
Vivimos en la era de las máquinas pensantes. Los grandes modelos de lenguaje, o LLM por sus siglas en inglés, se han infiltrado en casi todos los aspectos de nuestra vida digital, realizando proezas que hasta hace poco pertenecían al ámbito de la ciencia ficción. Redactan correos electrónicos, componen poesía, depuran código de programación y mantienen conversaciones con una fluidez casi humana. Esta revolución, sin embargo, se sustenta sobre un pilar cada vez más frágil: un apetito insaciable de poder computacional y energía. La magia tiene un coste, y ese coste está alcanzando niveles insostenibles.
El motor que impulsa esta era dorada de la inteligencia artificial es una arquitectura conocida como Transformer. Su mecanismo central, la autoatención, es a la vez su mayor fortaleza y su talón de Aquiles. Podemos imaginarlo como una reunión de comité donde, para cada decisión, cada miembro debe consultar individualmente a todos los demás. Si el comité tiene diez miembros, las consultas son manejables. Si tiene mil, el número de interacciones se dispara. Este fenómeno, conocido como «escalado cuadrático», significa que a medida que aumenta la longitud del texto que procesa el modelo, el coste computacional se multiplica de forma exponencial. Es el cuello de botella fundamental que impide a estas inteligencias artificiales leer y comprender una novela entera, analizar el historial financiero completo de una empresa o procesar un genoma de una sola vez.
Frente a esta crisis existencial, un equipo de investigadores ha propuesto una solución que no es una simple actualización, sino un cambio de paradigma. Su proyecto, bautizado como SpikingBrain, se inspira en el dispositivo computacional más eficiente que conocemos: el cerebro humano. En lugar de seguir escalando por fuerza bruta, la filosofía de SpikingBrain es emular los principios que la naturaleza ha perfeccionado durante millones de años, como la computación impulsada por eventos, la especialización modular y la memoria comprimida.
Este ambicioso proyecto se erige sobre tres pilares fundamentales que, en conjunto, ofrecen una solución integral. El primero es una arquitectura renovada, que se atreve a mirar más allá del rígido corsé del Transformer para incorporar mecanismos de atención híbridos y neuronas que se comunican mediante impulsos. El segundo es un método de entrenamiento más inteligente, un proceso de «conversión» que recicla el conocimiento de modelos ya existentes con una eficiencia asombrosa. Y el tercero, quizás el más disruptivo, es la demostración de que todo esto puede lograrse a gran escala en plataformas de hardware alternativas a las que dominan el mercado, un paso crucial para diversificar y asegurar el futuro del sector. SpikingBrain no es solo un nuevo modelo; es una declaración de intenciones, un manifiesto que aboga por una inteligencia artificial más eficiente, sostenible y, en última instancia, más inteligente.
Rompiendo las cadenas del Transformer
Para comprender la magnitud de la innovación que propone SpikingBrain, es imprescindible analizar en profundidad las limitaciones técnicas que busca superar. La arquitectura Transformer, a pesar de su éxito, arrastra una pesada carga computacional. Su problema fundamental reside en cómo gestiona la información contextual. El coste de su entrenamiento no solo crece, sino que se dispara de forma cuadrática con la longitud de la secuencia de datos, una relación matemática expresada como . Al mismo tiempo, la memoria necesaria para que el modelo funcione y genere respuestas, un proceso conocido como inferencia, aumenta de manera lineal ().
Estos no son meros detalles técnicos; son las barreras que definen lo que la inteligencia artificial puede y no puede hacer hoy en día. El escalado cuadrático significa que duplicar la longitud de un texto no duplica el coste de procesarlo, sino que lo cuadruplica. Procesar un documento diez veces más largo requiere cien veces más computación. Esta es la razón por la que, a pesar de su aparente omnisciencia, los LLM actuales tienen dificultades para manejar contextos extensos. Tareas como resumir un libro completo, analizar un expediente legal de miles de páginas o mantener una conversación coherente durante horas siguen estando, en gran medida, fuera de su alcance práctico.
Esta ineficiencia estructural ha generado consecuencias que trascienden el ámbito puramente tecnológico. Ha creado un foso económico y medioambiental en torno a la vanguardia de la inteligencia artificial. El desarrollo y la operación de estos modelos colosales exigen inversiones de miles de millones de dólares en clústeres de unidades de procesamiento gráfico (GPU) y en las facturas de electricidad para alimentarlos y refrigerarlos. Estos costes exorbitantes concentran el poder en manos de un puñado de corporaciones tecnológicas con recursos casi ilimitados, creando una alta barrera de entrada para la academia, las startups y los países con menor capacidad de inversión. Al mismo tiempo, la huella de carbono de la industria no deja de crecer, planteando serias dudas sobre la sostenibilidad de este paradigma a largo plazo.
