
Durante los últimos años, hemos sido testigos de una revolución silenciosa que ha reconfigurado nuestra interacción con la tecnología. La inteligencia artificial, antes un concepto relegado a la ciencia ficción y a los laboratorios de investigación, irrumpió en la conciencia colectiva a través de los chatbots, sistemas capaces de conversar, escribir poemas y resumir textos con una fluidez casi humana. Sin embargo, esta primera ola, aunque impresionante, no era más que el preludio de una transformación mucho más profunda. Hoy, la vanguardia de la innovación ya no se centra únicamente en construir modelos que puedan hablar, sino en forjar inteligencias que puedan actuar. Nos encontramos en el umbral de una nueva era: la búsqueda de la autonomía digital.
En este escenario global, una carrera tecnológica de una intensidad sin precedentes está en marcha. Ya no se trata solo de la capacidad de procesamiento o la elocuencia de un modelo, sino de su habilidad para ejecutar tareas complejas en el mundo real con un mínimo de supervisión humana. En este competitivo tablero, donde gigantes occidentales como OpenAI, Anthropic y Google parecían marcar el ritmo, ha emergido un contendiente formidable desde China. Su nombre es Z.ai, una compañía nacida del prestigioso entorno académico de la Universidad de Tsinghua y que, con un respaldo financiero masivo de titanes como Alibaba y Tencent, se ha posicionado como una fuerza a tener en cuenta en la escena mundial.
Su última creación, el modelo GLM-4.6, no es una simple actualización incremental. Representa un salto cualitativo, un paso deliberado hacia ese nuevo paradigma de la autonomía. Para comprender la magnitud de este avance, es fundamental desmitificar el lenguaje técnico que lo rodea y traducirlo a conceptos comprensibles. Tres pilares fundamentales sostienen la arquitectura de esta nueva generación de inteligencia artificial, y GLM-4.6 ha sido diseñado para dominarlos en conjunto.
El primer pilar es el de los agentes inteligentes, o la IA agéntica. Lejos de ser un software abstracto, un agente de IA puede ser imaginado como un equipo de asistentes digitales hipercompetentes. La diferencia fundamental con las tecnologías anteriores radica en la naturaleza de la instrucción. A un programa tradicional se le da una orden específica, como «calcula 5+7». A un agente inteligente se le asigna un objetivo, como «organiza la logística de mi viaje a la conferencia». El agente, a partir de esa meta general, es capaz de planificar de forma independiente los pasos necesarios, ejecutar acciones (como buscar vuelos, comparar precios, reservar hoteles) y aprender de los resultados para ajustar su estrategia hasta cumplir la misión. Es la transición de una herramienta que obedece a un colaborador que resuelve.
El segundo pilar es el razonamiento por pasos, una capacidad cognitiva que permite a la máquina abordar problemas de gran complejidad. Podemos visualizarlo como el método de un detective que resuelve un caso intrincado. En lugar de depender de un único salto intuitivo, que podría ser erróneo, el sistema descompone el problema en una secuencia lógica de etapas más pequeñas, una «cadena de pensamiento». En cada paso, puede recopilar información, formular una hipótesis, ponerla a prueba y utilizar la conclusión para informar el siguiente paso. Este proceso metódico y transparente es lo que le permite enfrentarse a desafíos, ya sean matemáticos, lógicos o de planificación, que son demasiado enrevesados para una respuesta instantánea y monolítica.
El tercer y último pilar es el de los intérpretes de código. Esta herramienta funciona como un laboratorio seguro y aislado, una especie de «caja de arena» digital donde el agente puede experimentar sin riesgo. Cuando una IA necesita realizar un cálculo complejo, analizar un conjunto de datos o verificar una solución que ha ideado, puede escribir un pequeño programa informático para hacerlo. El intérprete de código es el entorno controlado donde ejecuta ese programa, obtiene un resultado preciso y lo utiliza para continuar con su razonamiento. Este mecanismo es crucial, pues transforma al modelo de un mero procesador de lenguaje a un solucionador de problemas práctico, otorgándole la capacidad de verificar su propio trabajo y de interactuar con el mundo de una manera cuantitativa y rigurosa.
