
Por Javier Ruiz, Periodista Especializado en Inteligencia Artificial y Tecnología Emergente, para Mundo IA
El oráculo digital: la IA que aprendió a predecir el futuro
Desde los albores de la civilización, la humanidad ha estado obsesionada con descorrer el velo del futuro. Hemos mirado a las estrellas, hemos leído las entrañas de los animales, hemos consultado oráculos en templos humeantes y hemos construido complejos modelos estadísticos, todo en un intento incesante por saber qué nos depara el mañana. Esta búsqueda no es un mero capricho; es un imperativo de supervivencia y progreso. La capacidad de anticipar una sequía, prever una crisis económica o predecir el avance de una enfermedad es lo que nos permite prepararnos, innovar y, en última instancia, moldear nuestro propio destino. En el siglo veintiuno, hemos depositado nuestras esperanzas en un nuevo tipo de oráculo, uno forjado no en el misterio, sino en la lógica fría de los algoritmos: la inteligencia artificial.
Las inteligencias artificiales, y en particular los Grandes Modelos de Lenguaje o LLMs, se han convertido en repositorios de conocimiento sin precedentes. Entrenados con una porción monumental de la cultura y la información digital humana, pueden redactar textos, escribir código y responder preguntas con una erudición que a menudo supera a la de los expertos humanos. Sin embargo, saber mucho sobre el pasado no es lo mismo que entender el futuro. Por ello, la frontera de la investigación se ha desplazado hacia la creación de «agentes de IA», sistemas que no solo responden a preguntas, sino que actúan. Estos agentes pueden navegar por internet, leer documentos, analizar datos y utilizar herramientas digitales, comportándose menos como una enciclopedia estática y más como un analista o un investigador incansable. La pregunta que surge es inevitable: si un agente de IA puede leer todo lo que se ha escrito sobre un próximo evento, ¿podría predecir su resultado?
El problema hasta ahora ha sido cómo medir esta capacidad de manera fiable. Los métodos tradicionales para evaluar a las IAs son fundamentalmente defectuosos porque son estáticos. Ponen a prueba a la IA con datos del pasado, pidiéndole que «prediga» eventos cuyos resultados ya conocemos. Es como darle a un estudiante un examen de historia con el libro de texto abierto; puede encontrar la respuesta correcta, pero no demuestra una verdadera capacidad de análisis predictivo. Peor aún, la IA podría haber visto la respuesta durante su entrenamiento, un fenómeno conocido como «contaminación de datos», lo que invalida por completo la prueba. Estábamos midiendo la memoria de la IA, no su inteligencia. Es una diferencia crucial, la misma que existe entre un cronista que narra la batalla de ayer y un general que debe anticipar los movimientos del enemigo mañana.
Para resolver este enigma, un equipo de investigadores ha desarrollado una plataforma revolucionaria, un «banco de pruebas en vivo» diseñado para ser el examen definitivo para los agentes de IA predictivos. Esta iniciativa, bautizada como FutureX, rompe radicalmente con el pasado porque opera en el único terreno que importa: el futuro real y desconocido. En lugar de hacer preguntas sobre eventos pasados, este sistema plantea continuamente preguntas sobre eventos que aún no han ocurrido. Preguntas como: «¿Superará el precio de una acción determinada los cien dólares el próximo mes?», «¿Ganará un equipo específico su próximo partido?» o «¿Se publicará una investigación científica concreta antes de fin de año?». Estas no son preguntas de trivial; son cuestiones verificables cuyo resultado es incierto en el momento de la predicción.
En esta arena predictiva, los agentes de IA no pueden confiar en la memoria. Deben actuar como verdaderos analistas. Se les da una pregunta y un conjunto de herramientas digitales, principalmente la capacidad de navegar por la web en tiempo real. El agente debe entonces formular una estrategia: ¿qué información necesito?, ¿dónde puedo encontrarla?, ¿qué fuentes son fiables? Debe leer noticias, analizar informes, sopesar opiniones de expertos y sintetizar información a menudo contradictoria para llegar a una predicción final. Una vez que el agente emite su veredicto, la plataforma lo registra. El tiempo pasa, el evento ocurre en el mundo real, y solo entonces se conoce la verdad. La predicción del agente se compara con la realidad y se le asigna una puntuación de precisión.
