
En el vasto campo de la inteligencia artificial, donde los modelos más grandes y complejos a menudo dominan las tareas más exigentes, ha surgido una práctica fundamental que redefine cómo se desarrolla, comparte y despliega esta tecnología. Se trata de la destilación de conocimiento, una técnica que permite transferir la sabiduría de un modelo grande y poderoso (el «profesor» o «maestro») a uno más pequeño, eficiente y accesible, conocido como el «alumno» o «estudiante».
Este proceso no es meramente una operación de copia y pegado; es un acto de síntesis y compresión que captura la esencia del razonamiento de un gigante para alojarlo en un cuerpo más manejable. El concepto fue formalizado por Geoffrey Hinton y sus colegas en 2015, aunque sus raíces se remontan a trabajos previos de Caruana et al. en 2006 y propuestas tempranas de Alexey Ivakhnenko en 1965. La destilación ha evolucionado desde simples técnicas de compresión para dispositivos con recursos limitados hasta una herramienta estratégica para democratizar el acceso a capacidades de IA avanzadas, como GPT-4, Llama o Claude, adaptándolas a dominios especializados como la medicina.
El mecanismo central de la destilación reside en lo que se conoce como «objetivos blandos» o «targets suaves». En lugar de enseñar al modelo alumno únicamente con etiquetas duras, que son asignaciones categóricas claras como «esta imagen es un perro», el profesor proporciona al alumno una visión mucho más matizada. Genera una distribución de probabilidad completa sobre todas las posibles clases de salida. Por ejemplo, si el profesor clasifica una imagen, podría decir que hay un 90% de probabilidad de que sea un gato, un 7% de que sea un perro y un 3% de que sea un zorro.
Esta distribución no solo indica la respuesta correcta, sino que también revela información crucial sobre cómo el modelo generaliza y qué tan similares considera las diferentes categorías entre sí. Al imitar estas probabilidades suaves, el alumno aprende a replicar no solo las decisiones finales del profesor, sino también su forma de pensar, sus matices y sus incertidumbres.
Para lograr esto, se utiliza una función de pérdida especializada durante el entrenamiento del alumno. Esta función combina dos componentes: una pérdida estándar basada en las etiquetas duras reales (como la entropía cruzada) para asegurar que el alumno responda correctamente a las preguntas directas, y una segunda componente, la pérdida de destilación. La pérdida de destilación mide la divergencia entre la distribución de probabilidades que el alumno genera y la que generó el profesor.
La medida estadística comúnmente utilizada para esta divergencia es la Divergencia de Kullback-Leibler (KL), una fórmula que cuantifica cuánta información se pierde al aproximar la distribución del profesor con la del alumno. Para que esta comparación sea efectiva, especialmente cuando las probabilidades están muy concentradas en una sola clase, se aplica un truco técnico llamado «temperatura». Elevando temporalmente la temperatura en la función softmax del profesor, se suavizan las distribuciones de logits, haciendo que las probabilidades sean menos agudas y más informativas para el alumno. De este modo, el papel del profesor se convierte en un guía pedagógico, mientras que el rol del alumno es el de un estudiante atento que busca internalizar el conocimiento, no simplemente memorizar respuestas.
El legado de la destilación: desde BERT a los gigantes del razonamiento
La influencia de la destilación de conocimiento es profunda y visible en casi todos los aspectos de la moderna inteligencia artificial. Su impacto va desde la optimización de modelos existentes hasta la creación de nuevos ecosistemas de software. Una de las aplicaciones más emblemáticas es DistilBERT, una versión de BERT que, con solo 66 millones de parámetros frente a los 110 millones del original, es un 40% más ligera y un 60% más rápida en inferencia, todo ello sin perder el 97% de su precisión en benchmarks como GLUE. Este tipo de éxito demuestra la capacidad de la destilación para crear versiones de código abierto de modelos propietarios, democratizando el acceso a capacidades de lenguaje natural avanzadas. Otros ejemplos notables incluyen DistilGPT y DistilRoBERTa, modelos que han sido ampliamente adoptados en diversas tareas de procesamiento de lenguaje natural.