La verdadera trascendencia de GLM-4.6, y el argumento central de este análisis, no reside únicamente en su impresionante rendimiento en métricas aisladas. Su importancia radica en que representa la convergencia de estas tres capacidades (agencia, razonamiento y ejecución de código) en una única plataforma potente, cohesionada y, de manera crucial, económicamente accesible. Este lanzamiento no es solo una nueva ficha en el tablero; es una señal inequívoca de que hemos entrado en una nueva fase en la evolución y, sobre todo, en la proliferación global de la inteligencia artificial.
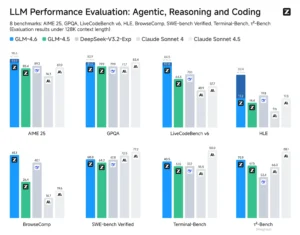
Evaluamos GLM-4.6 en ocho pruebas de referencia públicas que abarcan agentes, razonamiento y codificación. Los resultados muestran claras mejoras respecto a GLM-4.5. GLM-4.6 también presenta ventajas competitivas sobre los principales modelos nacionales e internacionales, como DeepSeek-V3.2-Exp y Claude Sonnet 4, pero aún se encuentra por detrás de Claude Sonnet 4.5 en cuanto a capacidad de codificación.
Anatomía de una mente digital, desglosando GLM-4.6
Para comprender cómo GLM-4.6 logra estas hazañas, es necesario examinar su arquitectura interna y las mejoras técnicas que lo distinguen de sus predecesores. Dos avances en particular, aunque puedan parecer meros números en una hoja de especificaciones, son los cimientos sobre los que se construye su avanzada capacidad de autonomía: una memoria expandida y una eficiencia operativa superior.
La primera de estas mejoras es su ventana de contexto de 200.000 tokens. En el universo de los modelos de lenguaje, un «token» es una unidad básica de texto, que puede ser una palabra o parte de ella. Una ventana de contexto, por tanto, puede entenderse como la memoria a corto plazo del modelo: la cantidad de información que puede tener «presente» en su mente en un momento dado. Una capacidad de 200.000 tokens es el equivalente a procesar el texto de una novela muy extensa, como Guerra y paz, de una sola vez. Esta memoria masiva no es un simple alarde técnico; es el habilitador crítico para las tareas complejas que definen a los agentes autónomos. Permite al sistema ingerir y razonar sobre bases de código enteras, analizar extensos documentos legales en busca de cláusulas específicas o mantener un estado coherente de su misión durante una operación autónoma que puede durar horas, todo ello sin olvidar su objetivo original. Es la diferencia entre tener una conversación breve y poder participar en un proyecto a largo plazo.
Sin embargo, una gran memoria por sí sola no es suficiente. Procesar enormes cantidades de información conlleva tradicionalmente un alto coste computacional y una mayor lentitud en la respuesta. Esto crea una barrera práctica que impide aprovechar todo el potencial de una ventana de contexto gigante. Aquí es donde entra en juego la segunda mejora clave de GLM-4.6: una eficiencia de tokens mejorada. El modelo es capaz de completar las mismas tareas utilizando aproximadamente un 15% menos de tokens que su versión anterior, GLM-4.5. Esto puede interpretarse como si el modelo se hubiera vuelto más elocuente o conciso. No necesita «pensar» con tantas palabras para llegar a la misma conclusión. Este refinamiento tiene implicaciones económicas y prácticas directas: se traduce en menores costes operativos y tiempos de respuesta más rápidos.
