
Planificar un viaje es, en esencia, un acto de optimismo. Es el arte de tejer una serie de esperanzas, destinos y horarios en un tapiz coherente y disfrutable. Sin embargo, para muchos, este acto creativo se ve rápidamente ahogado por una avalancha logística. Navegar por un océano de pestañas en el navegador, comparar precios de vuelos que cambian con cada parpadeo, descifrar mapas de transporte público en lenguas desconocidas y encontrar un hotel que no sea una quimera fotográfica.
Esta maraña de microdecisiones convierte lo que debería ser la emocionante antesala de una aventura en una tarea abrumadora, un trabajo no remunerado que exige paciencia, pericia y una dosis no menor de suerte. Durante años, la tecnología nos ha prometido un salvavidas. Han surgido innumerables sitios web y aplicaciones, cada uno de los cuales ofrece una pieza del rompecabezas: uno para los billetes de avión, otro para el alojamiento, un tercero para las reseñas de restaurantes y un cuarto para las actividades. Pero esta solución fragmentada a menudo solo ha servido para multiplicar el número de malabarismos que debemos realizar.
En este contexto de fragmentación y complejidad, la promesa de una inteligencia artificial verdaderamente útil ha sido un espejismo recurrente en el horizonte tecnológico. Imaginemos por un momento un asistente digital que vaya más allá de ser un simple motor de búsqueda glorificado. Un verdadero copiloto de viajes que no solo responda a preguntas directas, sino que entienda la intención subyacente de un vago «quiero unas vacaciones relajantes en la playa en junio, con un presupuesto moderado y algo de cultura local».
Un agente que no se limite a presentar una lista de opciones, sino que razone, planifique, anticipe problemas y presente un itinerario completo, coherente y personalizado. Un consejero digital que, de forma autónoma, pueda consultar horarios de trenes, verificar la disponibilidad de hoteles, sugerir rutas a pie para maximizar las visitas turísticas y hasta prever el tiempo necesario para desplazarse desde el aeropuerto hasta el centro de la ciudad. Esta no es una fantasía lejana; es el objetivo preciso de una nueva y revolucionaria línea de investigación en el campo de la inteligencia artificial.
Recientemente, un equipo de científicos e ingenieros ha publicado un trabajo que representa un salto cualitativo en esta dirección. El proyecto, bautizado como DeepTravel, no es una aplicación más, sino una arquitectura fundamental, un esqueleto conceptual para construir la próxima generación de planificadores de viajes autónomos. Lo que proponen es un cambio de paradigma: pasar de las inteligencias artificiales que siguen guiones predefinidos a sistemas que aprenden, se adaptan y resuelven problemas de forma creativa. Para lograrlo, se adentran en un territorio fascinante conocido como aprendizaje por refuerzo, una técnica que imita una de las formas más primarias y poderosas de aprendizaje humano y animal: el ensayo y el error.
Para entender la magnitud de esta propuesta, es necesario familiarizarse con algunos de sus conceptos clave, que los investigadores han ensamblado con la precisión de un relojero. El primero es la idea de un «agente». En este contexto, un agente no es un simple programa informático; es una entidad digital activa, dotada de la capacidad de percibir su entorno, tomar decisiones y ejecutar acciones para alcanzar un objetivo. Así como un agente de viajes humano utiliza herramientas como el teléfono, el correo electrónico y los sistemas de reserva, el agente de DeepTravel utiliza herramientas digitales, conectándose a diferentes servicios en línea para recabar información y ejecutar tareas.
El segundo concepto es el motor que impulsa a este agente: el aprendizaje por refuerzo. En lugar de ser programado con instrucciones explícitas para cada posible escenario, el agente aprende de la experiencia. Es como un niño que aprende a construir una torre con bloques. Si apila los bloques de forma inestable y la torre se derrumba, recibe una retroalimentación negativa (la frustración del fracaso) y ajusta su estrategia. Si consigue construir una torre alta y estable, recibe una retroalimentación positiva (la satisfacción del éxito) y refuerza esa técnica.
