
¿Cuándo podemos confiar en los modelos de lenguaje para la salud mental?
La inteligencia artificial ha comenzado a ocupar un lugar inesperado en nuestras vidas: el diván del terapeuta. Miles de personas recurren diariamente a ChatGPT, Claude y otros modelos de lenguaje masivo buscando apoyo emocional, consejo psicológico y acompañamiento en momentos de crisis. Esta tendencia, que surgió de manera orgánica durante la pandemia, plantea una pregunta fundamental que la comunidad científica apenas comienza a abordar de manera rigurosa: ¿cuándo podemos realmente confiar en estas herramientas para cuestiones tan delicadas como la salud mental?
La respuesta llega ahora a través de una investigación revolucionaria que ha establecido, por primera vez, un marco científico robusto para evaluar la confiabilidad de los sistemas de inteligencia artificial en el ámbito terapéutico. El estudio, liderado por un consorcio internacional de investigadores de York University, Vector Institute, Dalhousie University, IWK Health Hospital y King's College London, introduce dos conjuntos de datos masivos y una metodología estadística innovadora que promete transformar nuestra comprensión sobre las capacidades y limitaciones de la IA en salud mental.
El contexto que da urgencia a esta investigación es incontrovertible. Según la Organización Mundial de la Salud, existe apenas un profesional de salud mental por cada 7,692 personas en el mundo. Esta escasez crítica de recursos humanos especializados coincide con una epidemia global de trastornos mentales que se ha intensificado dramáticamente. En España, la situación es particularmente preocupante, con solo cinco psicólogos clínicos por cada 100,000 habitantes, una cifra que queda muy por debajo de los 20 profesionales recomendados por los expertos.
En este vacío asistencial, los modelos de lenguaje han emergido como una alternativa accesible e inmediata. Los usuarios encuentran en sistemas como ChatGPT una disponibilidad constante, un aparente anonimato protector y respuestas que parecen empáticas y comprensivas. Sin embargo, hasta ahora, la evaluación de estas herramientas se había basado en métricas superficiales o estudios de pequeña escala que no capturaban la complejidad inherente del diálogo terapéutico.
La dimensión cognitiva del apoyo psicológico abarca elementos como la capacidad de ofrecer orientación práctica, información relevante y sugerencias seguras. Por otra parte, la dimensión afectiva incluye la empatía, la comprensión emocional y la capacidad de proporcionar consuelo genuino. Esta dualidad fundamental en la terapia requería un enfoque de evaluación igualmente sofisticado.
Los investigadores desarrollaron lo que denominan el Marco de Acuerdo Afectivo-Cognitivo, una metodología estadística basada en coeficientes de correlación intraclase que permite medir no solo qué tan bien funcionan los sistemas de IA, sino también cuándo se puede confiar en su evaluación automática. Esta innovación representa un salto cualitativo respecto a los métodos tradicionales, que se limitaban a comparar similitudes superficiales entre respuestas sin considerar la calidad terapéutica real.
