
En el corazón de la transformación tecnológica actual, una innovación silenciosa está redefiniendo nuestra relación con la inteligencia artificial. No se trata de futuros imaginarios ni de escenarios de ciencia ficción, sino de una realidad tangible que ya está en funcionamiento: un sistema de inteligencia artificial desarrollado por el equipo de Alibaba Tongyi Lab, capaz de procesar información de múltiples fuentes en tiempo real. Este avance no solo representa un salto técnico significativo, sino una evolución fundamental en cómo concebimos la inteligencia artificial. Mientras las primeras generaciones de modelos de IA se centraban en tareas específicas. como generar texto, analizar imágenes o entender el lenguaje hablado, este nuevo enfoque integra estas capacidades en un único sistema coherente, permitiendo a las máquinas comprender el mundo de manera más completa y humana.
La tecnología ya ha transformado industrias clave, desde la medicina hasta la educación, pero este sistema marca un nuevo capítulo en esta evolución. Su capacidad para procesar y relacionar textos, imágenes, sonidos y datos sensoriales no solo mejora la eficiencia de las aplicaciones existentes, sino que abre posibilidades completamente nuevas. Por ejemplo, un médico podría analizar una radiografía mientras lee el historial clínico del paciente, detectando patrones que una herramienta especializada en imágenes o texto por sí sola no capturaría. En el ámbito educativo, un estudiante que tiene dificultades para entender un concepto matemático podría recibir una explicación visual, un audio narrativo y un texto simplificado, todo en una sola interacción. Estas aplicaciones no son hipotéticas: están en desarrollo y representan el futuro inmediato de la tecnología.
Sin embargo, detrás de esta promesa tecnológica hay desafíos profundos. La capacidad de integrar datos multimodales plantea preguntas sobre ética, seguridad y acceso. ¿Cómo evitar que estos sistemas perpetúen sesgos presentes en los datos de entrenamiento? ¿Qué garantías existen para proteger la privacidad cuando procesan imágenes personales o conversaciones auditivas? Estas son preguntas que no solo afectan a los desarrolladores, sino a toda la sociedad. En este artículo, exploraremos no solo cómo funciona este sistema innovador, sino también su impacto en el día a día, sus limitaciones y el camino que debe recorrer para convertirse en una herramienta verdaderamente inclusiva y responsable.
El universo de la inteligencia multimodal: Más allá de la palabra
Para comprender la relevancia de este avance, es esencial primero entender qué es la inteligencia artificial multimodal. Imagina que tu cerebro es un sistema complejo capaz de procesar información a través de los cinco sentidos: ves, oyes, tocas, hueles y saboreas. Cada uno de estos canales aporta una pieza del rompecabezas que es tu percepción del mundo. Hasta hace poco, la IA había sido limitada a uno o dos de estos canales. Los modelos de lenguaje natural, como los que generan textos o responden preguntas, dominaban el ámbito lingüístico, pero carecían de la capacidad para interpretar imágenes o sonidos. Por otro lado, sistemas especializados en visión artificial podían identificar objetos en fotos, pero no entendían el contexto narrativo que rodeaba a esos objetos.
La inteligencia multimodal busca cerrar esta brecha al crear modelos que procesen y relacionen información de distintas fuentes de manera coherente. No se trata simplemente de «añadir» la capacidad de entender imágenes a un modelo de lenguaje, sino de diseñar una arquitectura que permita al sistema extraer significados compartidos entre los datos. Por ejemplo, si un modelo ve una foto de un perro corriendo en un parque y escucha una frase que dice «el perro está feliz», debe ser capaz de conectar ambas piezas de información para inferir que el perro disfruta del momento. Esto requiere una comprensión profunda de cómo los humanos interpretan el mundo, algo que los modelos anteriores no lograban.
Este sistema innovador representa un avance en este campo al integrar tres componentes clave: procesamiento de texto, análisis de imágenes y comprensión auditiva. Estos no funcionan de manera independiente, sino que se complementan en tiempo real. Por ejemplo, si un usuario sube una foto a una aplicación y pregunta «¿qué hay en esta imagen?», el modelo no solo describe lo que ve, sino que también interpreta el contexto. Si la foto muestra una persona sosteniendo un libro en un parque, podría inferir que la persona está leyendo al aire libre y ofrecer recomendaciones relacionadas, como sugerir libros de naturaleza o actividades para disfrutar el entorno.
