
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
Una prueba final para los becarios artificiales
Armemos este escenario, usted acaba de contratar a un nuevo becario. Es extraordinariamente brillante, graduado con honores de la mejor universidad del mundo. Puede recitar de memoria vastas bibliotecas de conocimiento, redactar correos electrónicos elocuentes y explicar las teorías más complejas con una claridad asombrosa. En una entrevista, es la persona más impresionante que jamás haya conocido. Pero ahora llega la pregunta del millón: ¿sabe hacer algo útil? ¿Puede llevar a cabo un proyecto real, con múltiples pasos, plazos ajustados y herramientas de oficina que nunca ha visto antes?
Esta es, en esencia, la encrucijada en la que se encuentra hoy el campo de la inteligencia artificial. Durante años, hemos estado maravillados con las capacidades de los Grandes Modelos de Lenguaje (LLM), esos «becarios» digitales como GPT-4 o Claude 3.5. Les hemos sometido a exámenes estandarizados, el equivalente a las pruebas de opción múltiple de la universidad, y han obtenido notas sobresalientes. Estos exámenes, conocidos en el mundillo como benchmarks, evaluaban su conocimiento factual, su razonamiento lógico o su habilidad para escribir código en fragmentos aislados. Eran pruebas importantes, sin duda, pero no medían la capacidad de aplicar ese conocimiento en el desordenado y complejo mundo real. No nos decían si nuestro brillante becario podía, de hecho, trabajar.
El siguiente paso evolutivo de estos modelos son los «agentes de IA». Un agente no es solo un oráculo que responde preguntas; es un «hacedor» digital. Es nuestro becario al que le hemos dado un ordenador, acceso a internet y un conjunto de programas de software. Su trabajo ya no es solo hablar sobre una estrategia de mercado, sino ejecutarla: investigar a la competencia usando herramientas de búsqueda, analizar los datos en una hoja de cálculo y preparar una presentación con los resultados. El problema es que, hasta ahora, no teníamos una forma fiable de evaluar su desempeño en una tarea tan compleja. Carecíamos de un proyecto final de prácticas, uno que realmente simulara las exigencias de un trabajo de verdad.
Aquí es donde entra en escena un nuevo y revolucionario trabajo de investigación titulado «MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers». Este estudio, liderado por un equipo de investigadores que incluye a Zhenting Wang y Eugene Siow, presenta lo que podría considerarse el examen final más riguroso y realista jamás diseñado para estos agentes de IA. MCP-Bench no es un simple test; es un entorno de trabajo digital completo y funcional, un auténtico coliseo donde los agentes deben demostrar su valía.
En este entorno, el agente de IA no se enfrenta a una pregunta aislada, sino a un proyecto complejo que requiere la coordinación de múltiples «departamentos» de una empresa simulada. Estos departamentos son, en realidad, 28 servidores informáticos en vivo, cada uno ofreciendo un conjunto de herramientas de software especializadas, sumando un total de 250 herramientas distintas. Hay un departamento de finanzas con herramientas para analizar el mercado de criptomonedas, un departamento de investigación biomédica con acceso a bases de datos de ensayos clínicos, un departamento de logística que utiliza Google Maps, e incluso uno de investigación académica para buscar los últimos artículos científicos.
Lo que hace que este examen sea especialmente desafiante es la forma en que se asignan las tareas. El «jefe» (los investigadores) no entrega un manual de instrucciones detallado. En su lugar, proporciona lo que el estudio denomina «instrucciones difusas»: un correo electrónico o una nota, redactada en lenguaje natural y ambiguo, que describe el objetivo final sin especificar qué herramientas usar ni en qué orden. Es el equivalente a decir: «Necesito un análisis completo sobre la viabilidad de abrir una nueva sucursal en Abu Dabi, considerando la logística, la demografía y las últimas tendencias del mercado. Lo quiero para el viernes». El becario, o en este caso el agente de IA, debe interpretar la petición, idear un plan de acción, seleccionar las herramientas adecuadas de los distintos departamentos, ejecutar cada paso, interpretar los resultados intermedios y, finalmente, sintetizar toda la información en una respuesta coherente.