El laboratorio más grande del mundo para la IA terapéutica
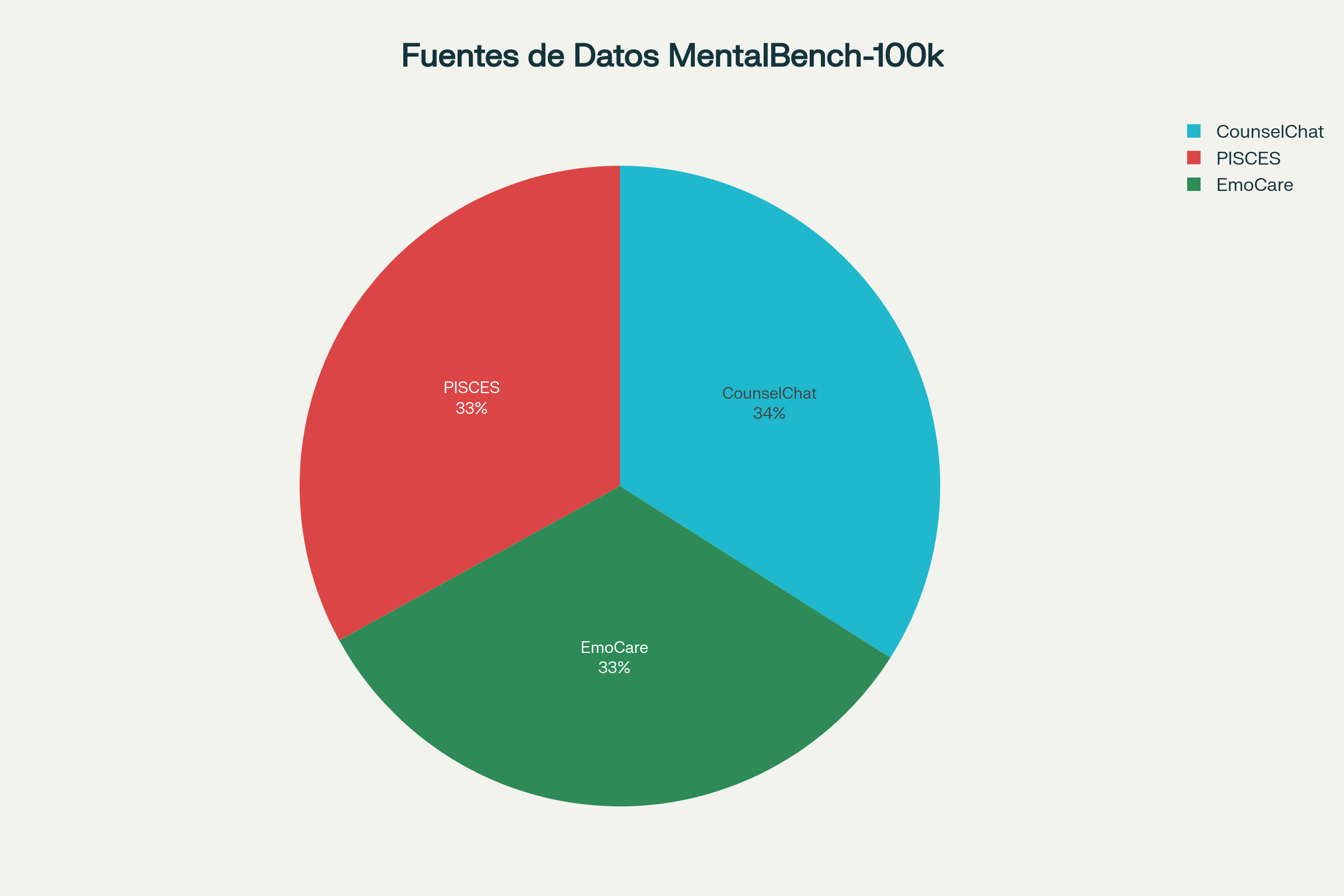
Para abordar la escasez histórica de datos auténticos en salud mental, el equipo creó MentalBench-100k, el primer conjunto de datos masivo que consolida conversaciones reales de apoyo psicológico. Este recurso sin precedentes reúne 10,000 diálogos auténticos extraídos de tres fuentes diferentes: transcripciones clínicas del ensayo PISCES, sesiones de consejería humana del dataset EmoCare, y consultas reales entre usuarios y terapeutas licenciados de la plataforma CounselChat.
La construcción de este benchmark enfrentó desafíos únicos. Los datos de salud mental son intrínsecamente sensibles, y la mayoría de los conjuntos de datos existentes se basan en contenido sintético o publicaciones de redes sociales que carecen de la profundidad y autenticidad de las interacciones terapéuticas reales. Como reconocen los investigadores, solo el 5% de los estudios previos incorporan datos de entornos de atención real, mientras que la mayoría depende de contenido artificial o de medios sociales.
Cada conversación en MentalBench-100k fue categorizada según 23 condiciones de salud mental predefinidas, abarcando desde ansiedad y depresión hasta problemas más específicos como autolesiones y explotación. Esta diversidad garantiza que el benchmark capture la complejidad real de los desafíos que enfrentan los usuarios cuando buscan apoyo psicológico. El proceso de categorización consideró la nuance de cada interacción, asegurando que se capturaran tanto los aspectos clínicos como contextuales que definen los distintos tipos de crisis psicológica.
