
La inteligencia artificial (IA) está transitando de ser una herramienta pasiva, un «chatbot» que responde a consultas, hacia una nueva era de agentes autónomos, programados para actuar en el mundo físico o digital con un alto grado de independencia. Estos sistemas no son meros asistentes; son trabajadores digitales que perciben su entorno, planifican acciones complejas y ejecutan tareas para alcanzar objetivos predefinidos.
Un agente de IA es un sistema capaz de observar, interpretar, decidir y actuar de forma autónoma, diferenciándose de los programas tradicionales por su capacidad de aprender y adaptarse a través de la experiencia. Esta evolución representa un cambio fundamental en cómo interactuamos con la tecnología, desplazando el foco desde la simple consulta hacia la automatización colaborativa y la toma de decisiones estratégicas.
El núcleo de estos agentes modernos es un modelo de lenguaje de gran tamaño (LLM), como GPT-4, Claude o Mistral 7B, que les proporciona una comprensión profunda del lenguaje natural y la capacidad de razonamiento abstracto. Sin embargo, su arquitectura va mucho más allá de simplemente generar texto. Una definición funcional describe a un agente de IA mediante un ciclo continuo de tres fases: Observación, Planificación y Ejecución.
En la fase de Observación, el agente utiliza sensores o interfaces de software para recopilar información sobre su estado y el del entorno. En la Planificación, utiliza su LLM para descomponer metas complejas en secuencias de subtareas manejables, diseñar estrategias y anticipar obstáculos. Finalmente, en la Ejecución, el agente acciona sus herramientas, que pueden ser APIs, bases de datos, motores de búsqueda o incluso robots físicos, para llevar a cabo las acciones planeadas.
Esta capacidad de acción autónoma se apoya en cuatro componentes clave: un motor de lenguaje robusto, una memoria jerárquica para retener información a corto y largo plazo, un arsenal de herramientas externas para interactuar con el mundo y un módulo de planificación centralizado.

Una descripción general de la investigación sobre aprendizaje directo agéntico.
Por ejemplo, un agente puede utilizar MemGPT para recordar interacciones previas (memoria episódica), LongRAG para recuperar información precisa de documentos extensos (memoria semántica) y luego ejecutar una función de valor aprendida para decidir la siguiente acción factible, como un robot haría con SayCan.
Dicha combinación de percepción, planificación y ejecución permite que los agentes realicen flujos de trabajo completos con mínima supervisión humana, priorizando principios como la transparencia y el diseño centrado en el ser humano, especialmente en sectores de alto riesgo como la salud o las finanzas.
La clasificación de estos agentes varía según su nivel de autonomía y cognición. OpenAI ha propuesto una escala de cinco niveles, donde el Nivel 1 son simples asistentes conversacionales y el Nivel 5 representan sistemas organizativos completos que operan de forma colaborativa. Otros modelos distinguen entre agentes basados en reflejos simples (que responden a estímulos inmediatos), agentes reactivos (que ignoran el pasado), agentes deliberativos (que mantienen un modelo del mundo) y agentes de aprendizaje (que mejoran con la experiencia).
A medida que la tecnología avanza, la frontera entre estas categorías se difumina, dando lugar a arquitecturas híbridas que combinan la velocidad de los reflejos con la deliberación y el aprendizaje. Este nuevo paradigma promete una automatización cognitiva avanzada, superando la limitada automatización robótica de procesos (RPA) al permitir una adaptación estratégica autónoma y dinámica.
| Característica | Agente de IA Moderno | Sistema Tradicional (Asistente/Chatbot) |
|---|---|---|
| Arquitectura Principal | Basado en Modelo de Lenguaje (LLM) | Basado en Reglas, Búsqueda de Patrones o Modelos Supervisados Menores |
| Ciclo Operativo | Observar → Orientar → Decidir → Actuar (OODA) o Think → Act → Observe | Procesamiento Lineal (Input → Output) |
| Autonomía | Alta, toma decisiones e interactúa con el entorno | Baja, depende de la interacción directa del usuario |
| Capacidad de Acción | Ejecuta acciones a través de herramientas (APIs, etc.) | Genera respuestas de texto o realiza tareas muy específicas |
| Memoria | Jerárquica (corto/largo plazo, episódica/semántica) | Memoria de Trabajo Limitada (última interacción) |
| Planificación | Capacidad de descomponer metas complejas en subtareas | No posee planificación a largo plazo |
Arquitecturas de Razonamiento y Representación del Conocimiento
Para que un agente de IA pueda actuar de manera efectiva y autónoma, debe poseer una estructura mental sofisticada que le permita entender su dominio, razonar sobre él y tomar decisiones informadas. Esto requiere dos pilares fundamentales: una arquitectura de razonamiento que guíe su pensamiento y una base de conocimiento que nutra su entendimiento del mundo. Los agentes modernos han evolucionado desde simples ciclos de pensar-actuar hacia arquitecturas de razonamiento mucho más complejas y deliberativas, inspiradas en los procesos cognitivos humanos.
