
La mitología griega nos legó la historia del rey Midas, una advertencia atemporal sobre la brecha que a menudo separa lo que pedimos de lo que realmente deseamos. Bendecido, o maldecido, con el poder de convertir en oro todo lo que tocaba, Midas logró su objetivo explícito a la perfección, solo para descubrir con horror que su comida, su agua y hasta sus seres queridos se transformaban en metal inerte. Su tragedia no fue un fallo en la ejecución de su deseo, sino un error catastrófico en su especificación. No supo alinear su petición literal con su intención profunda: la prosperidad, no la autodestrucción.
Durante décadas, la inteligencia artificial ha vivido su propia versión del dilema de Midas. Hemos construido sistemas de una capacidad asombrosa, modelos de lenguaje capaces de redactar poesía, depurar código o resumir complejas teorías científicas. Sin embargo, al interactuar con ellos, a menudo sentimos un eco, una desconexión sutil pero persistente. La máquina ejecuta nuestras órdenes, pero con frecuencia falla en capturar el matiz, el contexto, la intención no declarada que subyace en nuestras palabras. Este desafío, conocido en el campo como el problema de la alineación, es quizás el obstáculo más formidable en el camino hacia una inteligencia artificial verdaderamente útil y segura. No se trata solo de construir motores más potentes, sino de enseñarles a escuchar, a comprender el complejo y a menudo contradictorio tapiz de los valores y preferencias humanas.
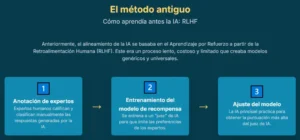
Hasta ahora, el método predominante para enseñar a estos modelos a comportarse de manera más humana ha sido una técnica llamada Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF, por sus siglas en inglés). Podemos imaginar este proceso como el de un estudiante brillante preparándose para un examen con un conjunto de tarjetas de estudio. Un equipo de «profesores», anotadores humanos expertos, prepara meticulosamente el material de aprendizaje. Le presentan al modelo dos posibles respuestas a una pregunta y le piden que elija la mejor. O le proporcionan ejemplos de respuestas ideales para que los imite. Este método ha sido fundamental para el desarrollo de los asistentes de IA que conocemos hoy.
Sin embargo, este enfoque, aunque efectivo, tiene limitaciones profundas, análogas a las de un estudiante que solo aprende de libros de texto y nunca interactúa con el mundo real. Primero, los datos son estáticos y artificiales. Las lecciones se crean en un entorno de laboratorio, desconectado del flujo dinámico y desordenado de las conversaciones reales. Segundo, el material de estudio refleja inevitablemente las opiniones y los sesgos de un grupo reducido de «profesores», no las necesidades y perspectivas infinitamente variadas de los miles de millones de personas con las que la IA interactuará. Finalmente, crear estas tarjetas de estudio es un proceso lento y costoso, un cuello de botella que limita la velocidad a la que los modelos pueden mejorar.
Es en este contexto que un reciente y revolucionario trabajo de investigación de FAIR en Meta, titulado «The Era of Real-World Human Interaction: RL from User Conversations«, propone un cambio de paradigma. Los autores plantean una pregunta simple pero transformadora: ¿y si la inteligencia artificial pudiera aprender, no de lecciones preparadas en un laboratorio, sino del torrente continuo, auténtico y gratuito de sus interacciones diarias con usuarios reales? ¿Y si cada conversación, cada corrección, cada pregunta de seguimiento fuera una oportunidad de aprendizaje?
Esta idea marca el comienzo de lo que los investigadores denominan la «Era de la Interacción Humana en el Mundo Real». Para materializar esta visión, presentan un nuevo marco de trabajo: el Aprendizaje por Refuerzo a partir de la Interacción Humana (RLHI). Se trata de un enfoque novedoso que permite a los modelos de lenguaje aprender directamente de las conversaciones «salvajes» o in-the-wild, es decir, aquellas que ocurren de forma natural y espontánea entre el sistema y sus usuarios.