El agente de DeepTravel funciona de manera análoga: intenta crear un plan de viaje (una acción) y un sistema interno lo evalúa, asignándole una «recompensa» si el plan es lógico y factible, o una «penalización» si contiene errores, como reservar un tren que llega después de la hora de cierre del hotel. A través de millones de estos ciclos de prueba y corrección, el agente desarrolla una intuición, una profunda comprensión de lo que constituye un buen plan de viaje.
Pero, ¿dónde puede un sistema de inteligencia artificial practicar la planificación de millones de viajes sin causar un caos de reservas falsas en el mundo real o depender de sitios web que cambian constantemente? Aquí entra en juego el tercer pilar del proyecto: la construcción de un «sandbox» o entorno de pruebas. Los investigadores crearon una réplica digital del mundo de los viajes, un universo controlado y autocontenido. Recopilaron y almacenaron ingentes cantidades de datos reales sobre vuelos, trenes, hoteles y puntos de interés, creando un campo de entrenamiento seguro, estable y ultrarrápido. En este laboratorio virtual, el agente puede experimentar libremente, cometer errores y aprender de ellos a una velocidad inalcanzable para un humano, sin las limitaciones y la inconsistencia de las plataformas en línea del mundo real.
Finalmente, para que el aprendizaje sea eficaz, la retroalimentación debe ser precisa y matizada. DeepTravel introduce un sofisticado sistema de recompensa jerárquico, que actúa como un dúo de mentores para el agente. Por un lado, un «verificador de trayectoria» actúa como un supervisor estratégico, evaluando la coherencia general de todo el itinerario. Este supervisor se hace preguntas de alto nivel: ¿Tiene el viajero tiempo suficiente para ir del aeropuerto a la estación de tren? ¿Son lógicos los desplazamientos entre las ciudades visitadas? ¿Se solapan las actividades? Por otro lado, un «refinador de pasos» funciona como un tutor táctico, proporcionando retroalimentación inmediata sobre cada acción individual que toma el agente.
¿Fue una buena idea buscar hoteles antes de haber definido las fechas del viaje? ¿Es eficiente consultar primero los trenes de alta velocidad para un trayecto largo? Este sistema de doble capa garantiza que el agente no solo aprenda a evitar errores garrafales, sino que también refine sus estrategias para volverse cada vez más eficiente e inteligente. DeepTravel, por tanto, no es solo un avance en la tecnología de viajes; es una ventana a un futuro en el que la inteligencia artificial se convierte en una colaboradora proactiva y razonadora, capaz de gestionar la complejidad del mundo real para simplificar nuestras vidas.

El amanecer de los planificadores autónomos
La tecnología de asistencia por inteligencia artificial, especialmente en el ámbito de los servicios al consumidor, ha estado dominada durante mucho tiempo por sistemas que, a pesar de su aparente sofisticación, operan sobre raíles conceptuales muy rígidos. Los chatbots que nos saludan en las páginas web de las aerolíneas o los asistentes de voz de nuestros teléfonos son maestros en el arte de la imitación conversacional, pero su inteligencia es a menudo superficial. Su capacidad para ayudar se deriva de lo que en la jerga técnica se conoce como «flujos de trabajo fijos» y «prompts artesanales».
Un flujo de trabajo fijo es esencialmente un guion, un árbol de decisiones preprogramado. Si el usuario pregunta A, el sistema responde B; si pregunta C, responde D. Funciona razonablemente bien para tareas sencillas y predecibles, pero se desmorona ante la ambigüedad, la complejidad o la simple necesidad de salirse del guion. Los prompts artesanales son las instrucciones cuidadosamente elaboradas por los desarrolladores para guiar a los grandes modelos de lenguaje (LLM) subyacentes, obligándolos a producir respuestas dentro de un marco muy estricto. El resultado es un asistente que se asemeja más a un empleado de un centro de llamadas leyendo un manual que a un verdadero experto capaz de improvisar y resolver problemas de forma creativa.