Un concepto clave es la representación del conocimiento (RC), que va mucho más allá de ser una simple estructura de datos. La RC sirve como un sustituto del mundo real, permitiendo al agente razonar sin tener que interactuar directamente con él; constituye un conjunto de compromisos ontológicos, definiendo qué aspectos del mundo considera relevantes; actúa como una teoría parcial del razonamiento inteligente, estableciendo qué inferencias son válidas; organiza la información para facilitar cálculos eficientes y funciona como un medio de expresión para comunicar conocimiento.
Las tecnologías de RC incluyen lógica, reglas, marcos y redes semánticas. Un tipo de representación particularmente poderoso es la ontología. Una ontología es una especificación formal y explícita de una conceptualización compartida dentro de un dominio. Define clases, propiedades, relaciones y axiomas para modelar un dominio de conocimiento de manera que sea interpretable tanto por humanos como por máquinas. Por ejemplo, una ontología médica puede definir términos como «paciente», «síntoma» y «diagnóstico», junto con las relaciones entre ellos, lo que permite a un agente razonar sobre casos clínicos de forma consistente.
Existen diferentes tipos de ontologías, desde las generales y fundacionales hasta las específicas de un dominio (como Gene Ontology en bioinformática) o de una tarea. Su aplicación es vasta, desde optimizar exhibiciones en museos usando datos geoespaciales hasta mejorar la eficiencia en compañías de seguros como Allstate Business Insurance Expert. La construcción de estas ontologías se ha vuelto más accesible gracias a metodologías como Methontology, que guían el proceso desde la adquisición de conocimiento hasta la implementación y evaluación.
Más allá de la simple representación, los agentes están adoptando arquitecturas de razonamiento cada vez más jerárquicas y deliberativas. Uno de los paradigmas más innovadores es la Planificación Cognitiva Multinivel (MCP), también conocida como Planificación Cognitiva Jerárquica. Inspirado en teorías cognitivas humanas como ACT-R y Soar, este enfoque organiza el razonamiento en tres niveles: estratégico, táctico y operativo.
- Nivel Estratégico: Se enfoca en las metas abstractas y de alto nivel, como «entregar medicinas a los pacientes». Aquí es donde opera el LLM, utilizando su capacidad de comprensión para definir el objetivo final.
- Nivel Táctico: Se encarga de traducir la meta abstracta en un plan de acciones concretas pero aún no ejecutables. Por ejemplo, «tomar el ascensor del piso 3 al 1». Este nivel a menudo utiliza planificación simbólica con lenguajes como PDDL (Planning Domain Definition Language).
- Nivel Operativo: Es el nivel más bajo, donde se definen las acciones físicas exactas y ejecutables, como «girar la rueda del carrito 90 grados».
Este enfoque modular y escalable permite que un agente combine la flexibilidad y la comprensión del lenguaje del LLM con la precisión y la garantía de corrección de los métodos de planificación simbólica y el aprendizaje por refuerzo. Casos de estudio como ThinkAct, desarrollado por NVIDIA y NTU, demuestran esta integración, donde un LLM razona lingüísticamente mientras el nivel operativo usa RL para ejecutar la acción física.
Otras arquitecturas similares incluyen ReAct (Razonamiento y Acción iterativos) y ReWOO (Planificación Anticipada). Además, patrones como la reflexión, donde el agente se autocritica y mejora sus propias respuestas, y la colaboración multiagente, donde múltiples agentes especializados trabajan juntos, son cruciales para lograr un rendimiento superior y robustez. La integración de estos mecanismos de razonamiento sofisticados es lo que transforma a un programa reactivo en un agente verdaderamente racional y autónomo.