Pero el verdadero salto innovador llegó con la generación sistemática de respuestas. Nueve modelos de lenguaje diferentes, desde el poderoso GPT-4o hasta modelos open-source como LLaMA-3.1-8B y Qwen-2.5-7B, fueron instruidos para responder como psiquiatras licenciados a cada una de las 10,000 consultas. El resultado: 100,000 respuestas que permiten una comparación sin precedentes entre diferentes arquitecturas de IA y su capacidad para proporcionar apoyo mental.
Esta diversidad de modelos era crucial para evitar sesgos asociados a un solo sistema. Los investigadores incluyeron tanto modelos propietarios de alta capacidad como alternativas de código abierto más accesibles, reconociendo que las aplicaciones reales de IA terapéutica probablemente utilizarán una gama amplia de tecnologías dependiendo de factores como costo, privacidad y disponibilidad. Algunos sistemas operan en servidores de empresas multinacionales, mientras que otros pueden ejecutarse localmente en dispositivos personales, lo cual tiene profundas implicaciones para la privacidad y la retención de datos sensibles.
Cuando las máquinas evalúan a las máquinas
El siguiente desafío era igualmente complejo: ¿cómo evaluar objetivamente la calidad de estas respuestas? Las métricas tradicionales del procesamiento de lenguaje natural, como BLEU o ROUGE, resultan inadecuadas para capturar elementos sutiles pero cruciales como la empatía genuina, la seguridad clínica o la relevancia terapéutica. Estas medidas fueron diseñadas originalmente para comparar similitudes léxicas entre textos, sin considerar la dimensión humana ni los matices contextuales que caracterizan la interacción terapéutica.
Aquí surge MentalAlign-70k, el segundo componente revolucionario de la investigación. Este benchmark compara sistemáticamente las evaluaciones realizadas por cuatro modelos de lenguaje de última generación (GPT-4o, Claude-3.7-Sonnet, Gemini-2.5-Flash y GPT-4o-Mini) con las valoraciones de expertos humanos con formación psiquiátrica formal. La selección de estos evaluadores fue cuidadosa, incluyendo solo a profesionales con certificaciones reconocidas internacionalmente en psicología clínica y terapia.
Los evaluadores, tanto artificiales como humanos, calificaron cada respuesta según siete atributos críticos organizados en dos ejes fundamentales. El Puntaje de Apoyo Cognitivo incluye orientación (capacidad de ofrecer estructura y pasos siguientes), informatividad (utilidad y relevancia de las sugerencias), relevancia (pertinencia contextual) y seguridad (adherencia a directrices de salud mental). El Puntaje de Resonancia Afectiva abarca empatía (calidez emocional y validación), utilidad (capacidad de reducir angustia) y comprensión (precisión en reflejar la experiencia emocional del usuario).
Esta estructura dual reconoce que el apoyo psicológico efectivo requiere tanto competencia técnica como conexión emocional. Un sistema puede ofrecer consejos técnicamente correctos pero carecer de la calidez humana necesaria para el bienestar emocional, o viceversa. La investigación desentraña esta compleja interacción, mostrando que no existe un único tipo de respuesta correcta, sino múltiples dimensiones que deben equilibrarse cuidadosamente.
El proceso de evaluación fue meticulosamente diseñado para eliminar sesgos. Todas las respuestas fueron anonimizadas completamente, y los evaluadores humanos permanecieron ciegos respecto al origen de cada respuesta. Para evitar sesgos de autopreferencia, cada modelo evaluador fue excluido de juzgar sus propias respuestas. El resultado: 70,000 evaluaciones que proporcionan la base empírica más robusta hasta la fecha sobre la confiabilidad de la IA en salud mental. Además, se implementaron controles de calidad continuos, eliminando evaluaciones de personas que demostraban patrones inconsistentes o potenciales conflictos de interés.
Revelaciones que transforman el panorama
Los hallazgos de la investigación revelan patrones complejos y matizados que desafían tanto el optimismo ingenuo como el pesimismo categórico sobre la IA terapéutica. Los resultados exponen una realidad más sofisticada: la confiabilidad de estos sistemas varía dramáticamente según el tipo de apoyo requerido. No existe una respuesta binaria de sí o no, sino un espectro de confiabilidad que depende de la tarea específica.
