
En la era dorada de la inteligencia artificial, una fuerza silenciosa pero colosal impulsa los avances que transforman nuestro mundo: los datos. Desde el reconocimiento facial en nuestros teléfonos hasta los sistemas de recomendación que adivinan nuestros gustos, cada paso adelante de la IA se asienta sobre vastas montañas de información. Sin embargo, no cualquier dato sirve. Para entrenar a la mayoría de los modelos de IA más potentes, necesitamos datos «etiquetados» o «anotados». Esto significa que cada imagen debe indicar lo que contiene (un gato, un coche, una persona), cada frase debe especificar su significado o intención, y cada registro de audio debe transcribirse con precisión.
La creación de estos conjuntos de datos etiquetados es un trabajo ingente, costoso y a menudo tedioso. Requiere ejércitos de anotadores humanos, que dedican horas a revisar y clasificar información. Es un cuello de botella, una barrera que ralentiza la innovación y limita el despliegue de la IA en nuevos dominios donde los datos etiquetados son escasos o inexistentes. Imaginemos, por ejemplo, intentar crear un sistema de IA para diagnosticar una enfermedad rara: ¿quién etiquetaría suficientes imágenes médicas de esa condición, si apenas hay casos documentados? La dependencia de este «oro etiquetado» es una de las grandes limitaciones de la inteligencia artificial moderna.
Pero, ¿y si pudiéramos romper esa dependencia? ¿Y si la propia inteligencia artificial pudiera generar sus propias etiquetas, su propia supervisión, a partir de datos crudos y sin procesar? Esto suena a ciencia ficción, a una máquina que no solo aprende, sino que decide qué aprender y cómo evaluarse a sí misma. Un reciente y fascinante estudio, Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision (La Computación como Maestra: Convirtiendo el Cómputo de Inferencia en Supervisión sin Referencia), arroja una luz prometedora sobre esta revolucionaria idea.
La investigación plantea una visión audaz: la capacidad de cómputo, es decir, el poder de procesamiento que usamos para ejecutar nuestros modelos de IA una vez entrenados (la fase de «inferencia»), puede ser convertida en una forma de «supervisión» o «enseñanza» para otros modelos. En otras palabras, la propia IA, a través de cálculos ingeniosos y redundantes, puede generar sus propias «respuestas correctas» para el entrenamiento. Esto elimina la necesidad de los costosos y laboriosos datos etiquetados por humanos, abriendo la puerta a una IA mucho más autónoma, escalable y versátil.
El estudio nos invita a reimaginar el ciclo de vida del desarrollo de la IA. En lugar de depender de la intervención humana para la curación de datos, los modelos podrían aprender de la misma «máquina maestra», utilizando sus propias capacidades de inferencia para generar un flujo interminable de conocimiento. Esta propuesta no solo tiene implicaciones técnicas profundas, sino que redefine nuestra comprensión de cómo la inteligencia artificial puede adquirir conocimiento, liberándose progresivamente de la mano que la alimenta. Es un paso hacia una IA más autosuficiente, capaz de explorar y aprender de forma independiente, superando uno de los mayores obstáculos para su expansión.
El cuello de botella de los datos etiquetados: Un desafío persistente
Para entender la magnitud de lo que propone «Compute as Teacher», es esencial primero comprender el problema que busca resolver: el persistente cuello de botella de los datos etiquetados. En la actualidad, la mayoría de los éxitos de la inteligencia artificial se deben a los modelos de «aprendizaje supervisado». Este enfoque se basa en alimentar a la IA con vastos conjuntos de datos donde cada entrada tiene una «etiqueta» o «respuesta correcta» asociada.
Pensemos en algunos ejemplos concretos:
- Visión por computadora: Si queremos entrenar una IA para reconocer perros, le mostramos miles o millones de imágenes de perros, cada una «etiquetada» como «perro». También le mostramos imágenes de gatos, coches, árboles, etc., cada una con su etiqueta correspondiente. La IA aprende a asociar patrones visuales con esas etiquetas.
- Procesamiento del lenguaje natural: Para que un modelo detecte si un correo electrónico es spam, se le muestran miles de correos, algunos marcados como «spam» y otros como «no spam». Si queremos que traduzca frases, se le dan pares de frases en dos idiomas, una «etiquetada» como la traducción correcta de la otra.
- Sistemas de recomendación: Para sugerir películas, la IA aprende de un historial de usuarios y sus valoraciones, donde cada valoración es una «etiqueta» de preferencia.