La planificación de un viaje es el antónimo de un problema sencillo y predecible. Es una tarea inherentemente dinámica y llena de restricciones entrelazadas. El presupuesto influye en la elección del alojamiento, que a su vez depende de la ubicación de los puntos de interés, cuya visita está supeditada a los horarios del transporte, que deben coordinarse con las fechas de los vuelos.
Cambiar una sola variable puede generar un efecto dominó que obligue a replantear todo el itinerario. Es un problema de optimización con múltiples objetivos: minimizar costes, maximizar el tiempo de disfrute, adaptarse a las preferencias personales y todo ello dentro de un marco de viabilidad logística. La rigidez de los sistemas actuales los hace fundamentalmente incapaces de abordar esta complejidad de manera holística. Pueden reservar un vuelo o encontrar un hotel, pero son incapaces de concebir el viaje como un todo unificado y coherente.
Aquí es donde el concepto de «inteligencia artificial agéntica» marca un punto de inflexión. Esta nueva visión propone una transición fundamental: de considerar a la IA como una herramienta pasiva que responde a órdenes, a verla como un colaborador activo que persigue objetivos. Un agente autónomo no espera instrucciones detalladas para cada paso. Se le presenta una meta general, como «planificar un viaje de una semana a Italia para dos personas centrado en la gastronomía y la historia», y el propio sistema es responsable de descomponer este objetivo en una secuencia de tareas ejecutables.
Debe inferir que necesita buscar vuelos a una ciudad principal como Roma o Florencia, investigar sobre regiones vinícolas, localizar hoteles con buenas reseñas culinarias, verificar los horarios de los trenes entre ciudades e incluso sugerir la reserva en restaurantes específicos. Este enfoque requiere que el sistema posea una forma de razonamiento y una capacidad de planificación estratégica que van mucho más allá del simple reconocimiento de patrones en el lenguaje. Es el salto de la competencia lingüística a la competencia cognitiva, una evolución crucial para que la inteligencia artificial pueda abordar problemas del mundo real de manera significativa y autónoma.

Aprendiendo a viajar: el motor del aprendizaje por refuerzo
El corazón palpitante de la innovación que propone DeepTravel es su decidida apuesta por el aprendizaje por refuerzo (RL, por sus siglas en inglés). Esta rama del aprendizaje automático se diferencia profundamente de otros enfoques más convencionales, como el aprendizaje supervisado, donde un sistema aprende a base de estudiar miles de ejemplos etiquetados por humanos. El RL es más audaz, más exploratorio; se inspira directamente en la psicología conductista. El sistema aprende actuando en un entorno para conseguir un objetivo, recibiendo recompensas por las acciones que lo acercan a esa meta y penalizaciones por las que lo alejan. Es un proceso de descubrimiento autónomo, un refinamiento constante a través de la experiencia directa.
Para ilustrar este concepto, podemos imaginar a un cocinero que quiere perfeccionar una receta. Un enfoque de aprendizaje supervisado consistiría en darle miles de recetas exitosas escritas por otros chefs para que aprenda a imitar los patrones. Un enfoque de aprendizaje por refuerzo, en cambio, sería ponerlo en una cocina con todos los ingredientes y un objetivo claro: crear el plato más delicioso posible. El cocinero empezaría a experimentar. Probaría a añadir una pizca más de una especia (una acción), probaría el resultado (observaría el entorno) y decidiría si el sabor ha mejorado (una recompensa) o empeorado (una penalización). Repetiría este proceso incansablemente, ajustando cantidades, cambiando técnicas de cocción, alterando el orden de los ingredientes. Con el tiempo, no solo aprendería a replicar una receta existente, sino que desarrollaría una intuición culinaria profunda, una comprensión de la interacción entre los sabores que le permitiría innovar y crear platos completamente nuevos y sorprendentes.
