
El pulso incesante de los mercados financieros es una sinfonía compleja de datos, emociones y decisiones. Desde los albores del capitalismo, la búsqueda de una ventaja, de una fórmula mágica que prediga el futuro, ha sido la obsesión de traders, analistas y gurús. Durante décadas, los ordenadores han jugado un papel cada vez más prominente, ejecutando algoritmos ultrarrápidos y analizando patrones que escapan al ojo humano. Sin embargo, estas máquinas operaban bajo un conjunto de reglas predefinidas, limitadas por la lógica explícita de sus programadores. Eran herramientas potentes, sí, pero carecían de lo que muchos consideraban la clave del éxito financiero: el razonamiento.
Imaginemos por un momento un Wall Street donde las decisiones no solo se basan en números y gráficos, sino en la comprensión profunda de noticias, informes económicos, publicaciones en redes sociales, y la capacidad de inferir, planificar y adaptarse a la información no estructurada. Esto suena a ciencia ficción, a una película donde un «cerebro» artificial lee entre líneas y opera con una intuición casi humana. Pues bien, la frontera entre la fantasía y la realidad se difumina rápidamente con el advenimiento de una nueva generación de inteligencia artificial: los modelos de lenguaje grandes (LLM, por sus siglas en inglés).
Estos modelos, como los que impulsan sistemas conversacionales populares, han demostrado una habilidad asombrosa para comprender, generar y razonar con lenguaje humano. Su éxito en tareas creativas o de análisis textual ha sido innegable, pero ¿qué pasaría si esa capacidad de razonamiento lingüístico se aplicara al vertiginoso mundo del trading financiero? ¿Podría una IA, capaz de «entender» un informe trimestral o el tono de un tuit de Elon Musk, superar a los algoritmos tradicionales o incluso a los expertos humanos?
Un reciente estudio, Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning, nos sumerge de lleno en esta fascinante posibilidad. Los investigadores han explorado la creación de un agente de trading de nueva generación que combina la potencia de los LLM con una técnica de entrenamiento llamada #Aprendizaje por Refuerzo# (RL, por sus siglas en inglés). La premisa es audaz: dotar a la inteligencia artificial no solo de la capacidad de procesar datos financieros, sino también de la habilidad de «pensar» sobre ellos, de razonar, de planificar sus movimientos como lo haría un inversor experimentado.
Este nuevo paradigma se basa en la idea de que los mercados no son solo números, sino narrativas. Las fluctuaciones están ligadas a eventos noticiosos, a declaraciones de líderes empresariales, a análisis complejos que van más allá de una simple secuencia de precios. Los LLM son excepcionalmente buenos en el procesamiento de este tipo de información cualitativa, que hasta ahora era un desafío para los sistemas de trading automatizados. Al integrar el razonamiento de los LLM con el aprendizaje por refuerzo, los científicos buscan construir un agente que no solo reaccione, sino que anticipe, aprenda de sus errores y optimice sus estrategias para maximizar los beneficios en un entorno dinámico e impredecible.
Este trabajo no es solo un avance técnico; es un vistazo a un futuro cercano donde la inteligencia artificial podría redefinir fundamentalmente la forma en que se toman las decisiones económicas, no solo en los grandes fondos de inversión, sino en cada rincón de la economía global. Nos invita a reflexionar sobre las implicaciones de una IA capaz de comprender los matices del lenguaje financiero y utilizarlos para generar riqueza, planteando preguntas cruciales sobre la estabilidad del mercado, la equidad y el papel futuro del discernimiento humano en las finanzas.
Decodificando la mente del LLM: Más allá de la predicción de palabras
Antes de sumergirnos en cómo la inteligencia artificial aprende a comerciar, es fundamental comprender la naturaleza y las capacidades de los modelos de lenguaje grandes. Estos sistemas son, en esencia, prodigios de la estadística lingüística. Han sido entrenados con volúmenes colosales de texto de Internet, libros, artículos científicos y bases de datos. Su tarea principal durante este entrenamiento masivo es predecir la siguiente palabra en una secuencia, basándose en el contexto previo. Al hacerlo billones de veces, desarrollan una representación interna increíblemente sofisticada del lenguaje, sus patrones gramaticales, su semántica y, sorprendentemente, una capacidad para capturar relaciones conceptuales y conocimientos del mundo real.
