
En los últimos años, la inteligencia artificial ha logrado hazañas que hace una década parecían ciencia ficción. Modelos lingüísticos capaces de mantener conversaciones coherentes, sistemas que resuelven problemas matemáticos complejos, asistentes virtuales que navegan por la web en busca de información precisa. Sin embargo, bajo esta apariencia de sofisticación se esconde una limitación fundamental que ha inquietado a los investigadores: estos sistemas, por poderosos que sean, actúan como pensadores solitarios que intentan hacer todo por sí mismos. Es como pedirle a un genio que sea simultáneamente investigador, programador, crítico y redactor, cuando en realidad cada una de estas funciones requiere habilidades y perspectivas distintas.
Un equipo de investigadores de la Universidad de Stanford, en colaboración con académicos de Texas A&M University, UC San Diego y Lambda, ha desarrollado una alternativa que promete transformar la manera en que concebimos los sistemas de inteligencia artificial. Su propuesta, denominada AgentFlow, representa un cambio de paradigma: en lugar de entrenar un único modelo monolítico que intenta dominar todas las tareas simultáneamente, construye un ecosistema colaborativo donde múltiples componentes especializados trabajan de forma coordinada, aprendiendo a mejorar su cooperación mediante la experiencia.
Para comprender la relevancia de este avance, es necesario entender primero el panorama actual. Los modelos lingüísticos de gran escala han demostrado capacidades impresionantes gracias al aprendizaje por refuerzo basado en resultados verificables. Este método permite que la inteligencia artificial aprenda mediante prueba y error, recibiendo recompensas cuando produce respuestas correctas. Cuando estos modelos se augmentan con herramientas externas, como motores de búsqueda o interpretes de código, pueden acceder a conocimiento actualizado y realizar cálculos precisos. Modelos como DeepSeek-R1 han mostrado comportamientos sofisticados en autocorrección y deducción multi-paso mediante este enfoque.
La estrategia predominante hasta ahora ha consistido en entrenar un único modelo para que intercale pensamientos internos con invocaciones a herramientas externas, todo dentro de un mismo contexto extenso. El modelo genera texto que representa su razonamiento, luego invoca una herramienta específica, procesa el resultado y continúa su cadena de pensamiento. Aunque este método ha funcionado bien en escenarios especializados con una sola herramienta, como usar código para resolver problemas matemáticos o realizar búsquedas web para responder preguntas de conocimiento intensivo, enfrenta desafíos significativos cuando la complejidad aumenta.
Estos desafíos se manifiestan de múltiples formas. Primero, el entrenamiento se vuelve progresivamente inestable a medida que los horizontes temporales se extienden, la diversidad de herramientas crece y los ambientes cambian con la retroalimentación de las herramientas. Segundo, la generalización en tiempo de inferencia permanece frágil ante tareas o herramientas no vistas durante el entrenamiento. Tercero, y quizás más fundamental, existe el problema de la asignación de crédito en horizontes largos: cuando un sistema ejecuta una secuencia de quince o veinte pasos y solo al final descubre si la respuesta es correcta o incorrecta, resulta extremadamente difícil determinar cuáles de esos pasos fueron beneficiosos y cuáles perjudiciales.
Los sistemas agénticos surgieron como una alternativa prometedora. Estos frameworks despliegan múltiples módulos especializados, a menudo modelos lingüísticos distintos con roles cuidadosamente diseñados, como planificador, crítico, codificador o ejecutor, que colaboran dentro de un flujo de trabajo estructurado. Al descomponer problemas complejos en subobjetivos y asignar tareas a módulos con capacidades y herramientas dedicadas, pueden abordar problemas que exceden el alcance de un modelo individual. Sin embargo, la mayoría de estos sistemas permanecen estáticos, orquestados por lógica predefinida o heurísticas de prompts sin capacidad de aprendizaje.