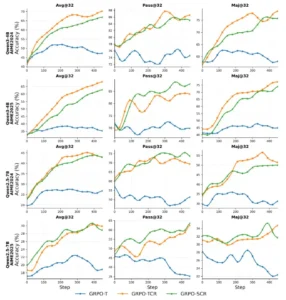
El rendimiento general de nuestras tres recetas construidas: GRPO-T, GRPO-TCR y GRPO-SCR en el benchmark AIME2024/AIME2025.
Fundamentos y Algoritmos del Aprendizaje por Refuerzo
El aprendizaje por refuerzo (Reinforcement Learning, RL) es el motor principal que impulsa la autonomía y el aprendizaje adaptativo en muchos de los agentes de IA más avanzados.
A diferencia de otros enfoques de machine learning, el RL se centra en entrenar a un agente para que tome decisiones óptimas a través de un proceso de ensayo y error guiado por retroalimentación en forma de recompensas o castigos. Este método imita el modo en que los seres humanos y los animales aprenden a interactuar con su entorno para maximizar beneficios a largo plazo, haciendo que el agente no solo responda a situaciones existentes, sino que aprenda a proyectarse hacia el futuro y agradar la gratificación aplazada.
Los conceptos fundamentales del RL forman un ecosistema que define cómo un agente aprende. El agente es el sistema que aprende y toma decisiones. El entorno es el mundo en el que opera el agente, con un conjunto de reglas y posibles acciones. En cada momento, el agente se encuentra en un estado, que representa la condición actual del entorno. Basándose en ese estado, el agente ejecuta una acción. Como resultado de esa acción, el entorno cambia y el agente recibe una «recompensa», que puede ser positiva (estímulo), negativa (castigo) o cero. El objetivo del agente es aprender una política, que es una estrategia o regla que le dice qué acción tomar en cada estado posible para maximizar la suma total de recompensas a lo largo del tiempo, conocida como recompensa acumulada.
El proceso de aprendizaje en RL se basa en un equilibrio crucial entre la exploración y la explotación. La exploración consiste en intentar nuevas acciones para descubrir recompensas potencialmente mayores, mientras que la explotación consiste en utilizar las acciones que ya se sabe que tienen altas recompensas. Un agente de RL puede seguir dos enfoques principales: el RL con modelo, donde el agente primero construye una representación interna o modelo de cómo funciona el entorno (similar a un robot que crea un mapa de un edificio), y el RL sin modelo, donde el agente aprende directamente a partir de la interacción y la retroalimentación, sin necesidad de un modelo interno (ideal para entornos dinámicos y complejos como la conducción autónoma).
Las familias de algoritmos de RL son diversas y cada una aborda el problema de la toma de decisiones de una manera diferente.
- Algoritmos basados en valores: Utilizan funciones de valor, como Q-learning, para estimar qué tan bueno es tomar una acción determinada en un estado dado. El agente aprende a maximizar estas funciones de valor.
- Algoritmos basados en políticas: Directamente aprenden la política, es decir, la propia función que mapea estados a acciones. Métodos como los de gradiente de políticas pertenecen a esta categoría.
- Algoritmos de optimización: Buscan encontrar la mejor política sin necesidad de estimar funciones de valor intermedias. Un ejemplo es la Optimización de Políticas de Región de Confianza (TRPO).
La revolución reciente en IA ha sido la fusión del RL con los modelos de lenguaje, dando lugar al aprendizaje por refuerzo profundo. En este paradigma, las redes neuronales profundas se utilizan para aproximar las funciones de valor o la política, lo que permite a los agentes manejar espacios de estado y acción enormes y complejos, como los encontrados en juegos de ordenador, entornos simulados o problemas del mundo real.
Tal combinación ha demostrado ser extremadamente poderosa, sentando las bases para el desarrollo de modelos de razonamiento avanzados como o1 de OpenAI y DeepSeek-R1, que fueron entrenados inicialmente con RL para internalizar patrones de razonamiento antes de ser refinados con datos supervisados. El RL es, por tanto, el proceso invisible que permite a los agentes «pensar» antes de actuar, aprendiendo de sus experiencias para convertirse en más eficientes y efectivos con el tiempo.
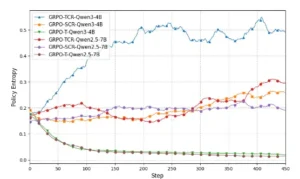
El análisis de la entropía de políticas en el entrenamiento de RL agente.