El enfoque de SpikingBrain, centrado en la eficiencia, representa un desafío directo a este modelo. No se trata solo de optimizar el rendimiento, sino de redefinir los fundamentos económicos y ecológicos del campo. Al proponer una arquitectura cuyo coste computacional escala de manera lineal, o casi lineal, con la longitud del texto, se abre la puerta a una nueva generación de modelos capaces de procesar información a una escala previamente inimaginable, pero con una fracción de los recursos. Es una apuesta por una inteligencia artificial más democrática y sostenible, donde el ingenio arquitectónico prevalezca sobre la fuerza bruta computacional.
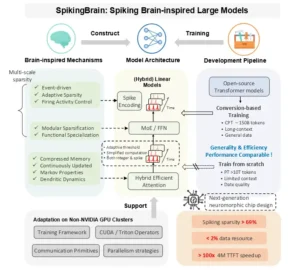
Descripción general de SpikingBrain. Inspirado en los mecanismos cerebrales, SpikingBrain integra atención eficiente híbrida, módulos MoE y codificación de picos en su arquitectura, respaldada por un flujo de conversión universal compatible con el ecosistema de modelos de código abierto. Esto permite un preentrenamiento continuo con menos del 2% de los datos, a la vez que se logra un rendimiento comparable al de los modelos de código abierto convencionales. Adaptamos aún más los marcos, operadores, estrategias paralelas y primitivas de comunicación para clústeres que no son NVIDIA (MetaX), lo que garantiza un entrenamiento e inferencia estables a gran escala. SpikingBrain alcanza una aceleración de más de 100 veces en TTFT para secuencias de 4 millones de tokens, mientras que el espigado ofrece una escasez de más del 69% a nivel micro. Combinados con la escasez de MoE a nivel macro, estos avances proporcionan una valiosa guía para el diseño de chips neuromórficos de próxima generación.
La arquitectura de la eficiencia: un viaje al interior de SpikingBrain
El corazón de la propuesta de SpikingBrain reside en un rediseño fundamental de sus componentes internos, abandonando la rigidez del Transformer por una estructura más flexible y biológicamente inspirada. Esta nueva arquitectura es una amalgama de mecanismos inteligentes que buscan emular la eficiencia del cerebro en lugar de la potencia de un superordenador.
Una manera más inteligente de prestar atención
El principal cuello de botella del Transformer, la autoatención, es el primer elemento que SpikingBrain deconstruye y reinventa. En lugar de depender exclusivamente del costoso mecanismo de atención completa o softmax, donde cada palabra se compara con todas las demás, SpikingBrain implementa un sistema híbrido que combina varias estrategias más eficientes.
La primera es la atención de ventana deslizante (SWA, por sus siglas en inglés). Este mecanismo funciona como una especie de «memoria local», donde cada palabra solo presta atención a sus vecinos más inmediatos dentro de una ventana de tamaño fijo. Es una solución pragmática y muy eficiente para capturar patrones y relaciones locales, aunque por sí sola podría pasar por alto conexiones a larga distancia en un texto.
La segunda, y más radical, es la atención lineal. Este enfoque representa una ruptura total con la idea de revisar constantemente el historial completo. En su lugar, el modelo mantiene un «estado» o resumen comprimido del pasado que se actualiza continuamente con cada nueva palabra. En lugar de volver a leer todo el documento en cada paso, simplemente consulta este resumen en constante evolución. Esta es la clave para lograr un uso de memoria constante durante la inferencia, sin importar cuán largo sea el texto de entrada.
La genialidad de SpikingBrain radica en cómo combina estos mecanismos. No opta por una solución única, sino que las hibrida de forma inteligente para obtener lo mejor de cada una. Para ello, explora dos estrategias principales. El modelo SpikingBrain-7B utiliza un enfoque «inter-capa», apilando diferentes tipos de atención como si fueran los pisos de un edificio. Una capa puede usar atención lineal para capturar el contexto global, mientras que la siguiente puede usar SWA para refinar los detalles locales. Por otro lado, el modelo SpikingBrain-76B emplea una estrategia «intra-capa» en paralelo. Aquí, la información se procesa simultáneamente a través de diferentes mecanismos de atención, y sus resultados se fusionan, permitiendo al modelo sopesar dinámicamente la importancia de la información local y global en cada paso del procesamiento.
Un equipo de especialistas: el poder de MoE
La segunda gran innovación arquitectónica es la incorporación de una estructura de Mezcla de Expertos (MoE, por sus siglas en inglés) en el modelo más grande, SpikingBrain-76B. En lugar de construir una única red neuronal monolítica y gigantesca, el enfoque MoE se asemeja más a la organización de una gran empresa. Imagine que, en lugar de tener un único director general que debe responder a cada pregunta, desde finanzas hasta marketing, la empresa cuenta con departamentos especializados. Un «enrutador», que actúa como un recepcionista inteligente, dirige cada consulta al departamento correcto, es decir, al «experto» más adecuado para manejarla.