Los primeros resultados de esta iniciativa son tan fascinantes como reveladores. El estudio demuestra que los agentes de IA más avanzados ya pueden predecir el futuro con una precisión significativamente mejor que el azar. No son oráculos perfectos, pero tampoco están adivinando a ciegas. El hallazgo más importante es que la capacidad de usar herramientas, de investigar activamente, es absolutamente crítica. Un agente que puede navegar por la web supera drásticamente a uno que solo puede confiar en su conocimiento interno. Además, los investigadores observaron un fenómeno de «razonamiento sinérgico», donde la IA es capaz de combinar múltiples piezas de información imperfecta para llegar a una conclusión más precisa que la que ofrecería cualquier fuente por separado.
Este revolucionario banco de pruebas no es solo una herramienta de evaluación; es un campo de entrenamiento. Al analizar cuándo y por qué fallan los agentes, los investigadores pueden identificar sus debilidades, como la mala interpretación de las preguntas o la dependencia de datos obsoletos, y utilizar esa información para construir sistemas más robustos. Este trabajo marca un cambio fundamental. Estamos pasando de construir IAs que son bibliotecas de nuestro pasado a forjar IAs que pueden ser nuestros socios en la exploración del futuro. La creación de un oráculo digital fiable ya no es una fantasía de la ciencia ficción; es un problema de ingeniería que estamos empezando a resolver, y este proyecto es el crisol en el que se están poniendo a prueba a sus primeros y más prometedores aprendices.
El problema de la bola de cristal estática
La explosión de la inteligencia artificial en la conciencia pública ha estado impulsada en gran medida por los Grandes Modelos de Lenguaje. Estas maravillas de la ingeniería de software han demostrado una capacidad asombrosa para procesar y generar lenguaje humano. Su poder reside en su entrenamiento: han sido expuestos a una porción inimaginablemente vasta de internet, absorbiendo miles de millones de páginas de texto, desde la literatura clásica hasta las conversaciones en redes sociales. El resultado es un sistema que posee un conocimiento enciclopédico sobre casi cualquier tema que se pueda nombrar. Sin embargo, este conocimiento es, por su propia naturaleza, retrospectivo. Es un eco perfecto del pasado y del presente hasta el momento en que su entrenamiento se detuvo.
Para superar esta limitación, los investigadores crearon los «agentes de IA». La idea era transformar estos modelos de lenguaje de repositorios pasivos de información a actores activos en el mundo digital. Un agente de IA es, en esencia, un LLM dotado de la capacidad de actuar. En lugar de simplemente responder a una pregunta con la información que ya posee, un agente puede decidir realizar una serie de acciones para encontrar nueva información. Su herramienta más poderosa es el acceso a internet. Al igual que un humano, puede «abrir un navegador», «escribir una consulta en un motor de búsqueda», «hacer clic en un enlace» y «leer el contenido de una página web». Este bucle de pensamiento y acción le permite actualizar su conocimiento con información en tiempo real.
Con la llegada de estos agentes, la posibilidad de la predicción del futuro se convirtió en una perspectiva tangible. La lógica era simple: si un agente puede leer todo lo que un analista humano puede leer (noticias de última hora, informes financieros, artículos científicos, debates de expertos), entonces, en teoría, debería ser capaz de hacer una predicción informada. Pero esta nueva y emocionante capacidad trajo consigo un viejo y persistente problema: ¿cómo sabemos si realmente funciona? ¿Cómo evaluamos la habilidad de un agente de IA para predecir el futuro de una manera que sea justa, rigurosa y a prueba de trampas?