El agente de DeepTravel es ese cocinero, y su cocina es el complejo mundo de la planificación de viajes. Su objetivo no es imitar itinerarios existentes, sino descubrir las mejores soluciones posibles para las necesidades de un usuario. Las «acciones» que puede realizar son variadas: buscar un vuelo con ciertos parámetros, consultar la disponibilidad de un tipo de habitación de hotel, preguntar por el horario de un museo o trazar una ruta entre dos puntos de la ciudad.
El «entorno» es su sandbox, que le devuelve los resultados de estas acciones. Y el «sistema de recompensa» es el crítico gastronómico que prueba cada una de sus creaciones. Un itinerario que incluye un vuelo que aterriza a las 23:00 y un tren hacia otra ciudad que parte a las 23:15 recibe una fuerte penalización por ser logísticamente inviable. Un plan que encuentra un hotel más barato pero igualmente bien valorado y más cerca de una estación de metro recibe una recompensa.
La belleza de este enfoque es que libera al sistema de las limitaciones del conocimiento humano preexistente. Un programador no podría prever y codificar manualmente todas las estrategias óptimas para la infinidad de posibles solicitudes de viaje. Sin embargo, a través del aprendizaje por refuerzo, el agente puede descubrir tácticas y combinaciones que a un humano quizás no se le ocurrirían.
Podría, por ejemplo, descubrir que para un determinado trayecto es más rápido y barato coger un tren a una ciudad cercana y desde allí un autobús regional, en lugar del vuelo directo más obvio. O podría aprender a secuenciar las visitas turísticas en una ciudad no por proximidad geográfica, sino por los tiempos de espera promedio en cada lugar según la hora del día, optimizando así el tiempo del viajero. Es un camino hacia una inteligencia artificial que no solo ejecuta, sino que también crea estrategias, una habilidad que hasta ahora había sido un dominio casi exclusivamente humano.
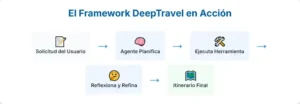
Construyendo un mundo de juguete: la importancia del «sandbox»
Uno de los aspectos más pragmáticos y a la vez más ingeniosos del proyecto DeepTravel es el reconocimiento de una verdad fundamental en el entrenamiento de la inteligencia artificial: la calidad del entorno de aprendizaje es tan importante como la brillantez del algoritmo. Entrenar un agente autónomo directamente en el internet real, interactuando con las interfaces de programación de aplicaciones (API) de aerolíneas, cadenas hoteleras y servicios de mapas, sería una empresa abocada al fracaso. El mundo digital real es un lugar desordenado, inconsistente y, a menudo, poco cooperativo.
Las API del mundo real presentan múltiples desafíos que actuarían como un ruido ensordecedor para un agente en pleno proceso de aprendizaje. Primero, la latencia: cada consulta a un servicio externo puede tardar varios segundos en recibir respuesta, lo que ralentizaría el entrenamiento de millones de iteraciones a un ritmo glacial, haciéndolo inviable. Segundo, la inestabilidad y la inconsistencia: las API cambian sus formatos de datos sin previo aviso, pueden sufrir caídas de servicio o devolver resultados erráticos o incompletos.
Un agente que recibe datos contradictorios no puede aprender patrones fiables. Tercero, las limitaciones de uso: la mayoría de los servicios imponen un límite al número de consultas que se pueden realizar en un período de tiempo determinado para evitar abusos. Un agente en entrenamiento, por su naturaleza, necesita realizar un volumen masivo de consultas, por lo que se toparía constantemente con estas barreras. Finalmente, está el coste: muchas API de alta calidad son servicios de pago, y el entrenamiento a gran escala tendría un coste prohibitivo.