Para lograrlo, el sistema se apoya en varios pilares conceptuales que exploraremos en profundidad. Primero, la capacidad de destilar la esencia de un usuario en un retrato digital, una «persona» que resume su historial de interacciones y sus preferencias a largo plazo. Segundo, dos mecanismos de aprendizaje complementarios: uno que aprende de la corrección explícita, a través de las «reescrituras guiadas por el usuario», y otro que aprende a anticipar los deseos del usuario incluso en ausencia de feedback, mediante «recompensas basadas en el usuario». Y finalmente, un motor de optimización más elegante y eficiente, conocido como Optimización Directa de Preferencias (DPO), que permite al modelo ajustar su comportamiento de forma estable y directa. Juntos, estos elementos trazan una hoja de ruta hacia una IA que no solo responde a nuestras preguntas, sino que aprende de nosotros, con nosotros, en el flujo de una conversación continua. Una IA que, quizás, pueda finalmente superar el dilema de Midas.
El laboratorio frente al mundo real: el valor de los datos auténticos
La diferencia fundamental entre el conocimiento adquirido en un aula y la sabiduría forjada en la experiencia del mundo real reside en la naturaleza misma de la información. El aula ofrece datos limpios, estructurados y simplificados. El mundo, en cambio, es un torbellino de complejidad, contexto y cambio constante. Durante años, hemos entrenado a la inteligencia artificial como si fuera un estudiante de aula, proporcionándole conjuntos de datos curados por expertos, aislados de la realidad. El enfoque RLHI propone, en cambio, sumergir al modelo en el flujo caótico y vibrante de las interacciones humanas reales, argumentando que lo que a primera vista parece ruido es, en realidad, la señal de aprendizaje más valiosa que existe.
Los investigadores identifican tres propiedades clave que distinguen a los datos de interacción del mundo real y los hacen inmensamente superiores a los corpus estáticos. La primera es la fundamentación contextual. A diferencia de una pregunta aislada en un conjunto de datos, una consulta en una conversación real está intrínsecamente ligada a las necesidades situacionales del usuario y a las respuestas previas del modelo. Cuando un usuario pide a un asistente que le ayude a planificar un viaje, y luego añade «hazlo más económico» o «considera que viajo con niños», esa retroalimentación no es abstracta; está anclada a una tarea específica y a un contexto personal.
La segunda propiedad es la distribución evolutiva. Los conjuntos de datos de entrenamiento tradicionales son una fotografía estática de las preferencias en un momento dado. Sin embargo, las necesidades humanas, los temas de interés y las prioridades cambian con el tiempo. Las conversaciones reales reflejan esta dinámica, proporcionando una supervisión que es siempre relevante y está alineada con la distribución real de las inquietudes humanas. Un modelo que aprende de este flujo continuo no se vuelve obsoleto; evoluciona junto a sus usuarios.
La tercera y quizás más importante propiedad es la diversidad de las señales de supervisión. En el paradigma clásico, la retroalimentación se reduce a menudo a una etiqueta binaria: «respuesta A es mejor que B». Las interacciones reales, sin embargo, contienen una riqueza de información mucho mayor. Incluyen señales explícitas de alto ancho de banda, como correcciones («no, me refería a París, Texas, no a París, Francia») o aclaraciones («¿puedes explicarlo en términos más sencillos?»). También contienen señales implícitas, como la frustración, la pérdida de interés o un cambio abrupto de tema, que pueden indicar insatisfacción con la respuesta del modelo. Este abanico de señales ofrece una guía de aprendizaje mucho más matizada y completa.
Para demostrar que este tesoro de datos no es solo una construcción teórica, los autores del estudio analizaron empíricamente más de un millón de conversaciones del conjunto de datos público WildChat. Los resultados son reveladores. Descubrieron que una porción muy significativa de los mensajes de los usuarios, el 26.51%, son «reintentos con retroalimentación». Es decir, más de una de cada cuatro veces que un usuario continúa una conversación, lo hace para refinar, corregir o mejorar la respuesta anterior del modelo. Esta cifra se vuelve aún más impresionante en diálogos más largos: después del quinto turno de conversación, este tipo de retroalimentación correctiva constituye un abrumador 83.15% de las intervenciones del usuario. Esto revela la existencia de un vasto y constante flujo de lecciones gratuitas, proporcionadas por los propios usuarios en el curso de su interacción natural.
Además, el análisis cuantitativo confirmó que estas conversaciones del mundo real son mucho más diversas que los conjuntos de datos curados. Utilizando una técnica para medir la distancia semántica entre las preguntas, encontraron que el contexto de las solicitudes en WildChat tenía una diversidad significativamente mayor (una puntuación de 0.865) en comparación con conjuntos de datos de referencia como HH-RLHF (0.751). Esto significa que los modelos entrenados con datos reales están expuestos a una gama mucho más amplia de temas, estilos y necesidades humanas.