El proceso de etiquetado es laborioso y caro. En muchos casos, se requiere personal especializado (médicos para imágenes de rayos X, lingüistas para traducciones complejas) y la intervención de varios anotadores para garantizar la calidad y la consistencia de las etiquetas. Grandes empresas como Google, Meta o Amazon invierten miles de millones en la creación y mantenimiento de estos datasets. Para startups, investigadores o empresas en nichos de mercado con datos escasos, esta barrera es casi insuperable.
Además del costo, hay otras limitaciones:
- Sesgo humano: Las etiquetas reflejan los sesgos de los anotadores. Si un grupo demográfico está subrepresentado en los datos o si los anotadores tienen prejuicios inconscientes, la IA aprenderá esos sesgos, lo que puede llevar a decisiones injustas o erróneas.
- Escalabilidad: A medida que los modelos de IA se vuelven más grandes y complejos, y a medida que exploramos nuevos problemas, la necesidad de datos etiquetados crece exponencialmente. La capacidad humana para generar estas etiquetas no puede seguir el ritmo.
- Dominios especializados: En campos como la ciencia, la medicina o la ingeniería, la cantidad de datos etiquetados es inherentemente limitada. Desarrollar IA para estas áreas es extremadamente difícil sin nuevas fuentes de supervisión.
En resumen, los datos etiquetados son el combustible de la IA moderna, pero su escasez, costo y limitaciones han frenado el progreso. La búsqueda de métodos que permitan a la IA aprender con menos dependencia de la supervisión humana se ha convertido en una de las áreas más candentes de la investigación, y es aquí donde «Compute as Teacher» ofrece una solución verdaderamente innovadora.
La inferencia como fuente de verdad: El giro conceptual
La idea central de «Compute as Teacher» es un cambio de perspectiva fundamental en cómo entendemos la computación. Tradicionalmente, distinguimos entre el entrenamiento de un modelo de IA (la fase en la que aprende de los datos) y la inferencia (la fase en la que el modelo ya entrenado realiza predicciones o toma decisiones). La inferencia es el «uso» del modelo, la aplicación de su conocimiento. El estudio propone que esta fase de uso, esta «computación de inferencia», puede ser, paradójicamente, una fuente de enseñanza.
¿Cómo es posible? El concepto clave es utilizar el propio modelo de IA, o una versión de él, para generar etiquetas para datos no etiquetados. Es decir, el modelo no solo predice, sino que esas predicciones, bajo ciertas condiciones, se tratan como la «verdad» que otros modelos (o el mismo modelo en una fase posterior) usarán para aprender.
Imaginemos que tenemos un modelo de IA ya entrenado y muy bueno en una tarea, como reconocer objetos en imágenes (el «modelo maestro» o «profesor»). Tenemos luego una gran cantidad de imágenes nuevas, sin etiquetar, para las cuales no tenemos la «respuesta correcta» humana. «Compute as Teacher» sugiere que podemos usar el modelo maestro para generar etiquetas para todas esas imágenes. Estas etiquetas generadas por la IA se convierten en la «supervisión» para entrenar a un «modelo estudiante» más pequeño, más eficiente o para mejorar el propio modelo maestro.
Esto se diferencia de métodos anteriores como el pseudo-labeling (pseudoetiquetado) en un aspecto crucial: no depende de un pequeño conjunto inicial de datos humanos etiquetados para «sembrar» el proceso. En «Compute as Teacher», la supervisión se genera sin referencia externa. La verdad proviene de la propia computación del modelo, de su capacidad intrínseca para procesar información.
Pensemos en un escenario. Tenemos un modelo de IA ya muy potente que reconoce si un animal es un gato o un perro. Ahora, se nos presenta una inmensa colección de fotos de animales sin ninguna etiqueta. En lugar de que un humano las clasifique, le pedimos a nuestro modelo ya entrenado que lo haga. El modelo clasifica el 90% de las fotos con gran confianza. Estas clasificaciones del modelo se convierten en las «pseudo-etiquetas» para entrenar a una nueva versión del modelo, o incluso a un modelo más pequeño y eficiente. Si el modelo maestro está suficientemente seguro de sus predicciones, estas actúan como una forma de verdad para el aprendizaje.