Los primeros intentos de crear bancos de pruebas, o benchmarks, para la predicción se basaron en el único recurso de datos que teníamos en abundancia: el pasado. Estos benchmarks estáticos funcionaban seleccionando un punto en el tiempo histórico, por ejemplo, el 1 de enero de 2020. Le daban a la IA acceso solo a la información disponible hasta esa fecha y le pedían que predijera un evento futuro, como el resultado de las elecciones presidenciales de Estados Unidos de ese año. Dado que nosotros ya conocemos el resultado, podíamos calificar fácilmente la precisión de la IA. A primera vista, esto parece un enfoque sensato. Es el equivalente a pedirle a un historiador que, basándose únicamente en los documentos de 1938, prediga el estallido de la Segunda Guerra Mundial.
Sin embargo, este enfoque estático adolece de dos defectos fatales que lo hacen fundamentalmente inadecuado para la era de los LLMs masivos. El primer defecto es la contaminación de datos. Los LLMs han sido entrenados con una porción tan grande de internet que es casi imposible garantizar que no hayan visto ya la respuesta a la pregunta de la prueba. Aunque se intente limitar su acceso a la información a una fecha anterior, el «conocimiento» del resultado podría estar ya grabado en los patrones de su red neuronal. Es como si nuestro historiador, sin saberlo, hubiera leído un libro de historia del siglo XXI durante su formación. Su «predicción» sobre la Segunda Guerra Mundial no sería un acto de razonamiento, sino de memoria. El modelo no está prediciendo; está recordando.
El segundo defecto es la falta de realismo y dinamismo. El futuro real no es un evento pasado y bien documentado. Es un entorno caótico, incierto y en constante cambio. La información nueva aparece cada segundo, a menudo contradictoria y a veces deliberadamente engañosa. Un verdadero analista debe navegar por esta niebla de información, sopesar la credibilidad de las fuentes y actualizar sus creencias a medida que surgen nuevos datos. Un benchmark estático no puede replicar esta presión del mundo real. Le proporciona a la IA un conjunto de datos limpio y congelado en el tiempo. No pone a prueba su capacidad para buscar información relevante en un mar de ruido, ni su habilidad para discernir la verdad de la desinformación. En resumen, los benchmarks estáticos no estaban probando la habilidad de un agente de IA para ser un analista de inteligencia; estaban probando su habilidad para ser un buen archivero. La comunidad científica necesitaba desesperadamente un nuevo tipo de examen, uno que no pudiera ser aprobado simplemente estudiando las respuestas de antemano.
FutureX, el campo de pruebas del mañana
La respuesta a los defectos de los benchmarks estáticos llega en la forma de una plataforma concebida desde cero para ser un campo de pruebas dinámico, justo y perpetuamente desafiante: FutureX. La filosofía que subyace a esta iniciativa es que la única manera de probar verdaderamente la capacidad de predicción es hacer preguntas sobre el futuro real y no verificable. Este enfoque representa una transición de un entorno de laboratorio controlado a una arena del mundo real. El funcionamiento de este innovador sistema se puede entender a través de tres componentes principales.
El primero es el motor de generación de preguntas. Este banco de pruebas necesita un suministro constante de nuevas cuestiones sobre el futuro. Las preguntas se obtienen de una variedad de fuentes y deben cumplir con dos criterios estrictos. Primero, deben ser verificables. La cuestión debe estar formulada de tal manera que, en una fecha futura específica, se pueda determinar una respuesta definitiva de «sí», «no» o un valor numérico. Preguntas vagas como «¿Mejorará la economía?» no son útiles. Preguntas precisas como «¿El índice S&P 500 cerrará por encima de los 6000 puntos el 31 de diciembre de 2025?» son ideales. Segundo, deben ser diversas. Las preguntas cubren un amplio espectro de dominios, incluyendo finanzas, política, deportes, ciencia y tecnología, e incluso cultura popular. Esto asegura que los agentes sean probados en su capacidad de razonamiento general, no solo en un área de especialización estrecha.
