
En una madrugada de mayo, un grupo de investigadores activó un par de servidores y pulsó “ejecutar”. Al otro lado de la línea, un conjunto de modelos de lenguaje comenzó a trabajar sobre algo inusual: no era un enigma literario ni un problema de álgebra, sino una serie de casos de inversión, análisis de carteras y preguntas sobre ética profesional que conforman el temido nivel III del examen de Chartered Financial Analyst (CFA). A las pocas horas (en algunos casos, en cuestión de minutos) los mismos algoritmos que se usan para traducir textos y redactar correos electrónicos devolvieron respuestas y explicaciones que, según evaluadores independientes, hubieran permitido aprobar uno de los exámenes más exigentes del sector financiero. Las personas tardan años de estudio y alrededor de mil horas de preparación para sortear con éxito los tres niveles del CFA, pero esta vez la hazaña se cumplió en tiempo récord gracias a la sinergia de datos, estrategias de razonamiento y computación avanzada.
El escenario parece sacado de una novela de anticipación, pero es real y tiene nombres propios. La iniciativa fue organizada por el laboratorio de investigación GoodFin en colaboración con académicos de la Stern School of Business de la Universidad de Nueva York. El proyecto no solo puso a prueba la capacidad de los sistemas de inteligencia artificial (IA) para lidiar con contenidos complejos; también construyó una plataforma, conocida como CFA Benchmark, que permite comparar modelos, identificar fortalezas y debilidades en sus procesos de razonamiento y ofrecer un marco reproducible para medir su desempeño sobre materiales inspirados en el examen CFA. El sitio web, dotado de un tablero interactivo, un comparador y un repositorio de preguntas, se ha convertido en referencia para evaluar algoritmos en contextos financieros y, de paso, en una ventana pública para entender qué significa aprobar un examen de esta naturaleza.
¿Por qué tanto interés en un examen profesional? El CFA es más que una credencial. Su contenido abarca análisis de portafolios, gestión de riesgos, mercados privados, ética y estándares profesionales. Obtenerlo implica un compromiso con el rigor, la actualización permanente y la integridad, atributos esenciales en una industria que administra el patrimonio de personas y organizaciones. El nivel III, en particular, se centra en la construcción de carteras y la planificación patrimonial. Es un examen que combina preguntas de selección múltiple y ensayos largos que deben justificar decisiones, explicar estrategias y demostrar adhesión a principios éticos. Superarlo no solo certifica conocimientos, sino que acredita la capacidad de aplicar criterios analíticos y valores en situaciones complejas. La irrupción de algoritmos capaces de aprobarlo pone en discusión el rol de la IA en la asesoría financiera, en la educación y en el mercado laboral.
La historia de esta evaluación es también la historia del progreso en IA. Hace apenas dos años, los modelos generativos lograban superar los niveles I y II del CFA, que se enfocan en herramientas cuantitativas y conceptos básicos de inversión. Las secciones de ensayo del nivel III seguían siendo el gran escollo: evaluar un texto en el que se deben justificar razonamientos y exponer criterios de manera estructurada es una tarea que parecía demasiado abstracta para una IA. Ese paradigma se ha quebrado. Modelos avanzados como o4‑mini de OpenAI, Gemini 2.5 Pro de Google y Claude Opus 4 de Anthropic han demostrado que, con estrategias de razonamiento específicas, pueden procesar preguntas largas, elaborar respuestas y defenderlas con argumentos coherentes. Lo lograron mediante técnicas conocidas como chain‑of‑thought prompting, en las que se solicita explícitamente al modelo que explique paso a paso su razonamiento antes de llegar a la conclusión.
El objetivo de este artículo es ofrecer una mirada integral sobre este fenómeno: explicar qué hay detrás de la capacidad de la IA para aprobar el examen CFA, desglosar la metodología que utilizan los responsables del CFA Benchmark para evaluar modelos, analizar las herramientas que permite comparar resultados, reflexionar sobre las implicaciones éticas y profesionales y, finalmente, plantear preguntas sobre la interacción entre máquinas y personas en el mundo de las finanzas. La narrativa se construirá de forma accesible para el lector no especializado, sin renunciar al rigor ni a la precisión técnica. Se evitará el uso de guiones largos, se alternarán sinónimos para evitar repeticiones y se utilizarán viñetas en contadas ocasiones, de acuerdo con las instrucciones recibidas.
