
Un documento de mil palabras cabe en cien tokens visuales. La propuesta desafía décadas de ortodoxia en procesamiento de lenguaje natural: en lugar de convertir imágenes en texto para alimentar modelos lingüísticos, DeepSeek invierte la lógica y comprime texto en representaciones visuales ultracompactas. El resultado es un sistema de reconocimiento óptico de caracteres que procesa más de 200.000 páginas diarias en una sola GPU, manteniendo 97 por ciento de precisión mientras reduce consumo computacional en veinte veces.
La innovación, presentada por DeepSeek bajo licencia MIT y disponible como código abierto, replantea preguntas fundamentales sobre cómo las máquinas procesan información documental. Durante años, investigadores asumieron que transformar píxeles en caracteres era el camino inevitable hacia la comprensión de documentos. DeepSeek-OCR demuestra que mantener representaciones visuales comprimidas puede ser más eficiente que descomponer cada letra en tokens textuales discretos.
El sistema implementa lo que sus creadores denominan «Compresión Óptica de Contextos», un paradigma donde la visión funciona como medio de compresión de alta fidelidad. Bajo el capó operan dos componentes principales: DeepEncoder maneja procesamiento de imágenes con 380 millones de parámetros, mientras un decodificador basado en DeepSeek-3B-MoE con 570 millones de parámetros activos genera texto estructurado.
La innovación reside en cómo DeepEncoder fusiona modelos complementarios. Integra SAM de Meta, un sistema de 80 millones de parámetros especializado en segmentación de imágenes, con CLIP de OpenAI, modelo de 300 millones de parámetros que vincula representaciones visuales y textuales. Entre ambos, un compresor reduce tokens en factor de 16. Una imagen de 1.024 por 1.024 píxeles genera inicialmente 4.096 tokens. SAM los procesa con huella de memoria contenida, el compresor los reduce a 256 tokens que CLIP finalmente interpreta para reconstrucción textual.
Esta cadena de procesamiento permite configuraciones adaptativas según complejidad documental. Presentaciones simples requieren apenas 64 tokens visuales. Libros y reportes estándar consumen alrededor de 100. Documentos complejos con tablas densas y diagramas multinivel demandan hasta 400 tokens en modo de máxima resolución. El sistema denomina «modo Gundam» a configuraciones extremas que asignan hasta 800 tokens para periódicos con layouts intrincados o papers académicos repletos de fórmulas matemáticas y ecuaciones químicas.
Los investigadores validaron eficiencia mediante experimentos de compresión agresiva. Con ratio de compresión 10 veces, el modelo mantiene 97 por ciento de precisión en reconocimiento de caracteres. Incluso forzando compresión hasta 20 veces, retiene aproximadamente 60 por ciento de exactitud, suficiente para ciertos casos de uso como indexación de archivos históricos o sistemas de memoria de largo plazo en conversaciones extendidas.
Características del Modelo
| Categoría | Especificación | Detalle/Beneficio |
|---|---|---|
| Arquitectura | Modelo 3B parámetros | DeepEncoder (380M) + DeepSeek3B-MoE (570M activos) |
| Compresión | Ratio 10x-20x | 97% precisión a 10x / 60% precisión a 20x |
| Eficiencia de tokens | 64-400 tokens/página | Tiny: 64 / Small: 100 / Base: 256 / Large: 400 / Gundam: 800 |
| Rendimiento | 200,000+ páginas/día | En GPU A100-40G individual |
| Velocidad inferencia | ~2,500 tokens/segundo | En hardware A100-40G estándar |
| Escalabilidad | 33M páginas/día | Con 20 servidores × 8 A100 cada uno |
| Benchmarks | Superior a competidores | vs GOT-OCR 2.0: 100 tokens vs 256 tokens vs MinerU 2.0: <800 tokens vs >6,000 tokens |
| Soporte multilingüe | ~100 idiomas | Sin cambio manual de configuración |
| Formatos salida | Markdown estructurado | Preserva tablas, fórmulas LaTeX, jerarquías |
| Componentes visuales | SAM + CLIP + Compresor | SAM (80M) + CLIP (300M) + Compresor 16x |
| Requisitos mínimos | 8GB VRAM | RTX 3070 / RTX 4060 Ti (5-10 pág/min) |
| Configuración recomendada | 16GB+ VRAM | RTX 4090 / A100-40G (100-200 pág/min) |
| Stack tecnológico | CUDA 11.8+ | PyTorch 2.6.0 + Transformers 4.46+ Flash Attention 2.7.3 + vLLM 0.8.5+ |
| Licencia | MIT License | Uso comercial sin restricciones |
| Disponibilidad | Código abierto completo | GitHub + Hugging Face (pesos del modelo) |