Aquí radica el problema central: lograr coordinación robusta en estos sistemas requiere fundamentalmente entrenamiento, porque la lógica artesanal o los prompts estáticos no pueden capturar de manera confiable cuándo y cómo los módulos deben colaborar, adaptarse a salidas de herramientas evolutivas o recuperarse de errores tempranos. Aunque algunos sistemas han empleado ajuste fino supervisado u optimización de preferencias para módulos clave, estos enfoques fuera de política están desacoplados de las dinámicas reales del sistema operando en vivo y aprenden deficientemente de los éxitos o fracasos posteriores.
AgentFlow aborda precisamente este vacío. El sistema está compuesto por cuatro módulos especializados que interactúan iterativamente: un planificador de acciones que decide qué hacer en cada momento, un ejecutor de herramientas que implementa esas decisiones, un verificador de ejecución que evalúa si los resultados son válidos y suficientes, y un generador de soluciones que produce la respuesta final. Estos componentes se coordinan mediante una memoria evolutiva compartida que registra todo el proceso de razonamiento de forma estructurada y determinista.
Lo verdaderamente innovador de AgentFlow no es simplemente su arquitectura modular, sino que optimiza directamente su planificador dentro del bucle operativo del sistema, aprendiendo de la experiencia mientras el sistema funciona. Esto contrasta radicalmente con métodos previos que entrenan componentes de forma aislada con datos estáticos, esperando que luego colaboren eficazmente cuando se ensamblan. Es la diferencia entre entrenar músicos individualmente con grabaciones y hacer que una orquesta ensaye junta, ajustando su coordinación en tiempo real.
Para hacer posible este entrenamiento dentro del flujo operativo, los investigadores desarrollaron un algoritmo denominado Flow-GRPO, que resuelve el espinoso problema de asignar crédito en secuencias largas con recompensas escasas. La solución es conceptualmente elegante: en lugar de intentar asignar créditos parciales a cada paso con heurísticas frágiles, el sistema asigna una única señal de recompensa verificable basada en el resultado final a toda la trayectoria completa, y difunde esta señal a cada turno. Esto transforma efectivamente el desafío del aprendizaje por refuerzo multi-turno en una secuencia de actualizaciones tractables de un solo turno.
Los resultados experimentales demuestran la efectividad de este enfoque de manera contundente. AgentFlow con un backbone de solo siete mil millones de parámetros supera a modelos especializados más grandes y sistemas agénticos previos en diez benchmarks diversos, logrando ganancias promedio del 14.9% en tareas de búsqueda intensiva de conocimiento, 14.0% en tareas agénticas más amplias, 14.5% en razonamiento matemático y 4.1% en razonamiento científico. Notablemente, incluso supera a GPT-4o, un modelo propietario con aproximadamente doscientos mil millones de parámetros, en todos estos dominios.

Izquierda: Rendimiento de AGENTFLOW con una estructura básica de escala 7B antes y después del ajuste de Flow-GRPO en diez puntos de referencia de razonamiento diferentes. Flow-GRPO mejora sustancialmente el rendimiento al optimizar la calidad de la planificación y la fiabilidad de la llamada a herramientas. Derecha: AGENTFLOW logra mejoras consistentes con respecto a las principales líneas de base, incluyendo LLM básicos, modelos de aprendizaje automático integrados en herramientas y sistemas de agencia sin entrenamiento. Todos los resultados de 7B utilizan Qwen2.5-7B-Base/Instruct como estructura básica y herramientas.
La anatomía de un sistema que piensa en equipo
Para apreciar la arquitectura de AgentFlow, conviene primero entender cómo funciona un turno completo de razonamiento. El sistema comienza con una consulta del usuario y un conjunto de herramientas disponibles. La memoria, inicialmente poblada solo con la consulta, sirve como el estado compartido que todos los módulos pueden leer y actualizar.
En cada turno, el planificador de acciones analiza la consulta original, el objetivo global, las habilidades requeridas y el historial de acciones previas almacenado en la memoria. Con esta información, formula un subobjetivo específico, selecciona la herramienta más apropiada del conjunto disponible y recupera el contexto relevante de la memoria. Esta acción no es un simple comando predefinido, sino una decisión generada por un modelo lingüístico entrenado mediante política, que aprende qué herramientas invocar y cuándo hacerlo según la situación.
