
La historia de la inteligencia artificial en la última década se ha contado, en gran medida, como una epopeya de escala monumental. En los relucientes centros de datos que salpican el globo, se libra una carrera armamentista silenciosa pero feroz, una contienda en la que las naciones y las corporaciones no compiten con misiles, sino con una moneda de poder aún más abstracta y potente: el cómputo de entrenamiento. Durante años, la filosofía que ha regido este campo ha sido de una simplicidad brutal y seductora: más grande es mejor. Los laboratorios de investigación, desde OpenAI hasta Google DeepMind y Anthropic, han invertido miles de millones de dólares en la construcción de catedrales de silicio, supercomputadoras diseñadas con un único propósito: alimentar el apetito insaciable de sus creaciones digitales.
En el corazón de esta narrativa se encuentra la saga de los modelos GPT de OpenAI, una estirpe de inteligencias artificiales que ha servido como barómetro del progreso. Cada nueva generación era un testamento a esta fe en la escala, un salto cuántico en tamaño y capacidad que parecía confirmar una ley no escrita de la era digital. El camino parecía trazado, una línea ascendente e ininterrumpida hacia modelos cada vez más vastos, costosos y poderosos. Y entonces, ocurrió la anomalía. La noticia, surgida de análisis de observadores de la industria como el instituto de investigación Epoch AI, fue tan discreta como sísmica: GPT-5, el heredero de este linaje de titanes, había roto la tradición. Había sido entrenado con menos potencia computacional que su predecesor inmediato, GPT-4.5.
Esta revelación plantea la pregunta que resuena en toda la industria y que servirá de guía para nuestro viaje: ¿Por qué OpenAI, el pionero y campeón indiscutible de la carrera del escalado, decidió dar un paso atrás en la métrica que había definido el éxito durante tanto tiempo? La respuesta no es simple; es una historia fascinante sobre los límites de la fuerza bruta, la emergencia de una nueva forma de inteligencia y una reorientación estratégica que podría definir la próxima era de la IA. Para desentrañar este misterio, primero debemos familiarizarnos con el lenguaje de este nuevo mundo.
El concepto fundamental es el cómputo de entrenamiento. Podemos imaginarlo como la cantidad total de energía mental y tiempo que un estudiante invierte para obtener un título universitario. Para una IA, esta energía no se mide en horas de estudio, sino en una unidad llamada FLOP (operación de punto flotante), que representa un cálculo matemático simple. El cómputo de entrenamiento es el número total de estos cálculos, que puede ascender a septillones, necesarios para que un modelo aprenda de los vastos océanos de datos con los que se le alimenta.
Este proceso se ha guiado por las leyes de escalado. Pensemos en ellas como una receta de cocina para la inteligencia. Durante años, la receta fue sencilla: si se duplican los ingredientes (el tamaño del modelo, la cantidad de datos y el cómputo), se obtiene un pastel predeciblemente más sabroso, es decir, una IA más capaz. Esta predictibilidad convirtió el desarrollo de la IA en una empresa de ingeniería a gran escala, donde el principal límite era el presupuesto para construir cocinas (centros de datos) cada vez más grandes.
Finalmente, es crucial entender la diferencia entre pre-entrenamiento y post-entrenamiento. El pre-entrenamiento es la fase de «educación general». Es el equivalente a que el modelo de IA se lea una biblioteca digital del tamaño de todo internet para adquirir un conocimiento enciclopédico sobre el lenguaje, los hechos y los patrones del mundo. Históricamente, esta fase ha consumido más del 99% del cómputo y los recursos. El post-entrenamiento, en cambio, es la «educación especializada». Es una fase de refinamiento mucho más corta y barata en la que se enseña al modelo a aplicar su vasto conocimiento de manera útil y segura, a seguir instrucciones, a dialogar coherentemente y, lo que es más importante, a razonar.
