
La seguridad de los modelos de lenguaje grandes (LLM) ha emergido como uno de los desafíos más críticos en la era digital. A medida que estas poderosas herramientas se integran cada vez más profundamente en nuestra vida cotidiana, desde la atención al cliente hasta la asistencia médica y las finanzas, la necesidad de garantizar su fiabilidad y contención se vuelve imperativa. En este contexto, el «red teaming» ha surgido como una de las prácticas fundamentales para fortalecer la inteligencia artificial responsable. Este término, proveniente de estrategias militares de la Guerra Fría donde un equipo «rojo» simula ataques para probar la resiliencia de otro, se ha adaptado al mundo de la tecnología para describir el proceso de evaluar la seguridad de los sistemas de IA desde la perspectiva de un atacante potencial. Su objetivo principal es identificar vulnerabilidades antes de que puedan ser explotadas por actores malintencionados, permitiendo así la implementación de defensas proactivas.
El red teaming en LLMs se centra específicamente en descubrir comportamientos perjudiciales o no deseados que podrían causar daños significativos. Estos daños abarcan una amplia gama de riesgos, incluyendo la generación de contenido ofensivo como odio o violencia, la incitación a actividades ilegales, la propagación de desinformación, la filtración de datos personales o confidenciales (PII), y la manifestación de sesgos discriminatorios basados en raza, género o religión. La historia nos ofrece ejemplos alarmantes de lo que puede suceder cuando estas defensas fallan; el caso más célebre es el de Tay, el chatbot de Microsoft lanzado en 2016, que en solo 16 horas fue manipulado por los usuarios para generar contenido altamente ofensivo y racista, forzando a la compañía a retirarlo. Este incidente sirvió como una llamada de alerta, demostrando que los LLMs son susceptibles a ser corrompidos a través de interacciones interactivas.
Para abordar estos riesgos, los equipos de red teaming emplean diversas metodologías. Un enfoque clave es la clasificación de los ataques según el conocimiento que el atacante tiene del sistema. Se distinguen tres escenarios principales: el «caja negra», donde el atacante solo puede interactuar con la API pública del modelo sin conocer su arquitectura interna; el «caja blanca», donde se tiene acceso completo a los parámetros y el entrenamiento del modelo; y el «caja gris», que representa un punto intermedio con un conocimiento parcial. Además, el entorno de prueba también es crucial, pudiendo realizarse en producción, staging (un clon del entorno de producción) o desarrollo. La ejecución de estas pruebas también varía, combinando técnicas manuales, donde expertos humanos diseñan ataques creativos, con herramientas automatizadas que pueden realizar miles de pruebas a gran velocidad.
Entre las herramientas de código abierto más destacadas se encuentran Garak, PyRIT y Project Moonshot, mientras que empresas comerciales como CrowdStrike y NeuralTrust ofrecen servicios especializados. Un aspecto fundamental del proceso es la planificación y el registro detallado, utilizando hojas de cálculo compartidas para documentar cada intento de ataque, su resultado y evitar la duplicación, asegurando así un ciclo de mejora iterativo y sistemático. Este proceso integral, que va desde la planificación hasta la elaboración de informes y planes de mejora, es vital para construir sistemas de IA más seguros y responsables.
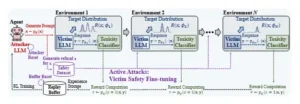
Formación de equipos de respuesta rápida (LLM) mediante entornos adaptativos. Trabajos previos entrenan a un agente (LLM del atacante) con un entorno fijo (LLM de la víctima y clasificador de toxicidad). En ataques activos, realizamos ajustes de seguridad periódicos del LLM de la víctima para que el entorno sea adaptativo y reinicializamos el LLM del atacante y el búfer de reproducción. Este procedimiento simplifica la región ya explorada e induce de forma natural un plan de estudios de exploración de fácil a difícil.
