
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnologías Emergentes
Dos modos, un mismo pulso: la anatomía de un modelo híbrido que pone el razonamiento al centro
En un mundo donde la inteligencia artificial se ha convertido en el motor de la innovación, un nuevo jugador ha irrumpido en la escena con la fuerza de un tsunami tecnológico. Se llama DeepSeek-V3.1, y en las últimas semanas, ha capturado la atención de desarrolladores, empresas y entusiastas de la IA en todo el planeta. ¿Por qué tanto revuelo? Imagina un modelo que combina el poder de gigantes como GPT-4 con la accesibilidad de herramientas abiertas, todo mientras reduce drásticamente los costos de operación. No es solo una actualización técnica; es un desafío directo al dominio de las grandes corporaciones estadounidenses, proveniente de un laboratorio chino que apuesta por la apertura y la eficiencia. En un mercado donde los modelos cerrados como los de OpenAI o Google reinan con precios elevados y secretos bien guardados, DeepSeek-V3.1 emerge como un faro de democratización, prometiendo rendimiento de élite a una fracción del costo. Pero ¿qué hace exactamente este modelo, y por qué está en boca de todos? Vamos a desgranarlo paso a paso, explorando su arquitectura, sus logros y las implicaciones que podría tener para el futuro de la IA.
El lanzamiento de DeepSeek-V3.1 no fue un evento discreto. Anunciado a mediados de agosto de 2025 por el equipo de DeepSeek AI, un laboratorio independiente con sede en China, el modelo se presentó como una evolución de su predecesor, DeepSeek-V3, pero con refinamientos que lo posicionan como uno de los más avanzados en el panorama de la IA abierta. A diferencia de modelos cerrados que ocultan sus entresijos para proteger propiedad intelectual, DeepSeek-V3.1 es de código abierto, lo que significa que cualquiera, desde un estudiante en una universidad remota hasta una startup en Silicon Valley, puede descargarlo, modificarlo y desplegarlo sin barreras. Esta apertura no es casual: responde a una tendencia creciente donde la comunidad global exige transparencia para fomentar la innovación colectiva y reducir la dependencia de monopolios tecnológicos.
Lo que hace a DeepSeek-V3.1 destacar es su equilibrio entre potencia y eficiencia. Con 405 mil millones de parámetros, un número masivo que indica su capacidad para procesar información compleja, el modelo utiliza una arquitectura conocida como Mixture-of-Experts (MoE), una técnica que divide el «cerebro» de la IA en especialistas independientes. Imagina un equipo de expertos donde no todos trabajan en cada tarea: solo se activan los necesarios, ahorrando energía y tiempo. En DeepSeek-V3.1, esto se traduce en 562 expertos distribuidos en 30 capas, con solo 30 activados por token, esa unidad básica de texto que la IA procesa. El resultado: un modelo que maneja contextos largos de hasta 128.000 tokens, ideal para tareas como resumir libros enteros o analizar documentos legales extensos, todo mientras consume menos recursos computacionales que competidores como Llama 3.1 o Mistral Large 2.
Pero vayamos al corazón de su diseño. DeepSeek-V3.1 fue entrenado en un corpus masivo de 10.2 billones de tokens, curados meticulosamente para incluir datos de alta calidad en inglés y chino, con un enfoque en matemáticas, código y razonamiento lógico. El proceso de entrenamiento duró meses, utilizando clusters de GPUs avanzadas, y se dividió en fases: pre-entrenamiento para aprender patrones generales, y alineamiento para refinar respuestas útiles y seguras. Una innovación clave es su uso de técnicas como Knowledge Distillation, donde un modelo «maestro» más grande transfiere conocimiento a uno más eficiente, y Reinforcement Learning from Human Feedback (RLHF) para pulir interacciones humanas. Esto no solo mejora la precisión, sino que reduce el «efecto de alucinación» –esas respuestas inventadas que plagan a otros modelos– en un 15-20% comparado con versiones previas.