El segundo componente es el entorno de ejecución de los agentes. Aquí es donde las IAs se ponen a prueba. Cuando se publica una nueva pregunta, los agentes participantes son activados. Cada agente es, en esencia, un LLM (como GPT-4) envuelto en un andamiaje de software que le permite interactuar con herramientas. La herramienta principal, y la más importante, es un navegador web. Cuando un agente recibe la pregunta, debe primero «pensar» en un plan. Podría decidir: «Para responder a esta pregunta sobre el precio de una acción, primero debo buscar noticias recientes sobre la empresa, luego buscar los informes de ganancias trimestrales y finalmente buscar análisis de expertos». A continuación, ejecuta este plan paso a paso, emitiendo comandos como search("informe de ganancias de la empresa X") o browse("url_del_articulo_de_noticias"). El entorno de la plataforma ejecuta estos comandos y devuelve los resultados al agente. Este proceso se repite en un bucle: el agente recibe nueva información, reflexiona sobre ella, actualiza su plan y decide qué hacer a continuación. Es un proceso de investigación activa que imita de cerca cómo un analista humano abordaría el problema.
El tercer componente es el sistema de evaluación. Una vez que el agente ha completado su investigación, debe emitir una predicción final. Por lo general, esto incluye una respuesta (por ejemplo, «sí») y una puntuación de confianza (por ejemplo, «80% seguro»). La herramienta de benchmark almacena esta predicción de forma segura. Luego, el mundo sigue su curso. Cuando llega la «fecha de resolución» de la pregunta, el equipo detrás del proyecto determina el resultado real del evento. Este resultado se convierte en la «verdad fundamental». Finalmente, la predicción del agente se compara con esta verdad y se califica su precisión. Por ejemplo, si el agente predijo «sí» con un 80% de confianza y el resultado fue efectivamente «sí», recibe una puntuación alta. Si el resultado fue «no», recibe una penalización.
La belleza de este diseño es que es inmune a los problemas de los métodos de evaluación estáticos. La contaminación de datos es imposible porque la respuesta no existe en ninguna parte del universo conocido en el momento de la predicción. La IA no puede haber «visto» la respuesta en su entrenamiento porque la respuesta aún no ha ocurrido. Además, el sistema es inherentemente dinámico y realista. El agente debe enfrentarse a la misma información desordenada, incompleta y a veces contradictoria que un humano. Debe lidiar con noticias de última hora, rumores y desinformación. Este marco de trabajo no solo evalúa el resultado final de la predicción; evalúa todo el proceso de razonamiento y de investigación que lleva a esa predicción. No es un examen final con un temario fijo; es un desafío continuo que evoluciona con el mundo real, asegurando que los agentes de IA se midan constantemente contra la prueba más dura de todas: la realidad misma.
Los primeros destellos del futuro, hallazgos clave
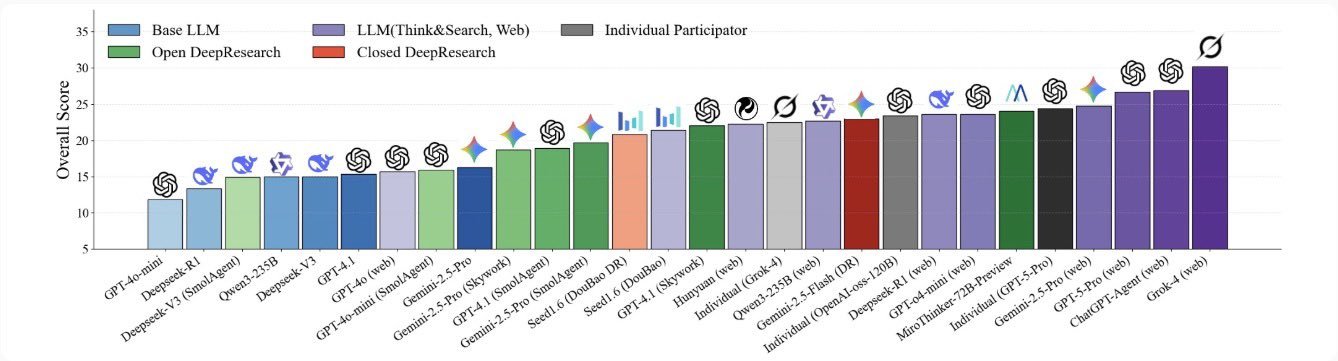
La implementación de esta arena predictiva y las primeras rondas de pruebas con los agentes de IA más avanzados han arrojado una serie de hallazgos que nos dan una primera visión fascinante de las capacidades predictivas de estas nuevas mentes artificiales. Los resultados son una mezcla de éxitos impresionantes, limitaciones claras y, sobre todo, una confirmación rotunda de la importancia del enfoque de los «agentes activos».