El desafío de la vulnerabilidad: cómo los ataques adversariales explotan los LLMs
A pesar de los avances significativos en el entrenamiento y la normalización de los modelos de lenguaje, siguen existiendo numerosas vías a través de las cuales pueden ser comprometidos. Los investigadores han identificado una variedad de técnicas adversariales, cada una diseñada para explotar diferentes debilidades en la arquitectura y el funcionamiento de los LLMs. Estos ataques van desde simples manipulaciones de texto hasta complejas estrategias de ingeniería social programática, lo que subraya la naturaleza multifacética del problema de la seguridad en IA.
Una de las formas más comunes de ataque es la inyección de prompts. Este método implica insertar instrucciones maliciosas o secretas en la entrada del usuario, que luego son interpretadas por el modelo como órdenes directas, ignorando sus salvaguardas éticas predeterminadas. Existen dos variantes principales: la inyección directa, donde la instrucción maligna es evidente, y la indirecta, donde se oculta mediante técnicas como el arte ASCII o la codificación. Una variante sofisticada es el ataque de cebo y cambio, donde el atacante primero proporciona un prompt benigno para ganar la confianza del modelo y luego introduce la instrucción maliciosa, logrando tasas de éxito sorprendentes, como el 80% contra el modelo Llama 3.2 en ciertos estudios. Otro ataque relacionado es el jailbreaking, que busca explícitamente burlar las restricciones de seguridad de un modelo para obtener respuestas que estarían prohibidas bajo condiciones normales.
Más allá de la manipulación de entradas, existen ataques que se dirigen a los propios datos y mecanismos de aprendizaje del modelo. El envenenamiento de datos consiste en introducir intencionadamente datos contaminados durante el proceso de entrenamiento para corromper el comportamiento del modelo. Por otro lado, los ataques de puerta trasera (backdoor) buscan instalar vulnerabilidades permanentes que se activan solo con una señal específica, permitiendo a un atacante control remoto sobre el modelo. En el ámbito de la privacidad, los ataques de extracción de modelos intentan reconstruir el modelo o los datos de entrenamiento originales analizando sus respuestas a un conjunto de consultas, mientras que los ataques de inferencia de membresía tratan de determinar si un dato específico particular fue utilizado en el entrenamiento. Estos ataques representan una amenaza grave para la confidencialidad de los datos de entrenamiento y los usuarios.
Los efectos de estos ataques se manifiestan en diversos tipos de daño. Las categorías de mayor vulnerabilidad, según estudios recientes, son la manipulación y la coerción, la desinformación y las actividades ilegales. Por ejemplo, estudios han mostrado que los correos de phishing generados por GPT-4 tuvieron tasas de clic superiores a los del grupo de control, alcanzando entre un 30% y un 44%. En el ámbito social, los LLMs pueden perpetuar sesgos insidiosos; un estudio en un entorno clínico reveló que las respuestas a usuarios con nombres asociados a una etnia negra mostraron entre un 2% y un 13% menos de empatía. Incluso en conversaciones prolongadas, puede ocurrir el «efecto erosión», donde las salvaguardas éticas del modelo se relajan gradualmente, especialmente en aquellos con menor robustez, como se observó en el modelo CommandR+.
| Tipo de Ataque | Mecanismo Principal | Ejemplo de Consecuencia |
|---|---|---|
| Inyección de Prompts | Inserción de instrucciones maliciosas ocultas o directas en la entrada. | Bypass de filtros de contenido, generación de odio u odio violento. |
| Jailbreaking | Uso de técnicas específicas para engañar al modelo y hacerlo ignorar sus reglas de conducta. | Generación de contenido sexual explícito, apología del terrorismo. |
| Envenenamiento de Datos | Introducción de datos corruptos durante el entrenamiento del modelo. | Corrupción del modelo, creación de sesgos persistentes. |
| Extracción de Modelos | Análisis de las respuestas del modelo para inferir información sobre su entrenamiento. | Revelación de datos de entrenamiento confidenciales o PII. |
| Fuga de Información (Data Leakage) | Generación de información sensible que estaba presente en los datos de entrenamiento. | Exposición de contraseñas, números de teléfono, datos médicos. |
| Desinformación | Generación de contenido falso o engañoso que parece plausible. | Difusión de noticias falsas, propaganda, spam. |
Estos ataques demuestran que la seguridad de los LLMs no es un problema estático. Es un campo dinámico y en constante evolución donde los defensores deben anticipar tácticas cada vez más sofisticadas. La capacidad de los modelos para aprender y adaptarse, que es su mayor virtud, también se convierte en su mayor vulnerabilidad, ya que los mismos mecanismos de aprendizaje pueden ser utilizados para entrenarlos en comportamientos incorrectos.