Más recientemente, la destilación ha adquirido una importancia estratégica en el desarrollo de modelos de razonamiento de alto nivel. El caso de Amazon Alexa es paradigmático: partiendo de solo 7,000 horas de datos etiquetados, utilizaron un modelo maestro para generar etiquetas blandas en un millón de horas de audio no etiquetado, una estrategia que les permitió mejorar significativamente el rendimiento de sus sistemas de reconocimiento de voz.
En el ámbito competitivo, investigadores de Shanghai Jiao Tong University demostraron que utilizando cadenas de razonamiento largas generadas por el modelo O1 de OpenAI, pudieron entrenar un modelo base más pequeño que superó al propio O1-preview en difíciles pruebas matemáticas como AIME y MATH500. Esto no solo ilustra la potencia de la destilación, sino que también plantea preocupaciones sobre la dependencia excesiva de replicar el trabajo de otros en lugar de innovar de forma fundamental.
Esta tendencia se ve reflejada en el surgimiento de competidores poderosos que se construyen sobre la base de destilar los modelos líderes del mercado. DeepSeek, una empresa china de IA, lanzó en enero de 2025 el modelo DeepSeek-R1, diseñado para competir directamente con o1 de OpenAI. Utilizando técnicas de destilación, DeepSeek creó versiones más pequeñas de este modelo de razonamiento avanzado, basándose tanto en la arquitectura Qwen como en Llama.
Los resultados fueron impresionantes: el modelo destilado basado en Qwen-32B alcanzó un 94.3% en MATH-500, y el basado en Llama-70B llegó al 94.5%, acercándose notablemente al rendimiento del modelo maestro de OpenAI. Estas acciones provocaron rumores de destilación no autorizada de los modelos de OpenAI y tuvieron un impacto tangible en el mercado, causando una caída del 18% en las acciones de Nvidia y perdiendo cerca de 600 mil millones en capitalización bursátil.
Los casos mencionados muestran que la destilación ya no es una técnica marginal, sino un pilar central en la estrategia de muchos actores del sector. Permite a empresas y organizaciones reducir costos computacionales, desplegar modelos en dispositivos de borde como móviles o vehículos autónomos, y ofrecer servicios más rápidos y económicos, como las versiones gratuitas de Gemini Flash o o3-mini de OpenAI. Sin embargo, este poder viene acompañado de importantes dilemas éticos y legales, como la posible violación de derechos de autor si se destila un modelo propietario sin permiso, o la pérdida de conocimiento valioso si el proceso no se realiza con cuidado.
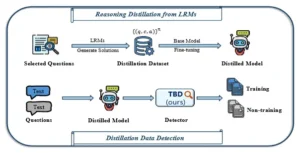
Descripción general de la detección de datos de destilación. El panel superior ilustra el proceso de destilación de razonamiento que destila las capacidades de razonamiento de los LRM a LLM más pequeños. El panel inferior ilustra el proceso de detección de datos de destilación.
El desafío emergente: la opacidad de los modelos destilados
A pesar de sus beneficios tangibles, la destilación de conocimiento introduce un desafío cada vez más crítico: la opacidad inherente a los modelos resultantes. Cuando se destila un modelo grande y complejo, el resultado puede ser una «caja negra» aún más compacta y difícil de interpretar. El conocimiento transferido, que originalmente residía en miles de millones de parámetros interconectados, se condensa en una estructura más pequeña, lo que dificulta entender exactamente cómo el modelo toma decisiones. Esta falta de transparencia es problemática en múltiples frentes. Primero, afecta la confianza del usuario.
Si un modelo médico destilado recomienda un tratamiento, sería imperativo entender sus bases para validar su decisión, pero la naturaleza opaca de la destilación lo hace un obstáculo. Segundo, complica la depuración y la mejora del modelo. Si el modelo comete errores sistemáticos, es más difícil rastrear la causa si el proceso de transferencia oculta las relaciones subyacentes. Tercero, presenta riesgos éticos y legales significativos. Si un modelo destilado perpetúa sesgos presentes en el modelo maestro, puede ser difícil identificar y corregir dichos prejuicios, lo que podría llevar a consecuencias discriminatorias indeseadas.