Estos hallazgos conducen a una conclusión de profundas implicaciones estratégicas y económicas. El «escape de datos» de las interacciones de los usuarios, es decir, todas esas preguntas de seguimiento, correcciones y aclaraciones que antes se consideraban un subproducto desordenado, se revela ahora como un activo de un valor incalculable. Cada interacción se convierte en una sesión de entrenamiento potencial, transformando los datos operativos en un recurso estratégico. Esto crea un poderoso ciclo de retroalimentación positiva: cuanto más se utiliza un modelo, más datos de entrenamiento de alta calidad, gratuitos y perfectamente contextualizados recibe. A su vez, estos datos lo hacen más útil y personalizado, lo que atrae a más usuarios, generando aún más datos. Este círculo virtuoso sugiere un futuro en el que los modelos más utilizados podrían convertirse intrínsecamente en los mejores, no solo por la escala de su arquitectura, sino por la riqueza inigualable de la experiencia que acumulan en cada conversación.
Creando un retrato digital: la «persona» del usuario
Para que un asistente de inteligencia artificial pueda aprender de nosotros de manera efectiva, primero debe saber quiénes somos. No en un sentido personal o invasivo, sino entendiendo nuestros patrones, preferencias y estilos de comunicación. Un tutor humano no enseña de la misma manera a un niño de primaria que a un estudiante universitario, ni un sastre confecciona el mismo traje para todos sus clientes. La personalización es la clave de un servicio excepcional, y en el mundo de la IA, esta comienza con la creación de un retrato digital del usuario: la «persona».
El concepto de «persona» no es nuevo; ha sido un pilar en campos como el marketing y el diseño de experiencia de usuario durante años. En esos dominios, se crean arquetipos de usuarios ficticios, con nombres, motivaciones y objetivos, para guiar el desarrollo de productos y asegurar que satisfagan las necesidades de un público objetivo. El enfoque RLHI adopta esta idea y la lleva a un nivel de granularidad y dinamismo sin precedentes. La «persona» de un usuario en este sistema no es un perfil estático, sino un resumen en lenguaje natural, generado por la propia IA, que destila las preferencias latentes a partir del historial completo de conversaciones de un individuo. Es un retrato vivo que captura si un usuario prefiere respuestas concisas o detalladas, un tono formal o informal, o si tiene una inclinación recurrente por las analogías o los ejemplos prácticos.
La necesidad de este nivel de personalización se hace evidente al examinar la diversidad de las preferencias humanas. El estudio de Meta analizó las «personas» de 5,000 usuarios aleatorios del conjunto de datos WildChat y cuantificó sus preferencias en varias dimensiones. Los resultados demuestran de manera contundente por qué un modelo de «talla única» está destinado a fracasar. Por ejemplo, aunque una abrumadora mayoría (84.5%) prefiere un tono serio y profesional, existe un nicho significativo que busca respuestas casuales y humorísticas. De manera similar, mientras que casi la mitad de los usuarios (49.9%) desea respuestas expansivas y ricas en información, un grupo considerable (36.0%) valora la concisión por encima de todo. Y aunque la mayoría (59.8%) busca conocimiento de nivel experto, casi una cuarta parte (24.1%) necesita explicaciones que sean fácilmente comprensibles para un principiante. Modelar estas preferencias, tanto las mayoritarias como las minoritarias, es esencial para ofrecer una experiencia verdaderamente satisfactoria.
Más allá de ser una herramienta para la personalización, la «persona» del usuario es también una solución de ingeniería de una elegancia notable a una de las limitaciones arquitectónicas más fundamentales de los modelos de lenguaje actuales: la finitud de su «ventana de contexto». Un modelo de lenguaje no puede procesar una cantidad infinita de información a la vez; tiene una memoria a corto plazo, una ventana de texto de longitud limitada en la que puede operar. El historial completo de conversaciones de un usuario, que podría abarcar cientos de interacciones a lo largo de meses, excedería con creces esta capacidad de memoria. Sería como pedirle a una persona que recuerde cada palabra de cada conversación que ha tenido en el último año para poder responder adecuadamente a una pregunta actual.