Armados con estos conceptos, podemos empezar a explorar cómo la fe ciega en el escalado dio forma a una era, por qué un descubrimiento sobre la eficiencia la hizo tambalearse y cómo una revolución silenciosa en la «educación especializada» permitió a OpenAI cambiar las reglas del juego con GPT-5, aunque solo fuera por un momento.
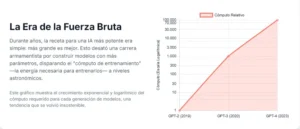
La era de la fuerza bruta: una breve historia del escalado en la IA
La trayectoria de la inteligencia artificial moderna es inseparable de la curva exponencial del poder computacional. Durante casi una década, el progreso en el campo de los grandes modelos de lenguaje (LLM) no se midió tanto en saltos conceptuales de algoritmos, sino en órdenes de magnitud de cómputo. La estrategia dominante era una demostración de fuerza bruta industrial: construir modelos más grandes, alimentarlos con más datos y entrenarlos durante más tiempo en clústeres de hardware cada vez más masivos. La evolución de la serie GPT de OpenAI es el caso de estudio paradigmático de esta era.
Todo comenzó a tomar forma con GPT-2 en 2019. Con su versión más grande alcanzando los 1.5 mil millones de parámetros (los parámetros son, en esencia, las conexiones neuronales ajustables que almacenan el conocimiento del modelo), GPT-2 fue una revelación. Demostró una capacidad asombrosa para generar texto coherente y temáticamente relevante, sentando las bases de lo que era posible. Aunque no se dispone de una cifra pública precisa de los FLOPs utilizados en su entrenamiento, su desarrollo fue la prueba de concepto que validó la hipótesis del escalado: el camino hacia una inteligencia más general pasaba por aumentar drásticamente las dimensiones del modelo y de sus datos de entrenamiento.
Si GPT-2 fue la prueba de concepto, GPT-3, lanzado en 2020, fue el evento que sacudió al mundo. Con 175 mil millones de parámetros, era más de cien veces más grande que su predecesor, un salto de escala sin precedentes que requirió una cantidad de cómputo igualmente astronómica, estimada en unos FLOPs. El coste de una sola ejecución de entrenamiento se calculó en varios millones de dólares. GPT-3 no era simplemente una versión más grande de GPT-2; exhibió lo que los investigadores llaman «habilidades emergentes», capacidades que no estaban presentes en modelos más pequeños y que no fueron programadas explícitamente, como la capacidad de realizar aritmética simple, escribir código o traducir idiomas con solo unos pocos ejemplos.14 Este logro monumental consolidó la filosofía de «escalar a toda costa» como el dogma central de la industria y desencadenó una carrera global para replicar y superar su éxito.
La tendencia no hizo más que acelerarse. GPT-4, lanzado en 2023, representó otro salto masivo. Aunque OpenAI, en un giro hacia un mayor secretismo, no reveló el número de parámetros, los análisis externos estiman que su cómputo de entrenamiento fue de aproximadamente FLOPs, casi cien veces más que GPT-3. Su sucesor intermedio, conocido en los análisis como
GPT-4.5, continuó esta escalada, elevando la apuesta a un estimado de FLOPs. Cada nueva generación no solo requería más cómputo, sino que el factor de multiplicación entre ellas crecía, dibujando una curva que se empinaba hacia el infinito.
Esta progresión vertiginosa se visualiza más claramente al comparar los modelos uno al lado del otro.