La solución de los investigadores fue tan elegante como ambiciosa: si el mundo real es un mal maestro, construyamos uno mejor. Se embarcaron en la monumental tarea de crear un «sandbox», un entorno simulado de alta fidelidad. Este proceso implicó la recopilación y el almacenamiento en caché de una cantidad ingente de datos de viajes. Esencialmente, crearon una instantánea coherente y localizada de la infraestructura global de viajes. Este «mundo de juguete» contiene una vasta base de datos de vuelos, horarios de trenes, redes de autobuses, perfiles de hoteles con sus precios y disponibilidad, información sobre puntos de interés, incluyendo horarios de apertura y ubicación, y mucho más.
La creación de este entorno controlado transformó por completo las posibilidades de entrenamiento. Dentro del sandbox, el agente puede realizar millones de consultas en cuestión de minutos, en lugar de meses. Cada consulta recibe una respuesta instantánea y, lo que es más importante, consistente. El formato de los datos es siempre el mismo, eliminando la confusión y permitiendo al agente concentrarse en la tarea de aprender a planificar. No hay límites de uso ni costes por consulta.
En esta réplica perfecta y predecible, el agente tiene la libertad de explorar el espacio de soluciones de forma segura y eficiente. Puede probar las ideas más descabelladas, cometer los errores más absurdos y aprender de cada uno de ellos sin consecuencias en el mundo real. Este entorno de pruebas es el equivalente a un simulador de vuelo para un piloto. Antes de enfrentarse a las complejidades y los peligros de un vuelo real, el piloto pasa cientos de horas en el simulador, donde puede experimentar todo tipo de condiciones y emergencias en un entorno seguro.
De la misma manera, el sandbox de DeepTravel es el simulador donde el agente se convierte en un planificador experto antes de que se le confíe la tarea de organizar las vacaciones de un ser humano. Este trabajo de ingeniería de datos, aunque menos glamuroso que el diseño de algoritmos, es una pieza absolutamente indispensable del rompecabezas, una que demuestra que para alcanzar la inteligencia artificial, a menudo primero hay que construir un universo a su medida.
El crítico y el maestro: un sistema de recompensa jerárquico
Si el aprendizaje por refuerzo es el motor y el sandbox es la carretera, el sistema de recompensa es el GPS que guía al agente en su viaje de aprendizaje. Proporcionar la retroalimentación adecuada es un arte sutil; una recompensa demasiado simple puede llevar a comportamientos no deseados, mientras que una demasiado compleja puede confundir al agente. El equipo de DeepTravel diseñó una estructura de retroalimentación de dos niveles, una arquitectura de recompensa jerárquica que actúa simultáneamente como un estratega de alto nivel y un instructor de detalle, proporcionando una guía mucho más rica y efectiva que un simple sistema de puntuación monolítico.
El primer nivel de esta jerarquía es el «verificador de trayectoria». Su función es la de un editor de contenido que revisa el borrador completo de un plan de viaje para evaluar su coherencia y viabilidad general. Este componente no se preocupa por los detalles minuciosos de cada decisión, sino por la lógica global del itinerario. Su principal responsabilidad es la verificación espaciotemporal. Por ejemplo, si el agente propone un plan que incluye una visita a un museo en París por la mañana y una cena en Roma esa misma noche, el verificador de trayectoria identificaría inmediatamente esta imposibilidad física y asignaría una penalización muy alta a todo el itinerario.
Su análisis se centra en la película completa, no en los fotogramas individuales. Evalúa si los tiempos de viaje entre lugares son realistas, si las reservas de hotel se alinean con las fechas de estancia en una ciudad y si las actividades planificadas encajan dentro del marco de tiempo disponible. Esta perspectiva holística es crucial para evitar que el agente aprenda a optimizar partes aisladas del plan en detrimento de su coherencia general.
