
Durante los últimos meses, hemos asistido a una transformación radical en la forma en que las grandes modelos de lenguaje abordan problemas complejos. Sistemas como o1 de OpenAI o DeepSeek-R1 han demostrado capacidades sorprendentes al generar largas cadenas de razonamiento antes de proporcionar una respuesta final.
Estos modelos «pensantes» no responden de inmediato: reflexionan, exploran alternativas, verifican sus propios pasos y, solo entonces, ofrecen una solución. El resultado ha sido espectacular en áreas como las matemáticas avanzadas, la programación o la resolución de acertijos científicos de nivel doctoral.
Sin embargo, existe un problema fundamental que amenaza con frenar esta revolución: el coste computacional. Cada vez que uno de estos sistemas genera un token adicional de razonamiento, debe procesar todo el contexto previo. En la arquitectura transformer, que sustenta a prácticamente todos los modelos lingüísticos actuales, esto implica que el tiempo de cálculo crece de forma cuadrática con la longitud del pensamiento. Si un modelo piensa durante mil tokens, el coste no es mil veces mayor que pensar un solo token, sino un millón de veces mayor.
Cuando se intenta escalar este razonamiento a decenas o cientos de miles de tokens, los recursos necesarios se vuelven prohibitivos. Entrenar un modelo para que piense durante cien mil tokens podría requerir meses de tiempo de computación en cientos de GPUs avanzadas, con costes que se disparan exponencialmente.
Aquí es donde entra en escena Delethink, un paradigma radicalmente distinto propuesto por un equipo de investigadores de Mila, McGill University, Microsoft Research y otras instituciones académicas canadienses.
La idea central es tan elegante como disruptiva: en lugar de obligar al modelo a mantener en su memoria de trabajo todo el historial de razonamiento acumulado, se le enseña a pensar en fragmentos de tamaño fijo, olvidando periódicamente el pasado y conservando solo un pequeño resumen textual que le permita continuar. Este resumen funciona como un estado markoviano, una especie de nota mental que condensa lo esencial para seguir adelante sin arrastrar el peso de miles de tokens previos.
El término «markoviano» proviene de la teoría matemática de procesos de Markov, donde el futuro depende únicamente del estado presente, no de toda la historia previa. Aplicado a la inteligencia artificial, esto significa que el modelo aprende a escribir, al final de cada bloque de razonamiento, una síntesis que encapsula todo lo relevante.
Cuando comienza el siguiente bloque, el contexto se reinicia: desaparece el texto antiguo y solo permanece la pregunta original junto con ese breve resumen. El modelo, entrenado mediante aprendizaje por refuerzo, descubre por sí mismo qué información debe preservar en esa transición y qué puede descartar sin perjudicar la calidad del razonamiento.
Las implicaciones son profundas. Mientras que los enfoques convencionales, que los autores denominan LongCoT (Long Chain of Thought, o cadena de pensamiento larga), sufren un crecimiento cuadrático en tiempo y memoria, Delethink escala de forma lineal.
Generar un razonamiento de un millón de tokens bajo LongCoT requeriría recursos astronómicos; con Delethink, el coste se mantiene manejable porque en ningún momento el modelo procesa más que un fragmento constante de contexto. La diferencia no es marginal: los investigadores estiman que entrenar un modelo para pensar en promedio noventa y cuatro mil tokens costaría veintisiete meses de GPU bajo el paradigma tradicional, frente a solo siete meses con Delethink.
Pero más allá de la eficiencia, lo verdaderamente notable es que este enfoque funciona. En experimentos con modelos de mil quinientos millones de parámetros entrenados sobre problemas matemáticos de competición de nivel universitario y olimpiadas internacionales, Delethink no solo iguala el rendimiento de los sistemas convencionales, sino que a menudo los supera.
Y, lo más sorprendente, cuando se permite al modelo pensar más allá del límite para el que fue entrenado (una práctica conocida como escalado en tiempo de prueba), Delethink sigue mejorando, mientras que los modelos tradicionales se estancan. Algunos problemas del examen AIME, una de las competiciones matemáticas más exigentes para estudiantes preuniversitarios en Estados Unidos, solo fueron resueltos por el modelo cuando se le permitió razonar durante más de ciento cuarenta mil tokens, pese a haber sido entrenado con un presupuesto de veinticuatro mil.
La pregunta que surge naturalmente es: ¿cómo es posible que un modelo pueda pensar eficazmente sin acceso a todo su historial de razonamiento? ¿No se perderá información crucial al borrar periódicamente el contexto? Los autores ofrecen una explicación fascinante: los modelos de razonamiento actuales, incluso sin entrenamiento específico, ya exhiben un comportamiento latentemente markoviano. Cuando se les aplica Delethink sin modificación alguna, recuperan la mayor parte de su rendimiento original.
Esto sugiere que, en cierto modo, estos sistemas ya han aprendido durante su preentrenamiento a condensar información de manera efectiva, quizás porque el razonamiento humano del que fueron entrenados también tiende a ser markoviano. Después de todo, cuando resolvemos un problema complejo, no retenemos cada paso intermedio en nuestra memoria de trabajo; vamos sintetizando conclusiones parciales que nos permiten avanzar sin saturarnos cognitivamente.
Delethink no es solo una técnica de optimización. Es una nueva forma de concebir el entorno de aprendizaje en el que operan estos modelos. Tradicionalmente, el entrenamiento por refuerzo de sistemas de razonamiento se ha centrado en ajustar la política del modelo (es decir, qué tokens genera) sin cuestionar el entorno subyacente, que simplemente concatena tokens indefinidamente.
Los investigadores detrás de Delethink han dado un paso atrás y preguntado: ¿y si el entorno mismo es el problema? Al rediseñar las reglas del juego, introduciendo reinicios periódicos y forzando al modelo a mantener un estado acotado, han desbloqueado una vía hacia el razonamiento ultraextendido que antes parecía inalcanzable.
Este artículo explorará en profundidad los fundamentos técnicos de Delethink, su validación experimental, las sorpresas que los investigadores encontraron en el camino y las implicaciones más amplias para el futuro de la inteligencia artificial. Porque si Delethink demuestra ser escalable y robusto, podríamos estar ante el primer paso serio hacia agentes de IA capaces de pensar durante millones de tokens, abriendo aplicaciones que hoy apenas podemos imaginar.
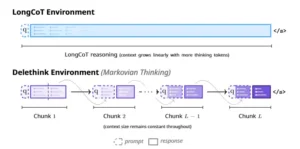
El diagrama conceptual clave. Arriba: LongCoT concatena tokens indefinidamente, el contexto crece sin límite. Abajo: Delethink divide el razonamiento en fragmentos (chunks) de tamaño fijo. Al final de cada chunk, el contexto se reinicia conservando solo la pregunta (q) más un resumen breve (parte violeta sombreada), manteniendo el tamaño constante.