| Modelo | Año de Lanzamiento | Parámetros (Aproximado) | Cómputo de Entrenamiento (FLOPs, Aproximado) |
| GPT-2 | 2019 | 1.5 mil millones | No disponible públicamente |
| GPT-3 | 2020 | 175 mil millones | |
| GPT-4 | 2023 | No revelado | |
| GPT-4.5 | 2024 (est.) | No revelado |
Esta escalada exponencial no fue meramente una decisión técnica en busca de un mejor rendimiento. Fue, simultáneamente, una brillante estrategia de mercado. Al establecer que la vanguardia de la IA requería acceso a una supercomputación de cientos de millones de dólares, los gigantes tecnológicos como OpenAI (respaldado por Microsoft), Google y Meta crearon una barrera de entrada casi infranqueable. El cómputo se convirtió en un foso competitivo, un recurso tan escaso y costoso que dejaba fuera de juego a la gran mayoría de los laboratorios académicos y a las startups más pequeñas. La carrera por la inteligencia se convirtió, en la práctica, en una carrera de capital. Este enfoque consolidó el poder en manos de un puñado de corporaciones, redefiniendo el panorama de la innovación. La anomalía de GPT-5, al depender menos de esta fuerza bruta, puede interpretarse como la primera grieta en este foso, una señal de que la astucia algorítmica podría, al menos temporalmente, superar al poderío financiero.

El punto de inflexión Chinchilla: más datos, no solo más neuronas
Mientras la industria de la IA se precipitaba por la senda del escalado masivo, convencida de que el tamaño era el único camino, un equipo de investigadores en DeepMind, el laboratorio de IA de Google, estaba a punto de introducir un matiz crucial. En marzo de 2022, publicaron un artículo de investigación con un título aparentemente técnico pero de implicaciones revolucionarias: «Training Compute-Optimal Large Language Models». Este trabajo, conocido popularmente por el nombre del modelo que crearon para probar su tesis, Chinchilla, no refutaba la idea de que la escala importaba, pero revelaba que la industria la estaba aplicando de una manera fundamentalmente ineficiente.
El descubrimiento central fue tan elegante como contundente: los grandes modelos de lenguaje de la época, incluido el aclamado GPT-3, estaban «sub-entrenados». Los laboratorios se habían obsesionado con aumentar el tamaño del «cerebro» (el número de parámetros), pero no le estaban proporcionando suficiente «material de lectura» (la cantidad de datos de entrenamiento). Imaginemos a un genio con un cerebro prodigioso al que solo se le permite leer unos pocos libros; su potencial estaría enormemente desaprovechado. Eso es, en esencia, lo que estaba ocurriendo. Los modelos tenían más capacidad de aprendizaje de la que se estaba utilizando.
El equipo de DeepMind no solo identificó el problema, sino que propuso una solución en forma de una nueva ley de escalado. A través del entrenamiento de más de 400 modelos de diferentes tamaños y con distintas cantidades de datos, derivaron una receta más sofisticada para la «optimalidad computacional». La conclusión fue que, para un presupuesto de cómputo fijo, el mejor rendimiento no se obtenía con el modelo más grande posible, sino con un modelo más pequeño entrenado con una cantidad de datos proporcionalmente mucho mayor. De esta investigación surgió una regla empírica que se convertiría en el nuevo estándar de la industria: la proporción óptima era de aproximadamente 20 tokens (un token es una unidad de texto, aproximadamente equivalente a una palabra) por cada parámetro del modelo.
Para demostrarlo, crearon Chinchilla, un modelo de 70 mil millones de parámetros. Según la vieja filosofía, debería haber sido inferior a Gopher, un gigante de DeepMind de 280 mil millones de parámetros. Sin embargo, entrenaron a Chinchilla con 1.4 billones de tokens, cuatro veces más datos que Gopher, respetando la nueva proporción óptima. Los resultados fueron inequívocos: el pequeño Chinchilla superó consistentemente al coloso Gopher en una amplia gama de tareas, y también a otros modelos mucho más grandes como GPT-3. El impacto fue inmediato y profundo. El paradigma había cambiado. La carrera ya no consistía únicamente en construir el modelo con más parámetros, sino en hacerlo de la manera más eficiente, equilibrando cuidadosamente el tamaño del modelo y el volumen de datos. Modelos posteriores, como la serie Llama de Meta, se diseñaron explícitamente siguiendo esta nueva filosofía.