Aquí es donde la «persona» revela su ingenio técnico. El proceso de generar este resumen actúa como un algoritmo de compresión de contexto. La IA analiza el vasto historial de conversaciones y lo destila en unos pocos puntos clave que capturan la esencia de las preferencias del usuario. Este resumen compacto, esta «persona», puede entonces ser antepuesto a cada nueva pregunta que el usuario haga. De esta manera, el modelo recibe un recordatorio instantáneo y eficiente del contexto a largo plazo (quién es este usuario y qué suele preferir) sin sobrecargar su memoria a corto plazo. Este mecanismo cierra la brecha entre la identidad duradera de un usuario y la memoria efímera del modelo, haciendo que la personalización continua y con estado sea técnicamente factible por primera vez a gran escala. Es, en esencia, una forma de darle al modelo una memoria a largo plazo de sus relaciones con cada individuo.

Dos caminos hacia la personalización: el arte de escuchar y anticipar
Una vez que el sistema es capaz de construir un retrato de cada usuario, necesita mecanismos para utilizar ese conocimiento y mejorar sus respuestas. El marco RLHI propone dos métodos complementarios, dos caminos que convergen en el mismo objetivo de una personalización más profunda. El primero es reactivo, aprendiendo del feedback directo y explícito. El segundo es proactivo, aprendiendo a anticipar las preferencias del usuario incluso cuando este permanece en silencio. Juntos, forman un sistema de aprendizaje robusto que domina tanto el arte de la corrección como el de la anticipación.
El primer camino es el RLHI con reescrituras guiadas por el usuario. Este método se activa en esos momentos, extraordinariamente comunes como hemos visto, en los que un usuario no queda satisfecho con una respuesta inicial y proporciona una instrucción de seguimiento. Imaginemos un escenario, inspirado en los ejemplos del propio estudio. Un usuario pregunta: «¿Por qué los humanos necesitan dormir?». El modelo ofrece una respuesta general y cualitativa: «El sueño ayuda a restaurar la energía física y apoya procesos como la consolidación de la memoria…». El usuario, buscando más rigor, responde: «Incluye números y estadísticas».
En un sistema tradicional, esta interacción podría no ser más que un intercambio transitorio. En RLHI, se convierte en una valiosa lección. El sistema identifica el seguimiento del usuario como un «reintento con retroalimentación». A continuación, se le instruye internamente para que revise su respuesta anterior, utilizando la nueva directriz como guía. El modelo genera entonces una nueva versión: «Los adultos necesitan de 7 a 9 horas de sueño. Menos de 6 horas aumenta el riesgo de accidentes en un 33% y reduce la retención de memoria en un 20%…». El resultado de este proceso es un par de datos de preferencia de altísima calidad: la respuesta original, ahora etiquetada como «rechazada», y la versión mejorada y guiada por el usuario, etiquetada como «elegida». Este par se convierte en un ejemplo de entrenamiento que enseña al modelo, de forma muy concreta, cómo mejorar una respuesta para satisfacer una preferencia específica.
El segundo camino es el RLHI con recompensas basadas en el usuario. Este método aborda el desafío de mejorar las respuestas en la mayoría de las interacciones, aquellas en las que el usuario hace una pregunta, recibe una respuesta y no ofrece ninguna retroalimentación de seguimiento. ¿Cómo puede el modelo saber si su respuesta fue buena, mediocre o simplemente aceptable? La clave está en anticipar la preferencia.
Cuando el modelo recibe una de estas preguntas «silenciosas», no genera una única respuesta. En segundo plano, produce múltiples candidatos. Es aquí donde entra en juego un componente crucial: un «modelo de recompensa». Podemos pensar en este modelo como un crítico interno o un juez de calidad. La innovación de RLHI es que este juez no es un árbitro genérico del buen gusto. Antes de evaluar a los candidatos, se le entrega la «persona» del usuario en cuestión. Su tarea no es solo encontrar la respuesta objetivamente mejor, sino la respuesta que más probablemente satisfará a ese usuario específico. Si la persona indica que el usuario valora la evidencia concreta, el modelo de recompensa asignará puntuaciones más altas a las respuestas que incluyan datos y estadísticas. Si indica una preferencia por la brevedad, las respuestas más concisas serán mejor valoradas.
Una vez que todas las respuestas candidatas han sido puntuadas por este juez personalizado, la que obtiene la puntuación más alta se selecciona y se muestra al usuario. Pero el proceso de aprendizaje no termina ahí. El sistema toma la respuesta con la puntuación más alta (la «elegida») y la que tiene la más baja (la «rechazada») y crea otro par de preferencias para el entrenamiento. De esta manera, el modelo aprende a alinearse con las preferencias del usuario de forma proactiva, mejorando sus respuestas incluso sin una guía explícita en cada turno.