| Costo operativo estimado | ~$0.001/página | En GPUs cloud (vs $0.01-0.05 APIs comerciales) |
| Tipos documentales | Cobertura amplia | Papers, contratos, facturas, gráficos financieros Manuscritos, documentación técnica, reportes |
| Capacidades especiales | Parsing profundo | Convierte gráficos a tablas Markdown Reconoce fórmulas LaTeX y ecuaciones químicas |
| Modos de procesamiento | Configuraciones adaptativas | Ajuste dinámico según complejidad documental |
| Integración | vLLM optimizado | Soporte nativo para aceleración de inferencia |
| Aplicación innovadora | Visual decay para memoria | Compresión progresiva de historiales conversacionales |
Dominando benchmarks con menos recursos
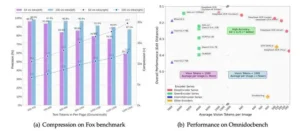
En pruebas sobre OmniDocBench, un conjunto de datos que abarca 1.355 páginas PDF distribuidas en nueve tipos documentales, cuatro categorías de layout y tres idiomas, DeepSeek-OCR superó a competidores establecidos con eficiencia notable. GOT-OCR 2.0 requiere 256 tokens visuales por página; DeepSeek alcanza resultados superiores con solo 100 tokens. MinerU 2.0 consume más de 6.000 tokens por página; DeepSeek logra métricas comparables con menos de 800 tokens, representando mejora de eficiencia superior a siete veces.
El benchmark incluye anotaciones ricas: 15 categorías a nivel de bloque como párrafos, encabezados y tablas, más cuatro anotaciones a nivel de span como líneas de texto, fórmulas inline y subíndices. Esta granularidad permite evaluación detallada de capacidades de parsing estructural, área donde modelos tradicionales fallan al perder alineación de columnas en tablas complejas o malinterpretar jerarquías de encabezados.
La arquitectura MoE del decodificador contribuye significativamente a eficiencia operacional. Aunque el modelo posee tres mil millones de parámetros totales, activa dinámicamente solo aquellos expertos necesarios para cada tarea específica, resultando en costo computacional efectivo de 570 millones de parámetros durante inferencia. Esta activación selectiva permite escalar capacidad sin penalizar latencia proporcionalmente.
Equipos de desarrollo reportan velocidades de inferencia cercanas a 2.500 tokens por segundo en GPU A100 de 40GB. Escalando a 20 servidores equipados con ocho A100 cada uno, throughput teórico alcanza 33 millones de páginas diarias. Estas cifras no son proyecciones académicas; empresas que procesan archivos masivos para construcción de datasets de entrenamiento confirman rendimientos similares en ambientes productivos.
Aplicaciones prácticas más allá del OCR convencional
El sistema no se limita a leer caracteres. Conserva la estructura semántica durante la conversión y habilita usos mucho más ambiciosos. En finanzas, por ejemplo, transforma gráficos complejos en tablas Markdown bien formadas y extrae series temporales directamente desde las visualizaciones, sin trabajo manual. En salud y en el ámbito jurídico, donde el volumen documental intimida, ya se están probando flujos que convierten historiales clínicos y expedientes extensos a formatos consultables mediante búsqueda semántica.
En el mundo académico la utilidad es inmediata. Procesa papers de cien páginas con notación matemática, fórmulas químicas y diagramas estructurales en unos dos minutos sobre hardware estándar, y mantiene las expresiones en LaTeX con una precisión cercana al 95 por ciento. Esa fidelidad recorta de raíz la revisión extenuante que antes demandaba horas de especialistas.
Su soporte nativo para alrededor de cien idiomas desactiva obstáculos clásicos. Puede manejar contratos que combinan inglés, chino y japonés, conservando términos técnicos en su lengua original, sin que el usuario deba configurar la detección de idioma. El modelo de visión y lenguaje entiende el contexto a través de fronteras idiomáticas y sostiene la exactitud incluso cuando los términos alternan entre alfabeto latino, caracteres chinos y silabarios japoneses.
Los autores sugieren además una aplicación sugestiva: compresión de historiales conversacionales en asistentes. Los intercambios antiguos podrían archivarse a resolución reducida, de forma análoga a cómo la memoria humana atenúa detalles con el paso del tiempo. Así entrarían contextos de miles de turnos en presupuestos de memoria razonables, lo que permitiría continuidad temporal prolongada sin que los costos computacionales crezcan de manera lineal.