El dilema del razonamiento largo
Para entender por qué Delethink representa un avance significativo, conviene primero comprender el problema que resuelve. Los modelos de lenguaje basados en transformers, la arquitectura dominante desde 2017, funcionan mediante un mecanismo llamado atención. Cuando el modelo procesa una secuencia de tokens, cada token «atiende» a todos los tokens anteriores, calculando qué partes del contexto son relevantes para generar el siguiente símbolo. Este proceso requiere comparar cada token con cada otro, lo que implica un número de operaciones proporcional al cuadrado de la longitud de la secuencia.
Si la secuencia tiene mil tokens, se realizan aproximadamente un millón de operaciones de atención. Con diez mil tokens, cien millones. Con cien mil, diez mil millones. Este crecimiento cuadrático no es solo teórico: se traduce directamente en tiempo de ejecución y consumo de memoria. La memoria intermedia conocida como caché KV, que almacena representaciones de los tokens previos para acelerar la generación, crece linealmente con la longitud, limitando el número de secuencias que pueden procesarse en paralelo en una GPU.
En el contexto del razonamiento extendido, esto crea un círculo vicioso. Para entrenar un modelo a pensar más, se necesitan ejemplos de razonamiento largo. Pero generar y procesar esos ejemplos durante el entrenamiento por refuerzo consume recursos desproporcionados.
Los investigadores han intentado diversas estrategias para mitigar el problema: limitar cuántas veces se usan trazas largas durante el entrenamiento, añadir penalizaciones para favorecer soluciones más breves, o desarrollar métodos de poda que terminen la generación anticipadamente. Sin embargo, todas estas soluciones operan dentro del paradigma LongCoT y, por tanto, heredan su escalado cuadrático fundamental.
Delethink propone una alternativa radical: cambiar el entorno de aprendizaje para que el estado que el modelo observa nunca crezca, independientemente de cuánto piense. Esto requiere reformular el problema de aprendizaje por refuerzo desde cero.
Anatomía de un pensador markoviano
El funcionamiento de Delethink puede describirse mediante una analogía. Imaginemos a un matemático resolviendo un problema complicado en una pizarra pequeña. Trabaja durante un rato, llenando la pizarra con ecuaciones y diagramas. Cuando se queda sin espacio, borra todo excepto las conclusiones clave, escribe una nota resumiendo lo que ha descubierto hasta ahora, y continúa trabajando desde ahí. Nunca tiene acceso simultáneo a todo el trabajo anterior, pero si sus resúmenes son buenos, puede seguir progresando sin perderse.
Delethink implementa este proceso de manera sistemática. El razonamiento se divide en fragmentos o «chunks» de tamaño fijo, por ejemplo, ocho mil tokens. Dentro de cada fragmento, el modelo genera texto normalmente, atendiendo a todos los tokens previos dentro de ese fragmento. Al alcanzar el límite, el sistema borra el contexto y reinicia la generación con un nuevo prompt que contiene solo la pregunta original más un pequeño «estado markoviano»: los últimos cuatro mil tokens del fragmento anterior.
Este estado markoviano es crucial. No es un resumen generado por un sistema externo ni información extraída algorítmicamente; es texto que el propio modelo escribió al final del fragmento previo, sabiendo (porque así lo aprendió mediante refuerzo) que será lo único que verá en el siguiente ciclo.
Durante el entrenamiento, el modelo recibe recompensas por resolver problemas correctamente, independientemente de cómo estructure su razonamiento. A través de miles de iteraciones, descubre que escribir cierto tipo de información cerca del final de cada fragmento (resultados intermedios, recordatorios de la estrategia, síntesis de subproblemas resueltos) le permite mantener la coherencia tras el reinicio.
El proceso se repite hasta que el modelo emite una señal de finalización o se alcanza un límite de iteraciones. Con fragmentos de ocho mil tokens y un estado markoviano de cuatro mil, cada ciclo añade cuatro mil tokens netos de razonamiento. Cinco iteraciones permiten pensar hasta veinticuatro mil tokens, manteniendo el contexto activo siempre por debajo de ocho mil.
El gradiente de aprendizaje, derivado formalmente en el artículo mediante el algoritmo REINFORCE clásico de aprendizaje por refuerzo, se calcula sumando las contribuciones de cada fragmento al resultado final. La estructura se asemeja a PPO (Proximal Policy Optimization), el método de optimización estándar en este campo, con la diferencia de que la pérdida se normaliza por el número total de tokens generados en la traza completa. Esto garantiza que trazas más largas no dominen artificialmente el gradiente.

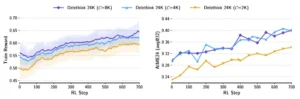
Triple resumen: (a) Durante entrenamiento, Delethink alcanza y supera a LongCoT. (b) Crucialmente: más allá del límite entrenado (zona sombreada), Delethink sigue mejorando mientras LongCoT se estanca. (c) El coste en horas de GPU crece linealmente para Delethink pero cuadráticamente para LongCoT.
La paradoja del rendimiento sin historia completa
Uno de los hallazgos más intrigantes del estudio es que Delethink no solo funciona tras entrenamiento, sino que ya funciona razonablemente bien desde el primer momento, sin ninguna adaptación. Los autores tomaron modelos de razonamiento preentrenados de la familia R1-Distill (versiones de mil quinientos millones, siete mil millones y catorce mil millones de parámetros) y simplemente aplicaron el procedimiento de fragmentación con reinicios, sin cambiar los pesos del modelo. Sorprendentemente, estos modelos recuperaron entre el setenta y el noventa por ciento de su rendimiento original bajo el paradigma LongCoT convencional, dependiendo del tamaño del fragmento utilizado.
¿Por qué funciona esto? La hipótesis de los autores es doble. Primero, los modelos de lenguaje son preentrenados mayoritariamente con contextos relativamente cortos (ocho a treinta y dos mil tokens). Podría ser que «piensen mejor» en ventanas de ese tamaño porque es a lo que están habituados. Segundo, y más especulativamente, el razonamiento humano que figura en los textos de entrenamiento es, en sí mismo, aproximadamente markoviano.
Cuando escribimos demostraciones matemáticas o explicaciones técnicas, tendemos a presentar resultados intermedios de forma explícita, de modo que cada paso se entienda sin necesidad de recordar cada cálculo previo. Los modelos, al aprender de estos textos, internalizan esta estructura.
Esta capacidad latente tiene consecuencias prácticas inmediatas. Significa que Delethink arranca con un conjunto abundante de trazas válidas desde la inicialización, proporcionando ejemplos positivos que el aprendizaje por refuerzo puede refinar. En contraste, si el comportamiento markoviano fuera completamente ajeno al modelo, el entrenamiento tendría que partir de cero, explorando aleatoriamente hasta encontrar estrategias funcionales, lo cual sería mucho más difícil.