Así funciona SpikingBrain-76B. Aunque el modelo tiene un conocimiento total equivalente a 76 mil millones de parámetros, para procesar cada palabra o token solo activa un subconjunto de estos, aproximadamente 12 mil millones de parámetros. Esto permite que el modelo posea una vasta base de conocimientos especializados sin incurrir en el coste computacional de utilizarla toda a la vez. Es una forma de escalar la capacidad del modelo manteniendo la eficiencia.
En conjunto, estas decisiones arquitectónicas reflejan un profundo cambio filosófico. Se alejan de la idea de una «inteligencia de fuerza bruta», donde el modelo intenta saberlo todo en todas partes y en todo momento, para acercarse a una «inteligencia estructurada y eficiente», que sabe dónde y cómo buscar la información correcta. La autoatención del Transformer tradicional es indiferenciada; es poderosa, pero ineficiente. Las arquitecturas de SpikingBrain introducen estructura, jerarquía y especialización. La SWA impone un sesgo de localidad, la atención lineal crea un estado de memoria comprimido y el MoE fomenta la especialización funcional.
Este diseño no es una simple colección de trucos de optimización; es un argumento implícito de que el camino hacia una inteligencia artificial más capaz y escalable reside en la creación de modelos con estructuras internas más sofisticadas, inspiradas en la propia organización del cerebro. El cerebro humano no procesa toda la información sensorial con toda la corteza cerebral de forma simultánea; posee regiones especializadas para la visión, el lenguaje o la planificación, y mecanismos complejos para dirigir el foco de atención. SpikingBrain, a su manera, intenta seguir esa misma senda de especialización y eficiencia.
El secreto está en el pulso: neuronas que imitan la vida
Más allá de la reorganización de la atención y la estructura general del modelo, SpikingBrain introduce un cambio aún más fundamental a nivel microscópico: la naturaleza de sus neuronas. Se adentra en el campo de las redes neuronales de impulsos (SNN, por sus siglas en inglés), una aproximación que busca imitar más fielmente el modo en que las neuronas biológicas se comunican.
Mientras que las neuronas artificiales tradicionales operan con valores continuos, análogos a un regulador de intensidad de luz que puede adoptar cualquier valor en un rango, las neuronas de impulsos o spiking funcionan con eventos discretos, como un interruptor de luz que solo puede estar encendido o apagado. Estas neuronas se comunican mediante «impulsos» o «spikes» que se emiten solo cuando su potencial de membrana interno alcanza un cierto umbral. Este paradigma es intrínsecamente más eficiente desde el punto de vista energético, ya que la computación y la comunicación solo ocurren cuando se produce un impulso, permaneciendo el sistema inactivo el resto del tiempo.
La innovación del umbral adaptativo
Una de las innovaciones cruciales de SpikingBrain en este ámbito es el desarrollo de las «neuronas de impulsos con umbral adaptativo». En modelos más simples, el umbral de disparo de una neurona () es un valor fijo. Esto puede generar problemas: un umbral demasiado bajo puede hacer que la neurona dispare constantemente, generando ruido e ineficiencia, mientras que un umbral demasiado alto puede provocar que nunca se active, volviéndola inútil.
La solución de SpikingBrain es hacer que este umbral sea dinámico y se correlacione con el potencial de membrana reciente de la propia neurona. Es como si cada neurona tuviera un control de volumen automático. Si recibe muchas señales de entrada y está muy activa, su umbral aumenta para volverse más selectiva. Si, por el contrario, está inactiva, su umbral disminuye para ser más sensible a las señales entrantes. Este mecanismo de autorregulación garantiza que las neuronas se mantengan en un estado de actividad equilibrado y moderado, lo que permite preservar la información relevante mientras se maximiza la «dispersión» (el número de momentos en que la neurona está en silencio), que es la clave de la eficiencia energética.
El lenguaje de los impulsos: esquemas de codificación
Una vez que una neurona decide disparar, el modelo necesita una forma de traducir el nivel de activación interno en una secuencia de impulsos a lo largo del tiempo. Para ello, SpikingBrain explora tres esquemas de codificación, cada uno con sus propias ventajas.
- Codificación binaria ({0,1}): Es el método más simple. Un impulso (1) representa una unidad de activación. Para representar un valor alto, la neurona debe emitir muchos impulsos a lo largo de varios pasos de tiempo. Es intuitivo, pero puede ser lento e ineficiente para valores de activación elevados.
- Codificación ternaria ({-1,0,1}): Este esquema añade un tercer estado: el impulso «inhibitorio» (-1). Esto lo hace mucho más expresivo y se alinea mejor con la biología, donde existen neuronas excitatorias e inhibitorias. La capacidad de emitir impulsos negativos permite representar valores de forma más compacta, reduciendo a la mitad tanto los pasos de tiempo necesarios como la tasa de disparo total en comparación con la codificación binaria.