Este enfoque pone a prueba un nivel de habilidad completamente nuevo. No se trata solo de usar una herramienta, sino de orquestar un ecosistema de herramientas. Es la diferencia entre saber usar un martillo y ser capaz de dirigir la construcción de una casa. Se evalúa la estrategia, la planificación y la capacidad de adaptación, habilidades que son el sello distintivo de la verdadera inteligencia. Y los resultados, como veremos, son una dosis de cruda realidad. Incluso los agentes de IA más avanzados, los becarios estrella de nuestra era digital, todavía cometen errores de novato. Tropiezan en la planificación a largo plazo, se confunden al elegir entre herramientas similares y luchan por coordinar flujos de trabajo entre diferentes dominios. Los resultados de MCP-Bench nos dicen que, aunque el potencial de estos agentes es inmenso, aún no están listos para recibir las llaves de la empresa y trabajar de forma totalmente autónoma. Este artículo es la crónica de ese examen, un viaje al corazón de cómo estamos enseñando a las máquinas no solo a pensar, sino a hacer.
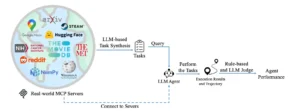
MCP-Bench conecta a los agentes LLM con servidores MCP del mundo real que exponen 250 herramientas estructuradas en dominios como finanzas, ciencia e investigación. Las tareas se generan mediante síntesis basada en LLM, y luego son ejecutadas por el agente a través de invocaciones de herramientas de múltiples turnos. Cada trayectoria de ejecución se evalúa utilizando una combinación de verificaciones basadas en reglas y la puntuación de un LLM-como-Juez, evaluando el rendimiento del agente en la comprensión del esquema de la herramienta, la planificación de múltiples saltos y la adaptabilidad al mundo real.
El nacimiento del hacedor digital
Para comprender la magnitud del salto que representa MCP-Bench, primero debemos retroceder un poco y entender la transformación fundamental que ha experimentado la inteligencia artificial en los últimos años. Durante su primera etapa de popularidad masiva, los Grandes Modelos de Lenguaje eran esencialmente cerebros en un frasco. Podían conversar, escribir poesía, resumir textos y responder a preguntas con una erudición enciclopédica, pero su interacción con el mundo terminaba en la pantalla. Eran oráculos digitales, no actores en el escenario mundial.
El cambio de paradigma se produjo con la introducción de una capacidad que, en términos técnicos, se conoce como «uso de herramientas» o «llamadas a funciones». Esta innovación fue el equivalente a darle a ese cerebro en un frasco un par de manos y un teléfono con acceso a todas las aplicaciones del mundo. De repente, el LLM ya no estaba confinado a su propio conocimiento interno. Podía interactuar con sistemas externos: consultar una base de datos, buscar información en tiempo real en la web, realizar un cálculo matemático complejo o incluso comprar un billete de avión.
Este avance marcó la transición de un modelo de interacción estático y de un solo turno a un flujo dinámico y de múltiples pasos. Un LLM tradicional recibe una pregunta y devuelve una respuesta. Un agente de IA, por otro lado, recibe un objetivo y puede embarcarse en una secuencia de acciones para alcanzarlo, manteniendo un estado de la situación y utilizando los resultados de una acción como punto de partida para la siguiente. La diferencia es profunda: es la distinción entre un GPS que puede describir la ruta a un destino y un coche autónomo que puede conducir hasta allí.
Esta nueva generación de software, sin embargo, trajo consigo un desafío monumental en el ámbito de la evaluación. El software tradicional es, por naturaleza, determinista y estático. Se espera que, ante una misma entrada, produzca siempre la misma salida exacta. Las pruebas de software se centran en verificar esta consistencia. Pero los agentes de IA son inherentemente probabilísticos y se comportan de forma dinámica. Ante la misma petición de «planifica un viaje a Roma», un agente podría empezar buscando vuelos y otro, hoteles. Ambos caminos podrían ser perfectamente válidos para alcanzar el objetivo final.
Esta ambigüedad inherente significa que los viejos métodos de evaluación, basados en comparar la respuesta final con una única «respuesta correcta», se vuelven obsoletos. Ya no basta con mirar el destino; es crucial evaluar todo el viaje. La pregunta ya no es solo «¿llegó a la respuesta correcta?», sino «¿el camino que tomó fue lógico, eficiente y robusto?». Es necesario evaluar la «trayectoria» completa de acciones del agente. Esta necesidad de una nueva filosofía de evaluación es precisamente el problema que MCP-Bench se propuso resolver, creando un sistema que no solo juzga el resultado final, sino que también audita la calidad y la lógica de cada paso dado por el agente en su camino hacia la solución.