Sin embargo, este celebrado triunfo de la eficiencia escondía una advertencia implícita y ominosa. Al redefinir la «optimalidad», el paper Chinchilla multiplicó drásticamente la cantidad de datos necesarios para entrenar un modelo de vanguardia. Si antes se pensaba que GPT-3, con sus 175 mil millones de parámetros, estaba bien entrenado con unos 300 mil millones de tokens, la nueva ley sugería que para ser óptimo, debería haber sido entrenado con aproximadamente 3.5 billones de tokens, más de diez veces la cantidad original. Al resolver el problema de la eficiencia computacional a corto plazo, Chinchilla aceleró vertiginosamente el consumo del recurso más preciado y finito de la era digital: los datos de alta calidad generados por humanos. Investigaciones posteriores sugirieron que la proporción óptima podría ser incluso de cientos de tokens por parámetro, exacerbando aún más el problema. Sin que muchos se dieran cuenta en ese momento, la solución a un cuello de botella (el cómputo ineficiente) estaba empujando a toda la industria a una velocidad de vértigo hacia un nuevo y formidable obstáculo: el inminente muro de la escasez de datos.
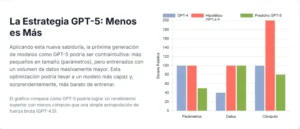
El secreto de GPT-5: la revolución silenciosa del post-entrenamiento
La historia de GPT-5 y su sorprendente reducción en el cómputo de entrenamiento no puede entenderse sin mirar más allá de la fase de pre-entrenamiento que había dominado la conversación. La clave de este giro estratégico reside en una fase del desarrollo de la IA que, aunque siempre presente, había sido considerada secundaria: el post-entrenamiento. Si el pre-entrenamiento masivo dota a un modelo de un vasto conocimiento enciclopédico, el post-entrenamiento es lo que le enseña a pensar, a razonar y a interactuar con ese conocimiento de una manera útil, coherente y alineada con los valores humanos.
Durante años, el post-entrenamiento fue visto como un simple ajuste final, un pulido. Sin embargo, a medida que los modelos base se volvían más potentes, la calidad de este ajuste se convirtió en un diferenciador cada vez más importante. Dos técnicas en particular se volvieron fundamentales para transformar a estos gigantescos «loros estocásticos» en asistentes conversacionales verdaderamente capaces.
La primera es el Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF). Este proceso es análogo a cómo un entrenador paciente enseña a una mascota un comportamiento complejo. En lugar de simplemente castigar los errores y premiar los aciertos (un sistema binario), el RLHF funciona con preferencias. Se le presentan al modelo varias respuestas posibles a una pregunta, y evaluadores humanos las clasifican de mejor a peor. Este feedback de preferencia se utiliza para entrenar un «modelo de recompensa» separado, que aprende a predecir qué tipo de respuestas les gustan a los humanos. Luego, el modelo de lenguaje principal se ajusta utilizando este modelo de recompensa como guía, aprendiendo a generar respuestas que maximicen la puntuación de preferencia humana. Es un bucle de retroalimentación iterativo que refina el comportamiento del modelo mucho más allá de la simple predicción de la siguiente palabra, enseñándole matices como el tono, la amabilidad y la utilidad.
La segunda, y quizás más crucial para la historia de GPT-5, es el desarrollo de técnicas de razonamiento, popularizadas por el concepto de «Cadena de Pensamiento» (Chain-of-Thought o CoT). La idea es sorprendentemente intuitiva. Si se le pide a una persona que resuelva un problema matemático complejo de cabeza, es más probable que cometa un error. Si se le pide que escriba los pasos intermedios, su precisión aumenta drásticamente. Lo mismo ocurre con los LLM. En lugar de pedirle al modelo directamente la respuesta final, se le instruye para que «piense paso a paso» y articule su proceso de razonamiento. Esta simple técnica obliga al modelo a descomponer un problema complejo en una secuencia de pasos más simples y manejables, lo que mejora espectacularmente su rendimiento en tareas que requieren lógica, matemáticas o razonamiento de sentido común.