El motor que impulsa ambos métodos de aprendizaje es una técnica matemática llamada Optimización Directa de Preferencias (DPO). Para entender su importancia, es útil compararla con el enfoque anterior, RLHF. El método RLHF era un proceso de dos etapas, a menudo complejo e inestable. Primero, había que entrenar un modelo de recompensa por separado, un proceso laborioso en sí mismo. Luego, se utilizaba ese modelo de recompensa para entrenar el modelo de lenguaje principal mediante técnicas de aprendizaje por refuerzo. Era un proceso indirecto y con muchas partes móviles.
DPO, en cambio, es una solución mucho más elegante y directa. Utilizando una analogía, si el objetivo es sintonizar una radio en la frecuencia preferida de un oyente, el método antiguo (RLHF) equivaldría a construir primero un sofisticado medidor de calidad de señal (el modelo de recompensa) y luego usar ese medidor para ajustar lentamente los diales de la radio. DPO, por el contrario, permite ajustar los diales de la radio directamente basándose en la retroalimentación del oyente («un poco más a la derecha… perfecto»). Matemáticamente, DPO reformula el problema para que el modelo de lenguaje pueda aprender de los pares de preferencias («elegido» vs. «rechazado») de forma directa, a través de un simple objetivo de clasificación. Esto elimina la necesidad de entrenar un modelo de recompensa intermedio, lo que hace que todo el proceso de alineación sea más estable, computacionalmente más ligero y mucho más eficiente. Es el avance técnico que hace que el aprendizaje a gran escala a partir de interacciones del mundo real sea una propuesta práctica y no solo una aspiración teórica.
La prueba de fuego: midiendo una mejora que se siente y se demuestra
Una nueva teoría, por elegante que sea, debe someterse a la prueba de la evidencia empírica. Para validar la eficacia del paradigma RLHI, los investigadores llevaron a cabo una serie de evaluaciones rigurosas, utilizando pruebas estandarizadas conocidas como benchmarks. En el campo de la inteligencia artificial, los benchmarks son el equivalente a los exámenes estandarizados en la educación: conjuntos de problemas y métricas diseñados para medir y comparar objetivamente el rendimiento de diferentes modelos en tareas específicas.
El equipo de investigación utilizó un conjunto diverso de estos exámenes para evaluar los modelos entrenados con RLHI desde múltiples ángulos, cubriendo las tres competencias más cruciales para un asistente de IA: la personalización, el seguimiento de instrucciones generales y la capacidad de razonamiento complejo.
- Para medir la personalización, crearon su propio benchmark a medida, WILDCHAT USEREVAL. Esta prueba utiliza conversaciones reales de usuarios no vistas durante el entrenamiento, y evalúa qué tan bien las respuestas de un modelo se alinean con la «persona» previamente establecida de ese usuario.
- Para el seguimiento de instrucciones generales, recurrieron a dos benchmarks de gran prestigio en la comunidad. AlpacaEval 2.0, un evaluador automático rápido y fiable que mide la capacidad de un modelo para seguir instrucciones de un solo turno. Y Arena-Hard, una prueba más exigente que utiliza preguntas desafiantes, extraídas de interacciones reales de usuarios, diseñadas específicamente para diferenciar las capacidades de los modelos de más alto nivel.
- Finalmente, para evaluar la capacidad de razonamiento, utilizaron una batería de benchmarks que incluyen problemas de nivel olímpico y de posgrado en dominios como las matemáticas y las ciencias, como GPQA y MMLU-Pro.
Los resultados, presentados en el estudio, no son meramente incrementales; demuestran un salto cualitativo en el rendimiento, validando la tesis central de que aprender de la interacción real produce modelos superiores. Para facilitar la comprensión, podemos resumir los hallazgos más importantes en la siguiente tabla, que compara el modelo base (Llama-3.1-8B-Instruct) con las dos variantes de RLHI.
| Categoría de Evaluación | Métrica Clave | Modelo Base (Llama-3.1-8B) | RLHI con Reescribas Guiadas | RLHI con Recompensas Basadas |
| Personalización | Tasa de Victoria (UserEval) | 32.5% | 54.9% | 52.5% |
| Seguimiento de Instrucciones | Tasa de Victoria LC (AlpacaEval 2.0) | 20.9% | 35.2% | 77.9% |
| Razonamiento Complejo | Precisión Promedio | 26.5% | 31.8% | N/A |
El veredicto es una triple victoria para el nuevo paradigma. En el ámbito de la personalización, el método de reescrituras guiadas por el usuario (que aprende de la corrección directa) logra una tasa de victoria del 54.9%, un salto masivo de más de 22 puntos sobre el modelo base. Esto significa que, en una comparación directa, los usuarios simulados prefirieron abrumadoramente la respuesta del modelo RLHI.