Es crucial entender que estas dos mejoras no son avances independientes, sino que operan en una profunda simbiosis. La ventana de contexto expandida y la eficiencia de tokens mejorada se refuerzan mutuamente, creando un círculo virtuoso que hace posible la autonomía avanzada. Una memoria más grande permite al agente abordar tareas de múltiples pasos y de mayor complejidad. No obstante, el coste y la latencia asociados a procesar esa vasta cantidad de información podrían hacer que su uso fuera prohibitivo en el mundo real. Al mejorar simultáneamente la eficiencia, Z.ai mitiga esta barrera. El modelo puede manejar más información (gracias a la gran ventana de contexto) mientras utiliza menos recursos para procesarla y responder (gracias a la eficiencia de tokens). Esta combinación es precisamente lo que convierte la promesa de agentes de IA sofisticados y de largo alcance en una realidad práctica, en lugar de una mera capacidad teórica. Es la llave que desbloquea el verdadero poder de una memoria digital prodigiosa.

La experiencia real es más importante que las tablas de clasificación. Se amplió CC-Bench desde GLM-4.5 con tareas más desafiantes, donde evaluadores humanos trabajaron con modelos dentro de contenedores Docker aislados y completaron tareas reales multi-turno que abarcaron el desarrollo frontend, la creación de herramientas, el análisis de datos, las pruebas y el algoritmo. GLM-4.6 mejora respecto a GLM-4.5 y alcanza casi la paridad con Claude Sonnet 4 (48,6 % de tasa de éxito), a la vez que supera claramente a otras bases de código abierto. Desde la perspectiva de la eficiencia de tokens, GLM-4.6 finaliza las tareas con aproximadamente un 15 % menos de tokens que GLM-4.5, lo que muestra mejoras tanto en capacidad como en eficiencia. Todos los detalles de la evaluación y los datos de trayectoria se han publicado para futuras investigaciones de la comunidad: https://huggingface.co/datasets/zai-org/CC-Bench-trajectories
El artesano del código, la nueva era de la programación
El campo donde el impacto de modelos como GLM-4.6 se manifiesta de forma más inmediata y tangible es el del desarrollo de software. Durante años, las herramientas de IA para programadores funcionaban como un sofisticado sistema de autocompletado, sugiriendo la siguiente línea de código o una función estándar. Ahora, estamos presenciando una transición fundamental: la IA está evolucionando de ser un simple asistente a convertirse en un auténtico colaborador, un artesano digital capaz de abordar la ingeniería de software de una manera mucho más integral.
Esta nueva generación de modelos está automatizando una porción cada vez mayor de las tareas rutinarias y repetitivas que consumen el tiempo de los desarrolladores, como la escritura de código repetitivo, la depuración de errores comunes o la generación de documentación. Al delegar estas labores en sus colegas de silicio, los programadores humanos pueden liberar su ancho de banda cognitivo para centrarse en los aspectos de mayor valor: la arquitectura de sistemas complejos, la resolución de problemas estratégicos y la innovación creativa que aún escapa al alcance de las máquinas.
Para medir con rigor las capacidades de estos nuevos artesanos digitales, la comunidad científica ha tenido que desarrollar una nueva generación de pruebas de evaluación, mucho más exigentes y representativas de los desafíos del mundo real. Para apreciar la destreza de GLM-4.6, es imprescindible comprender la naturaleza de estos nuevos guanteletes.
El primero de ellos es LiveCodeBench. Esta prueba puede ser descrita como un «examen sorpresa» para los modelos de IA. Su innovación clave reside en utilizar problemas extraídos de competiciones de programación muy recientes, a menudo de las últimas semanas o meses. Este método garantiza que es prácticamente imposible que el modelo haya visto las preguntas o sus soluciones durante su fase de entrenamiento. De este modo, LiveCodeBench evalúa la capacidad genuina de resolución de problemas y el razonamiento algorítmico, en lugar de la simple memorización. Se ha convertido en una defensa crucial contra la «contaminación de datos», un problema que puede inflar artificialmente las puntuaciones de los modelos en benchmarks más antiguos.
El segundo es SWE-bench, que puede ser concebido como el «programa de prácticas en el mundo real» para la IA. En lugar de resolver acertijos de programación aislados y autocontenidos, al modelo se le encomienda una tarea mucho más realista: arreglar errores (bugs) reales extraídos de proyectos de software populares y de código abierto alojados en la plataforma GitHub. Para tener éxito, la IA debe navegar por bases de código extensas y complejas, comprender las delicadas interacciones entre múltiples archivos y funciones, y finalmente generar un «parche» de código que solucione el problema sin introducir nuevos errores. Es una prueba mucho más holística de la habilidad para la ingeniería de software.
