
En el vertiginoso mundo de la inteligencia artificial, una idea se había instalado con la fuerza de un dogma: para resolver los problemas más enrevesados, las máquinas necesitaban «pensar más». Este principio, aparentemente intuitivo, dio origen a una carrera por crear modelos de lenguaje capaces de generar cadenas de pensamiento extraordinariamente largas y complejas. La imagen era poderosa: una IA que, ante un problema matemático de alta competición o un enigma científico, se sumergía en un monólogo interior digital de miles de palabras, explorando ángulos, verificando sus pasos y revisando sus cálculos antes de ofrecer una respuesta. Era la metáfora del genio torturado, del pensador incansable que llena pizarras de ecuaciones hasta dar con la solución. Sin embargo, un nuevo y revolucionario estudio, publicado hace apenas unas horas desde los prestigiosos Meta Superintelligence Labs en colaboración con la Universidad de Nueva York, ha hecho añicos esta creencia. El trabajo, titulado «¿Qué caracteriza a un razonamiento eficaz?», no solo cuestiona la narrativa de que «más largo es mejor», sino que demuestra con una contundencia abrumadora todo lo contrario: en el universo de la lógica artificial, los caminos más cortos, directos y con menos tropiezos son casi siempre los que conducen a la respuesta correcta.
Este estudio, liderado por la investigadora Yunzhen Feng, representa un cambio de paradigma en nuestra comprensión de cómo «piensan» las máquinas. Lejos de ser una simple optimización técnica, sus hallazgos nos obligan a replantearnos qué valoramos en el razonamiento, tanto humano como artificial. Durante años, la comunidad científica había observado que alargar el proceso de pensamiento de una IA, a menudo forzándola a generar más texto o a revisar sus pasos anteriores, parecía mejorar sus resultados. Esta técnica, que en la jerga se conoce como «escalado en tiempo de prueba», se convirtió en un estándar de la industria. Pero los resultados eran inconsistentes y, a veces, contradictorios. Algunos estudios sugerían que pensar demasiado podía llevar a las máquinas a un ciclo de dudas y a un rendimiento oscilante. Faltaba una investigación sistemática y a gran escala que arrojara luz sobre esta confusión. El equipo de Meta ha llenado ese vacío analizando diez de los modelos de razonamiento más avanzados del mundo, desde el Claude 3.7 de Anthropic hasta la familia Qwen 3 y el Grok de xAI, enfrentándolos a miles de problemas de matemáticas y ciencias de nivel experto.
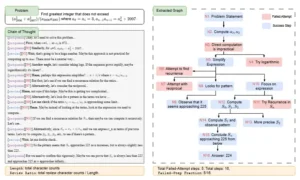
Para desentrañar el misterio, los investigadores introdujeron una forma novedosa de analizar el monólogo interior de las IA, conocido como «Cadena de Pensamiento» o CoT (Chain-of-Thought). En lugar de simplemente medir su longitud o contar cuántas veces el modelo decía «déjame revisar», decidieron visualizar la estructura lógica de ese pensamiento como un grafo, un mapa de nodos y conexiones similar a un árbol genealógico de ideas. Esta perspectiva les permitió ir más allá de las métricas superficiales y cuantificar la verdadera eficiencia del proceso de razonamiento. Fue así como descubrieron una métrica sorprendentemente simple pero increíblemente poderosa: la Fracción de Pasos Fallidos o FSF (Failed-Step Fraction). Este indicador mide, dentro de todo el proceso de pensamiento, qué proporción corresponde a callejones sin salida, a ramas de razonamiento que fueron exploradas y finalmente abandonadas.
Lo que Feng y su equipo encontraron fue una correlación negativa casi universal y estadísticamente robusta. A través de todos los modelos y tipos de problemas, cuanto menor era la fracción de pasos fallidos, mayor era la probabilidad de que la respuesta final fuera correcta. La longitud de la cadena de pensamiento y la cantidad de revisiones, por el contrario, mostraron una correlación negativa con el acierto. En otras palabras, los razonamientos más eficaces no eran los más largos ni los más meticulosos en sus revisiones, sino los más directos y certeros. Eran aquellos que cometían menos errores en el camino. Este hallazgo es profundo porque sugiere que las IA más competentes no son las que mejor se corrigen a sí mismas, sino las que menos necesitan hacerlo.