Los modelos de lenguaje frente al desafío CFA
La noticia de que una IA puede aprobar el nivel III del CFA salió a la luz el 24 de septiembre de 2025 a través de un artículo publicado por CNBC. El reportaje, replicado por diversos medios, destacaba que nuevas investigaciones mostraban cómo varios modelos eran capaces de superar el examen en minutos. Las pruebas incluyeron a 23 modelos de lenguaje de distintas empresas, desde los más conocidos (como GPT‑4 y sus variantes mini y nano) hasta sistemas emergentes como Gemini 2.5 y Claude Opus. Lo que diferenciaba a los modelos exitosos era la presencia de mecanismos de razonamiento, es decir, procesos internos que permiten organizar ideas, desglosar problemas y justificar decisiones.
La principal estrategia empleada por los investigadores fue la de chain‑of‑thought (cadena de pensamiento). Consiste en pedir al modelo que no solo devuelva una respuesta final, sino que explique sus pasos intermedios. Esto ayuda a evitar errores de razonamiento implícito y favorece una mayor coherencia en los resultados. Para garantizar la consistencia, los evaluadores generaron varias cadenas independientes (tres o cinco en promedio) y seleccionaron la mejor por consenso o por autoevaluación del propio modelo. Este procedimiento se aplicó a las preguntas de selección múltiple y, especialmente, a las preguntas de ensayo, donde el razonamiento explícito es crucial.
Otra técnica empleada fue el self‑discover, un método en el que el modelo debe diseñar su propia estructura de razonamiento antes de responder. En lugar de suministrarle un patrón fijo, se le invita a escoger qué módulos de razonamiento utilizar, cómo ordenarlos y cómo articular sus conclusiones. De esta forma se busca estimular la capacidad de planificación metacognitiva, algo parecido a lo que hace una persona cuando prepara una respuesta compleja: decide por dónde empezar, cómo organizar los argumentos y qué puntos destacar.
La combinación de estas técnicas dio resultados sorprendentes. Modelos como o4‑mini y Gemini 2.5 Pro alcanzaron puntajes que, según los criterios del CFA Benchmark, equivaldrían a aprobar cómodamente el nivel III del examen. Esto no significa que la IA haya adquirido las mismas competencias que un profesional certificado. Los mismos investigadores subrayan que la tecnología está lejos de reemplazar a los analistas humanos. Los algoritmos aún carecen de juicio contextual, sensibilidad ética y habilidades interpersonales para asesorar a clientes. Sin embargo, su desempeño evidencia una progresión acelerada en su capacidad para resolver problemas estructurados y redactar argumentaciones coherentes, rasgos que podrían complementar el trabajo de los profesionales.
Para dimensionar el logro, conviene repasar qué implica el nivel III del CFA. Este examen, que se administra una vez al año, se concentra en la gestión avanzada de carteras, la planificación patrimonial y la ética profesional. Incluye varias secciones de selección múltiple y una parte central de ensayos en la que se plantean casos de clientes con objetivos, restricciones, perfiles de riesgo e información familiar. Los candidatos deben construir portafolios, justificar asignaciones de activos, explicar estrategias de cobertura y proponer planes de retiro ajustados a las normas legales y a los estándares profesionales. La evaluación se enfoca en la capacidad de integrar conocimientos, aplicar fórmulas financieras y comunicar de manera persuasiva. Aprobar implica haber desarrollado disciplina de estudio, pensamiento crítico y compromiso con la integridad.
La irrupción de la IA en este contexto plantea preguntas de diferente índole. ¿Podrían los algoritmos reemplazar a los candidatos en el futuro? La respuesta más consensuada es negativa en el corto plazo. La profesión de asesor financiero requiere habilidades que van más allá de calcular retornos o diversificar portafolios. Incluye la capacidad de escuchar a los clientes, interpretar matices de su vida personal, navegar contextos de incertidumbre y tomar decisiones con responsabilidad. Aunque los modelos pueden simular razonamientos, no poseen consciencia ni experiencia vital. Por eso, los responsables del estudio insisten en que la IA debe ser vista como una herramienta que complementa el trabajo humano. De hecho, uno de los hallazgos del informe fue que los modelos obtienen mejores resultados cuando se les permite explicar sus pasos, lo que sugiere que la transparencia en el razonamiento facilita la corrección y la colaboración con personas.
Cómo se construye el CFA Benchmark
Una parte fundamental del proyecto es el diseño del banco de preguntas, su validación y la forma en que se evalúan las respuestas. El CFA Benchmark se articula en torno a cuatro grandes bloques: la construcción de la base de datos, la selección de modelos, las estrategias de razonamiento y el marco de evaluación. Cada componente está documentado públicamente en la sección Methodology del sitio web, lo que permite reproducir y verificar los experimentos.