Este «giro» conceptual es liberador. Significa que el costo computacional que ya invertimos en el desarrollo y la ejecución de modelos de IA puede ser reciclado, transformado en una valiosa fuente de supervisión. La computación se convierte en un recurso pedagógico, en un «maestro» incansable y siempre disponible. Esto abre la puerta a un aprendizaje de IA que no está limitado por la disponibilidad de datos etiquetados por humanos, sino por la capacidad de cómputo y la inventiva de los algoritmos.
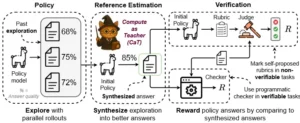
Estrategias para la autoprofesión: Cómo la IA se enseña a sí misma
El estudio «Compute as Teacher» explora varias estrategias ingeniosas para que la inteligencia artificial se genere su propia supervisión sin necesidad de referencias externas. Estas técnicas giran en torno a la idea de usar el poder de inferencia del modelo de manera inteligente para construir su propio conocimiento.
Una de las estrategias clave es la autoconsistencia. La idea es que si un modelo es realmente bueno en una tarea, sus predicciones deberían ser consistentes incluso bajo pequeñas variaciones o «perturbaciones» en los datos de entrada. Si un modelo identifica un gato en una imagen, y luego se le muestra la misma imagen con un ligero desenfoque o una pequeña rotación, debería seguir identificando un gato. Si es consistente, su predicción es más fiable.
Los investigadores utilizan esto de la siguiente manera:
- Generación de predicciones perturbadas: Se toma una imagen (o cualquier dato de entrada) sin etiquetar y se le aplican múltiples pequeñas perturbaciones (ligeros cambios, ruidos, etc.). Cada versión perturbada se pasa por el modelo.
- Verificación de la consistencia: Si el modelo produce la misma predicción (por ejemplo, «gato») para todas o la mayoría de las versiones perturbadas de la imagen, esa predicción se considera una «pseudo-etiqueta» de alta confianza.
- Filtrado y entrenamiento: Solo las pseudo-etiquetas de alta confianza (las que muestran autoconsistencia) se utilizan para entrenar o refinar el modelo. Esto asegura que el «maestro» (la computación de inferencia) solo proporcione lecciones en las que está muy seguro.
Otra estrategia importante es la generación adversarial. Este enfoque, inspirado en las Redes Generativas Adversarias (GANs), involucra a dos modelos que se «enfrentan» entre sí. En este contexto, un modelo (el «generador») crea nuevas instancias de datos (por ejemplo, imágenes sintéticas) y otro modelo (el «discriminador») intenta determinar si esas instancias son reales o generadas. Cuando el generador mejora en la creación de datos indistinguibles de los reales, indirectamente está generando datos que pueden ser usados para entrenar otras partes del sistema o para mejorar la robustez del modelo. Aunque más complejo, este método permite a la IA expandir su conocimiento de un dominio de datos de forma autónoma.
Además de estas, el estudio también explora la diversidad de predicción. En lugar de usar un solo modelo para generar etiquetas, se pueden usar varios modelos ligeramente diferentes (quizás entrenados con distintos subconjuntos de datos o con arquitecturas distintas). Si múltiples modelos independientes, pero bien entrenados, convergen en la misma predicción para un dato no etiquetado, esa predicción gana mucha más credibilidad y puede usarse como supervisión. Es como tener varios profesores expertos que coinciden en la respuesta de un problema.
Estas estrategias, aplicadas de forma inteligente, transforman la computación de inferencia en una fuente rica y constante de supervisión. La IA, de hecho, se convierte en su propio maestro, explorando el espacio de datos sin etiquetar y generando su propio «currículo» de aprendizaje. Esto no solo reduce la dependencia de los humanos, sino que también permite a la IA aprender de formas que quizás los humanos no habrían considerado, llevando a la emergencia de nuevas capacidades y soluciones.
Más allá de la teoría: Demostraciones y experimentos
Para validar sus audaces afirmaciones, los investigadores de «Compute as Teacher» llevaron a cabo una serie de experimentos rigurosos en diferentes dominios de la inteligencia artificial. Las pruebas estaban diseñadas para demostrar que las pseudo-etiquetas generadas por la propia computación de inferencia podían ser tan efectivas (o incluso más) que las etiquetas humanas para entrenar modelos.