Este tipo de integración es especialmente útil en aplicaciones prácticas. En el ámbito de la accesibilidad, por ejemplo, el sistema podría actuar como un asistente para personas con discapacidad visual, describiendo con precisión lo que ocurre en su entorno. En lugar de depender de servicios externos o aplicaciones especializadas, el modelo ofrece una experiencia fluida y contextualizada directamente desde el dispositivo que usa la persona. Otra aplicación relevante es en la educación, donde estudiantes con dificultades para comprender conceptos abstractos podrían recibir explicaciones en múltiples formatos: una animación, un audio narrativo y un texto simplificado, todo en una sola interacción.
Pero ¿cómo se logra esto? La clave está en la estructura del modelo. Este sistema utiliza una arquitectura híbrida que combina redes neuronales especializadas para cada tipo de datos con un «núcleo central» que coordina la información entre ellas. Este núcleo actúa como un puente entre las distintas modalidades, permitiendo que el sistema no solo procese cada tipo de dato por separado, sino que también identifique relaciones entre ellos. Por ejemplo, si el modelo analiza una imagen de un edificio y escucha un audio que describe su historia, puede vincular la descripción con características visuales específicas, como la arquitectura o los materiales utilizados.
Además, este sistema está diseñado para ser adaptable. Sus diferentes variantes, como la versión Captioner, Instruct y Thinking, están optimizadas para tareas específicas, pero comparten la misma base tecnológica. Esto significa que, aunque una versión se enfoca en generar descripciones de imágenes, otra puede resolver problemas lógicos o crear contenido creativo, sin necesidad de reiniciar el sistema desde cero. Esta flexibilidad es crucial para su adopción en múltiples sectores, ya que permite a los desarrolladores personalizar el modelo según las necesidades del usuario final.
El avance de este sistema también resalta la importancia de la comunicación natural. En lugar de requerir que los usuarios aprendan a interactuar con la tecnología mediante comandos específicos, el modelo busca entender las intenciones detrás de las preguntas o solicitudes. Por ejemplo, si un usuario dice «¿Qué puedo hacer con esto?», el sistema no solo identifica el objeto en cuestión, sino que también sugiere acciones prácticas, como «puedes usarlo para hacer una manualidad» o «es útil para organizar tu espacio». Esta capacidad de inferencia contextual es lo que hace que la interacción con este sistema se sienta más humana y menos mecánica.
Sin embargo, la complejidad de este enfoque también plantea desafíos técnicos. Procesar múltiples modalidades de información al mismo tiempo requiere una cantidad masiva de datos de entrenamiento y una potencia computacional considerable. Para superar esto, el sistema aprovecha técnicas avanzadas de optimización, como la reducción de la dimensionalidad de los datos y la segmentación inteligente de tareas, lo que permite que funcione de manera eficiente incluso en dispositivos con recursos limitados.
La inteligencia multimodal no es solo una cuestión de tecnología avanzada, sino de crear sistemas que reflejen la forma en que los humanos perciben y comprenden el mundo. Este sistema innovador representa un paso significativo en esta dirección, y su desarrollo abre nuevas posibilidades para la integración de la IA en la vida cotidiana.
Las variantes específicas: herramientas optimizadas para diferentes necesidades
Si bien este sistema se presenta como un todo integral, su verdadero potencial se manifiesta a través de sus variantes especializadas. Cada una está diseñada para abordar necesidades específicas, lo que permite a los usuarios seleccionar la herramienta más adecuada según su contexto. Estas variantes no son simplemente copias del mismo modelo, sino soluciones optimizadas para tareas concretas, manteniendo la coherencia y la precisión que caracterizan a la familia Qwen.
La primera variante destacada es Qwen3-Omni-30B-A3B-Captioner. Su nombre refleja su propósito principal: generar descripciones detalladas de imágenes. Este modelo es especialmente útil en aplicaciones de accesibilidad, donde personas con discapacidad visual requieren información visual en formato de texto. Por ejemplo, si un usuario sube una foto de un museo, el Captioner no solo identifica los objetos presentes, sino que también describe su contexto, como la época histórica del arte o la ubicación geográfica de la obra. Esto va más allá de simples etiquetas (como «pintura» o «escultura») y ofrece una narrativa que enriquece la experiencia del usuario.
