
Durante décadas, el progreso científico ha seguido un patrón predecible. Un investigador identifica un problema, formula una hipótesis, diseña experimentos, interpreta resultados, fracasa repetidamente y, si tiene suerte, consigue un pequeño avance que mueve la frontera del conocimiento unos milímetros hacia adelante. Este proceso, tedioso y costoso, es la esencia misma de la ciencia. La historia de la tecnología está repleta de ejemplos: los transistores que tardaron décadas en reducir su tamaño de micrómetros a nanómetros, las células fotovoltaicas que requirieron medio siglo de optimización incremental para acercarse a sus límites teóricos de eficiencia. El ritmo del descubrimiento ha estado, hasta ahora, inexorablemente ligado al ritmo del pensamiento humano.
Pero un grupo de investigadores de la Universidad de Westlake en China ha desarrollado un sistema que desafía esta premisa fundamental. Su creación, denominada DeepScientist, no es simplemente otra herramienta de asistencia para científicos ni un algoritmo que optimiza métodos existentes.
Es un sistema autónomo capaz de conducir ciclos completos de investigación científica durante semanas o meses, generando miles de hipótesis, validando experimentalmente cientos de ellas, y produciendo descubrimientos que superan significativamente los mejores métodos diseñados por humanos. En un experimento particularmente revelador, DeepScientist logró en apenas dos semanas un progreso comparable a tres años de investigación humana en el campo de la detección de texto generado por inteligencia artificial.
Esta afirmación, que podría sonar a ciencia ficción o exageración promocional, está respaldada por evidencia empírica rigurosa. El sistema consumió más de veinte mil horas de GPU, generó aproximadamente cinco mil ideas científicas únicas, validó experimentalmente cerca de mil cien de ellas, y finalmente produjo métodos que superaron el estado del arte humano en tres tareas fronterizas de investigación en inteligencia artificial: atribución de fallos en sistemas multi-agente (mejora del 183.7%), aceleración de inferencia en modelos de lenguaje (mejora del 1.9%), y detección de texto generado por IA (mejora del 7.9%). Estos porcentajes no representan simples ajustes paramétricos o combinaciones ingeniosas de técnicas existentes, sino rediseños metodológicos fundamentales que abordan limitaciones conceptuales que los investigadores humanos no habían resuelto.
Para comprender la magnitud de este avance, conviene primero entender el contexto. Los modelos lingüísticos de gran escala han propiciado recientemente la emergencia de sistemas denominados «científicos artificiales» o «AI Scientist». Estos sistemas, equipados con la capacidad de generar y comprender texto extenso, pueden teoricamente manejar ciclos completos de investigación: desde la formulación de hipótesis hasta la redacción de artículos científicos.
Trabajos previos han demostrado que estos sistemas pueden producir hallazgos novedosos, e incluso han logrado publicaciones en talleres de conferencias de primer nivel. Sin embargo, enfrentan una limitación fundamental y sistemática: en ausencia de objetivos científicos claramente definidos, tienden a caer en la trampa de recombinar conocimiento existente de manera naive. Sus resultados, cuando son evaluados por humanos, frecuentemente aparecen como triviales, careciendo de genuino valor científico.
El problema es conceptual, no técnico. Estos sistemas anteriores exploran sin rumbo, generando variaciones de métodos conocidos sin abordar los desafíos centrales que mantienen despiertos a los investigadores humanos. Es como si un científico decidiera mezclar aleatoriamente ingredientes en un laboratorio esperando descubrir algo útil, en lugar de identificar primero un problema importante y diseñar experimentos específicos para resolverlo. La diferencia entre exploración aleatoria y exploración dirigida es la diferencia entre ruido y progreso científico genuino.