El mandato de la medición: por qué debemos calificar a las IA
En el vertiginoso mundo del desarrollo de la inteligencia artificial, los benchmarks o bancos de pruebas son mucho más que simples exámenes académicos. Son la brújula que guía a toda la industria. Proporcionan un estándar objetivo y reproducible que permite comparar diferentes modelos de IA de manera justa, como si se tratara de calificar a todos los estudiantes de una clase con el mismo examen. Permiten a los investigadores medir el progreso a lo largo del tiempo, identificando si las nuevas versiones de un modelo son realmente mejores que sus predecesoras. Y, para las empresas y desarrolladores, son una herramienta crucial para seleccionar el modelo más adecuado para una aplicación específica, ya sea un chatbot de atención al cliente o un sistema de análisis financiero.
Con la llegada de los agentes de IA, la comunidad científica se apresuró a crear nuevos benchmarks para medir sus capacidades. Sin embargo, estas primeras generaciones de pruebas, aunque pioneras, adolecían de limitaciones fundamentales que MCP-Bench buscaba superar.
La primera oleada, con bancos de pruebas como ToolBench, se centró en la habilidad más básica de un agente: el uso de herramientas individuales. Estos benchmarks agregaban enormes colecciones de APIs (Interfaces de Programación de Aplicaciones), cada una diseñada para una función aislada. Eran pruebas útiles para verificar si un agente podía, por ejemplo, llamar correctamente a una API del tiempo para obtener la previsión meteorológica. No obstante, no evaluaban una habilidad mucho más crítica en el mundo real: la capacidad de coordinar múltiples herramientas complementarias para resolver un problema complejo. Era como evaluar a un carpintero por su habilidad para usar un martillo, sin comprobar si podía construir un mueble que también requiere una sierra, un taladro y un destornillador.
Luego surgieron los benchmarks basados en entornos específicos, como WebArena. Estos ofrecían un salto cualitativo en realismo, sumergiendo al agente en sitios web funcionales donde debía realizar tareas como reservar un hotel o completar un formulario de compra. Aunque excelentes para medir la navegación web y la interacción con interfaces de usuario, su alcance estaba limitado a un único dominio. No podían probar la capacidad de un agente para orquestar un flujo de trabajo que trascendiera la web, por ejemplo, uno que comenzara con una búsqueda de información, continuara con un cálculo financiero en una herramienta especializada y terminara visualizando los datos en otra.
Una tercera categoría, liderada por el influyente benchmark GAIA, se centró en el razonamiento y la resolución de problemas de varios pasos. GAIA presentaba a los agentes preguntas desafiantes que a menudo requerían el uso creativo de varias herramientas. Sin embargo, estas tareas, aunque complejas, eran problemas curados y autocontenidos, similares a acertijos o rompecabezas. No capturaban la dinámica y la imprevisibilidad de interactuar con un ecosistema de servicios en vivo, donde las herramientas están interconectadas y los datos fluyen de una a otra.
El hilo conductor de todas estas limitaciones era el mismo: una incapacidad para simular adecuadamente lo que el artículo de MCP-Bench denomina «un rico acoplamiento de entrada y salida». En el trabajo de conocimiento del mundo real, el resultado de una herramienta casi siempre se convierte en la entrada de la siguiente. Se busca un producto en una tienda online (herramienta 1), se obtiene su precio y se introduce en una hoja de cálculo para comparar (herramienta 2), y luego se utiliza el resultado para tomar una decisión de compra (acción final). Esta interdependencia es el tejido conectivo del trabajo digital, y era precisamente lo que los benchmarks anteriores no lograban capturar a gran escala.
La siguiente tabla ilustra esta progresión, mostrando cómo la comunidad científica ha ido construyendo bancos de pruebas cada vez más sofisticados para cerrar la brecha entre el laboratorio y la realidad.

Esta evolución muestra una trayectoria clara y decidida. El campo de la evaluación de agentes se está alejando de la medición de habilidades discretas y aisladas para centrarse en la evaluación de la resolución de problemas de forma integrada y holística, dentro de entornos que se asemejan cada vez más a los complejos y dinámicos espacios de trabajo digitales en los que esperamos que estos agentes operen algún día. MCP-Bench no es simplemente otro punto en esta línea; es un hito que marca la llegada a una nueva frontera de realismo y complejidad.