Pero el estudio no se detuvo en la correlación. Para probar una relación causal, los científicos realizaron dos intervenciones ingeniosas. Primero, para cada problema, generaron múltiples intentos de solución de una misma IA. Luego, en lugar de elegir una al azar, seleccionaron la respuesta final basándose en la que tenía la menor Fracción de Pasos Fallidos. El resultado fue un aumento drástico y consistente en la tasa de aciertos, de hasta un 10% en problemas matemáticos de alta dificultad. La segunda intervención fue aún más audaz: tomaron un razonamiento que había llegado a una conclusión incorrecta y, como un cirujano digital, editaron su «memoria», eliminando las ramas de pensamiento fallidas que había explorado. Al pedirle a la IA que continuara desde ese punto «limpio», la probabilidad de que llegara a la respuesta correcta se disparaba significativamente. Esto prueba algo fundamental: los errores pasados, incluso si son descartados, dejan una especie de «sesgo cognitivo» en la IA que contamina su razonamiento posterior. Este artículo explorará en detalle la metodología, las implicaciones y el profundo significado de estos hallazgos, que no solo nos enseñan a construir mejores inteligencias artificiales, sino que también nos invitan a reflexionar sobre la naturaleza de nuestro propio pensamiento.
La tiranía de la longitud y el mito de la revisión
La intuición humana a menudo equipara el esfuerzo con el resultado. Un estudiante que pasa más horas estudiando o un científico que revisa sus cálculos una y otra vez nos parece, a priori, más propenso al éxito. Durante los últimos años, esta misma lógica se aplicó al desarrollo de los grandes modelos de razonamiento (LRMs). La estrategia predominante, popularizada por estudios como S1, consistía en aumentar el «tiempo de cómputo en prueba», es decir, el esfuerzo que la máquina dedica a un problema antes de responder. La forma más sencilla de lograrlo era appending «tokens de espera», pequeñas instrucciones que animaban al modelo a seguir generando texto, a alargar su cadena de pensamiento y a revisar sus pasos previos. La premisa era que este tiempo adicional permitiría a la IA explorar más posibilidades, detectar errores y refinar sus conclusiones. Los primeros resultados parecían prometedores, y la industria adoptó la narrativa de que «pensar más largo es pensar mejor».
Sin embargo, como un eco lejano, empezaron a surgir dudas y resultados contradictorios. Algunos investigadores notaron que suprimir esos tokens de espera podía preservar la precisión reduciendo drásticamente la longitud. Otros observaron que añadir «espera» indefinidamente podía llevar a un rendimiento errático. El trabajo de Yunzhen Feng y su equipo aborda esta controversia de frente, llevando a cabo la evaluación más sistemática realizada hasta la fecha. Analizaron casi 8.000 cadenas de pensamiento generadas por diez modelos de IA de última generación en dos conjuntos de problemas notoriamente difíciles: HARP, un compendio de problemas de competiciones matemáticas de Estados Unidos, y GPQA-Diamond, una colección de preguntas científicas a nivel de posgrado.
Para evitar conclusiones erróneas, los investigadores emplearon una metodología estadística rigurosa. Sabían que las correlaciones simples podían ser engañosas. Por ejemplo, los problemas más difíciles naturalmente requieren razonamientos más largos y tienen una tasa de acierto menor, lo que podría crear una falsa correlación negativa entre longitud y éxito. Para aislar el efecto real, generaron 16 cadenas de pensamiento para cada pregunta y realizaron un análisis de correlación condicional. Esta técnica les permitió comparar los 16 intentos para un mismo problema, eliminando la dificultad de la pregunta como factor de confusión. En esencia, se preguntaron: para un mismo desafío, ¿los intentos más largos o los más cortos tienen más probabilidades de ser correctos?