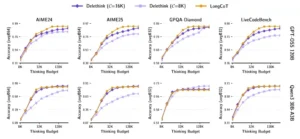
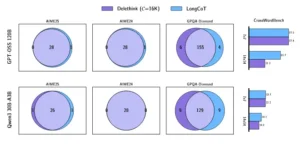
Los autores extendieron esta validación a modelos de vanguardia mucho más grandes: GPT-OSS de ciento veinte mil millones de parámetros y Qwen3 de treinta mil millones. Ambos, sin entrenamiento adicional, mostraron un comportamiento markoviano robusto en tareas diversas, desde exámenes de matemáticas de nivel olímpico hasta problemas de programación y crucigramas. En particular, los modelos resolvieron conjuntos de problemas casi idénticos bajo Delethink y LongCoT, con solapamientos superiores al noventa por ciento en las olimpiadas matemáticas AIME. Esto sugiere que la capacidad de razonar markovianamente no es un artefacto de modelos pequeños o entrenamiento específico, sino una característica emergente de los sistemas de razonamiento actuales.
Resultados experimentales
El experimento central del artículo consistió en entrenar un modelo R1-Distill de mil quinientos millones de parámetros mediante aprendizaje por refuerzo en un conjunto de aproximadamente cuarenta mil problemas matemáticos de nivel competitivo, utilizando tanto Delethink como LongCoT con un presupuesto idéntico de veinticuatro mil tokens de razonamiento. Ambos métodos partieron del mismo punto de inicialización y se entrenaron durante mil pasos de optimización.
Los resultados fueron contundentes. Delethink no solo alcanzó el rendimiento de LongCoT, sino que lo superó ligeramente en las métricas clave. En el examen AIME 2024, Delethink logró un cuarenta y seis por ciento de precisión frente al cuarenta por ciento de LongCoT. En AIME 2025, treinta y cinco por ciento frente a treinta por ciento. En HMMT, otra competición matemática universitaria, veintiuno por ciento frente a dieciocho por ciento. Estas diferencias pueden parecer modestas, pero en problemas de este nivel de dificultad, cada punto porcentual representa resolver correctamente uno o dos problemas adicionales de entre treinta, lo cual es significativo.
Más revelador aún fue el comportamiento durante el escalado en tiempo de prueba. Cuando se permite al modelo pensar más allá del límite para el que fue entrenado, LongCoT se estanca rápidamente. Un modelo entrenado para veinticuatro mil tokens apenas mejora si se le dan treinta y dos mil o sesenta y cuatro mil. Delethink, en cambio, sigue escalando.
Con ciento veintiocho mil tokens de presupuesto, continuó resolviendo problemas adicionales que no pudo abordar en veinticuatro mil. Algunos problemas de AIME 2025 solo fueron resueltos con trazas de más de ciento cuarenta mil tokens, pese a que el modelo nunca vio ejemplos tan largos durante el entrenamiento.
Este fenómeno de escalado más allá del régimen de entrenamiento es uno de los hallazgos más prometedores. Sugiere que Delethink no simplemente memoriza patrones de razonamiento de longitud específica, sino que aprende una estrategia genuina de progreso incremental que generaliza a horizontes temporales arbitrariamente largos.
Los autores también entrenaron una versión extrema: Delethink con presupuesto de noventa y seis mil tokens, utilizando fragmentos de ocho mil tokens e iteraciones de hasta veintitrés ciclos. Después de solo ciento cincuenta pasos adicionales de entrenamiento (una fracción del entrenamiento principal), este modelo alcanzó un cuarenta y nueve por ciento de precisión en AIME 2024, con trazas promedio de treinta y seis mil tokens. Resolver correctamente la mitad de un examen de este calibre es una hazaña notable para un modelo de solo mil quinientos millones de parámetros.
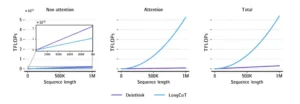
Estas tres gráficas muestran el coste computacional. En operaciones sin atención (izquierda), ambos métodos son similares. En atención (centro), LongCoT crece cuadráticamente mientras Delethink crece linealmente. El total (derecha): a un millón de tokens, Delethink requiere 17 veces menos operaciones.
El coste real: teoría y práctica de la eficiencia computacional
Las ventajas teóricas de Delethink en términos de complejidad computacional se traducen fielmente en ganancias prácticas. Los investigadores midieron meticulosamente el tiempo requerido por paso de entrenamiento y el throughput (tokens procesados por segundo) en un clúster de GPUs H100, el hardware más avanzado disponible actualmente para este tipo de tareas.
Un paso de entrenamiento bajo LongCoT con veinticuatro mil tokens tomaba aproximadamente doscientos cuarenta y ocho segundos. Delethink completaba el mismo trabajo en doscientos quince segundos. La diferencia, alrededor del trece por ciento, puede parecer modesta, pero se amplifica dramáticamente al escalar el razonamiento. Con un presupuesto de noventa y seis mil tokens, los autores estimaron que LongCoT requeriría más de tres mil horas de GPU por paso de entrenamiento, mientras que Delethink seguiría en rangos manejables gracias a su escalado lineal.
El cuello de botella no es solo el cálculo de atención, sino también la gestión de memoria. La caché KV en LongCoT crece linealmente con la longitud de la secuencia, limitando cuántas trazas pueden procesarse en paralelo. Para secuencias de un millón de tokens, la caché de un solo ejemplo llenaría completamente la memoria de una H100, incluso para un modelo pequeño de mil quinientos millones de parámetros.
Escalar más allá requeriría paralelización de secuencias, dividiendo cada traza entre múltiples GPUs, con los costes de comunicación asociados. Delethink evita este problema manteniendo la caché acotada: nunca excede el tamaño de un fragmento, independientemente de cuántos fragmentos se generen.
El throughput de generación exhibió la misma tendencia. Mientras que LongCoT experimentó una caída pronunciada de seis mil a tres mil tokens por segundo al aumentar la longitud de pensamiento de dieciséis mil a noventa y seis mil tokens, Delethink mantuvo un throughput constante de alrededor de ocho mil quinientos tokens por segundo en todo el rango. Esta estabilidad es crucial para el entrenamiento a gran escala, donde miles de trazas deben generarse repetidamente.
Los autores proporcionan un análisis teórico detallado del escalado de FLOPs (operaciones de punto flotante), demostrando que Delethink tiene complejidad O(n²S) donde n es el tamaño del fragmento y S el factor de escalado, frente a O(n²S²) de LongCoT. En otras palabras, duplicar la longitud de razonamiento duplica el coste bajo Delethink pero lo cuadruplica bajo LongCoT. A un millón de tokens, Delethink requiere diecisiete veces menos FLOPs que su contraparte convencional.
La disección el diseño
Como todo trabajo científico riguroso, los autores sometieron Delethink a una batería de ablaciones para entender qué componentes del diseño son esenciales y cuáles pueden ajustarse. Una variable clave es el tamaño del fragmento C. Los experimentos principales usaron ocho mil tokens, pero ¿qué sucede con fragmentos más pequeños?
