
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
Menos tokens, más cabeza en InternVL 3.5
El equipo de Shanghai AI Lab presentó InternVL 3.5: una familia de modelos multimodales abiertos que mejora el razonamiento y baja la latencia con tres piezas técnicas concretas. La novedad combina refuerzo en cascada, un router de resolución visual y un despliegue desacoplado entre visión y lenguaje. La cuestión es si estas mejoras alcanzan para recortar la brecha con los servicios comerciales sin disparar costos.
Apertura con datos, no promesas
InternVL 3.5 llega con cifras verificables: hasta 16 por ciento de mejora en razonamiento respecto a InternVL 3.0 y una aceleración de inferencia de poco más de cuatro veces gracias al router de resolución visual y a un despliegue que separa el encoder de visión del modelo de lenguaje en GPUs distintas. En MMMU, la versión de 8 mil millones de parámetros anota 73,4 y el modelo tope 241B-A28B llega a 77,7. La serie 3.5 además incorpora un modo de “pensamiento” explícito, capacidades para tareas GUI y un perfil de eficiencia que, si se sostiene en producción, quita excusas a quienes no adoptan multimodalidad por costo.
Lo que cambia en 3.5
InternVL 3.5 representa la nueva iteración de la línea de modelos multimodales de Shanghai AI Lab y OpenGVLab. El salto no está en un “más de lo mismo”, sino en un enfoque de entrenamiento y de servicio que intenta poner la inteligencia multimodal al alcance de equipos con presupuestos medidos. La hipótesis guía es doble. Primero, que un refuerzo en dos etapas puede sumar pasos de razonamiento de manera estable. Segundo, que un enrutador de resolución visual, más un despliegue desacoplado, reduce tokens, latencia y uso de hardware sin degradar calidad. La pregunta operativa: ¿qué parte de estas ganancias se sostiene fuera del paper y con datos ruidosos?
Antecedentes y marco
La familia InternVL viene escalando desde 2023 con una brújula clara: visión fuerte, multimodalidad real y apertura. InternVL 2.5, en diciembre de 2024, fue la primera abierta en superar 70 por ciento en MMMU con recetas de escalado en entrenamiento y en inferencia. En abril de 2025, InternVL 3.0 consolidó preentrenamiento nativo multimodal y fijó 72,2 en MMMU con el tamaño 78B, además de reforzar OCR, tablas y video. Llega InternVL 3.5 con tres novedades: refuerzo en cascada para razonar mejor, un router de resolución visual que comprime donde puede y mantiene detalle donde importa, y un despliegue desacoplado para exprimir el hardware disponible. El tablero competitivo se mueve: los abiertos incorporan agentes y herramientas, mientras los cerrados siguen liderando producto. InternVL 3.5 intenta achicar esa brecha con ingeniería y números.
Cómo funciona
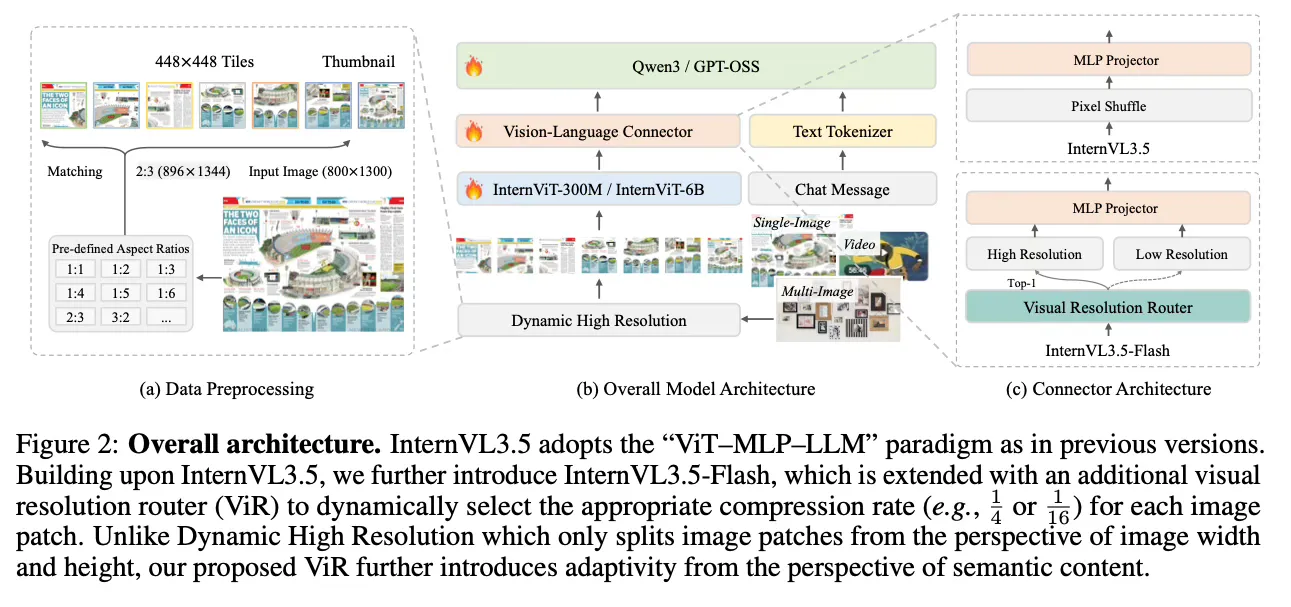
Tres bloques sostienen el salto
Cascade RL. En lugar de un único tramo de aprendizaje por refuerzo, la serie 3.5 alterna dos fases. La primera es un refuerzo offline que estabiliza y lleva a un buen punto de partida. La segunda es un refuerzo online que ajusta la distribución de salida y empuja el tope de rendimiento en razonamiento multimodal. La idea es simple: calentar motores con datos curados y luego afinar sobre la marcha, evitando inestabilidades típicas cuando se escala el RL en modelos grandes.