- Codificación por bits: Es el formato más comprimido y eficiente. En lugar de emitir un impulso por cada unidad de activación, este método codifica el valor numérico de la activación en su representación binaria a lo largo del tiempo. Por ejemplo, para representar un valor de 255, la codificación binaria necesitaría 255 pasos de tiempo. La codificación ternaria necesitaría unos 128. La codificación por bits de 8 bits, sin embargo, solo necesitaría 8 pasos de tiempo, uno por cada bit. Esta compresión temporal reduce drásticamente la comunicación entre neuronas y la carga computacional.
Este enfoque dual, que combina la eficiencia de las neuronas de impulsos con la flexibilidad de diferentes esquemas de codificación, se complementa con una estrategia de implementación pragmática. Los investigadores reconocieron que las GPU actuales, diseñadas para cálculos masivos en paralelo y síncronos, no son el hardware ideal para la computación asíncrona e impulsada por eventos de las SNN. Por ello, idearon un proceso en dos pasos: durante el entrenamiento, la dimensión temporal se colapsa y las activaciones se tratan como simples recuentos de impulsos enteros, lo que permite aprovechar la potencia de las GPU. Sin embargo, durante la inferencia, estos recuentos enteros pueden «re-expandirse» en secuencias de impulsos dispersas, preparadas para ejecutarse con una eficiencia energética masiva en futuros chips neuromórficos diseñados específicamente para este tipo de computación.
Esta estrategia es un puente pragmático entre el hardware de hoy y el de mañana. Permite que la tecnología sea viable y ofrezca beneficios tangibles en la actualidad, al tiempo que la posiciona para capitalizar las enormes ganancias de eficiencia que promete la próxima generación de hardware de inteligencia artificial.
Entrenar a un gigante con la agilidad de un colibrí
Uno de los aspectos más disruptivos del proyecto SpikingBrain no es solo qué construyeron, sino cómo lo hicieron. En una era definida por la necesidad de conjuntos de datos de tamaño astronómico y meses de entrenamiento en superordenadores, el equipo adoptó un enfoque radicalmente más eficiente: el entrenamiento basado en la conversión, o «upcycling».
La revolución del reciclaje: entrenamiento basado en la conversión
El dato más revelador de esta estrategia es el siguiente: todo el proceso de entrenamiento de los modelos SpikingBrain consumió aproximadamente 150 mil millones de tokens. Esta cifra, aunque enorme en términos absolutos, es minúscula en comparación con los más de 10 billones de tokens que suelen ser necesarios para entrenar desde cero un modelo de tamaño similar. Esto representa un ahorro de recursos superior al 98%.
Este logro es posible gracias a un principio fundamental que los investigadores denominan «correspondencia de mapas de atención». La idea subyacente es que las formas de atención más eficientes, como la atención lineal y la de ventana deslizante, no son conceptualmente ajenas a la atención softmax tradicional. Matemáticamente, pueden considerarse aproximaciones de bajo rango o dispersas del mapa de atención original. Esta base común permite hacer algo que parece casi un truco de magia: tomar un modelo Transformer ya entrenado y de código abierto (en este caso, Qwen2.5-7B), y «convertir» o adaptar sus pesos ya aprendidos a la nueva y eficiente arquitectura de SpikingBrain con un reentrenamiento mínimo. En lugar de enseñar al modelo a entender el lenguaje desde cero, se aprovecha el conocimiento ya codificado en sus redes y se le enseña a expresarlo a través de una estructura más eficiente.
El reciclaje de MoE
Esta filosofía de reciclaje se extiende también a la creación del modelo de Mezcla de Expertos. Para construir el colosal SpikingBrain-76B, en lugar de entrenar a cada uno de los 16 «expertos» desde cero, los investigadores replicaron los pesos de la red neuronal de avance (FFN) del modelo base en cada uno de los expertos al inicio del proceso.
Podemos visualizarlo como clonar el conocimiento de un experto generalista para crear un equipo de especialistas. Al principio, todos los especialistas son idénticos y poseen el mismo conocimiento general. Sin embargo, durante el corto proceso de entrenamiento de conversión, el ruido en los datos y el enrutamiento estocástico hacen que cada experto reciba señales de error (gradientes) ligeramente diferentes. Estas pequeñas diferencias, acumuladas a lo largo del entrenamiento, hacen que los expertos diverjan gradualmente y desarrollen sus propias especializaciones únicas. Es una forma increíblemente eficiente de poner en marcha un potente modelo de expertos sin el coste prohibitivo de entrenarlo desde sus cimientos.
Las implicaciones de este paradigma de «upcycling» son profundas y podrían democratizar fundamentalmente el acceso a la inteligencia artificial de vanguardia. Reenmarca el desarrollo de nuevas arquitecturas no como una tarea monumental de «creación desde la nada», que requiere una inversión masiva de capital y recursos computacionales, sino como un proceso ágil de «adaptación inteligente».