El éxito de esta variante radica en su capacidad para capturar matices que otros sistemas podrían pasar por alto. En lugar de limitarse a describir lo que está «en la imagen», el Captioner interpreta relaciones espaciales, emociones y contextos culturales. Por ejemplo, si la foto muestra a una persona caminando por un parque con un perro, el modelo no solo dirá «una persona y un perro», sino que también podría añadir «la persona parece estar disfrutando del día soleado», lo que proporciona una descripción más rica y humana.
Otra variante clave es Qwen3-Omni-30B-A3B-Instruct, diseñada para seguir instrucciones complejas. A diferencia de los modelos genéricos que responden a preguntas simples, este sistema es capaz de procesar solicitudes multifacéticas. Por ejemplo, si un usuario pide: «Crea un resumen de este artículo, incluyendo un breve análisis de su impacto en la sociedad y sugiere tres preguntas para discutir en clase», el Instruct no solo extrae la información principal del texto, sino que también genera una reflexión crítica y propone preguntas educativas. Esto es especialmente valioso en entornos educativos, donde los profesores pueden usar el modelo para crear materiales didácticos personalizados.
La tercera variante, Qwen3-Omni-30B-A3B-Thinking, se centra en la resolución de problemas lógicos y la toma de decisiones. Su nombre hace referencia a su capacidad para «pensar» antes de responder, es decir, para analizar la información de manera estructurada antes de ofrecer una solución. Por ejemplo, si un usuario solicita ayuda para planificar un viaje, el Thinking no solo sugiere destinos, sino que también evalúa factores como el presupuesto, el clima y las preferencias del usuario para ofrecer una recomendación equilibrada. Este enfoque es ideal para aplicaciones en gestión de proyectos, donde la toma de decisiones informadas es crucial.
Aunque estas variantes tienen objetivos específicos, comparten una base tecnológica común que garantiza su coherencia. Esto significa que, por ejemplo, si el Captioner identifica un objeto en una imagen, el Instruct puede usar esa información para generar una respuesta más contextualizada. La integración entre las variantes permite un flujo de trabajo fluido, donde la información procesada por un modelo se alimenta directamente al siguiente, sin necesidad de intermediarios.
Además, la flexibilidad de este sistema se ve reforzada por su capacidad para adaptarse a diferentes niveles de complejidad. En un entorno educativo, un estudiante principiante podría usar la versión Captioner para entender imágenes básicas, mientras que un estudiante avanzado podría aprovechar la versión Thinking para resolver problemas matemáticos complejos. Esta escalabilidad es esencial para garantizar que la tecnología sea accesible para usuarios de todas las edades y habilidades.
Un aspecto particularmente innovador es la capacidad de contexto persistente. Esto significa que, durante una interacción, el modelo mantiene un registro de la conversación y los datos procesados, lo que permite una comprensión más profunda a lo largo del tiempo. Por ejemplo, si un usuario pregunta primero sobre un libro y luego hace una pregunta relacionada con su autor, el sistema no necesita volver a analizar el libro completo, sino que utiliza la información previamente procesada para ofrecer una respuesta más precisa.
Las variantes de este sistema no son solo herramientas especializadas, sino partes de un ecosistema coherente que busca hacer la inteligencia artificial más útil y accesible. Su diseño refleja una comprensión profunda de las necesidades reales de los usuarios, lo que permite que la tecnología se adapte a contextos diversos sin perder su esencia.
Aplicaciones prácticas: De la teoría a la acción
La verdadera prueba de cualquier avance tecnológico radica en su capacidad para resolver problemas reales. En el caso de este sistema innovador, las aplicaciones prácticas son tan variadas como prometedoras, abarcando desde la atención médica hasta la educación, pasando por el entretenimiento y la gestión de recursos. Estas aplicaciones no son teóricas, sino productos de un diseño pensado desde la perspectiva del usuario final, lo que garantiza su utilidad en el día a día.
En el ámbito de la salud, este sistema está revolucionando la forma en que los profesionales de la medicina analizan y comprenden los datos clínicos. Por ejemplo, un radiólogo podría usar la versión Captioner para obtener descripciones detalladas de imágenes médicas, lo que facilitaría la identificación de anomalías. Pero el impacto va más allá: al integrar datos de historiales clínicos, exámenes de sangre y hasta imágenes de resonancia magnética, el modelo puede ofrecer una visión integral de la condición del paciente. Esto no solo acelera el diagnóstico, sino que también reduce el riesgo de errores humanos, ya que el sistema identifica patrones que podrían pasar desapercibidos a simple vista.