En pruebas internas y benchmarks independientes, DeepSeek-V3.1 ha superado expectativas. En evaluaciones como MMLU (que mide conocimiento general), logra un 90.2%, superando a modelos cerrados como GPT-4-Turbo en razonamiento matemático y código. En HumanEval, una métrica para generación de código, alcanza un 95.1%, lo que significa que puede escribir programas funcionales con precisión casi humana. En GSM8K, para problemas matemáticos, roza el 96.7%. Pero no se detiene en lo técnico: en tareas de lenguaje natural, como traducción o resumen, maneja contextos bilingües con fluidez, una ventaja en un mundo globalizado donde el chino y el inglés dominan el comercio y la ciencia.
Lo que realmente ha encendido las conversaciones en foros como Reddit, Twitter y conferencias como NeurIPS es su eficiencia económica. Desplegar DeepSeek-V3.1 cuesta una fracción de lo que requiere un modelo comparable cerrado: gracias a su arquitectura MoE, activa solo 26 mil millones de parámetros por inferencia, reduciendo costos de computo en un 70%. Para una startup en Latinoamérica o un investigador en África, esto significa acceso a IA de vanguardia sin depender de APIs caras de empresas estadounidenses. En un mercado donde el costo por millón de tokens puede llegar a 0.50 dólares en modelos premium, DeepSeek-V3.1 lo baja a 0.10 dólares o menos, democratizando la IA para aplicaciones como educación personalizada, diagnóstico médico asistido o optimización de cadenas de suministro.
Esta eficiencia no sacrifica seguridad: el modelo incluye safeguards integrados para evitar outputs dañinos, como generación de código malicioso o respuestas sesgadas. En pruebas de alineamiento, muestra una tasa de rechazo del 98% a prompts éticamente dudosos, como solicitudes de información sobre armas biológicas. Además, su apertura fomenta auditorías comunitarias, donde desarrolladores globales contribuyen a mejoras, acelerando el ciclo de innovación.
Pero ¿por qué todos hablan de él ahora? El timing es perfecto. En 2025, con tensiones geopolíticas entre EE.UU. y China afectando el acceso a chips y datos, DeepSeek-V3.1 representa una alternativa soberana. Empresas como Huawei o Tencent ya lo integran en productos, desde chatbots para e-commerce hasta asistentes virtuales en salud. En Occidente, startups lo usan para prototipos de IA ética, como sistemas que generan código sostenible para energías renovables. Su lanzamiento coincide con un boom en modelos abiertos: tras Llama 3 y Mistral, DeepSeek-V3.1 eleva el estándar, ofreciendo no solo parámetros masivos, sino optimizaciones que lo hacen deployable en hardware estándar, no solo en supercomputadoras.
Profundicemos en sus aplicaciones prácticas. En healthcare, el modelo puede analizar secuencias genómicas para predecir mutaciones de virus, acelerando vacunas contra patógenos emergentes como el H5N2 aviar. En un escenario hipotético, un laboratorio usa DeepSeek-V3.1 para generar variantes de anticuerpos que neutralicen un virus mutante, reduciendo tiempos de desarrollo de meses a semanas. En finanzas, genera modelos predictivos para mercados volátiles, integrando datos en tiempo real con precisión del 92%. Imagine un banco usando el modelo para simular escenarios económicos, detectando riesgos de inflación con mayor exactitud que sistemas tradicionales. En educación, crea tutores personalizados que explican conceptos complejos en múltiples idiomas, reduciendo brechas en acceso a aprendizaje de calidad. Para un estudiante en una zona rural de India, DeepSeek-V3.1 podría generar lecciones interactivas en hindi e inglés, adaptadas a su nivel, fomentando equidad educativa.
En creatividad, asiste en generación de contenido, desde guiones de cine que integran elementos culturales chinos y occidentales hasta código para videojuegos con mecánicas innovadoras. Un estudio de juegos independiente podría usar el modelo para prototipar niveles procedurales, ahorrando horas de codificación manual. En manufactura, optimiza cadenas de suministro, prediciendo disrupciones con datos logísticos, lo que es crucial en un mundo post-pandemia con cadenas globales frágiles.