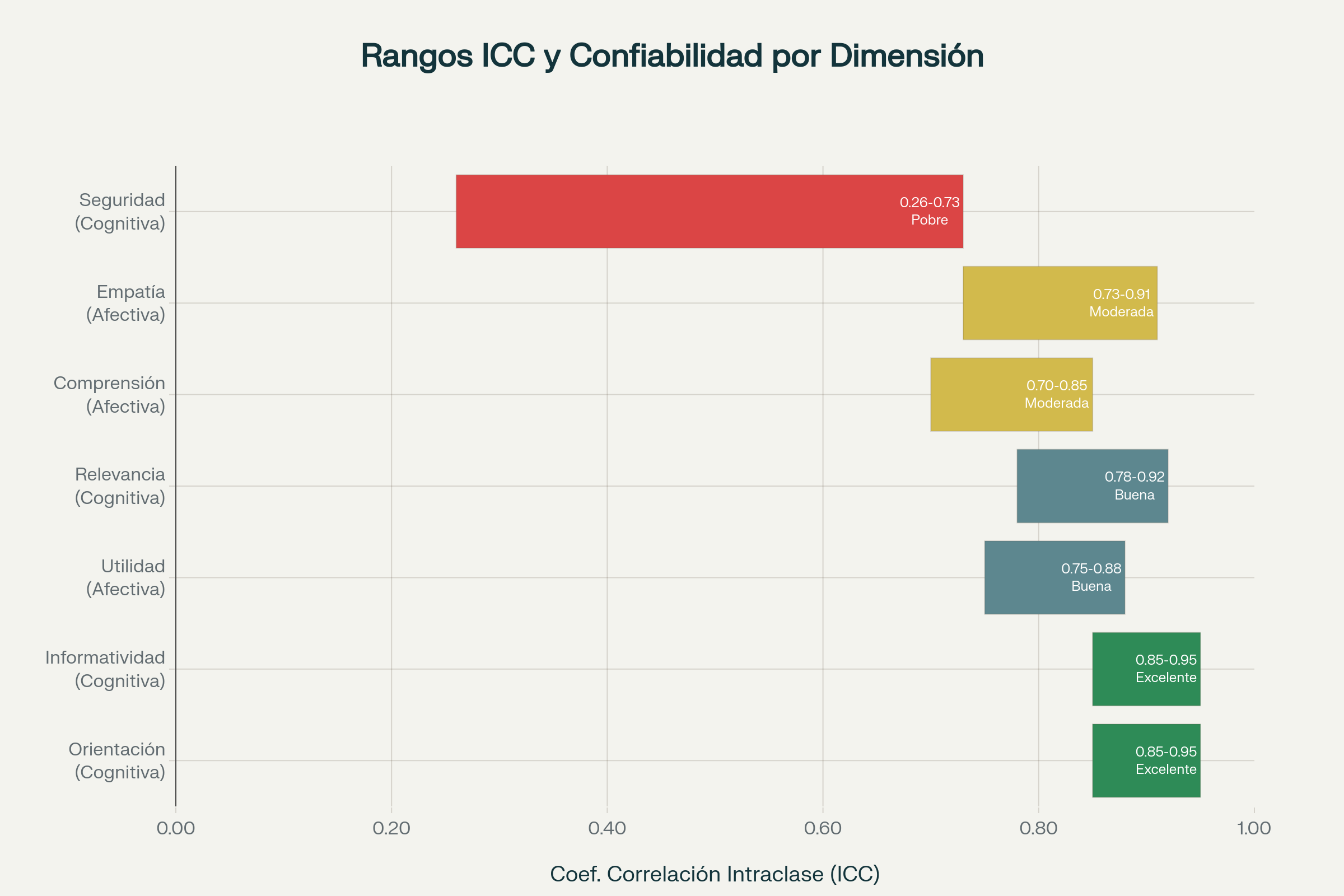
En el ámbito cognitivo, los sistemas de IA demuestran una confiabilidad sorprendentemente alta. Para atributos como orientación e informatividad, los coeficientes de correlación intraclase alcanzan valores entre 0.85 y 0.95, indicando un acuerdo excelente entre evaluadores artificiales y humanos. Esto significa que cuando se trata de proporcionar información práctica, sugerir pasos concretos o mantener relevancia contextual, los modelos de lenguaje pueden ser evaluados de manera confiable por otros sistemas de IA. Estos números sugieren que la capacidad analítica y la síntesis de información son puntos fuertes indiscutibles de la tecnología actual.