Entrenar un modelo con diez billones de tokens es una hazaña reservada para un puñado de gigantes tecnológicos globales. Sin embargo, la capacidad de lograr un rendimiento comparable al reentrenar un modelo de código abierto con solo 150 mil millones de tokens, una tarea dos órdenes de magnitud menor, reduce drásticamente la barrera de entrada. Esto significa que universidades, laboratorios de investigación más pequeños y startups pueden ahora experimentar, innovar y construir sobre modelos de última generación, adaptándolos a nuevas y eficientes arquitecturas como SpikingBrain. Este enfoque podría catalizar una explosión de innovación en el diseño de arquitecturas de IA, rompiendo la dependencia de unos pocos actores dominantes para definir el futuro del campo.
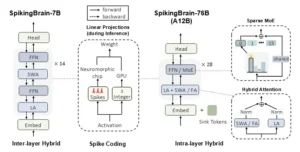
Arquitecturas integradas de los modelos SpikingBrain. FA: Atención Softmax completa; SWA: Atención de ventana deslizante; LA: Atención lineal. (Izquierda) SpikingBrain-7B es un modelo lineal con hibridación entre capas. (Centro) La codificación de picos convierte las activaciones en conteos enteros para la ejecución en GPU o en trenes de picos para hardware neuromórfico controlado por eventos. (Derecha) SpikingBrain-76B es un modelo híbrido-lineal de MoE con hibridación intracapa, configurado con 128 tokens de sumidero, 16 expertos enrutados y un experto compartido. Siete FFN densas se ubican en las capas [1, 2, 3, 5, 7, 9, 11], y todas las demás FFN se implementan como capas de MoE. Los módulos de atención se organizan como «LA + FA» en las capas [7, 14, 21, 28] y «LA + SWA» en las demás capas.
Un nuevo ecosistema de hardware: el desafío a la hegemonía tecnológica
Quizás uno de los logros más significativos y estratégicos del informe técnico de SpikingBrain es dónde se llevó a cabo este ambicioso proyecto. En un ecosistema de inteligencia artificial donde la gran mayoría del desarrollo y la investigación están intrínsecamente ligados a un único proveedor de hardware, el equipo de SpikingBrain demostró la viabilidad de su enfoque en una plataforma alternativa. Ambos modelos fueron entrenados de principio a fin en un clúster de cientos de GPU MetaX C550, una plataforma no perteneciente a NVIDIA.
Este hecho no es una anécdota, sino un hito. Demuestra que el entrenamiento estable y a gran escala de modelos con miles de millones de parámetros es factible fuera del ecosistema dominante. El informe detalla que el entrenamiento se mantuvo estable durante semanas, un requisito indispensable para proyectos de esta envergadura y una prueba de la madurez de la plataforma MetaX.
El desafío de la ingeniería
Lograr este hito no fue una tarea sencilla. El informe dedica una sección completa a detallar el inmenso guantelete de desafíos de ingeniería que tuvieron que superar, dejando claro que no se trataba de una simple portabilidad de código.
Para el entrenamiento distribuido de los complejos modelos MoE, implementaron optimizaciones específicas, como la «optimización de expertos fríos y calientes», que replica localmente los expertos más utilizados para reducir la congestión en la red de comunicación, o la «recomputación adaptativa», que recalcula ciertas activaciones para ahorrar memoria cuando un experto está sobrecargado.
La adaptación de los operadores de software, el código que ejecuta las operaciones matemáticas fundamentales, requirió un enfoque en dos frentes. Por un lado, adaptaron los núcleos de alto nivel escritos en Triton, un lenguaje de programación para computación de alto rendimiento. Por otro, migraron el código de bajo nivel escrito en CUDA, el lenguaje propietario de NVIDIA, al marco de trabajo nativo de MetaX, conocido como MACA.
Finalmente, orquestar el entrenamiento a través de cientos de GPU exigió el diseño de topologías de paralelismo complejas, una coreografía precisa que combinaba múltiples estrategias: paralelismo de datos (dividiendo los datos entre las GPU), paralelismo de pipeline (dividiendo el modelo en etapas), paralelismo de expertos (distribuyendo los expertos MoE) y paralelismo de secuencia (dividiendo las secuencias de texto largas).
El éxito de este esfuerzo de ingeniería es tanto una declaración tecnológica como geopolítica. Sirve como una prueba de concepto para un ecosistema de inteligencia artificial viable e independiente. En un momento en que la concentración del mercado de hardware de IA y las tensiones en la cadena de suministro global son motivo de creciente preocupación, la validación de una alternativa robusta podría remodelar el mercado global. Fomenta la competencia, impulsa la innovación y mitiga los riesgos asociados a una monocultura tecnológica. Al demostrar que es posible, el proyecto SpikingBrain no solo ofrece un nuevo tipo de modelo de lenguaje, sino que también proporciona un plan y una validación para otros que busquen construir un futuro de la inteligencia artificial más diverso y resiliente.