Dataset, construcción y validación
El primer paso del proyecto consistió en crear un conjunto de preguntas que reflejara fielmente el contenido del nivel III del CFA. Para ello, los investigadores recurrieron a AnalystPrep, un proveedor de preparación para este examen que sirve a más de cien mil candidatos en todo el mundo. Con su colaboración, elaboraron un banco de 60 preguntas de selección múltiple, organizadas en diez viñetas temáticas con seis preguntas cada una. Cada viñeta cubre uno de los temas clave del programa, como gestión de portafolios, mercados privados o ética profesional. Las preguntas fueron revisadas y validadas por evaluadores certificados, y posteriormente se calibraron con los estándares oficiales del CFA para asegurar que representaran adecuadamente la dificultad y la profundidad esperadas.
En cuanto a las preguntas de ensayo, se construyeron 11 viñetas independientes con un total de 43 preguntas, que suman 149 puntos. Cada viñeta presenta un caso con contexto detallado (objetivos del cliente, restricciones, horizonte de inversión, entre otros) y contiene entre dos y cinco preguntas abiertas. Los evaluadores humanos se encargaron de verificar la integridad del contenido y de garantizar que las preguntas no vulneraran la confidencialidad del material de exámenes reales. El objetivo era reproducir la experiencia del candidato que enfrenta una situación de cliente y debe formular estrategias de inversión concretas, con énfasis en la justificación argumentada.
Además de definir las preguntas, los responsables del CFA Benchmark también se preocuparon por la diversidad temática. Las áreas de cobertura incluyen: gestión patrimonial privada, gestión de carteras, mercados privados, gestión de activos, derivados y gestión de riesgos, medición de desempeño, construcción de portafolios y estándares éticos y profesionales. La amplitud de temas asegura que el desempeño de los modelos sea evaluado en distintas dimensiones, desde análisis cuantitativo hasta la interpretación de normativas.
Selección de modelos y categorización
Otro elemento clave es la elección de los modelos. El CFA Benchmark distingue entre reasoning models y non‑reasoning models. Los primeros son sistemas diseñados para elaborar cadenas de razonamiento explícitas y suelen incluir variantes de alto rendimiento de los principales proveedores. En la fecha de la última actualización (12 de septiembre de 2025) figuraban en este grupo modelos como o3‑mini y o4‑mini de OpenAI, Claude‑3.7‑Sonnet y Claude‑Opus 4 de Anthropic, Claude‑Sonnet 4, Gemini‑2.5‑Pro y Gemini‑2.5‑Flash de Google, Grok‑3‑mini‑beta (con dos niveles de esfuerzo) de xAI y Deepseek‑R1. Cada uno de ellos fue configurado con el máximo contexto que permite la plataforma y un presupuesto de consumo determinado.
Los non‑reasoning models corresponden a versiones de modelos que responden directamente sin exponer sus pasos. En la lista se encuentran GPT‑4o y las series GPT‑4.1 de OpenAI, GPT‑4.1‑mini y GPT‑4.1‑nano; Claude‑3.5‑Sonnet y Claude‑3.5‑Haiku de Anthropic; versiones del Grok‑3, así como series de Llama‑3 (8B‑instant y 3.3‑70B), Llama‑4‑Maverick y Llama‑4‑Scout de Meta. Completa el listado Mistral‑Large y Palmyra‑Fin, un modelo especializado en finanzas. La clasificación no implica que unos sean mejores que otros, pero permite diferenciar la naturaleza de sus respuestas y analizar cómo la explicitación del razonamiento impacta en el resultado final.
Estrategias de razonamiento
El CFA Benchmark evalúa a los modelos bajo distintas estrategias de prompt, cada una con objetivos específicos.
- Zero‑shot: la pregunta se presenta sin mayores indicaciones y se solicita una respuesta directa. Este modo permite medir las habilidades básicas del modelo para resolver problemas sin pistas ni ejemplos. Sirve como línea de base para comparar los efectos de técnicas más sofisticadas.
- Chain‑of‑thought con auto‑consistencia: en este caso, se indica al modelo que despliegue una secuencia de pasos lógicos antes de entregar la respuesta. Para garantizar la consistencia, se generan varias cadenas de razonamiento y se selecciona la mejor según un criterio mayoritario (en selección múltiple) o mediante autoevaluación en las preguntas de ensayo. Esta técnica busca imitar las estrategias de examen en las que el candidato anota sus pasos para identificar errores y corregirlos.