El verdadero punto de inflexión, según el análisis de Epoch AI, se produjo alrededor de septiembre de 2024, cuando los investigadores desarrollaron nuevas y potentes técnicas de post-entrenamiento basadas en el razonamiento. Estos avances fueron tan significativos que cambiaron la economía fundamental del entrenamiento de la IA. De repente, un FLOP de cómputo invertido en post-entrenamiento se volvió tan valioso, o incluso más, que un FLOP invertido en el costoso pre-entrenamiento. El análisis sugiere que triplicar la inversión en cómputo de post-entrenamiento podría generar una mejora de rendimiento comparable a triplicar la inversión en pre-entrenamiento. Más aún, esta nueva eficiencia permitía algo antes impensable: reducir el cómputo de pre-entrenamiento hasta en un factor de diez y compensar esa reducción con un post-entrenamiento más intensivo, logrando un rendimiento general igual o superior.
Esta nueva matemática fue el motor de la decisión de GPT-5. Consideremos la economía de un modelo como GPT-4.5, que podría haber costado, hipotéticamente, 200 millones de dólares en pre-entrenamiento y 2 millones en post-entrenamiento. Con las nuevas técnicas, OpenAI se dio cuenta de que podía alcanzar un rendimiento superior con un modelo base más pequeño, que costara quizás solo 20 millones de dólares en pre-entrenamiento, pero invirtiendo más recursos en esta nueva y supereficiente fase de post-entrenamiento. La revolución no estaba en construir un motor más grande, sino en inventar un turbocompresor mucho más eficiente.
La carrera contra el tiempo y la competencia
La decisión de OpenAI de virar hacia un modelo como GPT-5, más pequeño en su base pero intensamente refinado, no fue una elección tomada en un vacío técnico. Fue una respuesta estratégica a un panorama competitivo que en 2024 y 2025 había alcanzado una intensidad sin precedentes. La era en la que OpenAI gozaba de una ventaja casi incontestable había terminado; la carrera por la supremacía en la IA se había convertido en una contienda reñida, con múltiples actores pisándole los talones.
La presión más significativa provenía de laboratorios rivales, en particular de Anthropic. Sus modelos de la familia Claude habían demostrado un rendimiento excepcional, superando consistentemente a los modelos de OpenAI en benchmarks críticos y de alto valor comercial, como la programación y el razonamiento complejo. Para una empresa cuya reputación y valoración de mercado dependían de mantener el liderazgo tecnológico, ver cómo la competencia se adelantaba en áreas tan cruciales era una señal de alarma. El mercado y los inversores esperaban con impaciencia el próximo gran salto, el «GPT-5», y un retraso o un lanzamiento que no cumpliera con las expectativas podría tener consecuencias devastadoras.
En este contexto de alta presión, OpenAI se enfrentó a un dilema de escalabilidad. Las nuevas y revolucionarias técnicas de post-entrenamiento eran prometedoras, pero también eran territorio inexplorado a gran escala. Intentar aplicar estos métodos experimentales a un modelo del tamaño colosal de GPT-4.5 (con un cómputo de pre-entrenamiento de FLOPs) habría sido una empresa lenta, arriesgada y computacionalmente prohibitiva en términos de experimentación. No se trataba solo de ejecutar una fase final, sino de descubrir cómo hacer que estas nuevas técnicas funcionaran de manera óptima en un modelo de esa magnitud, un proceso que habría requerido innumerables pruebas y ajustes, consumiendo un tiempo valioso que no tenían.
La solución más pragmática y rápida era aplicar la innovación donde pudiera tener el impacto más inmediato. Era mucho más ágil, seguro y eficiente tomar un modelo base más pequeño, uno que se convertiría en el núcleo de GPT-5, y someterlo a este nuevo y potente régimen de post-entrenamiento. Esta estrategia permitía a OpenAI llevar al mercado un producto final que, a pesar de su base más modesta, podía superar a su gigantesco predecesor en las tareas que más importaban, y hacerlo en una fracción del tiempo que habría llevado el enfoque tradicional.