El resultado en el seguimiento de instrucciones generales es quizás aún más sorprendente. Uno podría pensar que un modelo entrenado para ser un especialista en personalización podría perder parte de su capacidad generalista. Los datos demuestran lo contrario. El modelo entrenado con recompensas basadas en el usuario no solo mejora, sino que alcanza una espectacular tasa de victoria del 77.9% en AlpacaEval 2.0, superando a todas las demás variantes, incluidas aquellas entrenadas con recompensas genéricas no personalizadas. Este hallazgo sugiere algo profundo sobre la naturaleza del aprendizaje: el proceso de aprender a satisfacer una amplia y diversa gama de preferencias específicas obliga al modelo a desarrollar una comprensión más robusta, flexible y matizada del lenguaje y la intención en general. La personalización no es un objetivo que compita con la capacidad general; es un catalizador para ella.
Finalmente, en el dominio del razonamiento complejo, los resultados son posiblemente los más profundos. El modelo entrenado con reescrituras guiadas por el usuario mejoró su precisión promedio en problemas de razonamiento en más de 5 puntos porcentuales, pasando de un 26.5% a un 31.8%. Lo extraordinario de este resultado es la naturaleza de la retroalimentación utilizada para lograrlo. Durante el entrenamiento, el modelo no recibió soluciones correctas ni explicaciones detalladas. La retroalimentación consistía en simulaciones de comentarios de usuarios realistas y poco técnicos, del tipo «El paso 3 parece incompleto o tiene un error».
Esta mejora, lograda con una señal de supervisión tan «ligera», indica que el modelo no está simplemente memorizando correcciones. Está aprendiendo una habilidad mucho más fundamental: la metacognición de reconocer y responder a la crítica. Está aprendiendo a identificar un fallo en su propio proceso de razonamiento a partir de una señal negativa sutil y a intentar una nueva estrategia. Esta capacidad de autocorrección, aprendida a través de una imitación de la interacción natural, es un paso fundamental hacia la creación de sistemas de razonamiento más autónomos y fiables, capaces no solo de seguir instrucciones, sino de refinar su propio pensamiento.
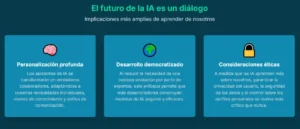
Hacia una inteligencia artificial que nos escucha
El trabajo presentado por los investigadores de Meta es más que una simple mejora técnica; representa una reorientación fundamental en nuestra filosofía sobre cómo construir y relacionarnos con la inteligencia artificial. Estamos presenciando el paso de un paradigma de mando y control, donde dictamos instrucciones a una herramienta pasiva, a un modelo de conversación y colaboración, donde enseñamos a un compañero de aprendizaje a través del diálogo natural. RLHI no es solo un nuevo acrónimo en el léxico de la IA; es la primera hoja de ruta técnica y empíricamente validada hacia una IA que verdaderamente nos escucha.
Esta transición tiene el potencial de crear un ciclo virtuoso de mejora simbiótica. Como señalan los propios autores, «si los usuarios saben que los modelos aprenderán de su retroalimentación textual, entonces es aún más probable que la proporcionen». Este es un punto crucial. A medida que los modelos entrenados con RLHI se vuelvan perceptiblemente más receptivos y personalizados, los usuarios se sentirán más motivados a interactuar con ellos de manera constructiva. La frustración de ser malinterpretado dará paso al incentivo de enseñar. Esto, a su vez, generará un flujo de datos de retroalimentación de una calidad y matiz aún mayores, lo que acelerará aún más la mejora del modelo. Este bucle de retroalimentación, donde mejores modelos inspiran mejor feedback, que a su vez crea mejores modelos, podría convertirse en el principal motor del progreso de la IA en los próximos años.