Una de las principales preocupaciones asociadas a los modelos destilados es la posible pérdida de precisión y calidad de conocimiento. Si bien la destilación puede mantener un rendimiento comparable al del modelo maestro, existe un compromiso inevitable (trade-off). El modelo alumno, por definición, tiene menos capacidad para representar el conocimiento, lo que puede llevar a una disminución en la precisión en tareas complejas o a un aumento en las alucinaciones, donde el modelo genera información plausible pero incorrecta.
Por ejemplo, el modelo DeepSeek 8b muestra un peor rendimiento que el modelo completo de 671b, lo que ilustra que la destilación no garantiza la preservación perfecta de la inteligencia. Además, el éxito de la destilación es altamente dependiente de la calidad del modelo maestro; si el maestro mismo es defectuoso o está sesgado, ese problema se transferirá al alumno.
Otro desafío importante es la complejidad del propio proceso de entrenamiento. La implementación requiere un cuidadoso ajuste de hiperparámetros, como la temperatura y los pesos dados a las diferentes partes de la función de pérdida, para lograr un equilibrio óptimo entre la imitación de las predicciones finales y la captura de los objetivos blandos.
Un entrenamiento excesivo puede llevar a que el modelo alumno aprenda patrones superficiales o «respuestas planificadas» en lugar de un verdadero entendimiento, lo que resulta en una pérdida de contexto y una menor capacidad de generalización. La reproducibilidad del proceso también es un punto débil; sin una documentación y configuraciones detalladas (una «receta»), es difícil replicar los mismos resultados, lo que socava la ciencia abierta y la validación independiente.
Finalmente, la proliferación de modelos destilados crea una capa adicional de anonimato en el panorama de la IA. Con tantos modelos pequeños disponibles en plataformas como Hugging Face, es cada vez más difícil saber si un modelo específico fue entrenado desde cero, o si en realidad es una versión más ligera de un modelo mayor y quizás propietario. Esta ambigüedad no solo es problemática desde una perspectiva de propiedad intelectual y cumplimiento de licencias, sino que también complica la evaluación de la seguridad y fiabilidad de estos sistemas.
¿Quién es responsable si un modelo destilado malicioso causa daños? La cadena de custodia del conocimiento se vuelve borrosa, y la propia identidad del modelo queda oscurecida detrás de su nombre y sus métricas de rendimiento. Superar estos desafíos requiere un enfoque multidisciplinar que combine investigación en interpretabilidad de modelos, mejores prácticas de entrenamiento y marcos regulatorios claros para garantizar que la eficiencia no se alcance a expensas de la responsabilidad y la transparencia.
La huella inconfundible: metodología y resultados del paper Detecting distillation data from reasoning models
En medio de la creciente opacidad de los modelos de IA, surge una pregunta crucial: ¿es posible determinar si un modelo dado es original o si, por el contrario, ha sido creado mediante la destilación de otro modelo? El artículo científico Detecting Distillation Data from Reasoning Models, publicado el 6 de octubre de 2025 por un equipo de investigadores liderado por Hongxin Wei, ofrece una respuesta rotunda: sí, es posible, y presenta un método novedoso para hacerlo. El estudio, que se centra específicamente en los modelos de razonamiento, introduce un indicador llamado Desviación de Probabilidad de Token (Token Probability Deviation, TBD), capaz de detectar si una pregunta específica formó parte de los datos utilizados para entrenar (destilar) un modelo de lenguaje.
La metodología de este método se basa en un hallazgo clave sobre el comportamiento de los modelos destilados. A diferencia de los modelos entrenados de forma convencional, los modelos destilados tienden a mostrar un patrón distintivo en su generación de texto. Para las «preguntas vistas» o miembros (es decir, aquellas que fueron parte de los datos de destilación), el modelo generará secuencias de tokens que tienen una probabilidad extremadamente alta y casi determinista.
En otras palabras, una vez que el modelo ha «aprendido» la respuesta correcta junto con su contexto de razonamiento, es muy probable que genere esa misma secuencia de manera consistente. Por el contrario, para las «preguntas no vistas» o no miembros (aquellas que no estaban en los datos de entrenamiento), el modelo debe improvisar. En esta improvisación, es más probable que genere tokens de baja probabilidad, es decir, aquellos que son menos comunes o esperados en su vocabulario.
