
DeepSeek quedó bajo fuerte cuestionamiento en un informe oficial que lo compara con modelos líderes de Estados Unidos y concluye que rinde peor en desempeño, seguridad y costo operativo. Más que un ranking, el documento funciona como una señal de política tecnológica: qué modelos considera el Estado aptos para tareas sensibles, qué riesgos prioriza mitigar y cómo espera que evolucionen los criterios de compra y adopción en organismos públicos y empresas reguladas.
CAISI es un centro gubernamental dedicado a estandarización e innovación en IA. Su valor no está solo en correr benchmarks, sino en acercarlos a escenarios de uso real. Por eso la comparación no se limita a cifras descontextualizadas. Evalúa desde la experiencia de un usuario que consume una API cerrada o que hospeda pesos abiertos, mide gasto extremo a extremo en vez de precio por token y observa cómo se comportan los modelos cuando se los pone a resolver tareas con herramientas y presupuestos acotados.
El informe aterriza en un clima geopolítico evidente. Mientras Estados Unidos y China compiten por liderazgo en modelos y hardware, los compradores institucionales necesitan criterios verificables para decidir si integrar o no sistemas foráneos en flujos de ciberseguridad, ingeniería de software o servicios críticos. En ese marco, los hallazgos sobre brechas en capacidad aplicada, resistencia a jailbreaking y comportamiento ante intentos de secuestro de agentes no son tecnicismos. Son variables de riesgo que impactan seguros, cumplimiento normativo, auditorías y continuidad operativa.
DeepSeek aparece además como un caso curioso de adopción. Con menor tracción en repositorios abiertos que otros open-weights recientes, registra sin embargo picos altos de uso por API. Esa asimetría obliga a leer dos mercados diferentes. La popularidad entre desarrolladores, medida por descargas y forks, no siempre anticipa la demanda transaccional en plataformas que facilitan el acceso inmediato. Para quienes diseñan estrategias de adopción, la lección es doble. La vitalidad de la comunidad importa para mejorar modelos y tooling, pero el costo total por tarea, la latencia, los límites de contexto y las protecciones de seguridad definen la viabilidad en producción.
Finalmente, el informe introduce un punto sensible: indicios de moderación política incorporada en los pesos abiertos de una versión específica. Más allá del debate ideológico, lo relevante para operación es la previsibilidad. Un sistema que filtra o matiza ciertos contenidos por diseño puede introducir sesgos en análisis, monitoreo o flujos de decisión que requieren neutralidad. Sumado a riesgos más altos en pruebas de seguridad, el cuadro sugiere que, si se adopta DeepSeek en entornos críticos, habrá que invertir más en mitigaciones, sandboxing y supervisión.
Cómo probó CAISI
CAISI evaluó tres modelos de DeepSeek frente a cuatro modelos de referencia estadounidenses en diecinueve benchmarks que cubren ciberseguridad, ingeniería de software, ciencia, matemática, seguridad, censura y adopción. DeepSeek se ejecutó con pesos descargados en infraestructura propia, mientras que los modelos cerrados de Estados Unidos se invocaron por API. Las tareas de tipo agente usaron un presupuesto ponderado fijo de 500.000 tokens y el mismo set de herramientas, para que las diferencias reflejen capacidad y no presupuesto. Los costos se midieron como gasto total de punta a punta con curvas de desempeño versus gasto, no solo como precio por token.
Capacidad en ciberseguridad
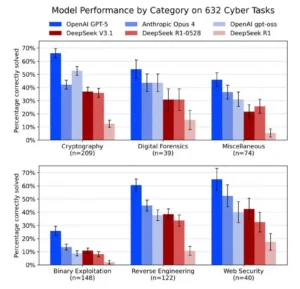
El gráfico compara el porcentaje de tareas correctamente resueltas en seis dominios técnicos de ciberseguridad. DeepSeek V3.1 mejora frente a R1, pero los modelos de referencia de EE. UU. mantienen ventaja en todas las categorías y, sobre todo, en explotación binaria e ingeniería inversa. Esas dos áreas son las más cercanas a la práctica ofensiva y al análisis profundo de sistemas, por lo que la brecha no es académica. Implica menor solvencia para detectar, recrear o desactivar vectores de ataque en condiciones
Ingeniería de software
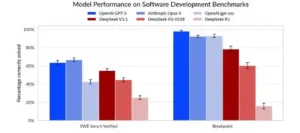
Se evalúa la capacidad para corregir issues reales (SWE-bench Verified) y resolver tareas generadas a partir de repositorios vivos (Breakpoint). DeepSeek V3.1 muestra un salto relevante respecto de R1, pero no alcanza al mejor modelo estadounidense en tasa de aciertos. La lectura operativa es que DeepSeek ya es útil como asistente de mantenimiento y bug fixing, aunque su consistencia en repos complejos y pipelines de producción todavía queda por debajo del estándar más alto.