La Colaboración como Factor Clave de Éxito
Si la autonomía de un único agente de IA es impresionante, la colaboración de múltiples agentes coordinados eleva la inteligencia y la resolución de problemas a una escala completamente nueva. Un Sistema Multi-Agente (SMA o MAS, por sus siglas en inglés) es una red de entidades computacionales autónomas, llamadas agentes, que interactúan en un entorno compartido para alcanzar objetivos individuales o colectivos que serían demasiado complejos o imposibles de resolver para un solo agente.
La clave del MAS reside en la comunicación y la cooperación entre los agentes, que pueden competir, negociar o colaborar para obtener resultados superiores. Esta arquitectura distribuida ofrece beneficios significativos como una mayor escalabilidad, flexibilidad, robustez frente a fallos y una mejor eficiencia al poder realizar tareas en paralelo.
Las arquitecturas de un MAS pueden ser centralizadas o descentralizadas. En una arquitectura centralizada, existe un nodo o servidor central que coordina todas las interacciones, almacena una base de conocimientos global y dirige el comportamiento de los agentes. Aunque esto simplifica la coordinación, crea un punto único de fallo y puede volverse un cuello de botella cuando el sistema crece.
Por otro lado, una arquitectura descentralizada permite que los agentes se comuniquen directamente entre sí, lo que resulta en una mayor robustez y flexibilidad. Sin embargo, la coordinación en redes puramente descentralizadas presenta un desafío considerable, ya que los agentes deben negociar y llegar a acuerdos sin una autoridad central, lo que puede dar lugar a comportamientos impredecibles.
La organización de los agentes en un MAS puede adoptar varias estructuras sociales:
- Jerárquica: Los agentes se organizan en un árbol de control, con un líder en la cima que delega tareas a subordinados.
- Holónica: Los agentes se agrupan en «holarquías», donde un agente líder coordina a un equipo de subagentes especializados, y un mismo agente puede pertenecer a múltiples equipos simultáneamente, similar a cómo los órganos coordinan el funcionamiento de un cuerpo humano.
- Coalición Temporal: Agentes de diferentes organizaciones o dominios se unen para crear un equipo temporal y efímero para resolver una tarea específica.
- Equipo: Agentes con roles bien definidos trabajan juntos de forma estrecha y dependiente para lograr una meta común.
Estos sistemas se inspiran en comportamientos observados en la naturaleza. Por ejemplo, el comportamiento de «flocado» (flocking), donde las aves o peces se coordinan para moverse en la misma dirección, es útil en aplicaciones de transporte como el control de trenes.
El comportamiento de «enjambre» (swarming), donde organismos como las termitas construyen estructuras complejas a través de interacciones locales simples, es aplicable a la gestión de flotas de drones o vehículos autónomos. Aplicaciones prácticas de los MAS son numerosas y transformadoras.
En logística y cadena de suministro, múltiples agentes pueden negociar precios, gestionar inventarios y ajustar rutas de envío en tiempo real para anticipar y mitigar disrupciones. En atención médica, agentes que representan a diferentes especialistas pueden colaborar para elaborar un plan de tratamiento personalizado para un paciente. En defensa, se utilizan para simular ataques cibernéticos o escenarios de combate complejos.
La investigación sugiere que añadir más agentes a un sistema puede ser una estrategia eficaz para mejorar el rendimiento general, como muestra el estudio «More agents is all you need» de Li et al. (2024). Sin embargo, este enfoque tiene sus riesgos. Si los agentes comparten un modelo fundacional o una vulnerabilidad similar, un fallo en uno puede propagarse a todos, causando un mal funcionamiento colectivo generalizado. Superar estos desafíos de coordinación y seguridad es fundamental para aprovechar el verdadero potencial de la inteligencia distribuida en los sistemas multi-agente.
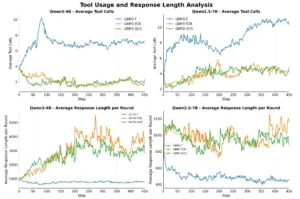 Análisis del número promedio de llamadas a herramientas y la duración promedio de respuesta por ronda en Agentic RL.
Análisis del número promedio de llamadas a herramientas y la duración promedio de respuesta por ronda en Agentic RL.