El rendimiento de GLM-4.6 en estas exigentes pruebas demuestra un salto cualitativo. En LiveCodeBench, por ejemplo, obtiene una puntuación que supone una mejora drástica sobre su predecesor, GLM-4.5, y lo sitúa en una posición altamente competitiva. Los análisis muestran que alcanza una paridad cercana con el aclamado modelo Claude Sonnet 4 de Anthropic. Sin embargo, es importante señalar un matiz que revela la vertiginosa velocidad de la innovación en este campo: aunque compite de tú a tú con Sonnet 4, todavía se encuentra un paso por detrás del modelo más reciente de Anthropic, Claude 4.5 Sonnet, lanzado casi simultáneamente.
El giro de la industria hacia benchmarks como LiveCodeBench y SWE-bench no es una mera decisión técnica para obtener mejores mediciones. Es, en realidad, una declaración de intenciones, un reflejo de una ambición mucho mayor para la inteligencia artificial. Las primeras pruebas de evaluación se centraban en la fluidez del lenguaje y la memorización de hechos; el objetivo era construir una IA que sabe. Posteriormente, benchmarks como el conocido HumanEval pusieron a prueba la capacidad de escribir pequeñas funciones de código aisladas; la meta era crear una IA que puede programar. Los nuevos estándares, sin embargo, evalúan la habilidad para razonar, depurar y modificar sistemas de software grandes y preexistentes. La ambición actual es forjar una IA que pueda hacer ingeniería. Por lo tanto, la decisión de Z.ai de destacar el rendimiento de GLM-4.6 en estas pruebas específicas y de alta dificultad es una señal estratégica clara. Están comunicando al mundo que su creación no es un chatbot más, sino una herramienta diseñada para enfrentarse a la compleja y a menudo desordenada realidad del desarrollo de software profesional.
Comparativa de rendimiento en benchmarks clave
| Métrica de Evaluación | GLM-4.6 | GLM-4.5 | Claude 4.5 Sonnet | Claude Sonnet 4 | DeepSeek-V3.2 |
| LiveCodeBench v6 | 82.8% | 63.3% | No disponible | 84.5% | No disponible |
| SWE-bench Verified | 68.0% | 64.2% | 77.2% | 67.8% | No disponible |
| AIME 2025 (Matemáticas) | 93.9% | No disponible | 87.0% | No disponible | No disponible |
Nota: Los datos de rendimiento se basan en las puntuaciones publicadas y pueden variar según la configuración de la evaluación. «No disponible» indica que no se han publicado resultados comparables para ese modelo en esa métrica específica en las fuentes consultadas.
La máquina que razona, más allá de la simple respuesta
Si la capacidad de programación es la habilidad manual del artesano digital, su capacidad de razonamiento es el motor cognitivo que impulsa todas sus acciones. Es el fundamento sobre el que se construyen sus competencias más avanzadas, desde la planificación estratégica hasta la resolución de problemas abstractos. Para evaluar esta dimensión, es necesario desplazar el foco de atención del código a otros dominios que exigen una lógica pura y rigurosa, como las matemáticas avanzadas y los puzles lógicos.
Una de las pruebas más reveladoras en este ámbito es el AIME (American Invitational Mathematics Examination), una competición de matemáticas de alto nivel para estudiantes de secundaria. El rendimiento casi perfecto de GLM-4.6 en la edición de 2025 de esta prueba es una evidencia contundente de sus profundas capacidades deductivas. Superar el AIME no es una cuestión de realizar cálculos a gran velocidad, algo que cualquier ordenador puede hacer. Requiere comprender enunciados complejos y ambiguos, identificar la estrategia de resolución adecuada y ejecutar una secuencia de pasos lógicos para llegar a la solución correcta. Es una demostración de un razonamiento matemático genuino.
