
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
LLM que planean y actúan
La imagen clásica del “chatbot” quedó chica. La pregunta dejó de ser si un modelo escribe bien y pasó a ser si puede traducir lenguaje en acciones concretas: buscar, citar, ejecutar código, coordinar con otros sistemas y sostener un plan. Ese giro define a los agentes basados en LLM. Ya no contestan: actúan. El cambio no es cosmético. Supone diseñar memoria para recordar lo útil, planificadores que dividen metas en pasos razonables y conectores que abren la puerta a APIs, bases documentales, simuladores o robots. Cuando todo eso convive, aparece algo nuevo: una conducta que se evalúa por resultados y no solo por frases bien formadas.
Pocos días atrás se publicó una revisión académica extensa que sintetiza la literatura de 2023 a 2025 y propone un marco común. Releva 108 artículos con foco en siete preguntas: qué arquitecturas vuelven “agentivos” a los LLM, cómo integrar herramientas externas, qué marcos de diseño predominan en sistemas de un solo agente y multiagente, cómo razonan, planifican y usan memoria, qué aporta el prompting y el fine-tuning, cómo evaluar de forma creíble y qué riesgos persisten. El aporte práctico es doble. Primero, separa hype de ingeniería: clasifica piezas que funcionan en la práctica y dónde fallan. Segundo, sube el estándar de evaluación, con inventario de benchmarks, métricas y sesgos típicos.
Es un excelente análisis de los LLM como agentes autónomos y usuarios de herramientas. Los LLM pueden convertirse en agentes competentes cuando las herramientas, la memoria y la planificación se diseñan en torno a ellos, y las principales deficiencias son el razonamiento verificable, la autosuperación robusta y la personalización. La mayoría de los sistemas actuales integran las indicaciones y las llamadas a herramientas en modelos generales, lo cual funciona en demostraciones pequeñas, pero falla con contextos extensos, entradas ruidosas o coordinación multiagente.
Alcance y taxonomía. La revisión organiza el campo en torno a modelos de referencia, uso de herramientas, marcos de agentes, razonamiento y memoria, indicaciones y ajuste, además de la evaluación, y abarca 108 artículos de 2023 a 2025 con una taxonomía estructurada y una lista clara de contribuciones. La Figura 1 muestra el mapa de temas y la Tabla 1 contrasta estudios previos.
Bloques fundamentales del agente. Un agente LLM se estructura por perfil, memoria, planificación y ejecución de acciones en un ciclo de retroalimentación donde la memoria moldea los planes y las acciones actualizan la memoria y el comportamiento.
La tesis de trabajo es modesta y útil: los agentes con LLM funcionan si se los mide en tareas donde el lenguaje es interfaz y el control de herramientas está bien gobernado. Donde falta gobernanza y trazabilidad, las promesas se diluyen.
Antecedentes y marco
La evolución fue rápida. En 2023 surgieron patrones de orquestación como ReAct y Reflexion que alternan razonamiento y acción, y técnicas de memoria explícita para no repetir errores. En paralelo, aparecieron marcos multiagente como CAMEL, MetaGPT y AutoGen que repartieron roles y fomentaron debate y consenso. El paso siguiente fue ampliar el “cuerpo” del agente con herramientas: búsqueda y RAG para anclar respuestas, intérpretes de código para calcular y automatizar, y entornos de simulación y robótica para probar decisiones. Mientras tanto, los modelos base se diversificaron. La familia GPT siguió como referencia frecuentada, pero el terreno abierto creció con LLaMA, Mistral, Qwen, Gemma y variantes multimodales. La revisión muestra que el campo dejó de ser un truco de prompting y maduró hacia arquitecturas repetibles, con piezas que se pueden auditar y comparar.