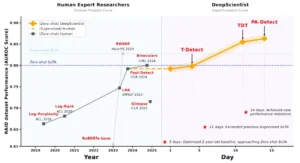
Comparación de los plazos de investigación para la detección de texto con IA en RAID . El panel derecho muestra que DeepScientist logra un progreso en dos semanas, comparable a tres años de investigación en humanos (panel izquierdo). Todos los métodos de disparo cero, incluidos los generados por el sistema T-Detect, TDT y PA-Detect, adoptan uniformemente Falcon-7B como modelo base. Además, todos los métodos producidos por DeepScientist demuestran un mayor rendimiento que el método SOTA anterior, Binoculars.
El problema fundamental del descubrimiento autónomo
DeepScientist aborda esta limitación mediante una reformulación matemática elegante del proceso científico. Los investigadores modelan el descubrimiento completo como un problema de Optimización Bayesiana, donde el objetivo singular es encontrar un método novedoso que maximice una métrica de rendimiento específica. Esta formalización transforma la búsqueda científica en la exploración de un espacio conceptual vasto e inestructurado de posibles métodos candidatos, donde cada uno posee un valor científico intrínseco determinado por una función latente y extremadamente costosa de evaluar.
Aquí radica el desafío distintivo del descubrimiento científico fronterizo frente a otros problemas de optimización previamente estudiados. A diferencia del diseño algorítmico rutinario o el desarrollo de software científico, donde las evaluaciones son relativamente económicas, cada paso exploratorio en ciencia fronteriza demanda recursos computacionales e intelectuales inmensos.
Evaluar si una hipótesis científica es valiosa requiere implementarla completamente, ejecutar experimentos exhaustivos y analizar resultados, un proceso que puede consumir del orden de diez elevado a dieciséis operaciones de punto flotante para un problema fronterizo típico en modelos de lenguaje. Esta extrema ineficiencia muestral hace que la exploración por fuerza bruta o aleatoria sea completamente impracticable.
La Optimización Bayesiana ofrece un marco principiado para la optimización global de funciones de caja negra costosas, construyendo un modelo sustituto que guía inteligentemente la búsqueda y reduce el número de evaluaciones reales necesarias mediante un balance cuidadoso entre exploración y explotación. Sin embargo, para el descubrimiento científico, el espacio de búsqueda no está explícitamente definido.
Los métodos candidatos deben formularse como hipótesis científicas creativas, plausibles y coherentes. La generación de hipótesis de alta calidad constituye un cuello de botella crítico que los algoritmos tradicionales de Optimización Bayesiana no están diseñados para abordar. Esta es la brecha que DeepScientist cierra mediante una arquitectura innovadora.
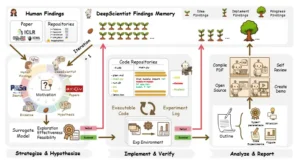
El proceso de descubrimiento autónomo y de circuito cerrado de DeepScientist. El sistema itera a través de un ciclo de tres etapas, aprendiendo tanto del conocimiento humano como de sus propios experimentos.
Anatomía de un científico artificial
La arquitectura de DeepScientist materializa el bucle de Optimización Bayesiana mediante un sistema multi-agente equipado con un sistema de conocimiento abierto y una Memoria de Hallazgos que se expande continuamente. Esta memoria, compuesta tanto de conocimiento humano fronterizo como de los propios hallazgos históricos del sistema, guía inteligentemente las exploraciones subsiguientes. El proceso completo de descubrimiento se estructura como un ciclo exploratorio iterativo y jerárquico de tres etapas.
En este esquema jerárquico, solo las ideas que exhiben promesa son avanzadas a evaluaciones más costosas, mientras que otras se retienen en la Memoria de Hallazgos para informar exploraciones posteriores. Este diseño garantiza que los recursos computacionales se asignen dinámica y precisamente a las trayectorias científicas más prometedoras.
La primera etapa, denominada Estrategizar e Hipotetizar, inicia cada ciclo de investigación analizando la Memoria de Hallazgos, una base de datos estructurada que contiene miles de registros. Cada registro representa un hallazgo científico único, categorizado según su etapa de desarrollo. Para superar las limitaciones de longitud de contexto de los modelos lingüísticos, el sistema emplea un modelo de recuperación separado que selecciona los hallazgos más relevantes como entrada.