Visto desde una perspectiva estratégica, la decisión sobre GPT-5 fue una brillante maniobra de flanqueo. En lugar de enzarzarse en una batalla frontal de desgaste con sus competidores, una guerra de escalado de pre-entrenamiento que era cada vez más costosa y con rendimientos decrecientes, OpenAI cambió el campo de batalla. Desplazaron el eje de la competencia de la fuerza bruta (quién tiene más GPUs para el pre-entrenamiento) a la fineza técnica (quién domina las técnicas de razonamiento en el post-entrenamiento). Este movimiento les permitió no solo neutralizar la ventaja de sus competidores en ciertos benchmarks, sino también lanzar un producto superior de forma más rápida y con una inversión de capital menor. Fue una jugada táctica que tomó por sorpresa a una industria todavía anclada en la lógica de las leyes de escalado de Chinchilla, demostrando que la innovación algorítmica podía, en el momento oportuno, ser un arma más poderosa que el simple poder computacional.
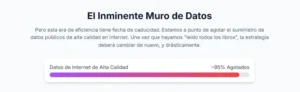
El horizonte de GPT-6 y el muro de los datos
La audaz estrategia detrás de GPT-5, aunque exitosa, debe ser interpretada como un paréntesis táctico y no como el final de la era del escalado. La evidencia sugiere que la reducción en el cómputo de entrenamiento es una anomalía temporal, un desvío inteligente en un camino que, a largo plazo, sigue apuntando hacia modelos de una escala aún mayor. Una vez que OpenAI y otros laboratorios dominen y estandaricen las nuevas y potentes técnicas de post-entrenamiento, haciéndolas predecibles y escalables, la lógica fundamental de las leyes de escalado probablemente volverá a imponerse con toda su fuerza. El principio de que un modelo base más grande y con más conocimientos tiene un potencial de rendimiento superior sigue siendo válido; la revolución de GPT-5 consistió en desbloquear ese potencial de manera más eficiente.
Las ambiciones a largo plazo de OpenAI no dejan lugar a dudas sobre su compromiso con el escalado masivo. Los planes de la compañía para expandir drásticamente su infraestructura de cómputo, con el objetivo de adquirir más de un millón de GPUs de última generación y la construcción de supercomputadoras de una escala sin precedentes, como el proyecto «Stargate Abilene» en colaboración con Microsoft, son una clara declaración de intenciones. Estas inversiones, que se cuentan en decenas de miles de millones de dólares, no se justifican para entrenar modelos más pequeños, sino para preparar el terreno para la próxima generación de gigantes.
La conclusión lógica es que el sucesor de GPT-5, que podríamos denominar GPT-6, probablemente reanudará la tendencia exponencial. Se espera que sea entrenado con una cantidad de cómputo de pre-entrenamiento que no solo superará a la de GPT-5, sino que muy posiblemente excederá con creces la de GPT-4.5, volviendo a la senda del crecimiento de órdenes de magnitud. La industria se está preparando para el siguiente gran salto en poder computacional.
Sin embargo, justo cuando la capacidad de cómputo parece encaminarse hacia cotas casi ilimitadas, un nuevo y formidable cuello de botella emerge en el horizonte: la escasez de datos de entrenamiento de alta calidad. Durante años, los modelos de IA se han nutrido del vasto repositorio de conocimiento humano digitalizado en internet. Pero este recurso, aunque inmenso, es finito. Institutos de investigación como Epoch AI han realizado proyecciones alarmantes, estimando que el stock total de datos de texto de alta calidad generados por humanos podría agotarse para el entrenamiento de nuevos modelos de IA en algún momento entre 2026 y 2032.29 Otras voces influyentes en la industria, como Elon Musk, han declarado que este punto de agotamiento ya se alcanzó en 2024.