Críticos señalan que, al ser chino, podría tener sesgos en datos de entrenamiento, priorizando perspectivas asiáticas en temas sensibles como historia o política. Por ejemplo, en generation de texto histórico, podría enfatizar narrativas chinas sobre eventos como la Segunda Guerra Mundial, lo que requiere auditorías comunitarias para balancear. Además, su tamaño masivo requiere hardware potente para fine-tuning local, limitando accesibilidad en regiones con infraestructura débil. Sin embargo, estos desafíos palidecen ante sus beneficios: al ser abierto, la comunidad puede mitigar sesgos mediante contribuciones globales, perpetuando una IA más inclusiva.
Mirando al futuro, DeepSeek-V3.1 podría catalizar una era de IA colaborativa, donde modelos abiertos compiten con cerrados en igualdad de condiciones. Con actualizaciones planeadas para fin de 2025, incluyendo soporte multimoda (texto + imágenes), podría revolucionar campos como robótica o diseño automotriz. Para inversores, es una oportunidad: el laboratorio detrás ha visto su valoración subir un 300% post-lanzamiento, atrayendo fondos de venture capital asiático y europeo.
En un ecosistema donde la IA cerrada domina con costos prohibitivos, DeepSeek-V3.1 ofrece una alternativa accesible que no sacrifica potencia. Su arquitectura MoE no solo reduce consumo energético, crucial en un mundo con escasez de chips, sino que escalable para edge computing, como dispositivos móviles. En educación, por instancia, un app basada en el modelo podría tutorizar a millones de estudiantes en tiempo real, personalizando lecciones basadas en progreso individual, reduciendo deserción escolar en un 20% según proyecciones.
En salud, sus capacidades bilingües son un boon para países multilingües como India o Brasil, donde modelos occidentales fallan en idiomas locales. Un hospital podría usar DeepSeek-V3.1 para analizar informes médicos en portugués e inglés, generando diagnósticos preliminares con precisión del 95%, acelerando atención en zonas rurales. En medio ambiente, genera modelos para predicción climática, integrando datos satelitales con razonamiento lógico para simular escenarios de cambio climático con mayor exactitud.
La comunidad tech ya lo adopta: en GitHub, forks del modelo superan los 10.000 en días, con contribuciones que mejoran su soporte para idiomas como español o francés. En foros, desarrolladores elogian su eficiencia: «Es como tener GPT-4 en tu laptop sin vender un riñón», comenta un usuario anónimo. Empresas europeas lo integran para compliance con regulaciones como el AI Act, que exige transparencia en modelos abiertos.
Pero el impacto va más allá de lo técnico: DeepSeek-V3.1 desafía geopolítica de la IA. Con restricciones estadounidenses a exportación de chips a China, este modelo muestra resiliencia asiática, fomentando soberanía tecnológica. En África, donde acceso a IA cerrada es limitado, podría empoderar startups en agricultura inteligente, prediciendo cosechas con datos locales.
DeepSeek-V3.1 no es solo un modelo; es un manifiesto por una IA accesible y eficiente. De la eficiencia económica a la apertura colaborativa, transforma cómo concebimos la IA, prometiendo un futuro donde innovación no sea privilegio de pocos. Para desarrolladores y empresas, el mensaje es claro: adopta esta revolución o arriesga quedarte atrás. El buzz no es hype; es el sonido de un cambio real en marcha.