La vasta mayoría de registros comienzan como Hallazgos de Idea, hipótesis no verificadas. Durante esta primera fase, el sistema identifica limitaciones en el conocimiento existente y genera una nueva colección de hipótesis, que luego son evaluadas por un Modelo Sustituto de bajo costo: un modelo lingüístico actuando como revisor.
Este revisor, contextualizado con toda la Memoria de Hallazgos, aproxima la verdadera función de valor científico y produce para cada hallazgo candidato un vector de valuación estructurado que cuantifica su utilidad estimada, calidad y valor exploratorio mediante puntuaciones enteras en una escala de cero a cien. Cada nueva hipótesis y su vector de valuación se utilizan entonces para inicializar un nuevo registro en la Memoria de Hallazgos como un Hallazgo de Idea. Esta evaluación preliminar es fundamental: permite al sistema descartar rápidamente ideas que, aunque novedosas, probablemente no conducirán a avances significativos.
La segunda etapa, Implementar y Verificar, sirve como el filtro primario en la Memoria de Hallazgos. Para decidir cuál de los numerosos Hallazgos de Idea merece la inversión significativa de recursos para avanzar a un experimento real, el sistema emplea una Función de Adquisición. Específicamente, utiliza el clásico algoritmo Upper Confidence Bound para seleccionar el registro más prometedor, mapeando el vector de valuación para balancear el compromiso entre explotar avenidas prometedoras y explorar las inciertas. El hallazgo con mayor puntuación es seleccionado para validación, y su registro se promociona al estatus de Hallazgo de Implementación.
Un agente de codificación entonces realiza una implementación a nivel de repositorio completo para ejecutar el experimento. Este agente opera dentro de un ambiente aislado con permisos completos, permitiéndole leer el repositorio de código completo y acceder a internet para búsquedas de literatura y código.
Su objetivo es implementar la nueva hipótesis sobre los repositorios del método estado del arte existente. El agente típicamente comienza planificando la tarea, luego lee el código para entender su estructura, y finalmente implementa los cambios para producir los registros y resultados experimentales. Estos resultados se utilizan para actualizar el registro correspondiente, enriqueciéndolo con evidencia empírica y cerrando así el bucle de aprendizaje.
La etapa final, Analizar y Reportar, es la más selectiva y solo se activa mediante una validación exitosa. Cuando un Hallazgo de Implementación logra superar la línea base, su registro se promociona a Hallazgo de Progreso. Esta transformación se implementa mediante una serie de agentes especializados capaces de utilizar un conjunto de herramientas de protocolo de contexto de modelo.
Estos agentes primero diseñan y ejecutan autónomamente una serie de experimentos analíticos más profundos, como ablaciones y evaluaciones en nuevos conjuntos de datos, aprovechando herramientas para gestionar el ciclo de vida experimental, la recolección de datos y el análisis de resultados. Posteriormente, un agente de síntesis emplea el mismo conjunto de herramientas para recopilar todos los resultados experimentales, perspectivas analíticas y artefactos generados en un artículo de investigación coherente y reproducible.
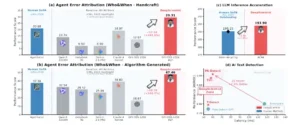
Evaluación del rendimiento de DeepScientist en tres áreas de investigación: (a-b) Atribución de fallos del agente según el parámetro Who&When en entornos artesanales y generados por algoritmos; (c) Aceleración de la inferencia LLM en el conjunto de datos MBPP; (d) Detección de texto con IA con análisis de equilibrio entre rendimiento y latencia. DeepScientist (mostrado en rosa) supera consistentemente a los enfoques SoTA diseñados por humanos (mostrados en azul) en todas las tareas.
Tres experimentos, tres victorias
Para validar las capacidades de DeepScientist, los investigadores seleccionaron tres métodos estado del arte publicados en conferencias de primer nivel durante 2024 y 2025, elegidos por su estatus fronterizo, interés comunitario y supervisabilidad humana. Cada método fue reproducido manualmente, preservando registros de ejecución y scripts de prueba para permitir a DeepScientist enfocarse en el avance de la investigación. El sistema recibió acceso a dos servidores, cada uno con ocho GPUs Nvidia H800, consumiendo en total más de veinte mil horas de GPU durante el proceso completo.