Los frutos del ingenio: rendimiento sin concesiones
Las ganancias en eficiencia serían una mera curiosidad académica si no vinieran acompañadas de un rendimiento sólido. La prueba de fuego para SpikingBrain era demostrar que sus arquitecturas inspiradas en el cerebro no solo eran eficientes, sino también potentes. Los resultados presentados en el informe técnico confirman que, en gran medida, han superado este desafío.
Compitiendo con los gigantes: rendimiento en benchmarks
La credibilidad de cualquier nuevo modelo de lenguaje se mide en su capacidad para competir en una serie de bancos de pruebas estandarizados que evalúan el razonamiento, el conocimiento general y la comprensión del lenguaje. En este frente, los modelos SpikingBrain demuestran ser contendientes serios.
El modelo SpikingBrain-7B, a pesar de su arquitectura lineal, alcanza un rendimiento comparable al de modelos Transformer avanzados y muy respetados como Mistral-7B y Llama3-8B. Esto indica que, con las estrategias de entrenamiento adecuadas, las arquitecturas de atención lineal pueden preservar una notable capacidad de modelado de propósito general. Por su parte, el modelo híbrido y de Mezcla de Expertos, SpikingBrain-76B, prácticamente cierra la brecha de rendimiento con su modelo base y se muestra competitivo frente a gigantes como Llama2-70B y Mixtral-8x7B, a pesar de activar un número significativamente menor de parámetros por token. Estos resultados son una prueba crucial de que la eficiencia no tiene por qué implicar un sacrificio sustancial en la capacidad del modelo.
| Modelo | MMLU | CMMLU |
| SpikingBrain-7B | 65.84 | 71.58 |
| Mistral-7B | 62.56 | 44.58 |
| Llama3.1-8B | 65.74 | 52.44 |
| Modelo | MMLU | CMMLU |
| SpikingBrain-76B (A12B) | 73.58 | 78.83 |
| Mixtral-8x7B (A13B) | 71.23 | 52.70 |
| Llama2-70B | 69.57 | 52.94 |
El evento principal: eficiencia en contextos largos
Donde SpikingBrain realmente brilla es en su especialidad: el procesamiento de secuencias largas. El resultado más destacado del informe es la asombrosa mejora en la velocidad de inferencia. El modelo SpikingBrain-7B logra una aceleración de más de 100 veces en el «Tiempo hasta el Primer Token» (TTFT) para secuencias de 4 millones de tokens, en comparación con el modelo base Transformer.
El TTFT, también conocido como tiempo de «prellenado», es el tiempo que tarda el modelo en procesar la instrucción o el texto inicial antes de empezar a generar una respuesta. Para textos muy largos, este es el principal cuello de botella. Una aceleración de 100 veces significa que una tarea que antes podía tardar más de una hora, como procesar un extenso informe, ahora podría completarse en menos de un minuto. Esta mejora no es incremental; es transformadora, y abre la puerta a aplicaciones que hasta ahora eran inviables.
| Longitud de Secuencia | SpikingBrain-7B (ms) | Qwen2.5-7B (ms) |
| 256k | 1015 | 7419 |
| 512k | 1037 | 14398 |
| 1M | 1054 | 27929 |
| 4M | 1073 | (extrapolado > 100,000) |
IA al alcance de la mano: inferencia en CPU y móviles
Los beneficios de la eficiencia de SpikingBrain no se limitan a los grandes centros de datos. El informe demuestra que una versión comprimida del modelo, con mil millones de parámetros, ofrece un rendimiento excepcional en hardware de consumo. Al ejecutarlo en una CPU de escritorio estándar, el modelo SpikingBrain-1B logró una aceleración de 15.39 veces sobre un modelo de referencia (Llama3.2-1B) al generar una secuencia de 256,000 tokens.
Este resultado es significativo porque demuestra que la arquitectura lineal, con su memoria y coste computacional constantes, es excepcionalmente adecuada para entornos con recursos limitados. Esto allana el camino para que capacidades avanzadas de IA se ejecuten de manera eficiente en ordenadores portátiles, teléfonos móviles y otros dispositivos de borde, sin necesidad de una conexión constante a la nube.
El poder de la dispersión: análisis de la eficiencia del spiking
Finalmente, el informe cuantifica la promesa del enfoque de neuronas de impulsos. La combinación del esquema de spiking con una técnica de cuantización (usando enteros de 8 bits para los pesos) resulta en una pérdida de rendimiento mínima, de aproximadamente un 2%, lo cual es un compromiso muy aceptable.