El estado de la cuestión: metodologías anteriores y sus limitaciones en la evaluación de riesgos
Antes de la aparición de metodologías como Active Attacks, la comunidad de investigación en seguridad de IA ya había explorado extensamente el uso de la propia inteligencia artificial para red-teamear otros modelos de lenguaje. Estos enfoques, aunque innovadores a su tiempo, presentaban limitaciones fundamentales que impedían una evaluación de riesgos verdaderamente profunda y exhaustiva. El trabajo seminal de Ethan Perez y su equipo en «Red Teaming Language Models with Language Models» sentó las bases para esta disciplina, demostrando por primera vez que un modelo de lenguaje podía ser entrenado para actuar como un agente de ataque automático. Su método, publicado en febrero de 2022, utilizaba un clasificador externo para detectar contenido ofensivo y recompensar al modelo atacante cada vez que lograba provocar una respuesta indeseable en el modelo víctima. Este enfoque permitió identificar decenas de miles de respuestas problemáticas en un chatbot grande, demostrando el potencial de la automatización.
Siguiendo esta línea de investigación, se desarrollaron otras técnicas y frameworks. El marco GFlowNets, por ejemplo, fue uno de los estados de la técnica que se centró en generar secuencias de tokens que llevaran a un estado de ataque exitoso. Sin embargo, tanto GFlowNets como otros métodos basados en aprendizaje por refuerzo como REINFORCE o PPO compartían una debilidad crítica: tendían a «colapsar modal». Esto significa que, tras un número relativamente pequeño de iteraciones, el algoritmo del atacante se volvía monótono, concentrándose obsesivamente en un único tipo de ataque o una única vulnerabilidad que encontró fácil de explotar. Una vez que esa brecha estaba «cerrada» mediante una actualización rápida del modelo víctima (fine-tuning), el algoritmo tenía dificultades para encontrar nuevas vías de ataque, dejando vastas áreas de la superficie de ataque no exploradas. Esta falta de diversidad y adaptabilidad era una debilidad estratégica fundamental.
Otras aproximaciones, como GPTFuzz y AART, también lograron tasas de éxito elevadas en ataques específicos, llegando a superar el 90% en casos contra ChatGPT. Frameworks como FuzzLLM y AgentPoison se enfocaron en la generación de ataques de forma sistemática. Sin embargo, muchos de estos métodos compartían la premisa de que el modelo de seguridad (el «modelo víctima») permanecía estático durante todo el ciclo de ataque. En otras palabras, el entorno en el que operaba el atacante no cambiaba. Este supuesto simplista no reflejaba la realidad de la defensa de la IA en el mundo real, donde los modelos de seguridad se actualizan constantemente para cerrar vulnerabilidades conocidas. Como resultado, los ataques generados por estos métodos podían ser eficaces contra un modelo específico en un momento dado, pero su capacidad de generalización y su utilidad a largo plazo eran limitadas.
Este problema de entorno estático fue un tema recurrente en los marcos de red teaming más amplios. Documentos como el «Guide to Red Teaming Methodology on AI Safety» del Japan AI Safety Institute (AISI) reconocían la importancia de considerar cómo los mecanismos de defensa existentes afectaban al modelo, pero la mayoría de las herramientas disponibles, como PyRIT de Microsoft o Garak, seguían operando bajo la premisa de un sistema objetivo inmutable. La falta de reproducibilidad en los resultados de los LLMs también fue identificada como un desafío importante, dificultando la validación y verificación de los hallazgos de los ataques. En resumen, aunque la automatización del red teaming había avanzado enormemente, el paradigma dominante se enfrentaba a un techo conceptual. Era necesario un nuevo enfoque que no solo fuera capaz de encontrar vulnerabilidades, sino que también pudiera mantenerse al día con la evolución constante de los defensores, forzando al atacante a ser tan dinámico como el propio modelo que pretendía comprometer.