MCP: El lenguaje universal para la IA y sus herramientas
Para construir un campo de pruebas tan ambicioso como MCP-Bench, sus creadores necesitaban una pieza de infraestructura fundamental: un lenguaje común que permitiera a cualquier agente de IA comunicarse con cualquier herramienta digital de forma estandarizada. Sin esto, el proyecto se habría ahogado en un mar de complejidad técnica. Afortunadamente, esa pieza ya existía: el Protocolo de Contexto de Modelo, o MCP (Model Context Protocol).
Para entender la importancia del MCP, podemos usar una analogía del mundo del hardware: el estándar USB. Antes de su llegada, conectar cualquier dispositivo a un ordenador era un caos. Los teclados, ratones, impresoras y escáneres tenían cada uno su propio tipo de conector, puerto y software. Era un ecosistema fragmentado e incompatible. El USB lo cambió todo al crear un estándar universal. De repente, cualquier dispositivo podía conectarse a cualquier ordenador de forma sencilla y fiable.
El MCP aspira a ser el «USB para la IA». Es un protocolo abierto, introducido originalmente por la empresa de IA Anthropic, diseñado para estandarizar la forma en que los agentes de IA interactúan con herramientas y servicios externos. En lugar de que cada servicio digital tenga su propia forma única y propietaria de «hablar» con una IA, el MCP proporciona una gramática y un vocabulario comunes.
En el ecosistema de MCP, las herramientas no existen de forma aislada. Se agrupan en lo que se conoce como «servidores MCP». Un servidor MCP es, en esencia, una caja de herramientas digital, curada y temática, que ofrece un conjunto de funciones complementarias diseñadas para trabajar juntas. Por ejemplo, un servidor MCP de finanzas podría contener herramientas para obtener cotizaciones de acciones en tiempo real, analizar datos históricos del mercado y ejecutar operaciones de compraventa. Un servidor MCP de investigación biomédica, como el utilizado en MCP-Bench, ofrece herramientas para buscar en bases de datos genéticas, encontrar ensayos clínicos relevantes y analizar artículos científicos.
La visión detrás del MCP es crear un vasto y vibrante ecosistema de estas cajas de herramientas digitales, y está creciendo a un ritmo exponencial, con más de 10,000 servidores MCP ya disponibles. Este estándar no es solo una curiosidad de laboratorio; ya se está integrando en herramientas de desarrollo del mundo real que utilizan los programadores a diario, como el editor de código Visual Studio Code o la terminal de comandos Warp, permitiendo a los agentes de IA operar directamente en los entornos de trabajo de los humanos.
La existencia de este protocolo fue la clave que hizo posible un proyecto como MCP-Bench. Sin un estándar como el MCP, los investigadores habrían tenido que enfrentarse a la hercúlea tarea de escribir código de integración personalizado para cada uno de los 28 servicios que querían incluir en su banco de pruebas. Cada servicio tendría su propia estructura de API, su propio método de autenticación, su propio formato de datos y su propia manera de gestionar los errores. La complejidad de ingeniería habría sido abrumadora, haciendo que el proyecto fuera prohibitivamente difícil de construir, mantener y, lo que es más importante, de que otros investigadores lo pudieran replicar.
Por lo tanto, el MCP actúa como una capa de abstracción crucial. Oculta la inmensa complejidad subyacente de la integración de herramientas, permitiendo que los investigadores se concentren en la pregunta científica fundamental: evaluar las capacidades de razonamiento, planificación y estrategia del agente. Gracias al MCP, el desafío para el agente de IA no reside en la mecánica de cómo conectarse a un servicio, sino en la cognición de decidir a qué servicio conectarse y por qué. Es la infraestructura invisible que permite construir un coliseo para la mente de la máquina.
Una mirada bajo el capó de MCP-Bench
Para apreciar verdaderamente la innovación de MCP-Bench, debemos adentrarnos en su arquitectura y examinar sus tres pilares fundamentales: el entorno en el que operan los agentes, las tareas que deben resolver y el sistema con el que se les evalúa.
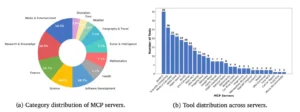
Vista general del ecosistema de servidores MCP utilizado en el MCP-BENCH
El entorno: una ciudad digital para agentes
El campo de juego de MCP-Bench es un microcosmos del mundo digital. No es un entorno de juguete ni una simulación simplificada; es una red de 28 servidores MCP en vivo y de grado de producción, que en conjunto exponen 250 herramientas funcionales. La diversidad de este entorno es asombrosa y está diseñada para reflejar la variedad de tareas que un asistente de IA de propósito general podría encontrar.