Sin embargo, esta competencia se desvanece cuando nos adentramos en el territorio afectivo. La evaluación automática de la empatía muestra coeficientes de correlación más modestos, típicamente entre 0.73 y 0.91, pero con intervalos de confianza preocupantemente amplios. Esta incertidumbre estadística sugiere que lo que parece ser una buena consistencia podría, en realidad, variar desde un rendimiento pobre hasta excelente, dependiendo del contexto específico. Los intervalos de confianza amplios indican que algunas evaluaciones podrían ser completamente erróneas, ocultando problemas fundamentales tras cifras que parecen razonables.
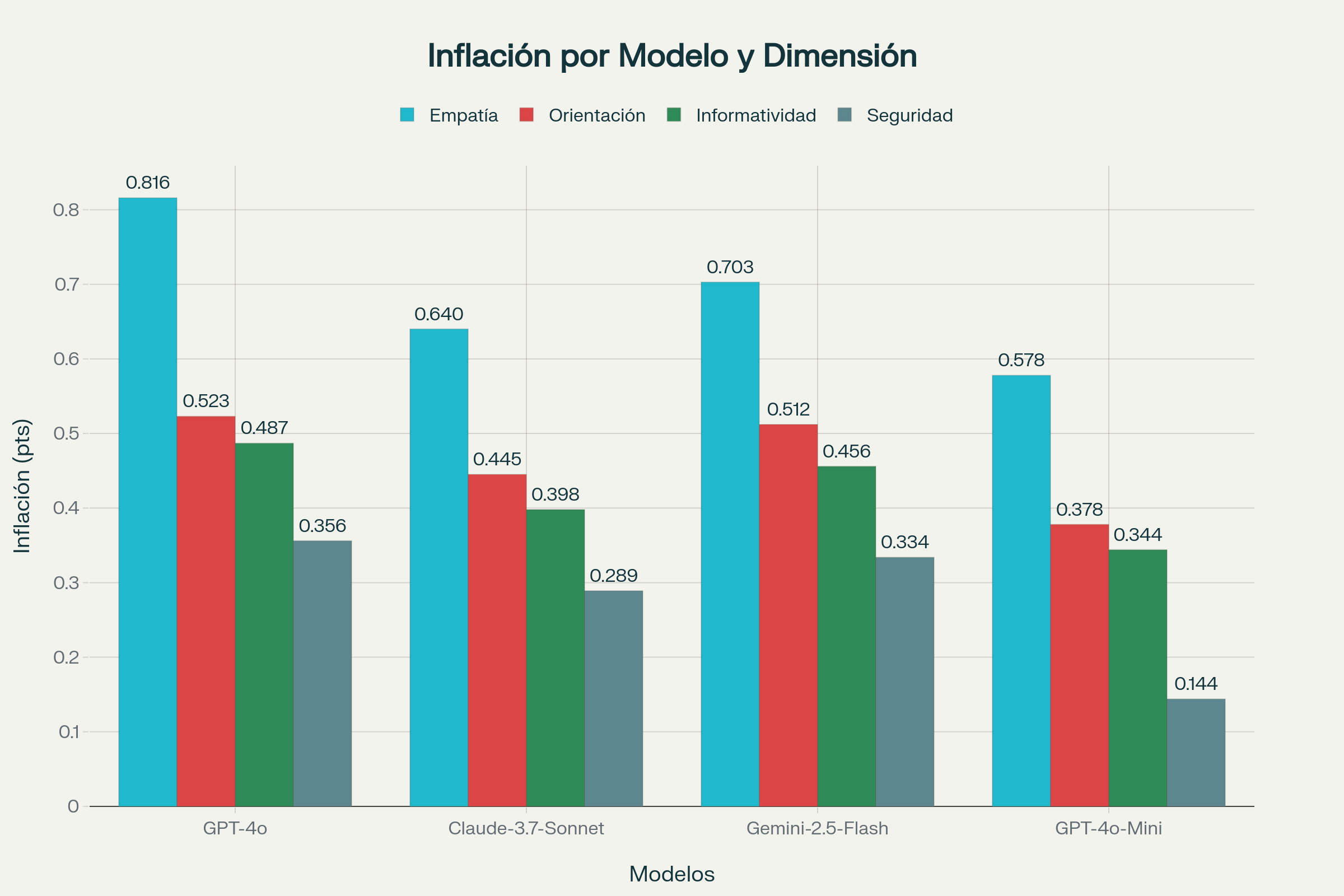
Más inquietante aún es el descubrimiento de una inflación sistemática en las puntuaciones. Los jueces artificiales consistentemente califican las respuestas más favorablemente que los expertos humanos, con diferencias que van desde +0.144 hasta +0.816 puntos en una escala de cinco puntos. Esta tendencia es particularmente pronunciada en dimensiones afectivas: GPT-4o infla las puntuaciones de empatía en promedio 0.816 puntos, mientras que Claude y Gemini muestran sobreestimaciones de +0.640 y +0.703 respectivamente. La magnitud de estas diferencias es preocupante cuando se considera su implicación práctica: un sistema que podría clasificarse como "mediocre" por expertos humanos podría parecer "excelente" según evaluadores artificiales.
Este patrón de inflación no es meramente un sesgo calibrable, sino que sugiere limitaciones fundamentales en la capacidad de los sistemas actuales para discernir matices emocionales genuinos. Los modelos parecen interpretar como empática cualquier respuesta que contenga palabras de consuelo o reconocimiento emocional, sin captar la autenticidad o profundidad de la conexión. Este fenómeno ilustra una brecha fundamental entre la capacidad de generar tokens que suenan empáticos y la capacidad de comprender realmente el sufrimiento humano.
