
El universo de la inteligencia artificial generativa, en particular el de los modelos capaces de conjurar imágenes a partir de descripciones textuales, se ha expandido a una velocidad vertiginosa. Lo que hace tan solo unos años parecía una fantasía de ciencia ficción, hoy es una herramienta común, utilizada por artistas, diseñadores, publicistas y curiosos en todo el mundo. Hemos sido testigos de una auténtica revolución visual, en la que autómatas programados con algoritmos de aprendizaje profundo son capaces de plasmar en lienzos digitales cualquier idea, por descabellada que parezca. De la simple instrucción de «un gato astronauta flotando en el espacio» a la compleja solicitud de «un retrato de estilo renacentista de un cíborg con una armadura dorada», la capacidad de estos sistemas para traducir el lenguaje en imágenes ha superado las expectativas más optimistas.
Pero en medio de este torrente de creatividad sintética, ha surgido una pregunta fundamental: ¿cómo medimos el progreso real de estas inteligencias? Durante mucho tiempo, la evaluación se ha centrado en métricas estéticas y técnicas, como la fotorealidad, la fidelidad de los colores o la composición. Se buscaba una imagen que se viera bien, que fuera convincente. Pero el acto de generar una imagen no es solo un ejercicio de estética; es, sobre todo, una prueba de comprensión. Un modelo puede dibujar una manzana con un realismo impecable, pero ¿entiende realmente lo que es una manzana? ¿Y qué sucede cuando la instrucción requiere un conocimiento que trasciende el arte? ¿Qué pasa si el texto de partida exige conceptos de física, de biología, de historia o de filosofía?
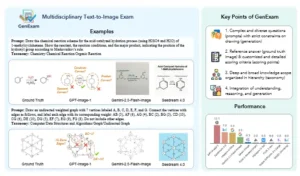
Es en este contexto que la aparición de un trabajo como «GenExam: A Multidisciplinary Text-to-Image Exam» no es solo relevante, sino crucial. Este estudio propone una nueva forma de pensar la evaluación de los modelos de inteligencia artificial generativa, desplazando el foco de la mera habilidad plástica a la profundidad conceptual. Los investigadores detrás de este fascinante proyecto han diseñado un examen, una prueba de fuego, que no se limita a poner a prueba la creatividad, sino la verdadera comprensión multidisciplinaria de los algoritmos. Imaginen un examen de admisión a la universidad para una inteligencia artificial, con preguntas que van desde la bioquímica hasta la historia del arte, pasando por la literatura y la astrofísica. Eso es, en esencia, este sistema de evaluación. Es una herramienta que nos permite discernir si un modelo es un mero artista que imita lo que ha visto, o un pensador capaz de sintetizar ideas complejas en una imagen coherente y precisa.
En este artículo, exploraremos en detalle los conceptos detrás de esta innovadora propuesta. Analizaremos por qué las evaluaciones existentes se quedan cortas, desglosaremos la estructura de GenExam y su metodología, y reflexionaremos sobre las profundas implicaciones que este trabajo tiene para el futuro de la inteligencia artificial. Desde la forma en que entrenamos a estos sistemas hasta cómo interactuamos con ellos, este nuevo enfoque promete cambiar las reglas del juego.
El dilema de la evaluación: más allá de lo visual
Tradicionalmente, la evaluación del rendimiento de los modelos de inteligencia artificial de texto a imagen se ha basado en métricas que, si bien son objetivas y cuantificables, no siempre capturan la complejidad de la tarea. La métrica de Distancia de Incepción (FID, por sus siglas en inglés) o la Métrica de Similitud de Contraste y Lenguaje (CLIP, por sus siglas en inglés) han sido herramientas estándar. La primera evalúa la calidad y la diversidad de las imágenes generadas, comparándolas con imágenes del mundo real. La segunda, en cambio, mide la coherencia entre el texto de entrada y la imagen resultante.