El ejecutor de herramientas toma la decisión del planificador y la implementa. Si el planificador seleccionó un motor de búsqueda, el ejecutor construye la consulta adecuada y procesa los resultados. Si eligió un intérprete de Python, genera el código necesario y lo ejecuta. El ejecutor actúa como el puente entre las intenciones abstractas del planificador y las operaciones concretas de las herramientas.
El verificador de ejecución evalúa críticamente el resultado obtenido. No simplemente registra lo que sucedió, sino que analiza si la información es válida, si contiene errores, si se alinea con el objetivo de la consulta y si la memoria acumulada ya contiene suficiente información para responder la pregunta original. El verificador produce una señal binaria: continuar con otro turno de razonamiento o detenerse porque ya se cuenta con lo necesario.
Si el verificador decide continuar, la memoria se actualiza determinísticamente incorporando la nueva evidencia: el subobjetivo perseguido, la herramienta seleccionada, el comando ejecutado, el resultado obtenido y el análisis del verificador. Esta actualización no es aleatoria ni ambigua; es una función determinística que garantiza que el estado del sistema evolucione de manera transparente y controlable. El ciclo se repite hasta que el verificador determine que se ha acumulado suficiente información o se alcance un presupuesto máximo de turnos.
Cuando el proceso concluye, el generador de soluciones sintetiza toda la información acumulada en la memoria para producir la respuesta final. Este módulo no participa en la exploración ni en la recolección de evidencia; su única función es transformar la memoria estructurada en una respuesta coherente y precisa para el usuario.
Esta descomposición modular ofrece ventajas significativas. Cada componente puede especializarse en su función sin necesidad de dominar todas las competencias simultáneamente. El planificador se enfoca en la estrategia de alto nivel, el ejecutor en la implementación técnica, el verificador en el control de calidad y el generador en la síntesis comunicativa. Además, la memoria evolutiva proporciona un registro explícito y determinista del proceso de razonamiento, permitiendo seguimiento transparente del estado, comportamiento controlable y crecimiento acotado del contexto.
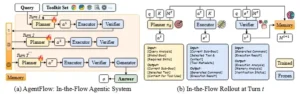
(a) Descripción general de AGENTFLOW, un sistema agéntico entrenable para la planificación en flujo y el uso de herramientas. Cuatro módulos (planificador, ejecutor, verificador y generador) se coordinan mediante una memoria evolutiva compartida M y un conjunto de herramientas K, dada una consulta q. La política del planificador se optimiza según la política dentro del bucle multivuelta del sistema para permitir un razonamiento adaptativo de largo plazo. (b) Una transición de estado único, que muestra la acción at, el resultado de la ejecución et y la señal del verificador vt que actualizan la memoria de M t a M t+1.
El arte de aprender mientras se actúa
El aspecto más revolucionario de AgentFlow reside en cómo aprende. Los métodos convencionales de entrenamiento fuera de línea, como el ajuste fino supervisado o la optimización de preferencias sobre trazas curadas, optimizan el planificador fuera del bucle activo. Este desacoplamiento previene la coordinación en tiempo real con los otros módulos, induce cambios de distribución entre entrenamiento e implementación y proporciona guía limitada sobre qué decisiones intermedias realmente importan. Los planificadores entrenados así a menudo se adaptan pobremente a dinámicas multi-turno; los errores tempranos se propagan en cascada y las correcciones posteriores resultan frágiles.
El aprendizaje dentro del flujo operativo aborda estos problemas directamente. El sistema ejecuta AgentFlow completo bajo la política actual, recolecta la trayectoria real de estados, acciones y eventos de herramientas que induce, y actualiza la política dentro del sistema agéntico usando una señal verificable de resultado final. Esto expone directamente el problema de asignación de crédito multi-turno y entrena al planificador en los estados exactos que enfrentará durante la inferencia.