Con fragmentos de cuatro mil tokens, manteniendo el presupuesto total en veinticuatro mil, el rendimiento se mantuvo sorprendentemente estable. En algunas tareas, como AIME, el modelo de mil quinientos millones con fragmentos de cuatro mil incluso superó la configuración de ocho mil. Esto sugiere que fragmentos más pequeños pueden forzar al modelo a ser más conciso y disciplinado en su razonamiento, evitando divagaciones. Sin embargo, con fragmentos de dos mil tokens, el rendimiento cayó notablemente.
El modelo rara vez emitía señales de finalización dentro del presupuesto, generando trazas larguísimas sin llegar a una conclusión. Esto indica que existe un límite inferior práctico: si el fragmento es demasiado pequeño, el modelo pierde el hilo del razonamiento y entra en un modo de generación continua sin propósito claro.
Otra variable ablacionada fue el tamaño del estado markoviano m. Los experimentos principales usaron m igual a la mitad del fragmento (cuatro mil tokens con fragmentos de ocho mil). Reducir m a mil tokens tuvo poco impacto en los modelos R1-Distill más pequeños, sugiriendo que solo una fracción modesta del contexto es esencial para mantener la coherencia.
Sin embargo, modelos más grandes y con ventanas de contexto nativas más amplias, como Qwen3 (entrenado con doscientos cincuenta y seis mil tokens de contexto), se beneficiaron significativamente de estados markovianos más grandes. Esto sugiere una interacción entre la capacidad del modelo y la cantidad de información que puede comprimir eficazmente en el estado portado.
Finalmente, los autores exploraron si Delethink podía aplicarse a checkpoints ya entrenados bajo LongCoT. Tomaron un modelo entrenado convencionalmente con veinticuatro mil tokens y simplemente aplicaron fragmentación Delethink en tiempo de prueba. El resultado fue un aumento de cuatro puntos porcentuales en precisión al escalar hasta ciento veintiocho mil tokens, sin reentrenamiento alguno. Esto demuestra que incluso modelos no diseñados para Delethink pueden beneficiarse parcialmente de su estructura, aunque el efecto es más pronunciado en modelos entrenados específicamente con este paradigma desde el inicio.
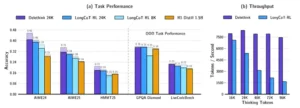
A la izquierda: Delethink iguala o supera a LongCoT en matemáticas (AIME, HMMT) y permanece competitivo en otras tareas (GPQA, LiveCodeBench). A la derecha: mientras LongCoT pierde velocidad drásticamente al escalar (de 7500 a 1500 tokens/segundo), Delethink mantiene throughput constante cerca de 8500 tokens/segundo.
Las pruebas de estrés
Para explorar las fronteras de lo que Delethink puede y no puede hacer, los investigadores diseñaron una prueba de estrés deliberada: resolución de crucigramas. A diferencia de las matemáticas, donde los resultados intermedios se pueden expresar textualmente de forma compacta, un crucigrama requiere mantener una cuadrícula bidimensional en memoria activa. Las palabras ya colocadas restringen las posibilidades para las siguientes, y perder acceso a esa información podría hacer imposible continuar coherentemente.
Los resultados fueron reveladores. En crucigramas de siete por siete casillas, tanto GPT-OSS como Qwen3 mantuvieron un rendimiento comparable bajo Delethink y LongCoT. En crucigramas de catorce por catorce, más complejos, el rendimiento bajo Delethink decayó respecto a LongCoT, pero siguió siendo no trivial. Los modelos encontraron soluciones markovianas válidas en una fracción significativa de los casos, sugiriendo que incluso en tareas aparentemente dependientes de memoria visual, existe margen para comprimir el estado de forma textual (por ejemplo, mediante listas explícitas de palabras colocadas y restricciones pendientes).
Esta prueba delimitó los límites actuales del enfoque. Delethink no es una solución universal; hay tareas donde la información histórica completa es genuinamente necesaria y no puede comprimirse sin pérdida. Sin embargo, el hecho de que incluso en estos casos extremos el modelo logre cierto éxito indica que el espacio de problemas abordables markovianamente es más amplio de lo que podría intuirse.
Implicaciones arquitectónicas
Uno de los comentarios más provocativos del artículo no está en los resultados experimentales, sino en las implicaciones para el diseño futuro de arquitecturas. Si el razonamiento puede hacerse efectivamente markoviano, entonces las arquitecturas con atención no cuadrática (como los modelos de espacio de estados tipo Mamba, atención lineal o atención dispersa) podrían volverse competitivas en dominios de razonamiento, donde tradicionalmente se han considerado inferiores a los transformers completos.
Históricamente, las alternativas a la atención cuadrática han luchado por igualar el rendimiento de los transformers en tareas complejas, en parte porque la atención completa permite dependencias de largo alcance arbitrarias. Sin embargo, si el razonamiento puede estructurarse de modo que cada paso solo dependa de un estado acotado, entonces la capacidad de atender a todo el historial se vuelve menos crítica. Modelos como Mamba, que operan con complejidad lineal mediante mecanismos de actualización de estado recurrente, podrían explotar Delethink para igualar o superar a los transformers en eficiencia sin sacrificar calidad.
Esto abre una vía hacia agentes de IA capaces de pensar durante millones de tokens con recursos razonables. La barrera ya no sería arquitectónica, sino de entrenamiento y alineación: enseñar a estos sistemas a razonar de forma disciplinada y fiable durante horizontes temporales tan extendidos.
Especulaciones y futuras direcciones
Los autores ofrecen varias hipótesis especulativas que merecen consideración. Una es que el preentrenamiento en contextos cortos podría hacer que los modelos «piensen más claramente» en ventanas reducidas, un fenómeno observado empíricamente en estudios de efectividad de contexto largo. Si esto es cierto, Delethink no solo sería más eficiente, sino potencialmente más efectivo al mantener al modelo en su régimen cognitivo óptimo.
Otra especulación intrigante es que el aprendizaje por refuerzo bajo Delethink podría fomentar abstracciones más sofisticadas. Con contexto limitado, el modelo tiene incentivos para desarrollar representaciones compactas de conceptos complejos, escribiendo tokens que encapsulen ideas de alto nivel en lugar de enumerar detalles exhaustivos. Esto podría acelerar el desarrollo de capacidades de razonamiento abstracto, aunque validar esta hipótesis requeriría estudios a escalas mucho mayores.
Finalmente, los autores sugieren que Delethink podría combinarse con otras técnicas de eficiencia, como cuantización de caché KV, atención dispersa o destilación de trazas. Cada una de estas aborda diferentes aspectos del problema computacional, y su combinación sinérgica podría desbloquear ganancias adicionales.

El panel izquierdo muestra que tanto Delethink como LongCoT mantienen entropía estable durante el entrenamiento, indicando que no colapsan. El panel derecho revela que Delethink genera más soluciones correctas en rangos largos de razonamiento (17K-23K tokens), aprovechando eficazmente su presupuesto extendido.