Uno de los dominios clave donde se probó el concepto fue la visión por computadora, específicamente en tareas de clasificación de imágenes. Se utilizó un modelo «maestro» ya bien entrenado para generar pseudo-etiquetas para un vasto conjunto de imágenes sin etiquetar. Luego, estas pseudo-etiquetas se usaron para entrenar un modelo «estudiante» desde cero o para refinar un modelo existente. Los resultados mostraron que el modelo estudiante entrenado con esta supervisión generada por la IA alcanzaba niveles de precisión comparables a los modelos entrenados con etiquetas humanas, e incluso superiores en algunos escenarios donde la cantidad de datos sin etiquetar era muy grande. Esto sugiere que la autoconsistencia y la diversidad de predicción permiten filtrar las pseudo-etiquetas de mayor calidad, creando un corpus de entrenamiento auto-supervisado eficaz.
Otro campo de aplicación explorado fue el procesamiento del lenguaje natural. Se probaron tareas como la clasificación de texto (por ejemplo, identificar el sentimiento de una reseña como positivo o negativo) o la detección de entidades nombradas (reconocer nombres de personas, lugares, organizaciones en un texto). De manera similar, un LLM actuó como maestro, generando pseudo-etiquetas para textos sin anotar. El rendimiento de los modelos entrenados con esta supervisión generada por la IA fue competitivo, lo que indica que la «computación como maestra» no se limita solo a datos visuales, sino que también es aplicable a la complejidad del lenguaje.
Los experimentos también abordaron el problema del ruido en las pseudo-etiquetas. Es natural que un modelo, al generar sus propias etiquetas, cometa errores. Los investigadores diseñaron algoritmos para mitigar este ruido, priorizando las pseudo-etiquetas de alta confianza (aquellas con alta autoconsistencia o consenso entre múltiples modelos). Este filtrado resultó ser crucial para asegurar que la «enseñanza» de la IA fuera de alta calidad y no introdujera errores sistemáticos.
Un hallazgo particularmente interesante fue que, en algunos casos, el entrenamiento con supervisión generada por la IA podía incluso superar al entrenamiento con un número limitado de etiquetas humanas. Esto se debe a que la IA puede generar un volumen mucho mayor de pseudo-etiquetas que la cantidad que los humanos podrían producir, y si bien algunas pueden ser ruidosas, el gran volumen de datos de alta confianza compensa esta debilidad, permitiendo al modelo estudiante aprender patrones más robustos y generalizables.
Estas demostraciones empíricas no solo validan la teoría detrás de «Compute as Teacher», sino que también proporcionan un camino práctico para implementar esta técnica en diversas aplicaciones de IA. Estamos viendo el nacimiento de un nuevo paradigma donde la escala y la autonomía del aprendizaje de la IA ya no están limitadas por la labor humana, sino por la capacidad de cómputo y la sofisticación de los algoritmos de auto-supervisión.
Implicaciones y el futuro: Un paso hacia la autosuficiencia de la IA
El estudio «Compute as Teacher» no es solo una curiosidad académica; es un trabajo con profundas implicaciones para la dirección futura de la inteligencia artificial y su impacto en la sociedad. Marca un hito significativo en la búsqueda de una IA más autosuficiente, capaz de aprender y evolucionar con una menor dependencia de la intervención humana.
Implicaciones tecnológicas y científicas:
- Aceleración del desarrollo de IA: Al eliminar el cuello de botella de los datos etiquetados, este enfoque puede acelerar drásticamente el desarrollo de nuevos modelos de IA, especialmente en dominios donde los datos son escasos o costosos de etiquetar (como la medicina, la ciencia de materiales, la exploración espacial).
- IA para dominios especializados: Permite el desarrollo de IA en campos muy específicos donde la creación manual de datasets etiquetados es inviable. Un modelo de IA podría, por ejemplo, aprender a clasificar nuevas especies de plantas o a identificar patrones en datos astronómicos con muy poca supervisión humana.
- Reducción de costos: Los costos asociados al etiquetado de datos son enormes. Al automatizar este proceso a través de la computación, se pueden liberar vastos recursos financieros y humanos, que pueden ser redirigidos hacia la investigación y el desarrollo de IA de mayor nivel.
- Mejora de la robustez y generalización: Al entrenar con vastos volúmenes de pseudo-etiquetas generadas bajo diversas condiciones (con perturbaciones, etc.), los modelos pueden volverse más robustos y capaces de generalizar mejor a situaciones nuevas o inesperadas.
- Un paso hacia la IA autónoma: Este trabajo es un escalón importante hacia sistemas de IA que no solo aprenden de los datos existentes, sino que también generan sus propios datos de entrenamiento, diseñan sus propios experimentos y, en última instancia, aprenden de forma continua e independiente. Es un paso hacia una IA que puede explorar el mundo por sí misma.