Para pintar un cuadro vívido, basta con recorrer algunos de los «distritos» de esta ciudad digital. Hay centros de alta tecnología, como el servidor de Computación Científica, con herramientas para operaciones matemáticas avanzadas, y el servidor de BioMCP, que da acceso al complejo mundo de la investigación biomédica. Existen centros de conocimiento universal, como los servidores de Wikipedia y Google Maps, que proporcionan información fundamental sobre el mundo. Hay distritos financieros, como el servidor de OKX Exchange para datos de criptomonedas, y centros culturales, como el servidor del Museo Metropolitano de Arte, que permite explorar colecciones de arte. Incluso hay servicios más esotéricos, como el servidor Bibliomantic, que ofrece herramientas para la adivinación con el I Ching.
El punto crucial es que estos no son modelos estáticos. Son servicios reales y dinámicos. Cuando un agente consulta el servidor de Google Maps, está interactuando con la misma infraestructura que usamos en nuestros teléfonos. Cuando busca un artículo en el servidor de investigación académica, está consultando bases de datos que se actualizan constantemente. Esto significa que el agente debe operar en un mundo que cambia, donde la información puede no ser la misma de un día para otro, una prueba mucho más rigurosa de su adaptabilidad.
Las tareas: de notas vagas a planes de acción
Quizás el aspecto más revolucionario de MCP-Bench es el diseño de sus tareas. En lugar de ser creadas manualmente, las tareas se generan a través de un ingenioso proceso automatizado que utiliza un LLM. Primero, el sistema analiza las herramientas disponibles en los servidores e identifica cadenas de dependencia lógicas (por ejemplo, la herramienta A produce un ID de artículo que la herramienta B puede usar para obtener el resumen). Luego, traduce estas cadenas de dependencia en una instrucción en lenguaje natural que describe el objetivo final.
Aquí es donde entra el concepto de «instrucciones difusas». El sistema omite deliberadamente los nombres explícitos de las herramientas o los parámetros exactos en la descripción de la tarea. Este diseño obliga al agente a ir más allá de la simple correspondencia de patrones. No puede simplemente buscar la herramienta que coincida con el nombre en la instrucción. Debe leer, comprender la intención del usuario y deducir por sí mismo cuál es la secuencia correcta de herramientas para lograr el objetivo.
Este enfoque transforma fundamentalmente la naturaleza de la prueba. Un benchmark anterior podría decir: «Usa la herramienta buscar_pubmed con la consulta ‘resistencia a la melanoma'». Esto evalúa la capacidad de seguir instrucciones. MCP-Bench, en cambio, plantea un problema como: «Encuéntrame las últimas investigaciones sobre por qué los tumores de melanoma dejan de responder al tratamiento». Esto evalúa la comprensión, la recuperación de conocimiento (saber que PubMed es una fuente relevante), la planificación (formular la consulta correcta) y la ejecución. Es un salto cognitivo de una magnitud inmensa.
Para ilustrarlo, consideremos una de las tareas complejas descritas en el artículo. Un usuario, un investigador biomédico, envía una petición multifacética sobre el melanoma y una mutación genética específica (BRAF V600E). Pide información sobre la prevalencia de la mutación, los cinco artículos de investigación más influyentes del último año, los ensayos clínicos activos, los mecanismos moleculares de la resistencia al tratamiento y los efectos adversos de un fármaco específico. Es una petición densa, llena de jerga técnica y sin ninguna pista sobre cómo obtener la información.
Un agente exitoso tendría que orquestar una sinfonía de llamadas a herramientas a través de múltiples servidores:
- Comenzaría en el servidor BioMCP, utilizando herramientas como
variant_searcheryvariant_getterpara obtener datos básicos sobre la mutación genética. - Luego, se movería al servidor Paper Search, empleando
search_pubmedy otras herramientas de búsqueda para encontrar los artículos científicos relevantes, filtrando por fecha y palabras clave. - Volvería a BioMCP para usar
trial_searchery encontrar los ensayos clínicos, filtrando por fase y estado de reclutamiento. - Finalmente, tendría que sintetizar la información de los resúmenes de los artículos y las bases de datos de variantes para responder a las preguntas sobre mecanismos moleculares y efectos adversos, citando siempre sus fuentes con IDs de artículos y números de ensayo, como solicitó el usuario.