Contexto en el ecosistema de investigación
Delethink se inscribe en un corpus creciente de investigación sobre escalado eficiente del razonamiento. Trabajos previos han explorado la poda de pasos innecesarios, la salida anticipada de generación, la regularización de longitud o la limitación de la frecuencia con que se usan trazas largas durante el entrenamiento. Todos estos enfoques operan dentro del paradigma LongCoT y, por tanto, heredan su escalado cuadrático.
Otra línea de investigación reciente, ejemplificada por InftyThink, propone resumir iterativamente el razonamiento para mantener el contexto acotado. Sin embargo, estos sistemas suelen depender de estrategias de resumen fijas, definidas manualmente o destiladas de ejemplos curados. Delethink difiere fundamentalmente al no imponer estructura predefinida: el modelo aprende por sí mismo qué y cómo resumir, mediante el gradiente de refuerzo.
En cuanto a arquitecturas alternativas, trabajos sobre atención lineal, sliding window attention o modelos híbridos transformer-Mamba han explorado reducir la complejidad cuadrática mediante aproximaciones o restricciones. Delethink es ortogonal a estos esfuerzos: puede aplicarse independientemente de la arquitectura subyacente, y de hecho podría potenciar esas arquitecturas al hacer viable su uso en regímenes de razonamiento ultraextendido.
Una mirada más profunda al mecanismo
Para comprender cabalmente la elegancia de Delethink, conviene examinar con mayor detalle cómo se ejecuta cada transición entre fragmentos. El momento crítico ocurre al alcanzar el límite de tokens en un bloque de razonamiento. En ese instante, el sistema no simplemente corta y continúa: realiza una operación que podría describirse como una «destilación en tiempo real» del conocimiento acumulado.
El modelo, hacia el final del fragmento, típicamente ha explorado diversas vías de solución, descartado callejones sin salida, verificado hipótesis y consolidado conclusiones parciales. De todo ese material, debe seleccionar qué preservar en los últimos cuatro mil tokens, sabiendo que será lo único visible en el siguiente ciclo. Esta selección no es aleatoria ni programada externamente: emerge del entrenamiento. El gradiente de refuerzo penaliza configuraciones donde el estado markoviano es insuficiente (porque llevan a errores en fragmentos posteriores) y recompensa aquellas donde la información esencial está codificada de forma que permite continuación fluida.
Lo fascinante es que diferentes problemas inducen diferentes estrategias de compresión. En demostraciones matemáticas, el modelo aprende a escribir lemas intermedios numerados y referencias explícitas a resultados previos. En problemas de programación, mantiene un inventario de funciones definidas y restricciones activas. En cuestiones de razonamiento multipasos, serializa el estado del problema en formato estructurado. No existe un esquema único de compresión: el modelo desarrolla un repertorio adaptativo según las demandas de cada tarea.
Esta adaptabilidad contrasta marcadamente con enfoques basados en resumen algorítmico, donde un mecanismo fijo (como seleccionar oraciones con alta perplejidad o usar un modelo auxiliar para condensar texto) se aplica uniformemente. Delethink permite que la estrategia de compresión coevolucione con la estrategia de resolución, optimizándose conjuntamente hacia la maximización de recompensa.
Estas curvas muestran cómo diferentes tamaños de fragmento (C=8K, 4K, 2K) afectan el entrenamiento. La configuración de 8K y 4K logran resultados similares y superiores tanto en recompensa de entrenamiento como en precisión real (AIME24), mientras que fragmentos muy pequeños (2K) rinden menos pero aún mejoran respecto al modelo base.
¿Por qué funciona desde el principio?
Uno de los aspectos más desconcertantes del trabajo es la efectividad de Delethink incluso sin entrenamiento específico. Modelos que nunca habían visto fragmentación con reinicio, cuando se les aplica este esquema, no colapsan ni generan incoherencias: simplemente ajustan su estilo y recuperan la mayor parte de su capacidad original.
Los autores ofrecen dos explicaciones plausibles, pero ninguna completamente satisfactoria. La primera apela a la estadística del preentrenamiento: si los modelos fueron expuestos principalmente a documentos de ocho a treinta y dos mil tokens, podrían haber desarrollado sesgos inductivos que favorecen el razonamiento en esas escalas. Sin embargo, esto no explica por qué el razonamiento no se desmorona al perder acceso a tokens anteriores dentro del mismo documento.
La segunda explicación es más profunda y especulativa. El texto humano, particularmente el técnico y científico, exhibe estructura markoviana implícita. Los autores humanos no esperan que el lector retenga cada detalle de páginas anteriores; por eso reiteramos conceptos clave, numeramos resultados importantes y construimos argumentos con dependencias locales manejables. Los modelos, entrenados en este corpus, podrían haber internalizado no solo el contenido sino también la estructura narrativa markoviana del razonamiento humano experto.
Si esto es correcto, tendría una implicación profunda: los transformers, pese a su capacidad de atención global, podrían estar operando internamente de manera más modular de lo que asumimos. Las representaciones intermedias quizás ya codifican información de forma comprimida y contextualizada, de modo que cada capa puede funcionar relativamente independiente de las activaciones distantes. Delethink simplemente haría explícita en el nivel de tokens una propiedad que ya existe en el nivel de representaciones latentes.
Esta hipótesis podría probarse mediante experimentos de ablación más profundos, examinando cómo fluye la información a través de las capas del transformer durante el razonamiento fragmentado versus continuo. Si las activaciones muestran patrones similares de dependencia local en ambos casos, apoyaría la idea de que el comportamiento markoviano es genuinamente emergente y no un artefacto del procedimiento de fragmentación.

Estos diagramas muestran la «cobertura de problemas» de Delethink versus LongCoT en modelos de vanguardia muy grandes. Los números indican cuántos problemas resuelve cada método exclusivamente y cuántos ambos resuelven. Lo notable: en AIME24 y AIME25, la superposición es casi total (28 problemas comunes), demostrando que Delethink no pierde capacidad de resolver ciertos tipos de problemas. En GPQA Diamond, cada método resuelve algunos problemas únicos, pero el total es equivalente. En crucigramas (derecha), se observa la única área donde Delethink muestra limitaciones en tareas que requieren memoria espacial explícita.
Delethink en acción: un caso de estudio detallado
Para ilustrar concretamente cómo opera Delethink, los autores proporcionan trazas ejemplares donde es posible observar la transición entre fragmentos. En un problema del examen AIME que requiere calcular propiedades geométricas de un triángulo inscrito en un círculo, el primer fragmento dedica aproximadamente seis mil tokens a establecer el sistema de coordenadas, derivar ecuaciones de las tangentes relevantes y plantear el sistema algebraico resultante.
Hacia el final del fragmento, el modelo converge a una expresión específica para la longitud buscada, pero no completa la simplificación aritmética final. Los últimos tokens del fragmento contienen: la fórmula parcialmente simplificada, una nota explícita indicando que resta reducir la fracción, y los valores numéricos clave obtenidos hasta ese punto. Esto constituye el estado markoviano.