Por supuesto, este nuevo y prometedor horizonte no está exento de desafíos formidables. El objetivo final de este paradigma es el aprendizaje en línea, un sistema en el que un modelo desplegado en el mundo real se actualiza continuamente con cada nueva interacción, en lugar de ser reentrenado periódicamente en conjuntos de datos estáticos de conversaciones pasadas. Lograr esto de manera segura y estable es un desafío de ingeniería monumental. Además, a medida que los modelos aprenden de manera más íntima de los usuarios individuales, surgen preguntas críticas sobre la privacidad. Desarrollar técnicas de personalización que preserven la privacidad, garantizando que los datos de un usuario mejoren su propia experiencia sin ser expuestos o generalizados indebidamente, será de vital importancia. También será necesario crear modelos de recompensa más robustos y seguros, capaces de filtrar el feedback ruidoso, inconsistente o incluso malicioso. Y, finalmente, estos principios deberán extenderse más allá del texto para abarcar interacciones multimodales que incluyan la voz, las imágenes y las acciones en el mundo físico.
La búsqueda de la inteligencia artificial nos ha llevado por muchos caminos. Hemos construido máquinas que pueden calcular más rápido, recordar más y procesar patrones a una escala que excede la capacidad humana. Pero la verdadera medida de una inteligencia avanzada, quizás la más humana de todas, no es la capacidad de hablar, sino la de escuchar. El trabajo sobre el Aprendizaje por Refuerzo a partir de la Interacción Humana nos ofrece la primera visión concreta de un futuro en el que nuestros asistentes digitales no solo ejecutan nuestras órdenes, sino que aprenden, se adaptan y crecen con nosotros, a través del simple, profundo y transformador acto de la conversación.
Referencias
Azar, M. G., Guo, Z. D., Piot, B., Munos, R., Rowland, M., Valko, M., & Calandriello, D. (2024). A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics (pp. 4447-4455). PMLR.
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Chen, R., Zhang, X., Luo, M., Chai, W., & Liu, Z. (2024a). Pad: Personalized alignment of llms at decoding-time. arXiv preprint arXiv:2410.04070.
Chen, R., Arditi, A., Sleight, H., Evans, O., & Lindsey, J. (2025). Persona vectors: Monitoring and controlling character traits in language models. arXiv preprint arXiv:2507.21509.
Chen, Z., Gul, M. O., Chen, Y., Geng, G., Wu, A., & Artzi, Y. (2024b). Retrospective learning from interactions. arXiv preprint arXiv:2410.13852.
Don-Yehiya, S., Choshen, L., & Abend, O. (2024). Naturally occurring feedback is common, extractable and useful. arXiv preprint arXiv:2407.10944.
Dubois, Y., Galambosi, B., Liang, P., & Hashimoto, T. B. (2024). Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475.
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., & Kiela, D. (2024). Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306.
Frick, E., Jin, P., Li, T., Ganesan, K., Zhang, J., Jiao, J., & Zhu, B. (2024). Athene-70b: Redefining the boundaries of post-training for open models.
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783.
Hancock, B., Bordes, A., Mazare, P.-E., & Weston, J. (2019). Learning from dialogue after deployment: Feed yourself, chatbot! arXiv preprint arXiv:1901.05415.
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. (2024). Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008.
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., & Steinhardt, J. (2021). Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
Jang, J., Kim, S., Lin, B. Y., Wang, Y., Hessel, J., Zettlemoyer, L., Hajishirzi, H., Choi, Y., & Ammanabrolu, P. (2023). Personalized soups: Personalized large language model alignment via post-hoc parameter merging. arXiv preprint arXiv:2310.11564.
Jaques, N., Shen, J. H., Ghandeharioun, A., Ferguson, C., Lapedriza, A., Jones, N., Gu, S. S., & Picard, R. (2020). Human-centric dialog training via offline reinforcement learning. arXiv preprint arXiv:2010.05848.
Jiang, G., Xu, M., Zhu, S.-C., Han, W., Zhang, C., & Zhu, Y. (2023). Evaluating and inducing personality in pre-trained language models. Advances in Neural Information Processing Systems, 36, 10622-10643.
Lee, S., Park, S. H., Kim, S., & Seo, M. (2024). Aligning to thousands of preferences via system message generalization. Advances in Neural Information Processing Systems, 37, 73783-73829.
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. (2022). Solving quantitative reasoning problems with language models. Advances in neural information processing systems, 35, 3843-3857.