- Self‑discover: este enfoque va más allá, invitando al modelo a diseñar su propio esquema de razonamiento. El modelo debe elegir qué módulos utilizar (por ejemplo, análisis cuantitativo, justificación legal, estructuración de portafolios), adaptarlos al problema concreto y planificar cómo integrarlos antes de redactar la respuesta. De este modo se examina la habilidad de planificación y de adaptación al contexto.
Marco de evaluación y métricas
Una vez que los modelos generan sus respuestas, el CFA Benchmark aplica criterios objetivos para calificarlas. En la parte de selección múltiple, las métricas incluyen la precisión (porcentaje de respuestas correctas sobre 60 preguntas), el tiempo de respuesta promedio por pregunta, el costo total en dólares para completar todas las preguntas (se considera el precio de usar cada modelo) y una puntuación directa de correctitud binaria. En las preguntas de ensayo, se emplean varias métricas: self grade (una evaluación realizada por GPT‑4.1 con la rúbrica del CFA, en una escala de 0 a 4), cosine similarity (medida de similitud semántica con las respuestas de referencia), ROUGE‑L F1 (que mide el solapamiento de secuencias de palabras) y cost efficiency (que relaciona la calidad del texto con el costo de generar la respuesta).
Para las evaluaciones largas, se utiliza un marco llamado “LLM‑as‑Judge”. Este sistema incorpora la rúbrica oficial del CFA para el nivel III y evalúa las respuestas de los modelos en varias dimensiones: precisión técnica (corrección de conceptos y cálculos), completitud (que todos los elementos de la pregunta estén presentes), calidad del razonamiento (flujo lógico y justificación de conclusiones) y cumplimiento de estándares profesionales (adhesión a los principios éticos). Cada dimensión se pondera para obtener una nota final que se aproxime al criterio de los examinadores humanos.
El CFA Benchmark agrupa sus métricas en dos grandes categorías:
- Calidad: se evalúa la precisión en las preguntas de selección múltiple y, en las preguntas de ensayo, el autoanálisis con la rúbrica, la similitud semántica y el solapamiento textual.
- Eficiencia: se examinan el costo (en dólares) para ejecutar el examen, la rapidez de respuesta y el aprovechamiento del contexto (longitud de la ventana de tokens). También se considera si el modelo pertenece a la categoría de razonamiento explícito o no.
Este conjunto de indicadores permite comparar modelos no solo por su capacidad para contestar correctamente, sino también por su consumo de recursos y su capacidad de justificar decisiones.
El panel de comparación y la tabla de líderes
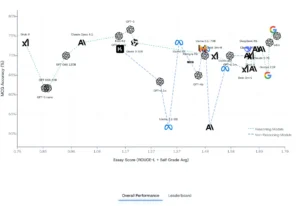
Uno de los elementos más valorados del CFA Benchmark es su interfaz interactiva. En la sección Overall, el sitio despliega un gráfico que compara el desempeño de los modelos en selección múltiple y en ensayos. En el eje vertical se representa la precisión en preguntas de opción múltiple (MCQ), mientras que el eje horizontal refleja la nota obtenida en los ensayos (una combinación de autoevaluación y métricas de similitud). Cada punto del gráfico corresponde a un modelo y su color indica si se trata de un sistema con razonamiento explícito o no. De este modo, el usuario puede apreciar de forma visual que los modelos de razonamiento tienden a concentrarse en la zona superior derecha, es decir, registran simultáneamente alta precisión y notas destacadas en ensayos, mientras que los modelos sin razonamiento se dispersan, con algunas excepciones notables.
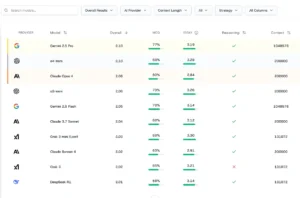
Debajo del gráfico aparece la tabla de líderes, que resume los resultados numéricos. Según la actualización de septiembre de 2025, los modelos más destacados fueron Gemini 2.5 Pro de Google y o4‑mini de OpenAI, ambos con un puntaje general de 2.10 en la escala interna. La tabla detalla la precisión en MCQ (por ejemplo, 77 % para Gemini 2.5 Pro y 68 % para o4‑mini), la nota en ensayo (3.19 y 3.28 respectivamente), el tiempo de contexto (número de tokens que pueden procesar) y si pertenecen a la categoría de razonamiento. Otros modelos situados en la parte alta incluyen Claude Opus 4 de Anthropic y variantes como Gemini 2.5 Flash y Claude 3.7 Sonnet. El ranking no solo sirve para coronar a los ganadores, sino que permite observar la distribución de rendimientos y advertir, por ejemplo, que algunos modelos de uso general tienen un costo significativamente más alto para un desempeño similar, o que un modelo compacto puede ser sorprendentemente competitivo.