Un caso concreto es el uso de este sistema en la detección temprana de enfermedades como el cáncer. Al procesar imágenes de mamografías junto con datos clínicos, el modelo puede identificar signos sutiles que indican la presencia de tumores, incluso en etapas iniciales. Esto es especialmente relevante en regiones con acceso limitado a especialistas, donde la tecnología puede actuar como un aliado para los médicos locales. Además, la capacidad del sistema para generar explicaciones en lenguaje sencillo permite a los pacientes entender sus resultados sin necesidad de un profesional intermedio, fomentando una mayor participación en su propio cuidado.
En el ámbito educativo, este sistema está transformando la forma en que los estudiantes interactúan con el conocimiento. Imagina un alumno que tiene dificultades para entender un concepto matemático. En lugar de leer solo un texto explicativo, podría recibir una explicación visual mediante gráficos, un audio narrativo y un texto simplificado que resalte los puntos clave. Este enfoque multimodal no solo hace el aprendizaje más accesible, sino que también mejora la retención de información, ya que los estudiantes interactúan con el material de múltiples ángulos.
Un ejemplo práctico es el uso de este sistema en aulas con estudiantes con necesidades educativas especiales. Para un niño con dislexia, el modelo puede convertir textos en narraciones auditivas, mientras que para un estudiante con dificultades para entender conceptos espaciales, puede generar diagramas interactivos. Esta adaptabilidad no solo beneficia a los estudiantes individuales, sino que también reduce la carga en los profesores, permitiéndoles enfocarse en la enseñanza personalizada en lugar de gestionar tareas repetitivas.
En el mundo del entretenimiento, este sistema está abriendo nuevas posibilidades para crear experiencias inmersivas. Por ejemplo, una aplicación podría usar la versión Captioner para generar descripciones detalladas de imágenes en tiempo real, lo que sería útil para usuarios con discapacidad visual que quieran disfrutar de contenido visual. Además, al integrar la comprensión auditiva, el sistema podría traducir diálogos de películas o series en texto, permitiendo a personas sordas acceder a contenido que antes era inaccesible.
Otra aplicación innovadora es en la creación de contenido creativo. Un escritor podría usar este sistema para generar ideas basadas en imágenes o sonidos, como crear una historia inspirada en una fotografía de paisaje o desarrollar un guion para un cortometraje a partir de una melodía. Estas herramientas no sustituyen la creatividad humana, sino que actúan como un aliado para explorar nuevas direcciones.
En el mundo empresarial, este sistema está optimizando procesos de gestión y toma de decisiones. Por ejemplo, una empresa podría usar la versión Thinking para analizar datos de ventas y proyectar tendencias futuras, considerando factores como la estacionalidad, el clima y las preferencias del consumidor. Esto permite a los líderes tomar decisiones más informadas y estratégicas, reduciendo el riesgo de errores costosos.
Además, en el sector de la logística, el sistema podría integrar imágenes de camiones, datos de tráfico y pronósticos meteorológicos para optimizar rutas de transporte. Esto no solo ahorra tiempo y combustible, sino que también reduce el impacto ambiental de las operaciones logísticas.
La aplicación más revolucionaria, sin embargo, podría ser en el campo de la sostenibilidad. Este sistema podría procesar imágenes de paisajes afectados por el cambio climático, junto con datos ambientales, para identificar áreas críticas que requieren atención inmediata. Por ejemplo, al analizar imágenes de bosques quemados, el modelo podría sugerir estrategias de reforestación basadas en la biodiversidad local y las condiciones del suelo.
Estas aplicaciones no son meras especulaciones, sino que están en proceso de desarrollo y prueba. Empresas y organizaciones líderes en múltiples sectores están colaborando con los desarrolladores para implementar estas soluciones en entornos reales. El éxito de estas iniciativas dependerá no solo de la tecnología en sí, sino de la colaboración entre ingenieros, expertos en cada campo y usuarios finales para asegurar que las herramientas se adapten a las necesidades reales.
Desafíos y consideraciones éticas: La otra cara de la tecnología
A pesar de sus promesas, el avance de este sistema plantea desafíos significativos que deben abordarse con cuidado. Estos no son obstáculos insuperables, sino aspectos que requieren atención constante para garantizar que la tecnología se utilice de manera responsable y beneficiosa para todos. Uno de los principales problemas es el sesgo en los datos de entrenamiento. Los modelos de IA aprenden a partir de grandes cantidades de información, y si esta información refleja sesgos presentes en la sociedad, el modelo puede perpetuar o incluso amplificar esos sesgos. Por ejemplo, si un sistema de reconocimiento facial ha sido entrenado principalmente con imágenes de personas de un determinado origen étnico, es más probable que cometa errores al identificar a personas de otras etnias.