Estas métricas han sido fundamentales para el desarrollo de la disciplina. Gracias a ellas, los investigadores han podido entrenar modelos más grandes y sofisticados, capaces de producir imágenes con un realismo asombroso. Sin embargo, su limitación intrínseca radica en que se centran en la forma, no en el fondo. Un modelo podría obtener una puntuación alta en FID y CLIP si produce imágenes que se parecen mucho a las fotos reales, incluso si el contenido de esas imágenes es conceptualmente incorrecto. Un ejemplo de ello sería un sistema que, al recibir la instrucción de «un motor de combustión interna», genera una imagen fotográfica y estéticamente atractiva, pero que en realidad no representa los componentes y el funcionamiento correctos de un motor. La imagen es bella, pero su contenido es un error.
El desafío, entonces, no es solo que la máquina sepa «dibujar», sino que entienda lo que dibuja. No se trata solo de la habilidad de replicar patrones visuales, sino de la capacidad de sintetizar información de múltiples fuentes y disciplinas. La creatividad humana, la que ha producido las grandes obras de arte y los avances científicos, es intrínsecamente interdisciplinaria. Un artista puede inspirarse en la física para crear una escultura, un biólogo puede utilizar la ilustración para explicar un proceso microscópico, y un filósofo puede recurrir a una metáfora visual para transmitir una idea compleja. Esta es la brecha que las métricas tradicionales no han logrado cerrar. Un modelo de inteligencia artificial que se limita a replicar patrones de su vasto conjunto de datos sin una comprensión conceptual de los mismos es, en el fondo, un loro visual, capaz de imitar, pero no de innovar o razonar.
GenExam: la prueba de fuego
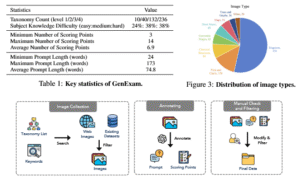
Frente a esta carencia, el trabajo sobre GenExam se alza como un faro. Los autores del estudio, conscientes de las limitaciones del sistema de evaluación vigente, propusieron una solución radicalmente distinta: un examen que fuerza a los modelos a ir más allá de la mera estética. No es un solo conjunto de datos, sino un compendio de preguntas formuladas por expertos en una amplia variedad de campos del conocimiento. Los investigadores colaboraron con profesionales de distintas áreas para crear un banco de pruebas que abarcase desde las ciencias duras hasta las humanidades.
El examen se divide en categorías temáticas. Por ejemplo, en el área de la biología, un modelo podría recibir la instrucción «ilustra el ciclo de vida de una mariposa». Para responder correctamente, la inteligencia artificial no solo debe ser capaz de dibujar una mariposa, sino que debe entender las distintas etapas de su metamorfosis y representarlas de manera secuencial y precisa. Un simple error en la cronología de las etapas o la omisión de alguna de ellas resultaría en una calificación deficiente, sin importar cuán hermosas sean las imágenes individuales. . Otro ejemplo podría ser una pregunta de física: «dibuja un péndulo simple en su punto más alto de oscilación, con vectores que muestren las fuerzas de gravedad y tensión». Aquí, el modelo debe demostrar no solo su capacidad para representar objetos físicos, sino también su conocimiento de conceptos abstractos y vectoriales, un desafío que va mucho más allá de la mera estética. .
En el ámbito de las humanidades, los desafíos son igualmente complejos. Un prompt podría ser «representa el concepto del mito de Sísifo». Esto requiere que el modelo no solo conozca el mito en sí, sino que sea capaz de destilar su esencia y convertirla en una imagen simbólica. La respuesta no se puede encontrar simplemente replicando una foto existente; debe ser una creación conceptual. De manera similar, una pregunta como «ilustra la teoría de la relatividad de Einstein» obliga a la inteligencia artificial a sintetizar una de las ideas más profundas de la física del siglo XX en una imagen visualmente coherente.