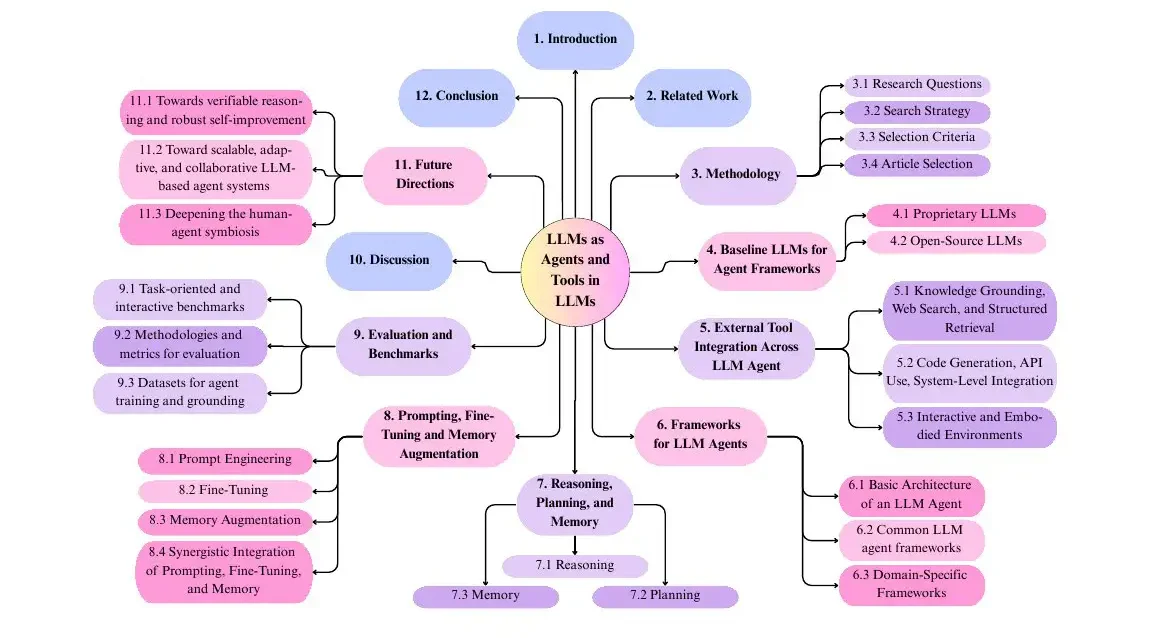
Una descripción general de la taxonomía utilizada en esta revisión.
Cómo funciona
Un agente con LLM se entiende mejor como una tubería simple, modulada y medible.
Perfil. Define el rol operativo: investigador, programador, analista clínico. Puede ser estático, con reglas claras, o dinámico, con generación de “personas” según la tarea. El perfil pauta estilo, tolerancia al riesgo y criterios de verificación.
Memoria. Hay dos capas. Una corta, en contexto, para sostener coherencia durante una interacción. Otra larga, fuera del LLM, para recordar experiencias, resultados y herramientas útiles. La memoria larga necesita políticas: qué guardar, por cuánto tiempo, cómo resumir y cómo expurgar. La clave práctica es recuperar poco y bien, no todo lo que haya.
Planificación. Convierte metas en pasos ejecutables. Puede ser determinista con cadenas de pensamiento, árbol de pensamientos y plantillas, o adaptativa con lazos de retroalimentación que replanifican ante resultados parciales. En dominios con reglas duras conviene explicitar planes y validarlos paso a paso.
Acción. Llama herramientas y escribe resultados. En modo básico, el agente produce texto. En modo operativo, ejecuta código, consulta APIs, lee documentos, navega entornos, mueve actuadores. La disciplina de “observación–acción–observación” habilita control y auditoría.
Reflexión. Evalúa qué funcionó y qué no, y escribe de vuelta a memoria. La reflexión no es “pensar más”, sino registrar por qué un camino fue mejor y cuándo evitarlo. Con esa rutina, el sistema mejora sin tocar pesos del modelo base.
La suma de estas piezas permite construir agentes útiles con LLM congelados. El aprendizaje se traslada de los parámetros al gobierno de memoria, planes y herramientas. En la práctica, los grandes saltos de calidad vienen de mejor recuperación, mejores validadores y menos latencia, más que de cambiar de modelo cada mes.
Comparaciones (benchmarks)
La revisión inventaría tres frentes de evaluación.
- Tareas interactivas y de herramientas. Plataformas que miden la capacidad para buscar, citar, ejecutar o navegar. Incluyen entornos de hogar simulado, juegos con reglas públicas y suites de investigación en la web. Lo crítico es medir recorrido completo: objetivo, plan, uso de fuentes, resultado y trazabilidad.
- Metodologías y métricas. Más allá de la tasa de acierto, se recomiendan indicadores de verificación: número de fuentes consultadas, repetibilidad, robustez fuera de distribución y costo por tarea. Se alienta registrar latencia y uso de recursos, claves en aplicaciones reales donde el usuario tolera tiempos acotados.
- Datasets y bancos de entrenamiento y prueba. El catálogo reúne decenas de conjuntos que cubren investigación, programación, clínica, química, robótica y colaboración social. La diversidad ayuda, pero introduce comparaciones disparejas si cada autor elige un subconjunto favorable. Por eso el artículo empuja hacia paneles comunes y protocolos de evaluación reproducible.
Hallazgos duros. La evidencia converge en varios puntos:
-
Los agentes mejoran mucho con acceso a herramientas precisas y documentación estructurada.
-
La memoria ayuda si está curada y se recupera con criterio. Memorias grandes con ruido penalizan.
-
Donde más fallan es en tareas que mezclan conocimiento tácito, ambigüedad y cambios de objetivo sobre la marcha.