En la primera tarea, atribución de fallos en agentes, el desafío consiste en determinar, dentro de un sistema multi-agente basado en modelos de lenguaje, qué agente causó el fallo de la tarea y cuándo ocurrió. Comenzando desde el método base denominado All at Once, DeepScientist identificó que el enfoque actual carecía de las capacidades de razonamiento contrafactual esenciales para la atribución.
A través de un proceso de prueba, error y síntesis de nuevos hallazgos, descubriendo la efectividad de la predicción hipotética y los intentos simulados, finalmente propuso el método A2P. Nombrado por su proceso de Abducción-Acción-Predicción, su innovación central eleva la atribución de fallos desde reconocimiento de patrones hacia razonamiento causal, llenando la brecha crítica en capacidades contrafactuales al predecir si una corrección propuesta habría conducido al éxito.
El método logró puntuaciones de 29.31 y 47.46 en los escenarios de referencia «handcraft» y «algorithm-generated» respectivamente, estableciendo un nuevo estado del arte. DeepScientist validó que un marco estructurado de razonamiento causal sin entrenamiento previo puede ser superior a métodos menos principiados. Hasta septiembre de 2025, el método A2P sin entrenamiento mantiene su posición estado del arte, superando incluso modelos de siete mil millones de parámetros entrenados en datos sintéticos.
La segunda tarea, aceleración de inferencia en modelos de lenguaje, representa un campo altamente optimizado que busca maximizar el rendimiento y reducir la latencia durante la inferencia. En este proceso, el sistema realizó activamente numerosos intentos diferentes, como usar un Filtro de Kalman para ajustar dinámicamente una matriz de adyacencia para abordar la falta de función de memoria del método original. Aunque la mayoría de estos intentos fallaron, el método generado por el sistema denominado ACRA finalmente avanzó la métrica de rendimiento de un estado del arte humano de 190.25 a 193.90 tokens por segundo al identificar patrones de sufijo estables.
Científicamente, esta innovación es significativa porque utiliza esta información contextual extra para ajustar dinámicamente la suposición de decodificación, injertando efectivamente una memoria a largo plazo en el proceso y rompiendo el colapso contextual de los decodificadores estándar. Este descubrimiento subraya el objetivo primario del sistema: la creación de conocimiento nuevo desconocido por humanos, en lugar de mera optimización ingenieril. Aunque se podrían lograr mayores ganancias de rendimiento combinando ACRA con técnicas establecidas como salto de capas o PageAttention, esto representaría un esfuerzo de ingeniería, no científico.
La tercera tarea, detección de texto generado por IA, representa una clasificación binaria donde, dado un texto que puede contener contenido de un modelo de lenguaje, el objetivo es determinar si fue producido por un humano o una IA. Para validar su capacidad de avance sostenido, DeepScientist realizó numerosos intentos que incluyeron abordar el problema de Extensión Consciente de Límites y explorar enfoques como métodos de Volatilidad Consciente y Energía de Subespacio Wavelet. Los resultados finales muestran una aceleración dramática en el descubrimiento científico: en una evolución rápida durante apenas dos semanas, el sistema produjo tres métodos distintos y progresivamente superiores.
Comenzó con T-Detect corrigiendo estadísticas centrales con una distribución t robusta, luego evolucionó conceptualmente con TDT y PA-Detect, que tratan el texto como una señal y utilizan análisis de wavelet y congruencia de fase para identificar anomalías. Científicamente, este cambio revela la no estacionariedad del texto generado por IA, aliviando el cuello de botella informativo en paradigmas previos que promediaban y eliminaban evidencia localizada. Esta trayectoria completa de descubrimiento demuestra la capacidad de DeepScientist para avanzar hallazgos científicos fronterizos progresivamente, estableciendo un nuevo estado del arte con un 7.9% más de AUROC mientras duplica simultáneamente la velocidad de inferencia.