El método TBD cuantifica esta diferencia en el comportamiento. Dada una pregunta, se calcula un «score» que mide la desviación de las probabilidades de los tokens que el modelo genera en respuesta. Si la pregunta era parte de los datos de destilación, el score será bajo, ya que los tokens generados tendrán alta probabilidad. Si la pregunta no era parte de esos datos, el score será alto, debido a la aparición de tokens de baja probabilidad. Lo notable de este enfoque es su simplicidad y su robustez: el método solo necesita la pregunta como entrada y no requiere acceso a las trazas completas de razonamiento del modelo, lo que lo hace fácil de implementar y aplicar.
Los resultados del estudio son convincentes. El método fue evaluado en varios modelos de razonamiento, incluyendo diferentes versiones del Qwen2.5 (7B, 14B y 32B), así como en modelos de referencia como Sky-T1-32B-preview y Bespoke-32B, que se sabe que han aplicado destilación de razonamiento. En el conjunto de datos S1, el modelo Qwen2.5-32B-Instruct finetuneado con TBD logró un Área bajo la Curva (AUC) de 0.918, una métrica que indica un alto nivel de discriminación entre las clases.
Específicamente, el método alcanzó un True Positive Rate (TPR) del 47% a un False Positive Rate (FPR) del 1%, lo que significa que pudo identificar correctamente casi la mitad de las preguntas de destilación mientras mantenía un error muy bajo. Los autores también encontraron que el método funcionaba mejor en modelos más grandes, lo que sugiere una correlación entre la capacidad de memorización del modelo y la manifestación de esta huella digital. Además, demostraron que el método es robusto a cambios en los hiperparámetros, como la longitud máxima del prompt, con una longitud de truncamiento óptima de 300 tokens, y que no requería ajustes específicos por tarea. Esta capacidad de detectar la firma de la destilación abre nuevas puertas para la verificación de modelos, la investigación académica y la vigilancia de la seguridad en el ecosistema de la IA.
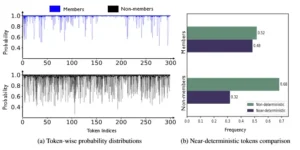
Comparación del comportamiento de generación a nivel de token de modelos destilados para 20 preguntas de miembros y 20 de no miembros bajo decodificación voraz. (a) Distribuciones de probabilidad por token: contrastamos la distribución de probabilidad por token entre miembros y no miembros, mostrando que los no miembros tienden a producir más tokens con menor probabilidad. (b) Tokens casi deterministas vs. no deterministas: los tokens casi deterministas indican tokens generados con probabilidades cercanas a 1, y viceversa para tokens no deterministas. El modelo de razonamiento destilado tiende a generar más tokens casi deterministas para miembros.
Implicaciones transformadoras: la relevancia social y tecnológica del método TBD
El desarrollo del método Token Probability Deviation (TBD) trasciende el simple ámbito de la investigación académica para convertirse en una herramienta con profundas implicaciones sociales, tecnológicas y científicas. Su relevancia radica en su capacidad para introducir un elemento de transparencia y auditoría en un campo que amenaza con volverse cada vez más opaco. En un ecosistema donde la mayoría de los modelos de IA de alto rendimiento son secretos comerciales y la proliferación de modelos destilados es masiva, la capacidad de verificar la procedencia de un modelo es fundamental para la responsabilidad y la confianza pública.
Desde una perspectiva social y ética, el método TBD se posiciona como un defensor de la integridad del ecosistema de la IA. Uno de los mayores problemas asociados a la destilación es la falta de claridad sobre el origen de los datos de entrenamiento. Si un modelo ha sido destilado de un modelo propietario sin permiso, podría constituir una violación de derechos de autor o términos de servicio.
El TBD proporciona una herramienta para investigar estas sospechas, permitiendo a los auditores y reguladores examinar modelos sospechosos para detectar signos de plagio o uso no autorizado. Esto podría forzar a una mayor transparencia por parte de las empresas de IA, obligándolas a declarar explícitamente si sus modelos son originales o derivados de terceros. Además, en contextos sensibles como la justicia penal o el diagnóstico médico, donde la fiabilidad de un modelo es crítica, el TBD podría ser utilizado como parte de un protocolo de validación para asegurar que un modelo no haya sido entrenado con datos contaminados o sesgados que podrían llevar a decisiones injustas.