A cambio, las ganancias en eficiencia son espectaculares. El esquema de spiking logra una «dispersión» del 69.15%, lo que significa que más de dos tercios de los cálculos potenciales simplemente se omiten porque las neuronas están en silencio, ahorrando una cantidad considerable de energía. Los autores estiman que, si se ejecutara en un hardware asíncrono especializado (chips neuromórficos), esta arquitectura podría reducir el consumo de energía en un 97.7% en comparación con los cálculos estándar de punto flotante de 16 bits. Esto se traduce en una mejora de la eficiencia energética de más de 43 veces. Es una cifra asombrosa que apunta hacia un futuro de inteligencia artificial verdaderamente sostenible y de bajo consumo.
| Modelo | Rendimiento (Promedio) | Rendimiento con Spiking (Promedio) | Caída de Rendimiento |
| SpikingBrain-7B | 0.6998 | 0.6875 | -1.76% |
| SpikingBrain-76B | 0.7304 | 0.7133 | -2.34% |
| Métrica de Energía | vs. FP16 MAC | vs. INT8 MAC |
| Reducción de Consumo | 97.7% | 85.2% |
| Mejora de Eficiencia | 43.48x | 6.76x |
Un atisbo del futuro eficiente de la IA
El informe técnico de SpikingBrain es más que la presentación de dos nuevos modelos de lenguaje. Es la articulación de una visión coherente y una demostración práctica de que es posible construir inteligencia artificial de una manera fundamentalmente diferente. El trabajo ofrece una solución integral y de múltiples capas a la crisis de escalado que amenaza con frenar el progreso en el campo. No se basa en un único truco ingenioso, sino en una combinación sinérgica de una arquitectura inspirada en el cerebro, un paradigma de entrenamiento eficiente y una audaz diversificación del hardware.
La implicación científica de este trabajo es profunda. Valida una hipótesis largamente sostenida: que los principios extraídos de la neurociencia pueden conducir a una inteligencia artificial más eficiente y, potencialmente, más capaz. Proporciona un ejemplo concreto y exitoso de cómo ir más allá del escalado por fuerza bruta, que ha dominado el campo durante la última década, para abrazar un diseño más matizado e inteligente.
Desde una perspectiva tecnológica, SpikingBrain ofrece una hoja de ruta práctica para construir modelos de lenguaje que puedan manejar contextos de información vastamente más grandes con una fracción del coste computacional y energético. La capacidad de procesar millones de tokens con una velocidad cien veces mayor no es una mejora incremental, sino un salto cualitativo que habilitará nuevas clases de aplicaciones. Además, el éxito en el clúster MetaX es una señal inequívoca de que el panorama del hardware de IA puede y debe diversificarse, fomentando un ecosistema más competitivo, innovador y resiliente.
Finalmente, las implicaciones sociales son quizás las más esperanzadoras. Al reducir drásticamente los requisitos de datos y computación para construir y desplegar modelos potentes, la filosofía de «reciclaje» y eficiencia de SpikingBrain tiene el potencial de democratizar el campo. Abre la puerta a que más actores, más allá de los gigantes tecnológicos, puedan contribuir a la vanguardia de la investigación y el desarrollo. Prepara el terreno para un futuro en el que la inteligencia artificial avanzada no solo sea más poderosa, sino también más sostenible, accesible y ubicua, capaz de ejecutarse eficientemente desde el centro de datos más grande hasta el dispositivo que llevamos en el bolsillo.
SpikingBrain representa un posible punto de inflexión, el comienzo de una transición de una era dominada por el mantra de «más grande es mejor» a una nueva era guiada por un principio más sabio: «más inteligente es mejor».
Referencias
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
OpenAI. (2025). GPT-5. https://openai.com/gpt-5/
Google DeepMind. (2025). Gemini 2.5 Pro. https://deepmind.google/models/gemini/pro/
Anthropic. (2025). Introducing Claude Opus 4.1. https://www.anthropic.com/news/claude-opus-4-1
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437.
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Tu, J., Zhang, J., Ma, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K.-Y., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., Wang, P., Peng, R., Men, R., Gao, R., Lin, R., Wang, S., Bai, S., Tan, S., Zhu, T., Li, T., Liu, T., Ge, W., Deng, X., Zhou, X., Ren, X., Zhang, X., Wei, X., Ren, X., Fan, Y., Yao, Y., Zhang, Y., Wan, Y., Chu, Y., Cui, Z., Zhang, Z., & Fan, Z.-W. (2024). Qwen2 technical report. ArXiv, abs/2407.10671.
Komatsuzaki, A., Puigcerver, J., Lee-Thorp, J., Riquelme Ruiz, C., Mustafa, B., Ainslie, J., Tay, Y., Dehghani, M., & Houlsby, N. (2022). Sparse upcycling: Training mixture-of-experts from dense checkpoints. arXiv preprint arXiv:2212.05055.
Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453.
Wang, S., Li, B. Z., Khabsa, M., Fang, H., & Ma, H. (2020). Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768.
Mercat, J., Vasiljevic, I., Keh, S., Arora, K., Dave, A., Gaidon, A., & Kollar, T. (2024). Linearizing large language models. arXiv preprint arXiv:2405.06640.