Otro campo de pruebas es el HLE (Hard Logical Evaluation), un benchmark diseñado específicamente para medir la consistencia lógica. Esta prueba presenta al modelo escenarios complejos donde debe mantener una coherencia interna a lo largo de su razonamiento, sin contradecirse. El rendimiento superior de GLM-4.6 en esta métrica es particularmente significativo. Esta habilidad es absolutamente crucial para aplicaciones del mundo real como el análisis de contratos legales, la planificación logística o la depuración de sistemas complejos, donde una única contradicción o un lapso en la lógica pueden invalidar por completo el resultado final.
Sin embargo, este poder de razonamiento en bruto se vuelve verdaderamente transformador cuando se combina con la capacidad del modelo para utilizar herramientas externas. GLM-4.6 no se limita a «pensar» en un vacío abstracto. Es capaz de utilizar su motor de razonamiento para tomar decisiones sobre cuándo y cómo emplear herramientas que aumentan su propia inteligencia. Puede, por ejemplo, deducir que un problema requiere un cálculo preciso y decidir ejecutar un fragmento de código en su intérprete. O puede reconocer que carece de información actualizada sobre un tema y optar por realizar una búsqueda en la web para obtener los datos que necesita. Esta interacción dinámica entre el razonamiento interno y las herramientas externas es lo que le permite superar las limitaciones de su conocimiento estático y actuar de manera efectiva en un entorno cambiante.
Esta fortaleza en el razonamiento formal no es una mera curiosidad académica; es un requisito indispensable para la creación de agentes autónomos en los que podamos confiar. Un agente autónomo, por definición, debe tomar decisiones de forma independiente para alcanzar los objetivos que se le han asignado. Si estas decisiones se basan en una lógica defectuosa, en «alucinaciones» o en un razonamiento inconsistente, sus acciones podrían ser, en el mejor de los casos, ineficaces y, en el peor, impredecibles o incluso perjudiciales. El rendimiento en benchmarks rigurosos de lógica y matemáticas sirve como un indicador fiable de la capacidad del modelo para mantener una cadena de pensamiento válida y coherente. Por lo tanto, un modelo que demuestra una fortaleza verificable en el razonamiento formal tiene muchas más probabilidades de convertirse en un agente fiable y predecible. Este rigor lógico es la roca madre sobre la que se debe construir una autonomía efectiva y segura.
El auge de los agentes, la IA como colega autónomo
La capacidad agéntica, ese anhelado objetivo de la inteligencia artificial autónoma, no es una característica aislada. Es la culminación, la síntesis armoniosa de todas las capacidades que hemos explorado hasta ahora. Un agente eficaz necesita la vasta memoria de una gran ventana de contexto para no perder el hilo de sus tareas. Requiere las habilidades prácticas de un programador para interactuar con sistemas digitales y crear soluciones. Y, fundamentalmente, precisa el motor cognitivo de un razonador lógico para planificar sus acciones y tomar decisiones sensatas. GLM-4.6 es un ejemplo paradigmático de cómo la convergencia de estos elementos da lugar a una nueva clase de inteligencia artificial.
Para poner a prueba esta autonomía emergente, se necesitan benchmarks que simulen tareas agénticas del mundo real. Uno de los más relevantes es BrowseComp, una prueba diseñada para evaluar una habilidad crucial: la capacidad de navegar de forma autónoma por la web para encontrar información difícil y entrelazada. Las preguntas de BrowseComp no pueden resolverse con una simple búsqueda en Google. Requieren persistencia, la formulación creativa de múltiples consultas de búsqueda, la capacidad de sintetizar información fragmentada de diversas fuentes y la habilidad para no rendirse ante los callejones sin salida. En esencia, simula a la perfección el trabajo de un asistente de investigación humano al que se le encarga una tarea compleja. El sólido rendimiento de GLM-4.6 en este benchmark demuestra su capacidad práctica para actuar y resolver problemas en un entorno digital real y no estructurado como es internet.