La evaluación de las respuestas de los modelos de inteligencia artificial no se realiza con algoritmos, sino con juicios humanos. Los investigadores reunieron a un panel de expertos, cada uno especializado en una de las disciplinas del examen, para calificar las imágenes generadas. Este enfoque cualitativo y subjetivo es fundamental para capturar la verdadera complejidad del desafío. Los expertos no solo evalúan si la imagen se ve bien, sino si es conceptualmente correcta, si responde adecuadamente al prompt y si demuestra una comprensión genuina de la pregunta subyacente. Los resultados de esta calificación humana se combinan para crear una puntuación global que refleja, de una manera mucho más precisa, la inteligencia y la capacidad de los modelos para razonar y sintetizar.

La mecánica del análisis y las revelaciones inesperadas
Para llevar a cabo su estudio, los creadores de GenExam aplicaron su innovador examen a una selección de los modelos de inteligencia artificial de texto a imagen más prominentes del momento. Los resultados, según el reporte, fueron reveladores. El análisis detallado de las respuestas de los diferentes sistemas de IA puso de manifiesto que, si bien todos los competidores eran capaces de generar imágenes de una calidad visual impresionante, su rendimiento conceptual variaba drásticamente de un modelo a otro.
Los modelos que se habían hecho famosos por su habilidad para crear imágenes fotorrealistas con gran detalle, como aquellas que se utilizan en la industria del cine o la publicidad, tendieron a fracasar en las pruebas de ciencias. Aunque sus representaciones de la fauna, la flora o los paisajes eran de una fidelidad admirable, mostraban graves deficiencias a la hora de ilustrar conceptos abstractos o procesos biológicos y físicos. Por ejemplo, la representación de un ciclo de Krebs o de la tabla periódica de los elementos podía ser un revoltijo de colores y formas sin una estructura química o lógica subyacente. Sus respuestas eran, en esencia, una representación superficial, una mímica de lo visual que no estaba respaldada por una verdadera comprensión del tema.
Por otro lado, los modelos que quizás no eran tan conocidos por su capacidad de generar imágenes de calidad fotorrealista, pero que tenían una arquitectura de procesamiento del lenguaje más sofisticada, sorprendieron por su desempeño en los desafíos intelectuales. Estos sistemas demostraron una habilidad notable para conectar ideas, sintetizar información compleja y producir imágenes que, aunque tal vez no fueran tan pulidas visualmente, eran conceptualmente correctas. Sus ilustraciones de conceptos de filosofía o sus representaciones de procesos geológicos o astronómicos eran mucho más precisas.
Esta dicotomía entre la destreza visual y la comprensión conceptual pone de manifiesto una verdad fundamental sobre el estado actual de la inteligencia artificial. Gran parte del desarrollo se ha centrado en optimizar la salida estética, en la búsqueda de la imagen perfecta. Pero el informe de GenExam nos recuerda que la verdadera meta debe ser la inteligencia en su sentido más amplio. La capacidad de un modelo de IA para ser una herramienta verdaderamente útil en campos como la investigación científica, la educación o la innovación, no dependerá solo de su talento para la representación, sino de su habilidad para entender y sintetizar el conocimiento de la forma más precisa.
El estudio también reveló inconsistencias dentro de un mismo modelo. Por ejemplo, algunos sistemas que sobresalían en el ámbito de la literatura y el arte, al interpretar metáforas y simbolismos, tropezaban estrepitosamente cuando se les pedían tareas de matemáticas o ingeniería. Esto sugiere que las redes neuronales, a pesar de su inmensidad, aún tienen un conocimiento fragmentado y poco unificado. Los modelos más avanzados son capaces de aprender y almacenar patrones de información, pero la capacidad de transferir ese conocimiento de un dominio a otro, una de las características distintivas de la inteligencia humana, es una habilidad que todavía no han dominado por completo.
Los investigadores concluyeron que el problema no es la falta de datos, sino la forma en que se estructuran esos datos y la manera en que los modelos son entrenados. No basta con exponer a la inteligencia artificial a billones de imágenes y textos. Es necesario que los conjuntos de datos de entrenamiento sean curados de manera más inteligente, con un enfoque en la conexión entre diferentes disciplinas y la comprensión de los conceptos subyacentes.