-
La colaboración multiagente rinde cuando hay roles nítidos y un árbitro o regla de consenso. Sin disciplina, el costo de coordinación se come las ganancias.
Voces y fuentes
El metaestudio aporta tres mensajes que conviene retener. Primero, elige cubrir todas las dimensiones críticas, no solo “razonamiento”: también herramientas, marcos, evaluación, seguridad y alineamiento. Segundo, hace explícito un sesgo del campo: buena parte de los trabajos emplea modelos propietarios como referencia y los alterna con alternativas abiertas de capacidad creciente. Tercero, y más importante, señala vacíos: falta estandarizar cómo se mide la verificación, sobran comparaciones con métricas incompletas y queda trabajo serio por hacer en privacidad, ataques y robustez.
Impactos por sector
Educación. Un tutor agente que planifica, busca, cita y recuerda errores comunes ahorra tiempo docente y eleva la calidad de las consignas. El valor real aparece cuando la memoria guarda estrategias que funcionaron con perfiles distintos de estudiantes. Riesgo: convertirlo en generador de respuestas sin explicación ni fuentes.
Salud. Agentes clínicos como copilotos de documentación, triage o búsqueda bibliográfica pueden mejorar tiempos y calidad de registro. La condición es férrea: trazabilidad, control de acceso y bloqueo de acciones sin revisión humana. La memoria aquí es un arma de doble filo y exige políticas estrictas de minimización y borrado.
Economía y productividad. En programación, análisis de datos o soporte, los agentes reducen fricción: leen tickets, reproducen bugs, proponen parches, generan tests y validan. El impacto depende de acoplarlos a repositorios, CI y monitoreo con permisos acotados. Sin guardrails, aumentan deuda técnica.
Ética y política pública. La administración puede usar agentes para trámites, informes y búsqueda de normativa con verificación cruzada. Pedirían bitácoras exhaustivas: qué fuente se consultó, qué plan se ejecutó, qué decisión se tomó y por qué. Sin transparencia, el riesgo es automatizar errores y sesgos con sello estatal.
Seguridad. La superficie de ataque crece. Un agente con herramientas puede ser manipulado con entradas diseñadas, documentación maliciosa o APIs ambiguas. Defenderse requiere validadores, listas blancas de herramientas, pruebas de caja roja y auditorías periódicas del comportamiento.
Controversias y vacíos
Verificación y alucinaciones. La herramienta no arregla el juicio. Sin verificación explícita y reglas de citación y cálculo, los agentes aceleran la producción de respuestas erróneas. La comunidad empuja hacia “razonamiento verificable”, donde cada paso deja rastros y las salidas se validan con funciones.
Evaluación inestable. Los benchmarks cambian y los modelos se actualizan. Sin suites públicas, firmes y variadas, la comparación se vuelve marketing. Hace falta medir con paneles compartidos, pruebas a ciegas y publicación de trazas.
Privacidad y trazabilidad. La memoria persiste. Registrar episodios sin minimizar, anonimizar y expurgar compromete a usuarios y organizaciones. Se necesitan catálogos de datos, políticas de retención y derecho al olvido operativos en la orquestación, no solo en el entrenamiento.
Robustez y seguridad. Ataques por instrucciones, inyección en documentos, herramientas con efectos colaterales. El agente necesita zonas de pruebas y simuladores antes de tocar sistemas reales. También detectores de salida fuera de distribución y “kill switch” si un plan deriva.
Dependencia de proveedores. Mezclar modelos propietarios y abiertos puede ser razonable, pero obliga a planes de contingencia. En dominios críticos, conviene que al menos una ruta funcional se base en modelos y orquestación que la organización pueda auditar y sostener.
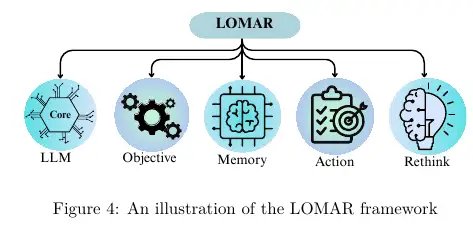
Las configuraciones de agente único se resumen mediante LOMAR, donde el LLM principal persigue un Objetivo, lee y escribe Memoria, toma Acción y luego Repiensa en función de la retroalimentación para mejorar el siguiente paso.
Escenarios (corto/mediano/largo)
Corto plazo
Supuestos: modelos actuales, orquestación madura, herramientas disponibles y equipos con práctica.
Escenario: agentes de investigación, programación y soporte adoptados en equipos y pymes. Valor por automatizar rutinas, mejorar búsquedas y acelerar verificaciones. Métricas de éxito: ahorro de horas, reducción de re-trabajos, latencia controlada y calidad de fuentes citadas.
Mediano plazo
Supuestos: paneles de evaluación más sólidos, prácticas de memoria y verificación estandarizadas, modelos abiertos más capaces.