Zhang, M., Arora, S., Chalamala, R., Wu, A., Spector, B., Singhal, A., Ramesh, K., & Ré, C. (2024). Lolcats: On low-rank linearizing of large language models. arXiv preprint arXiv:2410.10254.
Zhang, G., Qu, S., Liu, J., Zhang, C., Lin, C., Yu, C. L., Pan, D., Cheng, E., Liu, J., Lin, Q., Yuan, R., Zheng, T., Pang, W., Du, X., Liang, Y., Ma, Y., Li, Y., Ma, Z., Lin, B., Benetos, E., Yang, H., Zhou, J., Ma, K., Liu, M., Niu, M., Wang, N., Que, Q., Liu, R., Liu, S., Guo, S., Gao, S., Zhou, W., Zhang, X., Zhou, Y., Wang, Y., Bai, Y., Zhang, Y., Wang, Z., Yang, Z., Zhao, Z., Zhang, J., Ouyang, W., Huang, W., & Chen, W. (2024). Map-neo: Highly capable and transparent bilingual large language model series. arXiv preprint arXiv:2405.19327.
Li, J., Du, L., Zhao, H., Zhang, B.-w., Wang, L., Gao, B., Liu, G., & Lin, Y. (2025). Infinity instruct: Scaling instruction selection and synthesis to enhance language models. arXiv preprint arXiv:2506.11116.
Liu, C., Wang, Z., Shen, S. Y., Peng, J., Zhang, X., Du, Z.-D., & Wang, Y.-F. (2025). The chinese dataset distilled from deepseek-r1-671b. https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k
Madhusudhan, S. T., Radhakrishna, S., Mehta, J., & Liang, T. (2025). Millions scale dataset distilled from r1-32b. https://huggingface.co/datasets/ServiceNow-AI/R1-Distill-SFT
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
Korthikanti, V., Casper, J., Lym, S., McAfee, L., Andersch, M., Shoeybi, M., & Catanzaro, B. (2022). Reducing activation recomputation in large transformer models. arXiv preprint arXiv:2205.05198.
NVIDIA. (2025). Communication overlap. https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/features/optimizations/communication_overlap.html
Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V. A., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., & Zaharia, M. (2021). Efficient large-scale language model training on gpu clusters using megatron-lm. arXiv preprint arXiv:2104.04473.
Harlap, A., Narayanan, D., Phanishayee, A., Seshadri, V., Devanur, N., Ganger, G., & Gibbons, P. (2018). Pipedream: Fast and efficient pipeline parallel dnn training. arXiv preprint arXiv:1806.03377.
Jacobs, S. A., Tanaka, M., Zhang, C., Zhang, M., Song, S. L., Rajbhandari, S., & He, Y. (2023). Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509.
Sun, W., Lan, D., Zhong, Y., Qu, X., & Cheng, Y. (2025). Lasp-2: Rethinking sequence parallelism for linear attention and its hybrid. ArXiv, abs/2502.07563.
Chou, Y., Liu, Z., Zhu, R., Wan, X., Li, T., Chu, C., Liu, Q., Wu, J., & Ma, Z. (2025). Zeco: Zero communication overhead sequence parallelism for linear attention. arXiv preprint arXiv:2507.01004.
Chen, T., Xu, B., Zhang, C., & Guestrin, C. (2016). Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174.
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., & Catanzaro, B. (2019). Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053.
Zuo, J., Velikanov, M., Rhaiem, D. E., Chahed, I., Belkada, Y., Kunsch, G., & Hacid, H. (2024). Falcon mamba: The first competitive attention-free 7b language model. arXiv preprint arXiv:2410.05355.
Mistral AI team. (2023). Mistral 7b. https://mistral.ai/news/announcing-mistral-7b
Glorioso, P., Anthony, Q., Tokpanov, Y., Whittington, J., Pilault, J., Ibrahim, A., & Millidge, B. (2024). Zamba: A compact 7b ssm hybrid model. arXiv preprint arXiv:2405.16712.
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. (2024). The llama 3 herd of models. arXiv e-prints, arXiv-2407.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
Li, H., Zhang, Y., Koto, F., Yang, Y., Zhao, H., Gong, Y., Duan, N., & Baldwin, T. (2023). Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212.
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., & Tafjord, O. (2018). Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., & Choi, Y. (2019). Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830.
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Bou Hanna, E., Bressand, F., et al. (2024). Mixtral of experts. arXiv preprint arXiv:2401.04088.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Gemma Team, Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ramé, A., et al. (2024). Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118.
Joshi, M., Choi, E., Weld, D. S., & Zettlemoyer, L. (2017). Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551.
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., & Hou, L. (2023). Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911.
Su, J., Lu, Y., Pan, S., Wen, B., & Liu, Y. (2021). Roformer: Enhanced transformer with rotary position embedding. ArXiv, abs/2104.09864.