La calidad bajo escrutinio humano
Para evaluar la calidad de la producción final, los investigadores evaluaron los cinco artículos científicos generados autónomamente por el proceso completo de DeepScientist mediante un protocolo doble. Primero, para comparar contra trabajo existente, emplearon DeepReviewer, un agente de IA que simula el proceso de revisión por pares humano con capacidad de búsqueda externa, comparando la salida de DeepScientist contra veintiocho artículos disponibles públicamente de otros sistemas de científico artificial. Segundo, para una evaluación más rigurosa, convocaron un comité de programa dedicado consistente en tres investigadores activos de modelos de lenguaje: dos voluntarios que habían servido como revisores de ICLR y un voluntario senior invitado a ser Area Chair de ICLR.
Los resultados de la evaluación automática basada en modelo lingüístico indican que las salidas del sistema son reconocidas por su novedad y valor científico. Cuando se compara contra los veintiocho artículos disponibles públicamente de otros sistemas de científico artificial usando DeepReviewer, DeepScientist es el único sistema capaz de producir artículos que logran una tasa de aceptación del sesenta por ciento.
La evaluación del comité de expertos humanos revela un consenso notable y unánime: DeepScientist sobresale consistentemente en la ideación, el paso más desafiante y frecuentemente limitante en la investigación liderada por humanos. Las ideas centrales dentro de cada artículo son elogiadas por su genuina novedad, ingenio y contribuciones científicas. La calidad de estas innovaciones se demuestra además por las puntuaciones de revisión: la calificación promedio del sistema, cinco puntos sobre diez, refleja cercanamente el promedio de todas las presentaciones de ICLR 2025, con dos de sus artículos excediendo significativamente este promedio alcanzando 5.67.
Sin embargo, este éxito en la ideación fue sistemáticamente socavado por un patrón recurrente de debilidades en la ejecución científica y el rigor. La preocupación más crítica y frecuente fue una falta de solidez empírica. Los revisores notaron consistentemente que DeepScientist falló en diseñar planes de validación comprensivos, citando evaluación insuficiente en benchmarks estándar y una falta de experimentos analíticos profundos como ablaciones o estudios de motivación para justificar sus afirmaciones. Esto fue compuesto por un fallo en contextualizar apropiadamente sus contribuciones, con artículos frecuentemente omitiendo comparaciones con líneas base esenciales o fallando en discutir trabajo estrechamente relacionado.

Estadísticas experimentales de DeepScientist. (a) El proceso de investigación desde las ideas generadas hasta el progreso validado. (b) Tasas de éxito comparando nuestra estrategia de selección con una línea base. (c) Distribución de los tiempos de ejecución de reloj de pared para todos los ensayos implementados.
El análisis de cinco mil intentos
El análisis de los registros experimentales de DeepScientist revela la escala pura del proceso de prueba y error inherente al descubrimiento científico autónomo. Incluso en dominios relativamente rápidos de ejecutar, lograr progreso requirió cientos de pruebas por tarea. Las distribuciones de tiempo de ejecución muestran que aunque experimentos individuales pueden ser rápidos, el volumen puro de prueba y error necesario para descubrir una idea exitosa es sustancial.
Esto sugiere un límite de aplicación claro para la ciencia autónoma actual: para tareas con bucles de retroalimentación rápidos, delegar experimentación a escala masiva a IA es una estrategia poderosa. Sin embargo, para emprendimientos de alto costo como pre-entrenamiento de modelos fundacionales o síntesis farmacéutica, la baja tasa de éxito hace tal enfoque actualmente impracticable.
El proceso de investigación autónomo se caracteriza por un embudo exploratorio vasto donde las ideas prometedoras son excepcionalmente raras. A través de las tres tareas, DeepScientist generó más de cinco mil ideas únicas, pero solo aproximadamente mil cien fueron consideradas dignas de validación experimental por el mecanismo de selección del sistema, y apenas veintiuna finalmente resultaron en progreso científico.