Para entender cómo Flow-GRPO resuelve el problema de asignación de crédito, consideremos un ejemplo concreto. Supongamos que el sistema intenta responder una pregunta compleja sobre historia que requiere consultar múltiples fuentes, verificar fechas mediante cálculos y sintetizar información contradictoria. El proceso podría involucrar quince turnos: búsquedas en Wikipedia, consultas a motores de búsqueda generales, ejecuciones de código para calcular diferencias temporales, búsquedas adicionales para resolver ambigüedades. Al final, el sistema produce una respuesta que resulta ser correcta.
El desafío es este: ¿cómo saber cuáles de esos quince pasos fueron útiles y cuáles fueron desvíos innecesarios o incluso perjudiciales? Los métodos tradicionales intentarían asignar recompensas parciales a cada paso mediante heurísticas complejas: quizás recompensar cada vez que se obtiene información nueva, o penalizar cuando se repite una búsqueda, o dar crédito proporcional según la proximidad temporal al resultado final. Estas heurísticas son inevitablemente frágiles y pueden inducir comportamientos indeseados.
Flow-GRPO adopta un enfoque radicalmente distinto. Asigna una única recompensa binaria basada en la corrección de la solución final a toda la trayectoria, y difunde esta señal uniformemente a cada turno. Cada acción dentro de la secuencia recibe la misma recompensa global: uno si la respuesta final fue correcta, cero si fue incorrecta. Esta aparente simplicidad esconde una intuición profunda: al proporcionar al planificador el contexto completo de la memoria en cada turno junto con una señal consistente alineada con el éxito global, el algoritmo transforma efectivamente el problema de aprendizaje por refuerzo multi-turno en una serie de actualizaciones de política de un solo turno.
Técnicamente, el sistema recolecta múltiples trayectorias en paralelo para cada consulta, calcula ventajas normalizadas por grupo para reducir varianza y agudizar la asignación de crédito entre el conjunto, y actualiza la política usando un objetivo recortado similar al de PPO junto con regularización por divergencia KL para estabilizar el aprendizaje. El algoritmo opera sobre rollouts dentro del flujo que capturan la trayectoria completa de estados, acciones y eventos de herramientas inducidos por el sistema operando en vivo.
Esta metodología tiene implicaciones profundas. El planificador no aprende de trazas estáticas recolectadas previamente, sino de su propia experiencia operando el sistema completo. No recibe señales de recompensa artificialmente diseñadas para cada paso intermedio, sino retroalimentación auténtica sobre si la solución final fue correcta. No se entrena para imitar un comportamiento demostrado, sino para maximizar el éxito en la tarea real.
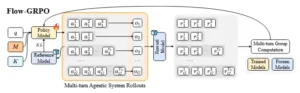
Optimización para nuestro sistema agéntico propuesto, AGENTFLOW. Dada una consulta q, una memoria evolutiva M y un conjunto de herramientas K, el modelo de políticas genera acciones dirigidas a subobjetivos y selecciona herramientas. Se entrena mediante Optimización de Políticas Refinadas de Grupo Basada en Flujo (Flow-GRPO), que permite el aprendizaje por refuerzo multiturno y la optimización estable en dinámicas colaborativas.
Cuando el alumno supera al maestro
Los experimentos realizados abarcan diez benchmarks diversos que evalúan capacidades en múltiples dominios. En tareas de búsqueda intensiva de conocimiento como Bamboogle, 2Wiki, HotpotQA y Musique, AgentFlow con su backbone de siete mil millones de parámetros alcanza una precisión promedio del 57.3%, superando significativamente a modelos especializados en búsqueda como Search-R1 que logra 33.3% y VerlTool con 39.0%. Incluso supera a GPT-4o, que a pesar de sus aproximadamente doscientos mil millones de parámetros solo alcanza 49.1%.
En GAIA, un benchmark diseñado específicamente para evaluar sistemas de inteligencia artificial general y agentes que requieren razonamiento secuencial, navegación web y uso comprensivo de herramientas, AgentFlow logra 33.1% de precisión frente al 17.3% de GPT-4o, una mejora del 15.8%. Para tareas agénticas más amplias que demandan coordinación compleja entre múltiples capacidades, el sistema demuestra ventajas consistentes sobre frameworks previos como AutoGen, que usando el mismo modelo base alcanza solo 6.3% en GAIA.