Lo que hace a los LLM tan revolucionarios no es solo su habilidad para generar texto coherente, sino su emergencia de capacidades de «razonamiento». No es que piensen como un ser humano, con conciencia o intenciones, pero su arquitectura y la vastedad de sus datos de entrenamiento les permiten exhibir comportamientos que se asemejan al razonamiento lógico, la inferencia y la planificación. Pueden responder preguntas complejas, resumir documentos extensos, traducir idiomas e incluso escribir código de programación. Esta «chispa» de razonamiento es lo que los hace tan atractivos para tareas que van más allá de la mera manipulación de texto.
En el contexto financiero, esta capacidad es un cambio de juego. Los sistemas tradicionales de trading algorítmico sobresalen en el análisis cuantitativo: detectar patrones en series de precios, volúmenes de negociación o datos económicos duros. Son rápidos, precisos y pueden procesar millones de puntos de datos en milisegundos. Sin embargo, su talón de Aquiles ha sido siempre la información no estructurada: el lenguaje. ¿Cómo cuantificar el impacto de una declaración del presidente de la Reserva Federal? ¿Cómo interpretar el sentimiento de un informe de ganancias que utiliza un lenguaje matizado? ¿Cómo prever las consecuencias de un titular de última hora en el mercado energético?
Los LLM abordan directamente esta limitación. Son capaces de:
- Comprender el contexto: Pueden leer un artículo de noticias sobre una empresa, identificar los actores clave, los eventos relevantes y el tono general (optimista, pesimista, neutral).
- Extraer información clave: Tienen la habilidad de sintetizar puntos importantes de informes económicos largos, identificar tendencias o extraer cifras específicas de un párrafo.
- Razonar sobre la información: Pueden combinar la información textual con otros datos para generar hipótesis o escenarios. Por ejemplo, si una empresa anuncia una nueva tecnología disruptiva, un LLM podría inferir posibles impactos en sus competidores o en el sector.
- Generar planes de acción: A través de su capacidad de planificación, pueden formular una secuencia de pasos a seguir para lograr un objetivo, como una estrategia de trading que considere múltiples factores lingüísticos y numéricos.
Este potencial de razonamiento lingüístico convierte a los LLM en candidatos ideales para mejorar la toma de decisiones financieras, elevando el análisis más allá de los números crudos hacia una comprensión más holística del ecosistema del mercado.
El arte de aprender: Aprendizaje por refuerzo en el ruedo financiero
Si los LLM aportan la capacidad de razonamiento lingüístico, el aprendizaje por refuerzo (RL) proporciona la experiencia necesaria para operar en el complejo y a menudo hostil entorno de los mercados financieros. El RL es una rama de la inteligencia artificial donde un «agente» aprende a tomar decisiones interactuando con un «entorno». No se le proporcionan ejemplos de lo que debe hacer (como en el aprendizaje supervisado), sino que aprende a base de «ensayo y error» y de un sistema de «recompensas» y «penalizaciones».
Pensemos en un perro al que se le enseña un truco. Si lo hace bien, recibe una recompensa (una galleta); si lo hace mal, no recibe nada o quizás una corrección. Con el tiempo, el perro aprende qué acciones conducen a la galleta. En el RL, el agente es nuestro sistema de IA, el entorno es el mercado financiero (con sus precios fluctuantes, noticias y eventos), y las recompensas son las ganancias obtenidas de las operaciones, mientras que las pérdidas actúan como penalizaciones.
La belleza del RL radica en su capacidad para aprender políticas complejas sin una programación explícita de todas las posibles eventualidades. El agente explora diferentes estrategias de trading, observa los resultados de sus acciones y ajusta su comportamiento para maximizar la recompensa acumulada a largo plazo. En el contexto de Trading-R1, esto significa que el LLM no solo «piensa» sobre los datos, sino que aprende activamente a traducir esos pensamientos en acciones de trading que generen beneficios.
La integración de LLM y RL es particularmente poderosa porque el LLM puede guiar el proceso de aprendizaje del RL. Tradicionalmente, los agentes de RL operan con datos numéricos o representaciones abstractas. Al añadir el LLM, el agente de RL puede recibir «consejos» o «razonamientos» en lenguaje natural sobre por qué una acción podría ser buena o mala. Por ejemplo, el LLM podría analizar un conjunto de noticias y generar un resumen conciso que indique: «Hay una alta probabilidad de que esta acción suba debido a X, Y y Z. Recomiendo una posición de compra». El agente de RL entonces usaría este razonamiento como parte de su proceso de decisión, ajustando su estrategia y recibiendo feedback del mercado real.