El futuro: una IA más sabia, no solo más bonita
El trabajo de GenExam trasciende la mera curiosidad académica. Su impacto se siente de manera directa en la forma en que pensamos y construimos la inteligencia artificial del futuro. Las conclusiones del estudio tienen implicaciones profundas tanto para el desarrollo tecnológico como para la sociedad en general.
En el ámbito de la educación, el potencial es inmenso. Pensemos en una herramienta de aprendizaje que no solo puede generar ilustraciones de alta calidad para un libro de texto, sino que además entiende los conceptos que está ilustrando. Un estudiante de medicina podría solicitar «muéstrame una representación del sistema circulatorio que muestre el flujo de sangre desde el corazón hasta los pulmones» y recibir no solo una imagen de alta calidad, sino una que es conceptual y anatómicamente correcta. Un profesor de historia podría pedir «ilustra el impacto de la revolución industrial en la sociedad victoriana» y el sistema generaría una imagen que capture los elementos esenciales del tema, como la urbanización, el trabajo infantil o la tecnología del vapor. La inteligencia artificial podría convertirse en un tutor visual, un compañero que no solo responde a las preguntas, sino que ayuda a visualizar ideas complejas.
En la investigación científica, el potencial es igualmente transformador. Los científicos podrían utilizar modelos de IA para visualizar datos complejos, para ilustrar teorías o para generar hipótesis visuales de difícil conceptualización. Un físico teórico podría pedir «muestra la geometría del espacio-tiempo alrededor de un agujero negro» y el modelo podría generar una imagen que, aunque abstracta, sea científicamente coherente. La inteligencia artificial dejaría de ser un mero software de diseño para convertirse en una herramienta de descubrimiento, capaz de acelerar la creatividad y el razonamiento en los campos de la investigación.
La propuesta de esta herramienta también nos obliga a repensar la interacción entre humanos y máquinas. Si bien la facilidad de uso y la calidad visual de los modelos actuales son impresionantes, la capacidad de una IA de comprender la intención y el conocimiento del usuario es el próximo gran paso. La tecnología del futuro no solo hará lo que se le pide, sino que también entenderá por qué se le pide. Esto nos permitirá delegar tareas intelectuales mucho más complejas a las máquinas, liberando nuestro propio tiempo y energía para la innovación.
En conclusión, el estudio sobre GenExam es una pieza fundamental en el rompecabezas del desarrollo de la inteligencia artificial. Su enfoque en la evaluación multidisciplinaria nos recuerda que la verdadera inteligencia no es solo la capacidad de imitar la forma, sino de comprender el fondo. Este trabajo nos invita a un cambio de paradigma, a dejar de lado la simple carrera por el fotorrealismo y a enfocarnos en la construcción de sistemas que sean verdaderamente sabios, no solo más bonitos. Al proponer un examen que desafía a los modelos en campos tan diversos como la biología, la filosofía y la ingeniería, los investigadores han sentado las bases para una nueva generación de inteligencias artificiales, una que no solo nos sorprenderá con su creatividad, sino que también nos ayudará a resolver los desafíos más complejos del mundo.
Referencias
- OpenAI (2025). GPT-Image-1. Obtenido de
https://openai.com/index/image-generation-api/. - Google (2025). Gemini-2.5-Flash-Image. Obtenido de
<a href="https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/">https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/</a>. - Stability AI (2025). Stable Diffusion 3.5. Obtenido de
https://stability.ai/stable-diffusion. - Midjourney (2025). Midjourney. Obtenido de
https://www.midjourney.com. - Wang, Z. et al. (2025). GenExam: A Multidisciplinary Text-to-Image Exam. ArXiv, abs/2509.14232.
- Goodfellow, I. et al. (2016). Deep Learning. MIT Press.
- Bender, E. M. et al. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. En Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
- Marcus, G. (2018). The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence. ArXiv, abs/1805.00073.