Este riesgo es especialmente crítico en aplicaciones como la seguridad o la justicia. Un modelo que interpreta imágenes de personas para fines de vigilancia podría discriminar a ciertos grupos si su entrenamiento no es diverso. Para mitigar este problema, es esencial que los desarrolladores implementen protocolos rigurosos de validación y diversificación de datos. Además, es necesario establecer marcos éticos que guíen la aplicación de estos sistemas en contextos sensibles, asegurando que se priorice la justicia y la equidad.
Otro desafío es la protección de la privacidad. Al procesar imágenes, audios y otros datos sensibles, este sistema genera riesgos de exposición de información personal. Por ejemplo, si un usuario sube una foto a una aplicación y el modelo la analiza para generar una descripción, existe la posibilidad de que dicha información sea almacenada o compartida sin el consentimiento explícito del usuario. Este riesgo es especialmente relevante en entornos donde la privacidad es un tema delicado, como en el ámbito médico o educativo.
Para abordar esta cuestión, es fundamental que los desarrolladores adopten medidas de seguridad robustas, como el cifrado de datos y la eliminación automática de información sensible después de su uso. Además, los usuarios deben tener control total sobre qué datos comparten y cómo se utilizan. Esto requiere una transparencia clara sobre los procesos de almacenamiento y uso de datos, así como herramientas que permitan a los usuarios gestionar sus preferencias de privacidad.
Un tercer desafío es la posibilidad de desplazamiento laboral. A medida que sistemas como este se vuelven más avanzados, es posible que algunas tareas tradicionalmente realizadas por humanos sean automatizadas. Por ejemplo, en el campo de la traducción, un modelo de IA podría reemplazar a traductores humanos en ciertos contextos. Aunque esto podría aumentar la eficiencia, también plantea preguntas sobre el valor del trabajo humano y cómo reorientar a los profesionales afectados.
Es importante reconocer que la automatización no necesariamente significa la eliminación de empleos, sino la transformación de roles. Los profesionales podrían centrarse en tareas más creativas y complejas, mientras que los sistemas de IA se encargan de las tareas repetitivas. Sin embargo, para lograr esta transición de manera equitativa, es necesario invertir en programas de capacitación y reentrenamiento para los trabajadores afectados.
Además, existe el riesgo de mal uso de la tecnología. Al igual que cualquier herramienta poderosa, este sistema podría ser aprovechado para crear contenido engañoso, como *deepfakes* de imágenes o audios falsos. Estos casos no solo socavan la confianza en la información, sino que también pueden tener consecuencias graves en áreas como la política o la seguridad. Para prevenir esto, es esencial desarrollar sistemas de verificación y autenticación que puedan detectar contenido manipulado.
La responsabilidad social también es un tema crítico. Los desarrolladores de este sistema tienen un deber ético de garantizar que su tecnología se utilice para el bien común, no solo para maximizar beneficios económicos. Esto implica colaborar con gobiernos, organizaciones no gubernamentales y comunidades afectadas para identificar y abordar problemas sociales concretos. Por ejemplo, en regiones con alta pobreza, el modelo podría ser adaptado para mejorar el acceso a servicios básicos, como la educación o la salud.
Los desafíos asociados con este avance no son obstáculos insuperables, sino oportunidades para mejorar la tecnología y su implementación. La clave está en adoptar un enfoque proactivo, que combine innovación con responsabilidad, para asegurar que la inteligencia artificial beneficie a toda la sociedad, no solo a unos pocos.
El camino hacia el futuro: ¿Hasta dónde podrá llegar?
El desarrollo de este sistema es solo el primer paso en una journey que promete redefinir la relación entre humanos y máquinas. En los próximos años, es probable que esta tecnología evolucione hacia sistemas aún más integrados y accesibles, capaces de funcionar en entornos con recursos limitados y adaptarse a las necesidades individuales de manera dinámica. Uno de los escenarios más prometedores es la integración con dispositivos de realidad aumentada (AR) y realidad virtual (VR). Imagina un mundo donde, al usar gafas AR, un usuario pueda obtener información en tiempo real sobre su entorno: identificar plantas en un parque, traducir carteles en un viaje al extranjero o incluso recibir instrucciones para arreglar un electrodoméstico simplemente mirándolo. Este sistema podría ser el corazón de estas experiencias, procesando información visual y auditiva para ofrecer respuestas contextualizadas.