Este enfoque representa un salto cualitativo. No solo se entrena a un agente para que opere, sino que se le dota de una capacidad interna de justificación y comprensión de sus propias acciones, lo que lo hace más adaptable y, potencialmente, más robusto frente a las sorpresas del mercado. El aprendizaje por refuerzo, al permitir que la IA se «sumerja» en el mercado y aprenda de cada operación, convierte al LLM de un mero procesador de texto en un estratega financiero en constante evolución.
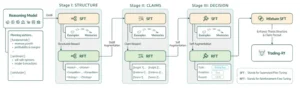
Trading-R1: Arquitectura de un estratega artificial
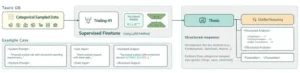
El corazón del estudio Trading-R1 reside en su innovadora arquitectura, diseñada para fusionar las habilidades lingüísticas de los LLM con la adaptabilidad del aprendizaje por refuerzo. Los investigadores no se limitaron a conectar un LLM a un sistema de trading existente; crearon un marco integral donde el razonamiento se convierte en una parte intrínseca de la toma de decisiones financieras.
La arquitectura de Trading-R1 se puede visualizar como un cerebro financiero dividido en módulos, donde cada parte tiene un rol específico pero interconectado:
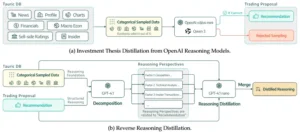
- Módulo de Observación y Preprocesamiento: Este es el «ojo» del sistema. Recopila una amplia gama de datos financieros, incluyendo precios históricos de acciones, volúmenes de negociación, indicadores técnicos clásicos y, crucialmente, una vasta cantidad de información textual: noticias de última hora, informes de empresas, análisis de expertos y cualquier otro dato relevante en lenguaje natural. Estos datos, tanto numéricos como textuales, se procesan y se presentan al resto del sistema de una manera que la IA pueda entender. El texto, por ejemplo, se codifica en representaciones numéricas que el LLM puede manipular.
- Módulo de Razonamiento del LLM: Aquí es donde reside la «mente» del agente. Un modelo de lenguaje grande de última generación (como un GPT-3.5 o similar) toma los datos preprocesados y genera un «razonamiento» sobre la situación actual del mercado y las posibles acciones. Este razonamiento no es una simple predicción, sino un análisis en lenguaje natural que justifica una decisión. Por ejemplo, podría generar un texto que diga: «Dada la reciente caída del precio de la acción X tras el anuncio de resultados por debajo de lo esperado, y considerando el sentimiento negativo en redes sociales, la recomendación es vender para evitar mayores pérdidas».
- Módulo de Planificación de Acciones: Con el razonamiento del LLM como guía, este módulo traduce la intención estratégica en una secuencia concreta de operaciones. Si el LLM sugiere «vender», este módulo decidirá cuántas acciones vender, a qué precio y en qué momento, considerando las restricciones del mercado y los objetivos del trader. Este módulo puede utilizar técnicas de planificación avanzadas, buscando optimizar las órdenes para minimizar el impacto en el mercado o maximizar el precio de ejecución.
- Módulo de Aprendizaje por Refuerzo (RL): Este es el «entrenador» del sistema. Después de que se ejecuta una operación (basada en el razonamiento del LLM y la planificación de acciones), el módulo de RL observa el resultado: ¿hubo ganancia o pérdida? Esta retroalimentación se utiliza para ajustar y mejorar la estrategia del agente. Si una decisión de venta basada en un razonamiento particular resultó en una pérdida, el sistema aprenderá a sopesar de manera diferente ese tipo de razonamiento en el futuro. El RL refina continuamente la «política» del agente, es decir, el conjunto de reglas que dictan cómo se toman las decisiones, para maximizar las recompensas (ganancias) a largo plazo. Es un ciclo de autoaprendizaje constante.
- Módulo de Memoria y Reflexión: Un componente crucial para la adaptación. A medida que el agente opera, registra sus experiencias, sus razonamientos y los resultados de sus acciones. Este módulo permite al LLM «reflexionar» sobre su desempeño pasado, identificar patrones exitosos o errores recurrentes, y ajustar su entendimiento del mercado. Es como un diario de trading que el LLM puede consultar y aprender de él para afinar su estrategia.
Esta compleja interacción entre el razonamiento lingüístico del LLM y el aprendizaje experiencial del RL permite a Trading-R1 no solo procesar información, sino también evolucionar y adaptarse a las cambiantes condiciones del mercado, una habilidad que es la marca distintiva de los traders más exitosos.