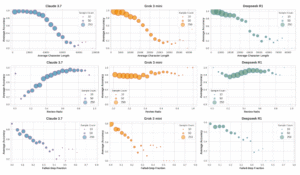
Los resultados fueron claros y consistentes a través de la gran mayoría de los modelos y en ambos dominios. Una vez controlado el factor de la dificultad, las cadenas de pensamiento más cortas estaban asociadas con una mayor probabilidad de acierto. El mismo patrón se observó para el comportamiento de revisión. Para medirlo de forma aislada, definieron la «Tasa de Revisión» como la fracción de texto dedicada a verificar, chequear o reformular pasos anteriores. De nuevo, una menor tasa de revisión se correlacionaba con un mayor éxito. La única excepción notable fue el modelo Claude 3.7 en problemas matemáticos, que parecía beneficiarse de una mayor revisión, un comportamiento estilístico que lo diferencia del resto.
Estos hallazgos invitan a una reflexión profunda sobre la naturaleza del razonamiento artificial. La idea de que una IA se beneficia de un proceso largo y lleno de auto-correcciones podría ser una simple proyección de nuestros propios procesos cognitivos. Los humanos, falibles y con memoria limitada, necesitamos revisar y verificar constantemente. Una inteligencia artificial, sin embargo, opera de manera diferente. Su «pensamiento» es una secuencia generativa, un camino probabilístico a través de un vasto espacio de conocimiento. Un razonamiento largo y con muchas revisiones no es necesariamente una señal de diligencia, sino que puede ser un síntoma de incertidumbre. Indica que el modelo no encontró un camino claro y directo hacia la solución y tuvo que recurrir a la exploración extensiva y a la corrección, procesos que, como demostrarían más adelante, están plagados de peligros. La eficacia, por tanto, no parece residir en la capacidad de enmendar un camino tortuoso, sino en la habilidad de trazar una línea recta desde el principio.
El mapa del pensamiento: más allá de las palabras
Si medir la longitud o la revisión de un texto es como juzgar un viaje por los kilómetros recorridos, el siguiente paso del equipo de Meta fue trazar el mapa de ese viaje. Se plantearon la hipótesis de que las métricas basadas en el recuento de palabras eran solo indicadores superficiales de una propiedad estructural más profunda del razonamiento. Para probarlo, desarrollaron un método para convertir cada cadena de pensamiento en un grafo de razonamiento. Este grafo es una representación visual de la estructura lógica del pensamiento, donde cada «paso» de razonamiento se convierte en un nodo y las dependencias lógicas entre ellos en conexiones. Un paso que lleva a otro se representa con una flecha. Si un paso lleva a explorar tres ideas diferentes, se convierte en un nodo con tres ramas.
La genialidad de este enfoque es que permite analizar el «cómo» piensa la IA, no solo el «cuánto». Permite distinguir entre un pensamiento lineal y directo y uno laberíntico y exploratorio. Para extraer estos grafos, los investigadores aprovecharon una habilidad emergente de los modelos de lenguaje modernos. Simplemente le pidieron al modelo Claude 3.7 que convirtiera cada cadena de pensamiento en código Graphviz, un lenguaje estándar para describir grafos. La alta fidelidad con la que los modelos actuales pueden realizar esta tarea, probablemente debido a la gran cantidad de documentación técnica en sus datos de entrenamiento, permitió una extracción precisa y escalable de miles de mapas de pensamiento.
Una vez que tuvieron estos mapas, pudieron definir y medir propiedades estructurales. La más importante de ellas fue la Fracción de Pasos Fallidos (FSF). Al generar el grafo, le pidieron al modelo que coloreara los nodos de dos maneras: azul para los pasos que forman parte del camino exitoso hacia la solución final, y rojo para los pasos que pertenecen a ramas de razonamiento que fueron exploradas pero finalmente abandonadas por considerarse incorrectas o callejones sin salida. La FSF es simplemente la proporción de nodos rojos sobre el total de nodos en el grafo. Es una medida de cuánto «esfuerzo desperdiciado» hubo en el proceso de pensamiento.
Al realizar el mismo análisis de correlación condicional, los resultados fueron aún más contundentes. La Fracción de Pasos Fallidos emergió como el predictor de éxito más fuerte, consistente y fiable de todos. A través de los diez modelos analizados y en ambos dominios de conocimiento (matemáticas y ciencias), una FSF más baja se correlacionaba de manera significativa y negativa con el error. Cuanto más directo y con menos desvíos fallidos era el mapa del pensamiento, mayor era la probabilidad de que la respuesta fuera correcta. Esta métrica superó a la longitud y a la tasa de revisión en consistencia, funcionando incluso para el caso atípico de Claude 3.7. Esto sugiere que el beneficio que Claude obtenía de la revisión no era por la revisión en sí, sino porque su estilo de revisión le permitía identificar y podar ramas fallidas de manera más eficaz.