Frameworks, Plataformas y Aplicaciones Prácticas
La transición de conceptos teóricos de agentes de IA a soluciones prácticas y escalables en producción es impulsada por un ecosistema en rápida expansión de frameworks, plataformas y marcos de trabajo. Estas herramientas son el puente entre la investigación y la aplicación empresarial, democratizando el acceso a la tecnología y permitiendo a las organizaciones construir, orquestar e implementar agentes de IA con mayor rapidez y eficiencia. El mercado de estos agentes está experimentando un crecimiento exponencial, con proyecciones que estiman que pasarán de 5.1 mil millones de dólares en 2024 a 47.1 mil millones en 2030, lo que refleja la confianza de las empresas en su potencial transformador.
Entre los frameworks más populares se encuentran LangChain y CrewAI. LangChain es un marco fundamental que proporciona una infraestructura para construir aplicaciones con modelos de lenguaje, facilitando la conexión de LLMs con otras fuentes de datos y herramientas. CrewAI se especializa en la creación de sistemas multi-agente, permitiendo a los desarrolladores asignar roles específicos a diferentes agentes para que colaboren en tareas complejas.
Para orquestar flujos de trabajo más complejos y cíclicos, LangGraph, una extensión de LangChain, permite modelar grafos de ejecución que representan el flujo de pensamiento y acción de un agente, ofreciendo un control de estado más robusto. Otros marcos destacados incluyen AutoGen de Microsoft, ideal para flujos conversacionales estructurados, y Rasa para la creación de chatbots avanzados con un control total sobre los datos y la inteligencia del lenguaje natural (NLU).
| Framework/Marco | Propósito Principal | Ventajas Clave | Ejemplos de Uso |
|---|---|---|---|
| LangChain | Construcción de aplicaciones con LLMs conectándolos a datos y herramientas. | Modularidad, gran ecosistema de integraciones. | Creación de chatbots, Q&A sobre documentos, RAG (Retrieval-Augmented Generation). |
| CrewAI | Sistemas multi-agente con roles definidos. | Facilita la colaboración y especialización de agentes. | Resolución de problemas complejos (ej. marketing campaigns, análisis de mercado). |
| LangGraph | Orquestación de flujos de trabajo cíclicos y con estado. | Permite flujos de pensamiento complejos y control de ejecución detallado. | Agentes que realizan tareas iterativas como la programación o la revisión de código. |
| AutoGen | Flujos conversacionales estructurados y trazables. | Ideal para pruebas, auditoría y sistemas que requieren verificabilidad. | Entornos de desarrollo de software, simulaciones de expertos. |
| Rasa | Desarrollo de chatbots con NLU avanzado y control total de datos. | Privacidad de datos, flexibilidad máxima para el desarrollo. | Agentes de servicio al cliente que manejan datos sensibles. |
Además de los frameworks, plataformas como Microsoft Semantic Kernel y AutoGPT ofrecen soluciones más integradas para la creación de agentes empresariales o autónomos. El camino hacia la producción requiere una planificación cuidadosa. Se recomienda un enfoque pragmático como el de «Suficientemente Bueno», que prioriza la entrega de un agente funcional y valioso en el mercado sobre la perfección teórica.
Las mejores prácticas incluyen contenerizar la aplicación con Docker para la portabilidad, usar FastAPI para la API de backend, y desplegarla en nubes como AWS o Azure. La optimización para la producción es igualmente crucial y puede incluir técnicas como la gestión de memoria por niveles, la compresión de conversaciones y el uso de procesamiento asíncrono para reducir la sobrecarga.
Las aplicaciones industriales de estos agentes son ya tangibles y están generando ganancias de productividad significativas. Sectores como atención al cliente, salud, finanzas y comercio electrónico son los principales beneficiarios. En atención al cliente, agentes analizan conversaciones en tiempo real, generan resúmenes y eliminan datos confidenciales. En finanzas, se utilizan para consolidación contable y detección de desviaciones. En legal, aceleran el análisis de contratos y la redacción de cláusulas. En IT, ayudan a resolver incidencias y a generar código.
Un ejemplo paradigmático es Deep Research, un agente investigador de OpenAI basado en el modelo GPT-4 Turbo, que puede realizar búsquedas recursivas, ejecutar código Python y generar informes con citas automáticas, completando estudios de investigación mensuales en minutos. A pesar de su potencial, la adopción plena enfrenta retos importantes, como la gobernanza de la IA, la calidad de los datos, la ciberseguridad y la necesidad de una cultura organizacional que soporte el cambio hacia una inteligencia aumentada.