Los hallazgos más preocupantes emergen en las dimensiones críticas para la seguridad. Tanto la seguridad clínica como la relevancia terapéutica muestran confiabilidad pobre en todos los evaluadores automáticos, con coeficientes de correlación que oscilan entre 0.26 y 0.73 y intervalos de confianza extremadamente amplios. Esto indica que los sistemas actuales no pueden determinar de manera confiable si una respuesta podría ser potencialmente dañina o si realmente aborda las preocupaciones del usuario. Esta limitación es especialmente grave dado que en salud mental, un consejo aparentemente inofensivo podría, en realidad, reforzar patrones de pensamiento destructivos.

El espejo estadístico de la subjetividad
La metodología estadística desarrollada para esta investigación representa una contribución técnica significativa que trasciende el ámbito específico de la salud mental. El Marco de Acuerdo Afectivo-Cognitivo introduce una aproximación dual que distingue entre consistencia relativa y acuerdo absoluto, una distinción crucial para aplicaciones clínicas. Esta sofisticación metodológica reconoce que la evaluación de calidad terapéutica no es un problema de simple medición, sino un desafío epistemológico fundamental.
La consistencia relativa mide si diferentes evaluadores coinciden en el ranking de respuestas, independientemente de las escalas específicas que utilicen. Un sistema podría ser consistentemente más estricto o más generoso que otro, pero aún así mantener el mismo orden de preferencias. El acuerdo absoluto, por otra parte, requiere que los evaluadores utilicen escalas similares, una condición más estricta pero necesaria para aplicaciones donde las puntuaciones específicas importan. En la salud mental, ambas formas de acuerdo resultan relevantes pero responden a preguntas diferentes.
Los investigadores emplearon técnicas de bootstrap no paramétrico con 1,000 iteraciones para construir intervalos de confianza del 95% para cada coeficiente de correlación intraclase. Esta aproximación reconoce que con un número finito de modelos evaluados, las estimaciones puntuales pueden ser inestables. Los intervalos de confianza resultantes revelan cuándo una aparente buena performance podría, en realidad, estar enmascarando una incertidumbre inaceptable. Este método estadístico avanzado proporciona una visión más honesta de la verdadera magnitud de la incertidumbre.