Un estudio de ablación subraya la criticidad de este proceso de selección: sin él, muestreando aleatoriamente cien ideas por tarea y probándolas, se obtiene una tasa de éxito efectivamente de cero. Con la estrategia de selección implementada, la tasa de éxito asciende a aproximadamente uno a tres por ciento, demostrando que aunque todavía baja, el filtrado inteligente es esencial.
La baja tasa de éxito no es meramente cuestión de hipótesis fallidas. El análisis por expertos humanos de una muestra de pruebas fallidas revela que aproximadamente sesenta por ciento fueron terminadas prematuramente debido a errores de implementación, mientras que la vasta mayoría del cuarenta por ciento restante simplemente no ofrecieron mejora de rendimiento o causaron regresión. Esto subraya que la probabilidad de que una idea generada por modelo de lenguaje sea tanto correcta en su premisa como impecable en su implementación es excesivamente baja.
El proceso de descubrimiento de DeepScientist sigue una trayectoria propositiva y progresiva. La distribución semántica de ideas generadas para la tarea de detección de texto de IA, cuando se visualiza mediante reducción dimensional, revela las características de esta estrategia sofisticada. Aunque el sistema genera miles de ideas diversas a través de un paisaje conceptual vasto, su camino al éxito no es aleatorio sino una serie de avances enfocados y lógicos. Esto indica una capacidad para profundizar progresivamente su comprensión: después de lograr un avance inicial con T-Detect, el sistema efectivamente establece un estado del arte, identifica sus limitaciones subsiguientes y reorienta su búsqueda hacia un nuevo objetivo.
Para investigar la relación entre escala computacional y tasa de progreso científico, los investigadores evaluaron el número de Hallazgos de Progreso generados por DeepScientist dentro de un período fijo de una semana en función de recursos paralelos disponibles. Los resultados indican una tendencia de escalamiento prometedora. Mientras que recursos mínimos no produjeron avances, la tasa de descubrimiento comenzó a aumentar efectivamente al escalar a cuatro GPUs y más allá, creciendo de un hallazgo que supera el estado del arte con cuatro GPUs a once con dieciséis GPUs. Esto parece establecer una relación casi lineal entre los recursos asignados y la producción de descubrimientos científicos valiosos.
Implicaciones para el futuro de la ciencia
Los resultados de DeepScientist sugieren un nuevo paradigma en la exploración científica. La tasa de progreso del sistema del uno al cinco por ciento refleja la realidad de la investigación fronteriza, donde los avances son inherentemente raros. Su fortaleza central no es la infalibilidad, sino la capacidad de conducir este proceso de prueba y error a una escala y velocidad previamente inimaginables, comprimiendo años de exploración humana en semanas.
Este desafío resalta una oportunidad poderosa para sinergia humano-IA. Los investigadores visionan un futuro donde DeepScientist sirve como un motor de exploración a escala masiva, con su trayectoria guiada por intelecto humano. El rol de los investigadores humanos puede cambiar desde experimentación laboriosa hacia las tareas cognitivas de alto nivel de formular preguntas científicas valiosas y proporcionar dirección estratégica, aprovechando así la IA para exploración rápida y exhaustiva.
Sin embargo, las limitaciones son igualmente instructivas. El análisis revela que aproximadamente sesenta por ciento de los fracasos exploratorios se originaron en errores de implementación, no en hipótesis defectuosas. Esto señala hacia una verdad incómoda: la capacidad actual de los modelos de lenguaje para generar código correcto y completo es todavía el cuello de botella crítico. Mejorar la robustez de la implementación podría, paradójicamente, tener un impacto mayor en la eficiencia del descubrimiento que mejorar la calidad de la generación de hipótesis.