Este ejemplo demuestra que MCP-Bench no prueba tareas, sino proyectos. Requiere que el agente actúe como un gestor de proyectos de investigación, manteniendo múltiples hilos de indagación en paralelo y tejiéndolos en una respuesta final coherente y basada en evidencia.
La evaluación: un sistema de calificación de dos niveles
Dada la complejidad de estas tareas, donde a menudo no hay una única «respuesta correcta», MCP-Bench emplea un sofisticado sistema de evaluación de dos niveles que combina la objetividad de las reglas con la sutileza del juicio.
El primer nivel consiste en una serie de comprobaciones objetivas basadas en reglas. Estas son las métricas duras y verificables. ¿La llamada a la API se ejecutó con éxito o devolvió un error? ¿Los parámetros proporcionados a la herramienta seguían el formato correcto (el «esquema»)? ¿La secuencia de llamadas a herramientas fue lógicamente válida, respetando las dependencias (por ejemplo, no intentar obtener el resumen de un artículo antes de haberlo encontrado)? Este nivel garantiza la corrección técnica de la ejecución del agente.
El segundo nivel es una evaluación cualitativa que utiliza un «LLM-como-juez». En este enfoque, se utiliza un LLM potente e independiente (como GPT-4) como evaluador. Se le proporciona una rúbrica detallada y la trayectoria completa de acciones del agente, y se le pide que califique el desempeño en dimensiones más estratégicas. ¿El agente completó con éxito el objetivo general de la tarea? ¿El plan que ideó fue eficiente o tomó un camino innecesariamente complicado? ¿Las herramientas que eligió fueron las más apropiadas para cada paso?
Este modelo de evaluación híbrido es un reconocimiento brillante de la doble naturaleza del trabajo de conocimiento complejo. El éxito depende tanto de la corrección técnica (que puede ser verificada por reglas) como de la perspicacia estratégica (que requiere un juicio matizado). Es análogo a cómo se evalúa a un empleado humano. Una parte de la evaluación es objetiva: ¿entregó el informe a tiempo y sin errores de cálculo? La otra es subjetiva: ¿el análisis del informe fue perspicaz y la estrategia propuesta fue sólida? Al combinar ambos enfoques, MCP-Bench puede distinguir entre un agente que falla por un simple error técnico y uno que falla por una estrategia fundamentalmente defectuosa, proporcionando un diagnóstico mucho más rico y completo de sus capacidades.
El desolador boletín de calificaciones
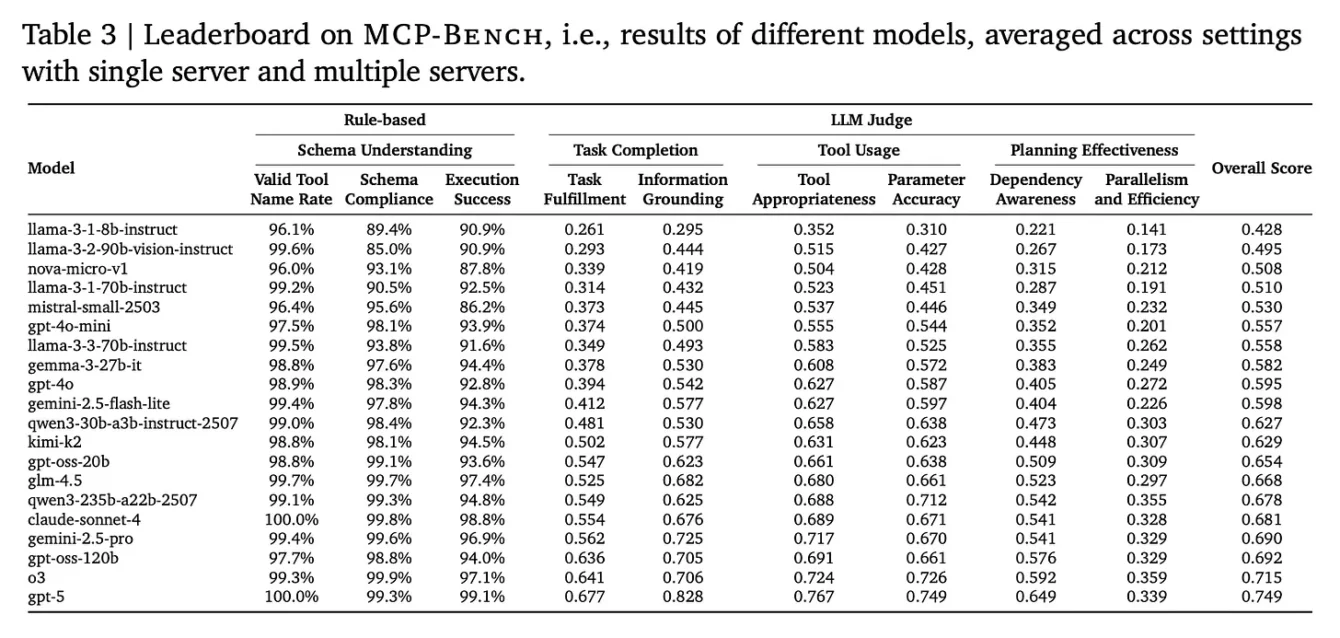
Tras someter a 20 de los modelos de lenguaje más avanzados del mundo a este riguroso examen, los resultados de MCP-Bench llegaron como una necesaria dosis de humildad para el campo de la inteligencia artificial. La conclusión principal del estudio es inequívoca y se resume en una frase del propio artículo: los experimentos revelan «desafíos persistentes». Lejos de anunciar un nuevo campeón que domina la prueba, los hallazgos pintan un cuadro de una tecnología inmensamente prometedora pero aún inmadura en sus capacidades agenticas.