La sección Compare permite seleccionar varios modelos y ver sus resultados lado a lado. Aunque la interfaz requiere interacción manual (clics y búsquedas), su utilidad radica en la personalización: un investigador puede elegir dos modelos de diferente proveedor y analizar cómo varían sus porcentajes de aciertos, su rendimiento en ensayos y sus costos. Esta vista comparativa es particularmente valiosa para empresas que deben decidir qué modelo integrar en sus servicios de análisis financiero o para desarrolladores que desean conocer las fortalezas y debilidades de cada arquitectura.
El Dashboard agrega otra capa de análisis. Presenta gráficos con el tiempo promedio de respuesta, el costo acumulado por modelo, la distribución de puntuaciones de ensayo y la evolución de la precisión a medida que se aplican diferentes estrategias de razonamiento. Permite filtrar por proveedor, por tamaño de modelo y por tipo de examen. Así, se puede observar, por ejemplo, que el uso de chain‑of‑thought mejora notablemente el desempeño en ensayos, pero también incrementa el costo y el tiempo de respuesta. También se puede comprobar que algunos modelos logran respuestas correctas en menos pasos que otros, lo que se traduce en mayor eficiencia. Estos insights ayudan a ajustar las estrategias de uso según las necesidades (más calidad con menos costo, mayor rapidez, mejor rendimiento en preguntas abiertas, etc.).
La plataforma incluye además un repositorio de ensayos y un repositorio de preguntas de selección múltiple. Allí se listan las viñetas completas, los contextos proporcionados y las respuestas de los modelos. Este acceso facilita replicar los experimentos, entrenar modelos adicionales y analizar con detalle cómo cada sistema estructura sus argumentaciones. Para los docentes y candidatos que se preparan para el examen, estos repositorios son una herramienta valiosa para practicar con materiales de calidad y ver ejemplos de respuestas elaboradas.
Implicaciones para la profesión financiera
El hecho de que una IA pueda aprobar un examen como el CFA tiene varias interpretaciones. En un primer nivel, demuestra que los modelos de lenguaje han alcanzado un grado de sofisticación que les permite comprender textos financieros complejos, razonar sobre portafolios y replicar argumentos. Sin embargo, esa capacidad no debe confundirse con una comprensión integral del mundo financiero. Los modelos trabajan sobre representaciones estadísticas del lenguaje y carecen de experiencia directa en mercados reales. Sus respuestas son coherentes porque han sido entrenados con miles de documentos, exámenes pasados, artículos y manuales; no porque hayan vivido la realidad de un crash bursátil o la ansiedad de un cliente durante una crisis.
Desde la perspectiva profesional, la IA ofrece oportunidades y desafíos. Puede convertirse en un aliado de los analistas, acelerando la elaboración de reportes, verificando cálculos y proporcionando primeras versiones de recomendaciones. También puede democratizar el acceso a servicios de asesoría, al permitir que plataformas automatizadas ofrezcan orientación básica a inversores individuales. Sin embargo, es crucial mantener la vigilancia sobre los sesgos, errores y confianzas injustificadas. Un modelo puede entregar un plan de inversión aparentemente impecable y, sin embargo, cometer un error básico de interpretación de riesgo o de cálculo de impuestos. Por ello, la incorporación de IA en la gestión de patrimonios debe ir acompañada de validación humana, auditorías y responsabilidad legal.
El avance de las máquinas también plantea preguntas sobre la formación de profesionales. Si un algoritmo puede aprobar el nivel III, ¿tiene sentido exigir a las personas que pasen por tres niveles de examen? La respuesta depende de la visión de la educación. El proceso de preparación para el CFA no solo transmite conocimiento; también desarrolla disciplina, capacidad analítica, ética y resiliencia. Es un camino que ayuda a interiorizar principios que no se aprenden memorizando respuestas. Los candidatos que estudian durante años adquieren un juicio que no se deriva de un corpus textual. Por lo tanto, aunque la IA pueda replicar resultados en la prueba, la experiencia humana seguirá siendo insustituible para la toma de decisiones con impacto real.