El hallazgo principal del estudio es que los agentes de IA modernos, cuando están equipados con las herramientas adecuadas, pueden predecir eventos futuros con una precisión no trivial. Esto significa que su rendimiento es significativamente mejor que el de una simple adivinación al azar. No son oráculos infalibles, y su tasa de aciertos varía considerablemente dependiendo del dominio y la dificultad de la pregunta, pero los resultados demuestran de manera concluyente que la capacidad de razonamiento de los LLMs puede ser aprovechada para una previsión genuina. La era de la predicción de la IA ha comenzado, no como una posibilidad teórica, sino como una realidad medible.
Sin embargo, el diablo, como siempre, está en los detalles. El descubrimiento más importante y revelador del estudio es el papel absolutamente crítico que desempeñan las herramientas. Los investigadores compararon el rendimiento de los agentes que tenían acceso a un navegador web con el de los «agentes de conocimiento cero», es decir, LLMs que solo podían responder basándose en el conocimiento estático de su entrenamiento. La diferencia fue abismal. Los agentes con capacidad para investigar activamente en internet superaron a sus homólogos ciegos por un margen enorme. Este hallazgo es fundamental. Demuestra que el futuro de la IA útil no reside en modelos que simplemente «saben» más cosas, sino en agentes que pueden «descubrir» y «razonar» sobre nueva información. La inteligencia predictiva no es una función de la memoria, sino de la investigación.
Profundizando en el comportamiento de los agentes exitosos, los investigadores identificaron un patrón de razonamiento sofisticado al que denominaron razonamiento sinérgico. Observaron que los mejores agentes no se limitaban a encontrar una única fuente y a basar su predicción en ella. En cambio, eran capaces de llevar a cabo una investigación multifacética, recopilando información de diversas fuentes que a menudo presentaban perspectivas diferentes o contradictorias. El agente era entonces capaz de sintetizar esta información, sopesar la credibilidad de las diferentes fuentes y combinar las pruebas para llegar a una conclusión que era más matizada y precisa que la que se podría obtener de cualquier fuente individual. Por ejemplo, para predecir los ingresos de una empresa, un agente podría combinar el análisis de un informe oficial de la empresa, varios artículos de noticias y el sentimiento general de los debates en foros financieros para formar una imagen completa. Es la esencia del buen análisis: la síntesis de información diversa.
Por supuesto, no todos los intentos fueron exitosos. El análisis de los fracasos es a menudo tan instructivo como el de los éxitos. Los investigadores identificaron varias causas comunes de error.
- Una de las principales fue la mala interpretación de la pregunta. A veces, la IA no lograba captar los matices de la pregunta, lo que la llevaba a buscar información irrelevante y a basar su predicción en premisas incorrectas.
- Otro problema frecuente era la incapacidad para manejar información contradictoria o la desinformación. A veces, un agente encontraba una fuente poco fiable o deliberadamente engañosa y le daba demasiada credibilidad, lo que sesgaba su predicción final.
Estos fracasos son cruciales porque nos muestran dónde deben centrarse los esfuerzos de investigación en el futuro: en mejorar la comprensión del lenguaje, en desarrollar un escepticismo algorítmico y en enseñar a los agentes a evaluar críticamente la fiabilidad de las fuentes. El innovador benchmark, por lo tanto, no solo actúa como un examinador, sino también como un diagnóstico, revelando las debilidades que deben ser curadas para que estos agentes puedan alcanzar su máximo potencial.
Las implicaciones de un oráculo digital
El desarrollo de esta plataforma y la demostración de que los agentes de IA pueden predecir el futuro con una precisión cada vez mayor no es un mero avance académico. Es un hito tecnológico que presagia una transformación profunda en la forma en que las industrias, los gobiernos y la sociedad en su conjunto toman decisiones. Las implicaciones de tener acceso a un «oráculo digital», aunque imperfecto, son vastas y abarcan tanto promesas extraordinarias como desafíos formidables.