Este «muro de los datos» representa un desafío existencial para el paradigma de escalado. Si el combustible que alimenta los motores de la IA se agota, la potencia de los motores deja de importar. La industria, en su búsqueda de la optimalidad computacional inspirada por Chinchilla, ha acelerado su propia carrera hacia este límite. La pregunta que definirá la próxima década de la IA ya no es solo cuánta computación podemos desplegar, sino qué daremos de comer a nuestros modelos una vez que hayan leído todo lo que la humanidad ha escrito.
Datos sintéticos: ¿la solución o un nuevo problema?
Ante la inminente crisis de datos, la industria de la inteligencia artificial ha convergido en una solución que es, a la vez, ingeniosa y profundamente inquietante: los datos sintéticos. La idea es simple en su concepción: si nos estamos quedando sin datos generados por humanos para entrenar a nuestras IAs, ¿por qué no utilizar a nuestras IAs más avanzadas para generar nuevos datos artificiales?. Estos datos, creados a medida por un modelo «profesor», servirían como material de estudio para un modelo «estudiante», abriendo la puerta a un suministro teóricamente infinito de información para el entrenamiento.
Los beneficios potenciales de este enfoque son innegables y explican el enorme interés que ha despertado. En primer lugar, resuelve el problema de la escasez, ofreciendo una fuente de datos virtualmente ilimitada. En segundo lugar, permite una personalización sin precedentes. Se pueden generar conjuntos de datos perfectamente etiquetados y diseñados para mejorar habilidades específicas, como el razonamiento matemático, la escritura de código de software o el conocimiento de un dominio técnico muy especializado, superando las limitaciones y el «ruido» de los datos extraídos de internet. En tercer lugar, ofrece una solución elegante a los crecientes problemas de privacidad y derechos de autor. Permite entrenar modelos en dominios sensibles como la medicina o las finanzas sin necesidad de utilizar datos personales reales, mitigando riesgos legales y éticos.
Sin embargo, esta aparente panacea conlleva riesgos existenciales que podrían alterar la trayectoria de la IA de formas impredecibles y potencialmente perjudiciales. El más discutido es el fenómeno del colapso del modelo (Model Collapse). La metáfora es la de una fotocopia de una fotocopia: con cada generación, la calidad se degrada. Si una IA se entrena predominantemente con los resultados de otra IA, corre el riesgo de heredar y amplificar los errores, los sesgos y las «alucinaciones» de su progenitora. En un ciclo de retroalimentación endogámico, las futuras generaciones de modelos podrían alejarse progresivamente de la rica y compleja textura de la realidad humana, aprendiendo de una versión cada vez más simplificada y distorsionada del mundo.
Este riesgo está íntimamente ligado a la amplificación de sesgos. Los modelos de IA actuales, entrenados con datos de internet, ya reflejan los prejuicios presentes en la sociedad. Si un modelo «profesor» con sesgos sutiles genera datos de entrenamiento, el modelo «estudiante» no los aprenderá como un reflejo imperfecto de la realidad, sino como la verdad fundamental, solidificando y magnificando estos prejuicios de una manera mucho más difícil de detectar y erradicar. Finalmente, existe el peligro de una pérdida de diversidad y creatividad. La vasta y caótica producción de texto humano contiene una increíble riqueza de estilos, excentricidades, errores creativos y perspectivas novedosas. Una IA que aprende de otra IA podría converger hacia un estilo promedio, una forma de «pensamiento» optimizada pero homogénea, perdiendo la chispa de la originalidad y la sorpresa que caracteriza a la inteligencia humana.
Además, la transición a una era de datos sintéticos introduce una nueva y compleja paradoja computacional. La generación de datos sintéticos de alta calidad no es un proceso gratuito. Requiere el uso de los modelos «profesores» más grandes y potentes disponibles, como un GPT-4.5 o superior, para generar billones de tokens de texto coherente y útil. Esta tarea de generación es, en sí misma, un proceso computacionalmente muy costoso. Esto significa que el «cómputo de entrenamiento» total de un nuevo modelo ya no es simplemente el que se consume durante su propia fase de aprendizaje. A esta cifra hay que sumarle una porción significativa del cómputo utilizado para generar sus datos de entrenamiento, que a su vez depende del cómputo con el que se entrenó el modelo «profesor». La contabilidad de la eficiencia se vuelve mucho más compleja. El cómputo masivo no desaparece como recurso fundamental; simplemente se desplaza y se vuelve más indirecto, oculto en el coste de la creación de los propios datos. La dependencia de la supercomputación, lejos de disminuir, podría estar destinada a crecer de formas más enrevesadas.