Visual Resolution Router y ViCO. La variante Flash introduce un enrutador que decide, para cada parche visual, cuántos tokens usar según la “riqueza semántica”. Donde hay poco que ganar, comprime agresivamente; donde hay detalle crítico, mantiene resolución. Para que la compresión no rompa consistencia, entra en juego un entrenamiento de consistencia visual que alinea respuestas entre resoluciones. Resultado buscado: menos tokens, casi el mismo rendimiento.
Decoupled Vision–Language Deployment. La inferencia separa el encoder de visión del LLM en GPUs distintas y optimiza el prefilling. Se procesan imágenes en lote y se envían embeddings compactos al subsistema de lenguaje. Este desacople habilita paralelismo real y mejor uso de clusters heterogéneos. El beneficio se siente en latencia y en costo por consulta.
Detalles de arquitectura. La familia sigue el patrón ViT más proyector más LLM, con InternViT como encoder visual y LLMs base de la serie Qwen/GPT-OSS. La ventana de contexto llega a 32K. Hay checkpoints intermedios por etapa de entrenamiento, útiles para investigación, ablations y auditoría.
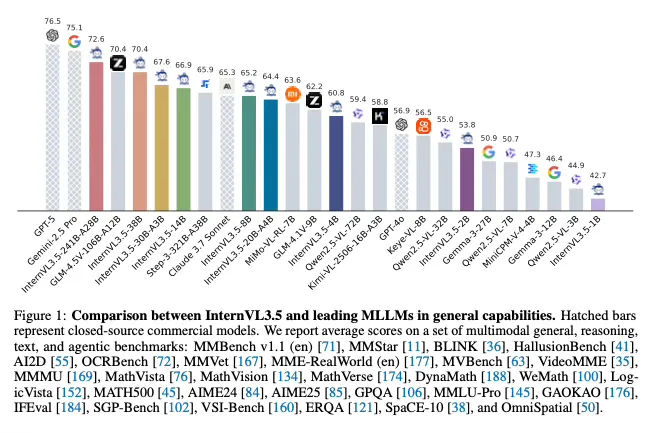
Comparaciones (benchmarks)
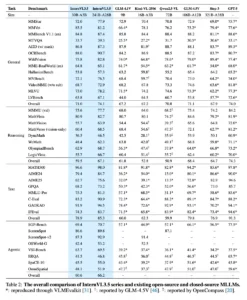
El equipo reporta hasta 16 por ciento de mejora en “razonamiento general” frente a InternVL 3.0 y un speed-up de 4,05 veces en inferencia combinando el router de resolución y el despliegue desacoplado. Son dos métricas que importan porque atacan el cuello de botella del mundo real: cuánto cuesta servir un flujo multimodal complejo y qué tan robusto es el razonamiento fuera de tareas triviales.
MMMU y otros. La serie 3.5 marca 73,4 con el tamaño 8B y 77,7 con 241B-A28B. La 3.0 había anotado 72,2 en MMMU con 78B. La mejora es consistente y favorece también a escalas medias, clave para despliegues costo-sensibles. En tareas de matemáticas y lógica, el paper muestra saltos de dos dígitos sobre la 3.0. En SGP-Bench, centrado en SVG, y en pruebas de GUI y embodied, la 3.5 mantiene competitividad o lidera entre abiertas.
