, sin necesidad de una API o una integración específica. Podríamos pedirle que «investigue las mejores opciones de viaje para unas vacaciones familiares en Italia y prepare un itinerario detallado», y el agente podría navegar por docenas de sitios web de aerolíneas, hoteles y reseñas, sintetizar la información y presentar un plan completo. Podría gestionar flujos de trabajo complejos que abarcan múltiples aplicaciones, actuando como un verdadero empleado digital que aprende y mejora con el tiempo. Esto podría desencadenar un aumento de la productividad sin precedentes y democratizar el acceso a habilidades digitales complejas para todos.
Sin embargo, este amanecer de la autonomía también proyecta sombras que debemos considerar con seriedad y previsión. La relevancia social de esta tecnología es dual. Por un lado, la promesa es deslumbrante: la automatización de tareas tediosas podría liberar el potencial humano para centrarse en la creatividad, la estrategia y la interacción humana. Las herramientas de software complejas podrían volverse accesibles para personas sin formación técnica, guiadas por agentes inteligentes. La investigación científica podría acelerarse drásticamente con agentes capaces de llevar a cabo experimentos digitales y analizar datos a una escala masiva.
Por otro lado, la proliferación de agentes cada vez más autónomos y capaces plantea interrogantes éticos y sociales urgentes. La cuestión del desplazamiento de puestos de trabajo se vuelve más aguda.
La necesidad de establecer barreras de seguridad robustas para evitar que estos agentes se utilicen con fines maliciosos o causen daños no intencionados es primordial. A medida que los agentes se vuelven capaces de aprender y actuar de forma independiente, ¿cómo garantizamos que sus objetivos permanezcan alineados con los valores humanos? El campo de la seguridad y el alineamiento de la IA, que ya es de vital importancia, se convierte en una prioridad absoluta.
El trabajo de los investigadores de Meta no nos ha entregado la inteligencia artificial general, pero nos ha proporcionado una de las piezas más importantes del rompecabezas hasta la fecha. La experiencia temprana es la clave que podría permitir que los sistemas de IA salgan del laboratorio y empiecen a operar de forma útil y fiable en el complejo y dinámico mundo real. Nos encontramos en un momento decisivo en la historia de la tecnología.
La era de programar máquinas podría estar dando paso a la era de criarlas. El viaje será, sin duda, desafiante y requerirá una cuidadosa navegación técnica y ética, pero el destino, un futuro en el que la inteligencia humana se vea aumentada y expandida por colaboradores artificiales verdaderamente capaces, parece hoy mucho más cercano.
Referencias bibliográficas
Zhang, K., Chen, X., Liu, B., Xue, T., Liao, Z., Liu, Z., Wang, X., Ning, Y., Chen, Z., Fu, X., Xie, J., Sun, Y., Gou, B., Qi, Q., Meng, Z., Yang, J., Zhang, N., Li, X., Shah, A., Huynh, D., Li, H., Yang, Z., Cao, S., Jang, L., Zhou, S., Zhu, J., Sun, H., Weston, J., Su, Y., & Wu, Y. (2025). Agent Learning via Early Experience. arXiv:2510.08558 [cs.AI].