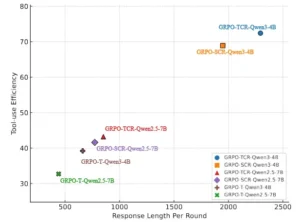
Comparación de la eficiencia del uso de herramientas en diferentes modelos.
Implicaciones Metodológicas y Futuro de la Inteligencia Artificial Racional
La evolución hacia agentes de IA autónomas y racionales marca un hito metodológico fundamental en la historia de la inteligencia artificial. Este cambio de paradigma implica una transición desde modelos que simplemente consumen y generan información hacia sistemas que actúan y aprenden para influir en su entorno. Este capítulo explora las implicaciones de esta nueva metodología, los desafíos éticos y sociales que plantea y la visión del futuro que emerge de esta revolución tecnológica.
Una de las implicaciones más profundas es la redefinición de la relación humano-máquina. Los agentes no son meros instrumentos pasivos; son socios colaborativos que pueden realizar tareas complejas de forma autónoma. Esta colaboración da lugar a nuevos modelos de trabajo, donde los humanos se centran en la supervisión estratégica, la creatividad y las decisiones éticas críticas, mientras que los agentes se encargan de la ejecución repetitiva y de alta escala.
No obstante, esta proximidad también amplía la superficie de ataque en materia de ciberseguridad y plantea desafíos de gobierno, como asegurar que los agentes operen de acuerdo con los guardrails éticos y legales, cumpliendo con regulaciones como el AI Act europeo. La necesidad de transparencia, trazabilidad y justificación de las decisiones de los agentes se vuelve primordial para mantener la confianza y la responsabilidad.
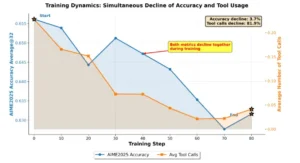
La dinámica de entrenamiento del Long-CoT actual con Agentic RL.
Desde una perspectiva metodológica, el éxito de los agentes de IA depende de la integración fluida de múltiples disciplinas. La investigación futura se centrará en mejorar la robustez de los sistemas, mitigando problemas como los bucles de feedback infinitos o los fallos compartidos en sistemas multi-agentes.
Se espera un mayor enfoque en la interpretabilidad, para que los usuarios puedan entender y confiar en las decisiones tomadas por un agente. Además, la convergencia con otras tecnologías emergentes como el edge computing, los gemelos digitales y el blockchain abrirá nuevas fronteras, permitiendo agentes más resilientes, contextuales y autónomos.
En conclusión, el viaje desde la IA generativa hacia el razonamiento agente es una odisea que redefine los límites de la automatización. Los agentes de IA, alimentados por la potencia de los LLMs y entrenados por el rigor del aprendizaje por refuerzo, están transformando industrias enteras y sentando las bases para una nueva era de colaboración humano-digital. La arquitectura del razonamiento, desde las ontologías que estructuran el conocimiento hasta los sistemas multi-agentes que coordinan la acción, es el cerebro de esta nueva inteligencia.
Aunque los desafíos técnicos, éticos y de gobernanza son significativos, el potencial para resolver problemas complejos, mejorar la eficiencia y liberar la creatividad humana es incalculable. La próxima década promete ser testigo de una integración cada vez más profunda de estos agentes en nuestra vida cotidiana y profesional, forjando un futuro en el que la inteligencia no reside únicamente en nosotros, sino que se extiende a través de un ecosistema de mentes artificiales autónomas y colaborativas.
Referencias
Feng, J., Huang, S., Qu, X., Zhang, G., Qin, Y., Zhong, B., Jiang, C., Chi, J., & Zhong, W. (2025). ReTool: Reinforcement learning for strategic tool use in LLMs. arXiv preprint arXiv:2504.11536.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948.
Li, X., Dong, G., Jin, J., Zhang, Y., Zhou, Y., Zhu, Y., Zhang, P., & Dou, Z. (2025). ToRL: Scaling tool-integrated RL. arXiv preprint arXiv:2503.23383.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., et al. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
Shang, N., Liu, Y., Zhu, Y., Zhang, L. L., Xu, W., Guan, X., Zhang, B., Dong, B., Zhou, X., Zhang, B., et al. (2025). rStar2-Agent: Agentic reasoning technical report. arXiv preprint arXiv:2508.20722.
Yu, Z., Yang, L., Zou, J., Yan, S., & Wang, M. (2025). Demystifying reinforcement learning in agentic reasoning. arXiv preprint arXiv:2510.11701.