Más allá de las métricas cuantitativas, la verdadera prueba de un agente es su desempeño en aplicaciones prácticas. Los desarrolladores y usuarios que han comenzado a integrar GLM-4.6 en marcos de trabajo agénticos, como las populares herramientas de codificación Claude Code o Kilo Code, ofrecen una perspectiva cualitativa valiosa. Los informes iniciales destacan su sólida integración y su eficacia en tareas de programación autónoma. Algunos usuarios han notado que el modelo puede tomarse su tiempo para «pensar» antes de actuar, un comportamiento que sugiere un proceso de deliberación interna más profundo antes de comprometerse con una línea de acción. Esta retroalimentación del mundo real complementa los datos de los benchmarks y pinta un cuadro de un sistema potente, aunque todavía en evolución.
La aparición de agentes tan capaces como los impulsados por GLM-4.6 no es solo una mejora tecnológica; representa el inicio de un cambio de paradigma en la forma en que los humanos interactuamos con los ordenadores. Históricamente, nuestra relación con las máquinas ha sido instructiva. En la era de la línea de comandos (CLI), les dábamos órdenes explícitas y textuales. Con la llegada de la interfaz gráfica de usuario (GUI), pasamos a darles instrucciones a través de clics e iconos. Incluso con los chatbots de la primera generación, el paradigma seguía siendo en gran medida el de dar órdenes, aunque fuera en lenguaje natural: «escríbeme un poema», «resume este texto».
La IA agéntica introduce una forma de interacción fundamentalmente nueva: la delegación. Estamos pasando de una interfaz orientada a comandos a una interfaz orientada a objetivos (GOI, por sus siglas en inglés). El usuario ya no necesita especificar los pasos. En su lugar, comunica una meta de alto nivel: «reserva mi viaje a la conferencia de la próxima semana, optimizando el coste y minimizando las escalas», «encuentra y corrige el error que está causando que esta aplicación se bloquee», o «investiga el mercado potencial para este nuevo producto y prepara un informe». El agente, impulsado por un cerebro como GLM-4.6, se encarga de traducir ese objetivo en una secuencia concreta de acciones (búsquedas web, ejecución de código, llamadas a API, etc.) y las lleva a cabo de forma autónoma hasta cumplir la misión. Este es un cambio profundo en la computación. Estamos dejando de ser meros operadores de herramientas para convertirnos en gestores de una fuerza de trabajo digital y autónoma.
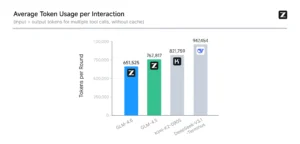
En términos de consumo promedio de tokens, GLM-4.6 es más de un 30% más eficiente que GLM-4.5, logrando la tasa de consumo más baja entre los modelos comparables.
Z.ai, el titán chino en el tablero geopolítico de la IA
La tecnología nunca existe en un vacío. La historia y el contexto geopolítico que rodean a GLM-4.6 son tan importantes como sus especificaciones técnicas para comprender su verdadero significado. La trayectoria de su creador, Z.ai, es un microcosmos de las ambiciones y estrategias de China en la carrera global por la supremacía en inteligencia artificial.
La génesis de Z.ai se encuentra en los pasillos de la Universidad de Tsinghua, a menudo apodada el «MIT de China», donde comenzó como un proyecto de investigación académica. Sin embargo, su transición al mundo comercial fue meteórica, impulsada por un torrente de inversiones de los gigantes tecnológicos más grandes de China, como Alibaba y Tencent, así como de fondos estatales y capital internacional estratégico, incluyendo a Prosperity7, el brazo inversor de la petrolera saudí Aramco. Esta mezcla de origen académico de élite y un respaldo financiero masivo la catapultó rápidamente a la primera línea de la innovación en IA.