Técnicamente, el método representa un avance significativo en el campo de la forense de IA y la seguridad de los modelos. Ha demostrado ser capaz de identificar modelos que han aplicado técnicas avanzadas de destilación, como la destilación de cadenas de razonamiento. Esto es particularmente importante porque la destilación de razonamiento es una de las formas más sofisticadas de transferir conocimiento, ya que va más allá de las respuestas simples para replicar el proceso de pensamiento del modelo maestro.
La capacidad de detectar incluso estos métodos avanzados indica que el enfoque del TBD está capturando un fenómeno fundamental en el funcionamiento de los modelos destilados. Esta capacidad de detección puede impulsar la investigación en contramedidas, llevando a una «carrera armamentística» entre los métodos de ocultación y los de detección, similar a lo que ocurre en la seguridad informática. Eventualmente, podría dar lugar a estándares de «limpieza» de datos de entrenamiento, donde los modelos deben pasar por un proceso de limpieza para eliminar cualquier «huella digital» de sus orígenes antes de ser compartidos públicamente.
Desde una perspectiva científica, el método TBD abre nuevas vías de investigación sobre los límites y las capacidades de los modelos de IA. Al estudiar por qué y cómo los modelos destilados desarrollan esta firma distintiva de generar tokens casi deterministas para las entradas vistas, los científicos pueden obtener una comprensión más profunda de la memoria interna de los modelos.
¿Cuánto de los datos de entrenamiento memorizan realmente? ¿Cómo interactúa esta memoria con la generalización? Las respuestas a estas preguntas son cruciales para entender tanto los puntos fuertes como las debilidades de los modelos de IA. Por ejemplo, si un modelo destilado muestra una alta propensión a memorizar los datos de entrenamiento, podría explicar por qué tiende a tener más alucinaciones o a ser más vulnerable a ataques de adversarialidad dirigidos a esas entradas específicas. El método, por lo tanto, no solo sirve como una herramienta de detección, sino que también funciona como un microscopio para observar los procesos internos de los modelos de IA, contribuyendo a una disciplina más sólida y fundamentada de la ciencia de la IA.
El futuro de la IA transparente: vigilancia, ética y la nueva era de la verificación
El trabajo de detección de la firma de la destilación no es un mero ejercicio académico; es un catalizador potencial para una nueva era en el desarrollo de la inteligencia artificial, una era marcada por la necesidad de la verificación, la vigilancia y la transparencia. Como la tecnología de la IA continúa avanzando a un ritmo vertiginoso, la capacidad de auditar y verificar los sistemas de IA se convertirá en una necesidad tan fundamental como la seguridad en la construcción civil o la inocuidad en la industria farmacéutica. El método TBD, y los principios en los que se basa, sentarán las bases para un ecosistema de IA más seguro y responsabilizable.
En el futuro inmediato, es probable que veamos la integración de estas técnicas de detección en herramientas de auditoría de IA. Empresas de consultoría, organismos gubernamentales y organizaciones sin fines de lucro podrían utilizar métodos como el TBD para realizar «exámenes de ADN» en los modelos de IA. Esto permitiría evaluar la procedencia de un modelo, verificar su conformidad con las licencias de uso y detectar la presencia de datos de entrenamiento no deseados o sesgados.
Imagine una plataforma en línea donde los usuarios puedan enviar un modelo y recibir un informe de auditoría que detalle su historial de entrenamiento, incluyendo si ha sido destilado y de qué modelo. Esta transparencia podría crear una ventaja competitiva para las organizaciones que se comprometen con la ética, al tiempo que sanciona a aquellas que operan en la oscuridad.
Sin embargo, esta nueva era de la verificación no estará exenta de desafíos y dilemas. La relación entre los creadores de modelos y los auditores se asemejará a una carrera armamentística. A medida que los métodos de detección se vuelvan más sofisticados, los creadores de modelos intentarán desarrollar técnicas de «ocultación» más efectivas, quizás alterando el comportamiento de sus modelos para que no exhiban las firmas detectables. Esto podría llevar a una situación en la que los modelos son deliberadamente diseñados para ser «auditor-friendly» en la superficie, mientras que su funcionamiento interno sigue siendo una «caja negra». Por lo tanto, será crucial que las técnicas de detección también evolucionen, incorporando análisis más profundos de la estructura del modelo y su comportamiento en un espectro más amplio de tareas.