El descubrimiento de la FSF como un indicador clave es un avance fundamental. Proporciona una nueva forma de evaluar la calidad del razonamiento de una IA que va más allá de la simple corrección de la respuesta final. Permite a los desarrolladores diagnosticar «por qué» un modelo está fallando. Un modelo con una alta tasa de errores pero una baja FSF podría tener un problema de conocimiento fundamental. Por el contrario, un modelo con una alta FSF está demostrando una ineficiencia en su proceso de exploración y una incapacidad para evitar caminos incorrectos. Esta distinción es crucial para mejorar las futuras generaciones de IA, ya que sugiere que el objetivo no debe ser solo entrenar modelos con más datos, sino también enseñarles a razonar de una manera más estructurada y eficiente.
La cirugía del pensamiento: una prueba de causalidad
Las correlaciones, por muy fuertes que sean, no demuestran causalidad. Que los razonamientos con menos pasos fallidos sean más exitosos no prueba necesariamente que los pasos fallidos causen el fracaso. Podría ser que una incapacidad subyacente para resolver el problema sea la causa tanto de los pasos fallidos como de la respuesta incorrecta. Para establecer un vínculo causal, el equipo de investigación diseñó dos experimentos de intervención, dos pruebas ingeniosas que se asemejan a una «cirugía del pensamiento» artificial.
El primer experimento fue una intervención en el momento de la selección de la respuesta. El procedimiento fue el siguiente: para cada problema en un conjunto de desafíos matemáticos de alta dificultad y libres de contaminación (AIME 2025), generaron 64 cadenas de pensamiento diferentes utilizando el mismo modelo de IA. Esto creó un conjunto de 64 posibles respuestas. La pregunta era: ¿cómo elegir la mejor de ellas sin saber la respuesta correcta? Probaron cuatro estrategias de selección:
- Una selección aleatoria, que serviría como línea de base.
- Seleccionar la respuesta del razonamiento más corto.
- Seleccionar la respuesta del razonamiento con la tasa de revisión más baja (o más alta para Claude).
- Seleccionar la respuesta del razonamiento con la Fracción de Pasos Fallidos (FSF) más baja.
Los resultados de esta competición de estrategias fueron reveladores. Aunque seleccionar por longitud y tasa de revisión ofreció una mejora modesta sobre la selección aleatoria, la estrategia basada en la FSF fue la ganadora indiscutible. Elegir el razonamiento con el camino más «limpio» y con menos errores exploratorios produjo las mayores ganancias en la tasa de aciertos para todos los modelos, con mejoras de hasta un 13% en algunos casos. Este experimento proporciona una fuerte evidencia causal. Si una métrica puede ser utilizada de forma fiable para seleccionar las respuestas correctas de un conjunto de candidatas, es porque está capturando una propiedad fundamentalmente ligada a la corrección del razonamiento. Demuestra que la FSF no es solo un síntoma, sino un indicador fiable de la calidad del proceso.
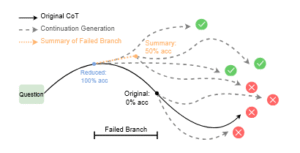
La segunda intervención fue aún más directa y fascinante. Se centraron en las cadenas de pensamiento que habían conducido a una respuesta incorrecta y se preguntaron: ¿el error estaba predestinado o la presencia de ramas fallidas desvió un proceso que de otro modo podría haber sido exitoso? Para responder a esto, realizaron una edición controlada de la cadena de pensamiento. Utilizando el grafo de razonamiento, identificaron el punto exacto donde comenzaba una rama de exploración fallida y la eliminaron por completo, truncando la cadena de pensamiento justo antes de que se cometiera el error. Luego, le pidieron al modelo que continuara razonando desde ese prefijo «saneado».