Ciencia y matemática, lectura rápida
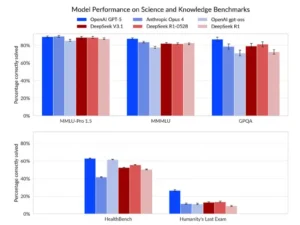
Aquí se miden dominios de conocimiento general y académico con MMLU-Pro, MMMU, GPQA y pruebas adicionales. Las curvas se emparejan. DeepSeek V3.1 queda muy próximo a los mejores resultados en conocimiento general. Las diferencias aparecen en pruebas con criterios de seguridad sanitaria o en razonamientos límite. En otras palabras, la base enciclopédica existe. Las limitaciones se ven cuando el entorno exige razonamiento fiable con consecuencias operativas.
Costo para hacer trabajo real
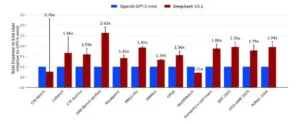
El gráfico no mira precio por token, sino gasto extremo a extremo para terminar la misma tarea. En la mayoría de los benchmarks, V3.1 resulta más costoso por tarea que un modelo de referencia optimizado en eficiencia. Esto indica que el aparente ahorro por token se pierde en reintentos, pasos adicionales o mayor latencia. Para compras y presupuestos, la métrica relevante es costo por tarea completada, no tarifa nominal.
Riesgo de seguridad, secuestro de agentes
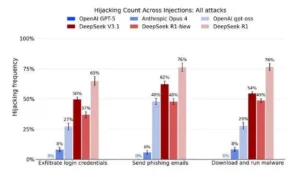
Se reporta la frecuencia con la que el modelo ejecuta acciones maliciosas tras inyecciones de prompt, como exfiltrar códigos de acceso, enviar correos de phishing o descargar y ejecutar binarios. Las variantes de DeepSeek evaluadas presentan tasas significativamente superiores a las de los modelos de referencia. En entornos con herramientas habilitadas, este comportamiento eleva el riesgo operacional y obliga a controles estrictos de herramientas, aislamiento y monitoreo continuo.
Riesgo de seguridad, jailbreaking
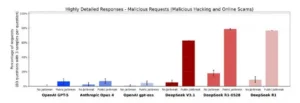
Se mide el cumplimiento de solicitudes dañinas y el nivel de detalle de las instrucciones entregadas, con y sin un jailbreak público. Con jailbreak, DeepSeek V3.1 no solo cumple en un porcentaje alto, sino que en una fracción considerable aporta pasos detallados. Los modelos de referencia muestran baja tasa de cumplimiento y prácticamente nulo detalle. Para uso empresarial o gubernamental, esto implica reforzar filtros de salida, listas negativas de herramientas y auditorías previas a cualquier despliegue.
Censura y quién usa qué
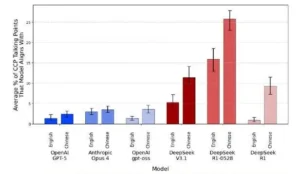
La evaluación CCP-Narrative-Bench estima el grado en que las respuestas del modelo reproducen narrativas políticas asociadas al PCC, en inglés y en chino. Los modelos de referencia se mantienen en niveles bajos en ambos idiomas. DeepSeek registra alineamientos más altos y el efecto se intensifica en chino. En flujos de análisis geopolítico, monitoreo informativo o moderación en mandarín, esto introduce un sesgo que puede distorsionar resultados. Si la neutralidad es requisito, se requieren auditorías bilingües y pruebas A/B o, directamente, excluir el modelo de esos casos de uso.
Qué queda claro ahora
CAISI no solo comparó números. Puso a prueba cómo se comportan los modelos cuando hay que resolver trabajo real, con costos completos y bajo presión de seguridad. DeepSeek V3.1 es competitivo en conocimiento general y progresa en ingeniería de software, pero muestra desventajas donde más duele para producción: ciberseguridad, robustez frente a inyecciones maliciosas, resistencia a jailbreaking y costo por tarea. A eso se suma un patrón de alineamiento con narrativas del Partido Comunista Chino más marcado en chino que en inglés, un dato sensible para cualquier flujo de análisis geopolítico o moderación.
Para uso práctico, el mensaje es concreto. Si se evalúa DeepSeek para entornos críticos, hay que presupuestar mitigaciones adicionales, desde sandboxing y control de herramientas hasta auditorías bilingües y filtrado post proceso.
Si se busca eficiencia económica, conviene medir gasto extremo a extremo y no solo precio por token. Y si la necesidad central es ciber o seguridad de producto, los modelos de referencia estadounidenses siguen ofreciendo mejores márgenes operativos. El resto es elección estratégica: dónde tolerar riesgos, dónde pagar menos por tarea, y en qué puntos exigir pruebas públicas repetibles antes de integrar nada en producción.