Implicaciones sociales y éticas:
- Reducción de sesgos: Si bien los modelos iniciales aún reflejarán sesgos de sus datos de entrenamiento originales, la capacidad de generar supervisión sin referencia podría, en teoría, permitir la creación de datasets más equilibrados y diversos de manera autónoma, si se diseñan las estrategias de autoprofesión con esa meta.
- Impacto en el empleo: La automatización del etiquetado de datos afectará a los trabajos de anotación. Sin embargo, también creará nuevas oportunidades en el diseño y la supervisión de estos «maestros» de IA.
- Fiabilidad y control: A medida que la IA se vuelve más autosuficiente, surgen preguntas sobre el control humano. ¿Cómo garantizamos que la IA se «enseña» a sí misma de manera segura y ética si no hay una referencia externa constante? La capacidad de auditar y comprender los procesos de auto-supervisión será crucial.
- Desarrollo asimétrico: Si el acceso a la computación masiva y a la investigación en este campo sigue siendo patrimonio de unas pocas grandes corporaciones, podría acentuar la brecha tecnológica entre quienes pueden permitirse crear sus propios «maestros» de IA y quienes no.
El trabajo «Compute as Teacher» nos obliga a repensar la naturaleza de la supervisión y del aprendizaje. Nos muestra que la propia capacidad de una máquina para procesar información puede ser una fuente de conocimiento para sí misma, en un bucle virtuoso de auto-mejora. Es una visión donde la IA no solo imita el aprendizaje humano, sino que desarrolla su propia pedagogía, rompiendo las cadenas de nuestra dependencia de los datos etiquetados. Estamos en el umbral de una era en la que el poder computacional no solo ejecuta algoritmos, sino que los educa, forjando el camino hacia inteligencias artificiales más autónomas y capaces.
El futuro de la sabiduría computacional
La metáfora de la inteligencia artificial como un «cerebro» ha sido recurrente, pero quizás incompleta. Con «Compute as Teacher», la IA no es solo un cerebro; es también un maestro y un estudiante, todo en uno. Este estudio nos presenta un futuro en el que los modelos de IA no solo aprenden de lo que les damos, sino que también aprenden de lo que hacen, de su propia inferencia, de su propia «experiencia computacional».
Esta independencia en la adquisición de conocimiento representa un avance fundamental. La IA podría liberarse de las limitaciones de los datasets finitos y sesgados, y comenzar a explorar el vasto e inexplorado territorio de los datos sin etiquetar con una autonomía sin precedentes. Esto podría llevar al descubrimiento de patrones y conocimientos que ni siquiera los humanos habíamos concebido.
El viaje hacia la IA general, aquella que puede aprender cualquier tarea intelectual que un humano, es largo y complejo. Pero cada vez que encontramos una forma de reducir la dependencia de la labor humana en el ciclo de aprendizaje, damos un paso gigantesco. «Compute as Teacher» es uno de esos pasos. Nos recuerda que el potencial de la computación va mucho más allá de la mera ejecución de instrucciones; reside en su capacidad para generar su propia sabiduría, transformándose en el arquitecto de su propio conocimiento. Es un emocionante capítulo en la historia de la inteligencia artificial, un capítulo donde la máquina, por primera vez, asume el rol de su propia maestra.
Referencias
Chen, P., Li, C., & Zhang, Y. (2025). Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision (No. arXiv:2509.14234). arXiv. https://arxiv.org/pdf/2509.14234
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). ImageNet Classification with Deep Convolutional Neural Networks. Communications of the ACM, 60(6), 84-90. (Originalmente publicado en 2012)
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback (No. arXiv:2203.02155). arXiv. https://doi.org/10.48550/arXiv.2203.02155
Radford, A., Kim, J. W., Xu, T., Brockman, G., McAlear, C., & Sutskever, I. (2023). Robust Speech Recognition via Large-Scale Weak Supervision. arXiv. (Originalmente publicado en 2022, revisado) https://arxiv.org/abs/2212.11585
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need (No. arXiv:1706.03762). arXiv. https://doi.org/10.48550/arXiv.1706.03762
Xie, Q., Dai, E., Hovy, E., & Liu, X. (2020). Unsupervised Data Augmentation for Consistency Training. arXiv. https://doi.org/10.48550/arXiv.1904.12848