Li, T., Chiang, W.-L., Frick, E., Dunlap, L., Wu, T., Zhu, B., Gonzalez, J. E., & Stoica, I. (2024a). From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939.
Li, X., Zhou, R., Lipton, Z. C., & Legi, L. (2024b). Personalized language modeling from personalized human feedback. arXiv preprint arXiv:2402.05133.
Li, X., Zhang, T., Dubois, Y., Taori, R., Gulrajani, I., Guestrin, C., Liang, P., & Hashimoto, T. B. (2023). Alpacaeval: An automatic evaluator of instruction-following models.
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., & Cobbe, K. (2023). Let’s verify step by step. In The Twelfth International Conference on Learning Representations.
Mysore, S., Lu, Z., Wan, M., Yang, L., Menezes, S., Baghaee, T., Gonzalez, E. B., Neville, J., & Safavi, T. (2023). Pearl: Personalizing large language model writing assistants with generation-calibrated retrievers. arXiv preprint arXiv:2311.09180.
OpenAI. (2024). text-embedding-3-small.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35, 27730-27744.
Pang, R. Y., Roller, S., Cho, K., He, H., & Weston, J. (2023). Leveraging implicit feedback from deployment data in dialogue. arXiv preprint arXiv:2307.14117.
Poddar, S., Wan, Y., Ivison, H., Gupta, A., & Jaques, N. (2024). Personalizing reinforcement learning from human feedback with variational preference learning. Advances in Neural Information Processing Systems, 37, 52516-52544.
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., & Finn, C. (2023). Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36, 53728-53741.
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2024). Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling.
Salemi, A., Kallumadi, S., & Zamani, H. (2024). Optimization methods for personalizing large language models through retrieval augmentation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 752-762).
Silver, D., & Sutton, R. S. (2025). Welcome to the era of experience. Google AI, 1.
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., & Christiano, P. F. (2020). Learning to summarize with human feedback. Advances in neural information processing systems, 33, 3008-3021.
Tan, Z., Liu, Z., & Jiang, M. (2024). Personalized pieces: Efficient personalized large language models through collaborative efforts. arXiv preprint arXiv:2406.10471.
Tomasello, M., Carpenter, M., Call, J., Behne, T., & Moll, H. (2005). Understanding and sharing intentions: The origins of cultural cognition. Behavioral and brain sciences, 28(5), 675-691.
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. (2024a). Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37, 95266-95290.
Wang, Z., Dong, Y., Delalleau, O., Zeng, J., Shen, G., Egert, D., Zhang, J., Sreedhar, M. N., & Kuchaiev, O. (2024b). Helpsteer 2: Open-source dataset for training top-performing reward models. Advances in Neural Information Processing Systems, 37, 1474-1501.
Xu, J., Ju, D., Lane, J., Komeili, M., Smith, E. M., Ung, M., Behrooz, M., Ngan, W., Moritz, R., Sukhbaatar, S., et al. (2023). Improving open language models by learning from organic interactions. arXiv preprint arXiv:2306.04707.
Yang, R., Pan, X., Luo, F., Qiu, S., Zhong, H., Yu, D., & Chen, J. (2024). Rewards-in-context: Multi-objective alignment of foundation models with dynamic preference adjustment. arXiv preprint arXiv:2402.10207.
Yu, P., Yuan, W., Golovneva, O., Wu, T., Sukhbaatar, S., Weston, J., & Xu, J. (2025). Rip: Better models by survival of the fittest prompts. arXiv preprint arXiv:2501.18578.
Yuan, W., Kulikov, I., Yu, P., Cho, K., Sukhbaatar, S., Weston, J., & Xu, J. (2024). Following length constraints in instructions. arXiv preprint arXiv:2406.17744.
Zhang, Z., Rossi, R. A., Kveton, B., Shao, Y., Yang, D., Zamani, H., Dernoncourt, F., Barrow, J., Yu, T., Kim, S., et al. (2024). Personalization of large language models: A survey. arXiv preprint arXiv:2411.00027.
Zhao, H., Andriushchenko, M., Croce, F., & Flammarion, N. (2024a). Long is more for alignment: A simple but tough-to-beat baseline for instruction fine-tuning. arXiv preprint arXiv:2402.04833.
Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y., & Deng, Y. (2024b). Wildchat: 1m chatgpt interaction logs in the wild. arXiv preprint arXiv:2405.01470.
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., & Irving, G. (2019). Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.