El campo de batalla: Pruebas y resultados en el simulador
Para evaluar la efectividad de Trading-R1, los investigadores lo sometieron a rigurosas pruebas en un entorno simulado de mercado financiero. Este tipo de simuladores son cruciales porque replican la complejidad y la imprevisibilidad de los mercados reales sin el riesgo de perder dinero. Es como un campo de entrenamiento virtual donde la IA puede cometer errores y aprender sin consecuencias financieras reales.
El enfoque de las pruebas fue dual: por un lado, se probó la capacidad de Trading-R1 para generar razonamientos coherentes y estratégicos basados en los datos financieros. Por otro lado, y lo más importante, se evaluó su desempeño en la tarea principal: generar ganancias de manera consistente.
Los resultados fueron impresionantes y, en muchos aspectos, superaron las expectativas. Trading-R1 demostró una notable capacidad para:
- Generar razonamientos de alta calidad: El LLM dentro de Trading-R1 fue capaz de producir explicaciones detalladas y lógicamente consistentes para sus decisiones de trading. Estos razonamientos no eran meras descripciones de las acciones, sino análisis profundos que combinaban datos numéricos con información textual. Por ejemplo, podría explicar una decisión de compra citando una tendencia de precios ascendente, un volumen de negociación creciente y una noticia positiva sobre la expansión de la empresa.
- Adaptarse a las condiciones del mercado: A través del aprendizaje por refuerzo, el agente demostró una notable flexibilidad. Si el mercado se volvía volátil, el agente ajustaba su estrategia para reducir el riesgo; si se presentaban oportunidades claras, las aprovechaba. Esta adaptabilidad es un sello distintivo de los traders humanos experimentados y es difícil de codificar explícitamente en algoritmos tradicionales.
- Superar a los benchmarks tradicionales: En las simulaciones, Trading-R1 consistentemente superó a los algoritmos de trading basados únicamente en indicadores técnicos o en estrategias pasivas (como simplemente mantener un portafolio diversificado). Esto es un logro significativo, ya que demuestra que la capacidad de razonamiento lingüístico del LLM aporta un valor tangible.
- Manejar la información no estructurada: El sistema brilló en situaciones donde la información textual era clave. Pudo interpretar noticias complejas, identificar sentimientos en informes y reaccionar a eventos externos de una manera que los sistemas puramente cuantitativos no podían. Por ejemplo, si una noticia importante sobre una fusión corporativa aparecía, Trading-R1 era capaz de procesarla, razonar sobre sus implicaciones y ejecutar operaciones en consecuencia.
- Mantener un balance riesgo/recompensa: Aunque el objetivo principal era la rentabilidad, el sistema también demostró una capacidad para gestionar el riesgo, evitando exposiciones excesivas y ajustando el tamaño de sus posiciones en función de la incertidumbre percibida.
Estos resultados no sugieren que Trading-R1 sea infalible o que el mercado haya sido «resuelto». El entorno simulado, por muy sofisticado que sea, nunca es una réplica perfecta del mercado real. Sin embargo, los hallazgos son una prueba contundente del potencial transformador de la combinación de LLM y RL en las finanzas. Demuestran que el razonamiento en lenguaje natural no es un lujo, sino una ventaja competitiva cuando se trata de navegar por la complejidad del trading moderno.
El futuro de las finanzas: Desafíos y horizontes
La aparición de agentes como Trading-R1 abre un abanico de posibilidades fascinantes y, a la vez, plantea desafíos considerables para el futuro de los mercados financieros y la sociedad en general. Es evidente que estamos al borde de una nueva era en el trading, una era donde la inteligencia artificial no solo calcula, sino que «comprende» y «razona».
Potenciales impactos positivos:
- Mayor eficiencia y accesibilidad: Los agentes de IA podrían democratizar el acceso a estrategias de inversión sofisticadas, tradicionalmente reservadas para grandes fondos. Podrían ofrecer asesoramiento y ejecución automatizada a pequeños inversores, optimizando sus carteras de manera inteligente.
- Mejor gestión de riesgos: Al integrar una gama más amplia de información (incluida la textual) y aprender de la experiencia, estos sistemas podrían identificar y mitigar riesgos de manera más efectiva que los métodos actuales, contribuyendo a una mayor estabilidad del mercado.
- Descubrimiento de nuevas oportunidades: La capacidad de los LLM para procesar y relacionar información diversa podría revelar patrones y oportunidades de inversión que los analistas humanos o los algoritmos tradicionales pasarían por alto.