En razonamiento matemático, evaluado mediante problemas del American Invitational Mathematics Examination 2024, American Mathematics Competition 2023 y el juego de 24, AgentFlow alcanza una precisión promedio del 51.5%. Esto supera sustancialmente a modelos especializados en código como ToRL con 37.0% y a sistemas de razonamiento como SimpleRL-reason con 36.6%. Incluso el poderoso modelo Llama-3.1 con cuatrocientos cinco mil millones de parámetros solo logra 32.4%.
Para razonamiento científico, evaluado en GPQA, un benchmark de preguntas de nivel de posgrado en biología, física y química diseñadas para ser excepcionalmente desafiantes, junto con MedQA que contiene problemas de exámenes de licencia médica profesional, AgentFlow alcanza 63.5% de precisión promedio frente al 55.5% de Luffy, el siguiente mejor sistema, y 45.5% de GPT-4o.
Estos resultados no son simplemente mejoras incrementales. Representan saltos cualitativos en capacidad que permiten resolver problemas previamente intratables. Un análisis de casos individuales revela patrones ilustrativos de cómo el sistema aprende estrategias efectivas.
En un problema del juego de 24 que requiere crear una expresión aritmética igual a 24 usando los números uno, uno, seis y nueve, el sistema antes del entrenamiento con Flow-GRPO intenta generar código Python que resulta incorrecto, cometiendo errores repetidos sin capacidad de autocorrección. Después del entrenamiento, el sistema intenta primero varias soluciones, reconoce su inefectividad, recurre espontáneamente a un enfoque de fuerza bruta generando y probando sistemáticamente todas las permutaciones posibles, encuentra expresiones válidas y finalmente verifica el resultado mediante un motor de búsqueda para confirmación adicional.
En una pregunta de GAIA que requiere identificar qué científico en un video histórico predijo más pronto la llegada de máquinas pensantes, el sistema entrenado formula una consulta altamente relevante en el primer intento y obtiene la respuesta correcta inmediatamente. El sistema sin entrenar comienza con una búsqueda directa en el video que falla, luego emite múltiples consultas redundantes a Google sin refinar adecuadamente la estrategia, eventualmente llegando a la respuesta correcta pero solo después de seis intentos ineficientes.
En un problema de física relativista de GPQA sobre cuánto tiempo experimentará un astronauta viajando a velocidad cercana a la luz, el sistema entrenado identifica correctamente el desafío central de dilatación temporal relativista sobre distancias interestelares y aplica la computación basada en física apropiada en pasos mínimos, llegando a la respuesta correcta eficientemente. El sistema sin entrenar malinterpreta la edad del astronauta como la duración del viaje, llevando a una cascada de cálculos erróneos a través de múltiples invocaciones de herramientas.
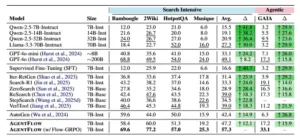
Comparación de la precisión en tareas de búsqueda intensiva y tareas agénticas. 7B-Base se refiere a Qwen-2.5-7B-Base y 7B-Inst se refiere a Qwen-2.5-7B-Instruct. AutoGen y nuestro método AGENTFLOW son sistemas agénticos que utilizan Qwen-2.5-7B-Instruct para los agentes y herramientas con tecnología LLM, lo que permite una comparación justa. Visualizamos las ganancias de AGENTFLOW con respecto a cada línea base en las columnas ∆.