Miradas hacia el futuro
La publicación del CFA Benchmark y el éxito de la IA en el examen abren caminos para futuras investigaciones. Una línea evidente es la mejora de los modelos en aspectos que todavía son débiles, como la justificación ética y el contexto cultural. Los ensayos de nivel III incluyen situaciones en las que hay que aplicar estándares profesionales y considerar la legislación de distintos países. Un modelo que no distinga entre un régimen fiscal y otro puede dar un consejo inadecuado. Para superar estos retos se necesitarán algoritmos más especializados, quizá entrenados con datos regulatorios y supervisados por expertos en compliance.
Otra línea de desarrollo está en la evaluación misma. El CFA Benchmark ya integra la rúbrica oficial y métricas avanzadas, pero la industria podría adoptar parámetros adicionales, como la capacidad de síntesis, la creatividad en la construcción de carteras y la adaptación a objetivos no convencionales (por ejemplo, inversiones sostenibles o criterios de inversión de impacto). También se podría explorar la incorporación de evaluadores humanos en el circuito, de modo que las notas resulten de una mezcla de juicio automatizado y juicio experto. Las máquinas podrían preclasificar respuestas y los humanos dedicar su tiempo a revisar los casos dudosos o los más relevantes.
Desde el punto de vista legal y ético, la discusión apenas comienza. ¿Cómo se regula la utilización de IAs que aprueban exámenes profesionales? ¿Debe existir una certificación para modelos, similar a la que obtienen los analistas humanos? ¿Quién responde si un plan elaborado con ayuda de una IA genera pérdidas para un cliente? Los marcos regulatorios aún no están adaptados a estas realidades, pero es probable que surjan normas y estándares específicos. Organismos como la CFA Institute podrían liderar debates sobre el uso responsable de la IA, tal como han hecho con la adopción de nuevas tecnologías en la industria.
En educación, las instituciones que preparan a los candidatos deben integrar herramientas de IA como apoyo, no como sustituto. Los estudiantes podrían utilizar los modelos para practicar la estructura de ensayos, recibir retroalimentación automática y mejorar sus argumentos. Pero también deberán aprender a identificar fallos y sesgos en las respuestas de la máquina. La alfabetización digital y algorítmica se vuelve indispensable: entender cómo funciona el modelo, qué tipo de errores puede cometer y cómo usarlo de manera ética y efectiva.
La sinfonía entre humanos y máquinas
La experiencia de ver a un algoritmo superar el nivel III del examen CFA es un recordatorio de que la inteligencia artificial ya no es un experimento de laboratorio, sino un actor que empieza a interactuar con actividades tradicionalmente humanas. El proyecto CFA Benchmark no solo demuestra que los modelos pueden procesar preguntas complejas; también ofrece una metodología rigurosa para medir su desempeño, compararlos y entender cómo piensan (o al menos, cómo imitan el pensamiento). La transparencia del proceso, la publicación del dataset y el enfoque en la calidad y la eficiencia permiten que investigadores, empresas y académicos debatan con datos en la mano.
Sin embargo, el fenómeno no debe suscitar alarmismo ni complacencia. La IA no reemplazará de inmediato al analista financiero ni hará obsoleto el examen CFA. Lo que sí hará es transformar la forma en que trabajamos, estudiamos y supervisamos. La verdadera sinfonía conversacional se dará cuando humanos y algoritmos trabajen en armonía: los modelos aportando velocidad, memoria y consistencia; las personas aportando contexto, juicio y empatía. La historia de los modelos de lenguaje frente al CFA es, en el fondo, una invitación a repensar el valor de nuestras competencias y a diseñar un futuro en el que la tecnología amplifique nuestra capacidad de tomar decisiones justas, informadas y responsables.
Referencias
- GoodFin & NYU Stern. (2025). Advanced Financial Reasoning at Scale: A Comprehensive Evaluation of Large Language Models on CFA Level III. [arXiv:2507.02954]
- TipRanks. (24 de septiembre de 2025). Artificial Intelligence Can Now Pass the Toughest Part of the CFA Exam in Minutes.
- CFA Benchmark. (2025). Methodology. — Documento que explica la construcción del dataset, las áreas de cobertura, la categorización de modelos, las estrategias de prompting y las métricas de evaluación.
- CFA Benchmark. (2025). Overall & Leaderboard. — Sección que presenta el gráfico de comparación de modelos y la tabla de líderes con las puntuaciones de los sistemas probados.