En el lado positivo, las aplicaciones potenciales son casi ilimitadas. En el mundo de las finanzas, los agentes de IA podrían actuar como analistas incansables, monitorizando los mercados globales 24 horas al día, identificando riesgos y oportunidades que pasarían desapercibidos para los humanos. Podrían democratizar el asesoramiento financiero, proporcionando análisis sofisticados a los inversores minoristas. En el campo de la ciencia y la medicina, los agentes podrían acelerar el descubrimiento prediciendo los resultados de los experimentos, identificando qué líneas de investigación son más prometedoras o incluso prediciendo brotes de enfermedades al analizar datos de salud pública en tiempo real. En la gestión de la cadena de suministro, podrían anticipar interrupciones debidas a eventos climáticos o tensiones geopolíticas, permitiendo a las empresas redirigir los envíos y evitar la escasez.
Los gobiernos también podrían beneficiarse enormemente. Los analistas de inteligencia podrían utilizar estos agentes para prever la inestabilidad política o las crisis humanitarias, permitiendo una intervención diplomática temprana. Los planificadores urbanos podrían predecir los flujos de tráfico o las necesidades de vivienda, lo que conduciría a ciudades más eficientes y habitables. En la lucha contra el cambio climático, los agentes podrían modelar el impacto de diferentes políticas con mayor precisión, ayudándonos a elegir las estrategias más efectivas para mitigar sus efectos. En esencia, cualquier campo que dependa de la previsión y la toma de decisiones en condiciones de incertidumbre, es decir, casi todos los campos del quehacer humano, podría ser revolucionado.
Sin embargo, este inmenso poder conlleva riesgos igualmente inmensos que debemos abordar con seriedad y previsión. El primer y más obvio es el riesgo de una dependencia excesiva. A medida que las predicciones de la IA se vuelvan más fiables, existirá la tentación de aceptarlas sin cuestionarlas, abdicando de nuestro propio juicio crítico. Esto es peligroso. Los modelos de IA, como ha demostrado este proyecto, cometen errores. Sus fallos pueden deberse a sesgos en los datos de entrenamiento, a la desinformación o a una incapacidad para comprender un contexto verdaderamente novedoso. Un error de predicción en un sistema financiero o militar automatizado podría tener consecuencias catastróficas. Por lo tanto, será crucial desarrollar sistemas que no solo proporcionen una predicción, sino que también expliquen su razonamiento de una manera que los humanos puedan entender y verificar. La «explicabilidad» de la IA será tan importante como su precisión.
Otro riesgo significativo es el potencial de uso malicioso. Un agente de IA capaz de predecir movimientos del mercado podría ser utilizado para la manipulación o el uso de información privilegiada a una escala sin precedentes. Los actores estatales podrían utilizar la predicción de la IA para obtener ventajas geopolíticas o para crear desinformación y propaganda más eficaces. La misma tecnología que puede predecir una crisis también puede ser utilizada para provocarla. Esto crea una nueva y urgente dimensión en la carrera armamentística de la ciberseguridad, donde la defensa contra los malos actores impulsados por la IA se convertirá en una prioridad principal.
Finalmente, existen cuestiones éticas y sociales más profundas. ¿Qué sucede cuando las predicciones de la IA comienzan a influir en la vida de las personas, por ejemplo, en las decisiones de contratación, en la concesión de préstamos o en las sentencias penales? Si una IA predice que una persona tiene un alto riesgo de reincidir, ¿debería eso influir en su sentencia? Estas preguntas nos obligan a confrontar los posibles sesgos inherentes a los modelos y a garantizar que la búsqueda de la precisión predictiva no se haga a costa de la equidad y la justicia. El oráculo digital nos ofrece un poder inmenso, pero también nos impone una responsabilidad igualmente inmensa: la de empuñar este poder con sabiduría, prudencia y un compromiso inquebrantable con los valores humanos.