En el segundo fragmento, el contexto se reinicia. El prompt ahora contiene únicamente la pregunta original más esos últimos cuatro mil tokens. El modelo retoma sin titubeos, simplificando la fracción mediante factorización, verificando que los términos son coprimos, y concluyendo con la respuesta correcta. No hay redundancia ni reexploración: el razonamiento continúa orgánicamente como si no hubiera habido interrupción.
Contrasta esto con un intento de forzar presupuesto mediante continuación simple, donde tras alcanzar una respuesta correcta el sistema añade un prompt genérico como «espera, déjame revisar». En esos casos, el modelo tiende a reabrir cuestiones ya resueltas, explorar alternativas innecesarias o incluso contradecirse, degradando la precisión. La diferencia radica en que Delethink estructura la transición: el reinicio del contexto señala inequívocamente al modelo que debe construir sobre el estado portado, no reconsiderar desde cero.
El experimento de noventa y seis mil tokens
El experimento quizás más audaz del artículo fue entrenar una versión de Delethink con presupuesto de noventa y seis mil tokens, utilizando hasta veintitrés iteraciones de fragmentos de ocho mil tokens. Este régimen multiplica por cuatro el presupuesto estándar y se adentra en territorios donde LongCoT sería prácticamente inviable con los recursos disponibles.
Los resultados fueron alentadores. Tras solo ciento cincuenta pasos adicionales de entrenamiento sobre un conjunto de datos de problemas matemáticos particularmente difíciles, el modelo alcanzó cuarenta y nueve por ciento de precisión en AIME 2024, con trazas promedio de treinta y seis mil tokens. Algunos problemas individuales requirieron la capacidad completa de noventa y seis mil tokens para ser resueltos.
Más revelador aún, cuando se permitió al modelo escalar en tiempo de prueba hasta doscientos cincuenta y seis mil tokens, continuó mostrando mejoras incrementales. La curva de precisión versus presupuesto no exhibió saturación, sugiriendo que con suficiente capacidad de razonamiento, estos problemas extremadamente difíciles admiten soluciones sistemáticas que simplemente requieren exploración exhaustiva del espacio de estrategias.
Este comportamiento contrasta dramáticamente con LongCoT, donde modelos entrenados con veinticuatro mil tokens apenas mejoran al recibir treinta y dos mil en tiempo de prueba, y se estancan completamente más allá. La diferencia sugiere que Delethink no está simplemente aprendiendo patrones de longitud específica, sino desarrollando una competencia meta-cognitiva: la capacidad de gestionar y extender el razonamiento de forma arbitraria, fragmento tras fragmento.
La cuestión de la cobertura de problemas
Un análisis particularmente interesante en el estudio examina qué problemas específicos resuelve Delethink versus LongCoT. Si el enfoque markoviano simplemente descartara ciertos tipos de razonamiento inviables sin historia completa, esperaríamos que ambos métodos resolvieran conjuntos disjuntos de problemas. Sin embargo, no es lo que ocurre.
En AIME 2024, Delethink y LongCoT con idéntico presupuesto de veinticuatro mil tokens resuelven prácticamente los mismos problemas. El solapamiento supera el noventa por ciento. Hay problemas que solo uno de los dos resuelve, pero son excepciones balanceadas: algunos favorecen a Delethink, otros a LongCoT. Esto indica que ambos enfoques acceden al mismo espacio de soluciones, simplemente mediante caminos ligeramente diferentes.
En tareas fuera de distribución como GPQA Diamond (preguntas de nivel doctorado en ciencias), el patrón se mantiene. Ambos métodos resuelven alrededor de ciento sesenta problemas de un total de doscientos, con solapamiento casi total. Esto refuta la preocupación de que Delethink pudiera ser específico a ciertos tipos de razonamiento o fallar sistemáticamente en problemas con estructura particular.
La única área donde se observa divergencia significativa es en los crucigramas de catorce por catorce, donde LongCoT supera a Delethink por un margen notable. Pero incluso allí, Delethink logra resolver más del sesenta por ciento de lo que LongCoT resuelve, demostrando que incluso tareas aparentemente dependientes de memoria espacial admiten estrategias markovianas parciales.

Estas gráficas muestran cómo modelos de 120 mil millones de parámetros (GPT-OSS, fila superior) y 30 mil millones (Qwen3, fila inferior) responden al escalado de tokens sin entrenamiento específico. Delethink con fragmentos de 16K (violeta oscuro) prácticamente iguala o supera a LongCoT (naranja) en todas las tareas, mientras que Delethink con 8K (violeta claro) mantiene rendimiento competitivo. Esto demuestra que el comportamiento markoviano emerge naturalmente incluso en modelos gigantes no entrenados para ello.
Democratizando el razonamiento avanzado
Más allá de los aspectos técnicos, Delethink tiene implicaciones significativas para la accesibilidad de capacidades de razonamiento avanzado. El paradigma LongCoT, con su escalado cuadrático, concentra inevitablemente las capacidades en organizaciones con acceso a infraestructura computacional masiva. Entrenar un modelo para pensar durante cien mil tokens bajo LongCoT requiere presupuestos que excluyen a universidades, empresas medianas y países con recursos limitados.
Delethink, al reducir radicalmente los requisitos computacionales, podría nivelar parcialmente el campo de juego. Un modelo de razonamiento ultraextendido entrenado con Delethink podría ejecutarse en infraestructuras más modestas, abriendo posibilidades para investigación académica independiente, aplicaciones educativas y desarrollo tecnológico en regiones del sur global.
Adicionalmente, la eficiencia de Delethink tiene implicaciones ambientales directas. El entrenamiento de modelos de lenguaje a gran escala ya genera preocupaciones por su huella de carbono. Multiplicar por cuatro los requisitos computacionales para soportar razonamiento extendido agravaría sustancialmente este problema. Delethink, al mantener los costes lineales, permite avanzar en capacidades sin escalar proporcionalmente el impacto ecológico.
Sin embargo, estas ventajas potenciales deben balancearse contra riesgos. Modelos capaces de razonamiento ultraextendido podrían habilitar aplicaciones de doble uso: desde asistentes científicos benéficos hasta sistemas de persuasión sofisticados o herramientas para eludir salvaguardas de seguridad mediante cadenas de razonamiento complejas. La accesibilidad ampliada que Delethink promete amplificaría tanto los usos beneficiosos como los potencialmente dañinos.
Limitaciones reconocidas y caminos hacia su superación
Los autores son transparentes respecto a las limitaciones actuales de su trabajo. Primero, Delethink ha sido validado exhaustivamente solo en dominios matemáticos y de programación, donde los resultados son verificables automáticamente mediante ejecución de código o comprobación simbólica. Su efectividad en razonamiento en lenguaje natural abierto, donde la calidad es más subjetiva, permanece inexplorada.
Segundo, los experimentos se concentran en modelos relativamente pequeños, hasta catorce mil millones de parámetros en los entrenamientos completos, aunque las validaciones de inicialización incluyen modelos de ciento veinte mil millones. No está garantizado que los patrones observados persistan al escalar a modelos de cientos de miles de millones o billones de parámetros, donde pueden emerger comportamientos cualitativamente nuevos.