- Reducción de sesgos humanos: Las decisiones de trading humano están a menudo influenciadas por emociones, sesgos cognitivos o fatiga. Una IA bien diseñada podría operar de forma más objetiva y consistente, libre de estas limitaciones.
Desafíos y consideraciones éticas:
- Estabilidad del mercado: Si una gran cantidad de agentes de IA comienzan a operar con estrategias similares o a reaccionar de forma coordinada a ciertas noticias, esto podría generar una volatilidad extrema, «flash crashes» o burbujas y colapsos más pronunciados. La interacción de múltiples IA en el mercado es un campo de estudio crucial.
- Transparencia y explicabilidad: La «caja negra» de los LLM y los sistemas de RL dificulta entender por qué una IA tomó una decisión particular. Esto es problemático en un entorno regulado como las finanzas, donde la explicabilidad y la auditoría son fundamentales. Necesitamos métodos para que la IA pueda justificar sus acciones de manera comprensible.
- Equidad y manipulación: Si solo un puñado de entidades tienen acceso a estas IA avanzadas, podría crearse una asimetría de información y una ventaja injusta. Además, existe el riesgo de que las IA puedan ser entrenadas (intencionalmente o no) para manipular el mercado a través de la propagación de desinformación o la explotación de sesgos.
- El papel del factor humano: ¿Qué sucederá con los traders y analistas humanos? Si las IA pueden razonar y operar de manera más efectiva, ¿cuál será el valor añadido de la inteligencia humana? Es probable que el rol se desplace hacia la supervisión, el desarrollo de estrategias de alto nivel y la resolución de problemas complejos que aún escapen a las máquinas.
- Entrenamiento y datos: La calidad de los datos de entrenamiento para los LLM es vital. Si los datos contienen sesgos o reflejan patrones de mercado obsoletos, la IA podría replicar esos fallos. El costo y la complejidad de entrenar y mantener estos sistemas también son considerables.
Este trabajo sobre Trading-R1 no solo es una proeza técnica, sino una invitación a una discusión más amplia sobre cómo queremos que la inteligencia artificial se integre en uno de los sistemas más complejos y cruciales de nuestra sociedad: los mercados financieros. Nos empuja a pensar no solo en lo que la IA puede hacer, sino en cómo debe hacerlo y para qué propósito, asegurando que su poder se utilice para el bien común.
El futuro, hoy
Los mercados financieros son un reflejo de la actividad humana, de sus esperanzas, miedos y expectativas. Durante milenios, han sido gobernados por la intuición, el análisis y, a menudo, la pura emoción humana. Con la llegada de los algoritmos de alta frecuencia, la velocidad y la escala numérica se convirtieron en reyes. Ahora, con la integración de los modelos de lenguaje grandes y el aprendizaje por refuerzo, estamos presenciando una nueva evolución. La capacidad de una máquina para leer un titular, comprender su implicación económica, planificar una serie de operaciones y aprender de la experiencia, todo ello en tiempo real, marca un hito significativo.
Trading-R1 no es simplemente un nuevo algoritmo; es un paradigma. Representa el matrimonio entre la «inteligencia» en el sentido de comprensión lingüística y la «inteligencia» en el sentido de acción estratégica y aprendizaje autónomo. El estudio es una demostración clara de que los LLM, más allá de generar poesía o responder preguntas, tienen el potencial de convertirse en agentes activos en los dominios más desafiantes y lucrativos de la economía.
Esta investigación es un llamado a la acción para reguladores, instituciones financieras y la comunidad de IA. Debemos prepararnos para un futuro en el que los mercados estén cada vez más influenciados por inteligencias artificiales que no solo ejecutan órdenes, sino que razonan y aprenden como lo harían sus contrapartes humanas, aunque con una velocidad y escala inalcanzables. La era del trading basado en el razonamiento de la IA no es una especulación lejana; es una realidad que estamos construyendo hoy, con todas sus promesas y sus advertencias. La mente artificial ha llegado a Wall Street, y su impacto será profundo e irreversible.
Referencias
Cai, C., Sun, Y., Lin, Y., Liu, Z., & Chen, G. (2025). Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning (No. arXiv:2509.11420). arXiv. https://arxiv.org/pdf/2509.11420
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., … Zoph, B. (2023, March). Gpt-4 technical report. arXiv. https://doi.org/10.48550/arXiv.2303.08774
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need (No. arXiv:1706.03762). arXiv. https://doi.org/10.48550/arXiv.1706.03762