La optimización revela el potencial oculto
El análisis detallado del comportamiento del sistema antes y después del entrenamiento con Flow-GRPO revela transformaciones fascinantes en cómo el planificador aprende a usar herramientas. Para la tarea 2Wiki, que requiere conocimiento factual amplio, el entrenamiento optimiza al planificador para aumentar el uso de Google Search en 42.0%, reconociendo que este motor proporciona acceso más amplio a información general. En contraste, para MedQA, un benchmark especializado que demanda información médica específica y profunda, el ajuste fino desplaza al planificador alejándose de herramientas generales, reduciendo las llamadas a Google Search del 66.2% al 10.9% mientras aumenta dramáticamente el uso de Wikipedia Search especializado del 0% al 59.8%.
Un aspecto crucial del aprendizaje es la reducción de errores en las invocaciones de herramientas. La tasa de error en las llamadas disminuye consistentemente durante el entrenamiento, con reducciones de hasta 28.4% en GAIA. Esta tendencia indica que el proceso no solo enseña al modelo qué herramienta usar, sino también cómo invocarla correctamente con argumentos y formato apropiados, llevando a integración de herramientas más robusta y efectiva.
El sistema también exhibe eficiencia adaptativa, donde aprende a condensar su razonamiento manteniendo la calidad. Durante el entrenamiento, la longitud promedio de las respuestas del planificador inicialmente aumenta durante una fase exploratoria, pero progresivamente se acorta y estabiliza. Esto muestra que el planificador aprende a equilibrar concisión e informatividad, evitando salidas innecesariamente largas sin sacrificar completitud.
Cuando se compara la dinámica de entrenamiento de AgentFlow usando Flow-GRPO contra un modelo monolítico de razonamiento integrado con herramientas entrenado con métodos tradicionales en el problema AIME24, las diferencias son reveladoras. AgentFlow logra ganancias de rendimiento sostenidas, con precisión de validación creciendo establemente. En contraste, el modelo monolítico estanca rápidamente su rendimiento y tiende a la baja, destacando la eficiencia superior del enfoque agéntico que usa descomposición y asignación de crédito estable para evitar la inestabilidad.
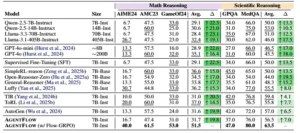
Comparación de la precisión de tareas de razonamiento matemático y científico. Como se muestra en la Tabla 1, AutoGen y AGENTFLOW utilizan Qwen-2.5-7B-Instruct para las herramientas basadas en LLM.
Cuando el entrenamiento hace la diferencia
Un estudio ablativo examina el impacto de diferentes estrategias de entrenamiento para el planificador de acciones mientras los otros módulos permanecen fijos. Los resultados son instructivos. Reemplazar el baseline congelado con un modelo más capaz como GPT-4o produce solo una ganancia modesta del 5.8% en promedio. Esto indica un cuello de botella clave: aunque un modelo más poderoso mejora la planificación, su naturaleza estática previene la co-adaptación con las dinámicas operativas de AgentFlow.
Las limitaciones de un planificador estático se exponen dramáticamente cuando se intenta destilar el comportamiento de GPT-4o mediante ajuste fino supervisado fuera de línea sobre sus trayectorias. Esto resulta en un colapso catastrófico del rendimiento, con una caída promedio de precisión del 19.0% comparado con el baseline congelado. Este fracaso surge del objetivo de imitación a nivel de token del ajuste fino supervisado, que se desalinea con el éxito a nivel de trayectoria y previene que el planificador se adapte a retroalimentación dinámica de herramientas o se recupere de errores acumulativos.
En contraste, entrenar el planificador con Flow-GRPO resulta altamente efectivo. Al optimizar para el resultado final, el planificador aprende a manejar flujos de trabajo de largo horizonte, logrando una ganancia promedio del 17.2% sobre el baseline congelado. La diferencia entre el colapso del ajuste fino supervisado y el éxito de Flow-GRPO subraya la importancia crítica del aprendizaje dentro del flujo operativo versus entrenamiento offline desacoplado.