Tercero, el tamaño óptimo del fragmento y del estado markoviano parece depender de factores como el tamaño del modelo, su contexto nativo de preentrenamiento y la naturaleza de las tareas. Los autores proporcionan heurísticas (fragmentos de ocho mil tokens, estado de cuatro mil), pero reconocen que configuraciones óptimas requerirían búsqueda específica por tarea.
Cuarto, aunque Delethink evita el escalado cuadrático de atención, introduce un costo adicional: la recodificación del estado markoviano al inicio de cada fragmento. Con fragmentos de ocho mil tokens y estado de cuatro mil, esto significa recodificar cuatro mil tokens cada vez, lo cual añade complejidad cuadrática localizada. Para fragmentos muy pequeños o estados muy grandes, este costo podría volverse significativo. Los autores demuestran que en sus configuraciones experimentales este efecto es despreciable, pero sería relevante en regímenes extremos.
Finalmente, Delethink requiere infraestructura de entrenamiento por refuerzo robusta, con generación de trazas a gran escala y estimación de ventajas. Esto es más complejo que el simple ajuste supervisado y puede presentar desafíos de estabilidad numérica, particularmente al escalar a modelos y presupuestos muy grandes.
Cada una de estas limitaciones sugiere direcciones de investigación futura. Validar Delethink en razonamiento en lenguaje natural abierto requeriría desarrollo de métricas de evaluación confiables, quizás basadas en juicio humano o modelos evaluadores avanzados. Escalar a modelos gigantescos demandaría optimizaciones adicionales de infraestructura, posiblemente incluyendo fragmentación adaptativa donde el tamaño del fragmento varía según la complejidad del problema. Y optimizar la configuración por tarea podría abordarse mediante metaaprendizaje, donde un sistema supervisor ajusta dinámicamente los hiperparámetros de Delethink según características del problema.

Aquí se compara el rendimiento de Delethink con fragmentos de 8K versus 4K tokens en modelos R1-Distill de diferentes tamaños (1.5B, 7B, 14B parámetros). Lo sorprendente: fragmentos más pequeños (4K) a veces funcionan igual o mejor que fragmentos grandes (8K), especialmente en el modelo pequeño de 1.5B en AIME24. Esto sugiere que fragmentos compactos pueden forzar al modelo a ser más disciplinado y conciso, aunque el patrón varía según el tamaño del modelo y la tarea.
Conexiones con aprendizaje por refuerzo clásico y teoría de control
Desde una perspectiva de aprendizaje automático fundamental, Delethink se inscribe en una tradición profunda de diseño de espacios de estado en problemas de decisión secuencial. En aprendizaje por refuerzo clásico, definir el estado correctamente es frecuentemente más importante que elegir el algoritmo de optimización. Un estado que incluye información irrelevante dificulta el aprendizaje por dilución de señal; uno que omite información crucial viola el supuesto de Markov y hace imposible la política óptima.
Tradicionalmente, en LongCoT el estado se define trivialmente como todo el historial. Esto satisface trivialmente la propiedad de Markov (toda la información está presente), pero crea un espacio de estados exponencialmente grande e inhomogéneo. Delethink redefine el estado de forma radicalmente más compacta, apostando a que el aprendizaje descubrirá una representación suficiente.
Esta estrategia tiene paralelos en teoría de control óptimo, donde técnicas como el filtro de Kalman mantienen una estimación del estado suficiente que resume toda la información relevante del pasado en forma compacta. La diferencia es que en Delethink el «filtro» no está diseñado analíticamente, sino aprendido mediante gradiente de política.
También hay resonancias con arquitecturas recurrentes, donde el estado oculto debe capturar información suficiente del pasado para procesar entradas futuras. La diferencia crucial es que en recurrentes el estado es una representación latente vectorial, mientras que en Delethink es textual y legible. Esto tiene ventajas de interpretabilidad: podemos inspeccionar qué información elige portar el modelo. Pero también limitaciones: el modelo debe gastar tokens explícitos en codificar el estado, mientras que arquitecturas recurrentes lo hacen implícitamente sin coste de generación.
Estas cuatro gráficas documentan el experimento más ambicioso: entrenar Delethink para pensar hasta 96 mil tokens. Los paneles muestran precisión (izquierda) y longitud promedio de las trazas (derecha) para AIME24 y AIME25. Las líneas discontinuas representan extensiones del presupuesto en tiempo de prueba (hasta 256K para el modelo 96K, hasta 128K para el modelo 24K). Lo revelador: incluso con entrenamiento breve (150 pasos), el modelo 96K supera las versiones de presupuesto menor, con trazas que alcanzan promedios de 30-42K tokens reales.
Hacia una teoría unificada del razonamiento fragmentado
El éxito de Delethink plantea preguntas teóricas profundas sobre la naturaleza del razonamiento en inteligencia artificial. ¿Qué tipos de problemas admiten soluciones genuinamente markovianas? ¿Existe una caracterización formal de cuándo la fragmentación preserva resolubilidad?
Una posible formalización partiría de la teoría de complejidad computacional. Podemos clasificar problemas según la memoria mínima requerida por una máquina de Turing para resolverlos. Problemas en LOGSPACE (espacio logarítmico) claramente admiten soluciones markovianas compactas. Problemas PSPACE-completos requieren memoria polinomial y podrían desafiar enfoques de estado acotado. La pregunta empírica es: ¿dónde se sitúan los problemas de razonamiento práctico en este espectro?
Los experimentos sugieren que muchos problemas matemáticos avanzados, pese a su dificultad intrínseca, admiten descomposiciones markovianas. Esto podría deberse a que las matemáticas humanas han coevolucionado con nuestras limitaciones cognitivas: desarrollamos formalismos y estrategias de demostración que funcionan dentro de memoria de trabajo acotada. Los modelos, entrenados en este corpus, heredan esas estructuras.
Si esta hipótesis es correcta, habría problemas genuinamente no markovianos que resistirían Delethink: aquellos cuya resolución requiere mantener información cuya compresión es algorítmicamente intratable. Identificar empíricamente tales problemas sería valioso para delimitar la frontera de aplicabilidad del enfoque.
El futuro del razonamiento artificial
Mirando hacia adelante, Delethink podría catalizar varias líneas de desarrollo. A corto plazo, esperaríamos ver su adopción en sistemas de razonamiento de próxima generación, particularmente conforme los desarrolladores busquen escalar más allá de contextos de cientos de miles de tokens sin costes prohibitivos.
A mediano plazo, podría impulsar el desarrollo de arquitecturas híbridas que combinen lo mejor de múltiples paradigmas: transformers para procesamiento local denso dentro de fragmentos, mecanismos de estado recurrente para portar información entre fragmentos, y atención dispersa para referencias ocasionales a información distante. Tales arquitecturas podrían ofrecer el rendimiento de transformers completos con la eficiencia de modelos lineales.