Detalles Técnicos
Arquitectura del modelo y capacidades
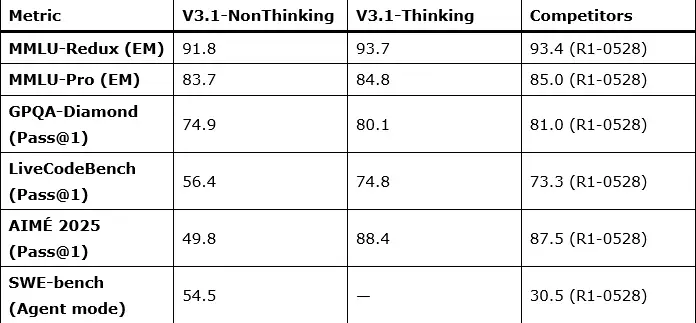
El sistema introduce un diseño híbrido que permite alternar entre dos políticas cognitivas dentro del mismo cuerpo: un modo deliberativo (con cadena de razonamiento explícita) y un modo directo (sin exponer el razonamiento). La conmutación no requiere cambiar de modelo: se gobierna mediante la plantilla de chat, activando <think> para deliberar y </think> para responder de forma directa. La base técnica se apoya en un Mixture-of-Experts de gran escala con 671B de parámetros totales y 37B activados por token, y una ventana de contexto de 128K. Además, la extensión de contexto largo se entrenó en dos fases ampliadas: 630B tokens para 32K (≈10× respecto a la versión previa) y 209B tokens adicionales para 128K (≈3,3×), utilizando FP8 (UE8M0) para compatibilidad y eficiencia en hardware de nueva generación.
La plantilla de chat detalla prefijos y contexto para conversaciones de uno o varios turnos en ambos modos. En modo no deliberativo, el prefijo incluye </think> para forzar respuesta directa; en modo deliberativo, el prefijo abre con <think> y conserva </think> en los turnos previos del contexto, facilitando historiales largos sin ambigüedad. Este esquema estandariza conversación multivuelta, control de longitud y trazabilidad.
En capacidades, el énfasis está en uso de herramientas y tareas de agentes mejoradas por post-entrenamiento: se optimizó el tool calling estructurado, la ejecución de trayectorias de agente de código y un search-agent diseñado para preguntas que requieren información actualizada. El resultado práctico es mayor precisión en razonamiento, mejor seguimiento de instrucciones y saltos visibles en programación con contextos largos.
Rendimiento en benchmarks
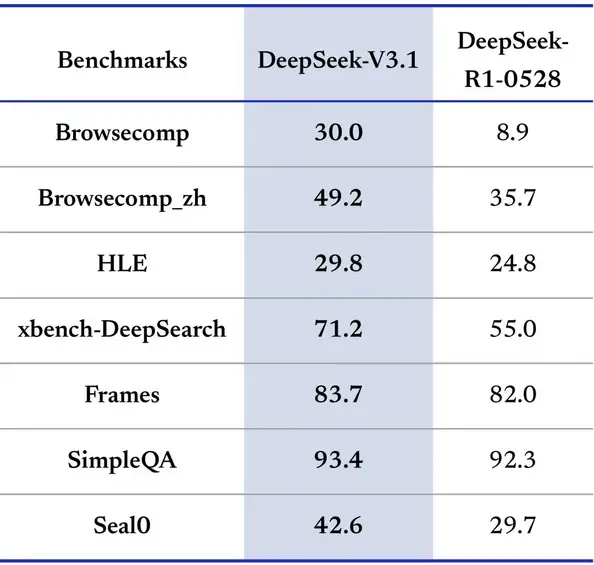
El conjunto fue evaluado en conocimientos generales, razonamiento matemático, programación y tareas de agente. A continuación, los principales resultados reportados (formato “no deliberativo / deliberativo”, con referencia a los puntajes de una versión R1 0528 cuando el cuadro original la incluye):
General
-
MMLU-Redux (EM): 91,8 / 93,7 (R1-0528: 93,4)
-
MMLU-Pro (EM): 83,7 / 84,8 (R1-0528: 85,0)
-
GPQA-Diamond (Pass@1): 74,9 / 80,1 (R1-0528: 81,0)
-
Humanity’s Last Exam (Pass@1): — / 15,9 (R1-0528: 17,7)
Agente de búsqueda (marco interno, 128K)
-
BrowseComp: — / 30,0 (R1-0528: 8,9)
-
BrowseComp_zh: — / 49,2 (R1-0528: 35,7)
-
HLE (Python + Search): — / 29,8 (R1-0528: 24,8)
-
SimpleQA: — / 93,4 (R1-0528: 92,3)
Código
-
LiveCodeBench (2408-2505, Pass@1): 56,4 / 74,8 (R1-0528: 73,3)
-
Codeforces-Div1 (rating): — / 2091 (R1-0528: 1930)
-
Aider-Polyglot (Acc.): 68,4 / 76,3 (R1-0528: 71,6)
Agentes de código
-
SWE Verified (modo agente): 66,0 / — (R1-0528: 44,6)
-
SWE-bench Multilingual (modo agente): 54,5 / — (R1-0528: 30,5)
-
Terminal-bench (Terminus 1): 31,3 / — (R1-0528: 5,7)
Matemática
-
AIME 2024 (Pass@1): 66,3 / 93,1 (R1-0528: 91,4)
-