Escenario: agentes de dominio con memoria gobernada y catálogos de herramientas curados. Surgen roles nuevos en ingeniería: curadores de memoria, diseñadores de planes, auditores de trazas. Las plataformas ofrecen “agentes certificados” con garantías de verificación.
Largo plazo
Supuestos: avances en razonamiento verificable, coordinación multiagente con costos bajos, integración segura con sistemas físicos.
Escenario: agentes como infraestructura. Viven en procesos, con monitoreo continuo y auditoría externa. La frontera estará en combinar razonamiento simbólico, aprendizaje por refuerzo seguro y memorias maleables con garantías. Reguladores exigen reportes de comportamiento y bitácoras estándar.
Ética y regulación
Privacidad por diseño. Minimizar, anonimizar, retener poco. La memoria del agente no puede convertirse en archivo pasivo de datos sensibles. Se auditan trazas y se permite el borrado selectivo a pedido del usuario.
Transparencia operativa. Cada respuesta significativa debería poder reconstruirse: qué pasos se planearon, qué herramientas se invocaron, qué fuentes se consultaron y con qué criterios se eligieron. Las organizaciones deben publicar políticas y límites de sus agentes.
Seguridad en capas. Listas blancas de herramientas, entornos de ejecución aislados, validadores de resultados y límites de acción. Ataques y fallas se tratan como incidentes de seguridad con playbooks específicos, no como “errores de lenguaje”.
Responsabilidad y rendición de cuentas. Si un agente desencadena una acción perjudicial, debe poder asignarse responsabilidad entre diseño, operación y supervisión. Esto implica contratos claros entre proveedores de modelos, integradores y organizaciones usuarias.
Estándares y evaluación pública. Panels comunes, datasets compartidos, pruebas reproducibles. La evaluación no puede quedar en manos de cada autor. Se requieren iniciativas interinstitucionales que mantengan suites vivas y documentación de cambios.
Una última mirada
Los agentes con LLM ya aportan valor donde el lenguaje es interfaz y hay herramientas buenas para operar. Su poder no vive solo en más parámetros, sino en memoria gobernada, planificación explícita y verificación. La literatura reciente trae un mensaje sensato: si se diseña bien la orquestación y se mide con rigor, el salto del texto a la acción es útil y medible. Lo que sigue depende menos de un “modelo milagroso” y más de disciplina de ingeniería, estándares de evaluación y reglas claras de seguridad y privacidad. Conviene mirar menos a la próxima demo y más a la trazabilidad del siguiente plan ejecutado.
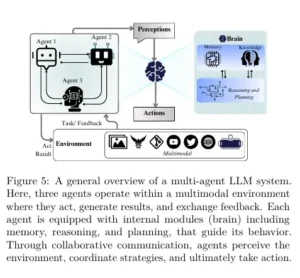
Colaboración entre múltiples agentesLos sistemas multiagente asignan roles, se coordinan a través de una comunicación de estilo cooperativo o de debate, se adaptan con memoria compartida o descentralizada y ajustan estrategias con retroalimentación ambiental y humana.
Glosario
- LLM. Modelo de lenguaje grande que predice secuencias y puede seguir instrucciones.
- Agente. Sistema que observa, planifica y actúa para lograr una meta.
- Memoria episódica. Registro estructurado de experiencias pasadas del agente con su resultado.
- RAG. Recuperación aumentada que integra documentos externos como base factual.
- ReAct. Patrón que alterna razonamiento con acciones de herramienta y nuevas observaciones.
- Reflexión. Mecanismo para evaluar una trayectoria y escribir aprendizajes a memoria.
- Raz. verificable. Estrategias para que cada paso deje evidencia comprobable.
Métricas y benchmarks
- Cobertura de tareas. Investigación en web, programación, clínica, química, robótica, colaboración.
- Indicadores de calidad. Acierto final, verificación de fuentes, repetibilidad, robustez fuera de distribución.
- Costos operativos. Latencia, llamadas a herramientas, consumo de cómputo por tarea.
- Memoria. Calidad de recuperación, tamaño efectivo, impacto en precisión y latencia.
- Multiagente. Calidad de consenso, costo de coordinación, mejora sobre agente único.
- Datasets y suites. Catálogo amplio de conjuntos 2023–2025 para tareas interactivas y de herramientas.
Fuentes
Chowa, S. S.; Alvi, R.; Rahman, S. S.; Rahman, M. A.; Khan Raiaan, M. A.; Islam, M. R.; Hussain, M.; Azam, S. “From Language to Action: A Review of Large Language Models as Autonomous Agents and Tool Users”. arXiv:2508.17281v1, 24 de agosto de 2025. https://arxiv.org/abs/2508.17281