Escalando hacia el futuro
Los investigadores exploraron cómo el tamaño del modelo backbone afecta el rendimiento del sistema y la eficacia de Flow-GRPO. Construyeron dos versiones usando Qwen2.5-3B-Instruct y Qwen2.5-7B-Instruct para todos los módulos y herramientas, entrenando solo el planificador con Flow-GRPO en ambos casos. El entrenamiento produce mejoras consistentes en tareas para ambos backbones, demostrando que la optimización dentro del flujo es efectiva a través de capacidades de modelo, mejorando AgentFlow independientemente del tamaño del modelo lingüístico.
También investigaron cómo el presupuesto máximo de turnos permitido afecta la profundidad de razonamiento y el rendimiento final durante la inferencia. Incrementar el máximo de tres a diez turnos mejora consistentemente los resultados en todas las tareas, acompañado por un aumento en el promedio de turnos consumidos. En benchmarks intensivos en conocimiento como 2Wiki y GAIA, un presupuesto de turnos mayor permite a AgentFlow recuperación de información más profunda. En benchmarks matemáticos como GameOf24 y AIME24, soporta descomposición de subobjetivos, estrategias alternativas y refinamiento de errores. El rendimiento final alcanza su pico en diez turnos máximos para todas las tareas, confirmando que un horizonte de razonamiento más largo beneficia al sistema sin causar bucles degenerativos.
Cuando las herramientas subyacentes se actualizan de versiones potenciadas por Qwen2.5-7B-Instruct a versiones potenciadas por GPT-4o, AgentFlow demuestra adaptabilidad notable. El sistema con herramientas mejoradas supera sustancialmente su rendimiento con herramientas básicas, logrando mejoras del 1.0% en GAIA, 6.0% en AMC23 y un notable 13.0% en HotpotQA. Este hallazgo soporta una tendencia consistente: después del entrenamiento dentro del flujo, el planificador puede aprovechar adaptativamente mejoras en las herramientas subyacentes para potenciar el rendimiento general del sistema agéntico.

Un ejemplo de caso práctico. Tras un fallo inicial debido a errores repetitivos (izquierda), AGENTFLOW, entrenado con Flow-GRPO, explora una nueva vía de solución en la curva 4 tras dos intentos fallidos (derecha).
Reflexiones sobre una nueva arquitectura de inteligencia
AgentFlow representa más que un avance técnico incremental. Encarna un cambio conceptual en cómo concebimos y construimos sistemas de inteligencia artificial capaces. Durante décadas, la narrativa dominante ha sido la de modelos cada vez más grandes y monolíticos que intentan dominar todas las competencias simultáneamente. Esta estrategia ha producido resultados impresionantes, pero enfrenta límites fundamentales de escalabilidad, adaptabilidad y coordinación.
La propuesta de los investigadores de Stanford y sus colaboradores sugiere una alternativa inspirada en cómo funcionan los equipos humanos efectivos. En lugar de buscar el experto solitario que lo sabe todo, construyen sistemas donde especialistas colaboran, cada uno aportando sus fortalezas únicas, coordinados mediante protocolos de comunicación explícitos y memoria compartida. Crucialmente, estos sistemas no solo se diseñan para colaborar, sino que aprenden a hacerlo mejor mediante experiencia directa.
El algoritmo Flow-GRPO resuelve uno de los problemas más espinosos del aprendizaje por refuerzo en contextos complejos: cómo asignar crédito cuando las recompensas son escasas, los horizontes son largos y las dinámicas son no estacionarias. Su solución de difundir una señal de resultado final a todos los turnos, transformando el problema multi-turno en una serie de actualizaciones de un solo turno, es conceptualmente elegante y prácticamente efectiva. Este enfoque podría tener aplicaciones más allá de sistemas agénticos, inspirando nuevas metodologías para entrenar cualquier sistema que deba coordinar decisiones secuenciales con retroalimentación retrasada.
Los resultados empíricos demuestran que este enfoque no es meramente teórico. Un sistema con un backbone de siete mil millones de parámetros, entrenado apropiadamente para coordinación efectiva, puede superar a modelos casi treinta veces más grandes en una variedad de tareas complejas. Esto tiene implicaciones significativas para la democratización de la inteligencia artificial avanzada. Si sistemas más pequeños y eficientes pueden lograr rendimiento comparable o superior mediante mejor arquitectura y entrenamiento, la barrera de entrada para desarrollar aplicaciones sofisticadas disminuye dramáticamente.