El horizonte, qué sigue para FutureX y la predicción de IA
El proyecto FutureX no es una iniciativa con un punto final; está diseñado para ser una plataforma viva y en constante evolución, un compañero de viaje en la búsqueda de la inteligencia artificial predictiva. Los resultados iniciales, aunque prometedores, son solo el primer paso en un largo camino. La propia arquitectura de este benchmark en vivo le permite crecer en sofisticación a medida que los agentes de IA también lo hacen, asegurando que el listón se eleve continuamente. El futuro de la investigación en este campo, guiado por este tipo de plataformas, se dirige hacia varios horizontes clave.
El primer horizonte es el de la complejidad de las preguntas y el razonamiento. Las preguntas actuales del sistema, aunque desafiantes, son en su mayoría binarias (sí/no) o numéricas y tienen horizontes de tiempo relativamente cortos. El siguiente paso es evolucionar hacia preguntas que requieran formas más complejas de razonamiento. Esto incluye preguntas condicionales («Si el evento A ocurre, ¿cuál es la probabilidad del evento B?»), preguntas comparativas («¿Qué estrategia de inversión es probable que tenga un mejor rendimiento en los próximos cinco años?») y preguntas que requieran una síntesis narrativa en lugar de una simple respuesta numérica. Abordar este tipo de preguntas obligará a los agentes a desarrollar capacidades de razonamiento causal y estratégico mucho más profundas.
El segundo horizonte es la expansión del conjunto de herramientas. Actualmente, la principal herramienta de los agentes en este entorno de pruebas es la navegación web. En el futuro, podemos imaginar agentes equipados con un arsenal de herramientas mucho más diverso y potente. Podrían tener acceso a bases de datos especializadas, a herramientas de análisis de datos que les permitan ejecutar código para modelar información, e incluso a la capacidad de interactuar con otras IAs para solicitar una segunda opinión o delegar subtareas. La verdadera inteligencia, tanto humana como artificial, a menudo reside en saber qué herramienta usar para cada trabajo. Probar esta capacidad será fundamental para crear agentes verdaderamente versátiles.
El tercer horizonte, y quizás el más importante, es el de la fiabilidad y la explicabilidad. Como hemos visto, el riesgo de una dependencia ciega de las predicciónes de la IA es significativo. La investigación futura se centrará intensamente en hacer que los agentes no solo sean más precisos, sino también más transparentes. El objetivo es desarrollar agentes que, junto con su predicción, puedan proporcionar un informe detallado de su proceso de razonamiento: qué fuentes consultaron, cómo sopesaron las pruebas contradictorias, qué suposiciones hicieron y cuál es el principal factor de incertidumbre en su predicción. Un oráculo que puede explicar por qué piensa lo que piensa es infinitamente más útil y seguro que uno que simplemente emite decretos desde una caja negra.
En última instancia, la visión a largo plazo que esta investigación ayuda a construir es la de una transición de la «predicción de eventos» a la «previsión estratégica». Predecir si una acción subirá o bajará es una cosa. Proporcionar un análisis exhaustivo de las tendencias del mercado, identificar los riesgos emergentes y sugerir una estrategia de inversión a largo plazo es otra muy distinta. El objetivo final no es simplemente crear IAs que puedan adivinar el futuro, sino crear IAs que puedan ayudarnos a entenderlo y a navegarlo con mayor sabiduría.
La invención de una herramienta de evaluación como esta es un hito porque nos proporciona, por primera vez, una forma rigurosa y realista de medir nuestro progreso hacia ese ambicioso objetivo. Es el mapa y la brúsa para nuestra expedición hacia el territorio desconocido de la inteligencia predictiva. El camino estará lleno de desafíos, tanto técnicos como éticos, pero por primera vez, tenemos una luz que nos guía, mostrándonos no solo lo lejos que hemos llegado, sino también la vasta y emocionante extensión del horizonte que aún nos queda por explorar.
Fuentes
- Li, Y., et al. (2025). FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction. arXiv preprint arXiv:2508.11987.
- Future X site