Otra área de innovación es la interacción con el mundo físico mediante sensores. Con el crecimiento de la Internet de las Cosas (IoT), los dispositivos inteligentes están cada vez más presentes en nuestros hogares y ciudades. Este sistema podría integrarse con estos dispositivos para monitorear y optimizar el consumo de energía, detectar fallas en sistemas de infraestructura o incluso prevenir accidentes en entornos industriales. Por ejemplo, un sistema de sensores en una fábrica podría enviar datos en tiempo real a este modelo, que analizaría la información para identificar patrones que indiquen posibles fallos en la maquinaria, permitiendo una intervención preventiva.
El campo de la medicina personalizada también podría beneficiarse enormemente de esta tecnología. Al combinar datos clínicos, imágenes médicas y registros de estilo de vida, este sistema podría ofrecer recomendaciones personalizadas para la prevención y tratamiento de enfermedades. Por ejemplo, un paciente con antecedentes familiares de diabetes podría recibir un plan de alimentación y ejercicio adaptado a su genética, basado en un análisis integral de sus datos. Este enfoque no solo mejora la eficacia del tratamiento, sino que también fomenta una mayor participación del paciente en su propio cuidado.
Además, la educación podría experimentar una transformación radical. Con este sistema, los estudiantes podrían acceder a entornos de aprendizaje inmersivos, donde las lecciones se adaptan dinámicamente a su ritmo y estilo de aprendizaje. Por ejemplo, un estudiante que tiene dificultades para entender un concepto matemático podría recibir una explicación en formato de juego interactivo, mientras que otro que prefiere el aprendizaje visual podría ver animaciones detalladas. Esta personalización no solo mejora la efectividad del aprendizaje, sino que también reduce la brecha educativa entre estudiantes con diferentes necesidades.
Sin embargo, el futuro de este sistema no está exento de obstáculos. La regulación será un factor crítico. A medida que la tecnología se vuelve más avanzada, los gobiernos y organismos internacionales deberán establecer marcos legales que garanticen su uso responsable. Esto incluirá normas para la transparencia en el entrenamiento de modelos, la protección de datos personales y la prevención de abusos. Además, es necesario fomentar la colaboración internacional para evitar que las regulaciones varíen de un país a otro, lo que podría generar desafíos para la implementación global de estos sistemas.
Otro desafío es la sostenibilidad. El entrenamiento de modelos de IA requiere grandes cantidades de energía, lo que puede contribuir al calentamiento global. Para abordar esto, los desarrolladores deben buscar alternativas más eficientes, como el uso de hardware especializado o la optimización de algoritmos para reducir el consumo energético. Además, es importante promover el uso de fuentes de energía renovable para alimentar los centros de datos donde se entrenan estos modelos.
En el ámbito social, la inclusión será clave. Aunque este sistema está diseñado para ser accesible, es necesario asegurar que las tecnologías emergentes no dejen atrás a las comunidades más vulnerables. Esto implica invertir en infraestructura digital en regiones con acceso limitado, así como en programas de educación y capacitación para que todos puedan aprovechar las ventajas de la tecnología.
El futuro de este sistema es prometedor, pero requiere un enfoque equilibrado que combine innovación, responsabilidad y colaboración. La tecnología no es el fin en sí misma, sino una herramienta para resolver problemas humanos. Con el cuidado adecuado, este sistema podría ser un pilar en la construcción de un mundo más conectado, inclusivo y sostenible.
Reflexión final: La tecnología al servicio de la humanidad
La llegada de este sistema marca un momento histórico en la evolución de la inteligencia artificial. No se trata simplemente de una mejora técnica, sino de un cambio paradigmático en cómo concebimos la relación entre humanos y máquinas. Hasta ahora, la IA ha sido vista como una herramienta para automatizar tareas, pero este avance nos invita a imaginar un futuro donde la tecnología actúa como un socio colaborativo, ampliando nuestras capacidades sin reemplazar nuestra creatividad o empatía.