La adopción productiva no es trivial. El stack pide CUDA 11.8 o superior, PyTorch 2.6.0, Transformers 4.46 en adelante y Flash Attention 2.7.3. Configurar dependencias en entornos heterogéneos introduce fricciones que frenan a equipos sin experiencia en operaciones de aprendizaje automático. La documentación asume familiaridad con visión computacional y arquitecturas transformer, lo que eleva la barrera de entrada para desarrolladores generalistas.
Los requisitos de hardware marcan el límite económico. Con 8 GB de VRAM se obtiene una inferencia básica a cinco o diez páginas por minuto, claramente insuficiente para pipelines de producción. Configuraciones con 16 GB o más en GPUs como RTX 4090 o A100 alcanzan entre 100 y 200 páginas por minuto, adecuadas para cargas empresariales medias. A gran escala se requieren clústeres multi-GPU y coordinación cuidadosa.
Las alternativas comerciales simplifican con APIs gestionadas y sin infraestructura propia, aunque el costo acumulado puede superar pronto la inversión en hardware. Las comparativas sitúan el costo en torno a 0.001 dólares por página en GPU en la nube, frente a 0.01 a 0.05 dólares en OCR tradicional. El punto de equilibrio depende del volumen mensual y de la capacidad técnica para operar pipelines autoalojados.
La precisión varía según el documento. Páginas nítidas sobre fondos uniformes rozan el 99 por ciento de exactitud. Escaneos antiguos de baja resolución, manuscritos con caligrafía irregular o diseños atípicos con texto superpuesto sobre imágenes complejas reducen el desempeño. Por eso, en entornos productivos se aplican flujos híbridos: todo resultado por debajo de un umbral de confianza pasa a revisión humana antes de alimentar sistemas posteriores.
Integrarlo en pilas existentes exige adaptación. Organizaciones que dependen de OCR propietarios afrontan costos de migración significativos. Cambian los formatos de salida, la gestión de errores y las garantías de latencia respecto de APIs maduras. La licencia MIT despeja trabas legales, aunque no elimina el esfuerzo de ingeniería necesario para ajustar workflows consolidados.
Implicaciones para construcción de datasets y memoria artificial
La posibilidad de procesar millones de páginas por día tiene consecuencias inmediatas para el entrenamiento de modelos lingüísticos de próxima generación. Una parte enorme del acervo textual sigue encerrada en contenedores visuales: libros escaneados, expedientes públicos digitalizados, repositorios científicos antiguos. DeepSeek-OCR libera ese material y lo convierte en texto estructurado utilizable en preentrenamiento, lo que amplía el universo de datos disponibles en órdenes de magnitud y desplaza el techo actual de escala.
La idea de un “decaimiento visual” aplicado a la memoria conversacional introduce una arquitectura en capas: lo reciente permanece en representación textual completa y lo antiguo se condensa de manera progresiva en versiones visuales de menor resolución. Esta jerarquía, que imita la forma en que olvidamos sin perder del todo, permitiría agentes con historiales extensos sin costos computacionales desbocados. Un asistente capaz de evocar cientos de charlas pasadas de modo difuso pero recuperable supondría un salto cualitativo frente a las limitaciones de la ventana de contexto vigente.
El ecosistema se mueve rápido. Competidores como Xiaohongshu, con su modelo dots.ocr, y varios proyectos de código abierto están acelerando la curva de innovación. La tendencia apunta a consolidar la compresión óptica como primitiva de base en los sistemas multimodales, de modo que el procesamiento visual eficiente se integre de forma nativa y se reduzcan los pasos intermedios de conversión de píxeles a texto.
Queda una incógnita relevante: hasta dónde puede generalizarse este enfoque más allá de los documentos con estructura clara. Videos, interfaces dinámicas y visualizaciones interactivas plantean retos distintos. Aun así, el principio que guía la investigación se mantiene firme. Si una representación visual comprimida transporta más información semántica por token que el texto plano, se abren rutas prometedoras para modalidades que antes se consideraban poco prácticas en entornos de lenguaje.
Referencias:
GitHub – deepseek-ai/DeepSeek-OCR: «Contexts Optical Compression»
Hugging Face – deepseek-ai/DeepSeek-OCR model card
The Decoder – «Deepseek’s OCR system compresses image-based text so AI can handle much longer documents»
All About AI – «DeepSeek-OCR: 3B Open-Source OCR Model For Markdown Docs»
OmniDocBench GitHub – «A Comprehensive Benchmark for Document Parsing and Evaluation»
Efficient Coder – «DeepSeek-OCR: How Vision Compression is Revolutionizing Long-Context Memory in AI»
Simon Willison – «Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code»