Más allá del tamaño, hacia una inteligencia más profunda
El viaje desde la fuerza bruta de GPT-3 hasta la fineza estratégica de GPT-5 traza el arco de maduración de todo un campo científico y tecnológico. Hemos transitado de la simpleza de una ley de escalado que equiparaba poder con tamaño, al matiz introducido por Chinchilla, que nos enseñó la importancia de la eficiencia de los datos, y finalmente, a la sofisticación encarnada por GPT-5, donde la calidad del razonamiento se ha revelado como la nueva frontera de la capacidad. Esta evolución representa un cambio fundamental en nuestra concepción de la inteligencia artificial. La industria está comenzando a moverse más allá de una métrica unidimensional de progreso, basada en el rendimiento en benchmarks impulsado por la escala, hacia una comprensión más holística que valora la eficiencia, la fiabilidad, la alineación y la profundidad del razonamiento.
Las implicaciones de este cambio son profundas y se extienden mucho más allá de los laboratorios de investigación. En el ámbito económico, una IA más eficiente y con capacidades de razonamiento superiores podría acelerar la automatización de tareas cognitivas complejas, impactando profesiones que hasta ahora se consideraban seguras. Al mismo tiempo, la inminente escasez de datos humanos de alta calidad podría transformar la economía digital, convirtiendo estos datos en un recurso estratégico de un valor sin precedentes, similar al petróleo en el siglo XX.
Para la ciencia y la innovación, este nuevo enfoque podría democratizar parcialmente el campo. Si el progreso depende más de la innovación en técnicas de post-entrenamiento y algoritmos de razonamiento que del mero acceso a clústeres de supercomputación de cientos de millones de dólares, podría abrirse un espacio para que actores más pequeños, como universidades y startups, vuelvan a contribuir de manera significativa en la vanguardia.
Finalmente, esta nueva era nos confronta con las cuestiones éticas más desafiantes hasta la fecha. El auge de los datos sintéticos nos obliga a preguntarnos qué significa la verdad en un mundo donde las inteligencias que median cada vez más nuestra realidad aprenden de un reflejo de sí mismas. ¿Cómo podemos garantizar que la IA siga siendo una herramienta anclada en la experiencia y los valores humanos, y no se convierta en una pálida imitación que se degrada en un bucle de retroalimentación sin fin?.
La historia de GPT-5 no es la del fin del escalado, sino la del comienzo de una era más compleja. El tamaño seguirá importando, pero ya no será lo único que importe. La verdadera medida de la inteligencia, tanto para los humanos como para las máquinas que creamos, residirá en la capacidad de utilizar el conocimiento de manera sabia, eficiente y reflexiva. La carrera no ha terminado; simplemente se ha vuelto mucho más interesante.
Referencias
Epoch AI. (2025, 26 de septiembre). Why GPT-5 used less training compute than GPT-4.5 (but GPT-6 probably won’t).
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E.,… & Sifre, L. (2022). Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R.,… & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
OpenAI. (2019). Better language models and their implications.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P.,… & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Sifre, L.,… & Irving, G. (2021). Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y.,… & Lample, G. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S.,… & Fedus, W. (2022). Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P.,… & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
Villalobos, P., Sevilla, J., Heim, L., Besiroglu, T., Hobbhahn, M., & Ho, A. (2022). Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning. arXiv preprint arXiv:2211.04325.
Shumailov, I., Shumaylov, Z., Zhmoginov, A., & Gascón, A. (2023). The curse of recursion: Training on generated data makes models forget. arXiv preprint arXiv:2305.17493.