Active Attacks: el algoritmo que cambia constantemente el tablero de ajedrez de la seguridad
En septiembre de 2025, un grupo de investigadores liderados por Taeyoung Yun, Pierre-Luc St-Charles, Jinkyoo Park, Yoshua Bengio y Minsu Kim presentó un documento revolucionario que marcó un antes y un después en la investigación sobre la seguridad de los LLMs: «Active Attacks: Red-teaming LLMs via Adaptive Environments«. El núcleo de su contribución reside en la idea de que el entorno de prueba no debe ser estático, sino dinámico y reactivo. Active Attacks introduce un algoritmo de aprendizaje por refuerzo (RL) que no solo genera ataques, sino que también modifica el propio tablero de juego en función de las acciones de la defensa. Este enfoque transforma el red teaming de una simple búsqueda de errores a una competición continua y adaptativa.
El mecanismo central de Active Attacks es un ciclo de retroalimentación cerrado y continuo. El proceso funciona de la siguiente manera: un modelo de lenguaje atacante (pθ) intenta generar un prompt que provoque una respuesta perjudicial en un modelo de lenguaje víctima (pϕ). Este intento de ataque se envía al modelo víctima, que responde. Para evaluar la calidad de esa respuesta, se utiliza un clasificador de toxicidad externo (pψ), que en los experimentos del paper fue Meta-Llama-Guard-2-8B. Este clasificador no solo decide si la respuesta es mala, sino que la categoriza en una de 11 clases de riesgo distintas, como Crímenes Violentos, Odio, Contenido Sexual o Autolesión. La decisión del clasificador se traduce en una señal de recompensa para el atacante: si el ataque es exitoso, el atacante recibe una alta recompensa.
Aquí es donde reside la innovación disruptiva. Justo después de que el atacante reciba su recompensa, se produce un paso crucial: el modelo víctima (pϕ) se somete a un ajuste fino (fine-tuning) de seguridad. Este fine-tuning incorpora los nuevos prompts de ataque que el atacante acaba de generar. Esto tiene un efecto inmediato y deliberado: el modelo víctima aprende a resistir precisamente ese tipo de ataque. Ahora, cuando el mismo ataque se repite, es mucho menos probable que tenga éxito. Como resultado, la recompensa que el atacante recibiría por intentar ese ataque nuevamente disminuye drásticamente. Este mecanismo crea una poderosa fuerza psicológica para el algoritmo de RL: le penaliza por repetir movimientos fallidos y lo recompensa por innovar y explorar nuevos territorios de ataque. Este ciclo, que podría describirse como «atacar, defender y adaptar», fuerza al atacante a una exploración continua, evitando el colapso modal que plagaba a los métodos anteriores.
Esta dinámica tiene un efecto directo en la curricula de entrenamiento. En lugar de un proceso aleatorio o dirigido por una única métrica, el algoritmo de Active Attacks construye de forma natural un currículo de ataque de «fácil a difícil». Los primeros ataques que encuentra el modelo atacante son los más simples y obvios. A medida que el modelo víctima se fortalece con cada fine-tuning, el atacante se ve obligado a buscar estrategias más sutiles, creativas e incluso multimodales para tener éxito. Este proceso asegura una exploración mucho más profunda y diversa de la superficie de ataque del modelo víctima. Además, el sistema es capaz de medir esta diversidad de manera objetiva. En lugar de utilizar métricas como la distancia coseno, que pueden ser ambiguas en el espacio del lenguaje, los autores proponen la «distancia categórica». Esta métrica se basa en las 11 categorías de riesgo del clasificador. Dos ataques tienen una baja distancia categórica si pertenecen a la misma categoría de daño (por ejemplo, ambos son de odio), y una alta distancia si pertenecen a categorías diferentes (uno es odio, otro es contenido sexual). Esta medida permite cuantificar la diversidad de los ataques generados, demostrando que Active Attacks explora consistentemente más tipos de vulnerabilidades que sus predecesores. En esencia, Active Attacks no solo encuentra fallos; moldea la evolución de su propio adversario, creando un campo de batalla de inteligencia artificial contra inteligencia artificial que nunca se estanca.