El segundo nivel es el «refinador de pasos», que opera con una lupa, analizando cada acción individual que el agente realiza. Este componente actúa como un tutor táctico que proporciona retroalimentación inmediata. Si el verificador de trayectoria es el editor, el refinador de pasos es el corrector de estilo que examina cada frase. Su objetivo es enseñar al agente no solo a producir un plan viable, sino a hacerlo de la manera más eficiente e inteligente posible. Por ejemplo, en las primeras etapas de su entrenamiento, el agente podría realizar acciones redundantes, como buscar repetidamente los mismos vuelos sin cambiar los parámetros. El refinador de pasos penalizaría este comportamiento ineficiente.
Del mismo modo, si el agente intenta reservar un hotel sin haber confirmado primero las fechas de los vuelos, el refinador le enseñaría que esa es una secuencia de acciones subóptima. A través de este mecanismo, el agente aprende las heurísticas y las mejores prácticas de la planificación. Aprende a priorizar, a secuenciar sus acciones lógicamente y a utilizar sus herramientas de la forma más eficaz.
Esta dualidad en el sistema de retroalimentación es lo que lo hace tan poderoso. El verificador de trayectoria proporciona la dirección estratégica a largo plazo, asegurando que el agente nunca pierda de vista el objetivo final de crear un plan coherente. El refinador de pasos ofrece la guía táctica a corto plazo, puliendo y optimizando el proceso para llegar a ese objetivo. Es una simbiosis perfecta entre un mentor que enseña los grandes principios y un instructor que corrige la técnica en cada movimiento.
Esta estructura permite un aprendizaje mucho más rápido y robusto, guiando al agente para que no solo evite los errores evidentes, sino que también desarrolle la elegancia y la eficiencia de un verdadero experto en la materia.
Más allá del itinerario: las implicaciones de DeepTravel
Aunque el dominio de aplicación inmediato de DeepTravel es la planificación de viajes, la verdadera importancia de este trabajo trasciende con creces la industria del turismo. La arquitectura conceptual que presenta, un agente autónomo que aprende a través del refuerzo en un entorno simulado y es guiado por un sistema de recompensa sofisticado, es una plantilla extraordinariamente versátil y potente para resolver una amplia gama de problemas complejos de planificación en múltiples sectores. Este proyecto no debe ser visto como la creación de una simple herramienta, sino como el desarrollo de una metodología fundamental para enseñar a las máquinas a razonar y a elaborar estrategias en escenarios del mundo real.
En el campo de la logística y la gestión de la cadena de suministro, por ejemplo, los desafíos son análogos a los de la planificación de viajes, pero a una escala mucho mayor. Optimizar las rutas de una flota de camiones, gestionar el inventario en múltiples almacenes y coordinar las entregas para minimizar los costes y los tiempos de espera es un problema de planificación combinatoria de una complejidad abrumadora. Un agente basado en los principios de DeepTravel podría entrenarse en un sandbox que simule la red logística de una empresa, aprendiendo a anticipar cuellos de botella, a reaccionar ante interrupciones inesperadas (como el mal tiempo o el tráfico) y a descubrir estrategias de enrutamiento y almacenamiento que superen la eficiencia de los métodos actuales.
De manera similar, en la planificación financiera personal, un agente podría ayudar a los usuarios a navegar por la complejidad de las decisiones de inversión, ahorro y jubilación. En un entorno simulado que modele los mercados financieros y las diferentes normativas fiscales, el agente podría aprender a construir carteras de inversión personalizadas, a optimizar las estrategias de ahorro a largo plazo y a adaptar los planes a los cambios en la vida del usuario, como un nuevo empleo o el nacimiento de un hijo. La aplicación de este paradigma se extiende a la gestión de proyectos, la planificación de la producción industrial e incluso a la investigación científica, donde un agente podría ayudar a diseñar secuencias de experimentos para probar una hipótesis de la manera más eficiente posible.
Desde una perspectiva social, la maduración de esta tecnología promete democratizar el acceso a una planificación experta y personalizada. En el contexto de los viajes, podría permitir a las personas con presupuestos ajustados disfrutar de experiencias ricas y bien organizadas que antes solo estaban al alcance de quienes podían permitirse un agente de viajes de lujo. Podría ayudar a los viajeros a descubrir destinos y experiencias fuera de los circuitos turísticos habituales, promoviendo un turismo más sostenible y distribuido.