Los resultados de esta «cirugía» fueron asombrosos. Al eliminar la rama fallida, la probabilidad de que el modelo, en su continuación, llegara a la respuesta correcta aumentaba drásticamente, con mejoras de entre el 8% y el 14%. Esto prueba de manera concluyente que las ramas fallidas no son inocuas. Incluso después de que el modelo las descarta y «retrocede» para probar otro camino, la existencia de ese error en su contexto de pensamiento inmediato actúa como un sesgo, una especie de ancla cognitiva que influye negativamente en la exploración posterior. El modelo no «olvida» completamente sus errores pasados, y estos contaminan su capacidad para encontrar el camino correcto. Eliminar físicamente el error de su «memoria» a corto plazo libera al modelo para que pueda alcanzar su verdadero potencial. Estos dos experimentos, en conjunto, transforman nuestra comprensión del razonamiento artificial, pasando de una visión de correlaciones a una de mecanismos causales claros.
Hacia una ciencia del razonamiento artificial
El estudio «¿Qué caracteriza a un razonamiento eficaz?» es mucho más que una simple comparación de modelos de inteligencia artificial. Es un trabajo fundacional que nos proporciona un nuevo lenguaje y un nuevo conjunto de herramientas para entender la cognición de las máquinas. Al desmantelar el mito de que «pensar más largo es pensar mejor», nos empuja hacia una visión más sofisticada y matizada de la inteligencia, una que valora la eficiencia, la direccionalidad y la limpieza del proceso por encima de la fuerza bruta computacional. La introducción de la Fracción de Pasos Fallidos como una métrica clave es una contribución de un valor incalculable, no solo para los investigadores, sino también para los ingenieros y desarrolladores que trabajan en la primera línea de la implementación de la IA.
La relevancia de estos hallazgos es inmensa. A nivel tecnológico, sugiere un cambio de estrategia en el diseño de futuros sistemas de IA. En lugar de centrarse únicamente en escalar el número de tokens que un modelo puede generar, el enfoque podría desplazarse hacia la «calidad estructural» del pensamiento. Podríamos ver el desarrollo de técnicas de entrenamiento que penalicen la exploración de ramas inútiles o que recompensen la concisión y la direccionalidad. La idea de gestionar activamente el contexto de un modelo, podando o resumiendo las ramas fallidas en tiempo real, emerge como una vía de investigación prometedora para crear sistemas más robustos y fiables.
A nivel social y filosófico, este estudio nos invita a reflexionar sobre nuestra propia inteligencia. La idea de que los errores pasados pueden sesgar el pensamiento futuro, incluso después de ser corregidos, es algo profundamente familiar para la experiencia humana. Este trabajo proporciona una evidencia cuantitativa de un fenómeno análogo en las máquinas, abriendo un nuevo campo de estudio en la «psicología» de la inteligencia artificial. Nos obliga a preguntarnos qué es realmente el razonamiento eficaz. ¿Es la capacidad de explorar un vasto número de posibilidades, como un gran maestro de ajedrez, o es la intuición para identificar el camino correcto casi al instante? Este estudio sugiere que, al menos para las IA actuales, la segunda opción es un indicador mucho más fuerte de competencia.
En última instancia, el trabajo de Yunzhen Feng y sus colegas en Meta marca el comienzo de una verdadera ciencia del razonamiento artificial. Nos aleja de las metáforas antropomórficas y de las métricas superficiales y nos acerca a una comprensión basada en la estructura, los mecanismos y la causalidad. La lección final es clara y poderosa: la inteligencia no se mide por el sudor en la frente, ni siquiera en la frente de silicio de una máquina. Se mide por la elegancia, la eficiencia y la precisión del camino que traza a través de la complejidad. En la búsqueda de la inteligencia, tanto artificial como humana, parece que la brújula más fiable no es la que nos lleva por el viaje más largo, sino la que nos guía para cometer la menor cantidad de errores posible en el camino.
Fuentes
Feng, Y., Kempe, J., Zhang, C., Jain, P., & Hartshorn, A. (2025). What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT. Meta Superintelligence Labs & New York University. arxiv.org/pdf/2509.19284
Muennighoff, N., et al. (2025). s1: Simple test-time scaling.
Jiang, G., et al. (2025). What makes a good reasoning chain? uncovering structural patterns in long chain-of-thought reasoning.
Guo, D., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.
Yue, A. S., et al. (2024). Harp: A challenging human-annotated math reasoning benchmark.