La estrategia de Z.ai ha sido forjada en el crisol de la intensa rivalidad tecnológica entre Estados Unidos y China. Un momento decisivo llegó cuando el Departamento de Comercio de EE. UU. incluyó a la compañía en su lista negra comercial, alegando vínculos con el ejército chino. Lejos de ser un golpe debilitante, esta acción actuó como un catalizador que validó y aceleró la estrategia preexistente de Z.ai: la búsqueda de la «independencia de pila completa» (full-stack independence). Esta estrategia se materializó en alianzas cruciales con campeones nacionales del hardware, especialmente Huawei, para desarrollar sistemas de IA que no dependieran de los chips de diseño estadounidense.
A partir de esta base de soberanía tecnológica, Z.ai ha articulado una ambiciosa estrategia de expansión global basada en dos conceptos clave: la «Ruta de la Seda Digital» y la «IA Soberana». Esta visión va mucho más allá de la simple venta de software. Lo que Z.ai ofrece al mundo no es solo un modelo de lenguaje, sino un ecosistema tecnológico completo, encapsulado en su oferta de «IA en una caja» (AI-in-a-Box). Se trata de sistemas preconfigurados que permiten a otras naciones, especialmente en el Sur Global y en mercados emergentes, construir sus propias capacidades de IA sin depender de los servicios en la nube de los gigantes estadounidenses como Amazon, Google o Microsoft. Esta propuesta resuena poderosamente con un número creciente de países que buscan la «soberanía tecnológica» y desconfían de una dependencia excesiva de la infraestructura digital occidental, en un mundo cada vez más consciente de los riesgos de la colonización digital.
El modelo de negocio de Z.ai, por tanto, debe ser entendido como un instrumento directo de la estrategia de poder blando de China. La asequibilidad extrema de GLM-4.6 y su disponibilidad como modelo de código abierto no son meras decisiones de precios; son actos estratégicos. Mientras que la estrategia estadounidense en la carrera de la IA ha incluido a menudo la restricción del acceso al hardware y a los modelos más avanzados, la estrategia de China, ejecutada a través de empresas como Z.ai, es la opuesta: se centra en la proliferación y la ubicuidad. Al hacer que un modelo altamente capaz como GLM-4.6 sea radicalmente más barato y esté abierto a la comunidad global, reducen drásticamente la barrera de entrada para que cualquier país o empresa pueda acceder a tecnología de vanguardia.
Al mismo tiempo, al ofrecer soluciones de «IA Soberana» que funcionan con hardware no estadounidense, están creando una alternativa viable y completa a la pila tecnológica occidental. A medida que los países adoptan estos sistemas, no solo están comprando un producto, sino que también están alineando implícitamente su infraestructura digital con los estándares técnicos y el ecosistema de China. El objetivo a largo plazo no es simplemente vender un modelo, sino establecer el estándar global dominante para la inteligencia artificial, ganando la «guerra de los estándares» no a través de la exclusividad, sino a través de la accesibilidad y el despliegue masivo. GLM-4.6 es el producto, pero la oferta real es una nueva esfera de influencia geopolítica digital.
Navegando el futuro con nuestros nuevos copilotos digitales
La llegada de modelos tan avanzados como GLM-4.6 no representa un punto final en el desarrollo de la inteligencia artificial, sino el comienzo de un capítulo completamente nuevo en nuestra relación con la tecnología. Estas herramientas están destinadas a remodelar profundamente nuestras profesiones, nuestras sociedades y, potencialmente, incluso nuestra forma de pensar. Navegar este futuro requerirá tanto una apreciación de su inmenso potencial como una conciencia lúcida de sus profundos desafíos.
El impacto más inmediato se sentirá en la redefinición del trabajo cualificado. El desarrollo de software, como hemos visto, es el ejemplo paradigmático. El papel del programador humano se alejará progresivamente de la ejecución de tareas rutinarias y la escritura de código línea por línea. En su lugar, el valor residirá cada vez más en la supervisión estratégica de los agentes de IA, en la formulación de los problemas correctos, en la arquitectura de sistemas complejos y en el ejercicio de la creatividad para imaginar nuevas soluciones. Las habilidades exclusivamente humanas, como la colaboración, la comunicación, la empatía para entender las necesidades del usuario y el pensamiento crítico, se convertirán en el verdadero diferenciador en un mundo donde la producción de código se ha mercantilizado.