La memoria evolutiva de AgentFlow ofrece otra lección importante. En un momento donde muchos sistemas operan como cajas negras impenetrables, la memoria estructurada y determinista proporciona transparencia sobre el proceso de razonamiento. Cada decisión, cada invocación de herramienta, cada verificación queda registrada explícitamente. Esto no solo facilita la depuración y mejora del sistema, sino que podría contribuir a construir sistemas más interpretables y confiables, aspectos cruciales para la adopción responsable de inteligencia artificial en dominios críticos.
Las direcciones futuras son múltiples y prometedoras. Los investigadores señalan la posibilidad de extender la optimización dentro del flujo a otros módulos más allá del planificador, incorporar señales de recompensa más granulares que complementen el resultado final, y escalar el framework para abordar tareas más complejas y abiertas. También surge la pregunta de cómo estos sistemas podrían aprender a incorporar herramientas nuevas dinámicamente, adaptándose a ambientes cambiantes sin necesidad de reentrenamiento extenso.
En un panorama donde la inteligencia artificial avanza a velocidad vertiginosa, AgentFlow nos recuerda que el progreso no proviene únicamente de modelos más grandes entrenados con más datos y más recursos computacionales. También surge de repensar fundamentalmente la arquitectura, de inspirarse en principios organizacionales que han demostrado efectividad en sistemas biológicos y sociales, y de desarrollar algoritmos que permitan a estos sistemas aprender de su propia experiencia operativa.
La inteligencia, después de todo, no es solo conocimiento acumulado o capacidad de procesamiento bruto. Es también la habilidad de planificar, ejecutar, verificar y adaptar, de coordinar múltiples perspectivas hacia objetivos comunes, de aprender de la experiencia y mejorar con la práctica. AgentFlow, con sus módulos especializados, su memoria compartida y su entrenamiento dentro del flujo operativo, captura estos aspectos de manera más fiel que los monolitos lingüísticos que han dominado el campo en años recientes.
Mientras la comunidad científica continúa explorando los límites de lo posible en inteligencia artificial, trabajos como este nos recuerdan que todavía hay espacio considerable para innovación conceptual. No se trata solo de hacer modelos más grandes, sino de hacer sistemas más inteligentes mediante mejor arquitectura, mejor coordinación y mejores métodos de aprendizaje. Y en ese espacio de innovación conceptual, AgentFlow marca un hito significativo que probablemente inspirará numerosas investigaciones futuras y aplicaciones prácticas.
Referencias
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948.
Zeng, W., Huang, Y., Liu, Q., Liu, W., He, K., Ma, Z., & He, J. (2025). SimpleRL-Zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892.
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., & Han, J. (2025). Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516.
Chen, M., Li, T., Sun, H., Zhou, Y., Zhu, C., Wang, H., Pan, J. Z., Zhang, W., Chen, H., Yang, F., et al. (2025). ReSearch: Learning to reason with search for LLMs via reinforcement learning. arXiv preprint arXiv:2503.19470.
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al. (2024). AutoGen: Enabling next-gen LLM applications via multi-agent conversations. First Conference on Language Modeling (COLM).
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S. K. S., Lin, Z., et al. (2024). MetaGPT: Meta programming for a multi-agent collaborative framework. International Conference on Learning Representations (ICLR).
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, Y., Liu, Y., Cui, Z., Zhang, Z., & Qiu, Z. (2024). Qwen2.5 technical report. arXiv preprint arXiv:2412.15115.
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300.
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A. J., Welihinda, A., Hayes, A., Radford, A., et al. (2024). GPT-4o system card. arXiv preprint arXiv:2410.21276.
Zhuofeng Li, Haoxiang Zhang, Seungju Han, Sheng Liu, Jianwen Xie et al. (2025) In-the-flow agentic system optimization for effective planning and tool use. arXiv preprint arXiv:2510.05592v1.