A largo plazo, Delethink podría ser visto retrospectivamente como un paso inicial hacia agentes de IA con capacidades de razonamiento verdaderamente extensas, capaces de abordar problemas que requieren semanas o meses de reflexión humana equivalente. Imaginemos asistentes de investigación que exploran exhaustivamente espacios de hipótesis científicas, sistemas de diseño que optimizan arquitecturas considerando miles de restricciones interdependientes, o planificadores estratégicos que simulan escenarios con horizontes de décadas.
La democratización del razonamiento profundo también podría transformar la educación. Tutores de IA capaces de razonamiento ultraextendido podrían proporcionar explicaciones personalizadas de complejidad arbitraria, adaptándose al nivel del estudiante y explorando conexiones conceptuales con profundidad previamente inalcanzable.
Naturalmente, estos desarrollos plantearán desafíos de gobernanza. Sistemas capaces de razonamiento tan extendido podrían eludir métodos de supervisión diseñados para modelos convencionales. Monitorear y alinear el comportamiento de un agente que piensa durante millones de tokens representaría un problema técnico sustancial. Será necesario desarrollar paralelamente técnicas de interpretabilidad que permitan auditar cadenas de razonamiento ultralargas y detectar comportamientos problemáticos antes de que escalen.
Estas tres gráficas muestran cómo mejora la precisión al aumentar el presupuesto de tokens durante la inferencia, pero dentro de los límites de entrenamiento (sin la zona sombreada de otras figuras). En AIME25 y AIME24, todas las versiones mejoran progresivamente hasta sus límites entrenados. En HMMT25 (derecha), la zona sombreada marca el territorio más allá del entrenamiento: Delethink 24K continúa escalando hasta 128K tokens, mientras que las versiones LongCoT se estancan en sus respectivos límites (24K y 8K), ilustrando la diferencia fundamental entre paradigmas.
Lecciones metodológicas para la investigación en IA
Más allá de sus contribuciones técnicas específicas, Delethink ofrece lecciones metodológicas valiosas para la investigación en inteligencia artificial. Primera, la importancia de cuestionar supuestos implícitos. Durante años, la comunidad asumió que el entorno de generación de lenguaje (estado como historial completo, acción como siguiente token) era la única formulación natural. Delethink demuestra que entornos alternativos pueden desbloquear ventajas fundamentales.
Segunda, el valor de las ablaciones sistemáticas y pruebas de estrés deliberadas. Los autores no se contentaron con demostrar que Delethink funciona en su caso de uso objetivo; exploraron activamente sus límites mediante tareas adversarias como crucigramas. Este tipo de validación rigurosa construye confianza y delimita claramente el dominio de aplicabilidad.
Tercera, la interacción entre teoría y experimento. El análisis de complejidad computacional predijo escalado lineal, que luego fue confirmado empíricamente mediante mediciones meticulosas. Esta concordancia fortalece ambas perspectivas y sugiere que los fundamentos teóricos son sólidos.
Cuarta, la importancia de la reproductibilidad y apertura. Los autores han liberado código, pesos de modelos y detalles experimentales exhaustivos. Esto permite a la comunidad validar, extender y construir sobre el trabajo, acelerando el progreso colectivo.
Una redefinición de los límites de lo posible
Delethink nos invita a reconsiderar qué significa para una máquina «pensar». Tradicionalmente hemos asumido que el pensamiento requiere acceso continuo a un registro completo de reflexiones previas. Delethink demuestra que esto es una convención, no una necesidad. Un sistema puede razonar eficazmente manteniendo solo un resumen compacto de su progreso, siempre que ese resumen capture la esencia de lo esencial.
Esta revelación tiene implicaciones filosóficas sutiles. Sugiere que el razonamiento no es fundamentalmente un proceso de acumulación exhaustiva de información, sino de destilación iterativa de conocimiento relevante. Cada ciclo de pensamiento refina y comprime, extrayendo lo significativo y descartando lo superfluo. El producto final no es la suma de todos los pasos intermedios, sino su síntesis organizada.
En términos prácticos, Delethink ha abierto una ventana hacia futuros donde la profundidad del razonamiento artificial no está limitada por consideraciones de hardware. Un modelo ejecutándose en un solo servidor podría, en principio, pensar durante millones de tokens, explorando con paciencia sobrehumana laberintos de posibilidades lógicas hasta encontrar soluciones que eludirían incluso a los mejores expertos humanos.
Pero quizás la lección más profunda sea humildad epistemológica. Delethink funciona, pero no comprendemos completamente por qué los modelos actuales ya exhiben comportamiento markoviano latente. Esta brecha entre resultado empírico y entendimiento teórico es característica de mucha investigación contemporánea en IA. Nos recuerda que, pese a nuestros avances, apenas estamos comenzando a comprender las propiedades emergentes de estos sistemas complejos.
El camino hacia la inteligencia artificial general, si tal cosa es alcanzable, probablemente estará pavimentado no solo con redes más grandes o datos más abundantes, sino con insights conceptuales que reformulen problemas aparentemente intratabables en términos manejables. Delethink es uno de esos insights: una idea simple en retrospectiva, pero que requirió valentía intelectual para articular y rigor experimental para validar.
En los próximos años veremos si este enfoque se consolida como un componente estándar del arsenal de razonamiento artificial, o si revela limitaciones que requieren reformulaciones adicionales. Pero independientemente del destino específico de Delethink, su mensaje perdura: el entorno en que aprenden nuestros modelos no es inmutable, y rediseñarlo creativamente puede desbloquear capacidades que los algoritmos solos no podrían alcanzar. En la danza entre arquitectura, algoritmo y entorno, este último ha sido durante demasiado tiempo el compañero silencioso. Delethink le devuelve el protagonismo que merece.
Referencias
Aghajohari, M., Chitsaz, K., Kazemnejad, A., Chandar, S., Sordoni, A., Courville, A., & Reddy, S. (2025). The Markovian Thinker. arXiv preprint arXiv:2510.06557.
Agarwal, S., Ahmad, L., Ai, J., Altman, S., et al. (2025). GPT-OSS-120B & GPT-OSS-20B Model Card. arXiv preprint arXiv:2508.10925.
Guo, D., Yang, D., Zhang, H., Song, J., et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.
Luo, M., Tan, S., Wong, J., Shi, X., et al. (2025). DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL. Notion Blog.
Sheng, G., Zhang, C., Ye, Z., Wu, X., et al. (2024). HybridFlow: A Flexible and Efficient RLHF Framework. arXiv preprint arXiv:2409.19256.
Yang, A., Li, A., Yang, B., Zhang, B., et al. (2025). Qwen3 Technical Report. arXiv preprint arXiv:2505.09388.
Zheng, L., Yin, L., Xie, Z., Sun, C., et al. (2024). SGLang: Efficient Execution of Structured Language Model Programs. Advances in Neural Information Processing Systems 38 (NeurIPS 2024).