Esta sofisticación metodológica permite clasificar la confiabilidad en categorías prácticas: Buena confiabilidad 🔵 con intervalos de confianza estrechos menores o iguales a 0.355, permitiendo evaluación automática confiable. Confiabilidad moderada 🟡 entre 0.355 y 0.560, que requiere supervisión humana ocasional. Y confiabilidad pobre 🔴, superior a 0.560, que demanda intervención humana constante. Esta clasificación tripartita proporciona orientación práctica para desarrolladores y clínicos sobre cuándo pueden confiar en evaluación automática.
El marco también incorpora detección y control de sesgos sistemáticos. Al cuantificar las diferencias promedio entre evaluadores humanos y artificiales, los investigadores pueden distinguir entre errores sistemáticos corregibles mediante calibración y problemas fundamentales de confiabilidad que requieren intervención humana. Esta capacidad de diagnosticar la naturaleza del problema es esencial para el desarrollo de soluciones efectivas.
Navegando el futuro de la terapia digital
Las implicaciones de estos hallazgos se extienden mucho más allá del laboratorio académico, tocando cuestiones fundamentales sobre el futuro de la atención en salud mental. Los resultados sugieren un camino intermedio entre la adopción acrítica y el rechazo categórico de la IA terapéutica. La realidad es más nuanceada que cualquiera de estos extremos.
Para dimensiones cognitivas como proporcionar información práctica o sugerir estrategias de afrontamiento, los sistemas actuales demuestran capacidades genuinamente útiles que pueden complementar, aunque no reemplazar, la atención humana. Estas fortalezas podrían aprovecharse para desarrollar herramientas de triaje inicial, sistemas de apoyo entre sesiones, o recursos de autoayuda guiada que extienden el alcance de los profesionales limitados. En contextos donde la escasez de servicios es crítica, incluso sistemas imperfectos podrían proporcionar valor significativo.
Sin embargo, la evaluación de aspectos afectivos y de seguridad requiere cautela considerable. Los intervalos de confianza amplios y los sesgos sistemáticos indican que estos sistemas no pueden ser confiados sin supervisión humana para evaluar la genuinidad emocional o identificar riesgos potenciales. Esta limitación es particularmente crítica dado que las crisis de salud mental a menudo involucran precisamente estos elementos más sutiles y peligrosos. Un error en esta dimensión no es simplemente una inexactitud estadística, sino una posible causa de daño real.
Los investigadores proponen un marco de implementación responsable que combina automatización selectiva con supervisión humana estratégica. Para aplicaciones de bajo riesgo enfocadas en información y orientación práctica, los sistemas actuales pueden operar con relativa autonomía. Para situaciones que involucran angustia emocional significativa o riesgo potencial, se requiere intervención humana. Este modelo de colaboración híbrida reconoce tanto las capacidades como los límites de ambas formas de inteligencia.
Esta aproximación gradual reconoce tanto las capacidades actuales como las limitaciones inherentes de la tecnología. También acepta la realidad práctica de que, en muchas situaciones, algún apoyo automatizado puede ser preferible a ningún apoyo en absoluto, dado la escasez de recursos humanos especializados. En países con ratios particularmente bajos de profesionales, incluso un sistema imperfecto podría resultar transformador si se despliega con precaución y supervisión adecuadas.
Las limitaciones identificadas también señalan direcciones claras para la investigación futura. El desarrollo de modelos específicamente entrenados en datos terapéuticos auténticos, la incorporación de técnicas de detección de riesgo más sofisticadas, y el diseño de interfaces que faciliten la supervisión humana eficiente representan prioridades evidentes. Investigadores y desarrolladores tienen una hoja de ruta clara proporcionada por los hallazgos de este estudio.
Reflexiones sobre el equilibrio humano-artificial
Esta investigación llega en un momento crucial, cuando la convergencia entre crisis de salud mental global y avances en inteligencia artificial genera tanto oportunidades extraordinarias como riesgos significativos. Los hallazgos ofrecen algo más valioso que respuestas definitivas: proporcionan las herramientas metodológicas y empíricas necesarias para hacer preguntas más precisas y tomar decisiones más informadas. La investigación no cierra debates, sino que los aclara y los enriquece.