Y, sobre todo, podría reducir significativamente la carga mental y el estrés asociados a la planificación, liberando nuestro tiempo y energía para que podamos centrarnos en la anticipación y el disfrute de la experiencia misma. Por supuesto, también plantea interrogantes sobre el futuro del trabajo de los agentes de viajes humanos, sugiriendo una evolución de su rol hacia la supervisión, la gestión de excepciones y la aportación del toque humano y la empatía que las máquinas aún no pueden replicar.
Científicamente, DeepTravel representa un paso importante en la larga búsqueda de una inteligencia artificial más general y autónoma. Se aleja del paradigma dominante de los grandes modelos de lenguaje, que se centran principalmente en la predicción de la siguiente palabra en una secuencia, y se adentra en el dominio del razonamiento orientado a objetivos y la acción con propósito.
Enseñar a una máquina a conversar es un logro impresionante, pero enseñarle a actuar de forma coherente en el mundo para alcanzar una meta es un desafío de un orden de magnitud superior. Este trabajo contribuye con una pieza clave a ese rompecabezas, demostrando un camino viable para construir sistemas que no solo procesan información, sino que la utilizan para tomar decisiones y resolver problemas prácticos.
El futuro de los viajes
El viaje que hemos emprendido a través de la arquitectura de DeepTravel nos lleva desde un problema universalmente reconocible, la frustrante complejidad de planificar un viaje, hasta la vanguardia de la investigación en inteligencia artificial. Hemos visto cómo la combinación de conceptos como los agentes autónomos, el aprendizaje a través de la experiencia y los entornos de simulación meticulosamente construidos está dando forma a una nueva generación de sistemas inteligentes. Estos sistemas prometen ir más allá de las respuestas enlatadas y los flujos de trabajo rígidos para ofrecernos una colaboración genuina, proactiva y razonada.
El logro fundamental de DeepTravel no es, por tanto, la creación de una aplicación de viajes definitiva, sino el establecimiento de un plan maestro, un marco de trabajo robusto y replicable para enseñar a las máquinas a abordar problemas de planificación multifacéticos. La verdadera innovación reside en su enfoque holístico: el reconocimiento de que para que una IA aprenda a resolver un problema complejo del mundo real, necesita un campo de entrenamiento seguro (el sandbox), un método de aprendizaje flexible (el aprendizaje por refuerzo) y un sistema de guía matizado (la recompensa jerárquica). Es esta sinergia de componentes lo que permite al agente trascender la simple ejecución de tareas para desarrollar una verdadera capacidad estratégica.
Aunque esta tecnología se encuentra todavía en sus fases de investigación y desarrollo, su trayectoria apunta hacia un futuro en el que los asistentes digitales se convertirán en auténticos copilotos en muchas facetas de nuestras vidas. Ya sea organizando nuestras finanzas, gestionando la logística de nuestros negocios o planificando nuestras próximas vacaciones, la inteligencia artificial agéntica tiene el potencial de absorber la complejidad para devolvernos simplicidad. DeepTravel, por tanto, es mucho más que una brújula más inteligente para nuestros viajes; es un hito significativo en la fascinante y continua expedición de la humanidad para crear una inteligencia que no solo refleje la nuestra, sino que la aumente, ayudándonos a navegar con mayor facilidad y sabiduría por el intrincado mapa de nuestro mundo.
Referencias
Ning, Y., Liu, R., Wang, J., Chen, K., Li, W., Fang, J., Zheng, K., Tan, N., & Liu, H. (2025). DEEPTRAVEL: AN END-TO-END AGENTIC RE-INFORCEMENT LEARNING FRAMEWORK FOR AU-TONOMOUS TRAVEL PLANNING AGENTS. arXiv:2509.21842 [cs.AI].