Este avance refleja una tendencia más amplia en la inteligencia artificial: el enfoque está cambiando de «hacer más» a «hacer mejor». En lugar de buscar modelos cada vez más grandes y complejos, los desarrolladores están priorizando la calidad de la interacción y la capacidad de resolver problemas reales. Este sistema es un ejemplo perfecto de esto, ya que su diseño se centra en la integración de múltiples modalidades de información para ofrecer soluciones prácticas y accesibles.
Sin embargo, el verdadero éxito de este sistema no dependerá solo de su tecnología, sino de cómo la sociedad decide utilizarla. La historia de la innovación tecnológica muestra que los avances más transformadores surgen cuando se alinean con las necesidades humanas y los valores éticos. Por ejemplo, la internet no se convirtió en la herramienta revolucionaria que es hoy solo porque era posible técnicamente, sino porque se adaptó a las necesidades de comunicación y colaboración de las personas. De manera similar, este sistema tendrá éxito si se integra en contextos donde realmente aporta valor, como en la educación, la salud o la sostenibilidad.
Es crucial recordar que la tecnología, por sí sola, no es neutral. Sus efectos dependen de quién la diseña, para quién la diseña y cómo se implementa. Por ello, es imperativo que los desarrolladores, gobiernos y comunidades trabajen juntos para garantizar que este sistema y sus derivados se utilicen de manera responsable y equitativa. Esto incluye la promoción de la diversidad en los equipos de desarrollo, la transparencia en los procesos de entrenamiento y la creación de marcos éticos que guíen su aplicación.
En el fondo, este sistema representa más que un avance tecnológico: es un recordatorio de que la inteligencia artificial debe estar al servicio de la humanidad. No se trata de crear sistemas que nos superen, sino de diseñar herramientas que nos ayuden a ser mejores, más conectados y más compasivos. Con un enfoque equilibrado y una visión clara, esta tecnología podría ser un puente hacia un futuro donde la tecnología y los seres humanos trabajen juntos para construir un mundo más próspero y justo.
Características sobresalientes:
📌 La primera IA omnimodal de código abierto de extremo a extremo que unifica texto, imagen, audio y video en un solo modelo, esto significa que, a diferencia de los modelos multimodales no nativos anteriores que atornillaban el habla o la visión a los modelos de texto primero, Qwen3-Omni integra todas las modalidades desde el principio, lo que le permite procesar entradas y generar salidas mientras mantiene la capacidad de respuesta en tiempo real.
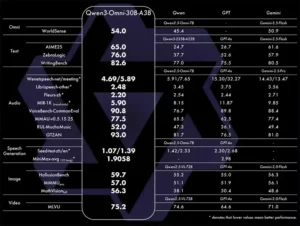
🏆 SOTA en los benchmarks de audio y AV 22/36
🌍 119L texto / 19L entrada de voz / 10L salida de voz
⚡ Latencia de 211 ms. Esto hace que las conversaciones, especialmente los chats de voz y video, se sientan instantáneas y naturales.
🎧 Puede procesar y comprender hasta 30 minutos de audio a la vez, lo que le permite hacer preguntas sobre grabaciones largas, reuniones o podcasts.
🎨 Totalmente personalizable a través de indicaciones del sistema.
🔗 Llamada de herramientas incorporada.
🎤 Modelo de subtitulador de código abierto (¡baja alucinación!).
📌 Contexto y límites
– Duración del contexto: 65,536 tokens en modo de pensamiento; 49,152 tokens en modo no pensante.
– Entrada máxima: 16,384 tokens.
– Producción máxima: 16,384 tokens.
– Cadena de razonamiento más larga: 32,768 tokens.
– Cuota gratuita: 1 millón de tokens (en todas las modalidades), válido durante 90 días después de la activación.
📌 Este modelo desbloqueará casos de uso muy amplios:
– Asistentes de voz a voz en tiempo real para atención al cliente, tutoría o accesibilidad.
– Chat entre idiomas y traducción de voz en 100+ idiomas.
– Transcripción, resumen y subtitulado de audio/vídeo de la reunión (hasta 30 minutos de audio).
– Generación de subtítulos y descripciones para contenido de audio y video.
– Agentes integrados en herramientas que pueden llamar a API o servicios externos.
– Personajes o asistentes de IA personalizados con estilos y comportamientos personalizables.
📌 Tres versiones distintas de Qwen3-Omni-30B-A3B, cada una con diferentes propósitos.