Entre los abiertos de referencia aparecen Qwen2.5-VL y Step-3, orientados a eficiencia y cobertura, más propuestas recientes que comprimen tokens visuales. La diferencia de InternVL 3.5 está en combinar tres palancas a la vez: refuerzo más estable, compresión dinámica por parche y despliegue desacoplado. En cerrados, el análisis del paper sugiere que la brecha promedio multimodal frente a los tope de gama actuales se achicó. Hay que tomar esa lectura con prudencia: mezclar baterías dispares siempre tiene margen de interpretación.
Trade-offs. El router ahorra tokens, pero añade complejidad de entrenamiento y de serving. El RL en cascada promete estabilidad, pero suma pasos y riesgos de “hacking” de la recompensa si el diseño del verificador y del feedback no es cuidadoso. El DvD baja latencias, aunque requiere orquestación y perfiles de hardware más afinados. El mensaje central es de ingeniería: la calidad crece cuando cada pieza hace su parte sin arruinar el presupuesto.
Voces y fuentes
El paper de InternVL 3.5 describe el pipeline, las ablations y el detalle del Cascade RL, además de enumerar benchmarks y resultados con fechas. La tarjeta de modelo en Hugging Face documenta escalas, licencias y la variante Flash con su entrenamiento de consistencia visual. La publicación de InternVL 3.0 ofrece la línea base de abril y contextualiza los números. Como material complementario, el análisis de la comunidad aporta una lectura de alto nivel útil para entender ángulos de adopción y límites metodológicos.
La síntesis que vale para equipos técnicos y de producto es directa: hay código, hay pesos y hay guías de despliegue. Eso habilita verificación independiente y comparativas costo-calidad que trascienden los gráficos del paper.
Impactos por sector
- Educación. Tutores y evaluadores multimodales que leen PDFs, diagramas y hojas de ejercicios pueden ganar velocidad real con Flash y DvD. Si la reducción de tokens se sostiene sin pérdida de calidad, se habilita corrección más barata de exámenes con imágenes, análisis de apuntes fotografiados y soporte para laboratorios virtuales con gráficos y tablas. La ventana extendida de contexto ayuda a procesar cuadernillos largos sin trocear.
- Salud. En OCR clínico, placas con texto incrustado, curvas y formularios, un MLLM más rápido con razonamiento robusto aporta. La apertura de pesos y etapas facilita auditoría, algo esencial en entornos regulados. El despliegue on-prem reduce superficies de exposición de datos. Reglas de sanidad digital y validaciones clínicas siguen siendo condición de entrada, pero el costo por consulta baja y eso cambia el ROI.
- Economía y empresas. Procesos comunes como clasificación de documentos, lectura de remitos, control de calidad visual en planta y extracción de datos de manuales técnicos se benefician de menos tokens y de GPUs separadas por función. En tamaños 8B a 14B, la ecuación precio-prestación ya es atractiva para back-office. La variante tope 241B no es barata de servir, pero cumple rol de referencia y de laboratorio.
- Ética y política pública. Un modelo abierto con checkpoints por etapa de entrenamiento permite auditorías con lupa. Al mismo tiempo, amplía responsabilidad: un modelo que “piensa” más pasos necesita verificación externa en decisiones sensibles y trazabilidad de cómo llegó a la respuesta. Para pilotos gubernamentales, la apertura habilita soberanía tecnológica y escrutinio, siempre que las políticas de datos y de seguridad acompañen.
Controversias y vacíos
Heterogeneidad de benchmarks. El promedio “overall” combina conjuntos con criterios y distribuciones distintas. Puede ocultar debilidades puntuales. Replicar en escenarios ruidosos importa tanto como subir un punto en tablas.
Estabilidad de RL. El esquema en cascada busca robustez, pero la literatura muestra que el refuerzo puede optimizar señales imperfectas de calidad. Diseñar bien la función de verificación y vigilar la deriva de estilo es tan importante como subir el score.
Estado de Flash y guías. La promesa de “50 por ciento menos tokens con rendimiento casi idéntico” es atractiva. La confirmación llegará cuando la implementación y los pesos específicos de la variante Flash estén plenamente disponibles y probados en producción. Si la reproducibilidad falla, el ahorro se diluye.
Infraestructura y orquestación. DvD alivia cuellos, pero exige una capa de servicio más sofisticada. No es plug and play. Requiere perfiles de lote, prefetch y colas elásticas. Donde no hay cultura de observabilidad, aparecerán problemas de colas frías y de saturación en el encoder de visión.