Además, la aplicación de estas herramientas plantea cuestiones éticas complejas. ¿Debería ser ilegal destilar un modelo propietario, incluso con fines de investigación? ¿Dónde se traza la línea entre el uso justo y la infracción de derechos de autor? La sociedad y el mundo legal necesitarán establecer marcos claros para navegar estos nuevos territorios. La detección de la firma de la destilación proporciona la evidencia empírica necesaria para que estas discusiones tengan lugar, moviéndolas de un terreno puramente especulativo a uno basado en hechos medibles.
En última instancia, el trabajo sobre la detección de la firma de la destilación es un recordatorio poderoso de que la innovación tecnológica y la responsabilidad deben caminar juntas. Mientras los ingenieros de IA construyen modelos cada vez más poderosos y eficientes, los científicos y los reguladores deben construir las herramientas y los marcos para asegurar que estos modelos se utilicen para el bien.
La capacidad de descubrir los secretos de los modelos de razonamiento no es solo un avance técnico; es un paso hacia una IA más inteligente, pero también más transparente y digna de confianza. Este esfuerzo colectivo de vigilancia y verificación es fundamental para garantizar que la revolución de la IA beneficie a toda la humanidad, en lugar de crear nuevas divisiones y riesgos imprevistos.
Referencias
Chang, K. K., Cramer, M., Soni, S., and Bamman, D. Speak, memory: an archaeology of books known to chatgpt/gpt-4. arXiv preprint arXiv:2305.00118, 2023.
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025.
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
Kumar, A., Zhuang, V., Agarwal, R., Su, Y., Co-Reyes, J. D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917, 2024.
Li, Y. Estimating contamination via perplexity: quantifying memorisation in language model evaluation. arXiv preprint arXiv:2309.10677, 2023.
Liu, W., Xu, J., Yu, F., Lin, Y., Ji, K., Chen, W., Xu, Y., Wang, Y., Shang, L., and Wang, B. Qfft, question-free fine-tuning for adaptive reasoning. arXiv preprint arXiv:2506.12860, 2025.
Ma, Z., Yuan, Q., Zhang, L., and Zhou, D. Slow tuning and low-entropy masking for safe chain-of-thought distillation. arXiv preprint arXiv:2508.09666, 2025.
Mireshghallah, F., Goyal, K., Uniyal, A., Berg-Kirkpatrick, T., and Shokri, R. Quantifying privacy risks of masked language models using membership inference attacks. arXiv preprint arXiv:2203.03929, 2022.
Mozes, M., He, X., Kleinberg, B., and Griffin, L. D. Use of llms for illicit purposes: Threats, prevention measures, and vulnerabilities. arXiv preprint arXiv:2308.12833, 2023.
Liu, D., Hao, Q., Liu, H., Yang, Z., Xie, J., Gu, N., et al. Beyond scaling law: A data-efficient distillation framework for reasoning. arXiv preprint arXiv:2508.09883, 2025b.
Xin, H., Ren, Z. Z., Song, J., Shao, Z., Zhao, W., Wang, H., Liu, B., Zhang, L., Lu, X., Du, Q., et al. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. arXiv preprint arXiv:2408.08152, 2024.
Xu, C., Guan, S., Greene, D., and Kechadi, M. Benchmark data contamination of large language models: A survey. arXiv preprint arXiv:2406.04244, 2024a.
Xu, R., Wang, Z., Fan, R.-Z., and Liu, P. Benchmarking benchmark leakage in large language models. arXiv e-prints, pp. arXiv–2404, 2024b.
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
Ye, Y., Huang, Z., Xiao, Y., Chern, E., Xia, S., and Liu, P. Limo: Less is more for reasoning. arXiv preprint arXiv:2502.03387, 2025.
Zhang H. et al. (2025) Detecting distillation data from reasoning models. arXiv e-prints, pp. arXiv–2510.04850.