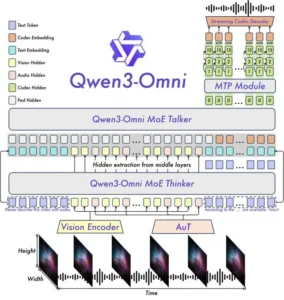
– El modelo Instruct es el más completo, ya que combina los componentes Thinker y Talker para manejar entradas de audio, video y texto y para generar salidas de texto y voz.
– El modelo de pensamiento se centra en las tareas de razonamiento y el procesamiento de la larga cadena de pensamiento; Acepta las mismas entradas multimodales pero limita la salida al texto, lo que lo hace más adecuado para aplicaciones en las que se necesitan respuestas escritas detalladas.
– El modelo Captioner es una variante ajustada creada específicamente para subtítulos de audio, que produce descripciones de texto precisas y de baja alucinación de las entradas de audio.
🧵Precios a través de la API de Qwen3-Omni A través de la API de Alibaba, la facturación se calcula por 1,000 tokens. El modo de pensamiento y el modo de no pensamiento comparten el mismo precio, aunque la salida de audio solo está disponible en el modo de no pensamiento.
📌 Costos de los insumos:
– Entrada de texto: 0,00025 USD por 1K tokens (≈ 0,25 USD por 1 millón de tokens)
– Entrada de audio: 0,00221 USD por 1K tokens (≈ 2,21 USD por 1M de tokens)
– Entrada de imagen/video: $0.00046 por 1K tokens (≈ $0.46 por 1M de tokens)
📌 Costos de salida:
– Salida de texto: 0,00096 USD por 1K tokens (≈ 0,96 USD por 1 millón de tokens) si la entrada es solo de texto 0,00178 USD por 1K tokens (≈ 1,78 USD por 1M de tokens) si la entrada incluye imagen o audio
– Salida de texto + audio: 0,00876 USD por 1K tokens (≈ 8,76 USD por 1M de tokens) — solo la parte de audio; El texto es gratis
🧵Detalles de entrenamiento de Qwen3-Omni
📌 La construcción de Qwen3-Omni se dividió en preentrenamiento y postentrenamiento.
El lado de audio está alimentado por Audio Transformer (AuT). Se entrenó con 20 millones de horas de audio supervisado, principalmente (80%) ASR chino e inglés, más 10% ASR en otros idiomas y 10% de comprensión de audio. El modelo final es un codificador de parámetros de 0,6B que funciona sin problemas en tiempo real y fuera de línea.
El entrenamiento previo se realizó en 3 pasos. Primero, la alineación del codificador donde los codificadores de visión y audio se entrenaron mientras el LLM permanecía congelado. En segundo lugar, un entrenamiento general se ejecuta en aproximadamente 2T tokens, mezclando 0.57T de texto, 0.77T de audio, 0.82T de imágenes y porciones de video más pequeñas. En tercer lugar, una fase de contexto largo que amplió el límite de tokens de 8,192 a 32,768, con más audio y video largos agregados.
Después del entrenamiento afinó ambas mitades de manera diferente.
– El Thinker obtuvo un ajuste fino supervisado, una destilación fuerte a débil y una optimización GSPO utilizando reglas más LLM como juez.
– El Talker pasó por 4 etapas de entrenamiento, alimentado con cientos de millones de muestras de habla multimodal y preentrenamiento continuo en escenarios seleccionados, con el objetivo de reducir las alucinaciones y hacer que el habla sea más natural.
Qwen3-Omni se distribuye bajo Apache 2.0, una licencia flexible que permite el uso comercial, las modificaciones y la redistribución. No obliga a los proyectos derivados a ser de código abierto.
Se incluye una licencia de patente incorporada, lo que ayuda a reducir el riesgo legal al integrarla en sistemas propietarios.
Para las empresas, el modelo se puede agregar libremente a herramientas o servicios sin tarifas de licencia. También se puede adaptar a las necesidades específicas de la industria o a las leyes locales, mientras que las empresas aún se benefician de las mejoras compartidas por la comunidad en general.
Referencias
– Hugging Face. (2023). *Qwen3-Omni Collection*.
– Tongyi Lab. (2023). *Introducing Qwen3-Omni: A New Era of Multimodal Intelligence*.
– European Commission. (2022). *Ethical Guidelines for Trustworthy AI*.
– World Health Organization. (2021). *AI in Healthcare: Opportunities and Challenges*.
– MIT Technology Review. (2023). *The Future of Multimodal AI: From Theory to Practice*.