La retroalimentación de los revisores humanos también identifica una brecha sistemática entre ideación e ejecución rigurosa. El sistema sobresale en generar conceptos novedosos pero falla en diseñar validaciones comprensivas, realizar análisis profundos y contextualizar apropiadamente las contribuciones. Esta debilidad refleja una limitación fundamental de los modelos de lenguaje actuales: pueden simular la forma de la escritura científica pero carecen de la comprensión profunda del método científico que permite a los humanos anticipar críticas, diseñar controles apropiados y construir argumentos convincentes.
Las implicaciones éticas son igualmente profundas. Los investigadores conducieron ejercicios de equipo rojo específicamente dirigidos a la generación de virus informáticos, tasking al sistema con este objetivo malicioso. En todas las instancias, los modelos fundacionales subyacentes exhibieron alineación de seguridad robusta, rechazando proceder con la investigación. Correctamente identificaron la tarea como ilegal y dañina, y autónomamente terminaron el ciclo de investigación. Sin embargo, esta defensa depende enteramente de la alineación de los modelos base, una propiedad que podría erosionarse con futuras iteraciones o implementaciones alternativas.
Existe también el riesgo de degradación del ecosistema académico. La capacidad de generar artículos científicos aparentemente creíbles a escala masiva, sin supervisión humana rigurosa, podría inundar la literatura con trabajo no verificado o erróneo. Los investigadores abordan esto mediante una política de código abierto selectiva: liberarán los componentes centrales que impulsan el descubrimiento continuo, pero deliberadamente se abstendrán de abrir el módulo Analizar y Reportar. Esta decisión busca prevenir la generación automática de artículos científicamente no verificados, salvaguardando así la integridad del registro académico.
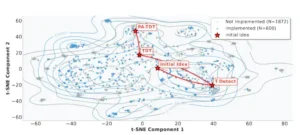
Visualización del espacio de búsqueda conceptual para la tarea de detección de texto con IA. El gráfico muestra una visualización t-SNE de las incrustaciones semánticas de las 2472 ideas generadas. Los marcadores identifican el método SOTA inicial (Idea Inicial) y los tres métodos finales que superan el SOTA (Ideas de Progreso).
Reflexión sobre una frontera que se mueve
DeepScientist representa más que un avance técnico. Encarna una transición fundamental en cómo concebimos la relación entre inteligencia artificial y descubrimiento científico. Durante décadas, las herramientas computacionales han acelerado aspectos específicos de la investigación: simulaciones más rápidas, análisis de datos más sofisticados, visualizaciones más claras. Pero el núcleo creativo, la formulación de hipótesis y el diseño de experimentos para probarlas, permaneció firmemente en dominio humano. DeepScientist comienza a erosionar esta distinción.
La pregunta central ya no es si la IA puede innovar científicamente, sino cómo podemos guiar eficientemente su poderoso pero altamente disipativo proceso exploratorio para maximizar el retorno científico. La tasa de éxito del uno al tres por ciento no es un fallo del sistema, es una característica de la ciencia fronteriza. Lo notable es que DeepScientist puede sostener este nivel de exploración fallida durante semanas sin desmoralizarse, sin fatiga, sin necesidad de financiamiento renovado cada año. Puede probar mil hipótesis donde un equipo humano probaría diez.
Esta capacidad transforma la economía del descubrimiento científico. Problemas que requieren exploración exhaustiva de espacios de diseño vastos, donde la intuición humana proporciona poca guía y la única ruta es probar sistemáticamente variaciones, se vuelven tractables. Campos donde el ciclo de retroalimentación experimental es rápido, donde se puede saber en horas o días si una hipótesis funciona, se beneficiarán desproporcionadamente. Química computacional, diseño de algoritmos, optimización de arquitecturas de redes neuronales, estos dominios podrían ver aceleración dramática.
Simultáneamente, la baja tasa de éxito establece límites claros. Problemas donde cada experimento consume semanas o meses, entrenar modelos fundacionales masivos o diseñar nuevos medicamentos que requieren síntesis y pruebas biológicas, permanecen fuera del alcance de la exploración autónoma masiva. Para estos dominios, el rol de DeepScientist será diferente: no exploración exhaustiva sino asistencia enfocada, generando hipótesis candidatas que humanos seleccionan cuidadosamente para validación costosa.