Escenarios
Corto plazo, de uno a tres meses. Adopción de 3.5-Instruct en flujos con documentos largos y capturas de pantalla. Pruebas A/B de ViR frente a compresión fija. Primeras integraciones de DvD en clusters mixtos con foco en prefilling y en lotes de imágenes. Supuesto: guías y pesos de las variantes 8B y 14B maduros y reproducibles.
Mediano plazo, de tres a nueve meses. Aparición de forks que integren ViR y consistencia visual en pipelines propios. Tablas de costo-calidad para OCR, tablas y multipágina. Evaluaciones sistemáticas de agentes GUI con benchmarks como ScreenSpot y OSWorld-G. Supuesto: la promesa “50 por ciento menos tokens con rendimiento casi igual” se sostiene en más de un dominio.
Largo plazo, de nueve a dieciocho meses. Convergencia hacia MLLMs abiertos con rutas adaptativas de inferencia y refuerzo estabilizado. Si se publican trazas del modo de pensamiento, la comunidad podrá depurar sesgos y mejorar verificabilidad ex-post. Supuesto: continuidad del modelo de apertura de InternVL y guías de despliegue que eviten dependencia de hardware exótico.
Ética y regulación
Transparencia y trazabilidad. Abrir pesos y etapas intermedias permite auditar el aporte de cada fase del pipeline. Es recomendable registrar prompts de sistema del modo de pensamiento, decisiones del router de resolución y rutas de despliegue. Sin trazas, no hay explicabilidad práctica.
Privacidad por diseño. El despliegue on-prem y el desacople reducen exposición, pero las memorias de contexto extensas obligan a políticas de minimización y borrado. En sectores regulados, conviene realizar evaluaciones de impacto algorítmico y someter cambios de política de inferencia a revisión.
Seguridad y agentes. En GUI y embodied, más razonamiento implica más superficie de riesgo. Mínimos razonables: permisos granulares, sandboxing, verificación externa en decisiones de alto impacto y listas de herramientas con controles por defecto. Modelo abierto no equivale a modelo sin guardas.
InternVL 3.5 se sostiene en números
La mejora llega por cirugía de entrenamiento y de servicio: refuerzo en cascada para pensar mejor y dos llaves de eficiencia para servir más rápido. Si los números se sostienen en producción, la familia se vuelve opción seria para documentos, tablas, pantallas y tareas con contexto largo. Quedan tareas: validar la estabilidad del refuerzo, medir robustez fuera de laboratorio y comprobar el ahorro real de tokens en la variante Flash. Si esas tres piezas encajan, la distancia con los cerrados ya no será una barrera psicológica sino una elección de producto.
Recuadros
-
Glosario
-
Cascade RL. Esquema de refuerzo en dos etapas, una offline para estabilizar y otra online para afinar la distribución de salida.
-
ViR. Enrutador que decide cuántos tokens usar por parche según contenido, con compresión agresiva donde no hay detalle crítico.
-
ViCO. Entrenamiento de consistencia visual que alinea el comportamiento entre resoluciones y habilita la variante Flash.
-
DvD. Despliegue desacoplado que separa encoder visual y modelo de lenguaje en GPUs distintas para bajar latencia.
-
Thinking mode. Configuración de inferencia que induce cadenas explícitas de razonamiento.
-
MMMU. Benchmark de razonamiento multimodal de dominio amplio usado como referencia de progreso.
-
-
Métricas y benchmarks (lista compacta)
-
Razonamiento general. Hasta +16,0 por ciento frente a InternVL 3.0. Fecha: 25/08/2025. Fuente: paper InternVL 3.5.
-
Velocidad de inferencia. 4,05 veces respecto a InternVL 3.0 combinando ViR y DvD. Fecha: 25/08/2025. Fuente: paper InternVL 3.5.
-
MMMU. 73,4 (InternVL 3.5-8B) y 77,7 (InternVL 3.5-241B-A28B). Fecha: 25/08/2025. Fuente: paper InternVL 3.5.
-
Línea base. InternVL 3.0-78B con 72,2 en MMMU. Fecha: 14/04/2025. Fuente: paper InternVL 3.0.
-
Flash. 50 por ciento menos tokens visuales con rendimiento casi idéntico a 3.5 estándar. Estado de publicación: en despliegue progresivo. Fuente: tarjeta de modelo. [No verificado la fecha exacta de liberación de todos los pesos de Flash.]
-
Fuentes
-
InternVL 3.5. “Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency” (arXiv, 25/08/2025). https://arxiv.org/abs/2508.18265