El potencial para una transformación positiva es inmenso. Agentes autónomos podrían acelerar drásticamente la investigación científica, analizando datos y formulando hipótesis a una velocidad sobrehumana. Podrían crear sistemas de educación verdaderamente personalizados, adaptándose al ritmo y estilo de aprendizaje de cada estudiante. En medicina, podrían ayudar en el diagnóstico, la planificación de tratamientos y el descubrimiento de nuevos fármacos, inaugurando una era de atención sanitaria más precisa y accesible.
Sin embargo, este futuro prometedor está inextricablemente ligado a riesgos significativos que debemos abordar de frente. La amenaza del desplazamiento laboral es real y requerirá una reinvención de nuestros sistemas educativos y redes de seguridad social. La capacidad de los agentes para recopilar y procesar datos a una escala masiva plantea desafíos sin precedentes para la privacidad individual; un agente diseñado para ser el asistente personal perfecto podría convertirse, sin las salvaguardias adecuadas, en el sistema de vigilancia más invasivo jamás concebido. Además, la interacción de múltiples agentes autónomos en sistemas complejos podría dar lugar a comportamientos emergentes, consecuencias imprevistas que son difíciles de predecir y controlar, con implicaciones para la estabilidad financiera, social e incluso la seguridad internacional.
Quizás el desafío más sutil y profundo sea el que podríamos llamar la paradoja cognitiva. A medida que delegamos cada vez más tareas de pensamiento, planificación y resolución de problemas a estos copilotos digitales increíblemente competentes, corremos el riesgo de que nuestras propias habilidades cognitivas se atrofien. Si ya no necesitamos memorizar, calcular, planificar o incluso depurar nuestros propios errores, ¿qué pasará con la musculatura de nuestra mente? El verdadero reto no será simplemente usar la IA, sino aprender a colaborar con ella de una manera que aumente nuestra propia inteligencia en lugar de suplantarla.
En última instancia, modelos como GLM-4.6 no son una fuerza de la naturaleza ante la que debamos reaccionar pasivamente. Son artefactos de la ingeniosidad humana, herramientas de un poder extraordinario. Su impacto final no estará determinado por sus algoritmos, sino por las elecciones que nosotros, como sociedad, hagamos sobre cómo los desarrollamos, los gobernamos y los integramos en el tejido de nuestras vidas. Nuestra tarea no es ser meros espectadores de su evolución, sino arquitectos activos y sabios de nuestro futuro compartido con estas nuevas mentes digitales, asegurando que sirvan como instrumentos para el empoderamiento humano y el progreso colectivo.
Referencias
AWS. (n.d.). What is Agentic AI? Amazon Web Services.
Holter, A. (n.d.). GLM-4.6 vs Claude Sonnet 4.5: Benchmarks, Capabilities, and Cost-Effectiveness.
Li, S., et al. (2024). LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv.
Phan, L., et al. (2025). BrowseComp: A Benchmark for Web Browsing Agents. arXiv.
Reddit. (n.d.-a). r/LocalLLaMA – GLM-4.6 beats Claude Sonnet 4.5.
Reddit. (n.d.-b). r/LocalLLaMA – GLM-4.6 now on artificial analysis.
Reddit. (n.d.-c). r/LocalLLaMA – GLM 4.6 is a f*ing amazing model and nobody can convince me otherwise.
Reddit. (n.d.-d). r/LocalLLaMA – GLM-4.6 outperforms claude-4-5-sonnet while being ~8x cheaper.
Rockrose. (n.d.). The Rise of Zhipu AI: China’s Answer to OpenAI..
Weights & Biases. (n.d.). OpenAI’s new browsing benchmark: BrowseComp.
Winsome Marketing. (n.d.). Blacklisted and Brilliant: China’s Zhipu AI.
World Economic Forum. (2024, December). AI agents can empower human potential while mitigating risks.
Z.ai. (2025, September 30). GLM-4.6: Advanced Agentic, Reasoning and Coding Capabilities. Z.ai Blog.