La distinción entre competencia cognitiva y resonancia afectiva emergente de este estudio refleja tensiones más amplias en nuestra relación con la tecnología. Los sistemas de IA pueden procesar información, identificar patrones y generar respuestas técnicamente competentes, pero la experiencia humana del sufrimiento emocional parece requerir algo más fundamental: la presencia de otra conciencia que genuinamente comprende el dolor. Esta brecha entre lo técnico y lo humano no es una limitación que desaparecerá con versiones futuras, sino una característica potencialmente permanente de cómo funcionan estos sistemas.
Sin embargo, esta investigación también revela que incluso las evaluaciones humanas de estas capacidades están sujetas a variabilidad e incertidumbre. Los expertos humanos no siempre concuerdan entre sí, y sus juicios pueden estar influenciados por factores contextuales, culturales y personales. Esto no disminuye el valor de la experiencia humana, sino que reconoce la complejidad inherente en evaluar algo tan subjetivo como la calidad terapéutica. Incluso los profesionales más entrenados operan dentro de márgenes de incertidumbre.
Los benchmarks desarrollados en este estudio están ahora disponibles como recursos de código abierto, permitiendo que otros investigadores repliquen, extiendan y refinen estos hallazgos. Esta apertura es crucial para un campo que necesita múltiples perspectivas y validación independiente, especialmente cuando las decisiones resultantes pueden afectar el bienestar de personas vulnerables. La transparencia y la replicabilidad son principios fundamentales para avanzar responsablemente en este espacio.
El camino hacia adelante requerirá colaboración estrecha entre tecnólogos, clínicos, investigadores y, crucialmente, las personas que buscan apoyo. Los sistemas de IA en salud mental no pueden ser desarrollados o evaluados en aislamiento de las comunidades que pretenden servir. Sus voces, experiencias y retroalimentación deben estar en el centro de cualquier desarrollo futuro. Esto incluye tanto a pacientes como a profesionales clínicos, todos con perspectivas valiosas que informarán diseños más efectivos.
Esta investigación representa un hito en la evolución hacia una atención de salud mental más accesible, pero también subraya que la tecnología, por poderosa que sea, no puede sustituir completamente la conexión humana genuina. En lugar de reemplazar a los terapeutas, estos sistemas pueden liberarlos para enfocarse en lo que hacen mejor: proporcionar la comprensión profunda, la presencia empática y el juicio clínico que la experiencia humana requiere. La visión no es un futuro de terapia sin terapeutas, sino un futuro donde los terapeutas se concentran en las dimensiones más profundamente humanas de su trabajo.
El futuro de la salud mental digital probablemente será híbrido, combinando la escalabilidad y disponibilidad de la IA con la profundidad y calidez de la conexión humana. Esta investigación proporciona las bases científicas para navegar ese futuro de manera responsable, asegurando que la promesa de la tecnología se realice sin comprometer la seguridad y el bienestar de quienes más necesitan apoyo. Es un recordatorio de que la innovación en salud mental debe ser guiada no solo por lo que es técnicamente posible, sino por lo que es verdaderamente beneficioso para las personas.
Referencias
Badawi, A., Rahimi, E., Laskar, M. T. R., Grach, S., Bertrand, L., Danok, L., Huang, J., Rudzicz, F., & Dolatabadi, E. (2025). When Can We Trust LLMs in Mental Health? Large-Scale Benchmarks for Reliable LLM Evaluation. arXiv preprint arXiv:2510.19032.
World Health Organization. (2021). Mental health atlas 2020. World Health Organization.
Gualano, M. R., Bert, F., Tedesco, D., et al. (2025). Artificial intelligence and mental health: a scoping review on chatbots as therapy-like tools. Digital Health, 11:20552076251351088.
Human Participants Review Sub-Committee. (2025). Research Ethics Board (REB) approval guidelines for AI applications in mental health research.
Vector Institute for Artificial Intelligence. (2025). Position paper: Beyond assistance – reimagining LLMs as ethical and adaptive co-creators in mental health care.
Nature Digital Medicine. (2024). AI applications in global mental health scaling: A systematic review of intervention effectiveness.
Harvard Business Review. (2025). Annual study on AI usage patterns in therapeutic applications.