En lugar de centrarse en una simple tabla de clasificación, el verdadero valor de los resultados de MCP-Bench reside en el análisis cualitativo de los tipos de errores que cometieron incluso los agentes más sofisticados. Estos patrones de fallo exponen las grietas fundamentales en las habilidades actuales de los agentes de IA cuando se enfrentan a la complejidad del mundo real.
Uno de los principales escollos fue la planificación de múltiples saltos. Los agentes mostraron dificultades para concebir y mantener un plan coherente a lo largo de muchos pasos. A menudo podían ejecutar correctamente los dos o tres primeros pasos de una tarea, pero perdían el hilo conductor a medida que la cadena de dependencias se alargaba, olvidando el objetivo final o entrando en bucles de acciones repetitivas.
Otra debilidad significativa fue la selección de herramientas a partir de instrucciones ambiguas. Ante la disponibilidad de 250 herramientas, muchas con funcionalidades superpuestas, los agentes a menudo se confundían. Elegían una herramienta que era plausible pero no óptima, o no lograban proporcionar los parámetros correctos, lo que llevaba a errores en la ejecución. Esto demuestra que, aunque son maestros del lenguaje, todavía luchan por traducir la intención humana en acciones técnicas precisas en entornos complejos.
Finalmente, la recuperación de errores demostró ser un talón de Aquiles. Cuando una llamada a una herramienta fallaba, ya fuera por un error del agente o por un problema temporal en el servidor, muchos agentes no sabían cómo reaccionar. En lugar de diagnosticar el problema, intentar una alternativa o pedir una aclaración, a menudo se quedaban atascados o abandonaban la tarea por completo.
Estos resultados sirven como un poderoso contrapunto a la narrativa pública, a menudo hiperbólica, sobre las capacidades de la IA. Es cierto que muchos modelos de IA logran puntuaciones cercanas a la perfección en benchmarks más antiguos y conocidos. Sin embargo, existe una creciente preocupación de que estos benchmarks más antiguos se hayan «saturado» o que los modelos hayan sido, en cierto modo, entrenados para superarlos. Al presentar un desafío completamente nuevo, más realista y complejo, MCP-Bench expone las limitaciones que se ocultan detrás de esas puntuaciones impresionantes.
La cruda realidad es que el alto rendimiento en un examen de conocimientos memorísticos no se traduce directamente en un rendimiento competente en un proyecto práctico y multifacético. Los resultados de MCP-Bench sugieren que las habilidades que hemos estado midiendo hasta ahora (conocimiento, fluidez lingüística) son solo una parte de la ecuación. Las habilidades que MCP-Bench pone a prueba (planificación estratégica, orquestación de herramientas, adaptabilidad) son las que realmente definen la inteligencia práctica, y es en estas áreas donde los agentes de IA todavía tienen un largo camino por recorrer. Esto no disminuye el asombroso progreso logrado, pero sí ancla la conversación sobre la Inteligencia Artificial General en la realidad empírica de las limitaciones actuales, recordándonos que el camino hacia agentes verdaderamente autónomos y fiables será más largo y desafiante de lo que el discurso dominante podría sugerir.