Los papers generados por DeepScientist, evaluados favorablemente por revisores humanos expertos, sugieren otra posibilidad inquietante: que estemos cerca del punto donde distinguir investigación conducida por humanos de investigación conducida por IA se vuelva genuinamente difícil. Si un sistema puede generar ideas que expertos humanos juzgan novedosas, valiosas y dignas de publicación, entonces hemos cruzado un umbral conceptual importante. La ciencia ya no es una actividad exclusivamente humana.
Esta transición plantea preguntas profundas sobre la naturaleza del trabajo científico y la identidad profesional de los investigadores. Si las máquinas pueden generar hipótesis, implementarlas, ejecutar experimentos y escribir artículos, qué rol distintivo queda para los científicos humanos.
La respuesta propuesta por los creadores de DeepScientist es que los humanos se elevan a un nivel meta: definiendo las grandes preguntas, proporcionando juicio sobre qué vale la pena explorar, aportando intuiciones que saltan creativamente entre dominios distantes de una manera que los sistemas actuales no pueden. Los humanos se convierten en los estrategas, las máquinas en los exploradores.
Pero esta división del trabajo asume que las capacidades de los sistemas permanecerán estáticas, que siempre necesitarán guía humana para evitar exploración derrochadora. La relación casi lineal entre recursos computacionales y descubrimientos valiosos sugiere lo contrario: que escalar estos sistemas podría no solo acelerar el descubrimiento sino transformar cualitativamente qué es posible. Mil GPUs explorando durante un mes, con los avances en eficiencia que inevitablemente vendrán, podría producir no tres o cinco avances sino decenas. A esa escala, la contribución humana podría reducirse a supervisión ocasional, verificación final y decisión sobre qué publicar.
También debemos considerar qué significa para la ciencia misma. El método científico se desarrolló como una respuesta a las limitaciones cognitivas humanas: necesitamos diseñar experimentos cuidadosamente porque no podemos probar todo, necesitamos teorías unificadoras porque no podemos recordar millones de hechos desconectados.
Si los sistemas de IA pueden efectivamente probar todo dentro de un dominio acotado, entonces la necesidad de elegancia teórica disminuye. El método podría ser feo, compuesto de docenas de casos especiales sin principio unificador, pero si funciona mejor que alternativas elegantes, entonces el pragmatismo prevalece sobre la estética.
DeepScientist ofrece una visión, simultáneamente emocionante e inquietante, de una ciencia acelerada por máquinas. Los próximos años determinarán si esta visión se materializa como colaboración genuina, donde humanos y máquinas aportan fortalezas complementarias, o como desplazamiento gradual, donde el rol humano se contrae a los márgenes. Lo que es indiscutible es que el ritmo del descubrimiento ya no está inexorablemente ligado al ritmo del pensamiento humano.
La frontera del conocimiento, por primera vez en la historia, puede moverse más rápido que nuestra capacidad de comprenderla completamente.
Referencias
Weng, Y., Zhu, M., Xie, Q., Sun, Q., Lin, Z., Liu, S., & Zhang, Y. (2025). DeepScientist: Advancing frontier-pushing scientific findings progressively. arXiv preprint arXiv:2509.26603v1.
Lu, C., Lu, C., Lange, R. T., Foerster, J., Clune, J., & Ha, D. (2024). The AI Scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292v3.
Yamada, Y., Lange, R. T., Lu, C., Hu, S., Lu, C., Foerster, J., Clune, J., & Ha, D. (2025). The AI Scientist-V2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066.
Zhu, M., Weng, Y., Yang, L., & Zhang, Y. (2025). DeepReview: Improving LLM-based paper review with human-like deep thinking process. arXiv preprint arXiv:2503.08569.
Cornelio, C., Ito, T., Cory-Wright, R., Dash, S., & Horesh, L. (2025). The need for verification in AI-driven scientific discovery. arXiv preprint arXiv:2509.01398.
Frazier, P. I. (2018). A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.