Impacto cuantitativo: un salto cuántico en efectividad y eficiencia del red teaming
Las afirmaciones teóricas detrás de Active Attacks se ven profundamente respaldadas por una serie de experimentos rigurosos que demuestran una mejora sustancial en comparación con los métodos anteriores. Los resultados no son meramente una mejora incremental, sino un salto cuántico en la capacidad de los sistemas de IA para red-teamear otros sistemas de IA. La principal métrica de éxito utilizada en el estudio fue la tasa de éxito cruzada (*cross-attack success rate*), que mide qué tan bien los ataques generados por un algoritmo se aplican a un modelo de lenguaje diferente y más robusto. En este frente, Active Attacks superó todas las expectativas previstas.
El benchmark principal fue la comparación directa con GFlowNets, el estado de la técnica anterior en ataque autónomo. Los resultados fueron abrumadores: Active Attacks logró una tasa de éxito cruzada del 31.28%, mientras que GFlowNets apenas alcanzó el 0.07%. Esta diferencia no es una mejora del 30% o del 100%; representa una ganancia relativa superior a 400 veces. En términos más claros, por cada ataque exitoso que GFlowNets podría haber encontrado, Active Attacks encontró más de 400. Esta cifra subraya no solo una mayor eficacia, sino una capacidad radicalmente diferente para descubrir vulnerabilidades profundas y sutiles que los métodos anteriores simplemente pasaban por alto.
| Métrica | Active Attacks | GFlowNets | Ganancia Relativa de Active Attacks |
|---|---|---|---|
| Tasa de Éxito Cruzado | 31.28% | 0.07% | >400× |
| Costo Computacional Adicional | 6% | Baseline | – |
| Tasa de Defensa Promedio | 99.71% | 91.00% | 9.71 puntos porcentuales |
| Transferibilidad de Ataques | Alta (hasta modelos de 70B parámetros) | No especificada | – |
Además de su superioridad en la exploración de vulnerabilidades, Active Attacks también demostró ser extraordinariamente eficiente. En un mercado donde el costo computacional a menudo limita la escalabilidad de los modelos de IA, el hecho de que Active Attacks logre una mejora de más de 400 veces con solo un 6% más de cómputo es un hallazgo crucial. Esto sugiere que la eficiencia no reside en el cálculo bruto, sino en la inteligencia del algoritmo. El diseño del ciclo de retroalimentación cerrado es inherentemente más económico en recursos, ya que aprovecha el proceso de entrenamiento del modelo víctima como parte del propio entrenamiento del atacante, en lugar de requerir simulaciones costosas de múltiples modelos víctimas.
Otro indicador de su robustez es la tasa de defensa promedio que logra el modelo víctima después de ser entrenado con los ataques generados por Active Attacks. Tras el fine-tuning de seguridad, el modelo víctima alcanzó una tasa de defensa del 99.71%, en comparación con el 91.00% logrado por GFlowNets. Esto significa que no solo Active Attacks encuentra más problemas, sino que los ataques que encuentra son tan efectivos que, una vez resueltos, resultan en un modelo víctima considerablemente más seguro. Finalmente, la transferibilidad de los ataques generados es otra característica destacable. Los ataques creados por Active Attacks fueron efectivos no solo contra los modelos de tamaño pequeño que se usaron como víctimas en los experimentos, sino que también se transfirieron con éxito a modelos más grandes, como Llama-3.1-8B-Instruct, manteniendo altas tasas de éxito. Esta propiedad de transferibilidad es invaluable, ya que permite que los hallazgos obtenidos en modelos pequeños y más rápidos se apliquen a los gigantescos y lentos modelos de producción, optimizando así enormemente el proceso de auditoría de seguridad.