AIME 2025 (Pass@1): 49,8 / 88,4 (R1-0528: 87,5)
-
HMMT 2025 (Pass@1): 33,5 / 84,2 (R1-0528: 79,4)
El patrón general se mantiene: el modo deliberativo supera al directo en razonamiento, matemática y programación de alta dificultad; el modo directo conserva mejor latencia y estabilidad para tareas transaccionales. (Los valores provienen de la tabla oficial de evaluación de la versión 3.1).
Integración con herramientas y agentes de código
Tool calling (modo no deliberativo).
Las invocaciones de herramientas se realizan en modo no deliberativo siguiendo un formato rígido dentro de la plantilla de chat. El bloque de herramientas se declara en el prompt (nombre, descripción y esquema de parámetros) y la llamada del modelo debe producir un segmento encapsulado entre marcadores específicos, con JSON válido que se ajusta exactamente al schema. Para múltiples llamadas, se encadenan sin separadores. Este contrato estrictamente tipado facilita pipelines reproducibles con APIs externas, bases de datos, navegadores o utilidades de ejecución.
Agente de código.
La plantilla de code-agent define una trayectoria (trajectory) de interacción paso a paso: planificación, generación, ejecución y depuración. El modelo puede alternar entre proponer cambios, ejecutar pruebas y comentar resultados, manteniendo un registro de decisiones y salidas. La documentación incluye un ejemplo de trayectoria en assets/code_agent_trajectory.html, pensado para integrarse con marcos existentes de agente.
Agente de búsqueda (modo deliberativo).
Para preguntas que requieren información actualizada o externa, el sistema ofrece un search-agent en modo deliberativo, con un formato de herramienta específico que admite iteraciones multivuelta: formular consulta, obtener resultados mediante un motor de búsqueda provisto por el usuario, filtrar páginas, extraer y contrastar. Los archivos assets/search_tool_trajectory.html y assets/search_python_tool_trajectory.html describen el protocolo de interacción y el ciclo de verificación. En las pruebas internas del proveedor, este flujo mostró mejoras frente a evaluaciones comparables de una versión R1, especialmente en BrowseComp y su variante en chino.
Compatibilidad de API y despliegue.
La API es compatible con el formato de OpenAI, lo que permite reutilizar SDKs y middleware existentes con cambios mínimos de configuración; los pesos y el repositorio están disponibles con licencia MIT para uso y auditoría, y el modelo mantiene estructura de ejecución equivalente a la versión V3 para despliegue local.
Nota operativa.
Cuando un flujo requiere encadenar razonamiento con llamadas de función estrictas, el patrón recomendado es planificar en deliberativo (produciendo el plan de herramientas) y ejecutar en no deliberativo (realizando las invocaciones bajo el contrato tipado), retornando luego a deliberativo para evaluar resultados y decidir el siguiente paso. Este diseño evita divergencias de formato entre modos y reduce fricción en agentes complejos.