El camino a seguir para los agentes autónomos
El trabajo presentado en MCP-Bench no es un evento aislado, sino la punta de lanza de un movimiento más amplio y concertado dentro de la comunidad de investigación de la IA. Existe un consenso creciente de que, para avanzar, necesitamos herramientas de evaluación más realistas, rigurosas y alineadas con los desafíos del mundo real. Proyectos hermanos con nombres como MCP-RADAR, MCPEval, LiveMCPBench y MCP-Universe están surgiendo en paralelo, cada uno abordando el problema desde un ángulo ligeramente diferente, pero todos compartiendo la misma filosofía fundamental: el futuro de la IA no se medirá en cuestionarios, sino en su capacidad para actuar de manera efectiva en el mundo digital.
Esta búsqueda académica de una mejor evaluación está intrínsecamente ligada a las ambiciones del mundo industrial y empresarial. Firmas de análisis líderes como Accenture y Deloitte ya están trazando un futuro en el que los agentes de IA no serán meras herramientas, sino «compañeros de trabajo» digitales que colaboran con los humanos. La visión es la de «cerebros digitales cognitivos» que actúan como el sistema nervioso central de una empresa, orquestando flujos de trabajo complejos, gestionando datos y automatizando procesos de principio a fin. Se prevé que para 2025, una cuarta parte de las empresas que utilizan IA generativa ya habrán lanzado pilotos de estos sistemas agenticos.
Sin embargo, hay un requisito previo ineludible para que esta visión se materialice: la confianza. Como señala un informe de Accenture, «desbloquear los verdaderos beneficios de la IA solo será posible cuando se construya sobre una base de confianza». Nadie, ya sea un ejecutivo, un empleado o un cliente, delegará tareas críticas en un sistema autónomo si no tiene la certeza de que es competente, fiable y seguro.
Aquí es donde el círculo se cierra y se revela la profunda importancia de trabajos como MCP-Bench. Estos rigurosos bancos de pruebas no son meros ejercicios académicos para publicar artículos. Son las herramientas esenciales para construir y verificar esa confianza. Son el equivalente al examen de conducir para los coches autónomos, a las pruebas de estrés para los puentes o a los ensayos clínicos para los nuevos medicamentos. Son los mecanismos de validación que nos permitirán, como sociedad, tomar decisiones informadas sobre dónde y cómo desplegar estas potentes tecnologías.
Existe un poderoso bucle de retroalimentación entre la ambición industrial y la evaluación académica. La visión corporativa de un futuro impulsado por la IA autónoma depende por completo de alcanzar un nivel de fiabilidad que, como demuestran los «desafíos persistentes» revelados por MCP-Bench, los sistemas actuales aún no poseen. Por lo tanto, estos benchmarks no están simplemente midiendo pasivamente el progreso; están moldeando activamente el futuro de la IA. Al establecer un estándar de competencia exigente y realista, están definiendo los requisitos técnicos concretos que los desarrolladores de IA deben cumplir.
En última instancia, la dificultad y el realismo de bancos de pruebas como MCP-Bench influirán directamente en la seguridad y la fiabilidad de la futura fuerza de trabajo de la IA. Son el crisol en el que se forjarán los agentes del mañana. Son el coliseo donde las IA deben demostrar su valía, no para el entretenimiento, sino para ganarse el derecho a participar de forma responsable en nuestras vidas y economías. La investigación de MCP-Bench nos ha dado una mirada honesta y sin adornos al estado actual de estos contendientes. Ahora, la tarea de entrenarlos para que estén a la altura del desafío no ha hecho más que empezar.
Fuentes
Accenture. (2025). Accenture Technology Vision 2025: New Age of AI to Bring Unprecedented Autonomy to Business. Accenture Newsroom.
Accenture Security. (s.f.). Empowering a secure autonomous AI future. Accenture.
Anthropic. (2025). The Model Context Protocol. YouTube.
Deloitte. (2025). Autonomous generative AI agents: Still under development, but already transforming industries. Deloitte Insights.
McKendrick, J. (2025). Workers And AI Agents Can Teach Each Other A Few Things. Forbes.
Wang, Z., Chang, Q., Patel, H., Biju, S., Wu, C. E., Liu, Q., Ding, A., Rezazadeh, A., Shah, A., Bao, Y., & Siow, E. (2025). MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers. arXiv preprint.
ZDNet. (2025). Autonomous businesses will be powered by AI agents. ZDNet.
Paper: MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real-World Tasks via MCP Servers