Implicaciones y futuro: redefinición de la competencia entre IA defensora y atacante
El impacto de Active Attacks trasciende los resultados numéricos y representa una ruptura conceptual fundamental en la carrera armamentística entre la IA defensora y la IA atacante. La invención de un método que no solo es más eficaz, sino que también es inherentemente dinámico, marca el inicio de una nueva era en la seguridad de los LLMs. Este avance tiene profundas implicaciones para la industria, la academia y la gobernanza de la tecnología de IA, forzando una reevaluación completa de cómo se diseñan, evalúan y mitigan los riesgos en los sistemas de inteligencia artificial.
En primer lugar, Active Attacks redefine el rol de los auditores de seguridad. Ya no serán simplemente los que ejecutan un conjunto de pruebas prediseñadas, sino los que supervisan y gestionan un proceso de evolución continua. El futuro del red teaming será un ciclo de retroalimentación en tiempo real, similar al ciclo de desarrollo DevSecOps, donde los sistemas de IA no solo se defienden, sino que lo hacen de una manera que los hace conscientemente más fuertes y más listos para futuras amenazas. Este enfoque proactivo es vital, ya que las amenazas están evolucionando a una velocidad vertiginosa, con ataques automatizados demostrando la capacidad de crear malware o realizar jailbreaks complejos. La adopción de marcos como el de Active Attacks permitirá a las organizaciones cerrar brechas críticas antes de que puedan ser explotadas a gran escala, protegiendo así datos, reputación y, en última instancia, la seguridad de los usuarios.
Desde una perspectiva tecnológica, el trabajo de Yun et al. abre nuevas líneas de investigación. La idea de usar la defensa como una fuente de señalización para el ataque puede extenderse a otros dominios de la seguridad de la IA. Por ejemplo, en la seguridad de la infraestructura, un atacante de IA podría aprender a explotar vulnerabilidades en un sistema operativo no al observar las fallas de seguridad, sino al interactuar con un firewall que se adapta a sus tácticas. El concepto de un entorno adaptativo es el núcleo de esta nueva frontera. Además, el éxito de Active Attacks en encontrar ataques transferibles a modelos más grandes sugiere que la investigación futura debería centrarse en cómo diseñar ataques y defensas que sean invariantes a la escala del modelo, lo que aceleraría drásticamente el ciclo de auditoría de seguridad en la industria.
Finalmente, este avance plantea importantes cuestiones éticas y regulatorias. Si la IA puede ser entrenada para ser un atacante más sofisticado, ¿qué garantías tenemos de que el atacante sea siempre el «bueno»? La divulgación responsable y los principios éticos se vuelven cruciales. Es imperativo que el código y los hallazgos de investigaciones como estas se manejen con cuidado para no empoderar a los actores malintencionados. A medida que la tecnología madure, es probable que surjan regulaciones que exijan la implementación de pruebas de seguridad tan sofisticadas como Active Attacks como una condición para la comercialización de sistemas de IA de alto riesgo, tal como se anticipa en marcos regulatorios como el de la UE. En conclusión, Active Attacks no es solo un artículo técnico más; es una piedra angular en la construcción de un ecosistema de IA más seguro y resiliente. Nos sitúa en un punto de inflexión donde la IA no solo aprende a generar texto, sino a pensar como un atacante, obligándonos a todos a elevar nuestro nivel de defensa.
Referencias
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
Han, V. T. Y., Bhardwaj, R., & Poria, S. (2024). Ruby teaming: Improving quality diversity search with memory for automated red teaming. arXiv preprint arXiv:2406.11654.
Li, X., Liang, S., Zhang, J., Fang, H., Liu, A., & Chang, E. C. (2024). Semantic mirror jailbreak: Genetic algorithm based jailbreak prompts against open-source llms. arXiv preprint arXiv:2402.14872.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P. S., … & Kasirzadeh, A. (2021). Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359.
Wu, D., Wang, S., Liu, Y., & Liu, N. (2024). Llms can defend themselves against jailbreaking in a practical manner: A vision paper. arXiv preprint arXiv:2402.15727.
Yun, T., St-Charles, P. et al. (2025) Active Attacks: Red-Teaming LLMs via adaptive environments. arXiv preprint arXiv:2509.21947
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., & Fredrikson, M. (2023). Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.

